Archon
Archon: A Unified Multimodal Model for Holistic Digital Human Generation
Archon is a unified multimodal model generating holistic digital humans by modeling seven modalities jointly. It uses efficient semantic video tokenization and a Thinking in Modality strategy to improve control and fidelity for talking-head video synthesis.
Demos
The demo videos showcase Archon's unified model generating digital humans by fusing description, script, speech, animation, segmentation, and video. Evaluate the coherence between speech and facial/body animations, and the quality of the semantic segmentation and video synthesis. These illustrate Archon's flexible any-to-any modality generation and efficient video parameterization for realistic outputs.
Links
Paper & demos
Code & resources
Impact
Abstract
Digital humans are fundamental to immersive interaction, yet creating a unified model for holistic modalities, including text, audio, motion, and visual content, remains an open challenge. In this paper, we present Archon, a fully pretrained, human-centric unified multimodal model for holistic avatar generation. Archon unifies seven modalities with modality-specific tokenizers, and a native autoregressive unified multimodal model pretrained on synchronized modalities and 72 diverse tasks to model holistic joint distributions. To address the token explosion challenge in high-fidelity talking videos, we introduce a memory-efficient semantic video reparameterization, achieving 4x token reduction while preserving fine-grained dynamics, coupled with a semantic-driven video diffusion decoder. We further propose a "Thinking in Modality" that decomposes ambiguous cross-modal tasks into stepwise thinking in an alternative chain of modality, progressively enhancing fidelity and controllability. Extensive experiments demonstrate that Archon achieves superior or comparable performance across diverse digital human generation tasks, validating the effectiveness of our unified framework. Project page: https://zju3dv.github.io/archon/.
Introduction
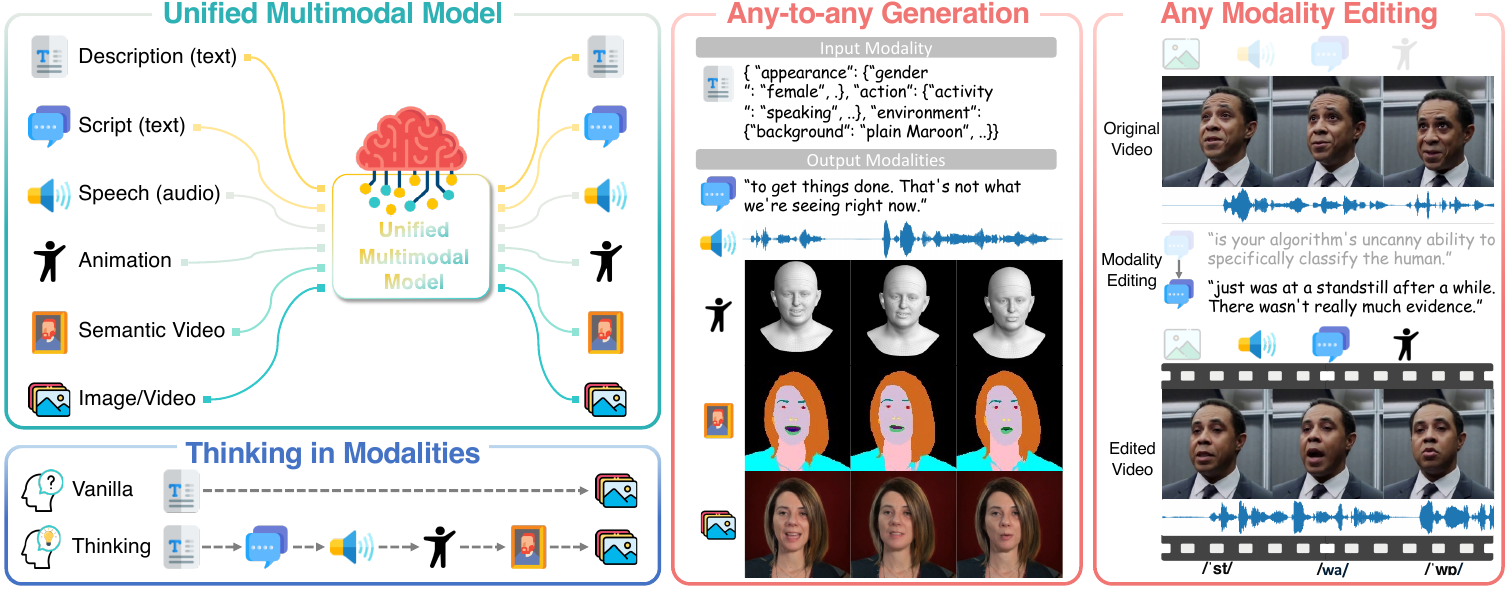
Archon is a unified, human-centric multimodal model for holistic digital human generation. The paper targets an unusually broad setting: instead of building separate systems for speech-driven video, image-conditioned speech, reenactment, lip reading, or text-driven avatar synthesis, Archon aims to model the joint distribution over a shared set of human modalities and support any-modality-to-any-modality generation, understanding, and editing.
The seven modalities are description, script, speech, animation, semantic video, image, and video. The central claim is that these signals can be treated as elements of a single autoregressive multimodal language model, provided that each modality has a tokenizer that turns it into discrete tokens and the model is trained on many synchronized cross-modal tasks.
The motivation is that existing digital-human systems are usually fragmented into specialized experts. Those experts can be strong on a narrow task, but they are brittle when composed, difficult to scale to new modalities, and limited in their ability to share representations across tasks. Archon instead pursues a holistic design: one backbone, multiple modality-specific tokenizers, and a task formulation that makes arbitrary input-output modality combinations trainable.
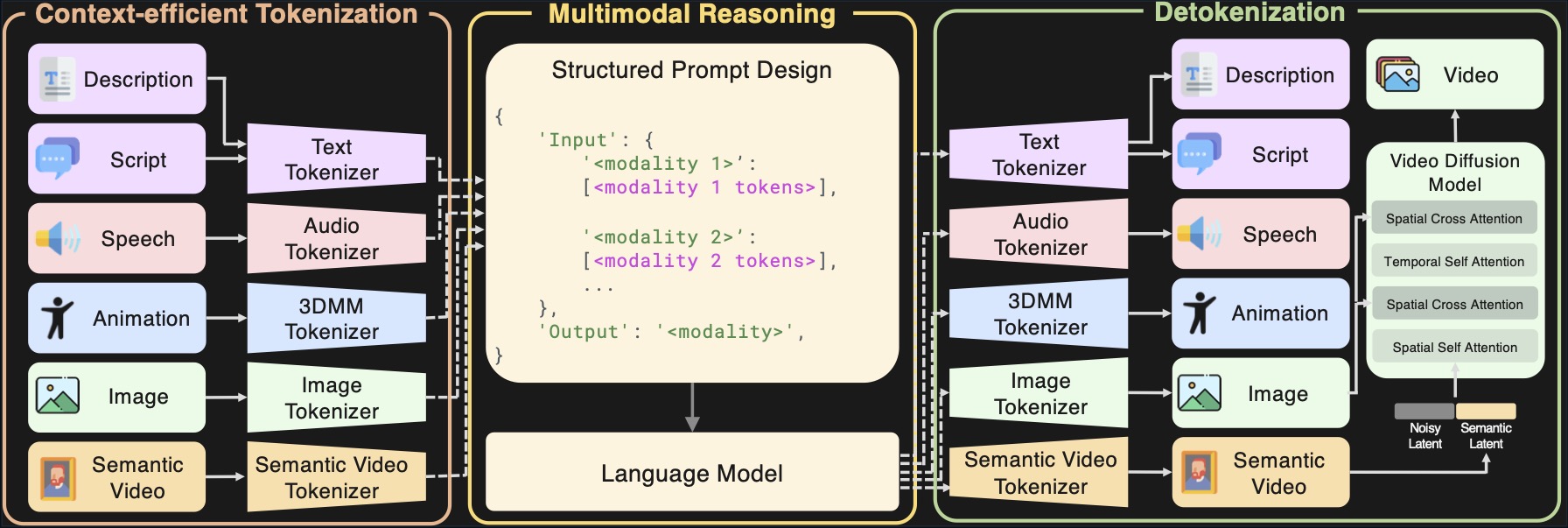
A second core challenge is token explosion for talking videos. A high-frame-rate human video can easily exceed the context budget of a language model if encoded with a conventional video tokenizer. Archon addresses this with a memory-efficient semantic video representation: rather than modeling RGB video directly in the language-model context, it tokenizes a semantic segmentation video and a reference image, reducing token count by about $4\times$ while preserving motion and structure, then uses a separate semantic-driven diffusion decoder to reconstruct a high-fidelity RGB video.
The third major idea is Thinking in Modality, an inference-time strategy that decomposes ambiguous cross-modal tasks into a chain of intermediate modalities. For example, speech-to-video can be routed through intermediate identity, expression, semantic, or description steps before final video synthesis. This is intended to reduce uncertainty and improve controllability without retraining.
Model overview
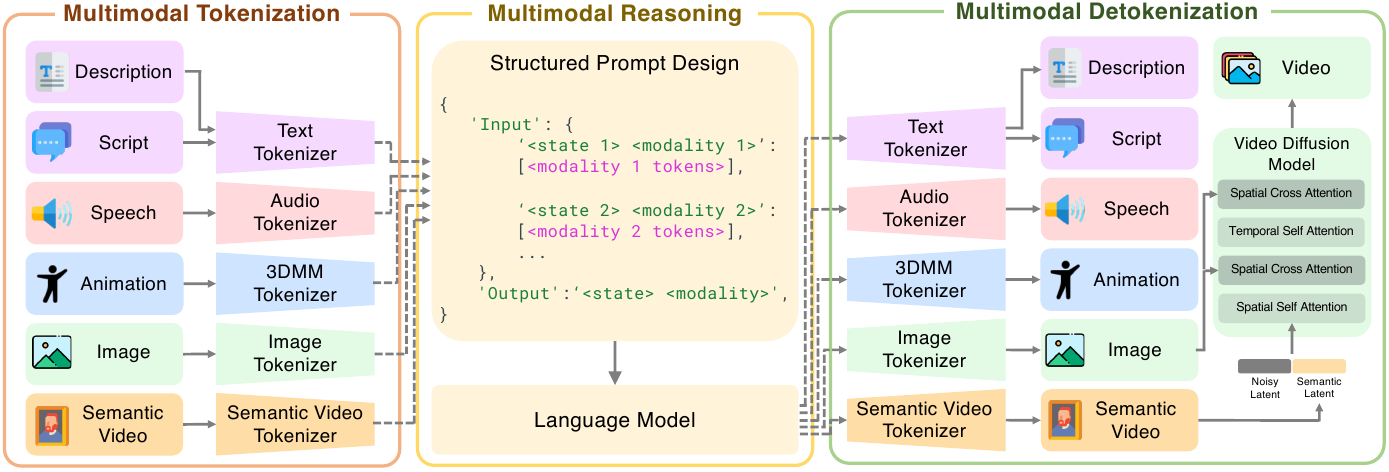
Archon has four main components:
- a set of modality-specific tokenizers;
- a native autoregressive language-model backbone for cross-modal reasoning;
- a semantic-driven diffusion decoder for high-quality video generation;
- an inference strategy called Thinking in Modality.
The backbone is a pretrained 1B PaLM2 model with bidirectional prefix attention. The multimodal vocabulary is organized into contiguous token ranges by modality, allowing all modalities to be represented in a unified sequence model. The paper emphasizes that the prompt is structured as natural-language descriptors rather than relying on a sparse set of special tokens, which helps the model parse the desired modality type, state, input, and output more explicitly.
Multimodal tokenization
Archon tokenizes each modality with a design chosen to balance fidelity and sequence efficiency.
Text and description
Text uses the original T5 tokenizer. Descriptions are generated as structured JSON-like attributes that capture appearance, action, and environment. The supplementary material shows that a vision-language model is prompted to return fields such as gender, age group, ethnicity, clothing, facial features, mouth action, head motion, gaze, lighting, background, and scene context. This structured description is then used as one of the modalities in the unified model.
Image tokenizer
Images are encoded using pretrained MAGVIT-v2. The paper uses the pretrained image tokenizer to quantize $256\times256$ images into a discrete $16\times16$ token grid, leveraging its high compression and visual fidelity.
Speech tokenizer
Speech is tokenized with a pretrained SoundStream residual vector quantizer. Audio is sampled at 16 kHz and represented at 25 frames per second. For efficiency and stability, the paper keeps only the first 4 residual quantization levels, each with a vocabulary of 1,024 codes, and orders the resulting token stream from lower to higher residual levels.
Animation tokenizer
Animation is represented with 3D Morphable Model parameters. The method tokenizes three components: identity or shape, expression, and pose. Each is encoded with a separate VQ-based model, because these factors differ in temporal behavior and semantic meaning. The main text describes this as a compact RVQ-style representation over shape, expression, and pose, while the supplementary implementation details provide the corresponding tokenizer architecture and training hyperparameters for the identity, expression, and pose streams.
In the supplementary architecture, the animation tokenizer is a 1D convolutional encoder-decoder with residual blocks and a residual vector quantizer. It compresses temporal animation sequences by a factor of $4$ in the temporal dimension before quantization, then reconstructs them symmetrically.
Semantic video tokenizer
The most distinctive tokenizer is the semantic video tokenizer. Instead of tokenizing RGB video directly, Archon decomposes a video into a reference image and a semantic video. The semantic video is made of discrete labels from a 21-class facial and upper-body parsing scheme, including categories such as background, face, neck, ears, hair, brows, lashes, pupil, iris, sclera, beard, glasses, clothes, headwear, accessory, lips, teeth, tongue, nostrils, and other-in-mouth.
This representation is designed to preserve motion and structure while discarding texture details that are expensive to model in the language-model context. The paper reports that this reduces token count by $4\times$ relative to direct RGB video tokenization and makes high-frame-rate talking videos tractable within an $8$K context window.
The semantic tokenizer itself is obtained by fine-tuning MAGVIT-v2 with an extra spatial downsampling step at the encoder input and a matching upsampling step in the decoder. The tokenizer uses an invertible color embedding to map each semantic label to a distinct RGB color, so the semantic mask can be treated as a color video for encoding and decoding. The codebook size is set to $2^{10}$.
The supplement states that this tokenizer is trained on $128\times128$ clips with a composite objective:
Here $\mathcal{L}_{\mathrm{recon}}$ is an $L_2$ reconstruction loss, $\mathcal{L}_{\mathrm{adv}}$ is a patch-based temporal adversarial loss with weight $\lambda_{\mathrm{adv}}=0.3$, $\mathcal{L}_{\mathrm{commit}}$ is the VQ commitment loss, and $\mathcal{L}_{\mathrm{seg}}$ is a pixel-wise cross-entropy-style segmentation loss with weight $\lambda_{\mathrm{seg}}=3.0$.
Autoregressive multimodal formulation
Rather than giving the model a separate task token for every possible input-output combination, Archon reformulates generation as a sequence of one-modality-at-a-time predictions. The paper divides the modality set into time-dependent modalities, including script, speech, expression, semantic masks, and video, and time-invariant modalities, including image, description, and shape or identity. The model is trained to generate one target modality conditioned on the current conditioning set and previously generated modalities.
In simplified form, the recurrence is:
This means the model learns to predict one modality at a time while conditioning on all available context. The authors argue that this preserves the expressive power of joint generation but substantially reduces task-space complexity.
The training prompt is not an opaque special-token sequence. Instead, the input is serialized as structured natural-language descriptors that make the modality type, state, input, and output explicit. This is intended to improve semantic grounding and reduce reliance on a small set of learned task markers.
Archon is pretrained on 72 multimodal tasks, and the supplementary material breaks them down into continuation tasks, cross-modal generation tasks, and chained generation tasks. The task set includes combinations such as speech-to-speech continuation, description-to-speech, speech-plus-image-to-semantics, and description-plus-script-plus-speech-plus-image to full semantic-video generation.
To balance the training mixture, the paper does not sample tasks uniformly. Instead, it uses multiple tasks per step and a difficulty- and frequency-aware weight:
where $p_i$ is the perplexity of task $i$ measured using a baseline model and $N_{m(i)}$ is the number of tasks whose output modality is $m(i)$. This is meant to counteract task-count imbalance, model bias, and difficulty variance.
Semantic-driven video diffusion
Discrete semantic tokens are useful for reasoning, but they do not directly produce photorealistic talking-head video. Archon therefore adds a second-stage video decoder: a semantic-driven latent diffusion model that turns semantic video, a reference image, and text into a high-quality RGB video.
The diffusion backbone is based on WALT, which the authors modify to accept low-resolution reference images, semantic masks, and textual descriptions. The semantic latents are concatenated with the noisy video latents along the feature dimension to provide strong motion guidance. The reference image is injected via cross-attention, and its segmentation mask is concatenated with the image latent before cross-attention so that appearance transfer is mediated by semantic structure.
The diffusion model is fine-tuned end-to-end. Reference images and semantic masks are processed at $256\times256$, while the output video is synthesized at $512\times512$. Training uses $v$-prediction and an $L_2$ loss on the predicted velocity.
The supplementary ablation on this module shows that both text conditioning and the joint cross-attention with reference-image semantics matter. Removing text conditioning worsens the reported scores, and using only the RGB reference image instead of the joint image-plus-segmentation conditioning also degrades quality.

Thinking in Modality
The paper observes that not all modality transitions are equally easy. Direct speech-to-video generation, for example, is more ambiguous than going through intermediate animation or description representations. Archon’s inference-time answer is to let the model “think” in a modality chain that gradually reduces uncertainty.
In practice, this means decomposing a hard target into a sequence of easier intermediate generations. One example in the paper is speech-to-video, where the model can be asked to produce 3DMM shape, expression, semantic video, and description before the final video. This strategy requires no retraining; it simply exploits the model’s ability to condition on multiple modalities.

The authors report that the full modality chain produces sharper outputs, better identity alignment, and better synchronization than direct generation. In the main ablation, the full chain outperforms a direct speech-to-video baseline on both CelebV-HQ and HDTF.
Training data and implementation
The model is trained on a large dataset of about 6,000 hours of monologue videos from the public internet. Each clip contains synchronized speech and script. The authors caption the videos with Gemini 2.5 Pro, fit 3DMM parameters using an optimization-based pipeline, and extract face segmentation using a DinoV2-based segmentation model.
For the video pipeline, the data are processed into head-centric clips: raw videos are decoded at $30$ fps, facial landmarks are detected, a bounding box is derived from the 3DMM fit, a stable crop is computed from the union of the boxes across the clip, and the crop is resized to $256\times256$.
Training the language model uses a pretrained 1B PaLM2 checkpoint with a multimodal vocabulary of about 550K tokens. The optimizer is Adam with weight decay $10^{-3}$, a $4{,}000$-step warmup from $0$ to $10^{-3}$, and cosine decay to $5\times10^{-5}$. The paper uses 256 TPUv6 Trillium chips for 20 days with batch size 256.
The diffusion model uses Adafactor, a $6{,}000$-step warmup to $1.2\times10^{-4}$, then a constant learning rate. It is trained on 128 TPUv6 chips for 10 days with batch size 128.
The supplementary implementation section also details tokenizer training. The semantic tokenizer is fine-tuned from MAGVIT-v2 for 140 hours on 4 TPU v4 devices, and the 3DMM tokenizers are trained with AdamW using cosine schedules and warm-up on 128 TPU v2 devices.
Experiments: qualitative capabilities
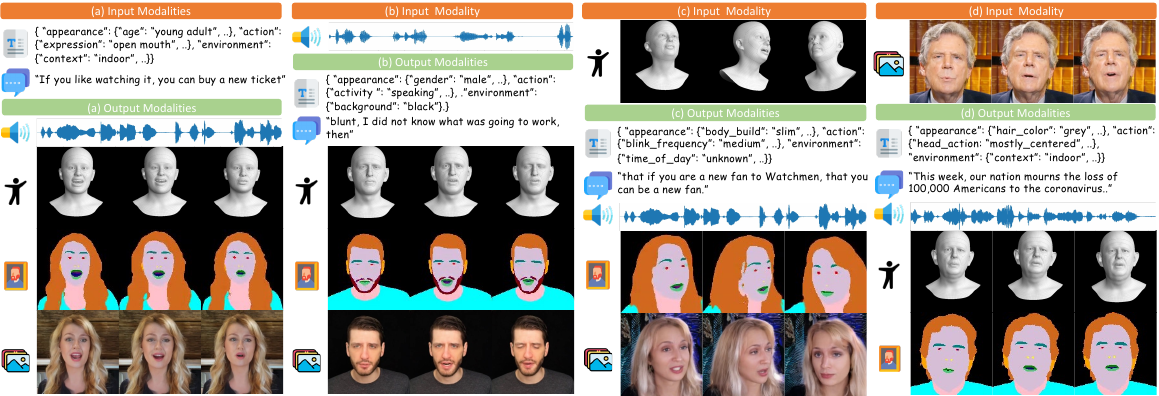
The qualitative results emphasize three capabilities: generation, understanding, and editing.
- Text-to-all generation: given a description, optionally with a script, the model can generate script, speech, 3DMM animation, semantic segmentation, and final talking video.
- Speech-to-all generation: given speech, the model infers appearance and script, then generates animation, segmentation, and video.
- Low-level-to-high-level understanding: from video, semantic, or 3DMM inputs, the model can infer descriptions, scripts, speech, and animation-related outputs.
The paper also highlights that the model can support fine-grained control when conditioned on 3DMM or segmentation, yielding responsive head motion and accurate expression. This is presented as evidence that the unified representation is not limited to generation from text alone; it can also perform cross-modal parsing and reconstruction.
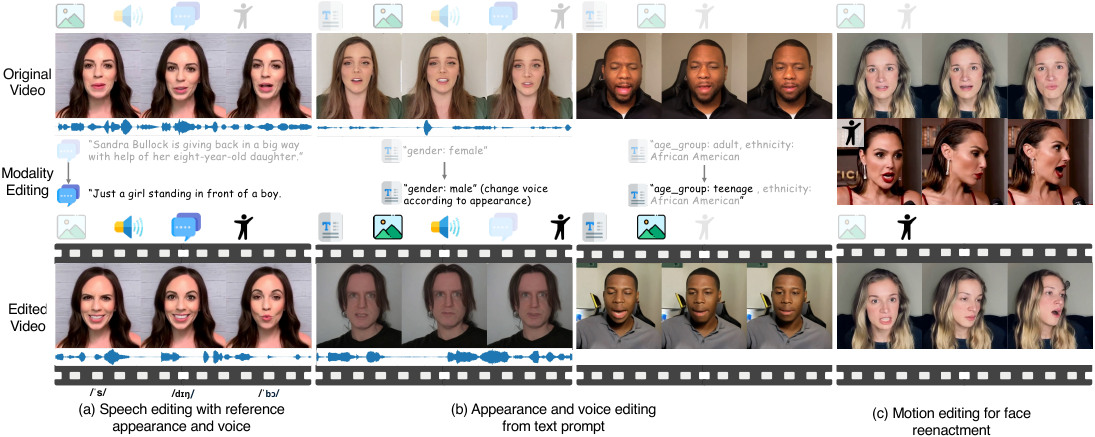
Editing is another major qualitative strength. The model can edit the script while preserving identity and voice, change appearance with a text prompt while leaving other factors unchanged, or drive head motion from a reference video for reenactment. The supplementary examples extend this to disentangled attribute editing and more expressive motion transfer.

In the supplementary comparison against NExT-GPT, the authors claim that Archon produces substantially higher-quality talking video and intelligible audio from text prompts. They also report a video-understanding comparison with Qwen-Omni on HDTF-based annotations, where Archon reaches an F1 score of $0.90$ versus $0.93$ for the much larger Qwen-Omni model.
Quantitative evaluation
The paper evaluates on two held-out benchmarks, CelebV-HQ and HDTF, each with 200 test videos sampled disjoint from training data. For these benchmarks, scripts are extracted from speech using Whisper. The primary benchmarked task is speech-driven video generation, and the second is image-conditioned text-to-speech.
The metrics for speech-driven video generation cover video realism and identity-speech consistency: FID and FVD for distributional distance, Q-Align IQA for quality, SyncNet-based Sync-C and Sync-D for lip synchronization, and audio metrics such as MCD-DTW and cosine identity similarity in the audio experiments.
Speech-driven video generation
The main comparison includes AniPortrait, EchoMimic, and Hallo3. The starred methods are trained on the benchmark dataset; Archon is used without benchmark-specific finetuning.
| Method | FID ↓ | FVD ↓ | Sync-C ↑ | Sync-D ↓ | IQA ↑ |
|---|---|---|---|---|---|
| AniPortrait* | 39.73 | 160.7 | 3.493 | 10.982 | 3.833 |
| EchoMimic* | 56.81 | 236.9 | 4.463 | 9.575 | 3.601 |
| Hallo3 | 15.67 | 105.5 | 5.429 | 9.158 | 3.722 |
| Archon | 6.818 | 93.81 | 5.210 | 8.998 | 3.794 |
| Method | FID ↓ | FVD ↓ | Sync-C ↑ | Sync-D ↓ | IQA ↑ |
|---|---|---|---|---|---|
| AniPortrait | 42.03 | 162.8 | 2.879 | 10.889 | 3.813 |
| EchoMimic* | 45.90 | 241.6 | 5.467 | 9.36 | 3.743 |
| Hallo3* | 12.78 | 96.51 | 6.376 | 9.131 | 3.83 |
| Archon | 5.779 | 81.64 | 6.198 | 8.822 | 3.94 |
On CelebV-HQ, Archon is best on FID, FVD, and Sync-D, while remaining competitive on Sync-C and IQA. On HDTF, it is best on all metrics except Sync-C, where it is close to the strongest value. The paper interprets this as evidence that the unified framework can match or exceed specialist systems despite being trained for many tasks rather than only one.

The qualitative comparison notes that some baselines can produce unnatural expressions or fail on identity and eye-motion details, whereas Archon maintains coherent appearance, realistic lip motion, and stable synchronization.
Image-conditioned text-to-speech
Archon is also evaluated against FaceTTS. Here the key trade-off is that Archon is not specialized for speech synthesis quality alone, yet it still improves voice identity consistency and semantic matching.
| Method | CelebV-HQ MCD-DTW ↓ | CelebV-HQ C-SIM ↑ | CelebV-HQ Id. Acc. ↑ | HDTF MCD-DTW ↓ | HDTF C-SIM ↑ | HDTF Id. Acc. ↑ |
|---|---|---|---|---|---|---|
| FaceTTS | 7.9383 | 0.9048 | 0.6032 | 7.8128 | 0.8844 | 0.5715 |
| Archon | 8.918 | 0.9117 | 0.6223 | 8.9822 | 0.9002 | 0.5911 |
Archon improves cosine similarity and identity accuracy on both datasets, while its MCD-DTW is slightly worse. The authors attribute that gap to a lightweight general-purpose detokenizer, whereas FaceTTS uses a heavier task-specific audio diffusion model.
Ablations and analysis
The paper includes two important ablation stories: the value of unified modeling, and the value of Thinking in Modality. It also contains a supplementary ablation of the semantic-driven diffusion conditioning.
For unified modeling, the authors compare Archon against an ensemble of modality-specific expert models with matched total parameter count and the same training data and settings. The unified model wins across all reported metrics, which the paper uses to argue that shared multimodal training gives stronger representations than isolated per-modality experts.
| Setting | FID ↓ | FVD ↓ | Sync-C ↑ | Sync-D ↓ | IQA ↑ |
|---|---|---|---|---|---|
| W/o unified model, CelebV-HQ | 7.279 | 170 | 3.209 | 10.143 | 3.695 |
| W/o thinking, CelebV-HQ | 13.76 | 128.1 | 3.088 | 10.209 | 3.593 |
| Full model, CelebV-HQ | 6.818 | 93.81 | 5.210 | 8.998 | 3.794 |
| W/o unified model, HDTF | 6.353 | 199.5 | 3.991 | 9.97 | 3.892 |
| W/o thinking, HDTF | 13.43 | 110.3 | 4.478 | 9.597 | 3.809 |
| Full model, HDTF | 5.779 | 81.64 | 6.198 | 8.822 | 3.94 |
The Thinking-in-Modality ablation is especially revealing. Directly generating video from speech is substantially worse than routing the inference through intermediate 3DMM, semantic, and description representations. On both benchmark datasets, the full chain improves video quality and lip synchronization, and the paper explicitly connects this to reduced ambiguity and a smoother semantic transition.
The supplementary diffusion ablation further shows that removing either textual conditioning or the joint image-plus-segmentation cross-attention hurts the final video synthesis. This supports the authors’ claim that semantics is not just a compact tokenization trick, but also a bridge for transferring appearance from the reference image into motion-conditioned video generation.
Discussion, limitations, and ethics
The paper is explicit that Archon is not yet a universal solution for all avatar settings. The supplementary discussion identifies several limitations and extensions:
- Single-speaker focus: Archon currently generates single-speaker talking videos.
- Multi-turn dialogue: a multi-turn scenario with one speaker appearing at a time could be handled by an external agent that alternates speaker identities and queries the model turn by turn.
- Multiple people in one frame: simultaneous multi-person generation would require finetuning on dedicated multi-person datasets.
- Semantic bottleneck: the semantic video representation may miss some fine-grained visual cues; the authors suggest replacing it with more detailed but still memory-efficient alternatives in future work.
- Higher expressiveness: more cinematic or high-quality datasets may improve expressiveness and diversity of avatars.
The authors also address ethics and dual-use risk. They acknowledge that high-fidelity avatar generation can be misused for harassment or misinformation, state that the work is intended for academic use, and emphasize responsible deployment measures such as watermarking and bias monitoring.
Takeaways
The paper’s main technical contribution is not simply “a bigger talking-head model,” but a coherent framework for holistic digital-human modeling: shared tokenization across heterogeneous modalities, a unified autoregressive trainer over $72$ tasks, a memory-efficient semantic-video route for long clips, and an inference-time modality-chaining strategy for ambiguous cross-modal synthesis.
Empirically, Archon is strongest where the paper expects the unified design to matter most: it can generate and understand multiple modalities in a coordinated way, it performs competitively against specialist baselines on benchmark tasks, and it improves downstream quality when intermediate modalities are inserted at inference time. The result is a practical step toward any-to-any digital human systems that are more compositional than a collection of separate experts.
Code & Implementation
This repository currently serves as a placeholder for the Archon project and does not yet contain implementation code or runnable scripts. According to the README, the original system was implemented in a non-public internal codebase, and this public repository plans to release an open-source reimplementation over time.
The planned public release aims to provide pretrained model checkpoints, configuration files, data processing scripts, training recipes, and evaluation tools that correspond to the unified multimodal model described in the paper. Until these assets and source files are made available, users should consider this repository as a roadmap and introduction rather than a runnable implementation.
For details and updates, the project page and official paper remain the primary references.