SwanVoice
SwanVoice: Expressive Long-Form Zero-Shot Speech Synthesis for Both Monologue and Dialogue
SwanVoice is a zero-shot TTS system for expressive long-form speech synthesis in monologue and multi-speaker dialogue. It models entire conversations to keep acoustic consistency and smooth speaker transitions, outperforming typical turn-by-turn methods in expressiveness and coherence.
Links
Paper & demos
Code & resources
Abstract
Zero-shot text-to-speech (TTS) has improved substantially for single-speaker synthesis, yet expressive long-form multi-speaker dialogue remains difficult. A common workaround is to synthesize each turn with a monologue TTS model and stitch the outputs together. This adds inference cost and often breaks acoustic consistency, conversational coherence, and affective continuity across turns. Recent dialogue TTS systems have begun to address this setting, but they still struggle to keep expressive coherence, controllable speaker switching, and monologue quality at the same time. We present SwanData-Speech and SwanVoice. SwanData-Speech builds monologue and dialogue corpora from in-the-wild audio, using Swan Forced Aligner for pause-aware word-level alignment and RobustMegaTTS3 for pronunciation-hard cases. Built on these data, SwanVoice is a zero-shot TTS model for 1--4 speakers, combining a 25 Hz VAE, raw-text conditioning with pause-aware symbols and pinyin substitution, and a flow-matching DiT with speaker-turn conditioning. Training starts from monologue speech, moves through mixed and real dialogue data, and then uses DiffusionNFT post-training with phone-level and speaker-similarity rewards. On SwanBench-Speech, SwanVoice obtains higher richness and hierarchy scores than all evaluated open-source baselines in both monologue and dialogue settings, while content accuracy remains the main limitation. Audio demos are available at https://swanaigc.github.io//#swanvoice.
Overview
SwanVoice addresses a specific gap in zero-shot TTS: generating expressive long-form speech for both monologue and multi-speaker dialogue without stitching together independent turns. The paper argues that turn-by-turn synthesis often breaks acoustic consistency, conversational coherence, and affective continuity, especially when the output must sound like a single recorded scene rather than a concatenation of isolated utterances. SwanVoice is built to model the entire conversation context at once, while still retaining strong monologue quality.
The system has two tightly coupled parts:
- SwanData-Speech, a data pipeline that turns in-the-wild audio into monologue and dialogue training subsets with pause-aware transcripts, diarization, filtering, and pronunciation-hard synthetic augmentation.
- SwanVoice, a zero-shot TTS model for 1--4 speakers that combines a 25 Hz VAE, raw-text conditioning with pause and pinyin controls, a flow-matching DiT backbone, a curriculum from monologue to real dialogue, and DiffusionNFT post-training.
The main empirical claim is not that SwanVoice solves content accuracy perfectly, but that it produces the most expressive long-form speech among the evaluated open-source systems on SwanBench-Speech, especially on the richness and hierarchy dimensions in both monologue and dialogue settings.
SwanData-Speech: data construction and preprocessing
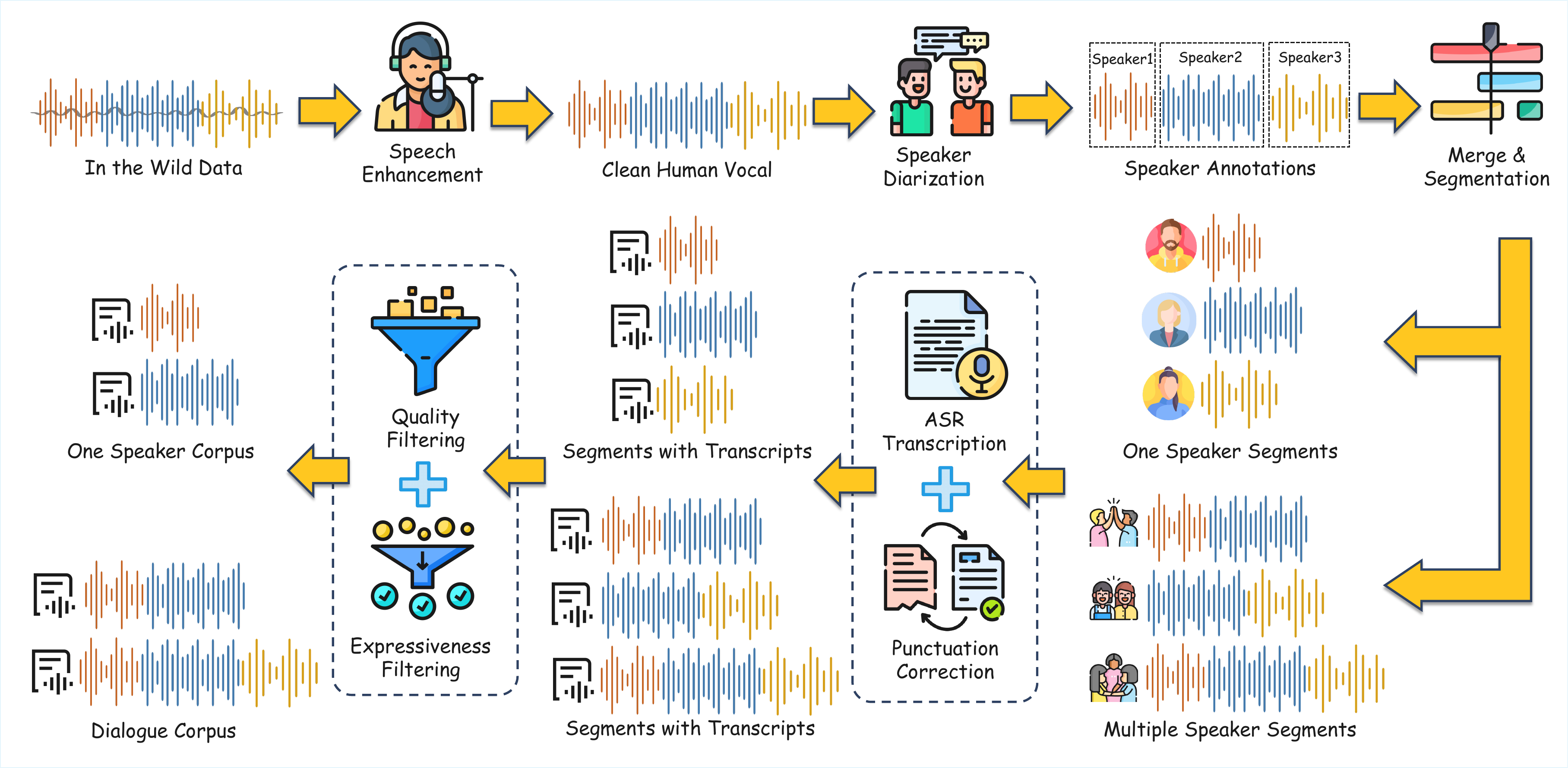
SwanData-Speech starts from a very large raw collection drawn mainly from internal resources, plus selected open-source Chinese and English data. The paper reports roughly 2.59 million hours of audio in the raw pool, including about 2.24 million hours of Chinese and 0.35 million hours of English. The final pipeline outputs separate monologue and dialogue subsets for SwanVoice, while an additional 80K-hour subset is reserved for forced-aligner training and evaluation.
The pipeline is designed to keep the transcript close to acoustic reality rather than semantic punctuation conventions. This is important because downstream TTS models can otherwise learn punctuation behavior that does not match pauses, hesitations, or turn boundaries in speech.
Hard-case synthetic data for pronunciation robustness
To strengthen pronunciation coverage, the paper constructs a synthetic subset called RobustMegaTTS3. The authors gather the full word list from GCIDE 0.54 and the Level-1 and Level-2 Chinese character lists from the official table of general standard Chinese characters. An LLM, Qwen3-235B-A22B-Instruct-2507, generates five example sentences per entry.
They also generate:
- 20K Chinese hard cases covering polyphonic-character disambiguation in context, erhua, tone sandhi, onomatopoeic characters, homographs with different pronunciations, noun--verb stress shift, and irregular spellings.
- 20K English hard cases with pronunciation edge cases.
- 100K Chinese--English code-switching texts spanning 13 scenarios and roles.
This portion of the corpus is rendered with MegaTTS 3, which provides pronunciation knowledge for rare and ambiguous cases. The goal is to cover difficult pronunciations and code-switching that are sparse in crawled speech.
Segmentation, diarization, and pause-aware transcription
The pipeline first applies speech enhancement via vocal separation, then performs speaker diarization using the 3D-Speaker toolkit with VAD, embeddings, clustering, and speaker-aware grouping. Short same-speaker fragments separated by at most 2 seconds are merged, segments shorter than 0.1 seconds are removed, and merged same-speaker samples are capped at 60 seconds. For dialogue, consecutive multi-speaker segments are merged up to 120 seconds, with each merged sample containing 2--4 speakers and no silence interval longer than 2 seconds.
Transcription uses SenseVoice-Small with Chinese and English language filtering, and inverse text normalization is disabled so that the text remains closer to pronunciation. A small text Transformer restores punctuation before pause correction. Dialogue turns are explicitly wrapped with <S{id}> and </S{id}> tokens so the downstream model can condition on speaker identity at the turn level.
Pause-aware punctuation is then reconstructed with a forced aligner. The paper uses the gap between adjacent character timestamps to revise punctuation:
- Pauses shorter than 0.08 s are ignored.
- Pauses between 0.08 s and 0.18 s are marked with
<|sp|>. - Pauses between 0.18 s and 0.45 s become commas.
- Pauses longer than 0.45 s become sentence punctuation, depending on the original punctuation before correction, with period as the default.
The point is to align textual markup with acoustic pauses, because in conversational speech semantic punctuation and real pausing can diverge substantially.
Filtering and expressiveness selection
All samples are scored using DNSMOS and the non-intrusive PESQ/STOI estimators from torchaudio-SQUIM. After the initial quality filtering, emotion2vec+ classifies each sample’s emotion and confidence. High-confidence non-neutral samples define a high-expressiveness subset. This is consistent with the paper’s goal of building training data that is not merely clean, but also sufficiently expressive for long-form dialogue generation.
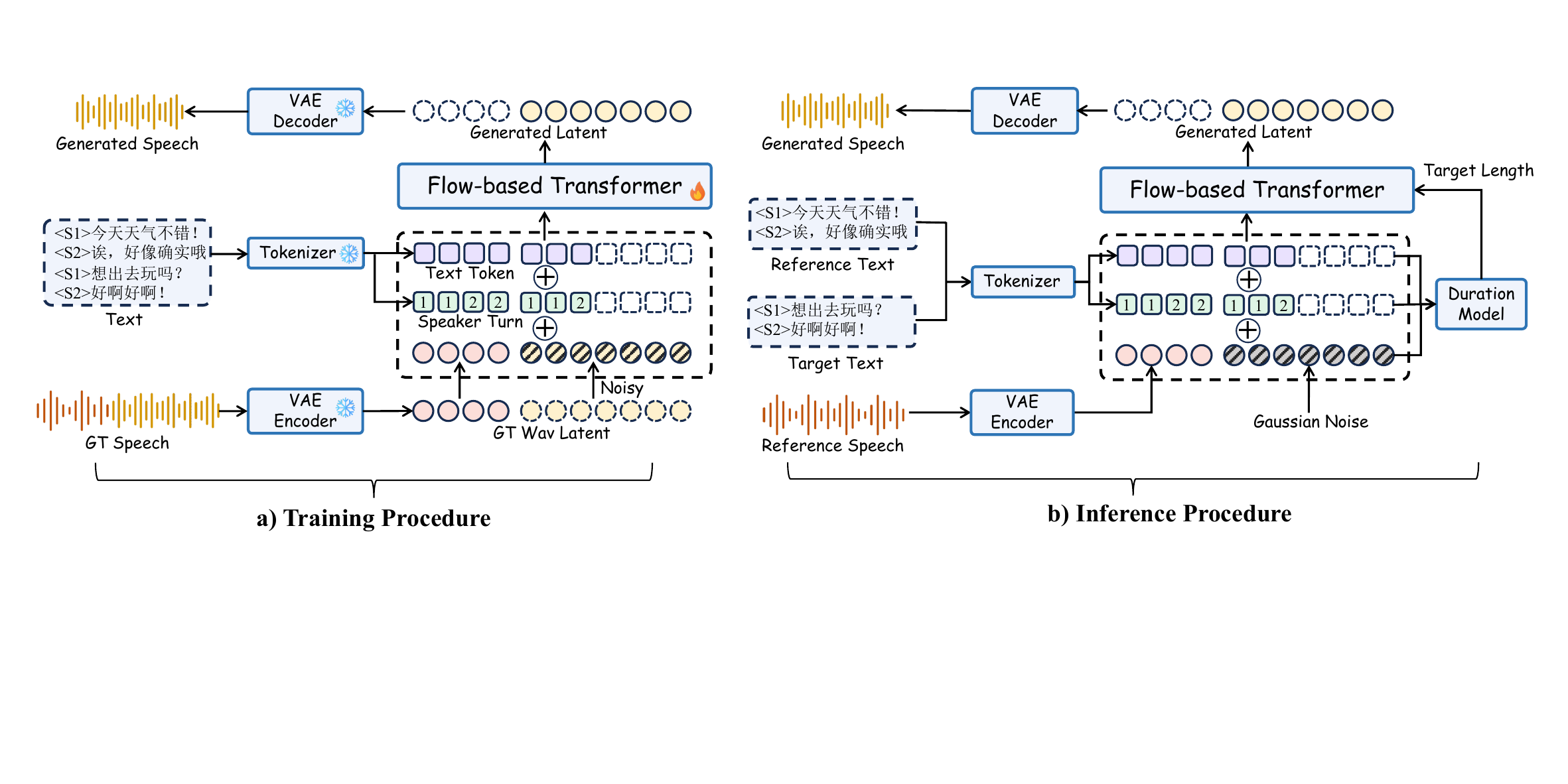
SwanVoice: architecture and training
Speech codec VAE at 25 Hz
SwanVoice uses a variational autoencoder to compress waveform sequences to 25 latent frames per second. The encoder follows the design of WavTokenizer-style speech tokenization, and the decoder is based on HiFi-GAN. The model is trained with a reconstruction loss, a lightly weighted KL regularizer, and adversarial losses from multi-period, multi-scale, and multi-resolution discriminators.
The paper writes the overall VAE objective as:
$$ \mathcal{L} = \mathcal{L}_{\mathrm{rec}} + \mathcal{L}_{\mathrm{KL}} + \mathcal{L}_{\mathrm{Adv}}, $$
where $\mathcal{L}_{\mathrm{rec}}$ is a spectrogram-domain reconstruction term, $\mathcal{L}_{\mathrm{KL}}$ is a lightly weighted latent regularizer, and $\mathcal{L}_{\mathrm{Adv}}$ is an LSGAN-style adversarial loss. The practical motivation is to reduce sequence length for long-form generation while still preserving perceptual fidelity.
Raw-text tokenizer, pause symbols, and pinyin control
Instead of relying on a separate grapheme-to-phoneme frontend, SwanVoice conditions directly on raw text using the CosyVoice tokenizer. The tokenizer is BPE-based, but for Chinese it effectively operates at character granularity, which reduces long-pronunciation sparsity problems that can occur when one token must represent an overly long or ambiguous pronunciation.
The tokenizer vocabulary is extended in three ways:
- a dedicated pause token,
<|sp|>; - 1,549 pinyin syllable combinations for pronunciation control;
- speaker-turn labels aligned one-to-one with the text-token sequence.
During training, a random subset of Chinese characters is replaced by pinyin forms extracted with pypinyin. At inference time, pinyin hints can force the pronunciation of polyphonic characters or dialect-sensitive forms. For dialogue, each turn is wrapped with <S{id}> and </S{id}>, and a parallel speaker label sequence is built by detecting these tags and assigning a speaker ID to each token span.
Flow-matching DiT with speaker-turn conditioning
The generator is a flow-matching Diffusion Transformer conditioned on text, speaker-turn labels, and a reference speech latent. Before fusion with speech latents, the padded text and turn embeddings are processed by a lightweight Transformer stack so that the model can build text-side and turn-side features first. The paper argues that this is preferable to naive early concatenation because it improves in-context conditioning.
Training uses a complete utterance latent $\mathbf{z}^{\star}$. The latent is split into a reference segment and a target segment; for dialogue, the reference segment must contain at least some speech from every speaker. The target is noised, and the model predicts the velocity field along the flow trajectory:
$$ \mathcal{L}_{\mathrm{flow}} = \mathbb{E}_{t \sim \mathcal{U}(0,1),\, \mathbf{z}^{\star} \sim p_{\mathrm{data}},\, \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \mathbf{I})} \left[ \left\| \mathbf{u}_{\theta}(\mathbf{z}_{t}, t, \mathbf{c}) - (\mathbf{z}^{\star} - \boldsymbol{\epsilon}) \right\|_{2}^{2} \right], $$
with $\mathbf{z}_{t} = (1-t)\boldsymbol{\epsilon} + t\mathbf{z}^{\star}$ and conditioning $\mathbf{c}$ containing the processed text, the speaker-turn embeddings, and the reference latent. RMSNorm is used throughout, and AdaLN-style global adapters are added to stabilize optimization and preserve long-form consistency in timbre and recording conditions.
Three-stage curriculum
The paper emphasizes that training directly on conversational data is unstable. SwanVoice therefore uses a three-stage curriculum:
- Monologue pretraining on about 2 million hours of Chinese and English monologue speech, plus the pronunciation-hard and code-switching synthetic cases.
- Mixed conversational training on monologue data plus concatenated 2--4-speaker dialogue examples, with dialogue sampled more often than its raw-hour proportion to teach speaker switching while protecting monologue quality.
- Supervised fine-tuning on monologue data plus real 2--4-speaker conversational data, mainly from movies, TV dramas, and podcasts, to learn higher-level coherence, recording-environment stability, and emotional continuity.
Post-training with DiffusionNFT
After supervised training, the model still makes predictable mistakes such as misreading difficult words or drifting in prompt speaker identity. The authors address this with DiffusionNFT, an online reinforcement-learning-style post-training stage that updates the flow-matching model using sampled utterances and reward scores. The optimization is value-free and aligns well with the flow-matching backbone.
The reward has two parts:
- Phone consistency reward, computed by running an external phone recognizer on the generated speech and comparing the phone-tone sequence to the target pronunciation. If $\mathbf{u}^{\mathrm{ref}}$ and $\mathbf{u}^{\mathrm{hyp}}$ are the reference and hypothesis phone-tone sequences, then the paper defines $\mathrm{WER}(\mathbf{u}^{\mathrm{ref}}, \mathbf{u}^{\mathrm{hyp}})$ in the usual substitution/deletion/insertion sense and sets $r_{\mathrm{phone}} = \exp(-\mathrm{WER})$.
- Speaker similarity reward, computed as cosine similarity between frozen speaker embeddings of the generated speech and the reference prompt.
The total reward is the average of the two, $r = \frac{1}{2}(r_{\mathrm{phone}} + r_{\mathrm{sim}})$. The post-training data includes 3K real human conversation samples, which are transcribed and pause-corrected before use. The paper notes that the post-training objective explicitly targets pronunciation robustness and timbre preservation, while improved environment consistency and expressiveness are observed as side effects.
Inference and staircase CFG
At inference time, the model takes a reference speech segment and a target text sequence, synthesizes the target content, and preserves the reference speaker identity and speaking style. The reference speech is transcribed with SenseVoice-Small to obtain speaker-specific reference text, and target duration is estimated using a simple speaking-rate heuristic for each speaker in the prompt. The decoder uses sway sampling so that the early denoising steps capture coarse contours and later steps refine fine details.
The paper also introduces a staircase classifier-free guidance scheme with three conditioning variants: null, text-only, and full. The guided prediction is:
$$ \tilde{v}_{t} = v_{\emptyset} + \omega_{\mathrm{text}}(v_{\mathrm{text}} - v_{\emptyset}) + \omega_{\mathrm{ref}}(v_{\mathrm{full}} - v_{\mathrm{text}}), $$
where $\omega_{\mathrm{text}}$ controls content guidance and $\omega_{\mathrm{ref}}$ controls reference-dependent speaker/style guidance. This separation lets the user strengthen timbral similarity without tying it too tightly to the text-conditioning strength.
Evaluation setup
The paper evaluates SwanVoice on SwanBench-Speech using three axes: acoustics, semantics, and expressiveness. The acoustic metrics are timbre consistency, reverb consistency, and sound fidelity. Semantic metrics are content error and prosodic coherence. Expressiveness is measured using a large multimodal language model as a judge, with separate scores for sentence-level expressive richness and paragraph-level expressive hierarchy.
For expressiveness, audio is split into non-overlapping 10-second chunks for richness. Hierarchy is scored on the full utterance using three rubric dimensions: Emotional Variation, Vocal Dynamics, and Scene Appropriateness. The evaluator used in the paper is Gemini-3-Pro, and samples are randomized and anonymized to reduce bias.
The paper compares SwanVoice against 10 open-source monologue baselines and 6 open-source dialogue baselines. The reported baseline sets are:
- Monologue: ZipVoice, SparkTTS, CosyVoice2-0.5B, CosyVoice3-0.5B, GLM-TTS, MegaTTS3, IndexTTS2, FishSpeech-1.5, F5TTS, and VibeVoice.
- Dialogue: ZipVoice-Dialog, MoonCast, MOSS-TTSD, FireRedTTS2, VibeVoice, and SoulX-Podcast.
Monologue results
SwanVoice’s monologue results are especially strong on the expressive dimensions. It reaches 3.81 in richness and 3.62 in hierarchy, both the best among the evaluated open-source systems. Relative to the strongest expressive baseline, VibeVoice, the gains are 0.39 points in richness and 0.56 points in hierarchy. SwanVoice is not the best model on content error, but it remains competitive on acoustic quality and prosodic coherence.
| Model | Timbre | Reverb | Sound Fidelity | Content Error | Prosody | Richness | Hierarchy |
|---|---|---|---|---|---|---|---|
| CosyVoice-2 | 0.93 | 2.37 | 3.58 | 0.106 | 2.81 | 2.02 | 2.59 |
| CosyVoice-3 | 0.93 | 2.73 | 3.80 | 0.077 | 3.26 | 2.64 | 2.47 |
| FishSpeech | 0.93 | 2.00 | 4.09 | 0.066 | 3.77 | 2.37 | 2.90 |
| F5TTS | 0.92 | 2.12 | 2.60 | 0.085 | 2.87 | 2.77 | 2.97 |
| GLM-TTS | 0.94 | 1.64 | 3.90 | 0.074 | 3.28 | 1.57 | 2.39 |
| IndexTTS-2 | 0.93 | 1.77 | 2.78 | 0.077 | 3.63 | 3.32 | 2.94 |
| MegaTTS-3 | 0.93 | 2.07 | 3.52 | 0.072 | 3.22 | 2.40 | 3.01 |
| SparkTTS | 0.92 | 2.04 | 3.53 | 0.314 | 2.35 | 2.23 | 2.22 |
| VibeVoice | 0.92 | 2.45 | 3.47 | 0.092 | 3.75 | 3.42 | 3.06 |
| ZipVoice | 0.89 | 2.10 | 3.53 | 0.213 | 2.97 | 2.11 | 2.05 |
| SwanVoice | 0.93 | 2.06 | 3.60 | 0.172 | 3.56 | 3.81 | 3.62 |
The key monologue takeaways are:
- Richness: 3.81, the best reported score.
- Hierarchy: 3.62, the best reported score.
- Content accuracy: weaker than the best baseline; FishSpeech is much lower in content error at 0.066.
- Acoustics: timbre consistency is 0.93, sound fidelity is 3.60, and prosody is 3.56, all competitive but not the absolute best.
Dialogue results
For dialogue, SwanVoice again leads on expressiveness, reaching 3.62 in richness and 3.71 in hierarchy. These are 0.53 and 0.56 points better than the strongest expressive baselines, respectively. The model also maintains competitive acoustic quality and prosodic coherence, though content error is still not the best among the compared systems.
| Model | Timbre | Reverb | Sound Fidelity | Content Error | Prosody | Richness | Hierarchy |
|---|---|---|---|---|---|---|---|
| FireRedTTS-2 | 0.91 | 3.54 | 2.54 | 0.148 | 2.93 | 2.52 | 2.65 |
| MoonCast | 0.90 | 3.29 | 2.60 | 0.284 | 2.93 | 2.42 | 2.54 |
| MOSS-TTSD | 0.89 | 3.52 | 2.83 | 0.227 | 2.57 | 3.04 | 2.86 |
| SoulX-Podcast | 0.92 | 3.23 | 3.98 | 0.101 | 3.89 | 2.80 | 3.15 |
| VibeVoice | 0.89 | 2.09 | 2.75 | 0.204 | 3.00 | 3.09 | 2.83 |
| ZipVoice-Dialog | 0.90 | 3.49 | 2.48 | 0.116 | 3.46 | 2.88 | 2.93 |
| SwanVoice | 0.92 | 3.02 | 3.77 | 0.145 | 3.70 | 3.62 | 3.71 |
The main dialogue conclusions are:
- Richness: 3.62, the best reported score.
- Hierarchy: 3.71, the best reported score.
- Content accuracy: still a limitation; SoulX-Podcast has the lowest reported content error at 0.101, while SwanVoice reports 0.145.
- Acoustics: timbre is 0.92, reverb is 3.02, and sound fidelity is 3.77, which are competitive with the baselines.
Appendix: Swan Forced Aligner
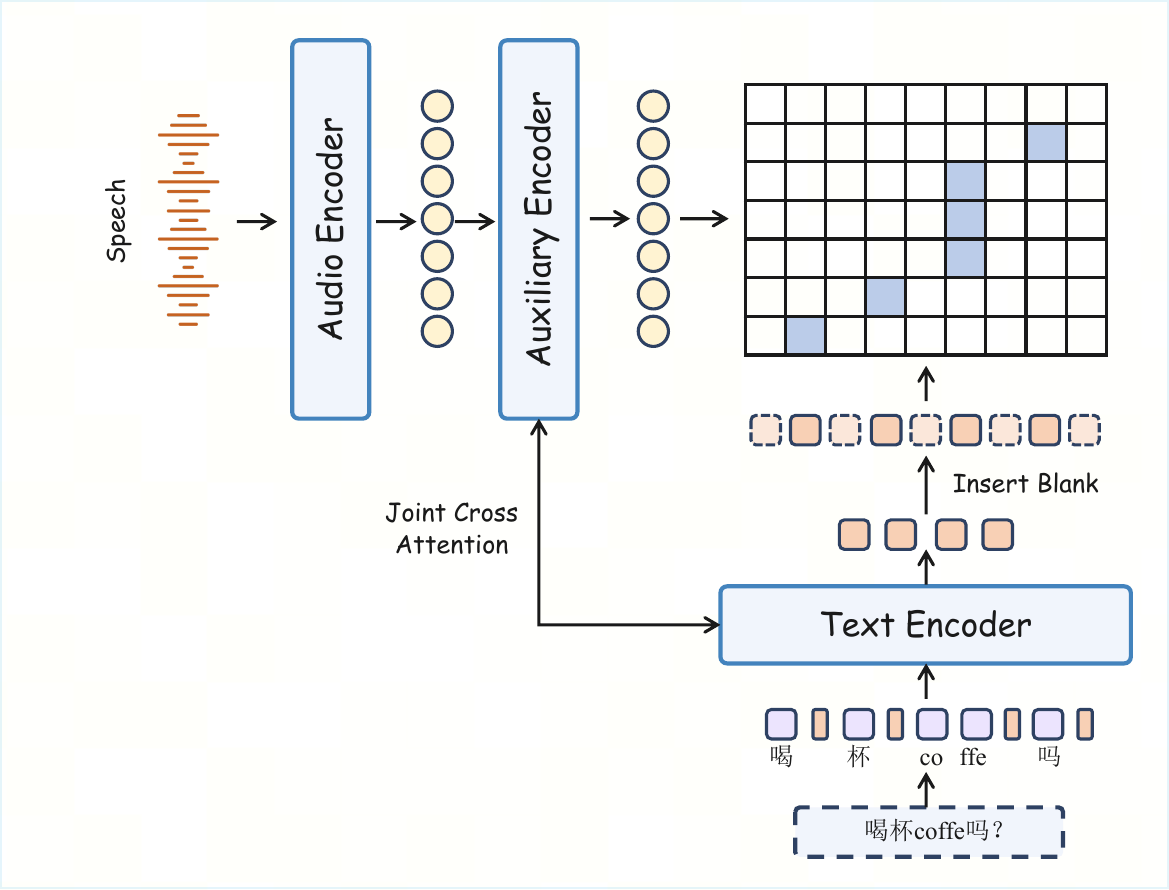
The appendix is not just ancillary: the aligner is a major enabler of SwanData-Speech. The paper’s central argument is that pause-aware alignment is needed because ASR punctuation is optimized for readability, not for acoustic timing. If punctuation and pauses diverge, a downstream TTS model can learn to place pauses inconsistently and lose control over prosody.
Problem setup and tokenization
Swan Forced Aligner takes a waveform $x$ and transcript $y$ and estimates word-level intervals $\{(s_i, e_i)\}_{i=1}^{M}$. The transcript is tokenized into subwords, but the aligner inserts a special anchor token <|wbd|> after each lexical word. This anchor collects the contextualized representation of the entire word span, allowing alignment at the lexical-word level even when a word is split into multiple subword tokens.
Backbone encoders and structured topology
The audio side uses a pretrained acoustic encoder, specifically WavLM, followed by a lightweight Transformer encoder. The text side uses a 16-layer bidirectional Transformer. The model has about 400M parameters. The aligner then operates over an explicit interleaved word--blank topology:
$$ (b_0, w_1, b_1, w_2, \dots, w_M, b_M), $$
where $w_i$ denotes a word state and $b_i$ denotes a blank or gap state. Internal blanks are not represented by a single global prototype; instead, they are conditioned on adjacent words, so the aligner can distinguish short coarticulatory gaps from long pauses and phrase boundaries.
Valid paths are monotonic and use three transition types: stay, adv1, and adv2. These transitions enforce transcript-consistent decoding while still allowing blank skipping where appropriate.
Scoring, calibration, and loss terms
The aligner combines frame-level unary scores and transition scores. The paper emphasizes score canonicalization and separate unary/transition gains because even small numerical differences can change a Viterbi path when scores are poorly calibrated. The final path score is the sum of calibrated unary terms and calibrated transition terms.
The training objective combines four components:
- a frame-level cross-entropy alignment loss;
- a CRF loss over the monotonic lattice;
- duration supervision for both word states and blank states;
- a monotonicity regularizer that discourages decreases in the expected word index over time.
Inference uses Viterbi decoding by default, with an optional posterior-based decoding mode that uses forward--backward state posteriors when local acoustic evidence is ambiguous. Word-level confidence is derived from the average state probability over the aligned span.
Aligner experiments
The forced aligner is trained on the separate 80K-hour Chinese-English alignment subset, which spans audiobooks, podcasts, conversational speech, meetings, and live streams. The training set is pseudo-annotated with Montreal Forced Aligner timestamps. Implementation details include a 4-layer bidirectional auxiliary Transformer, AdamW with learning rate $10^{-5}$, 24 A100 GPUs, and 80K training steps.
Evaluation uses accumulated averaging shift, or AAS, where lower is better. Swan Forced Aligner is compared against Monotonic-Aligner, NeMo Forced Aligner, WhisperX, Qwen3 Forced Aligner, and LattifAI Aligner.
| Aligner | GTSinger-Speech-ZH | LibriSpeech-Clean | LibriSpeech-Others |
|---|---|---|---|
| Monotonic-Aligner | 61.98 | - | - |
| NeMo Forced Aligner | - | 87.05 | 91.85 |
| WhisperX | 221.29 | 87.02 | 96.64 |
| Qwen3 Forced Aligner | 47.31 | 27.84 | 29.74 |
| LattifAI Aligner | 31.60 | 25.70 | 36.00 |
| Swan Forced Aligner | 45.19 | 27.67 | 29.92 |
The reported AAS results support three concrete claims: Swan Forced Aligner is the best open-source aligner on the Chinese and LibriSpeech-Clean benchmarks; it is within 0.18 ms of Qwen3 Forced Aligner on LibriSpeech-Others; and it remains roughly 10 ms behind the proprietary LattifAI system on that same benchmark.
Limitations and takeaways
The paper is explicit that SwanVoice is not solved as a content-accuracy problem. In both monologue and dialogue, the model’s content error is not the best among the compared open-source systems. The authors also note that speaker switching can still fail when the speakers are acoustically close or when the prompt is short. These failure modes point to three future directions: better pronunciation control, stronger alignment and pause modeling, and more robust speaker-turn conditioning.
Despite these limitations, the paper’s main technical contribution is coherent: it treats long-form dialogue as a full-context generation problem, and it supports that decision with a matching data pipeline, a turn-aware zero-shot model, and an aligner that explicitly respects word and pause structure. The result is a system that is consistently stronger on expressive richness and hierarchical variation than the open-source baselines reported in the paper.