Semantic Motion Anchors
Semantic Motion Anchors: Bridging Motion and Meaning in Co-Speech Gestures
This paper introduces semantic motion anchors, a new intermediate representation that links 3D co-speech gestures with their communicative intent by verbalizing motion and grounding it in spoken text. This improves retrieval of semantically meaningful gestures and shows user preference for gestures conveying intent.
Links
Paper & demos
Impact
Abstract
Learning a shared representation between spoken text and gesture is central to co-speech gesture retrieval, synthesis, and understanding, but remains challenging for semantically meaningful gestures whose communicative intent is not captured by motion alone. Direct contrastive alignment between transcripts and continuous motion embeddings often overemphasizes low-level kinematics and misses the symbolic content of semantic gestures. We propose semantic motion anchors, natural-language abstractions of gesture motion capturing physical form and communicative intent. Our method discretizes 3D gestures into body-hand motion primitives, verbalizes them into structured descriptions, and grounds them in the transcript to provide auxiliary contrastive supervision. On BEAT2, our method improves text-to-gesture R@1 by 8.2% over a direct text-motion baseline and outperforms prior retrieval approaches on text to gesture and gesture to text retrieval directions. Beyond aggregate retrieval metrics, semantic motion anchor supervision helps retrieve gestures that are semantically meaningful for the spoken query, rather than defaulting to generic motion patterns. A downstream retrieval-augmented gesture generation study showed that users significantly preferred gestures retrieved by our approach over a retrieval-augmented generation baseline, demonstrating that semantically grounded retrieval translates to gestures that better convey communicative intent in downstream generation.
Overview
Semantic Motion Anchors: Bridging Motion and Meaning in Co-Speech Gestures addresses a core mismatch in co-speech gesture retrieval: raw motion embeddings are good at capturing kinematics, but semantic gestures often derive their meaning from discourse context rather than from movement alone. The paper argues that direct transcript-motion contrastive learning can overfit to low-level motion similarity and miss communicative intent, especially for sparse semantic gestures such as enumeration, self-reference, uncertainty, contrast, and quantification.
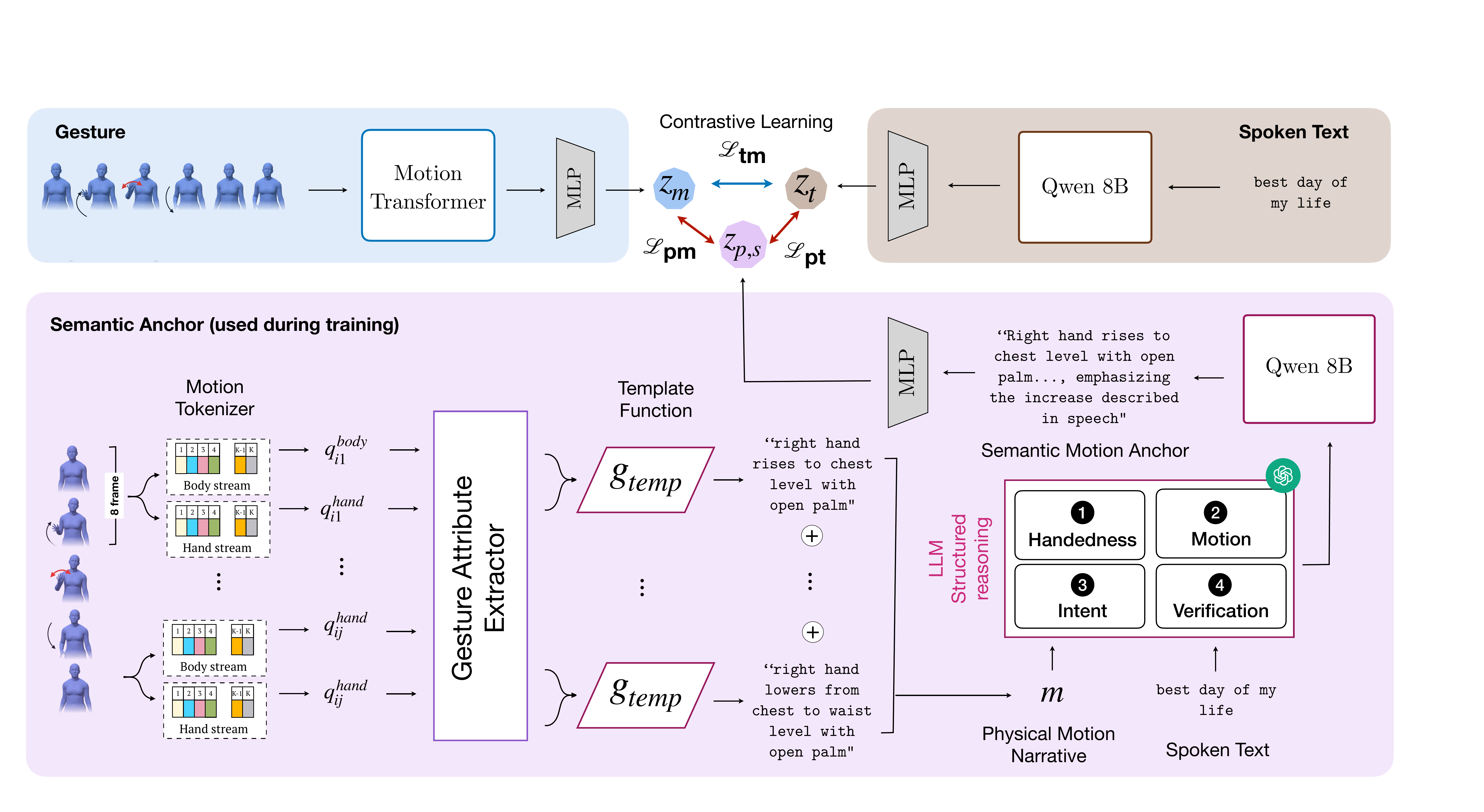
The proposed solution is to insert an intermediate natural-language abstraction called a semantic motion anchor. A gesture clip is discretized into motion tokens, those tokens are verbalized into structured physical-form descriptions, and an LLM grounds those descriptions in the transcript to produce an anchor that jointly encodes what the gesture looks like and what it means in context. The anchor is then used as auxiliary contrastive supervision during retrieval training.
On BEAT2, the method improves text-to-gesture R@1 from 39.1 to 42.3 over the direct text-motion baseline, an absolute gain of 3.2 points and a relative gain of 8.2%. The paper also reports improvements over prior baselines in both retrieval directions, better semantic label matching for retrieved gestures, stronger cross-dataset transfer using anchor proxies, and a downstream user study in which participants preferred retrieved gestures from the proposed system over a retrieval-augmented generation baseline.
Method
The retrieval task is defined over paired examples $(X_i, y_i)$, where $X_i \in \mathbb{R}^{T \times 114}$ is a 3D upper-body gesture sequence over 38 joints and $y_i$ is the transcript window. The model learns a shared retrieval space for transcripts and motion, but it adds a semantic anchor $a_i$ as a training-only supervision signal.
The main training objective combines four symmetric InfoNCE terms:
$$ \mathcal{L} = \mathcal{L}_{tm}(\mathbf{z}_t, \mathbf{z}_m) + \lambda_p\,\mathcal{L}_{phys}(\mathbf{z}_p, \mathbf{z}_m) + \lambda_s\,\mathcal{L}_{int}(\mathbf{z}_s, \mathbf{z}_t) + \lambda_b\,\mathcal{L}_{br}(\mathbf{z}_p, \mathbf{z}_s), $$
where $\mathbf{z}_t$ is the transcript embedding, $\mathbf{z}_m$ is the motion embedding, $\mathbf{z}_p$ is the physical-form anchor embedding, and $\mathbf{z}_s$ is the semantic-intent anchor embedding. The weights $\lambda_p$, $\lambda_s$, and $\lambda_b$ control the auxiliary physical, intent, and bridge losses. The paper’s sensitivity analysis shows that $\lambda_p$ must stay small, while $\lambda_s$ is more tolerant; the bridge loss is kept very small and peaks near $\lambda_b = 0.02$.
Motion tokenization
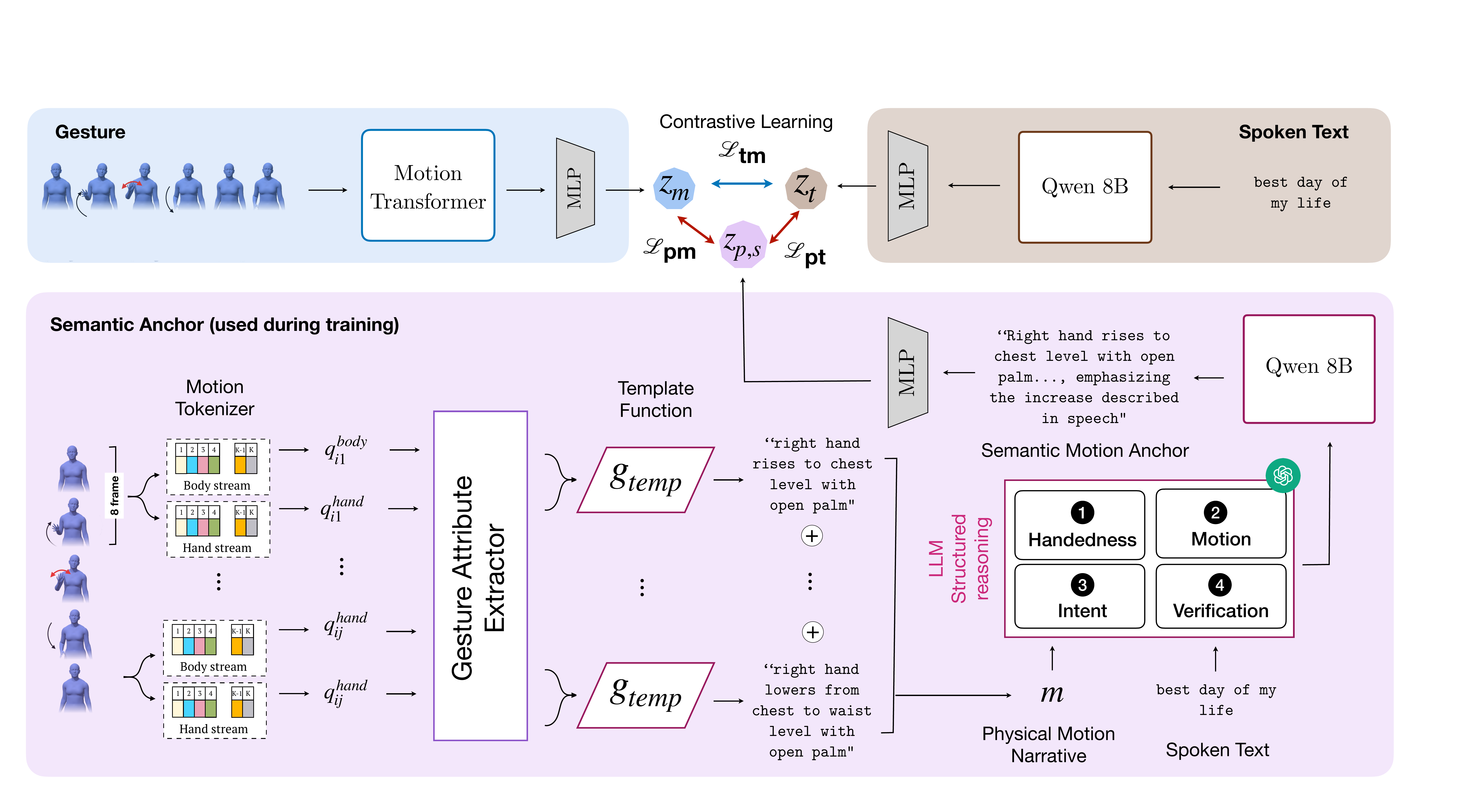
Motion is tokenized using a two-stream RVQ-VAE trained on a combined corpus of TED Expressive and BEAT2 motion capture data. The model splits the 38-joint upper body into a body stream and a hand stream, and encodes them separately with 1D convolutional encoders. Each stream downsamples 8 frames into one latent vector. The body stream uses three residual quantization stages with codebooks of size $(128, 128, 128)$, while the hand stream uses $(128, 64, 32)$. Quantized body and hand latents are concatenated and decoded by a shared transposed-convolutional decoder.
Preprocessing centers skeletons at the neck, scales them to a unit sphere, and aligns them to a torso-oriented coordinate frame. Finger joints are additionally normalized relative to the wrist. Training uses an $L_2$-style reconstruction objective with stream-decoupled gradients so that the much larger hand subspace does not overwhelm the body stream. The paper’s appendix reports that the selected RVQ-VAE configuration achieves the best reconstruction among tested variants, with combined MPJPE 0.0442 and jitter 0.0060.
Rule-based verbalization of motion primitives
Each 8-frame token is reconstructed and converted into a deterministic natural-language fragment using geometric rules. The body stream extracts wrist height, horizontal placement, depth, elbow bend, arm reach, and motion direction. The hand stream extracts palm orientation and coarse hand shape. These attributes are mapped to template text, producing a compact physical-motion narrative for each primitive.
The paper uses a stream-wise lookup dictionary rather than enumerating the full Cartesian product of body and hand token combinations, because the full joint dictionary would be extremely large. Temporal aggregation uses the middle-frame state when attributes are stable, and explicitly describes transitions when the first and last labels differ. When both hands share the same orientation, shape, and transition pattern, they are collapsed into one bimanual description.
The verbalizer is intentionally coarse: it prioritizes robust body-level and hand-level cues over fine finger articulation. This design choice is consistent with the paper’s stated limitation that subtle gesture phases and detailed finger configurations are not fully modeled.
Semantic motion anchors
A semantic anchor is produced by combining the motion narrative with the transcript using a structured reasoning prompt. The anchor is decomposed into two parts: $a^{phys}$ for physical form and $a^{int}$ for communicative intent. Both are embedded by a frozen Qwen3-Embedding-8B encoder, while the transcript is embedded by the same frozen encoder but routed through a separate transcript projector. The motion side is encoded by a trainable transformer $f_{mot}$.
The system uses a two-stage training schedule. First, it warms up only on transcript-motion contrastive learning, $\mathcal{L}_{tm}$. Then it fine-tunes with the full multi-term objective and reinitializes the anchor projector so that anchor supervision acts as structured regularization rather than replacing the retrieval task itself.
In implementation, the motion encoder is a 2-layer, 4-head Transformer with hidden size 256 and maximum sequence length 1024. All projection heads map into a 512-dimensional retrieval space using LayerNorm, Linear, GELU, Dropout(0.1), and Linear layers, followed by $L_2$ normalization. The temperature parameter starts at $\tau = 0.07$ and is learned during training.
Data, annotation, and evaluation protocol
The retrieval experiments are trained on BEAT2 and evaluated on the BEAT2 test split. The paper uses a 90/5/5 split with $N_{train} = 15{,}395$, $N_{val} = 855$, and $N_{test} = 856$. TED is used only for out-of-domain evaluation.
For anchor-quality evaluation, the paper introduces Semantix, a human-annotated dataset of 878 semantic gesture clips from TED Expressive and BEAT2. The annotations include both physical-form descriptions and communicative-intent descriptions. A primary annotator labeled an initial set of 231 TED samples, an expert reviewer revised them, and the finalized guidelines were used to annotate the remainder. An additional 100 BEAT2 semantic gesture samples were annotated with the same schema.
The paper validates automatic description scoring with an LLM-as-a-judge setup using GPT-5.4. The judge compares a generated description with a gold reference and outputs two scores: PoseScore for physical similarity and IntentScore for communicative similarity, each on a 1--5 scale. Human validation on 100 sampled anchors shows strong rank correlations: on TED, Spearman $\rho = 0.887$ for pose and $\rho = 0.810$ for intent; on BEAT2, $\rho = 0.942$ for pose and $\rho = 0.947$ for intent. In both datasets, the LLM is slightly more conservative than the human rater.
Prompt sensitivity for anchor generation
The appendix compares four prompt styles for generating anchors from the same token-based motion narrative: naive zero-shot prompting, in-context prompting, chain-of-thought prompting, and the structured reasoning prompt used in the main method. The key finding is that intent is relatively stable across prompts, while physical-form quality depends more strongly on prompting strategy. The structured reasoning prompt achieves the best overall pose score on TED and the best weighted average pose score across TED and BEAT2.
| Prompt | TED Pose | TED Intent | BEAT2 Pose | BEAT2 Intent | Weighted Pose | Weighted Intent |
|---|---|---|---|---|---|---|
| Naive prompt | 3.0 | 4.1 | 3.3 | 4.4 | 3.1 | 4.2 |
| In-context learning prompt | 3.1 | 4.1 | 3.3 | 4.4 | 3.2 | 4.1 |
| Chain-of-thought prompt | 3.0 | 4.2 | 3.4 | 4.4 | 3.1 | 4.2 |
| Structured reasoning prompt | 3.4 | 4.1 | 3.2 | 4.3 | 3.3 | 4.2 |
Training and implementation details
The retrieval model is trained with AdamW at learning rate $5 \times 10^{-5}$, weight decay $10^{-4}$, gradient clipping at 1.0, batch size 512, and a constant schedule. Training runs for up to 40 epochs with early stopping patience 10. The model is trained on a single H100 GPU. The motion encoder and projection heads are trainable; the text encoder remains frozen.
The paper compares against several baselines under the same data splits and evaluation protocol: GestureDiffuCLIP, TMR, JEGAL, and a direct text-contrastive baseline. GestureDiffuCLIP uses a frozen CLIP ViT-B/32 text encoder and plain symmetric InfoNCE. TMR adds false-negative filtering using transcript similarity. JEGAL replaces hard negatives with soft positive targets for similar transcripts. The authors emphasize that their comparison isolates the effect of the training objective rather than confounding architectural differences.
Main retrieval results on BEAT2
The main BEAT2 test gallery contains 856 candidates. The proposed model outperforms all baselines in both gesture-to-text and text-to-gesture retrieval. Relative to the strongest prior baseline, JEGAL, gesture-to-text retrieval improves by 14.2% in R@1 and 9.4% in MRR, while text-to-gesture retrieval improves by 7.6% in R@1 and 6.1% in MRR. Gains are consistent across Recall@5 and Recall@10 as well, though the biggest benefit is concentrated at the top rank, which is the most operationally important retrieval regime.
| Method | Gesture → Text | Text → Gesture | ||||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | MRR | R@1 | R@5 | R@10 | MRR | |
| GestureDiffuCLIP | 32.3 | 57.4 | 66.6 | 44.0 | 33.8 | 57.5 | 67.2 | 45.1 |
| TMR | 37.4 | 57.7 | 65.7 | 47.0 | 39.1 | 58.7 | 66.4 | 48.6 |
| JEGAL | 36.6 | 58.4 | 66.6 | 47.0 | 39.3 | 59.3 | 66.8 | 48.9 |
| Text Contrastive | 37.2 | 57.5 | 65.4 | 47.0 | 39.1 | 58.7 | 66.3 | 48.5 |
| Text Contrastive with Semantic Anchors | 41.8 | 62.0 | 68.9 | 51.4 | 42.3 | 62.5 | 69.5 | 51.9 |
Ablations and sensitivity analyses
The paper isolates two distinct contributions of anchor supervision: the existence of an auxiliary contrastive signal, and the semantic content of the anchor itself. A random-anchor control replaces anchor text embeddings with deterministic random unit vectors seeded per sample. This preserves the extra contrastive structure but removes semantics, allowing the authors to test whether gains come from regularization alone.
| Method | Gesture → Text | Text → Gesture | ||||||
|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | MRR | R@1 | R@5 | R@10 | MRR | |
| No Anchor | 37.2 | 57.5 | 65.4 | 47.0 | 39.1 | 58.7 | 66.3 | 48.5 |
| Random Anchor | 40.7 | 60.3 | 67.5 | 50.0 | 42.1 | 61.0 | 68.1 | 51.2 |
| Semantic Anchors | 41.8 | 62.0 | 68.9 | 51.4 | 42.3 | 62.5 | 69.5 | 51.9 |
The appendix also reports a more compact table showing that semantic anchors outperform random anchors on R@5 and MRR in both directions when the comparison is restricted to the top ranks: for gesture-to-text, R@5 improves from 60.35 to 62.05 and MRR from 50.02 to 51.44; for text-to-gesture, R@5 improves from 60.96 to 62.53 and MRR from 51.22 to 51.85.
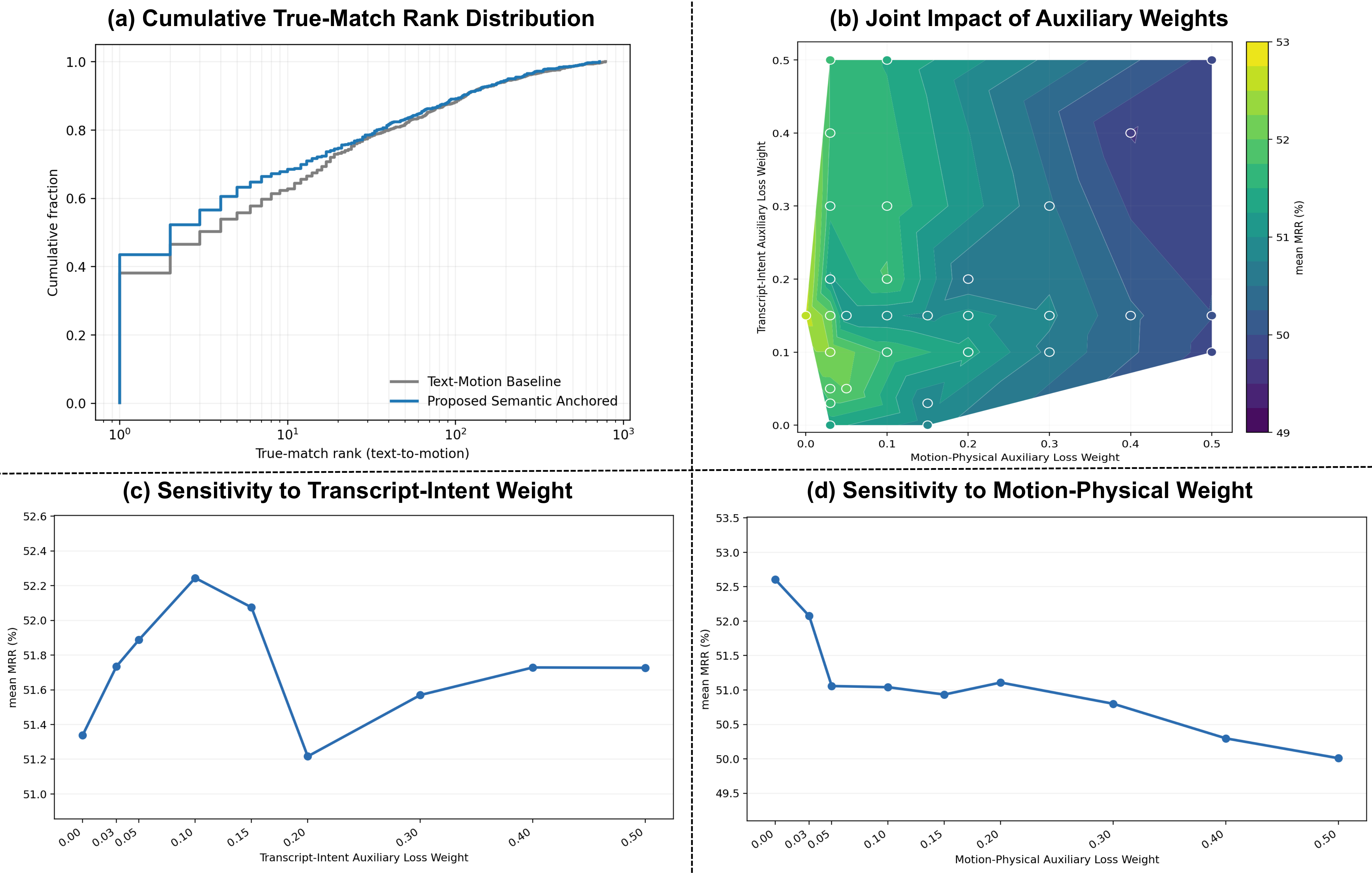
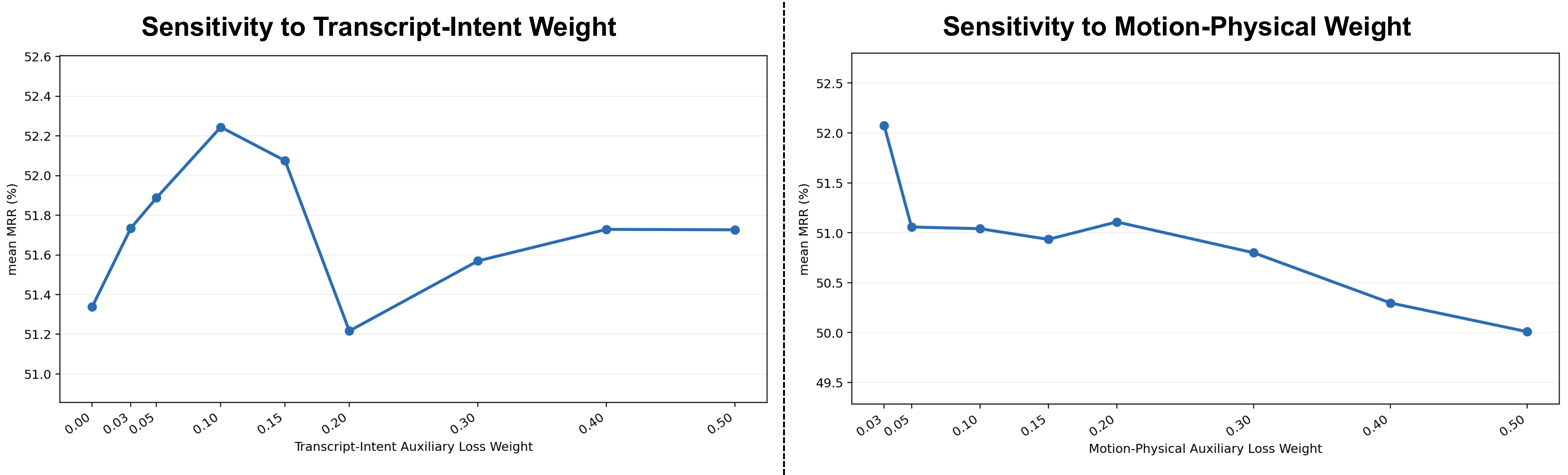
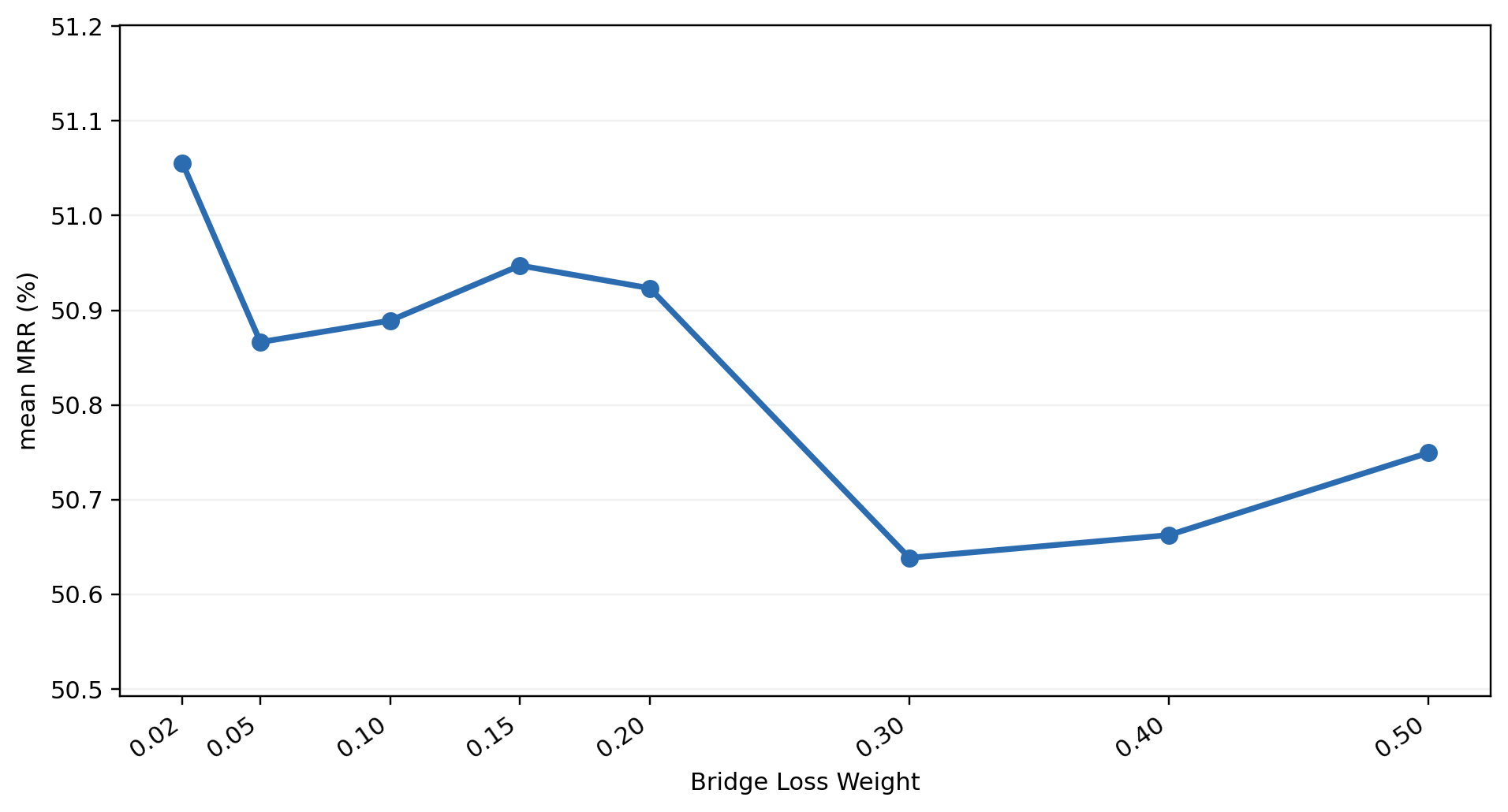
The sensitivity plots show a clear asymmetry: the transcript-intent branch tolerates a moderate range of $\lambda_s$ values, while even small increases in $\lambda_p$ beyond the near-optimal region hurt retrieval. The bridge term should remain very small; performance peaks near $\lambda_b = 0.02$ and drops when the shared anchor space is overconstrained.
| Body CBs | Hand CBs | Dim | MPJPE Body | MPJPE Hand | MPJPE All | Jitter |
|---|---|---|---|---|---|---|
| (128) | (64) | 64 | 0.0403 | 0.0878 | 0.0777 | 0.0065 |
| (128) | (128) | 128 | 0.0386 | 0.0851 | 0.0762 | 0.0064 |
| (128) | (512) | 128 | 0.0357 | 0.0723 | 0.0646 | 0.0064 |
| (128, 128) | (64, 4, 2) | 128 | 0.0314 | 0.0658 | 0.0585 | 0.0065 |
| (128, 128) | (128, 64) | 128 | 0.0300 | 0.0602 | 0.0538 | 0.0063 |
| (128, 128, 128) | (128, 64, 32) | 128 | 0.0253 | 0.0493 | 0.0442 | 0.0060 |
| Downsampling factor | Test MPJPE (all) |
|---|---|
| 4 frames | 0.0397 |
| 8 frames | 0.0442 |
| 16 frames | 0.0529 |
These RVQ-VAE ablations justify the final choice of 8-frame tokens: shorter chunks preserve more detail but yield longer token sequences, while longer chunks reduce sequence length at the cost of more reconstruction error and harder verbalization. The authors therefore choose the 8-frame compromise for the main experiments.
Cross-dataset generalization and semantic transfer
The paper evaluates transfer from BEAT2 to TED under two gallery settings. The first is TED-to-TED, where the gallery also comes from TED. To avoid leakage, the gallery is represented by physical-form anchors rather than transcript-derived semantic anchors. The second is TED-to-BEAT2, where TED transcripts query a BEAT2 gallery. Since exact paired cross-dataset retrieval targets do not exist, the paper uses proxy metrics based on semantic labels and embedding similarity.
The reported metrics include Acc@1, Hit@5, Hit@10, MRR, label nDCG@10, BestCos@5, MeanCos@10, and semantic nDCG@10. The main takeaway is that raw motion embeddings transfer poorly under domain shift, while anchor-based proxies provide a more transferable interface.
| Method | Semantic Label (%) | Pairwise Win Rate (%) | Semantic Context (%) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc@1 | Hit@5 | Hit@10 | MRR | nDCG@10 | nDCG@10 | MeanCos@10 | BestCos@5 | MeanCos@10 | nDCG@10 | |
| Setup: TED transcripts as query and BEAT2 motion embeddings as gallery | ||||||||||
| Text Contrastive | 12.3 | 39.4 | 49.0 | 24.3 | 12.0 | 56.4 | 54.0 | 55.7 | 48.1 | 70.1 |
| Random Anchor | 12.7 | 37.7 | 50.0 | 24.3 | 12.7 | 56.9 | 55.9 | 55.8 | 48.2 | 70.2 |
| Proposed | 11.5 | 38.2 | 50.7 | 23.4 | 12.5 | -- | -- | 56.0 | 48.3 | 70.5 |
| Setup: TED transcripts as query and BEAT2 semantic-anchor proxies as gallery | ||||||||||
| Text Contrastive | 15.8 | 37.7 | 49.3 | 26.7 | 14.2 | 55.0 | 57.6 | 56.7 | 48.9 | 71.2 |
| Random Anchor | 9.9 | 33.8 | 44.8 | 21.1 | 10.2 | 71.2 | 71.6 | 53.7 | 46.6 | 67.8 |
| Proposed | 17.2 | 41.2 | 53.5 | 28.4 | 14.6 | -- | -- | 57.2 | 49.5 | 71.8 |
For TED-to-TED, the appendix also reports that motion embeddings are near chance under the domain shift, while replacing raw motion with physical-form descriptions improves retrieval. In that proxy setting, the proposed semantic-anchor model reaches R@5/MRR of 4.6/3.48 for gesture-to-text and 4.5/3.42 for text-to-gesture, clearly above the random-anchor control and the direct text-contrastive baseline.
Semantic label match rate on BEAT2
Because co-speech gestures are many-to-many with speech, the paper also measures whether the top-1 retrieved gesture shares the same semantic label as the ground-truth gesture. This analysis is more permissive than exact Recall@1 and better reflects semantic alignment.
| Category | n | Ours | Text Contrastive | Random Anchor |
|---|---|---|---|---|
| Emphasis | 250 | 57.2 | 52.8 | 57.2 |
| Discourse | 227 | 62.1 | 57.7 | 61.7 |
| Other-reference | 111 | 59.5 | 56.8 | 58.6 |
| Self-reference | 92 | 52.2 | 52.2 | 44.6 |
| Emotion | 16 | 56.2 | 43.8 | 50.0 |
| Uncertainty | 15 | 66.7 | 53.3 | 60.0 |
| Quantification | 11 | 45.5 | 27.3 | 27.3 |
| Temporal reference | 12 | 50.0 | 33.3 | 50.0 |
| Overall | 856 | 56.9 | 52.6 | 55.1 |
The paper highlights especially strong gains for categories with distinctive semantic form, including quantification, temporal reference, uncertainty, and emotion. At the same time, broad classes such as emphasis and discourse remain challenging because they exhibit large within-class variation. The examples in the appendix show that the proposed method often retrieves gestures whose communicative function matches the query better than text-only or random-anchor controls, even when the exact instance differs.
Downstream retrieval-augmented gesture generation
To test whether retrieval quality matters for generation, the authors run a perceptual user study with 32 participants. Each participant sees 10 forced-choice comparisons and chooses which of two retrieved gestures better suits a highlighted query word. The comparison is between gestures retrieved by the proposed anchor-based system and gestures retrieved by RAG-Gesture’s retrieval step.
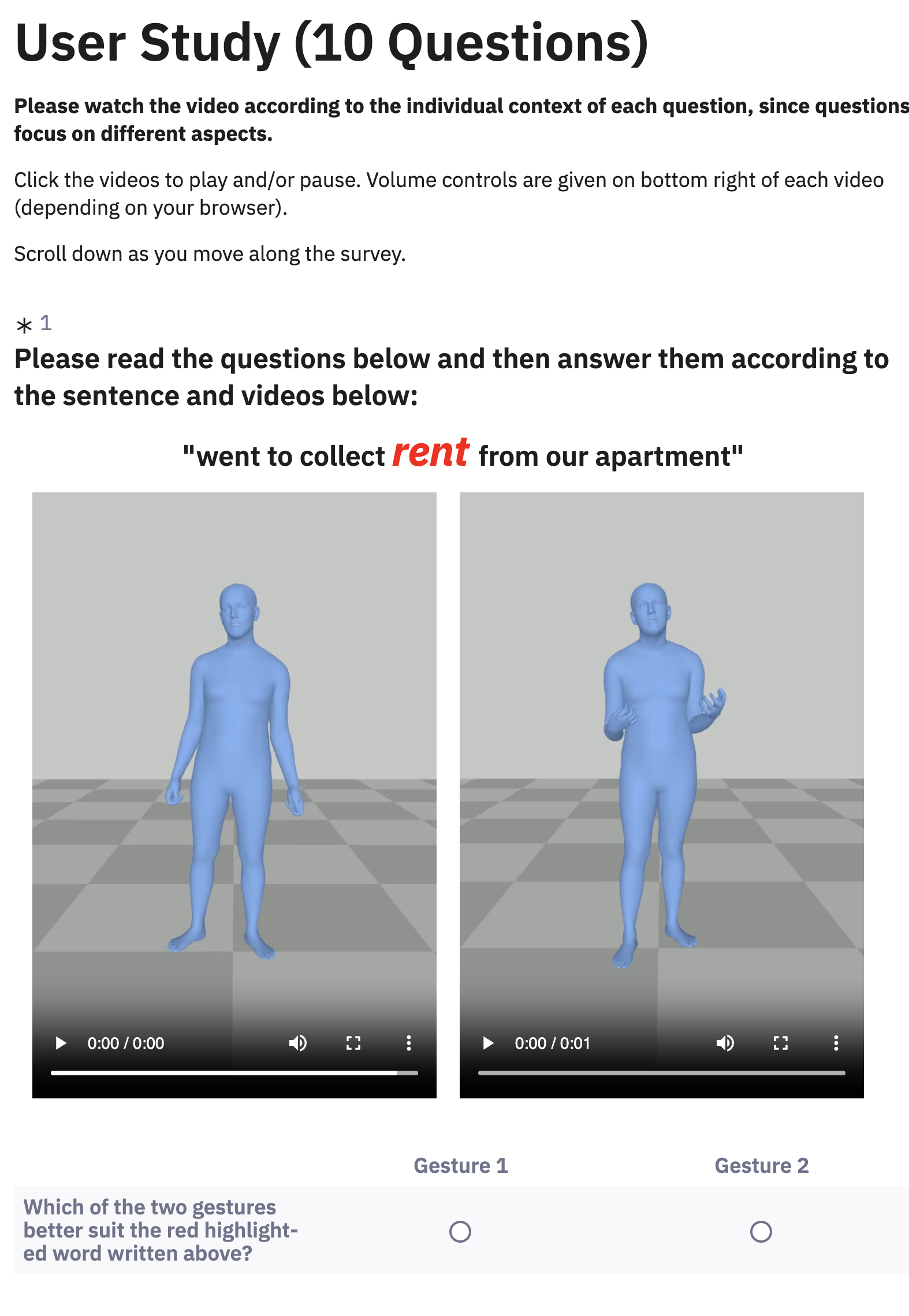
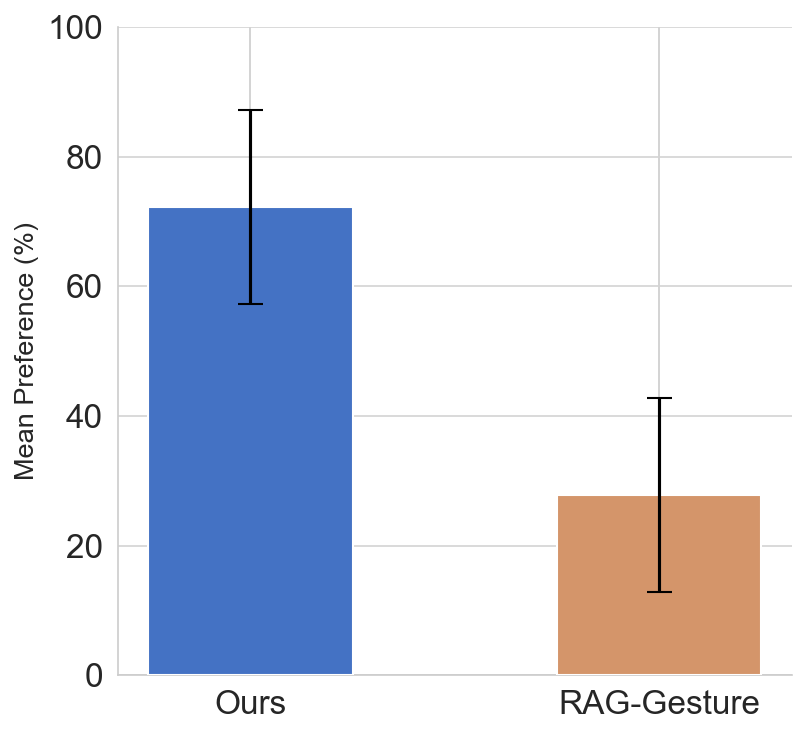
Participants preferred gestures retrieved by the proposed method 72.2% of the time, versus 27.8% for RAG-Gesture, and the difference is statistically significant under a Wilcoxon signed-rank test with $W = 11.5$ and $p < 0.0001$. The authors interpret this as evidence that semantically grounded retrieval translates into gestures that better match communicative intent in downstream generation settings.
Limitations
The paper explicitly notes several limitations. First, semantic motion anchors capture only a subset of gesture-relevant properties; they do not model subtle finger articulation or fine-grained gesture phases. Second, anchor generation requires an offline LLM step, so there is extra computational overhead and dependence on a closed-source model, even though the cost is one-time. Third, the approach is trained primarily on BEAT2 and TED, so it may not generalize equally well across cultures, languages, or demographic groups where gesture conventions differ.
The authors also frame the method as a relatively simple contrastive setup, leaving open more expressive ways of incorporating anchors into retrieval or generation systems.
Bottom line
The central contribution of the paper is a practical bridge between motion and meaning: discrete motion primitives are turned into natural-language descriptions, and those descriptions are used to supervise a language-gesture retrieval model. In-domain, this improves top-rank retrieval on BEAT2; out-of-domain, it yields better transferable proxy representations; and downstream, it produces retrieved gestures that people judge as more suitable for speech-conditioned generation.