NAVA
Native Audio-Visual Alignment for Generation
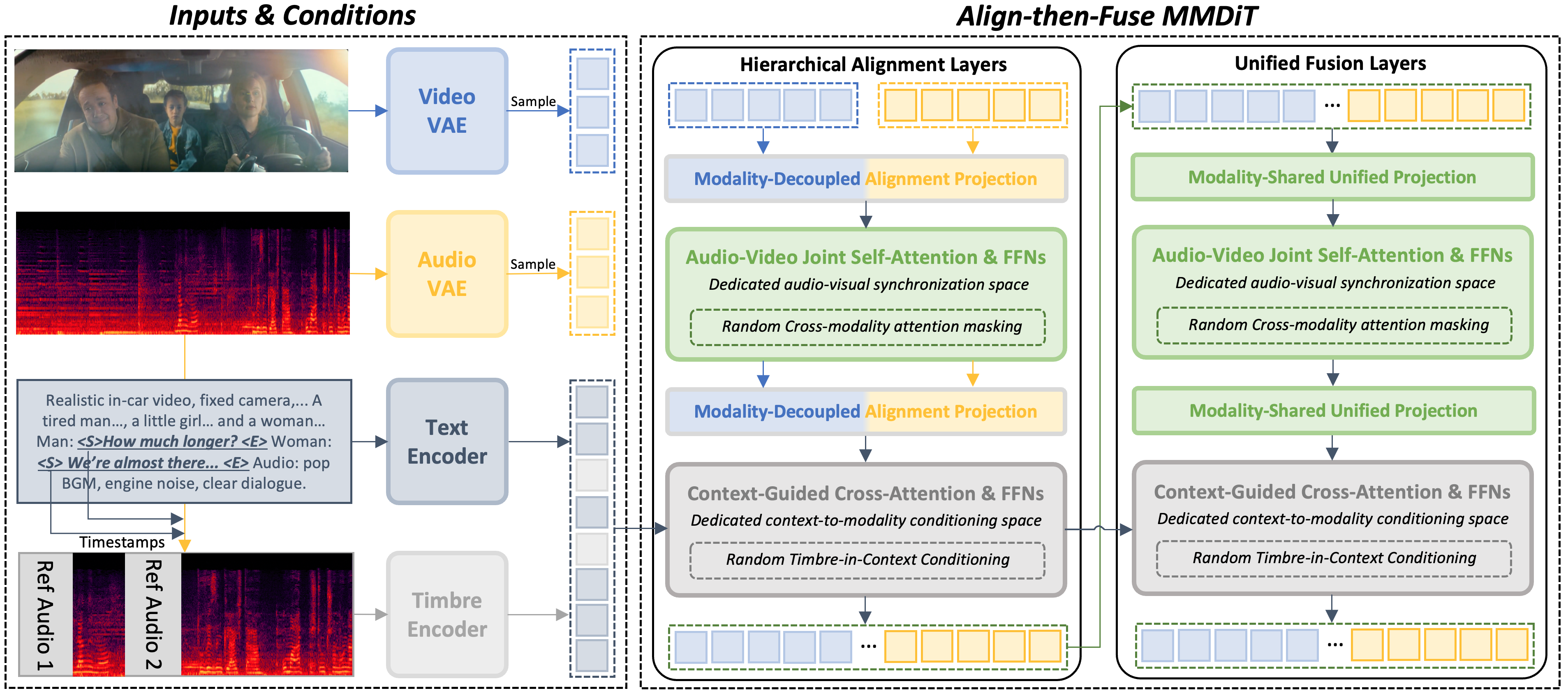
NAVA is a joint audio-video generation model that separates audio-video synchronization from semantic context. It enables precise alignment and controllable multi-speaker timbre by dedicating a space for native audio-visual alignment before context conditioning, improving on dual-tower and unified tri-modal methods.
Demos
The demos showcase NAVA's state-of-the-art native audio-visual alignment, generating synchronized audio and video with precise multi-timbre speech control and language-driven camera movements. Focus on the seamless integration of audio and video in a single denoising trajectory, natural speech timbres, and high visual quality at 720p resolution. This highlights NAVA’s efficiency and superior synchronization achieved with only 6.3B parameters.
Links
Paper & demos
Code & resources
Abstract
Joint audio-video generation aims to synthesize temporally synchronized and semantically coherent visual-acoustic content. However, existing open-source methods mainly rely on either dual-tower designs with posterior alignment or fully unified tri-modal designs that mix textual context, audio and video in one shared space. The former weakens fine-grained audio-video co-evolution, while the latter couples semantic conditioning with low-level synchronization. To address these limitations, we propose NAVA, a Native Audio-Visual Alignment framework for joint audio-video generation. NAVA is built upon context-conditioned native audio-visual alignment: it first establishes audio-video correspondence in a dedicated interaction space, and then uses external context to condition the joint denoising process. Specifically, NAVA is instantiated with an Align-then-Fuse MMDiT architecture, which transitions from modality-aware audio-video alignment to modality-shared joint denoising. Furthermore, we introduce Timbre-in-Context Conditioning to associate reference timbre cues with corresponding speech spans to achieve controllable speech timbre. Experiments on Verse-Bench and Seed-TTS, together with a user study, demonstrate that NAVA achieves superior video quality, precise audio-visual synchronization, competitive audio quality, and stronger reference-timbre controllability using only 6.3B parameters.
Introduction
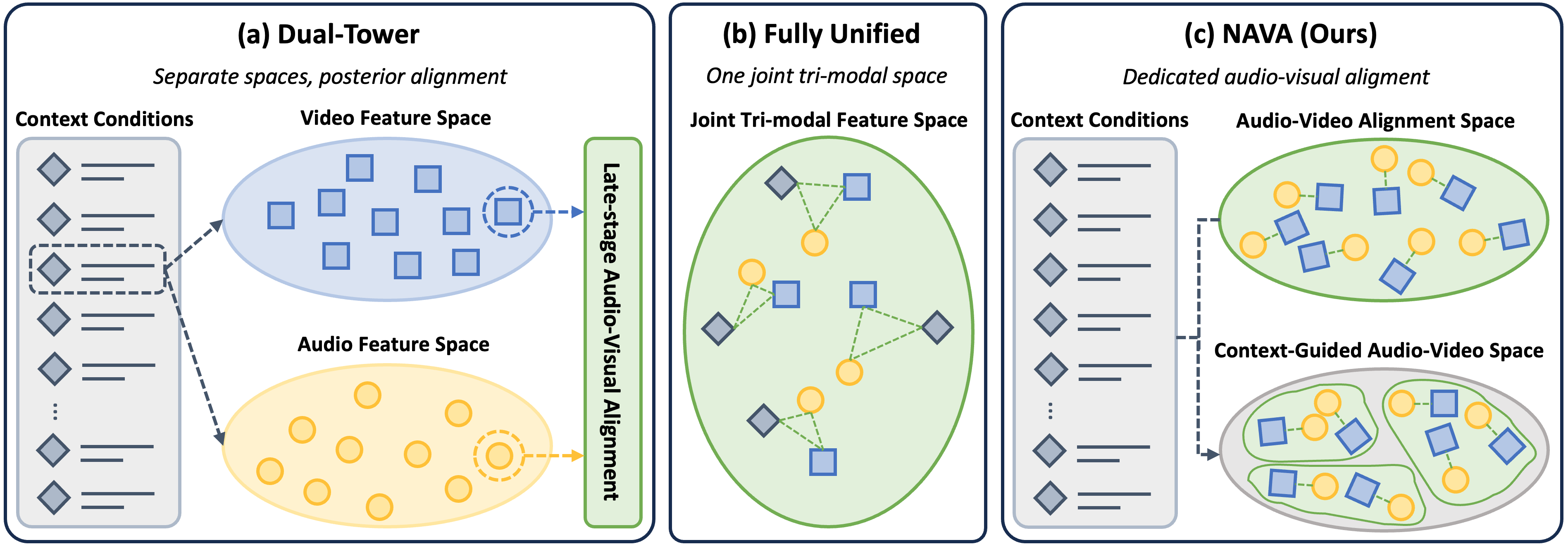
Native Audio-Visual Alignment for Generation proposes NAVA, a joint audio-video generation framework that explicitly separates audio-video synchronization from textual or reference conditioning. The paper is motivated by two shortcomings in existing open-source systems: dual-tower designs often establish audio-video correspondence only after each stream has already evolved independently, while fully unified tri-modal designs mix text, audio, and video into one shared space and thereby entangle semantic control with low-level synchronization. NAVA argues that better joint generation comes from first learning native audio-video correspondence in a dedicated interaction space and then using context as external guidance during denoising.
The core design is an Align-then-Fuse MMDiT architecture with Hierarchical Alignment Layers (HAL) followed by Unified Fusion Layers (UFL). Early layers preserve modality-aware alignment between audio and video tokens; later layers share generation parameters for compact collaborative denoising. The model is also extended with Timbre-in-Context Conditioning, which binds reference timbre cues to specific speech spans so the system can control who speaks which content without adding a separate speaker-control branch.
The paper reports that NAVA uses only 6.3B parameters yet achieves the strongest overall trade-off on Verse-Bench and strong timbre controllability on Seed-TTS. The resulting model is positioned as a practical middle ground between late-fusion dual-stream methods and fully unified tri-modal transformers: it preserves a dedicated synchronization pathway while still enabling context-controlled generation.
Problem Setting and Design Rationale
NAVA formalizes generation in terms of audio tokens $h_a$, video tokens $h_v$, and context tokens $c$, where $c$ contains text prompts and can be augmented with control signals such as reference timbre embeddings. The paper contrasts three paradigms.
In dual-tower systems, audio and video are first conditioned independently on context and then aligned later: $$h'_a = \operatorname{CrossAttn}(h_a, c), \qquad h'_v = \operatorname{CrossAttn}(h_v, c),$$ followed by $$[\tilde{h}_a, \tilde{h}_v] = \operatorname{CrossModalAttn}(h'_a, h'_v).$$ This late interaction can weaken fine-grained co-evolution during generation.
Fully unified systems place context, audio, and video into one attention space: $$[\tilde{h}_a, \tilde{h}_v, \tilde{c}] = \operatorname{SelfAttn}([h_a, h_v, c]).$$ This enables direct tri-modal interaction, but the paper argues it couples semantic conditioning and synchronization too tightly.
NAVA instead aligns audio and video in a dedicated interaction space and injects context afterwards: $$[h'_a, h'_v] = \operatorname{SelfAttn}([h_a, h_v]), \qquad [\tilde{h}_a, \tilde{h}_v] = \operatorname{CrossAttn}([h'_a, h'_v], c).$$ The intended effect is to let self-attention learn event-level correspondence, while cross-attention provides semantic and controllable guidance without disrupting the synchronization structure.
Method
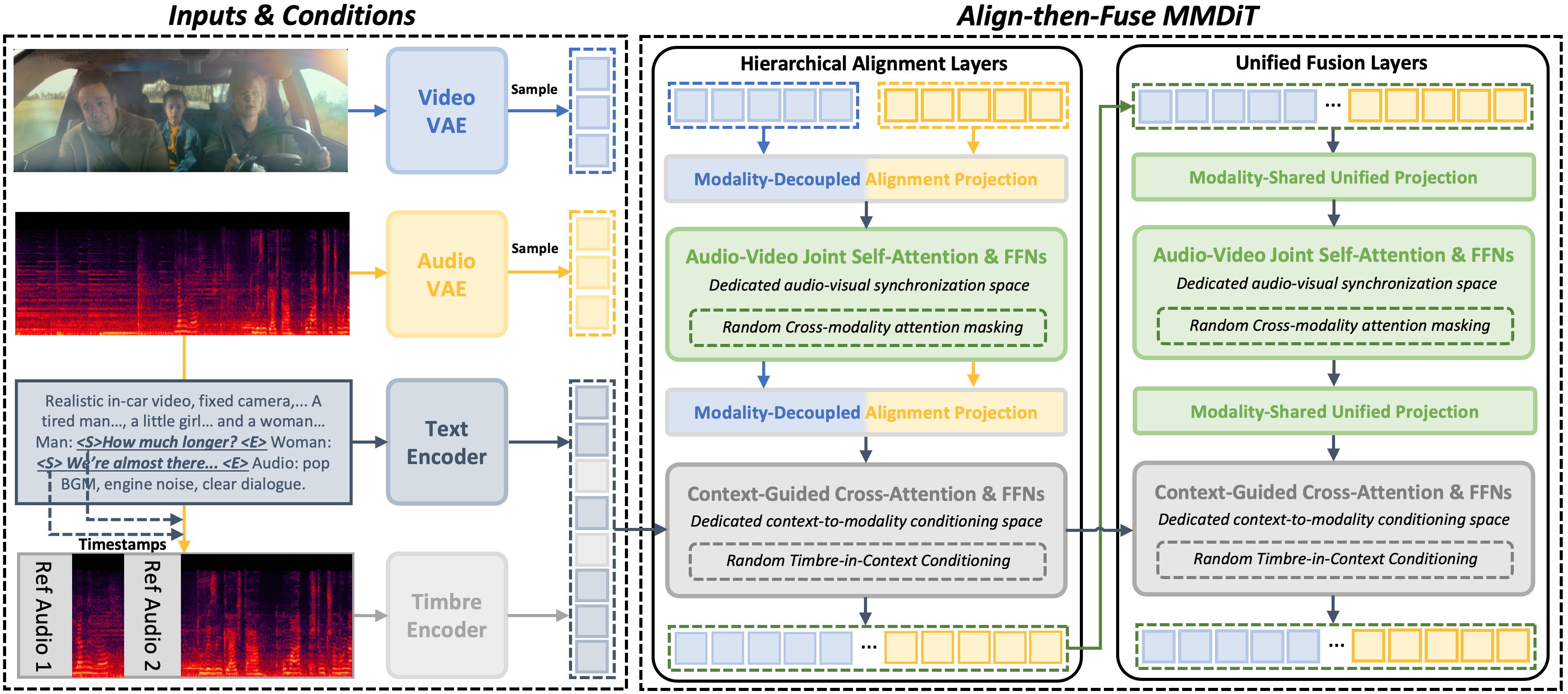
Align-then-Fuse MMDiT
NAVA is instantiated as a multimodal diffusion transformer with 30 MMDiT blocks: the first 10 blocks are HAL and the remaining 20 blocks are UFL. Audio and video are encoded into latent tokens by separate VAEs, while textual context and optional timbre cues are encoded as conditioning tokens. The architecture is intentionally progressive: it first reduces the representational gap between modalities, then shifts to shared fusion for efficient denoising.
Hierarchical Alignment Layers
The early HAL stages are designed to stabilize heterogeneous audio-video interaction before fully shared processing begins. Because audio spectrogram latents and video latents differ in token rate, spatial-temporal organization, and feature distribution, forcing them into one shared projection too early can suppress modality-specific structure. NAVA addresses this with modality-decoupled alignment projection: audio and video are mapped by modality-specific projections and then placed into a shared interaction space.
Within this space, the model uses audio-video joint self-attention and feed-forward networks to let acoustic and visual patterns co-evolve during denoising. The paper emphasizes that this is different from posterior alignment modules because the correspondence is learned during the generation trajectory itself. To handle rate mismatch, the rotary positional embedding for audio tokens is rescaled as $$\theta_{\mathrm{rope}} = \frac{TR_v}{TR_a},$$ where $TR_v$ and $TR_a$ are the video and audio token rates. Context is kept external and injected separately through cross-attention, preserving a dedicated audio-video synchronization space.
Unified Fusion Layers
After native correspondence has been established, NAVA transitions to UFL. Here, audio and video tokens share projections and transformer blocks, which reduces stream separation and supports compact collaborative denoising. The authors argue that this parameter sharing is more stable only after alignment has already reduced the modality gap. Context still enters via cross-attention, so semantic guidance remains decoupled from the synchronization mechanism.
Timbre-in-Context Conditioning
To control speech timbre, NAVA treats reference timbre as a contextual attribute attached to the relevant speech span rather than as a global control vector. For a speech span $\mathcal{S}_i$ with reference utterance $\mathcal{R}_i$, the model computes a timbre token $$\mathbf{s}_i = E_{\mathrm{tim}}(\mathcal{R}_i),$$ where $E_{\mathrm{tim}}$ is the timbre encoder. The span is rewritten as $$[\langle S \rangle,\, \mathbf{s}_i,\, \mathrm{Text}(\mathcal{S}_i),\, \langle E \rangle],$$ and all spans are augmented this way to form the context sequence. This allows different utterances in the same prompt to be assigned different timbres and supports compositional multi-speaker generation without modifying the backbone.
The paper highlights that this design is naturally compatible with the existing context-conditioning pathway and does not require an auxiliary speaker-control branch. In other words, timbre becomes one more contextual factor, but one that is explicitly anchored to speech spans instead of being broadcast globally.
Condition-Factorized Classifier-Free Guidance
NAVA extends classifier-free guidance by factorizing it into three directions: textual prompt adherence, audio-video alignment, and reference timbre preservation. Let $\mathbf{v}_\theta^{c,a,\tau}(z_t)$ be the prediction at step $t$ for noisy latent $z_t$, conditioned on text $c$, alignment interaction $a$, and timbre $\tau$. The paper defines $$\Delta_{\mathrm{text}} = \mathbf{v}_\theta^{c,a,\tau}(z_t) - \mathbf{v}_\theta^{\varnothing,a,\tau}(z_t),$$ $$\Delta_{\mathrm{align}} = \mathbf{v}_\theta^{c,a,\tau}(z_t) - \mathbf{v}_\theta^{c,\varnothing,\tau}(z_t),$$ $$\Delta_{\mathrm{timbre}} = \mathbf{v}_\theta^{c,a,\tau}(z_t) - \mathbf{v}_\theta^{c,a,\varnothing}(z_t),$$ and combines them as $$\hat{\mathbf{v}}_\theta(z_t) = \mathbf{v}_\theta^{c,a,\tau}(z_t) + s_{\mathrm{text}}\Delta_{\mathrm{text}} + s_{\mathrm{align}}\Delta_{\mathrm{align}} + s_{\mathrm{timbre}}\Delta_{\mathrm{timbre}}.$$ The key idea is that different guidance directions can independently tune prompt following, synchronization, and timbre matching at inference time.
To support these guidance directions during training, the model uses structured dropout. Random cross-modality attention masking creates partially decoupled audio-video paths for alignment guidance, while random timbre-in-context conditioning drops or replaces timbre tokens to create timbre-free and timbre-conditioned examples.
Data Pipeline, Prompting, and Training
The appendix describes a large-scale audio-visual corpus assembled from heterogeneous sources, including Koala-36M, TED-style speech videos, and raw movie/TV footage. Raw videos are segmented at scale using a Hadoop-based pipeline. To reduce shortcut learning from overlaid text and subtitles, the authors apply OCR-based filtering and subtitle removal with PaddleOCR. They also deduplicate clips by extracting video embeddings with VideoCLIP, clustering them with large-scale k-means, and merging or filtering small clusters.
Clips are tagged with modality-aware metadata. Visual tags are produced through VLM-based filtering and tagging, covering categories such as movies, documentaries, TV series, live streams, speeches, news, and interviews. Audio tags are produced using YAMNet and an omni-modal tagger to identify single-speaker speech, multi-speaker speech, ambient sound, music, and singing. These tags are used to construct subsets for pretraining and supervised fine-tuning.
Captioning follows a two-stage strategy. On the large-scale corpus, video and audio captions are generated separately with Qwen3-VL and Qwen3-Omni and then fused by concatenation or rewriting with Gemini-3-Flash. For higher-quality and multi-speaker subsets, Gemini-3-Pro is used to produce more accurate and temporally grounded captions. The paper also emphasizes structured dense captions at both training and inference time, rather than short free-form prompts, because joint audio-video generation needs prompts to specify scene layout, motion, camera behavior, lighting, and the temporal ordering of sound events.
The unified prompt template decomposes a clip into global visual description, temporal dynamics, camera and composition, and audio description. For speech videos, spans are explicitly marked with $\langle S \rangle$ and $\langle E \rangle$ and can include speaker timbre, emotion, speaking rate, and sound-field position. For non-speech clips, the template emphasizes action sounds, contact and friction sounds, object sounds, ambience, music, singing, and reverberation. This structured prompting is central to the model's support for temporally ordered, acoustically grounded generation.
Training uses a progressive multi-task schedule over T2AV, TI2AV, T2A, T2V, and TIA2AV tasks. Stage 1 trains on audio-only and paired audio-visual data with a $3:1$ sampling ratio to initialize the audio pathway while preserving visual capability from the pretrained video backbone. Stage 2 shifts to a $1:2$ ratio and mixes high-quality audio data with the full audio-visual dataset to improve audio fidelity and synchronization. Stage 3 fine-tunes on curated high-quality audio-visual data to improve instruction following and controllable generation, especially for multi-speaker dialogue, complex motion, and camera control.
The paper reports the following implementation details: NAVA has 6.3B parameters, uses 30 MMDiT blocks, is initialized from Wan2.2-5B, uses Wan2.2-VAE for video latents with a $4 \times 16 \times 16$ compression ratio, and uses LTX2.3-VAE for multi-channel audio latents. The reported training setup uses AdamW with learning rate $5 \times 10^{-5}$ on 128 NVIDIA H100 GPUs, effective batch size 512, and 70K steps. The model also uses random cross-modality attention masking and timbre-condition dropout with probabilities of $20\%$ each, plus image conditions sampled with probability $50\%$.
The appendix further describes the broader infrastructure: training is distributed with FSDP, an asynchronous server-based preprocessing pipeline reduces media I/O and encoding bottlenecks, and samples are bucketed by sequence length. Micro-batches contain only one modality to keep sequence lengths predictable, while modalities are interleaved across gradient accumulation steps. The appendix estimates a three-stage training cost of about 107,520 H100 GPU-hours on 160 NVIDIA H100 GPUs.
Data Statistics
- Raw collection: approximately 20M audio clips and 100M video clips.
- After subtitle filtering, quality filtering, near-duplicate removal, and alignment filtering: about 15M clips for large-scale training.
- Koala-36M contributes approximately 20% of the final training corpus.
- Average video duration: about 7 seconds.
- Supervised fine-tuning subset: about 160K high-quality samples with strong alignment and accurate captions.
Experimental Setup
The main evaluation follows the paper's Verse-Bench and Seed-TTS protocols. Verse-Bench is used for objective audio-video generation evaluation across speech videos, sound effects, and musical instruments. Seed-TTS is used for reference-timbre controllability under an audio-only evaluation protocol. For fairness, the paper compares against the base versions of all models without super-resolution, distillation, or post-processing modules, and rewrites all test prompts with Gemini-3-Flash to match each model's expected inference format while preserving benchmark semantics.
Reported baselines on Verse-Bench are Ovi 1.1, MoVA, daVinci-MagiHuman, and LTX 2.3, spanning the dual-tower and fully unified paradigms. For Seed-TTS, the paper compares against DreamID-Omni and also includes audio-only references such as CosyVoice, CosyVoice2, and Qwen2.5-Omni.
Evaluation metrics cover four dimensions: audio-video alignment, video quality, audio quality, and timbre controllability. For alignment, the paper reports Sync-C and Sync-D from SyncNet, plus ImageBind score. For video quality, it reports identity consistency and aesthetic score, summarized in the main table as a single video-quality score. For audio quality, it reports word error rate (WER), Production Quality (PQ) from AudioBox-Aesthetics, and Fréchet Distance (FD). For timbre controllability, it uses Seed-TTS timbre similarity, which is reported as speaker similarity in the table.
Main Results
On Verse-Bench, NAVA achieves the best overall synchronization and video quality with competitive audio quality, despite being substantially smaller than several baselines. The paper emphasizes that this outcome supports the align-then-fuse hypothesis: early dedicated alignment can improve synchronization without forcing the whole model into a fully unified tri-modal space.
| Model | Params | Resolution | Sync-C $\uparrow$ | Sync-D $\downarrow$ | IB $\uparrow$ | Video Quality $\uparrow$ | WER $\downarrow$ | PQ $\uparrow$ | FD $\downarrow$ |
|---|---|---|---|---|---|---|---|---|---|
| Ovi 1.1 | 10B | 720p | 7.484 | 7.979 | 0.199 | 0.636 | 0.102 | 5.843 | 0.942 |
| MoVA | A18B (32B) | 720p | 7.289 | 7.808 | 0.269 | 0.603 | 0.126 | 7.233 | 0.922 |
| daVinci-MagiHuman | 15B | 540p | 7.149 | 7.816 | 0.269 | 0.600 | 0.151 | 5.956 | 0.931 |
| LTX 2.3 | 19B | 512p | 7.248 | 7.690 | 0.337 | 0.576 | 0.106 | 6.946 | 0.829 |
| NAVA | 6.3B | 720p | 7.791 | 7.566 | 0.313 | 0.659 | 0.099 | 6.861 | 0.833 |
The strongest Verse-Bench result is NAVA's Sync-C = 7.791 and Sync-D = 7.566, showing the best lip-audio synchronization among the compared systems. It also obtains the best video-quality score at 0.659 and the best speech intelligibility with WER = 0.099. In terms of semantic alignment, NAVA's ImageBind score of 0.313 is below LTX 2.3's 0.337 but remains competitive. For audio quality, NAVA's PQ of 6.861 is below MoVA's 7.233, but its Fréchet Distance of 0.833 is close to the best value, which is LTX 2.3's 0.829.
On Seed-TTS, NAVA is evaluated as an audio-video model under an audio-only protocol and still achieves the best reference-timbre control among audio-video systems. It reaches WER = 4.20 and speaker similarity = 66.7, outperforming DreamID-Omni by a wide margin and even matching or surpassing the audio-only reference models on similarity.
| Model Category | Model | WER $\downarrow$ | Speaker Similarity $\uparrow$ |
|---|---|---|---|
| Audio | CosyVoice | 4.29 | 60.9 |
| CosyVoice2 | 2.57 | 65.2 | |
| Qwen2.5-Omni | 2.72 | 63.2 | |
| Audio-Video | DreamID-Omni | 31.76 | 35.7 |
| NAVA | 4.20 | 66.7 |
The Seed-TTS result is particularly notable because NAVA is not an audio-only system, yet it achieves a speaker similarity of 66.7, higher than every audio-only baseline in the table, while keeping WER at a competitive level. The paper interprets this as evidence that timbre can be controlled through the context pathway without sacrificing the joint-generation objective.
Qualitative Results
The qualitative figure highlights several difficult cases: speech in complex acoustic scenes, speech during motion, musical performance, multi-speaker dialogue, and shot transitions. The paper reports that NAVA produces temporally synchronized speech, sound effects, and instrumental audio even when the visual scene changes, and that it can maintain controllable speaker assignment across multi-speaker and multi-shot settings. This directly supports the claim that correspondence is learned natively rather than being added as a late-stage patch.
User Study
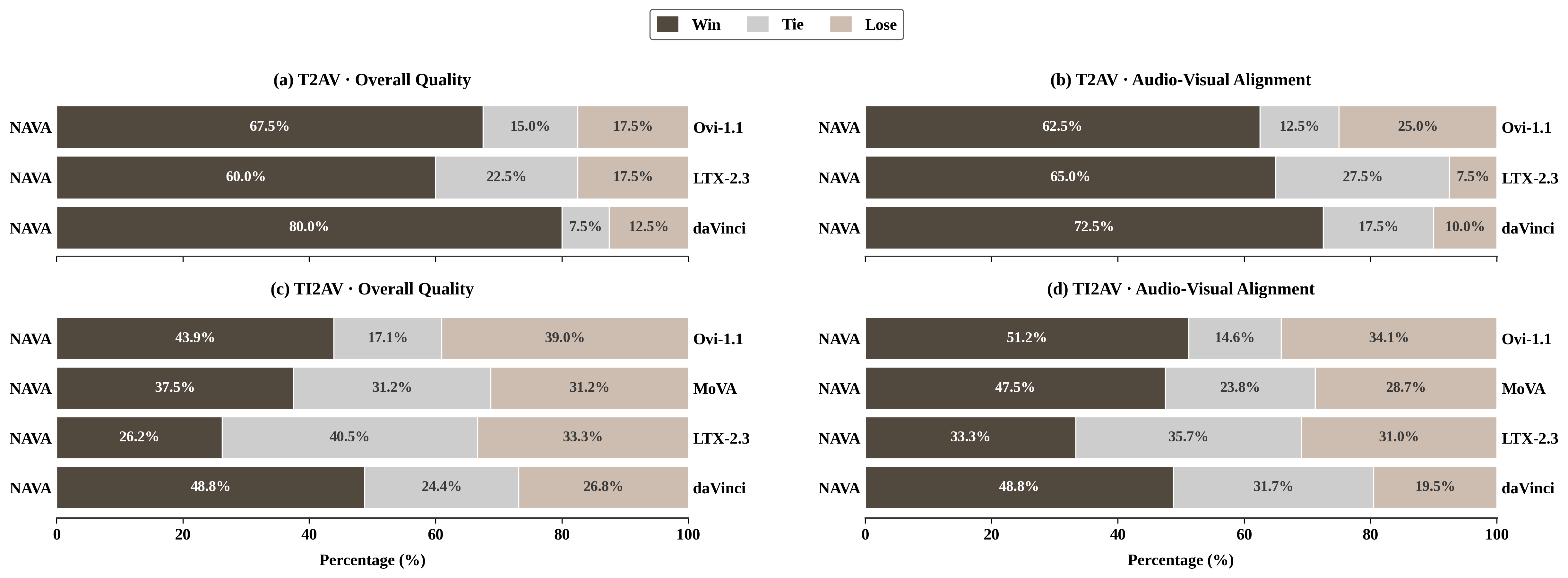
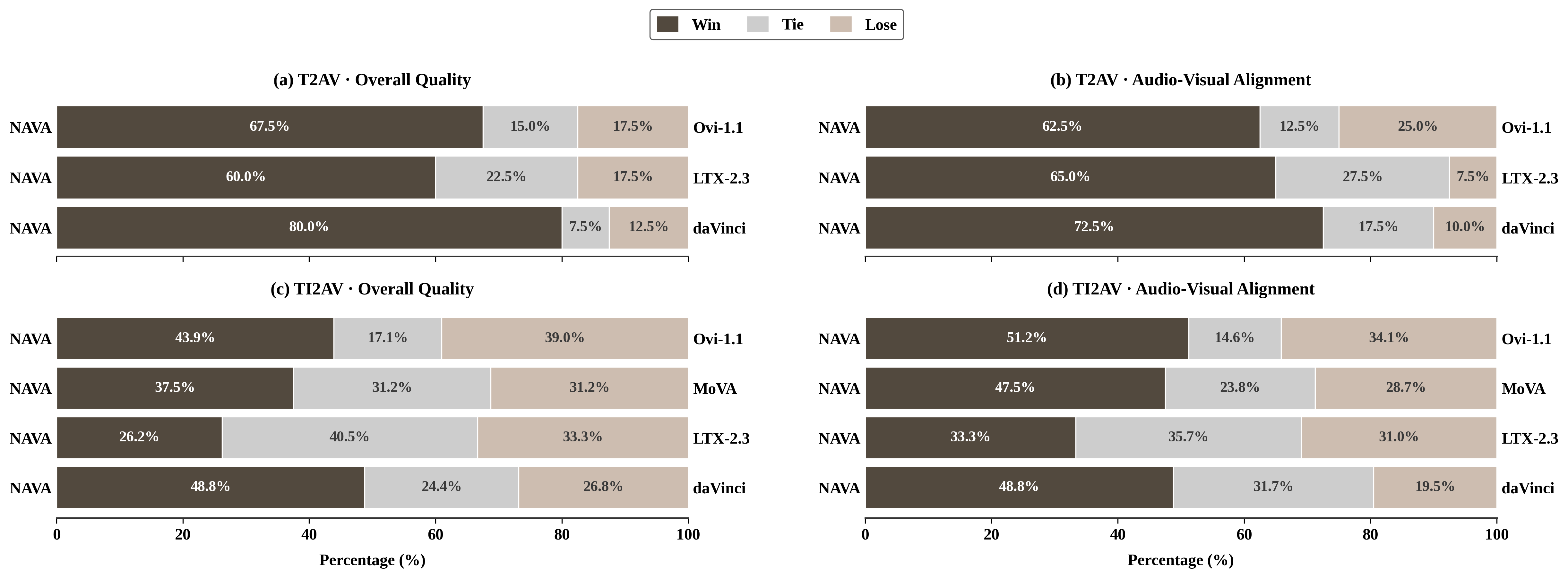
The paper conducts a GSB-based human evaluation over 250 cases covering both T2AV and TI2AV. Participants compare paired outputs on two axes: overall audio-visual quality and audio-visual alignment accuracy, and choose Win, Tie, or Lose. For T2AV, NAVA is compared against Ovi 1.1, LTX 2.3, and daVinci-MagiHuman; MoVA is excluded because its released model is not designed for text-only inputs in that setting. For TI2AV, NAVA is compared against Ovi 1.1, MoVA, LTX 2.3, and daVinci-MagiHuman.
The reported win rates show that NAVA is preferred in most comparisons, especially on alignment. On T2AV, NAVA achieves win rates of 67.5%, 60.0%, and 80.0% for overall quality against Ovi 1.1, LTX 2.3, and daVinci-MagiHuman, respectively, and alignment win rates of 62.5%, 65.0%, and 72.5%. On TI2AV, NAVA achieves overall-quality win rates of 43.9%, 37.5%, 26.2%, and 48.8% against Ovi 1.1, MoVA, LTX 2.3, and daVinci-MagiHuman, respectively, with alignment win rates of 51.2%, 47.5%, 33.3%, and 48.8%. The paper notes that LTX 2.3 remains competitive on TI2AV, but NAVA is strong on alignment across the comparison set.
Ablation Studies
Align-then-Fuse Architecture
The first ablation studies the contributions of HAL and UFL. The paper compares three variants: UFL only, HAL plus UFL, and HAL only. The table shows that removing the alignment stage hurts synchronization and semantic consistency, while removing the fused later stage reduces video quality and cross-modal consistency. The full align-then-fuse design is therefore the best overall compromise.
| HAL Layers | UFL Layers | Model Params | Sync-C $\uparrow$ | IB $\uparrow$ | Video Quality $\uparrow$ | PQ $\uparrow$ | WER $\downarrow$ |
|---|---|---|---|---|---|---|---|
| yes | 5B | 7.643 | 33.22 | 67.53 | 5.296 | 0.182 | |
| yes | yes | 6.3B | 7.684 | 34.34 | 67.67 | 5.377 | 0.177 |
| yes | 7.7B | 7.030 | 30.91 | 66.62 | 5.347 | 0.167 |
The combined HAL+UFL model has the best synchronization and semantic consistency, with Sync-C $= 7.684$ and IB $= 34.34$, and also the best video-quality score at $67.67$ and the best PQ at $5.377$. The UFL-only model shows that direct sharing without early alignment is weaker on correspondence, while the HAL-only model retains better audio-side metrics such as WER $= 0.167$ but loses video quality and semantic consistency. The paper's interpretation is that early alignment is necessary for fine-grained correspondence, but shared fusion is still important for compact collaborative denoising.
Condition-Factorized Guidance
The second ablation isolates alignment CFG and timbre CFG. Alignment CFG substantially improves synchronization on Verse-Bench, while timbre CFG improves reference-speaker matching on Seed-TTS. The results show that the guidance directions are indeed factorized: one can steer synchronization and timbre independently at inference time.
| Setting | Sync-C $\uparrow$ | Sync-D $\downarrow$ | IB $\uparrow$ | Video Quality $\uparrow$ | PQ $\uparrow$ | WER$_{\mathrm{VB}}$ $\downarrow$ | WER$_{\mathrm{Seed}}$ $\downarrow$ | ASV $\uparrow$ |
|---|---|---|---|---|---|---|---|---|
| NAVA without Align CFG | 6.170 | 8.755 | 0.355 | 0.667 | 6.658 | 0.126 | ||
| NAVA with Align CFG | 7.791 | 7.566 | 0.402 | 0.659 | 6.860 | 0.099 | ||
| NAVA without Timbre CFG | 3.78 | 65.5 | ||||||
| NAVA with Timbre CFG | 4.20 | 66.7 |
Alignment CFG increases Sync-C from 6.170 to 7.791, reduces Sync-D from 8.755 to 7.566, and improves IB from 0.355 to 0.402. It also improves audio metrics, reducing WER from 0.126 to 0.099 and increasing PQ from 6.658 to 6.860, while video quality changes only slightly. Timbre CFG increases speaker similarity from 65.5 to 66.7 but raises Seed-TTS WER from 3.78 to 4.20. The paper reads these results as evidence that the two guidance directions control different generation attributes rather than acting as a single entangled knob.
Interpretation and Limitations
Overall, the paper's empirical story is that NAVA improves joint audio-video generation by creating a native alignment stage before shared fusion. This helps it preserve video quality while achieving better synchronization than larger dual-tower and fully unified baselines. The timbre mechanism also shows that reference-speaker control can be expressed as contextual information tied to speech spans, which gives stronger controllability than global reference injection.
The authors explicitly note a remaining limitation: NAVA still struggles with certain long-tail and highly compositional audio events, including rare animal sounds, music, singing, and complex mixtures of scene sounds. They attribute this to data coverage and suggest broader, more carefully curated audio-visual data as the main remedy. They also mention a future direction toward even deeper audio-video coupling, including earlier fusion mechanisms such as joint audio-video tokenizers or unified representation models.
Conclusion
NAVA presents a clear architectural claim: separate native audio-video alignment from external semantic conditioning, then fuse them only after correspondence has been established. With HAL, UFL, and Timbre-in-Context Conditioning, the model demonstrates strong results on synchronization, video quality, audio quality, and reference-timbre controllability. The paper's experiments and ablations support the view that dedicated alignment space plus decoupled guidance is a promising direction for scalable and controllable audio-video generation.