ImmersiveTTS
ImmersiveTTS: Environment-Aware Text-to-Speech with Multimodal Diffusion Transformer and Domain-Specific Representation Alignment
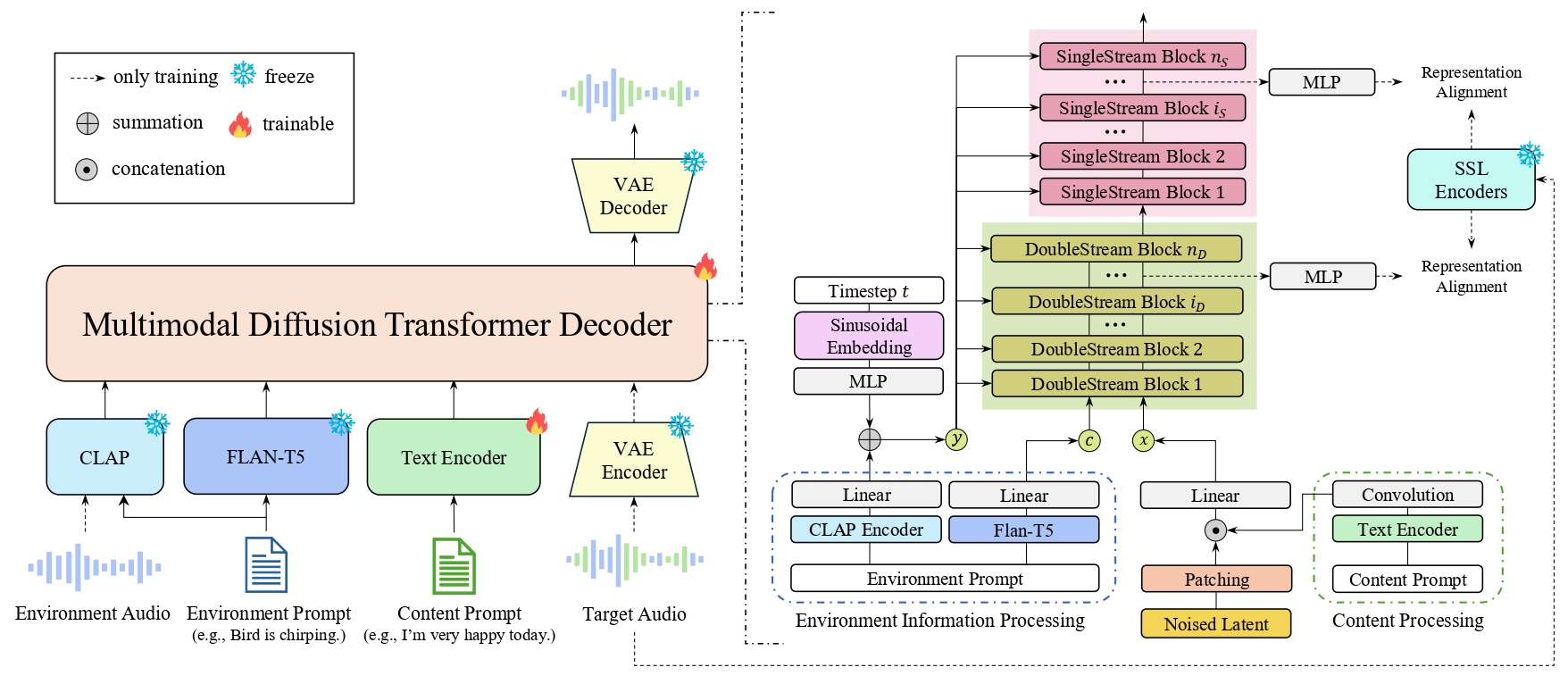
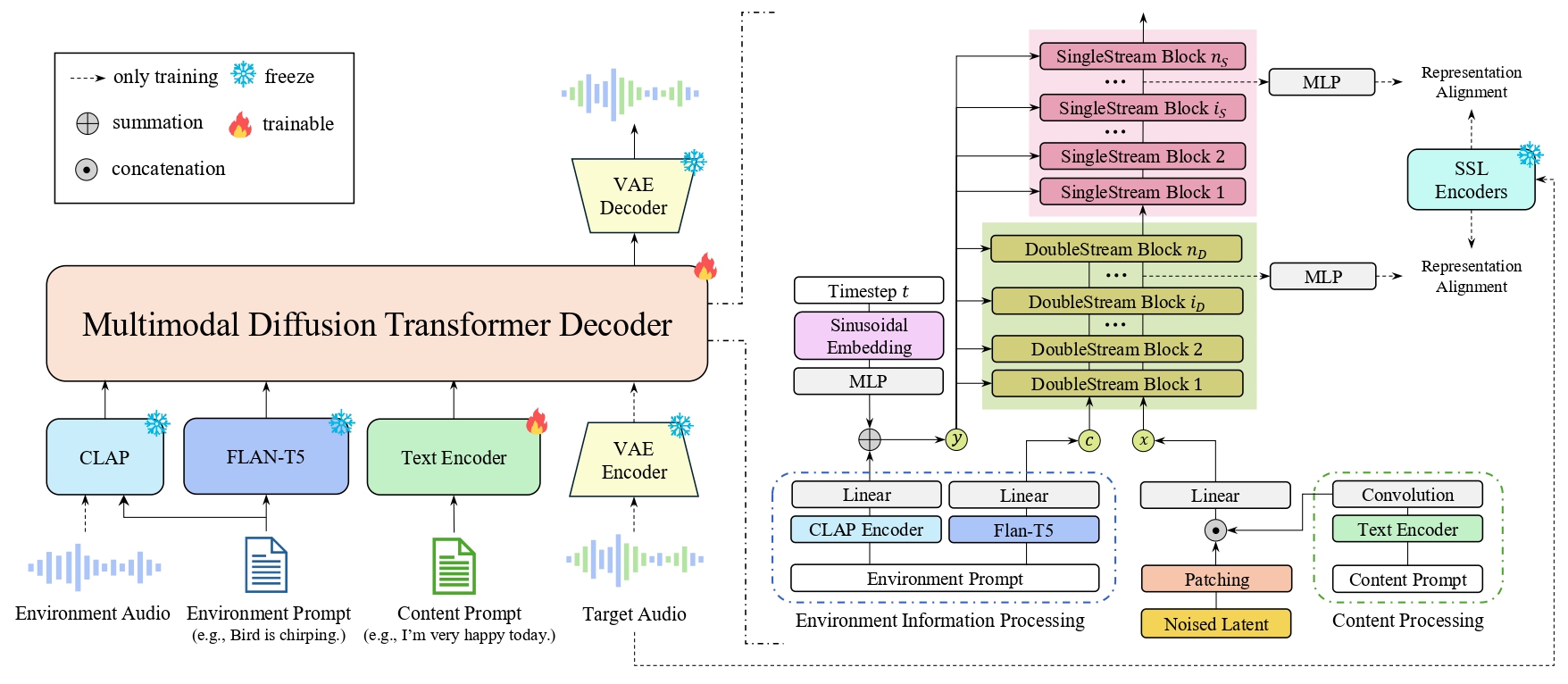
ImmersiveTTS synthesizes speech seamlessly integrated within environmental sounds by modeling transcript-aligned speech and text-conditioned environment together. It uses a multimodal diffusion transformer and domain-specific alignment to improve naturalness and coherence beyond prior text-to-speech methods.
Demos
ImmersiveTTS demos show environment-aware text-to-speech where natural speech integrates with realistic background sounds like birds, gunfire, and car noises. Evaluate the naturalness, clarity, and how well speech blends with environments, highlighting cross-modal fusion. The overview image illustrates the model's architecture and training approach for immersive audio synthesis.
Links
Paper & demos
Code & resources
Impact
Abstract
Recent advancements in text-guided audio generation have yielded promising results in diverse domains, including sound effects, speech, and music. However, jointly generating speech with environmental audio remains challenging due to the inherent disparities in their acoustic patterns and temporal dynamics. We propose ImmersiveTTS, an environment-aware text-to-speech (TTS) model that generates natural speech seamlessly integrated within environmental contexts by explicitly modeling cross-modal interactions. Our model builds on a multimodal diffusion transformer and fuses transcript-aligned speech latent with text-conditioned environmental context via joint attention. To enhance semantic consistency, we introduce a domain-specific representation alignment objective tailored to environment-aware TTS, leveraging complementary self-supervised representations from speech and audio encoders. Experimental results show that ImmersiveTTS achieves higher naturalness, intelligibility, and audio fidelity than existing approaches across objective metrics and human listening tests.
1. Problem setting and high-level idea
ImmersiveTTS targets environment-aware text-to-speech: given a speech transcription and a natural-language description of the acoustic scene, the model synthesizes speech that is intelligible while also sounding embedded in the requested environment. The paper frames this as a harder problem than either standard text-to-speech or text-to-audio, because the model must jointly handle two heterogeneous targets: linguistic speech content and environmental audio structure. The main technical claim is that a single generative backbone can do this well if it explicitly models cross-modal interaction between the transcript-conditioned speech stream and the environment-conditioned context stream, and if training is stabilized with a domain-specific representation-alignment objective.
- It adapts a multimodal diffusion transformer backbone to environment-aware speech synthesis.
- It uses joint attention between a speech latent stream and an environment context stream.
- It adds a domain-specific representation alignment loss using separate SSL teachers for speech and environmental audio.
- It is trained with flow matching rather than a standard diffusion U-Net objective, and uses dual classifier-free guidance at inference.
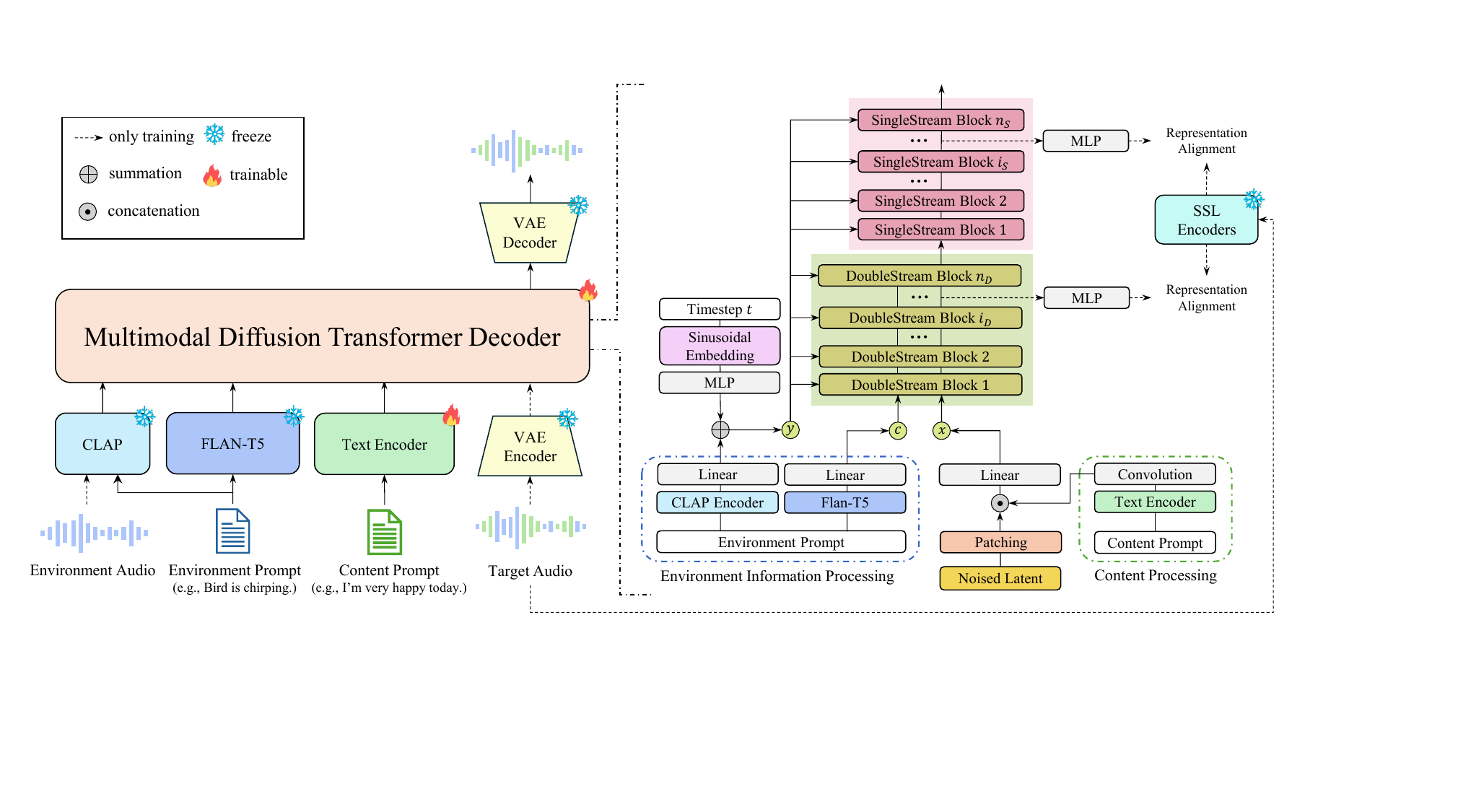
2. Core architecture
2.1 Latent audio representation and flow matching
The model operates in a compressed latent space derived from the pretrained AudioLDM2 variational autoencoder. Raw waveforms are converted into log-mel spectrograms, encoded into a latent tensor, and later decoded back to audio with the same VAE decoder plus a pretrained vocoder. The VAE is frozen during training.
If $X_{\text{wav}}$ is the raw waveform and $Z$ is the latent representation, the model learns a velocity field $v_\theta$ that transports a simple prior distribution to the data distribution through the ordinary differential equation
$$\frac{d}{dt} Z_t = v(Z_t,t), \quad Z_0 \sim \pi_0, \quad Z_1 \sim \pi_1.$$
Training minimizes the flow-matching loss
$$\mathcal{L}_{\text{Flow}}(\theta) = \mathbb{E}_{t,Z_0,Z_1}\left[\left\| (Z_1 - Z_0) - v_\theta(Z_t,t) \right\|^2\right], \quad Z_t = (1-t)Z_0 + tZ_1.$$
The paper emphasizes that this rectified-flow formulation is a practical fit for high-fidelity generation because it supports ODE sampling with relatively few function evaluations.
2.2 Conditioning design: transcript-aligned speech and text-conditioned environment
The model is conditioned on two text inputs: a content prompt $y_{\mathrm{cont}}$ containing the transcription, and an environment prompt $y_{\mathrm{env}}$ describing the background scene. ImmersiveTTS uses the Flux-style multimodal diffusion transformer architecture, with a stack of double-stream transformer blocks followed by single-stream blocks. The double-stream stage keeps the modalities separate but allows them to exchange information through joint attention. Only the speech stream is passed into the later single-stream blocks for final refinement.
The environment context branch uses a dual-granularity strategy. A global CLAP embedding of the environment prompt is projected by an MLP and used, together with the diffusion timestep, to modulate AdaLN scale and shift parameters. In parallel, token-level Flan-T5 embeddings are linearly projected into the model dimension and fed as the environment context sequence, giving the speech stream access to finer-grained environmental details through joint attention.
The speech branch explicitly aligns transcription with acoustic frames. A text encoder converts $y_{\mathrm{cont}}$ into hidden states, monotonic alignment search estimates durations, and the hidden states are expanded into a frame-level prior mel representation. A convolutional mapper then bridges this prior representation into the audio-latent manifold, and the result is concatenated with the noisy latent $Z_t$ before entering the speech stream.
In the appendix implementation details, the authors further state that a speaker embedding from a pretrained WavLM-based speaker verification model is projected and injected as an additional conditioning signal to preserve speaker identity.
2.3 Domain-specific representation alignment
A central novelty is the domain-specific REPA objective. Instead of aligning the transformer to a single generic teacher, the paper uses a dual-teacher strategy specialized for the two domains the model must satisfy simultaneously: WavLM for speech fidelity and ATST-Frame for environmental acoustics. The idea is to regularize intermediate speech-stream hidden states so that they resemble self-supervised representations that already encode the relevant semantics of each domain.
For each teacher encoder $E_k$, the target representation is $r_k = E_k(X)$. The speech-stream hidden state is projected through a lightweight MLP into the teacher feature space, temporally synchronized to the teacher representation, and aligned by cosine similarity:
$$\mathcal{L}_{\text{SSL}_k} = -\mathbb{E}_{X}\left[\operatorname{CosSim}(\tilde r_k, \tilde h'_k)\right].$$
The full alignment penalty is the weighted sum
$$\mathcal{L}_{\text{REPA}} = \sum_{k=1}^{K} \lambda_k \mathcal{L}_{\text{SSL}_k},$$
and in the reported experiments the weights are all set to $1$. The paper argues that this dual alignment mitigates the common trade-off between speech intelligibility and environmental realism: WavLM pushes the model toward precise linguistic structure, while ATST-Frame helps preserve acoustic scene cues.
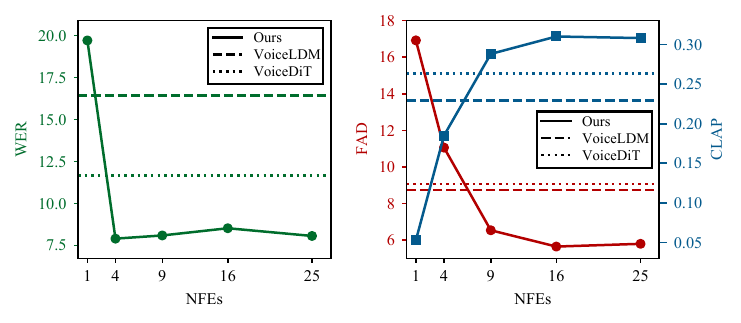
3. Training and inference
The total training objective combines four terms:
$$\mathcal{L} = \lambda_{\text{P}}\mathcal{L}_{\text{Prior}} + \lambda_{\text{D}}\mathcal{L}_{\text{Dur}} + \lambda_{\text{F}}\mathcal{L}_{\text{Flow}} + \lambda_{\text{R}}\mathcal{L}_{\text{REPA}}.$$
The prior and duration losses supervise the transcript-to-frame alignment path, while the flow and representation-alignment losses supervise the generative backbone. All weights are set to $1$ in the experiments. The CLAP and T5 encoders are frozen, as are the VAE and the SSL teachers.
Several implementation details matter for stability:
- The timestep $t$ is sampled from a logit-normal distribution with mean $0$ and variance $1$ rather than uniformly.
- During training, the content prompt and environment prompt are independently masked with probability $0.1$ to enable dual classifier-free guidance.
- Inference uses Euler integration of the learned ODE and then decodes the generated latent with the VAE decoder and vocoder.
- The main experiments use a balanced dual-guidance setting of $(\omega_{\text{env}},\omega_{\text{cont}})=(3,3)$ for ImmersiveTTS, while the appendix studies how changing either scale affects quality.
The paper also writes the dual classifier-free guidance explicitly as a correction to the base velocity field, combining unconditional, environment-only, and content-only predictions. The practical takeaway from the analysis is that too much environmental guidance can damage intelligibility, while too much content guidance can reduce scene coherence and audio realism.
The reported architecture uses 12 double-stream blocks, 18 single-stream blocks, 6 attention heads, and a hidden dimension of 1024, for about 450M trainable parameters. Training runs for 400k steps on 2 NVIDIA RTX A6000 GPUs with AdamW and a constant learning rate of $10^{-4}$.
4. Data, preprocessing, and evaluation protocol
4.1 Training data construction
The training corpus is built from LibriTTS train-clean-360 for clean speech and WavCaps for environmental sounds. The paper filters WavCaps to remove any clips with spoken content, leaving 340k non-speech clips out of the original 400k. Training examples are made by mixing clean speech with environmental audio at an SNR sampled uniformly between 2 and 10 dB. To preserve the ability to generate clean speech, the mixing step is skipped with probability $0.15$.
Audio is downsampled to 16 kHz and converted to 64-bin mel spectrograms using an STFT with FFT size 1024, window size 1024, and hop length 160. The frozen AudioLDM2 VAE then encodes the spectrogram into an 8-channel latent target.
4.2 Test sets
The main environment-aware evaluation uses the AudioCaps test set. The paper also evaluates an augmented test set created by mixing clean speech from Seed-TTS test-en with non-speech clips from AudioCaps test. In addition, single-task evaluations are reported on the LibriTTS test set and the AudioCaps test set, and the appendix includes broader baseline comparisons.
4.3 Metrics
The subjective evaluation reports mean opinion scores on a 5-point scale for speech naturalness (SN-MOS), environmental consistency (EC-MOS), overall integration naturalness (ON-MOS), and, in the appendix, speaker similarity (S-MOS). The evaluations use 30 sampled utterances per test set, 20 native English crowd workers per task, and 95% confidence intervals.
Objective metrics include word error rate (WER) using Whisper-Large-v3, speaker embedding cosine similarity (SECS) using WavLM-base-sv, Frechet audio distance (FAD) using VGGish features, CLAP score for text-audio semantic coherence, and the number of function evaluations (NFEs) as a measure of sampling cost. The single-task appendix additionally reports UTMOS as a proxy for speech naturalness.
5. Main results
Across both the original environment-aware test set and the augmented test set, ImmersiveTTS is consistently better than the diffusion baselines VoiceLDM and VoiceDiT on the metrics that matter most for the joint problem: speech naturalness, overall integration, intelligibility, audio fidelity, and text-environment coherence. The paper also emphasizes that these gains are obtained with only 25 NFEs, compared with 200 NFEs for the baselines.
The authors note that the high WER of the ground-truth and reconstructed environment-aware samples is not surprising, because background audio can mask speech and degrade ASR.
| Model | Trainable params | NFEs | SN-MOS | EC-MOS | ON-MOS | WER | FAD | CLAP |
|---|---|---|---|---|---|---|---|---|
| Ground Truth | — | — | — | — | — | 22.29 | — | 0.503 |
| Reconstructed | — | — | 4.08 ± 0.08 | 4.16 ± 0.08 | 3.49 ± 0.05 | 22.58 | — | 0.488 |
| VoiceLDM | 508M | 200 | 3.41 ± 0.06 | 3.33 ± 0.07 | 2.55 ± 0.05 | 16.45 | 8.75 | 0.229 |
| VoiceDiT | 566M | 200 | 3.47 ± 0.05 | 3.44 ± 0.07 | 2.63 ± 0.05 | 11.68 | 9.07 | 0.263 |
| ImmersiveTTS | 450M | 25 | 4.20 ± 0.07 | 3.48 ± 0.07 | 3.47 ± 0.05 | 8.06 | 5.80 | 0.308 |
On this test set, ImmersiveTTS achieves the best scores on SN-MOS, ON-MOS, WER, FAD, and CLAP. It improves both speech quality and environment integration over the baselines, while also being much faster at inference.
| Model | Trainable params | NFEs | SN-MOS | EC-MOS | ON-MOS | WER | FAD | CLAP |
|---|---|---|---|---|---|---|---|---|
| Ground Truth (Augmented) | — | — | — | — | — | 7.86 | — | 0.317 |
| Reconstructed | — | — | 4.02 ± 0.08 | 3.95 ± 0.08 | 3.41 ± 0.07 | 3.59 | — | 0.291 |
| VoiceLDM | 508M | 200 | 3.32 ± 0.06 | 3.24 ± 0.07 | 2.91 ± 0.08 | 11.20 | 6.98 | 0.118 |
| VoiceDiT | 566M | 200 | 3.45 ± 0.06 | 3.38 ± 0.06 | 3.12 ± 0.08 | 7.08 | 5.37 | 0.134 |
| ImmersiveTTS | 450M | 25 | 4.18 ± 0.07 | 3.32 ± 0.06 | 3.23 ± 0.08 | 4.48 | 3.92 | 0.207 |
On the augmented set, ImmersiveTTS again gives the best SN-MOS, ON-MOS, WER, FAD, and CLAP among the unified environment-aware systems. VoiceDiT has a slightly higher EC-MOS, but the paper’s interpretation is that ImmersiveTTS offers the better overall balance between speech clarity and scene integration.
6. Single-task evaluation and broader baselines
The appendix also evaluates the model in single-task settings. For TTS, ImmersiveTTS produces lower WER than VoiceLDM and VoiceDiT, but still does not reach specialized TTS systems such as CosyVoice2 or CosyVoice3. For TTA, ImmersiveTTS produces better FAD and CLAP than VoiceLDM and VoiceDiT, but is far behind specialized audio generators such as AudioLDM2-Audio and TangoFlux. This is consistent with the paper’s central message: a unified environment-aware model must trade off some single-domain performance in order to jointly model speech and background audio.
| Model | NFEs | WER | UTMOS | SECS | FAD | CLAP |
|---|---|---|---|---|---|---|
| Ground Truth | — | 2.21 | 4.00 | 0.9218 | — | 0.512 |
| VoiceLDM | 200 | 14.01 | 2.82 | 0.7601 | 8.71 | 0.288 |
| VoiceDiT | 200 | 11.08 | 3.33 | 0.8942 | 8.23 | 0.302 |
| ImmersiveTTS | 25 | 9.89 | 3.23 | 0.8859 | 7.81 | 0.323 |
The broader appendix comparisons make the same point more strongly. In dedicated TTS, CosyVoice2 and CosyVoice3 achieve much lower WER and higher SECS than the environment-aware system. In dedicated TTA, AudioLDM2-Audio and TangoFlux reach much better FAD and CLAP. The best pipeline baseline is the two-stage combination of specialized generators and post-hoc mixing, but that requires separate models and does not capture speech-background interaction inside a single generative process.
7. Ablations and diagnostic analyses
7.1 Representation-alignment ablation
The paper’s most informative ablation compares alignment targets. The trend is clear: using only a speech teacher helps intelligibility, using only an environmental teacher helps scene coherence, and using the complementary pair gives the best overall result.
| Strategy | Target SSL | Speech domain | Environment domain | WER | FAD | CLAP |
|---|---|---|---|---|---|---|
| Base | — | — | — | 11.21 | 9.64 | 0.236 |
| Single | WavLM | Yes | No | 10.97 | 8.02 | 0.231 |
| Single | ATST | No | Yes | 13.77 | 8.78 | 0.271 |
| Single | USAD | Yes | Yes | 9.04 | 7.93 | 0.239 |
| Dual | WavLM + USAD | Yes | Yes | 8.95 | 7.33 | 0.248 |
| Dual | USAD + ATST | Yes | Yes | 8.94 | 8.20 | 0.266 |
| Dual | WavLM + ATST | Yes | Yes | 8.06 | 5.80 | 0.308 |
This ablation supports the design choice in the main model: WavLM and ATST-Frame are complementary, and the direct pair is better than the distilled unified encoder USAD in this setting. The paper also reports that aligning in the middle or slightly earlier transformer layers is more stable than aligning at very late or very early layers, and that injecting both teachers into the MM-DiT stage gives the strongest results.
7.2 Sampling-step efficiency
The sampling analysis shows a smooth quality-efficiency trade-off. As NFEs increase, WER and FAD decrease while CLAP increases. The largest gain is seen when moving from extremely few steps to a moderate number of steps. Importantly, ImmersiveTTS reaches or exceeds the diffusion baselines with far fewer steps; the paper specifically notes that at 9 steps it already outperforms VoiceLDM and VoiceDiT, both of which use 200 NFEs.
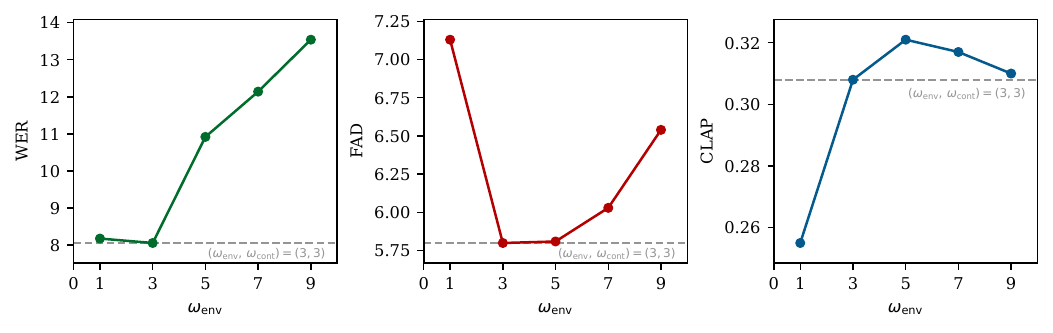
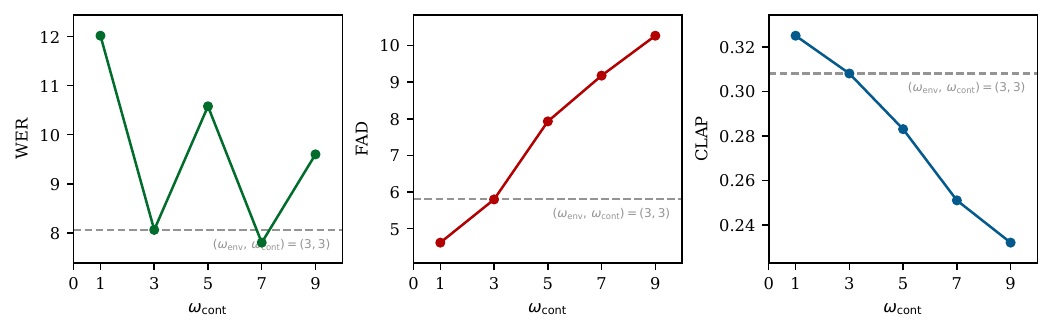
The dual-guidance sweeps clarify how the two conditioning streams interact. Raising the environment guidance scale above the balanced setting hurts speech intelligibility sharply, even if it can slightly improve semantic alignment of the background. Raising the content guidance scale can reduce WER up to a point, but it steadily worsens FAD and CLAP when pushed too far. The balanced setting around $(3,3)$ is therefore used as the main operating point.
7.3 Speaker identity preservation
The appendix also reports S-MOS on the augmented set. ImmersiveTTS obtains an S-MOS of 3.15, matching VoiceDiT and exceeding VoiceLDM, and it is close to the reconstructed samples at 3.18. This suggests that the model preserves speaker identity reasonably well even though the primary challenge is environment-aware synthesis.
8. Limitations
The paper is explicit about several limitations. First, training relies largely on synthetic mixtures of speech and environmental audio, so it may not fully capture the complexity of real-world acoustic scenes. Second, robustness across different SNRs and scene difficulty levels is not fully explored. Third, the model does not provide explicit control over paralinguistic properties such as prosody, speaking style, or emotion. The authors identify these as important directions for future work, especially if the goal is to synthesize speech that is not only environment-matched but also expressive.
9. Bottom-line takeaways
- ImmersiveTTS extends multimodal diffusion transformers to environment-aware TTS with a purpose-built dual-stream design.
- Its main novelty is not just the backbone, but the way it couples transcript-aligned speech latents, prompt-conditioned environmental context, and domain-specific self-supervised alignment.
- The dual-teacher REPA choice, especially WavLM plus ATST-Frame, is the key ablation result supporting the method.
- The model improves subjective naturalness and integration while also lowering WER and FAD relative to prior unified environment-aware baselines, and it does so with much fewer sampling steps.
- Specialized single-task systems still win on their own metrics, which reinforces the paper’s framing of environment-aware TTS as a genuinely multi-objective generation problem.
Code & Implementation
This repository implements the ImmersiveTTS model as described in the paper, providing an environment-aware text-to-speech system using a multimodal diffusion transformer architecture.
The main code base includes:
train.py: The primary training script initializes the model, loads datasets (LibriTTS for speech and WavCaps for environmental audio), and handles multi-GPU training using Hugging Face Accelerate. It integrates pretrained components such as VAE from AudioLDM2, CLAP for audio-text embeddings, and optional speech/audio encoders (e.g., WavLM, USAD, ATST-Frame) for self-supervised representation alignment.immtts/pipeline.py: Defines theImmersivettsPipelineclass that loads a pretrained checkpoint, prepares necessary encoders and vocoders, and provides the inferencegeneratemethod. This method converts raw text to phoneme tokens, extracts speaker embeddings, processes environmental text with CLAP, runs the diffusion inference to generate latent representations, and decodes them to waveforms.
The repository also contains configuration YAML files for training setup and model hyperparameters.
As stated in the README, users can configure dataset paths, distributed training options, and other hyperparameters via these configs, then use the provided launch commands to train or generate speech conditioned on both textual content and environmental context.