TokTalk
TokTalk: Expressive Real-time Facial Animation from Audio-LLM Tokens
TokTalk creates expressive real-time 3D facial animation directly from Audio-LLM token embeddings, reducing latency and capturing nuanced speech cues. Its modular design enables seamless integration with various Audio-LLMs, producing live talking-head avatars with controllable style and synchronized motion.
Links
Paper & demos
Abstract
Recent advances in Audio-LLMs like GPT-4o have ushered in an era of conversational interaction with language models. Conversational avatars however, still seem robotic in facial expression and conversational flow, in part due to sequential stages of speech recognition, text generation, turn-based text response, speech synthesis, and audio driven facial animation. Based on our insight that audio-tokens produced by current Audio-LLMs carry sufficient information to reconstruct a plausible facial performance, we present TokTalk, a system that directly outputs expressive facial animation in real-time from streaming audio-tokens. We construct a novel audio-token to 3D facial motion dataset, on which TokTalk is trained using a Chunk-based Conditional Flow Matching model. A lightweight adaptation strategy allows our trained model to seamlessly connect to any token-based Audio-LLM at minimal computational overhead. Our chunk-based processing further enables parametric trade-off between latency and facial quality, shown through ablation studies. We further show that the real-time performance of TokTalk is comparable in latency to prior art solutions, and significantly favorable (via a perceptual study) in terms of quality, expressivity and control of the 3D facial performance. We showcase TokTalk's flexibility using a chatbot Avatar, a voice-driven user Avatar, and an animation Director's interface, as diverse audio-visual face applications.
Introduction and Problem Setting
TokTalk addresses a specific bottleneck in conversational avatar systems: modern Audio-LLMs can generate speech-like token streams quickly, but the downstream facial animation stage is often still built as a cascaded pipeline that first produces text, then synthesized audio, then waveform-based features, and only then 3D facial motion. The paper argues that this sequential design increases latency and also strips away expressive signals that are important for a believable conversational face, such as hesitant pauses, breaths, laughter, stutters, and emotional tremors.
The central claim is that the intermediate tokens produced by audio-generation systems contain enough information to drive a plausible facial performance directly. Rather than relying on ASR-oriented encoders like wav2vec 2.0 or HuBERT, which were optimized to align speech with text, TokTalk consumes the token embeddings of Audio-LLMs and maps them directly to 3D facial motion. This makes animation generation parallel with audio generation instead of strictly following it.

The design goal is not only lower latency, but also expressiveness and controllability. The paper explicitly positions TokTalk against three broad prior categories: procedural systems that can be editable but often need transcript and phonetic context; low-latency deterministic systems that are fast but less expressive; and diffusion-based systems that are expressive but usually too slow for real-time use. TokTalk’s proposed middle ground is a flow-matching model that is both streamable and style-conditioned.
Core Idea and System Overview
TokTalk is organized as a lightweight plug-in that sits alongside the Audio-LLM audio decoder. It takes the token embeddings that the Audio-LLM is already using and predicts FLAME facial parameters in parallel. The architecture is intentionally modular so that it can connect to different Audio-LLM backends without retraining the full motion model.
The paper’s high-level latency argument is simple. In a traditional cascaded avatar pipeline, first-frame latency is modeled as $$ \text{Latency} = \text{TTFTB} + T_{\text{audio}} + T_{\text{animation}}, $$ where TTFTB is the time to first token batch. In TokTalk, audio decoding and animation generation happen in parallel, so the first-frame latency becomes $$ \text{Latency} = \text{TTFTB} + \max(T_{\text{audio}}, T_{\text{animation}}). $$ As long as animation generation is not slower than audio synthesis, TokTalk can effectively “hide” the facial generation cost behind the audio decoder.
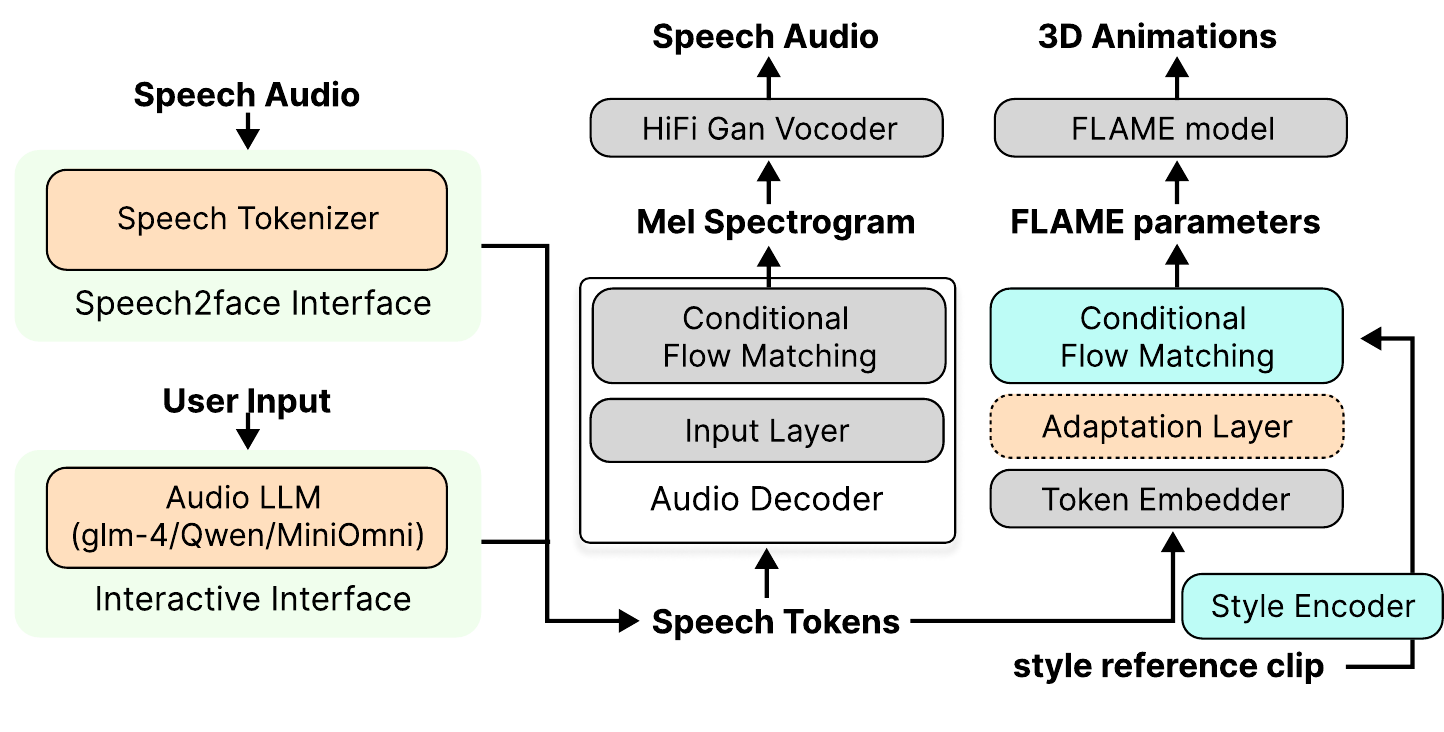

The pipeline has two important properties. First, it can operate directly on Audio-LLM token embeddings. Second, it can also be used in a conventional recording-to-animation setting by first tokenizing recorded audio with a speech tokenizer and then running the same token-based animation model. This makes the system relevant both for Audio-LLM avatars and for ordinary audio-driven facial animation.
Related Work Context
The paper frames TokTalk as a response to two gaps in prior work. On the one hand, classical speech-to-face methods are typically built around waveform-derived or ASR-oriented representations, which are good at phonetic alignment but weak on paralinguistic motion. On the other hand, recent high-quality diffusion models can capture expressive motion and style, but their iterative sampling makes them too slow for real-time use.
The related-work discussion also emphasizes a more recent family of real-time systems that reduce latency by distilling or compressing models, such as few-step diffusion or jointly distilled encoders and decoders. Those systems improve speed, but the paper argues that they often trade away quality, introduce jitter, or reduce controllability. TokTalk instead shifts the generation point “upstream” into the token space shared with Audio-LLMs, which lets it avoid extra waveform-processing latency without relying on aggressive distillation.
A second background trend is the move from continuous speech features to discrete speech tokenization in TTS and audio LLMs. The paper cites token-based systems built with VQ or RVQ, and notes that modern audio LLMs already use discrete token streams to unify speech generation and language modeling. TokTalk extends that paradigm by adding a token-to-animation decoder so the same intermediate representation can drive both speech and facial motion.
Method
Pipeline architecture
The animation model consumes a sequence of audio embeddings $e = \{e_i\}_{i=1}^{T}$, where each $e_i \in \mathbb{R}^{d_{\text{audio}}}$, and produces a sequence of FLAME parameters $X_{1:T}$ representing expression, jaw, and neck-pose coefficients. The decoder is designed to be causal and chunk-wise so it can operate on streaming input. TokTalk uses a conditional flow matching model to learn a time-dependent vector field that transforms noise into a facial-motion sequence, conditioned on the audio embeddings and an optional style reference.
The paper’s motion representation is based on FLAME, which decodes the predicted coefficients into 3D vertex animation. A separate style encoder extracts a style embedding $s$ from a reference motion clip, allowing the system to reproduce not just lip motion but the characteristic motion style of a given performance.
A key architectural component is the adaptation layer. Different Audio-LLMs use different tokenization schemes and token embedding spaces, so TokTalk inserts a lightweight mapping module that projects tokens from a target system into the embedding space expected by the pretrained motion decoder. The paper describes this as a shallow transformer trained after the base decoder has been frozen. This avoids retraining the full motion model whenever the Audio-LLM backend changes.
Conditional flow matching formulation
TokTalk trains a conditional flow matching model $\mathcal{G}$ to map from a standard normal base distribution to the target FLAME motion distribution. Given a target motion sequence $X_1 \in \mathbb{R}^{T \times d_{\text{FLAME}}}$ and noise $X_0 \sim \mathcal{N}(0, I)$, the method uses a linear interpolation path $$ X_t = (1-t)X_0 + tX_1, \quad t \in [0,1]. $$ The target vector field along this path is $$ u_t(X \mid X_1) = \frac{dX_t}{dt} = X_1 - X_0. $$ The model is trained with the objective $$ \mathcal{L}_{\text{CFM}}(\theta) = \mathbb{E}_{t, p(X_1), p(X_0)}\left\|v_\theta(X_t, t, e, s) - (X_1 - X_0)\right\|^2, $$ where $v_\theta$ is the learned velocity field. At inference time, facial motion is generated by numerically solving the ODE $$ \frac{dX_t}{dt} = v_\theta(X_t, t, e, s), \quad X_0 \sim \mathcal{N}(0, I), $$ using an Euler solver.
The paper states that the decoder uses a causal chunk-wise design with block-causal attention. This matters for real-time operation because each chunk can be generated as audio arrives, and overlapping regions are handled through temporal inpainting to maintain continuity across chunk boundaries.
Style conditioning
Style conditioning is integrated directly into the flow model. A jointly trained style encoder $\mathcal{E}$, following the MSMD design, produces a style embedding $s = \mathcal{E}(X_{\text{ref}})$ from a reference clip $X_{ ref}$. The model then generates motion as $\hat{X}_{1:T} = \mathcal{G}(\{e_i\}_{i=1}^{T}, s)$. The empirical effect of this conditioning is one of the main ablations in the paper: style conditioning substantially improves motion metrics and is also preferred in the user study.
Training strategy
Training is done in two stages. In stage one, the base flow matching model is trained on token embeddings generated by the base Audio-LLM tokenizer and decoder. During this stage the adaptation layer is skipped, so the model learns an end-to-end mapping for one specific token space. Conditioning signals are randomly dropped during training to support classifier-free guidance.
In stage two, the base decoder is frozen and only the adaptation layer is trained for a new Audio-LLM backend. For each target backend, embeddings $\{\tilde{e}_i\}_{i=1}^{\tilde{T}}$ are extracted and temporally interpolated to match the sampling rate of the base tokenizer. The adaptation objective combines flow matching with an embedding-alignment loss: $$ \mathcal{L}_{\text{adapt}} = \mathcal{L}_{\text{CFM}} + \lambda \mathcal{L}_{\text{align}}, $$ with $\lambda = 0.5$ and $$ \mathcal{L}_{\text{align}} = \left\|\mathcal{D}(\{\tilde{e}_i\}_{i=1}^{\tilde{T}}) - \{e_i\}_{i=1}^{T}\right\|^2. $$ Here $\mathcal{D}$ is the adaptation layer.
Inference details
During streaming inference, tokens arrive in chunks of duration $C$ seconds. The adaptation layer maps incoming embeddings into the base input space when needed. The motion model then generates FLAME parameters causally, chunk by chunk, with overlap-conditioned temporal inpainting. The overlap region from the previous chunk is treated as known and preserved, while the new region is initialized from noise and updated by the velocity field.
TokTalk also uses classifier-free guidance during inference: $$ v_\theta^{\text{cfg}}(X_t, t, e, s) = (1 + w) v_\theta(X_t, t, e, s) - w\, v_\theta(X_t, t, \varnothing, \varnothing), $$ where $w$ is the guidance weight. The paper uses this to balance fidelity and controllability.
Applications
The paper demonstrates three use cases. First, an audio-LLM-driven chatbot avatar, where facial animation runs in parallel with speech generation and does not add extra latency beyond the Audio-LLM itself. Second, a voice-driven user avatar, in which a live user’s speech is tokenized on the fly and used to animate an embodied avatar. Third, an animation director interface, where text prompts or audio instructions steer the emotional tone and speech cadence of the audio-LLM while the visual style is guided by a reference clip.
These applications are used to argue that the system is not just a research model for lipsync, but a modular face-generation layer for interactive audiovisual interfaces. The director-style interface is especially notable because it separates control over voice delivery and visual style while keeping the two synchronized.
Experimental Setup
The paper evaluates TokTalk along three axes: whether Audio-LLM token embeddings are better conditioning signals than ASR-oriented speech features; whether TokTalk is competitive on facial-animation quality; and whether the system is suitable for real-time use with controllable quality-latency trade-offs.
The authors evaluate with four metrics. Mean square error (MSE) and lip vertex error (LVE) measure reconstruction and lip-sync accuracy. Facial dynamic difference (FDD) and mouth opening distance (MOD) measure adherence to reference motion style. Lower values are better for all four metrics.
Dataset
The motion model is trained and evaluated on the same corpus used by DiffPoseTalk: HDTF combined with TFHP. The resulting dataset contains 1,052 videos from 588 subjects, with approximately 26.5 hours of footage at 25 fps. The split is by speaker: 460 training subjects, 64 validation subjects, and 64 test subjects.
For the representation analysis on emotional speech, the paper uses RAVDESS, where emotional variation is pronounced. That study isolates the effect of audio representation on expressive facial animation.
Implementation details
The flow-matching decoder is a 1D U-Net-style Transformer adapted from CosyVoice’s conditional decoder. It uses two downsampling blocks, two upsampling blocks, and 12 middle blocks; each stage contains 4 Transformer blocks with 8 attention heads. The adaptation layer projects source embeddings with a 1D convolution, adds positional embeddings, and processes the sequence with a 4-layer Transformer encoder.
Training is performed on a single NVIDIA L40S GPU using Adam with learning rate $10^{-4}$. The base model is trained for 144 hours with the conditional flow-matching objective. The adaptation layer is then trained for 24 hours while the base model remains frozen. The inference-time guidance weight is set to $w = 0.3$.
The base tokenizer is Mimi, and the system is adapted to CosyVoice2 and GLM-4-Voice token embeddings. The paper notes that these choices are relevant because Mimi underlies systems such as Qwen3-Omni and Moshi, while CosyVoice2 is used by Mini-Omni-2 and LLaMA-Omni. The key point is that the adaptation layer lets TokTalk swap audio backends without retraining the motion decoder.
Audio Representation Analysis
The first experiment tests the paper’s core hypothesis: do Audio-LLM tokens carry richer information for facial animation than ASR-oriented features? On RAVDESS, the authors compare token embeddings from GLM-4-Voice, CosyVoice2, and Moshi against wav2vec 2.0, HuBERT, and Whisper, and also include EmoTalk as an emotion-tagged baseline.
The results show that Audio-LLM token embeddings are competitive with ASR-based representations and sometimes outperform them on reconstruction and mouth-related metrics. CosyVoice2 performs best on MSE, LVE, and MOD among the compared representations. Wav2vec 2.0 obtains the best FDD, indicating that ASR-style features can still capture some temporal dynamics well. However, the overall picture supports the paper’s claim that speech-generation tokens preserve useful phonetic, acoustic, and prosodic information. All TokTalk variants also outperform EmoTalk on the reported errors, despite not requiring explicit emotion or intensity labels.
| Model | MSE (mm) ↓ | LVE (mm) ↓ | FDD ($\times 10^{-5}$ m) ↓ | MOD (mm) ↓ |
|---|---|---|---|---|
| ASR based | ||||
| Wav2vec2 | 0.26 | 2.15 | 2.63 | 1.51 |
| HuBERT | 0.27 | 2.26 | 3.03 | 1.65 |
| Whisper | 0.25 | 2.07 | 2.79 | 1.41 |
| Audio LLM based | ||||
| GLM-4-Voice | 0.23 | 1.87 | 3.11 | 1.42 |
| CosyVoice2 | 0.22 | 1.84 | 2.99 | 1.35 |
| Moshi | 0.24 | 2.03 | 2.90 | 1.40 |
| Other baseline | ||||
| EmoTalk | 0.35 | 3.11 | 4.33 | 1.65 |
Generation Quality and Comparisons
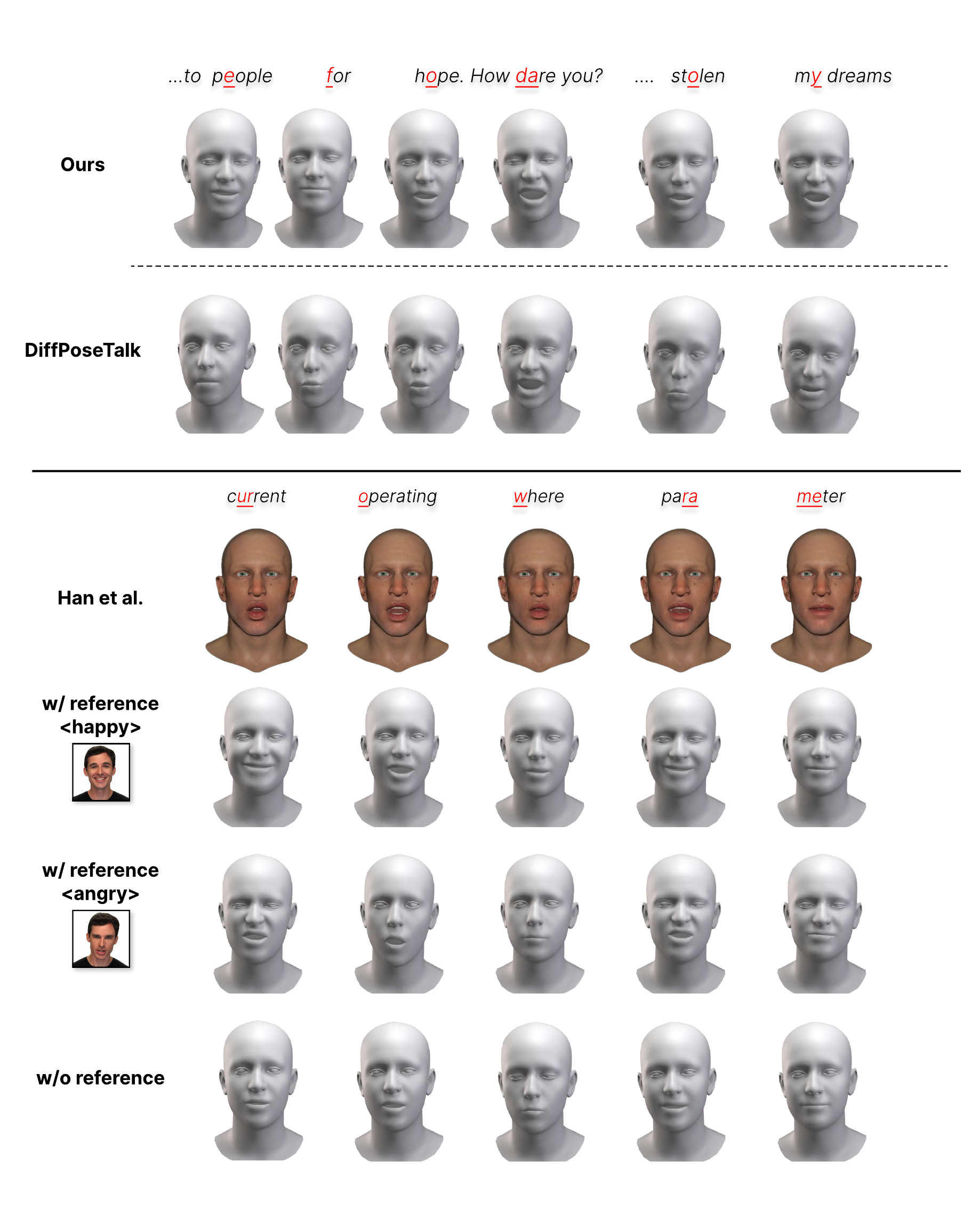
The main quantitative comparison is against DiffPoseTalk, MSMD, and FaceFormer. MSMD and FaceFormer are retrained on the same HDTF+TFHP split used by TokTalk. DiffPoseTalk uses the official implementation and weights. Importantly, TokTalk is evaluated in a real-time streaming setting, whereas DiffPoseTalk is an offline non-real-time model, so the comparison is intentionally strict in terms of deployment constraints.
The paper reports that TokTalk with style conditioning substantially outperforms the version without style conditioning, confirming that the reference clip contributes useful motion information beyond the audio content itself. The adaptation variants using CosyVoice2 and GLM-4-Voice remain close to the base model, showing that the adaptation layer transfers across token spaces with only minor degradation.
| Model | MSE (mm) ↓ | LVE (mm) ↓ | FDD ($\times 10^{-5}$ m) ↓ | MOD (mm) ↓ |
|---|---|---|---|---|
| TokTalk w/o style | 2.11 | 20.73 | 4.45 | 3.15 |
| TokTalk w/ style | 1.39 | 14.53 | 4.29 | 2.82 |
| Adaptation layers | ||||
| CosyVoice2 | 1.37 | 14.26 | 4.34 | 2.94 |
| GLM-4-Voice | 1.35 | 14.02 | 4.44 | 2.96 |
| Prior methods | ||||
| DiffPoseTalk | 1.33 | 13.64 | 4.33 | 2.68 |
| MSMD | 1.54 | 16.07 | 11.19 | 2.65 |
| FaceFormer | 2.50 | 24.02 | 5.19 | 3.77 |
The paper’s interpretation is nuanced. TokTalk is not the best method on every metric, but it is competitive with DiffPoseTalk while being real-time and style-controllable. In particular, the authors emphasize that TokTalk achieves comparable MSE, LVE, and MOD and slightly better FDD under streaming conditions, which they view as evidence that token-conditioned flow matching can preserve much of the motion fidelity of offline diffusion while enabling low-latency generation.
Perceptual study
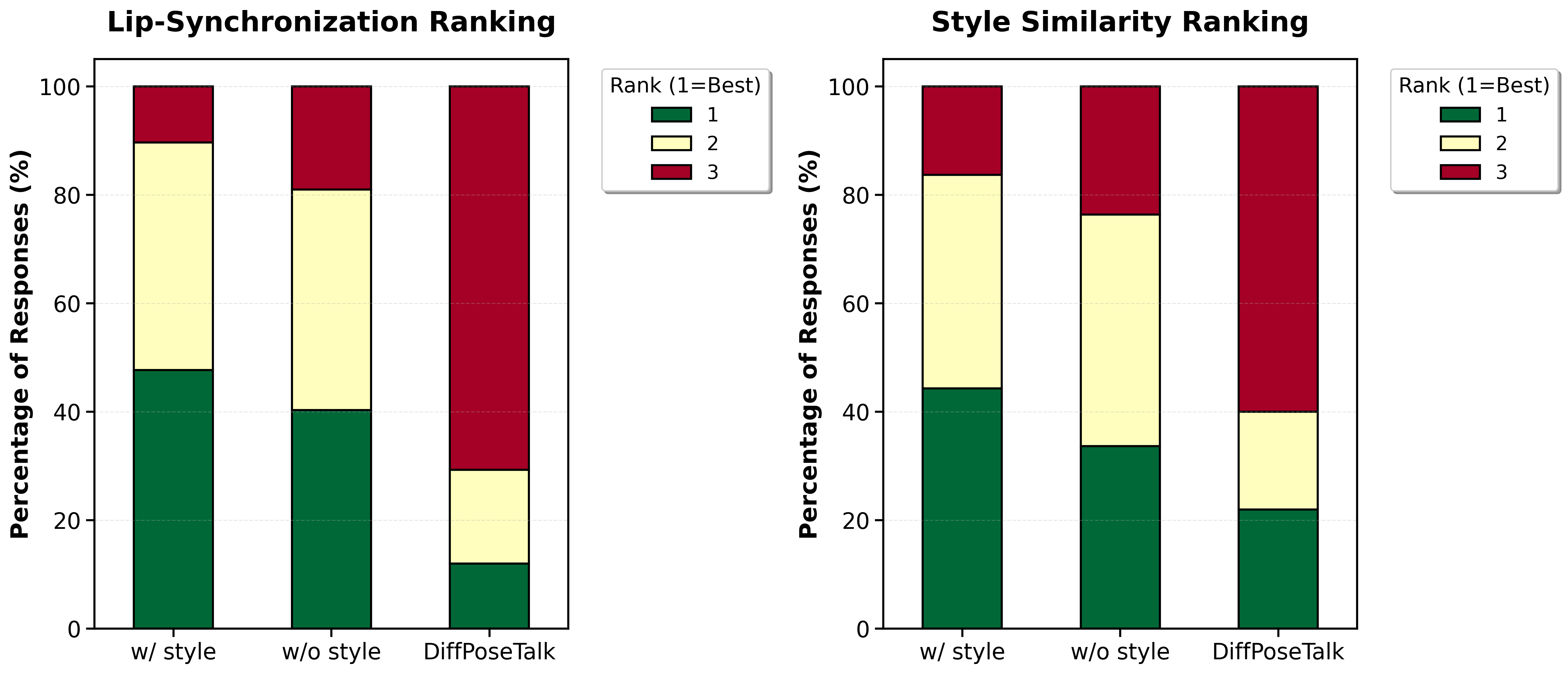
To complement the quantitative results, the authors ran a user study with 15 expressive videos selected from the test set and from iconic YouTube performances. Twenty participants ranked three generated outputs for each video: TokTalk with style conditioning, TokTalk without style, and DiffPoseTalk. The rankings were evaluated for lip synchronization and style similarity to the ground truth. Each metric involved 300 total comparisons.
The perceptual results strongly favor TokTalk. For lip synchronization, the style-conditioned TokTalk variant achieves the best mean rank and significantly outperforms both the unconditioned variant and DiffPoseTalk; the Friedman test reports $\chi^2 = 158.72$ with $p < 10^{-34}$. For style similarity, TokTalk again ranks best with mean rank 1.72, significantly outperforming TokTalk without style (1.90, $p < 0.01$) and DiffPoseTalk (2.38, $p < 10^{-12}$), with Friedman statistics $\chi^2 = 69.84$ and $p < 10^{-15}$.
Runtime and Latency
Runtime is a major part of the paper’s claim. TokTalk is designed so that its facial animation stage does not add latency when the animation decoder is fast enough to keep up with the audio decoder. The paper uses TTFTB $= 200$ ms and $T_{\text{audio}} = 200$ ms as representative values based on prior Audio-LLM systems. Under these assumptions, TokTalk’s overall latency remains 400 ms because animation and audio generation run in parallel.
The paper compares TokTalk to TinySig and the method from Lee et al. as real-time baselines, and to DiffPoseTalk as a non-real-time reference. The reported animation time for TokTalk spans 26--187 ms depending on the number of flow-matching steps, but because these values stay below the assumed audio-decoder time, the total latency stays constant at 400 ms.
| Method | TTFTB (ms) | $T_{\text{audio}}$ (ms) | $T_{\text{animation}}$ (ms) | Total latency (ms) |
|---|---|---|---|---|
| TinySig | 200 | 200 | 1.4 | 401.4 |
| Lee et al. | 200 | 200 | 10 | 410 |
| DiffPoseTalk | 200 | 200 | 3326 | 3726 |
| TokTalk | 200 | 200 | 26--187 | 400 |
The authors stress that TokTalk’s speed advantage comes from parallelism rather than from minimizing the quality of the motion model. This is a meaningful distinction from heavily distilled real-time systems, which can be fast but may lose expressiveness or introduce jitter. TokTalk instead spends more compute on motion quality while still hiding the animation cost behind the audio decoder.
Runtime-Quality Trade-off and Ablations
TokTalk uses chunk size $C$ and flow-matching steps $n$ as explicit knobs for balancing quality and speed. Larger chunks reduce the frequency of chunk boundaries and improve continuity, while more flow steps improve numerical accuracy at the cost of longer animation generation time. The paper measures both MSE and a jitter score defined as average per-frame acceleration near chunk boundaries.
Across the ablation grid, increasing $C$ and $n$ generally improves both MSE and jitter, with the largest gains appearing in jitter. This supports the authors’ claim that the chunked formulation is flexible enough to support different deployment regimes. The chosen real-time setting, $C = 0.4$ s and $n = 20$, is intended to ensure that $T_{\text{animation}} \leq T_{\text{audio}}$ while keeping first-token delay low. The paper also notes that adaptation adds only about 20 ms of overhead.
| Steps ($n$) | $T_{\text{animation}}$ (ms) | $C = 0.4$ s | $C = 0.8$ s | $C = 1.2$ s | |||
|---|---|---|---|---|---|---|---|
| MSE ↓ | Jitter ↓ | MSE ↓ | Jitter ↓ | MSE ↓ | Jitter ↓ | ||
| 1 | 26 | 1.61 | 0.232 | 1.58 | 0.246 | 1.57 | 0.239 |
| 5 | 60 | 1.57 | 0.223 | 1.55 | 0.204 | 1.54 | 0.171 |
| 10 | 101 | 1.56 | 0.201 | 1.54 | 0.184 | 1.53 | 0.151 |
| 20 | 187 | 1.57 | 0.178 | 1.53 | 0.161 | 1.52 | 0.140 |
A notable observation is that improving smoothness is more sensitive to these settings than raw reconstruction error. The paper interprets this as evidence that maintaining continuity across chunk boundaries is the main challenge in chunked generative animation, and that fewer steps can reintroduce jitter, similar to what is observed in few-step diffusion systems.
Limitations
The authors are explicit about TokTalk’s remaining latency constraints. Even though the facial model runs in parallel with audio synthesis, speech-driven use still requires a minimum chunk size of 400 ms, which is higher than the lookahead of some autoregressive alternatives such as TinySig’s 265 ms. Audio tokenizer constraints also matter: for example, CosyVoice requires at least five tokens, corresponding to about 200 ms of audio.
Another limitation is that fewer flow-matching steps cause more jitter. The paper shows that using 20 steps reduces artifacts substantially, but if future audio decoders become faster, TokTalk may need to reduce the number of steps to keep animation generation from becoming the bottleneck. That would create a direct quality-latency trade-off.
The discussion section also notes broader interaction limitations that TokTalk does not solve. Real conversational systems still need turn-taking detection, listening behaviors, and additional non-verbal cues such as head nods, shakes, and eye gaze. These are identified as future directions rather than current capabilities.
Takeaways
The main technical takeaway is that Audio-LLM token embeddings are rich enough to drive a believable and expressive 3D facial performance, and that a chunked conditional flow-matching decoder can exploit this representation in real time. TokTalk’s plug-in design makes it compatible with multiple Audio-LLMs through a lightweight adaptation layer, while style conditioning provides explicit control over facial delivery.
In the paper’s framing, this is a shift from cascaded speech-to-face generation to a parallel token-to-face system. The practical implication is that conversational avatars can gain more expressive, better synchronized facial motion without paying a separate animation-latency penalty, so long as the animation decoder is fast enough to remain under the audio synthesis time.