DOA
DOA: Training-Free Decoder-Only Attention Policy for Long-Form Simultaneous Translation with SpeechLLMs
DOA is a training-free policy that uses decoder self-attention as a proxy alignment for streaming long-form simultaneous speech translation. It enables low-latency, high-quality translation with off-the-shelf SpeechLLMs without retraining, by guiding read/write decisions from self-attention signals.
Demos
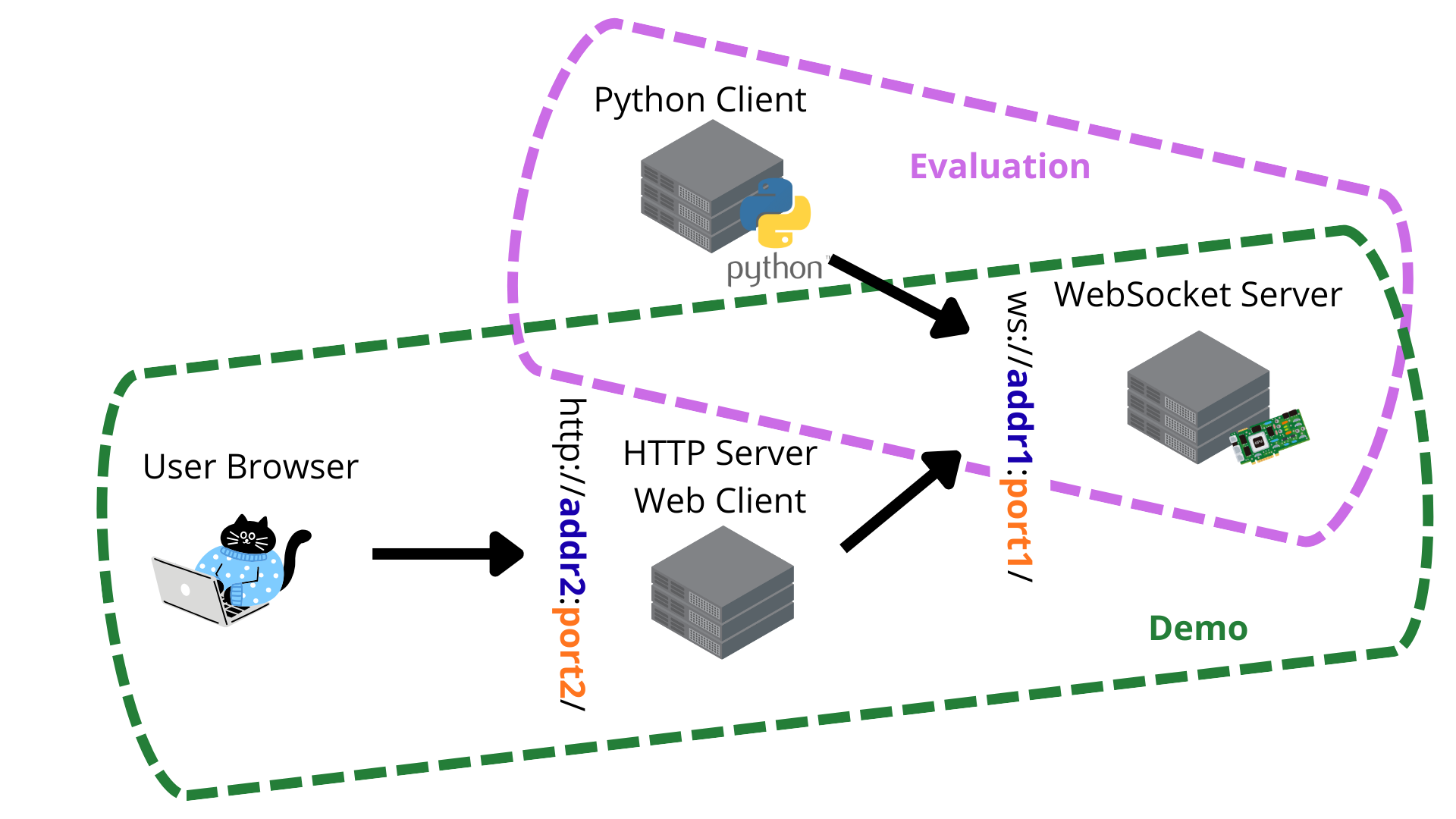
The simulstream demos showcase a Python library for simultaneous streaming speech recognition and translation using a WebSocket client-server architecture. They highlight real-time transcription and translation from continuous audio streams, focusing on latency, translation quality, and ease of integrating custom speech processors. Evaluation should watch for responsiveness and translation accuracy over long, unsegmented speech input.
Links
Paper & demos
Code & resources
Abstract
Simultaneous speech-to-text translation (SimulST) generates translations while speech is still unfolding, requiring a streaming policy that decides when to read and when to write. State-of-the-art approaches rely on attention-based encoder-decoder models where cross-attention provides explicit alignment signals. In contrast, Speech Large Language Models (SpeechLLMs) are decoder-only architectures relying solely on self-attention. This raises a central question: whether decoder self-attention contains sufficiently stable alignment signals to guide the streaming policy. Moreover, existing approaches typically rely on training-based adaptations or heuristic wait-$k$ policies and have not been validated in long-form settings. To fill these gaps, we propose Decoder-Only Attention (DOA), a training-free policy that enables long-form simultaneous translation with off-the-shelf SpeechLLMs by deriving a proxy alignment from self-attention. Experiments on Phi4-Multimodal and Qwen3-Omni show that DOA provides an effective alignment signal for supporting streaming decisions, enabling low-latency long-form SimulST with quality close to offline decoding without retraining.
Introduction
Simultaneous speech-to-text translation (SimulST) must produce translations while the source speech is still unfolding. That setting forces a streaming policy to balance two competing objectives: low latency and high translation quality. In classical attention-based encoder-decoder systems, the policy can exploit cross-attention as an explicit alignment signal. This paper asks whether the same idea can be transferred to modern Speech Large Language Models (SpeechLLMs), which are decoder-only architectures and therefore do not expose cross-attention.
The central research question is whether decoder self-attention in SpeechLLMs is stable enough to serve as a proxy alignment signal for streaming decisions. The paper focuses on the long-form setting, where audio streams can last several minutes and the model must manage growing acoustic and textual context over time. The authors argue that prior work has mostly relied on either training-based streaming adaptations or heuristic wait-$k$ policies, and that long-form simultaneous translation with off-the-shelf SpeechLLMs has not been properly validated.
To address this gap, the paper proposes Decoder-Only Attention (DOA), a training-free policy that repurposes decoder self-attention as a proxy cross-attention matrix. The key claim is that this proxy alignment is sufficiently stable to support read/write decisions for long-form SimulST without retraining the underlying SpeechLLM. The paper validates the idea on two open-weight models, Phi4-Multimodal and Qwen3-Omni, for English-to-German and English-to-Italian translation.
The main technical and empirical contributions are:
- a proxy alignment mechanism derived from decoder self-attention;
- a simultaneous decoding policy that uses the proxy alignment to decide which tokens are safe to emit;
- an incremental long-form inference scheme that prunes both textual and acoustic history to keep context bounded;
- an empirical study showing that punctuation-based textual history is stronger than fixed-word history for decoder-only SpeechLLMs;
- layer- and head-wise analyses showing that averaging attention across layers and heads is the most robust choice;
- benchmark results demonstrating low-latency long-form SimulST with quality close to offline decoding, without task-specific retraining.
Method: Decoder-Only Attention (DOA)
From self-attention to proxy cross-attention
DOA is designed for decoder-only SpeechLLMs that encode speech and text in a single autoregressive sequence. During generation, the model produces self-attention weights from each decoder layer $l$ and head $h$. If the sequence contains $S$ audio tokens followed by $T$ generated text tokens, the self-attention matrix is written as:
$$A^{(l,h)} \in \mathbb{R}^{T \times (S + T)}$$
Because the audio tokens occupy the prefix of the sequence, the method isolates the columns corresponding to the acoustic context:
$$\tilde{A}^{(l,h)} = A^{(l,h)}[:, :S]$$
This yields a proxy cross-attention matrix
$$\tilde{A} \in \mathbb{R}^{T \times S}$$
that plays the same role as cross-attention in encoder-decoder systems. The paper also allows attention to be taken from a single layer and head or averaged across selected layers and heads:
$$\bar{A} = \frac{1}{|\mathcal{L}|\,|\mathcal{H}|} \sum_{l \in \mathcal{L}} \sum_{h \in \mathcal{H}} \tilde{A}^{(l,h)}$$
For each generated token, the policy aligns that token to the audio position receiving maximum attention:
$$a_t = \arg\max_s \bar{A}_{t,s}$$
The resulting alignment sequence is the only signal needed for the streaming policy. In other words, DOA does not learn a separate alignment model; it extracts a proxy alignment directly from the decoder's own attention patterns.
Read/write decision rule
DOA introduces a cutoff hyperparameter $f$ that marks the number of most recent audio frames considered acoustically unstable. Tokens aligned to positions inside the last $f$ frames are treated as too fragile to commit, because later speech may revise their interpretation. The emission rule is therefore:
$$a_t < S - f$$
where $S$ is the current number of available audio frames. Larger values of $f$ make the policy more conservative, increasing latency but reducing the risk of premature output. Smaller values reduce latency but allow more aggressive emission.
Conceptually, the policy operates as a read/write controller: it reads incoming speech chunks, computes proxy alignments over the current acoustic and textual context, and writes only those tokens whose aligned audio evidence is sufficiently far from the unstable tail of the stream.
Long-form adaptation and bounded context
The paper's long-form extension is important because the goal is not just streaming on short utterances, but continuous translation of long audio streams. DOA therefore maintains two rolling histories:
- Audio history: the accumulated speech chunks seen so far;
- Textual history: the previously generated translation, used as a prefix for the next decoding step.
To prevent unbounded growth, the paper evaluates two textual history selection strategies:
- Fixed words: keep the last $N$ generated words or characters;
- Punctuation: keep only the segment after the most recent strong punctuation mark.
Audio pruning is then guided by the proxy alignment. The policy discards consecutive audio frames that are aligned exclusively with the discarded textual history, while preserving frames aligned with the retained textual prefix and the newly generated hypothesis. If this pruning fails to reduce the audio history enough and the context exceeds a maximum duration, the oldest frames are truncated as a fallback.
This makes the method model-agnostic in the practical sense used by the paper: it only requires access to decoder self-attention weights, so it can be applied to any SpeechLLM with that capability.
Illustration of the layer/head analysis


Experimental setup
The paper follows IWSLT-style simultaneous translation evaluation settings. It uses MCIF as the test set for English-to-German and English-to-Italian, and ACL 60/60 English-to-German as a development set for hyperparameter selection and analysis. Inference is run with the SimulStream toolkit, and OmniST-Eval is used to compute the long-form latency metrics LongYAAL and LongLAAL. Translation quality is measured with BLEU and COMET.
The evaluated models are open-weight SpeechLLMs selected for language support and suitability for English-to-German and English-to-Italian translation:
| Model | Parameters | Role in the paper | HuggingFace version used |
|---|---|---|---|
| Phi4-Multimodal | 5.6B | Primary model for hyperparameter selection and analysis; also evaluated in final results | 4.48.2 |
| Qwen3-Omni | 30B | Used to validate model-agnosticity in the final results | 5.0.0 |
| SeamlessM4T | 1B | Attention-based encoder-decoder baseline with StreamAtt | 4.48.2 |
The inference configuration is also carefully specified. Speech is processed in 1-second chunks, matching the SimulStream default. For Phi4-Multimodal, the cutoff $f$ is swept over $\{5, 10, 15, 20, 25\}$ during parameter selection. For final comparisons, both Phi4-Multimodal and Qwen3-Omni are evaluated with $f \in \{5, 15, 25\}$, which the paper treats as low-, medium-, and high-latency regimes. The StreamAtt baseline on SeamlessM4T uses the default SimulStream settings with $f \in \{4, 8, 12\}$.
The remaining inference constraints are: maximum audio length of 120 seconds for Phi4-Multimodal and SeamlessM4T, and 90 seconds for Qwen3-Omni; maximum new tokens per decoding step of 32; and maximum textual history length of 128 tokens. The paper also notes that prompts differ by model: a simpler instruction is used for Phi4-Multimodal because more complex prompts degraded performance, while Qwen3-Omni uses a more detailed translator-style prompt.
Experiments run on a mixed GPU environment with NVIDIA A40 40GB and NVIDIA L40S 48GB, using a single GPU at a time. The paper reports average run times of approximately 1–2 hours for SeamlessM4T, 4–5 hours for Phi4-Multimodal, and 25–26 hours for Qwen3-Omni.
Results and analysis
Textual history selection: punctuation versus fixed words
The first ablation compares the two textual history strategies on Phi4-Multimodal using proxy cross-attention averaged across layers and heads. The main conclusion is that punctuation-based history selection is more stable and generally yields the best or near-best quality across all latency regimes, while remaining comparable in latency to the fixed-word strategy. This is notable because it reverses a trend observed in some encoder-decoder streaming work, where fixed words often outperform punctuation-based history.
The paper's interpretation is that decoder-only SpeechLLMs benefit from sentence-level textual continuity. Preserving the text after the most recent strong punctuation mark appears to produce a more coherent autoregressive context than keeping a fixed number of words.
| Method | $f$ or $N$ | BLEU | COMET | LongYAAL | LongLAAL | empty% |
|---|---|---|---|---|---|---|
| punctuation | 5 | 30.12 | 0.7317 | 1511 | 1599 | 0.43% |
| punctuation | 10 | 32.23 | 0.7476 | 1976 | 2150 | 0.21% |
| punctuation | 15 | 32.80 | 0.7552 | 2389 | 2487 | 0.43% |
| punctuation | 20 | 33.98 | 0.7593 | 2835 | 2947 | 0.43% |
| punctuation | 25 | 34.70 | 0.7673 | 3219 | 3460 | 0.21% |
| fixed words ($N=10$) | 5 | 29.02 | 0.7193 | 1476 | 1560 | 0.00% |
| fixed words ($N=10$) | 10 | 31.29 | 0.7362 | 1957 | 2050 | 0.00% |
| fixed words ($N=10$) | 15 | 32.95 | 0.7525 | 2374 | 2471 | 0.00% |
| fixed words ($N=10$) | 20 | 33.74 | 0.7537 | 2790 | 2891 | 0.00% |
| fixed words ($N=10$) | 25 | 33.97 | 0.7550 | 3178 | 3305 | 0.43% |
| fixed words ($N=20$) | 5 | 29.37 | 0.7339 | 1476 | 1619 | 0.21% |
| fixed words ($N=20$) | 10 | 27.01 | 0.7274 | 1980 | 3825 | 0.21% |
| fixed words ($N=20$) | 15 | 31.13 | 0.7519 | 2383 | 2927 | 0.00% |
| fixed words ($N=20$) | 20 | 30.30 | 0.7375 | 2748 | 3511 | 0.21% |
| fixed words ($N=20$) | 25 | 34.36 | 0.7708 | 3175 | 3317 | 0.43% |
| fixed words ($N=30$) | 5 | 16.74 | 0.7119 | 1516 | 7791 | 0.21% |
| fixed words ($N=30$) | 10 | 32.95 | 0.7487 | 1966 | 2049 | 0.43% |
| fixed words ($N=30$) | 15 | 33.74 | 0.7590 | 2379 | 2476 | 0.43% |
| fixed words ($N=30$) | 20 | 34.08 | 0.7640 | 2797 | 2897 | 0.43% |
| fixed words ($N=30$) | 25 | 34.57 | 0.7691 | 3200 | 3312 | 0.21% |
Several details are worth noting. First, punctuation gives a smoother latency-quality trade-off across the full range. Second, fixed words can occasionally look competitive on one metric while becoming unstable on another; for example, some configurations produce unusually large LongLAAL values, which suggests that fixed windows can interact poorly with the decoder-only setup. Third, punctuation remains the paper's preferred choice for the remainder of the experiments.
Layer-wise and head-wise behavior
The second ablation studies how the proxy alignment behaves when attention is taken from specific layers or heads instead of averaging across them. The paper's conclusion is that averaging across layers and heads is the best and easiest option. Layer-wise behavior is substantially more unstable than head-wise behavior: six layers lead to complete failure, with latency degradation close to or exceeding 1 second relative to the average. No layer improves both latency and quality compared with averaging. By contrast, a few heads show small improvements in both metrics, with heads 2 and 10 highlighted in the paper, but the gains are minimal. As a result, the paper uses the layer-and-head average for final results.
This finding is important because it differs from some earlier attention-based encoder-decoder studies, where selecting a specific layer could outperform averaging. In DOA, the self-attention signal appears more fragile across layers, so the robust default is to average broadly rather than to search for a single best layer.
Final benchmark results on MCIF
The final evaluation applies DOA with attention averaged across layers and heads. The paper compares Phi4-Multimodal and Qwen3-Omni against the StreamAtt baseline built on the attention-based encoder-decoder model SeamlessM4T. The main message is that both DOA-equipped SpeechLLMs achieve highly competitive quality, approach offline decoding performance, and consistently dominate the baseline in the latency-quality trade-off.
The authors also emphasize that the method generalizes across model families with very different architectures: Phi4-Multimodal is a dense model, whereas Qwen3-Omni is mixture-of-experts. Despite this difference, DOA works without adaptation on both.
| Language | Model | $f$ | BLEU | COMET | LongYAAL | LongLAAL | empty% |
|---|---|---|---|---|---|---|---|
| English to German | |||||||
| en-de | SeamlessM4T | 4 | 21.95 | 0.6857 | 1682 | 1825 | 1.09 |
| en-de | SeamlessM4T | 8 | 23.77 | 0.7026 | 2265 | 2379 | 1.20 |
| en-de | SeamlessM4T | 12 | 24.58 | 0.7124 | 3157 | 3292 | 0.98 |
| en-de | Phi4-Multimodal | 5 | 15.45 | 0.7091 | 1338 | 7739 | 0.44 |
| en-de | Phi4-Multimodal | 15 | 29.40 | 0.7602 | 2240 | 2334 | 0.33 |
| en-de | Phi4-Multimodal | 25 | 30.88 | 0.7682 | 3044 | 3161 | 0.22 |
| en-de | Qwen3-Omni | 5 | 24.59 | 0.7392 | 725 | 896 | 9.25 |
| en-de | Qwen3-Omni | 15 | 26.49 | 0.7884 | 2744 | 3959 | 3.70 |
| en-de | Qwen3-Omni | 25 | 28.18 | 0.7911 | 3749 | 4889 | 0.44 |
| English to Italian | |||||||
| en-it | SeamlessM4T | 4 | 33.37 | 0.7592 | 1631 | 1735 | 0.76 |
| en-it | SeamlessM4T | 8 | 34.58 | 0.7663 | 2238 | 2319 | 0.65 |
| en-it | SeamlessM4T | 12 | 36.48 | 0.7725 | 3064 | 3209 | 0.65 |
| en-it | Phi4-Multimodal | 5 | 29.73 | 0.7707 | 1327 | 2950 | 1.20 |
| en-it | Phi4-Multimodal | 15 | 32.26 | 0.7870 | 2174 | 4051 | 1.20 |
| en-it | Phi4-Multimodal | 25 | 33.68 | 0.7985 | 3024 | 4891 | 0.11 |
| en-it | Qwen3-Omni | 5 | 34.78 | 0.8010 | 72 | 998 | 3.81 |
| en-it | Qwen3-Omni | 15 | 37.26 | 0.8086 | 620 | 1926 | 3.70 |
| en-it | Qwen3-Omni | 25 | 38.14 | 0.8282 | 3806 | 5466 | 0.33 |
Several patterns stand out from these results:
- Quality rises with latency. For both Phi4-Multimodal and Qwen3-Omni, increasing $f$ generally improves BLEU and COMET, as expected in a simultaneous translation setting.
- Qwen3-Omni is the strongest system overall. It achieves the best reported COMET scores in both language pairs, including 0.7911 on English-to-German and 0.8282 on English-to-Italian at the highest-latency setting.
- Low-latency operation is possible without retraining. Qwen3-Omni reaches extremely low latency at $f=5$, including a reported LongYAAL of 72 on English-to-Italian, albeit with a non-zero empty-output rate.
- Phi4-Multimodal is easier to control in latency. The paper notes that increasing the cutoff by 10 consistently corresponds to about an 800 ms latency increase for this model.
- Both DOA systems outperform the StreamAtt baseline in the latency-quality trade-off, indicating that proxy alignment from decoder self-attention is a competitive streaming signal.
- Empty outputs are more common in the most aggressive regimes. This is especially visible for Qwen3-Omni at low latency, and the empty-output rate generally decreases as the cutoff increases.
Limitations
The paper is explicit about several limitations. First, the evaluation only covers English source speech, mainly because long, publicly available speech translation benchmarks remain scarce. That means the evidence is strong for English source streams but does not directly establish performance for multilingual or cross-domain input.
Second, the output languages are limited to German and Italian, both written with Latin scripts. The authors note that it remains open whether the same proxy-alignment mechanism transfers cleanly to languages with different scripts or tokenization behavior, such as logographic languages like Chinese or Japanese, or morphologically rich languages such as Turkish or Finnish.
Third, the paper does not report computationally aware latency because the experiments were run in a heterogeneous GPU environment. The authors therefore present ideal latency comparisons only, and they caution that absolute timing across architectures should be interpreted carefully. They also point out that differences in hardware, codebase optimization, and HuggingFace repository versions can materially affect compute-aware latency, but they leave that analysis for future work.
Takeaways for conversational and streaming AI systems
- Decoder-only SpeechLLMs can be made useful for streaming translation without additional training, provided their self-attention is converted into a proxy alignment signal.
- For long-form streaming, history management matters as much as the alignment rule itself. In this paper, punctuation-based textual retention is the most reliable strategy.
- Broad attention averaging is safer than trying to hand-pick a single layer. The layer-wise signal is unstable, while averaged attention works robustly across models.
- Across the reported benchmarks, DOA delivers a practical Pareto improvement over a strong attention-based encoder-decoder baseline, making it a compelling option for low-latency conversational translation pipelines.
Overall, the paper's main message is that decoder self-attention in SpeechLLMs is not just an internal bookkeeping mechanism; it can be repurposed as a useful alignment signal for streaming control. That makes DOA a simple but effective bridge between offline SpeechLLMs and long-form simultaneous translation.
Code & Implementation
The simulstream repository implements a Python library for simultaneous and streaming speech recognition and translation, matching the paper's focus on simultaneous speech-to-text translation (SimulST) with streaming policies. The codebase provides a flexible WebSocket server-client architecture for real-time speech processing, supporting both transcription and translation while streaming audio input, which aligns with the paper's goal of enabling low-latency long-form simultaneous translation.
The core of the implementation resides in the simulstream.server.speech_processors module, which defines the base classes and different speech processor implementations. These are designed to support various streaming policies, including attention-based ones. The BaseStreamAtt class in base_streamatt.py is a foundational partial implementation for streaming attention-based policies that extracts and uses cross-attention scores to select audio history, a concept related to the decoder attention policy studied in the paper.
The simulstream/inference.py script provides an entry point for running inference on WAV files using configured speech processors, handling chunked audio streaming, configuring source/target languages, and logging metrics. This reflects the evaluation setup described in the paper, where off-the-shelf SpeechLLMs are used with a training-free policy (DOA) for streaming translation decisions.
The repository's design is modular, allowing new speech processors following the SpeechProcessor abstract base class interface to be implemented and integrated easily. While the paper proposes the DOA policy, the current code includes base and existing attention-based policies (like StreamAtt). The repository supports evaluation and demo executions as described in the README.
In summary, the repository implements the streaming speech translation framework with configurable speech processors and streaming policies, providing the infrastructure to integrate and test the DOA (Decoder-Only Attention) policy method as described in the paper. Users run simulstream_inference --speech-processor-config config/speech_processor.yaml to evaluate their configured model on datasets.