Chatterbox-Flash
Chatterbox-Flash: Prior-Calibrated Block Diffusion for Streaming Zero-Shot TTS
Chatterbox-Flash is a zero-shot streaming TTS model that converts an autoregressive decoder into a block-diffusion decoder. It uses prior-calibrated scoring and early decoding for efficient, low-latency synthesis without changing the model architecture, enabling high-quality speech with streaming support.
Links
Paper & demos
Code & resources
Impact
Abstract
We present Chatterbox-Flash, a zero-shot text-to-speech model obtained by fine-tuning a pretrained autoregressive TTS decoder into a block-diffusion decoder, enabling parallel token generation within each block while retaining block-by-block streaming. We find that naively transferring mainstream block-diffusion decoding to discrete speech tokens degrades quality, as a long-tail token distribution biases parallel position selection toward a few high-frequency tokens. To mitigate this without architectural modification, we introduce two inference-time techniques: prior-calibrated scoring, which subtracts the block-level marginal token distribution, and an early-decoding schedule, which adaptively terminates iteration based on calibrated confidence. On standard zero-shot TTS benchmarks, Chatterbox-Flash attains high-fidelity synthesis comparable to strong autoregressive and non-autoregressive baselines, while supporting streaming inference with time-to-first-packet on par with streaming AR systems and substantially lower real-time factor. Code and audio samples are available at https://github.com/resemble-ai/chatterbox-flash.
Introduction
Chatterbox-Flash is a zero-shot text-to-speech system that converts a pretrained autoregressive decoder into a block-diffusion decoder while keeping the original model architecture intact. The core goal is to combine three properties that are usually in tension: high speech quality, native streaming, and substantially lower decoding latency than sequential autoregressive generation.
The paper starts from the observation that modern zero-shot TTS is often dominated by autoregressive models because they synthesize high-quality speech and can stream token-by-token, but they are inherently sequential. Diffusion-style decoders can generate multiple tokens in parallel, yet most mainstream diffusion decoding methods do not transfer cleanly to discrete speech codecs. In codec space, the token distribution is highly skewed toward a few dominant tokens, especially silence- or low-energy-like codes, and that skew can corrupt the position-ranking logic used by block diffusion during parallel unmasking.
Chatterbox-Flash addresses this with two inference-time additions rather than architectural changes: prior-calibrated scoring, which subtracts a token prior from the per-position model confidence, and an early-decoding schedule, which stops denoising early when calibrated confidence is already high enough. Together, these preserve block-wise streaming while sharply reducing the compute required per generated block.
The model is evaluated on standard English zero-shot TTS benchmarks and is reported to match or exceed strong autoregressive and non-autoregressive baselines on quality while being the only comparison system with native streaming support in the authors’ setup. The main empirical message is that block diffusion can work well for speech, but only if the decoding rule is calibrated to the non-uniform prior structure of discrete audio tokens.
Method
The system is built on top of Chatterbox-TTS, an open-source two-stage zero-shot TTS pipeline. Stage 1 is the decoder that maps text and prompt speech into discrete speech tokens at 25 Hz. Stage 2 is a flow-matching vocoder that converts those tokens to waveform chunks in a streaming-friendly way. Chatterbox-Flash keeps the codec, speaker encoder, and vocoder pipeline, and replaces the original autoregressive decoder with a block-diffusion decoder trained by masked denoising.
Architecture and conditioning
The decoder conditions on a composite input $$ \mathbf{c} = [\mathbf{e}_s, \mathbf{x}_{\text{text}}, \mathbf{x}_{\text{speech}}], $$ where $\mathbf{e}_s$ is a global speaker embedding from a GE2E-trained voice encoder, $\mathbf{x}_{\text{text}}$ is the input text token sequence, and $\mathbf{x}_{\text{speech}}$ is the prompt speech token sequence extracted from the reference audio. The speech output is a sequence of codec tokens $\mathbf{y} = (y_1, \ldots, y_T)$.
In the original autoregressive factorization, the speech sequence is modeled as
$$
p(\mathbf{y} \mid \mathbf{c}) = \prod_{t=1}^{T} p(y_t \mid y_{
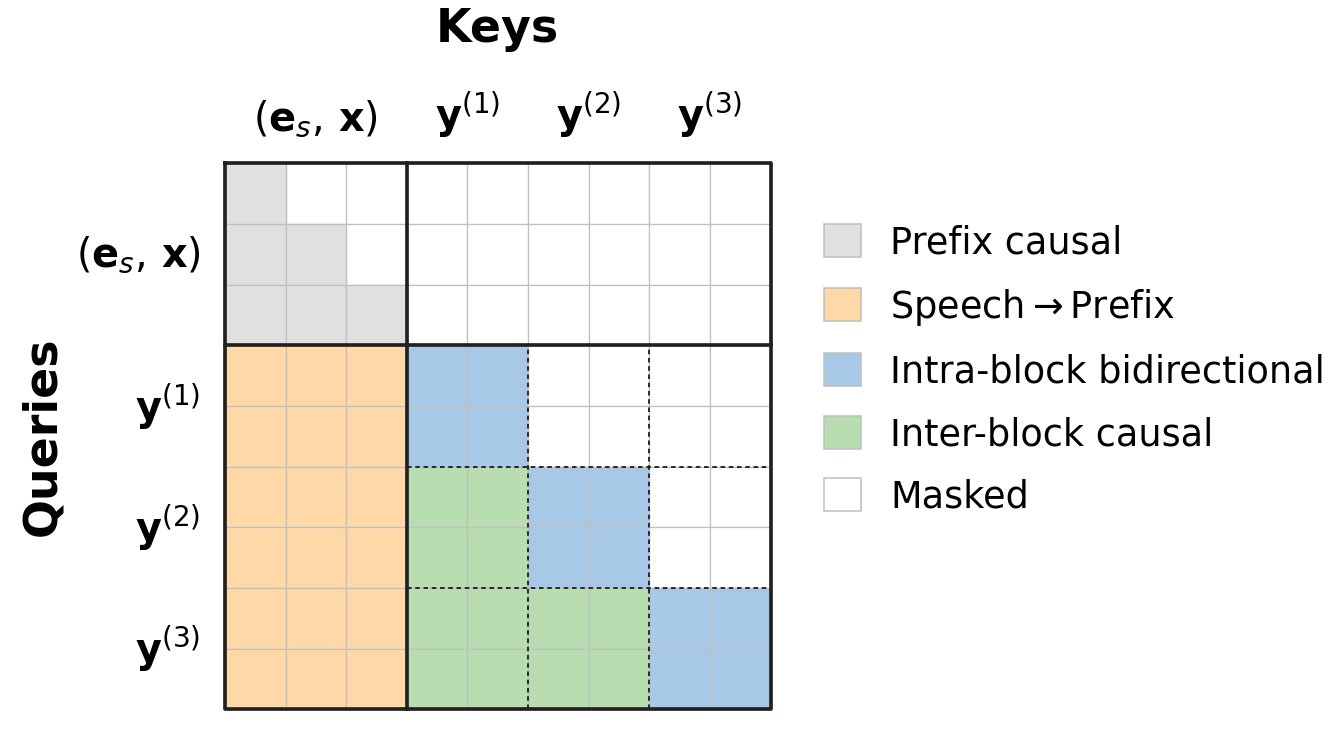
Training uses a hybrid attention pattern: the conditioning prefix is causal, speech tokens in the current block attend bidirectionally within the block, and attention is causal across blocks. This means the current block can use the clean prefix and all previous committed blocks, but it cannot see future blocks. The paper emphasizes that the conditioning prefix remains causal to preserve the pretrained backbone’s embedding space and maintain monotonic text-to-speech alignment.
Training uses complementary masking over the speech tokens. At each step, the model samples a noise time $t \sim \mathcal{U}(\epsilon, 1-\epsilon)$, derives a per-token mask probability from a fixed noise schedule, and replaces a subset of speech positions with a mask token. A complementary view is added in the same batch so that every position is supervised under both masked and unmasked contexts.
The denoising loss uses a token-shift parameterization: a masked position is predicted from the hidden state at the previous position rather than from the mask token itself. For a masked token position $i$, the per-token loss is
$$
\ell_i = -\log p_\theta\!\left(y_i \mid \mathbf{c}, \mathbf{x}^{(
This formulation keeps the backbone’s autoregressive interface intact, but exposes each block to bidirectional context during training. The practical effect is that the model can still run block by block at inference time, yet learn a parallel denoising objective inside the block.
At inference, blocks are decoded left to right. Once a block is committed, it becomes clean context for the next block, and key-value caches are appended sequentially. The conditioning prefix is encoded once at the start and reused across all later blocks because it never attends to speech tokens. Within each block, the forward pass predicts a token distribution at every masked position, and the decoder must decide both which positions to unmask and how many positions to commit per step.
The paper argues that naive block-diffusion decoding fails on discrete speech because the model’s confidence is often dominated by the marginal frequency of common tokens instead of by local contextual fit. This is especially harmful near block boundaries, where incorrect early commits can cascade into boundary-induced context truncation and corrupt all later blocks.
To correct this bias, Chatterbox-Flash uses prior-calibrated scoring, which is a pointwise mutual information-style score:
$$
s_i^{(k)} = \log p_i^{(k)}(\hat{x}_i^{(k)}) - \log \bar{p}(\hat{x}_i^{(k)}).
$$
The first term is the conditional log-confidence at position $i$ in decoding step $k$. The second term subtracts the marginal likelihood of the same token under a reference prior $\bar{p}$, so the score rewards tokens that are specifically supported by local context rather than simply common in the codec vocabulary.
The reference prior is not estimated from the current block’s context, because that would be self-referential. Instead, the paper defines an unconditional block prior computed once by running a single forward pass on an all-masked sequence with conditioning zeroed out:
$$
\bar{p}(v) = \frac{1}{D} \sum_{j=1}^{D} p_\theta\!\left(v \mid [\mathrm{MASK}]^D,\, \mathbf{c} = \mathbf{0}\right)_j.
$$
This cached prior depends only on the model and block size, and is reused throughout inference.
For how many positions to commit at each step, the paper builds on a time-shifted schedule. The cumulative fraction of unmasked tokens by step $k$ is
$$
r_k = \frac{\tau \cdot (k/K)}{1 + (\tau - 1) \cdot (k/K)},
$$
with total denoising budget $K$ and shift parameter $\tau$. The new fraction to unmask at step $k$ is the difference between successive $r_k$ values.
On top of that, the authors introduce early decoding. They compute a per-step threshold from the calibrated scores,
$$
\theta_k = \operatorname{Quantile}\!\left(\{s_i^{(k)}\}_{i \in \mathcal{M}}, q_k\right),
$$
where
$$
q_k = \max\!\left(0,\, 1 - \alpha \cdot \frac{k+1}{K}\right).
$$
At early steps, only the most confident positions are released; later steps relax the threshold and commit more positions. The system combines the time-shift schedule and the confidence threshold, and stops once all positions are unmasked or the step budget $K$ is reached. This is the mechanism that turns calibrated confidence into a compute-saving policy.
The decoder also supports classifier-free guidance. The conditional and unconditional logits are combined as
$$
\ell_i = (1+w)\,\ell_i^c - w\,\ell_i^u,
$$
and the token to commit is chosen from the guided distribution. Importantly, the prior-calibrated ranking score is computed on the conditional branch alone, so the position ordering is not distorted by the guidance scale $w$. The default CFG scale is $w = 1.0$.
The implementation uses FlashInfer-based attention kernels, paged key-value cache management, a frozen prefix cache, a growing block cache, cache snapshots for CFG, and CUDA graph replay for fixed-size block execution. These are serving optimizations rather than algorithmic changes, but they are important for the reported latency and throughput numbers.
The model is trained on approximately $70$k hours of English speech, corresponding to $43.8$M utterances from $528$k speakers. The training mix spans large-scale read speech, expressive and anechoic speech, accented English, and a sizable amount of privately collected audiobook, conversational, IVR, and short-form data. The paper explicitly notes that the private portion broadens coverage for conversational, expressive, and short-form utterances beyond standard read-speech corpora.
Evaluation is performed on two public English zero-shot TTS benchmarks: LibriSpeech-PC test-clean and Seed-TTS test-en. The reported objective metrics are SIM-o (cosine similarity between speaker embeddings of generated and reference speech), WER against the input text, and UTMOS for naturalness. For LibriSpeech-PC, WER is computed using HuBERT-based ASR; for Seed-TTS, the paper uses Whisper-large-v3. Baseline numbers are taken from OmniVoice’s report.
The canonical inference configuration is block size $D = 16$, denoising budget $K = 8$, time-shift parameter $\tau = 0.5$, CFG scale $w = 1.0$, sampling temperature $T = 0.2$, and position temperature $\beta = 5$. The paper reports two primary operating points: a quality-oriented one with $\alpha = 0$ and an efficiency-oriented one with $\alpha = 0.5$.
Training starts from a pretrained Chatterbox-TTS checkpoint and continues with AdamW, cosine learning-rate decay, a peak learning rate of $10^{-5}$, $10\%$ warmup, effective batch size $440$, and bf16 precision. The model is trained with block size $D = 32$, then evaluated at smaller or equal inference block sizes. All experiments are run on NVIDIA H100 GPUs.
The headline result is that the block-diffusion conversion preserves or improves quality relative to the AR backbone while adding streaming-friendly parallelism. Compared with the original Chatterbox AR model, Chatterbox-Flash improves both speaker similarity and WER on the two benchmarks, while keeping UTMOS essentially unchanged.
Relative to the AR backbone, Chatterbox-Flash improves on LibriSpeech-PC from SIM-o $0.707$ to $0.717$ and WER from $1.99$ to $1.67$, while matching UTMOS at $4.29$. On Seed-TTS test-en, SIM-o improves from $0.685$ to $0.704$ and WER from $2.20$ to $1.96$, with UTMOS staying effectively unchanged at about $4.09$ to $4.10$.
The most important decoding finding is that Fast-dLLM v2-style threshold decoding transfers poorly to discrete speech tokens: WER exceeds $14$ on both benchmarks. By contrast, the time-shift schedule and the prior-calibrated scoring rule produce nearly identical objective quality on the saturated read-speech benchmarks, which the authors interpret as evidence that PMI’s main value is not direct quality gain at high compute, but a better-calibrated confidence signal for early stopping.
With early decoding enabled, the average number of denoising steps drops from $8$ to $6.47$ on LibriSpeech-PC and to $6.10$ on Seed-TTS, while WER remains essentially unchanged on LibriSpeech-PC and increases only slightly on Seed-TTS. This is the paper’s main quality–compute trade-off result.
The paper also reports streaming-oriented latency metrics against Qwen3-TTS, an autoregressive streaming baseline. The two metrics are time to first packet (TTFP) and real-time factor (RTF). Chatterbox-Flash is competitive on TTFP and substantially better on RTF, especially as block size grows and early decoding becomes more aggressive.
The best reported streaming configuration, $D = 32$ with $\alpha = 0.75$, reaches TTFP $103$ ms and RTF $0.076$, corresponding to roughly $13\times$ real-time synthesis. The authors argue that this is where block diffusion becomes especially compelling for deployment: TTFP stays close to streaming autoregressive systems, but steady-state throughput is far lower in wall-clock cost.
A side-by-side human study against ElevenLabs v3, a frontier commercial zero-shot TTS system, uses independent 5-point Likert ratings for naturalness and speaker similarity. Chatterbox-Flash achieves a slightly lower mean naturalness score but a cleaner low tail, and substantially higher speaker similarity.
The paper interprets this as evidence that the model preserves reference-speaker characteristics very well despite being trained on a smaller corpus than many of the larger baselines, while still remaining competitive on perceived naturalness.
To test whether prior calibration matters beyond saturated read speech, the authors also evaluate on EmergentTTS-Eval, which contains more prosodically and linguistically difficult utterances. Here, PMI helps more clearly: overall WER drops by $10.6\%$ relative, while the judge-based MOS stays essentially unchanged.
The most informative ablations are about block size, denoising budget, and the two inference-time calibration parameters $\alpha$ and $\beta$. The paper’s overall conclusion is that decoding quality saturates quickly on the easy benchmarks, but compute can still be reduced substantially by using calibrated early termination.
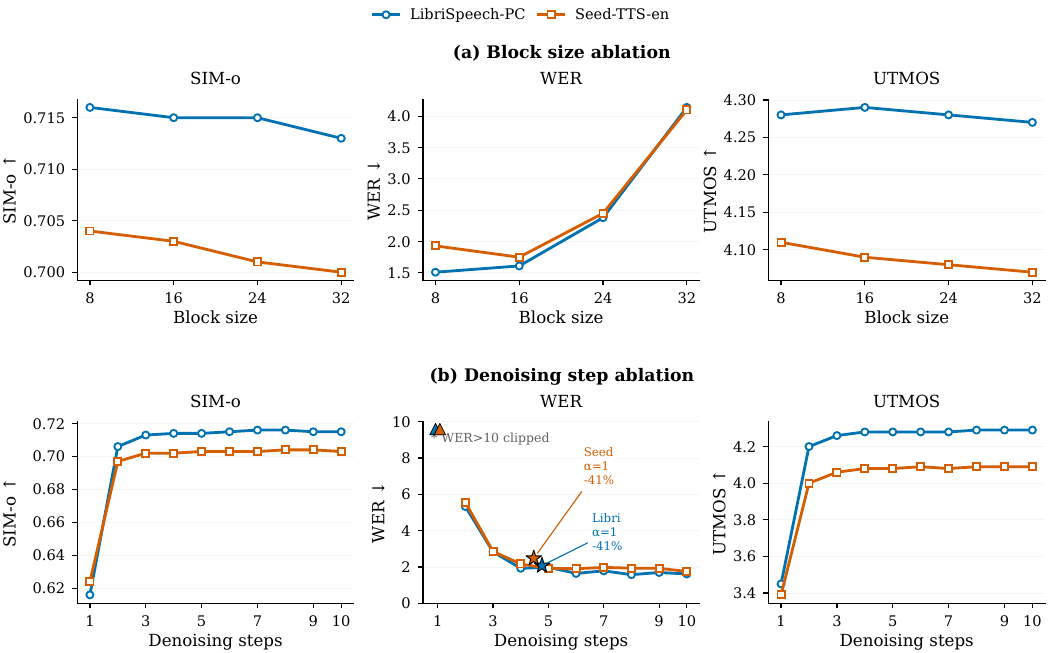
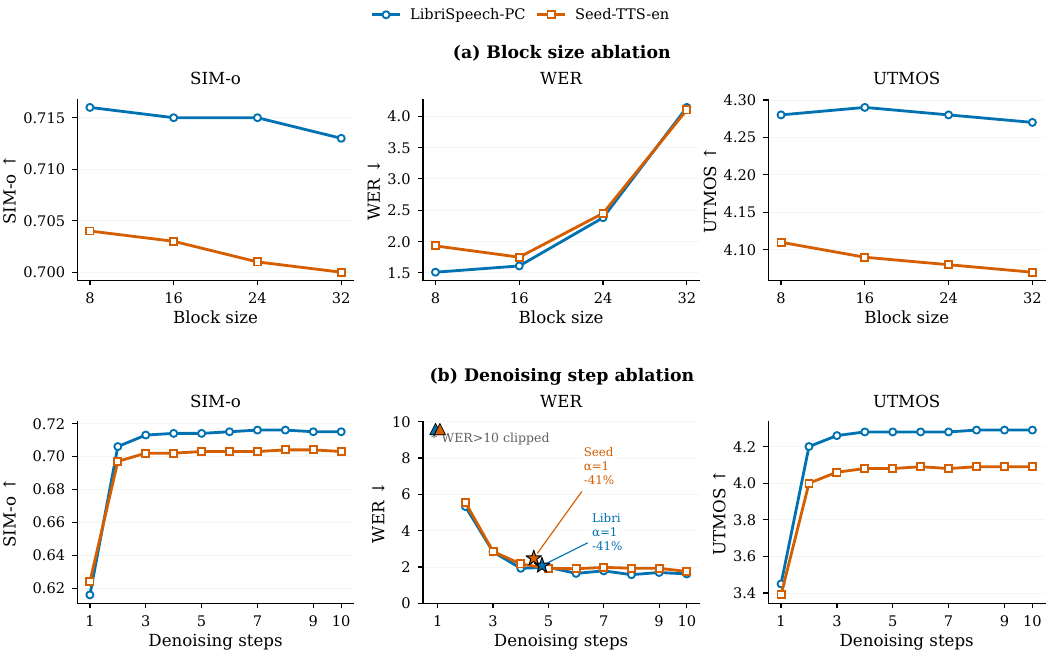
Block size. With inference block size swept over $D \in \{8, 16, 24, 32\}$, SIM-o and UTMOS remain almost flat, but WER is stable only up to $D = 16$ and then degrades sharply at larger blocks. This indicates that large blocks make parallel unmasking too hard: the model must commit more positions simultaneously than it can confidently rank, even after prior calibration.
Step budget. With fixed-step decoding and $D = 16$, quality becomes usable only once $K \geq 3$, and it plateaus by about $K \geq 6$. The authors therefore choose $K = 8$ as the default, which offers some headroom for adaptive early termination without entering the unstable low-step regime.
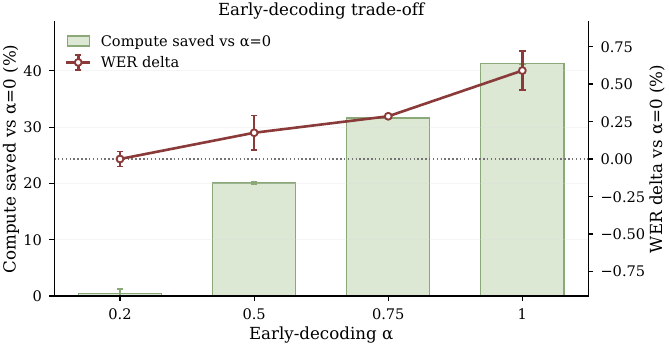
Early decoding. At $D = 16$ and $K = 10$, increasing $\alpha$ progressively saves more compute: about $20\%$ at $\alpha = 0.5$, $32\%$ at $\alpha = 0.75$, and $41\%$ at $\alpha = 1.0$. WER rises only mildly across this range. The canonical efficiency setting is therefore $\alpha = 0.5$, which gives a meaningful compute reduction with negligible quality loss.
Sampling temperature. The speech-token sampling temperature is swept over $T \in \{0.2, 0.4, 0.6, 0.8, 1.0\}$. The default $T = 0.2$ is the best read-speech operating point, minimizing mean WER while leaving SIM-o and UTMOS nearly unchanged. Higher temperatures gradually degrade WER.
Position temperature and decoding method. The position-level Gumbel temperature $\beta$ is compared at $\beta = 0$ versus $\beta = 5$ across both the TS schedule and PMI, and at step budgets $K \in \{2, 5, 8\}$. The key finding is that $\beta = 5$ consistently improves WER over deterministic top-$n_k$ selection, especially at low $K$. Comparing PMI and the TS schedule at $\beta = 5$, the two methods track each other closely on the saturated benchmarks, reinforcing the claim that PMI is mainly valuable as a calibrated confidence signal rather than as a direct quality improvement when compute is plentiful.
The appendix also reports that the streaming server version of the model incurs a modest quality drop relative to offline decoding. At the default streaming setting $D = 16$, $\alpha = 0.5$, the server scores SIM-o $0.688$, WER $2.03$, and UTMOS $4.07$ on LibriSpeech-PC, compared with offline $0.713$, $1.67$, and $4.28$. Larger blocks increase the quality gap, especially in WER, which is consistent with the main block-size ablation.
Two additional scaling explorations are important for understanding the method’s limits. A fully causal CARD-style block formulation works only at very small block sizes and starts to show prosodic collapse from $D = 5$ onward. A block-size-annealing, self-distillation recipe can grow the block up to roughly $D = 8$, but beyond that confidence collapses and sampling becomes highly sensitive to temperature and CFG scale. These experiments suggest that the current bottleneck is not simply engineering, but the difficulty of preserving both prosody and confidence calibration as block size increases.
The paper is unusually explicit about its limitations. First, the authors prioritize training stability in a fixed mixed-data regime and do not isolate the contribution of individual data sources. Second, the model becomes unstable when fine-tuned with much larger blocks, specifically $D \geq 128$, even with prior-calibrated decoding; this indicates that the method does not yet scale arbitrarily in parallelism. Third, on saturated read-speech benchmarks, prior-calibrated scoring and the time-shift baseline are statistically equivalent in objective quality, so the main advantage of PMI in the reported setup is its usefulness as a calibrated confidence signal for early stopping rather than a universal quality improvement.
The authors also note that whether prior calibration helps more under tighter compute budgets or on out-of-domain references remains open. Likewise, full-sequence diffusion systems such as OmniVoice may still have advantages when block-size scaling becomes unstable, and the paper views pseudo-streaming adaptations of such systems as a useful future comparison point.
Chatterbox-Flash shows that a pretrained autoregressive zero-shot TTS decoder can be converted into a practical block-diffusion model for streaming synthesis without changing the architecture. The two key ideas are prior calibration to neutralize dominant-token bias in discrete speech codecs and early decoding to turn that calibrated confidence into compute savings. On standard zero-shot benchmarks, the model matches strong baselines in quality, improves over its AR predecessor, and delivers much lower real-time factor with competitive time-to-first-packet. The result is a compelling design point for production-oriented, streaming, zero-shot TTS.
This repository implements the Chatterbox-Flash model as part of the broader Chatterbox family of text-to-speech systems. The core code lies under the The repo provides classes Pretrained models and tokenizer files are downloaded automatically from Hugging Face Hub or can be loaded locally. Conditioning includes speaker embeddings and speech prompts from reference audio enabling zero-shot voice cloning. The pipeline reflects the staged decoding and prior calibration mechanisms described in the paper at a high level. The README contains comprehensive usage examples illustrating model instantiation, conditioning preparation, and generation calls for both the standard and Turbo variants.Hybrid attention mask
Training objective
Inference: block-autoregressive decoding
Prior-calibrated scoring
Unmasking schedule and early decoding
Classifier-free guidance
Training data and experimental setup
Dataset
Samples
MLS-English 10.8M Emilia (English, part 1) 9.1M Loquacious 3.9M GLOBE 582K LibriTTS-R 375K HiFi-TTS 324K EARS 12K Expresso 12K Audiobook 17.7M Podcasts 726K IVR (VC-augmented) 445K Short-form utterances 292K Conversational 50K Stylized speech 62K Total 43.8M (≈70k hours) Main results
Model
#Params
Steps
LibriSpeech-PC test-clean
Seed-TTS test-en
SIM-o↑ WER↓ UTMOS↑
SIM-o↑ WER↓ UTMOS↑
Ground-truth -- -- 0.690 1.87 4.10 0.734 2.14 3.52 Autoregressive Models IndexTTS2 1.7B -- 0.700 2.35 4.06 0.706 2.33 3.65 CosyVoice3 1.1B -- 0.694 1.59 4.28 0.696 2.17 3.96 VoxCPM 0.7B -- 0.717 1.74 4.18 0.731 1.92 3.77 Qwen3-TTS 1.1B -- 0.704 1.60 4.41 0.708 1.54 4.16 Chatterbox 0.5B -- 0.707 1.99 4.29 0.685 2.20 4.10 Non-Autoregressive Models F5-TTS 0.4B -- 0.655 1.89 3.89 0.664 1.85 3.72 ZipVoice 0.1B -- 0.668 1.64 3.98 0.697 1.70 3.82 MaskGCT 2.2B -- 0.691 2.26 3.91 0.713 2.88 3.55 OmniVoice-Emilia 0.8B -- 0.697 1.57 4.23 0.717 1.72 3.88 OmniVoice 0.8B -- 0.729 1.30 4.28 0.741 1.60 3.91 Block-Autoregressive Models (Chatterbox-Flash, Ours) w/ Fast-dLLM v2 decoding 0.5B 10 0.656 15.36 4.14 0.646 14.49 4.00 w/ TS schedule 0.5B 8 0.714 1.69 4.29 0.703 1.97 4.09 w/ PMI ($\alpha = 0$, ours) 0.5B 8 0.717 1.67 4.29 0.704 1.96 4.09 w/ PMI + ED ($\alpha = 0.5$, ours) 0.5B 6.4 0.713 1.67 4.28 0.704 2.04 4.08 Streaming efficiency
Model / Config
TTFP (ms)↓
RTF↓
Qwen3-TTS (autoregressive) 25 Hz, 1.7B 150 0.253 25 Hz, 0.6B 138 0.234 12 Hz, 1.7B 101 0.313 12 Hz, 0.6B 97 0.288 Chatterbox-Flash (25 Hz, 0.5B, ours) $D = 16$, $\alpha = 0.5$ (default) 118 0.107 $D = 16$, $\alpha = 0.75$ 106 0.091 $D = 24$, $\alpha = 0.5$ 119 0.100 $D = 24$, $\alpha = 0.75$ 105 0.084 $D = 32$, $\alpha = 0.5$ 115 0.090 $D = 32$, $\alpha = 0.75$ 103 0.076 Human evaluation
Metric
ElevenLabs v3
Chatterbox-Flash
NMOS mean↑ 4.04 3.91 % ≤ 2↓ 12.9 8.6 % ≥ 4↑ 80.0 67.1 SMOS mean↑ 3.50 4.56 Hard-sample evaluation
Metric
TS schedule
PMI
WER (overall)↓ 38.52 34.42 MOS (judge)↑ 3.487 3.476 Per-category WER↓ Foreign Words 18.48 18.16 Paralinguistics 22.35 19.59 Pronunciation 79.89 69.93 Ablations and analysis
T
LibriSpeech-PC test-clean
Seed-TTS test-en
SIM-o↑ WER↓ UTMOS↑
SIM-o↑ WER↓ UTMOS↑
0.2 (default) 0.715 1.61 4.29 0.703 1.75 4.09 0.4 0.715 1.64 4.29 0.704 1.82 4.08 0.6 0.714 1.75 4.28 0.702 1.93 4.07 0.8 0.713 1.75 4.26 0.702 2.05 4.05 1.0 0.714 2.01 4.24 0.702 2.15 4.02
K
Method
β
LibriSpeech-PC test-clean
Seed-TTS test-en
SIM-o↑ WER↓ UTMOS↑
SIM-o↑ WER↓ UTMOS↑
2 TS schedule 0 0.679 15.10 4.00 0.676 15.40 3.81 TS schedule 5 0.697 8.74 4.13 0.690 9.13 3.93 PMI 0 0.690 11.82 4.08 0.682 13.98 3.86 PMI 5 0.707 5.17 4.21 0.697 5.37 4.01 5 TS schedule 0 0.714 2.52 4.26 0.702 2.50 4.08 TS schedule 5 0.714 1.91 4.28 0.702 2.13 4.09 PMI 0 0.715 2.36 4.27 0.703 2.46 4.07 PMI 5 0.713 1.96 4.27 0.703 2.01 4.08 8 TS schedule 0 0.714 1.87 4.28 0.703 2.07 4.09 TS schedule 5 0.714 1.69 4.29 0.703 1.97 4.09 PMI 0 0.716 1.82 4.28 0.703 2.25 4.09 PMI 5 0.717 1.67 4.29 0.704 1.96 4.09
Config
SIM-o↑
WER↓
UTMOS↑
$D = 16$, $\alpha = 0.5$ (default) 0.688 2.03 4.07 $D = 16$, $\alpha = 0.75$ 0.687 2.27 4.06 $D = 24$, $\alpha = 0.5$ 0.687 2.63 4.07 $D = 24$, $\alpha = 0.75$ 0.688 2.74 4.07 $D = 32$, $\alpha = 0.5$ 0.686 3.86 4.06 $D = 32$, $\alpha = 0.75$ 0.685 3.70 4.05 Offline reference 0.713 1.67 4.28 Limitations
Conclusion
Code & Implementation
src/chatterbox/ directory, including key modules such as tts.py and tts_turbo.py which encapsulate model loading, conditioning, and synthesis.ChatterboxTTS and ChatterboxTurboTTS implementing zero-shot TTS with different configurations corresponding to the paper's autoregressive and streaming block-diffusion approaches. These classes manage model components like the T3 decoder, S3Gen vocoder, and voice encoder, handling tokenization, conditioning on reference audio, and audio generation.