IP-Adapter Fine-Tuning-Free Talking Face
IP-Adapter Is All You Need: Towards Fine-Tuning-Free Diffusion-Based Talking Face Generation
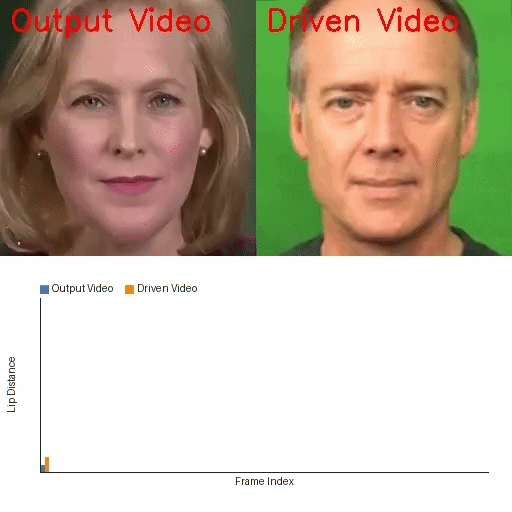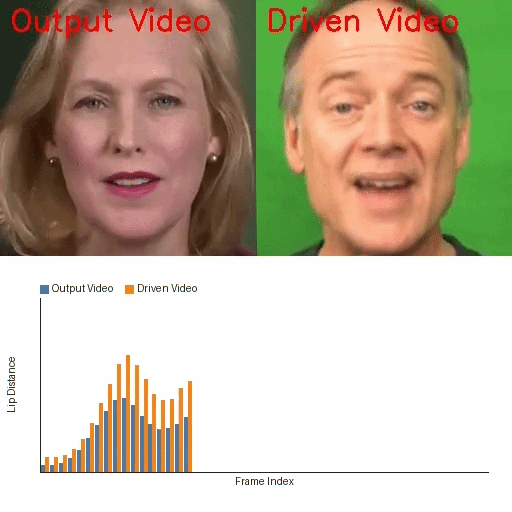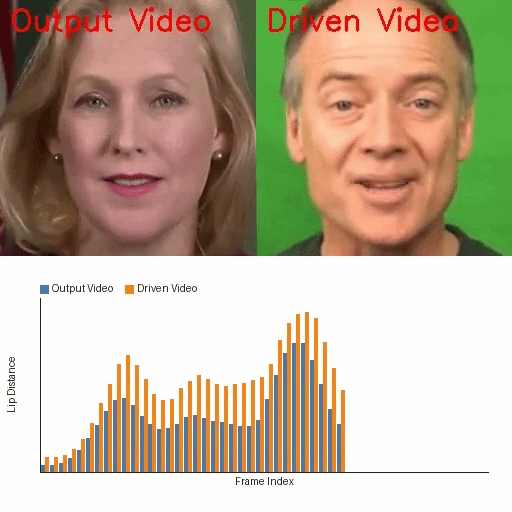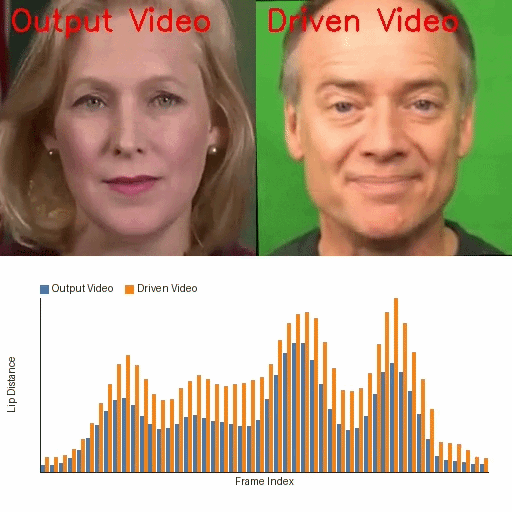
A fine-tuning-free diffusion framework that uses pretrained Stable Diffusion and IP-Adapter for lip-synced talking face generation. It addresses identity drift, lip-sync accuracy, and temporal flicker with parameter-free modules, enabling scalable and efficient talking face synthesis without costly model training.
Demos
The demo showcases the fine-tuning-free talking face generation capability of the IP-Adapter method using pretrained Stable Diffusion weights. Viewers should observe the precise lip synchronization, identity preservation without drift or distortion, and the high visual fidelity without flicker or temporal jitter, all of which highlight the method's strength in stable and realistic face animation without task-specific model fine-tuning.
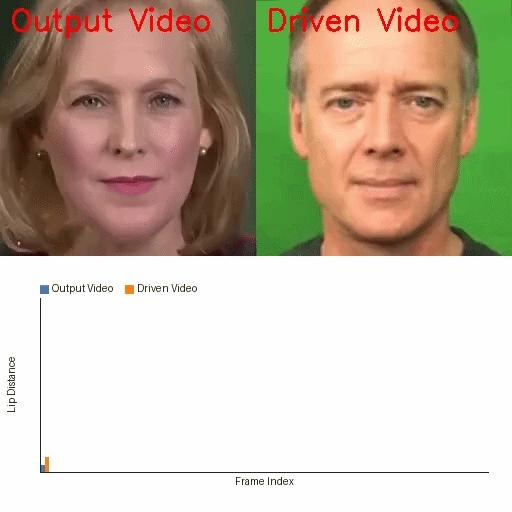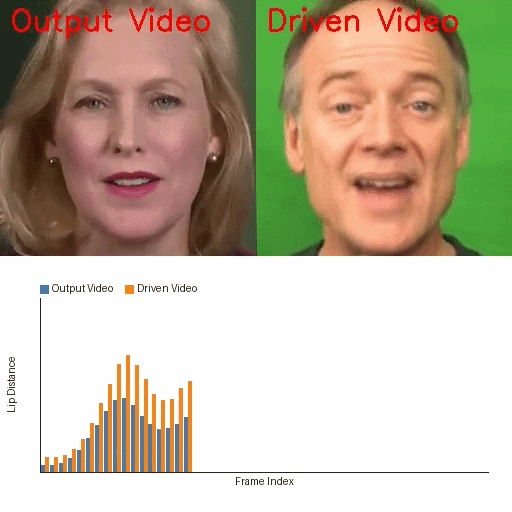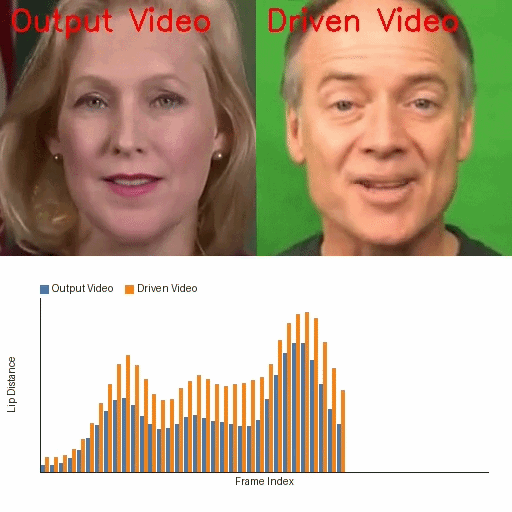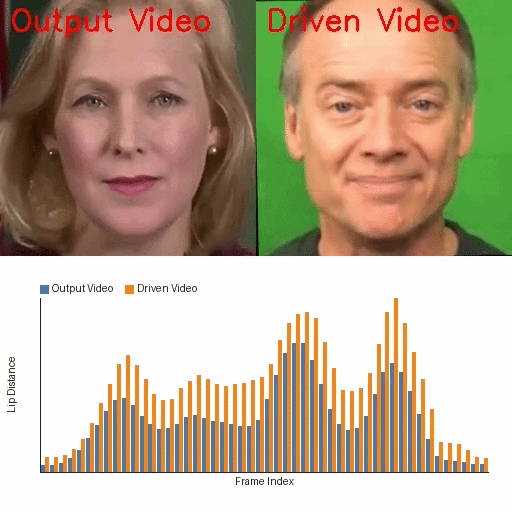
Links
Paper & demos
Code & resources
Impact
Abstract
With the rapid advancement of diffusion models, talking face generation has made remarkable progress. However, existing diffusion-based methods still require task-specific fine-tuning and large-scale audiovisual datasets, resulting in high computational costs that hinder scalability and accessibility of diffusion-based approaches across the research community. To address this, we propose a finetuning-free paradigm that directly performs talking face generation using the pretrained weights of Stable Diffusion and IP-Adapter. This backbone leverages the visual embedding capability of IP-Adapter to mine lip-related semantics from the pretrained Stable Diffusion. To address the challenges of identity drift, synchronization errors, and temporal instability, we also design three trainable-parameterfree components: (1) the Structurist, which explicitly disentangles and reassembles lip and appearance features to mitigate identity drift and appearance distortion; (2) the Structure Controller, which adaptively refines embeddings based on quasi-monotonic motion trends for precise lip synchronization; and (3) the Noise Sensor, which introduces Gaussian prior to detect and suppress flicker and jitter artifacts and enhance temporal consistency. Experimental results show that our method outperforms existing SOTA approaches in both lip-sync accuracy (at least 0.16 gain in PCLD) and visual fidelity (at least 0.7 improvement in FID), establishing a novel fine-tuning-free diffusion framework for talking face generation.
Overview and motivation
FreeTalkDiff is a fine-tuning-free diffusion framework for talking face generation. The central claim of the paper is that a pretrained pairing of Stable Diffusion and IP-Adapter already contains enough visual semantic capacity to drive lip-synchronized talking video synthesis, provided that the lip-conditioning signal is reorganized and stabilized carefully. The work is explicitly positioned against the dominant diffusion-based talking-face pipeline, where billion-parameter models are typically task-specifically fine-tuned on large audiovisual datasets with substantial GPU cost. In contrast, this method uses pretrained Stable Diffusion 1.5 and IP-Adapter-FaceID directly, with no additional trainable parameters and no task-specific fine-tuning.
The paper’s motivation is summarized by a set of empirical observations: IP-Adapter’s global image embedding tends to focus on the mouth region; however, a raw lip reference also leaks redundant color and texture, which can produce identity drift and appearance distortion. In addition, plain image-conditioned diffusion still exhibits imprecise lip control and temporal flicker/jitter. To address these three failure modes, the authors introduce three parameter-free modules: the Structurist, the Structure Controller, and the Noise Sensor.

The headline contribution is not a new diffusion backbone, but a way to reuse pretrained components for talking-face generation without further optimization. The authors claim this removes the main bottleneck of prior diffusion-based systems: long training schedules, large multi-GPU runs, and dependence on large-scale audiovisual corpora. In their comparison table of diffusion-based methods, the proposed approach is listed with 0.00 trainable parameters and no required train set, GPUs, steps, or fine-tuning cost.
Method overview
The pipeline builds on an image inpainting Stable Diffusion backbone combined with IP-Adapter-FaceID. The inputs are masked frames, random noise latents, and scaled masks, which are concatenated and denoised by the U-Net. At each layer, the FaceID variant of IP-Adapter injects identity embeddings and image prompts. The identity reference is encoded by ArcFace for identity preservation, while the lip reference is first converted into a structure frame by the Structurist and then encoded by a CLIP image encoder. The resulting structure embedding is further refined by the Structure Controller before being fused into the diffusion process. A Noise Sensor then suppresses temporal instability in the decoded video.
The design is intended for a few-shot setting: identity is conditioned by a short reference clip or image set, and the mouth motion is controlled by another reference clip. The authors state that the modules themselves have no trainable parameters, so the system does not require any task-specific training stage.
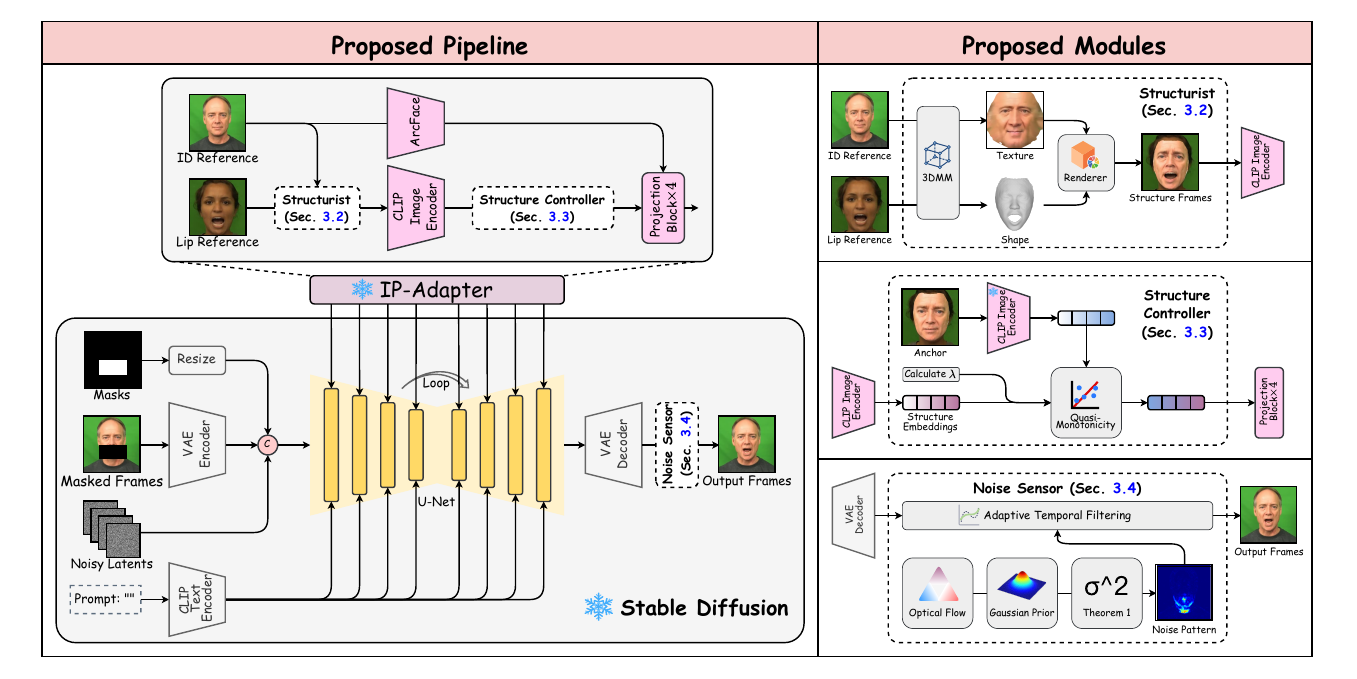
3DMM-based Structurist
The Structurist addresses redundant conditioning information. The paper uses a 3D Morphable Model to project lip-reference faces into shape and texture parameter spaces. Shape parameters carry lip-motion geometry, while texture parameters preserve appearance such as color and fine detail. Let the shape and texture of a face be represented as
$$P = \bar{P} + \sum_{i=1}^{M} \alpha_i \sigma_i^P v_i^P, \qquad Q = \bar{Q} + \sum_{i=1}^{M} \beta_i \sigma_i^Q v_i^Q,$$
where $\alpha_i$ and $\beta_i$ are shape and texture coefficients, and $\sigma_i^P$, $\sigma_i^Q$ are the corresponding eigenvalues. The Structurist combines the texture parameters from the target identity with the shape parameters from the lip reference, then renders the resulting parametric face into a structure image prompt, called the structure frame. This structure frame is passed through the CLIP image encoder inside IP-Adapter to produce the structure embedding used as the lip-motion condition.
The intended effect is to keep motion-related lip geometry while suppressing the leakage of appearance attributes from the reference lip clip. In the paper’s qualitative ablation, removing the Structurist allows texture and color from the structure frame to leak into the output, which causes identity drift and appearance distortion.
Quasi-monotonicity-based Structure Controller
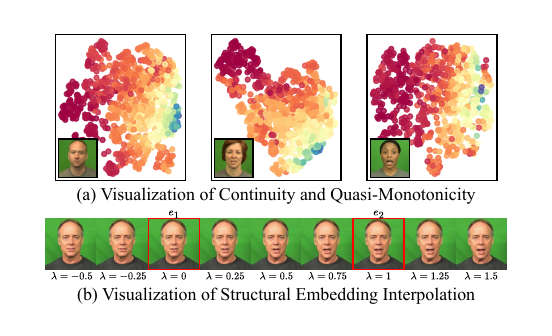
The Structure Controller is designed to improve fine-grained lip synchronization. The authors empirically analyze the structure-embedding space $\mathcal{E}$ by projecting embeddings to 2D with UMAP and coloring points by measured lip distance. They report two properties: continuity and quasi-monotonicity. Continuity means embeddings of the same identity form smooth clusters. Quasi-monotonicity means that moving along certain embedding directions changes lip opening approximately monotonically.
Formally, for the lip-distance function $f : \mathcal{E} \to \mathbb{R}^+$, the paper states the following behavior for linear interpolation and extrapolation between embeddings $e_1$ and $e_2$:
$$ \begin{cases} f((1-\lambda)e_1 + \lambda e_2) \leq \min\{f(e_1), f(e_2)\} & \forall\, \lambda \in (-\infty, 0] \\ \min\{f(e_1), f(e_2)\} \leq f((1-\lambda)e_1 + \lambda e_2) \leq \max\{f(e_1), f(e_2)\} & \forall\, \lambda \in (0, 1) \\ f((1-\lambda)e_1 + \lambda e_2) \geq \max\{f(e_1), f(e_2)\} & \forall\, \lambda \in [1, +\infty) \end{cases}. $$
This motivates an adaptive correction rule. Let $S_{\text{anchor}}$ denote the structure frame with the smallest lip opening, and let $\gamma(\cdot)$ be the lip-distance measurement. For the current frame, the adjusted embedding is
$$e_{\text{current}} = (1-\lambda)\,\mathrm{CLIP}(S_{\text{anchor}}) + \lambda\,\mathrm{CLIP}(S_{\text{current}}),$$
where $\lambda = \gamma(L_{\text{current}}) / \gamma(L_{\text{previous}})$. If the reference lips are opening, then $\lambda > 1$ and the embedding extrapolates toward a more open mouth configuration. If the lips are closing, then $\lambda < 1$ and the embedding is pulled back toward the anchor. The paper’s hypothesis is that this geometry-aware interpolation/extrapolation corrects the mismatch between generated and target mouth motion.
Gaussian-prior-based Noise Sensor
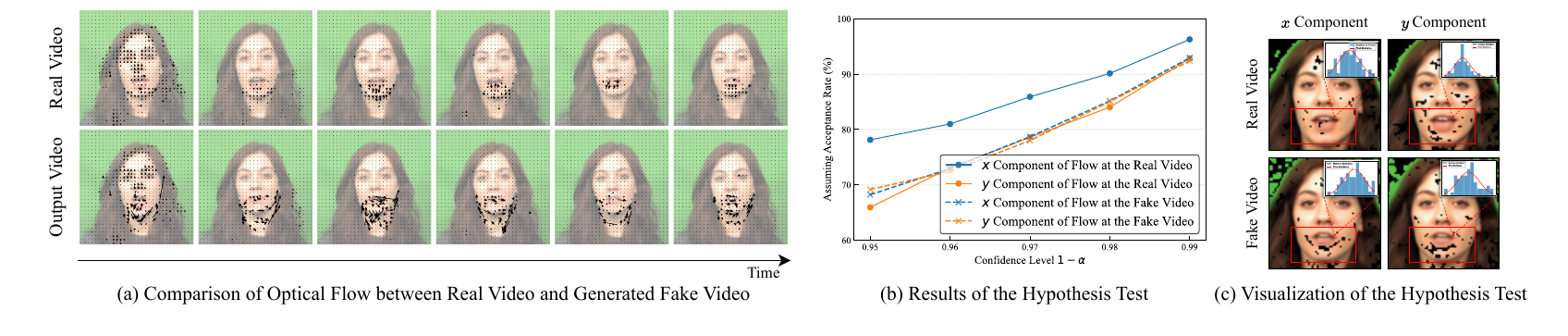
The Noise Sensor targets flicker and jitter in the mouth region. The authors observe that optical flow in real videos is smooth and continuous, whereas generated videos often show oscillatory motion. They test a Gaussian prior on lip-region optical flow using the Shapiro-Wilk test and report that, at confidence level 0.99, 92.4%–96.3% of pixels follow a Gaussian distribution. This motivates a statistical noise model for temporal artifacts.
Under the Gaussian assumption, the optical flow vector at pixel $(i,j)$ is modeled as $\mathbf{V}_{ij} \sim \mathcal{N}(\boldsymbol{\mu}_{ij}, \mathbf{\Sigma}_{ij})$. The paper’s supplementary proof derives the noise variance for the generated video as
$$ \sigma_{\hat{\mathbf{R}}_{ij}}^2 = \sigma_{\mathbf{V}_{ij}^{\text{fake}}}^2 - \frac{\operatorname{Cov}^2(\mathbf{V}_{ij}^{\text{fake}}, \mathbf{V}_{ij}^{\text{real}})}{\sigma_{\mathbf{V}_{ij}^{\text{real}}}^2} \geq 0, $$
and defines the per-pixel noise pattern as
$$D_{ij} = \sqrt{\sigma_{\hat{\mathbf{R}}_{ij,x}}^2 + \sigma_{\hat{\mathbf{R}}_{ij,y}}^2}.$$
Larger $D_{ij}$ indicates stronger jitter or flicker. The Sensor then applies a spatially adaptive temporal Gaussian filter whose kernel is parameterized by the estimated noise magnitude:
$$G_{ij}(k) = \operatorname{softmax}\left(-\frac{k^2}{2D_{ij}^2}\right),$$
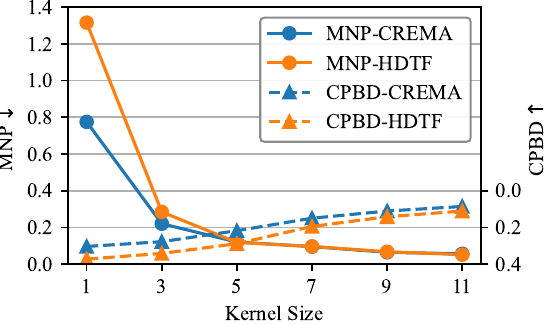
where $k$ is the temporal offset. The filter smooths noisy regions more aggressively while preserving cleaner regions, with the paper noting that a kernel size of 5 gives the best trade-off between stability and clarity.
What the method claims to solve
- Identity drift and appearance distortion: caused by redundant appearance cues from the lip reference; addressed by the Structurist.
- Imprecise lip control: the raw IP-Adapter embedding is too coarse for subtle lip motion; addressed by the Structure Controller.
- Temporal instability: flicker and jitter in the mouth region; addressed by the Noise Sensor.
The authors emphasize that these corrections are achieved without introducing trainable parameters, so the system remains compatible with the fine-tuning-free goal.
Experimental setup
The paper evaluates on two datasets. CREMA contains green-screen backgrounds, and HDTF contains high-definition in-the-wild videos. All clips are standardized to $512 \times 512$ resolution, 25 fps, and 16 kHz audio sampling rate.
The comparison includes ten representative methods spanning GAN-based, autoregressive, and diffusion-based families: Wav2Lip, MakeItTalk, Audio2Head, TalkLip, SadTalker, MuseTalk, LatentSync, EchoMimic, Hallo2, and Sonic.
For lip synchronization, the paper reports Procrustes Disparity (PD), Cosine Similarity of Lip Distance sequences (CSLD), and Pearson Correlation of Lip Distance sequences (PCLD). For visual fidelity, it reports FID, LPIPS, and CPBD. Lower is better for PD, FID, and LPIPS; higher is better for CSLD, PCLD, and CPBD.
Implementation-wise, the backbone uses Image Inpainting Stable Diffusion 1.5 and IP-Adapter-FaceID. Sampling uses the DPM-Solver++ scheduler with 20 steps. The Noise Sensor uses an adaptive Gaussian temporal filter with kernel size 5. Text prompts are left empty to avoid semantic interference.
Quantitative comparison
The main quantitative result is that FreeTalkDiff achieves the best performance on both datasets across all reported metrics. The paper summarizes the gains as at least 0.16 improvement in PCLD and at least 0.7 improvement in FID over existing state-of-the-art diffusion-based methods.
| Method | Type | CREMA | HDTF | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PD ↓ | CSLD ↑ | PCLD ↑ | FID ↓ | LPIPS ↓ | CPBD ↑ | PD ↓ | CSLD ↑ | PCLD ↑ | FID ↓ | LPIPS ↓ | CPBD ↑ | ||
| Wav2Lip | few-shot, non-diffusion | 0.01950 | 0.649 | 0.235 | 14.9 | 0.056 | 0.134 | 0.01897 | 0.756 | 0.358 | 12.4 | 0.057 | 0.205 |
| MakeItTalk | one-shot, non-diffusion | 0.02022 | 0.745 | 0.417 | 74.1 | 0.213 | 0.023 | 0.02443 | 0.752 | 0.250 | 87.5 | 0.293 | 0.042 |
| Audio2Head | one-shot, non-diffusion | 0.01506 | 0.807 | 0.531 | 80.2 | 0.313 | 0.058 | 0.01794 | 0.760 | 0.282 | 92.2 | 0.314 | 0.058 |
| TalkLip | few-shot, non-diffusion | 0.01396 | 0.783 | 0.475 | 15.4 | 0.065 | 0.146 | 0.01736 | 0.805 | 0.424 | 14.0 | 0.060 | 0.201 |
| SadTalker | one-shot, non-diffusion | 0.02442 | 0.666 | 0.337 | 61.6 | 0.294 | 0.108 | 0.01652 | 0.816 | 0.544 | 35.2 | 0.225 | 0.212 |
| MuseTalk | few-shot, diffusion | 0.01853 | 0.668 | 0.313 | 5.2 | 0.037 | 0.143 | 0.01790 | 0.788 | 0.343 | 2.4 | 0.037 | 0.241 |
| LatentSync | few-shot, diffusion | 0.01767 | 0.762 | 0.429 | 2.2 | 0.032 | 0.189 | 0.01483 | 0.827 | 0.540 | 1.5 | 0.025 | 0.255 |
| EchoMimic | one-shot, diffusion | 0.01925 | 0.665 | 0.310 | 71.0 | 0.291 | 0.081 | 0.01596 | 0.840 | 0.524 | 50.1 | 0.476 | 0.145 |
| Hallo2 | one-shot, diffusion | 0.02030 | 0.627 | 0.121 | 7.9 | 0.175 | 0.131 | 0.01524 | 0.844 | 0.547 | 3.9 | 0.191 | 0.211 |
| Sonic | one-shot, diffusion | 0.01774 | 0.707 | 0.408 | 32.9 | 0.228 | 0.104 | 0.01642 | 0.832 | 0.558 | 23.8 | 0.415 | 0.153 |
| FreeTalkDiff | few-shot, diffusion | 0.00860 | 0.887 | 0.711 | 1.5 | 0.020 | 0.218 | 0.01026 | 0.883 | 0.718 | 0.5 | 0.023 | 0.289 |
The table shows that the proposed method is strongest on both lip synchronization and visual fidelity. On CREMA, it achieves PD of 0.00860, CSLD of 0.887, PCLD of 0.711, FID of 1.5, LPIPS of 0.020, and CPBD of 0.218. On HDTF, it achieves PD of 0.01026, CSLD of 0.883, PCLD of 0.718, FID of 0.5, LPIPS of 0.023, and CPBD of 0.289. The paper attributes the gains in PD/CSLD/PCLD primarily to the adaptive Structure Controller, and the improvements in FID/LPIPS/CPBD to the Structurist and Noise Sensor.
Qualitative results
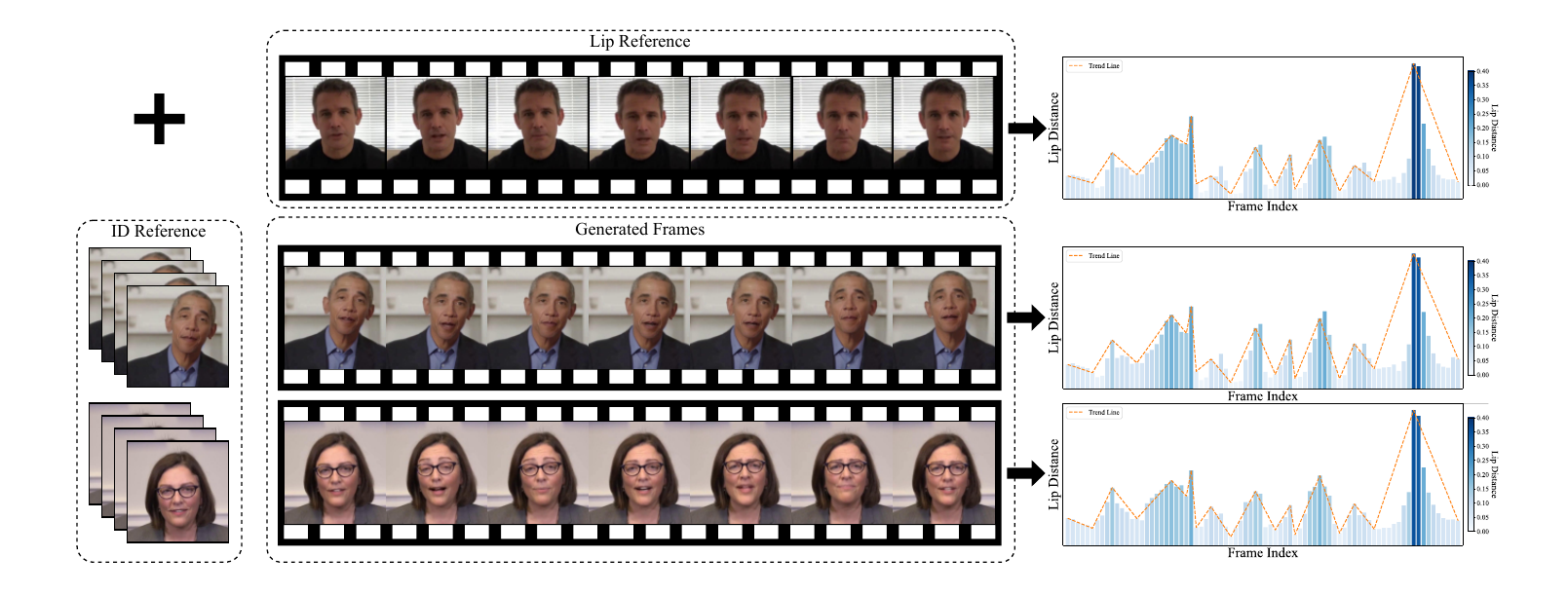
The qualitative results reinforce the quantitative findings. In frame visualizations, baseline methods often show weak, delayed, or even opposite lip-motion trends relative to the reference, while FreeTalkDiff tracks the target motion more faithfully. The lip-distance plots show that the generated sequence follows the ground-truth amplitude and rhythm more closely than competing methods.
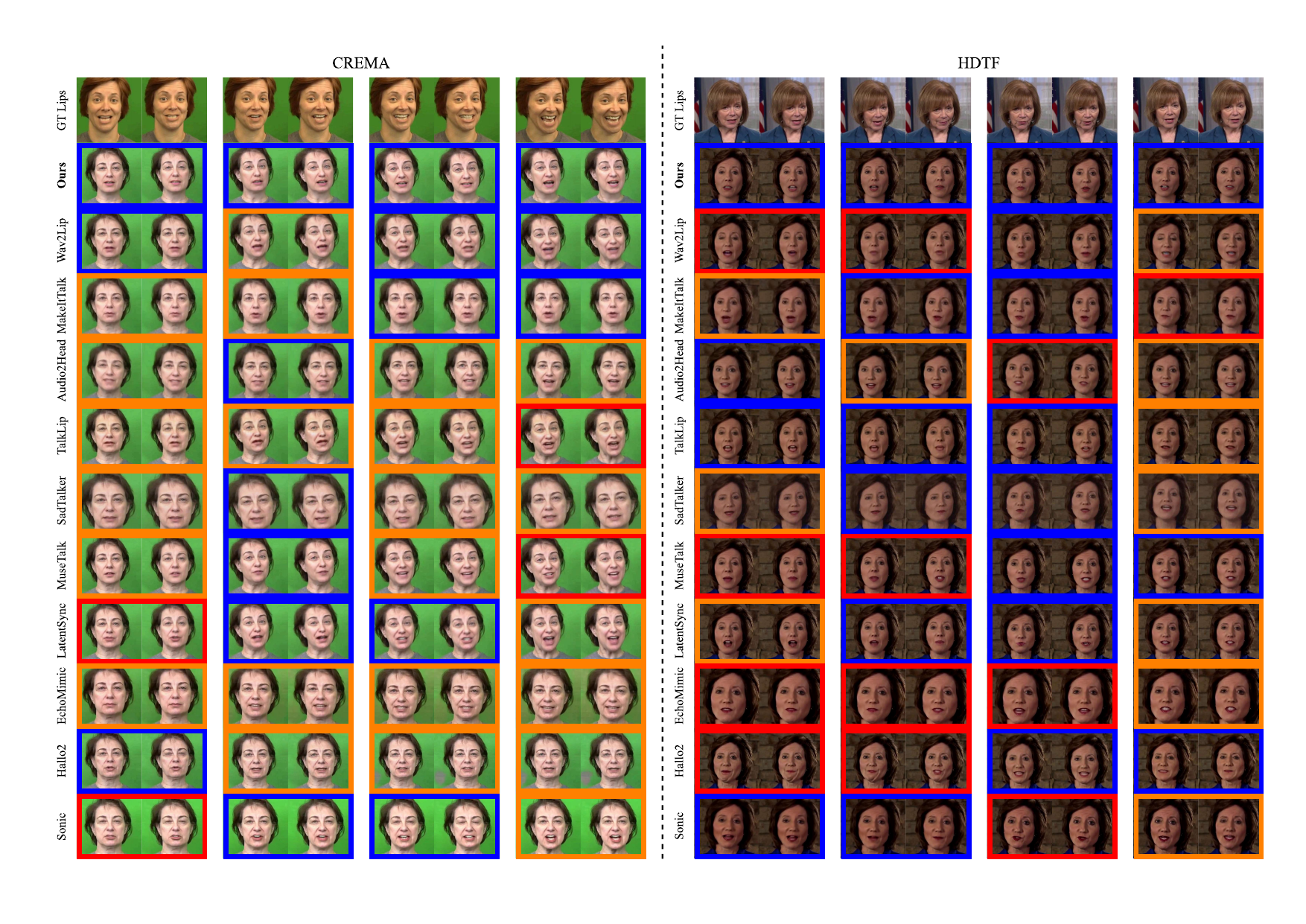
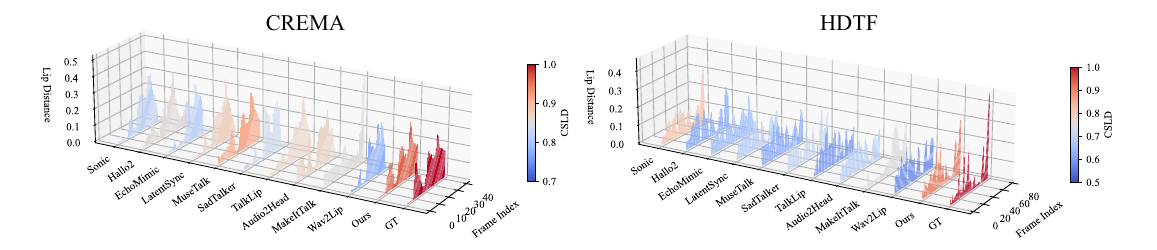
These visualizations are important because the paper’s main claim is not just better frame realism, but better motion correctness: the mouth should open and close with the same timing and amplitude trend as the reference clip, while identity and appearance should remain stable.
Ablation analysis
The paper includes ablations on each proposed module and on the temporal filter kernel size. The results support the authors’ modular decomposition of the problem: the Structurist controls identity leakage, the Structure Controller sharpens motion alignment, and the Noise Sensor suppresses temporal artifacts.
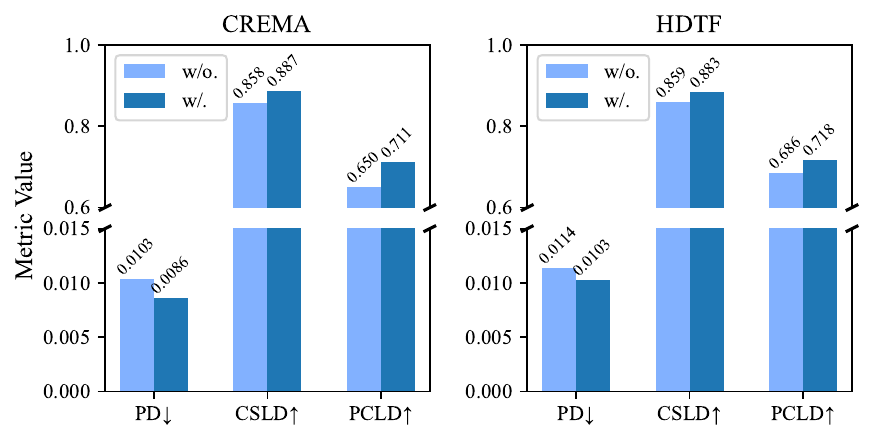
Structure Controller ablation
Removing the Structure Controller increases lip-shape error and weakens temporal motion alignment. The reported metrics are:
| Setting | CREMA | HDTF | ||||
|---|---|---|---|---|---|---|
| PD ↓ | CSLD ↑ | PCLD ↑ | PD ↓ | CSLD ↑ | PCLD ↑ | |
| Without Structure Controller | 0.01035 | 0.858 | 0.650 | 0.01135 | 0.859 | 0.686 |
| With Structure Controller | 0.00860 | 0.887 | 0.711 | 0.01026 | 0.883 | 0.718 |
Visually, the controller makes the generated lips follow the reference more accurately and reduces the mismatch in opening/closing rhythm.

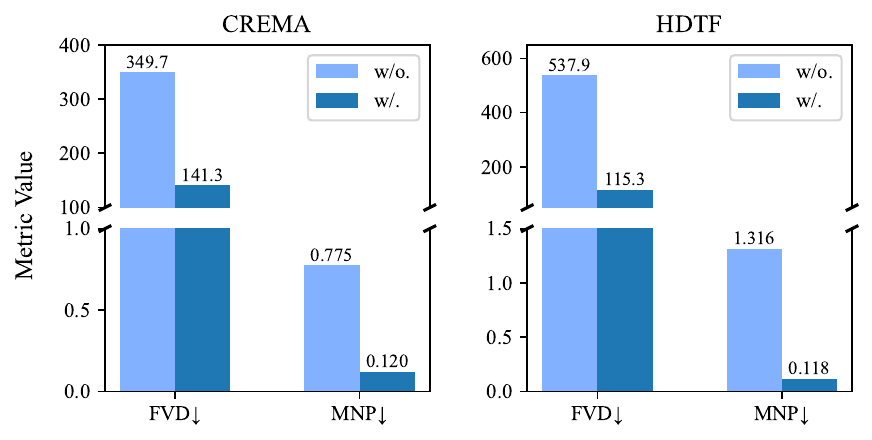
Noise Sensor ablation
Removing the Noise Sensor leads to substantially higher temporal artifact scores. The paper reports the following numbers using FVD and MNP (Mean of Noise Pattern):
| Setting | CREMA | HDTF | ||
|---|---|---|---|---|
| FVD ↓ | MNP ↓ | FVD ↓ | MNP ↓ | |
| Without Noise Sensor | 349.7 | 0.775 | 537.9 | 1.316 |
| With Noise Sensor | 141.3 | 0.120 | 115.3 | 0.118 |
The qualitative result is a visible reduction in mouth-region flicker and jitter after temporal filtering.
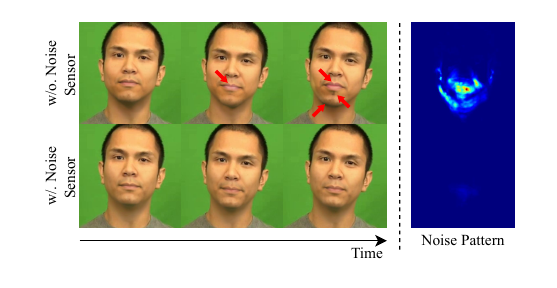
Structurist ablation
The paper does not provide a numerical table for the Structurist in the main text, but its qualitative ablation clearly indicates that without structural disentanglement, texture and color from the structure frame bleed into the output. This causes identity drift and appearance distortion. With the Structurist, the output is more consistent with the target identity, and the mouth expression can still be preserved because expression information is partly retained in the structural texture stream.

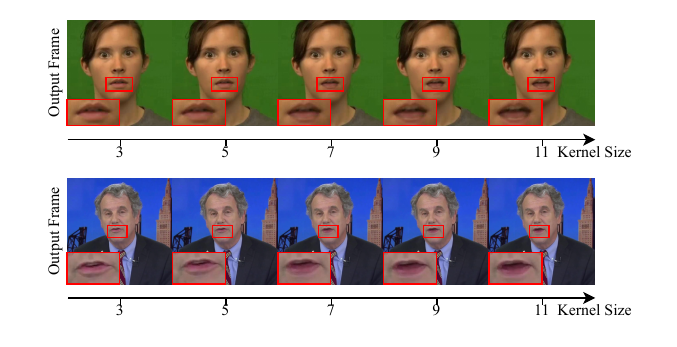
Kernel-size sensitivity for the temporal filter
The paper compares different kernel sizes for the adaptive temporal Gaussian smoothing. The qualitative conclusion is a standard bias-variance trade-off: larger kernels reduce flicker noise, but too much smoothing causes mouth-region blur and ghosting. The authors state that a kernel size of 5 provides the best compromise between temporal smoothness and visual clarity.
ArcFace ablation
ArcFace is used to inject identity information through the FaceID version of IP-Adapter. The ablation shows that removing ArcFace weakens identity preservation in the mouth region and introduces color and jawline discrepancies. This confirms that the identity pathway matters even though the system is otherwise fine-tuning-free.

Discussion and stated limitations
The supplementary discussion highlights several important boundary cases and limitations of the approach.
- Expression control through text prompts is possible but imperfect. The paper shows that text prompts can influence mouth expression, but this may create inconsistencies in other facial regions and reduce naturalness.
- Current IP-Adapter usage is still clip-level. The authors discuss that a hypothetical AnimateDiff + IP-Adapter backbone is attractive, but the current IP-Adapter shares one lip reference across the entire clip rather than assigning distinct lip features to each frame. As a result, that combination tends to produce static lip shapes and does not yet solve fine-tuning-free talking face generation.
- Pretrained ControlNet conditions are not lip-aware enough. Experiments with Canny edge, depth map, lineart, normal map, and OpenPose show that pretrained ControlNet fails to accurately control mouth shape. The paper attributes this to the destruction of fine lip details in many conditions and the lack of localized mouth dynamics in the pretrained representation.
- The temporal filter has a smoothing/blur trade-off. Larger kernels reduce flicker but also lower image clarity and can introduce motion blur or ghosting.


Ethical considerations
The paper explicitly notes the risk that realistic talking-face generation can be misused for deceptive or malicious deepfakes. To mitigate this, the authors show generated videos with a visible watermark and encourage transparent synthetic labeling and consent-based use.

Conclusion
The paper’s core conclusion is that pretrained Stable Diffusion plus IP-Adapter can be turned into a strong talking-face generator without task-specific fine-tuning, if the mouth-conditioning pipeline is carefully structured. The Structurist removes redundant appearance leakage, the Structure Controller corrects lip motion along quasi-monotonic embedding directions, and the Noise Sensor suppresses temporal artifacts with a Gaussian prior. Across CREMA and HDTF, the method is reported to outperform prior art on both lip synchronization and visual quality, establishing a new fine-tuning-free diffusion framework for talking face generation.
The authors’ future work is to explore multimodal fusion of semantic, emotional, and expressive cues, and to integrate large language models with visual diffusion models for end-to-end parameter-frozen audiovisual generation systems.
Code & Implementation
This repository implements the FreeTalkDiff framework for fine-tuning-free diffusion-based talking face generation as described in the paper.
The core implementation resides primarily in the pipelines/freetalkdiff.py file, which defines the main FreeTalkDiff pipeline class. This class extends a diffusion backbone pipeline and orchestrates the full generation process by integrating specialized trainable-parameter-free modules proposed in the paper:
- Masker: Handles segmentation-based masks for face and mouth regions.
- MediapipeStructurist: Extracts structured lip and facial embeddings using a MediaPipe-based canonical face model to explicitly disentangle lip and appearance features.
- StructureController: Refines the embeddings based on motion trends to improve lip synchrony, using insights from facial landmark heights over time.
- NoiseSensor: Acts to enhance temporal consistency by suppressing flicker and jitter artifacts in the generated frames.
The repository also contains supplementary modules implementing these core components under the modules/ directory (e.g., structurist.py, structure_controller.py, noise_sensor.py), aligning closely with the functionalities described in the paper.
An end-to-end inference script scripts/inference.py enables running the full pipeline with input identity and driving videos, following the example command in the README.
Overall, the repository provides a modular and extensible codebase matching the proposed fine-tuning-free pipeline leveraging pretrained Stable Diffusion and IP-Adapter backbones, integrating the specialized modules designed to address identity preservation, synchronization, and temporal stability in talking face generation.