UNISON
UNISON: A Unified Sound Generation and Editing Framework via Deep LLM Fusion
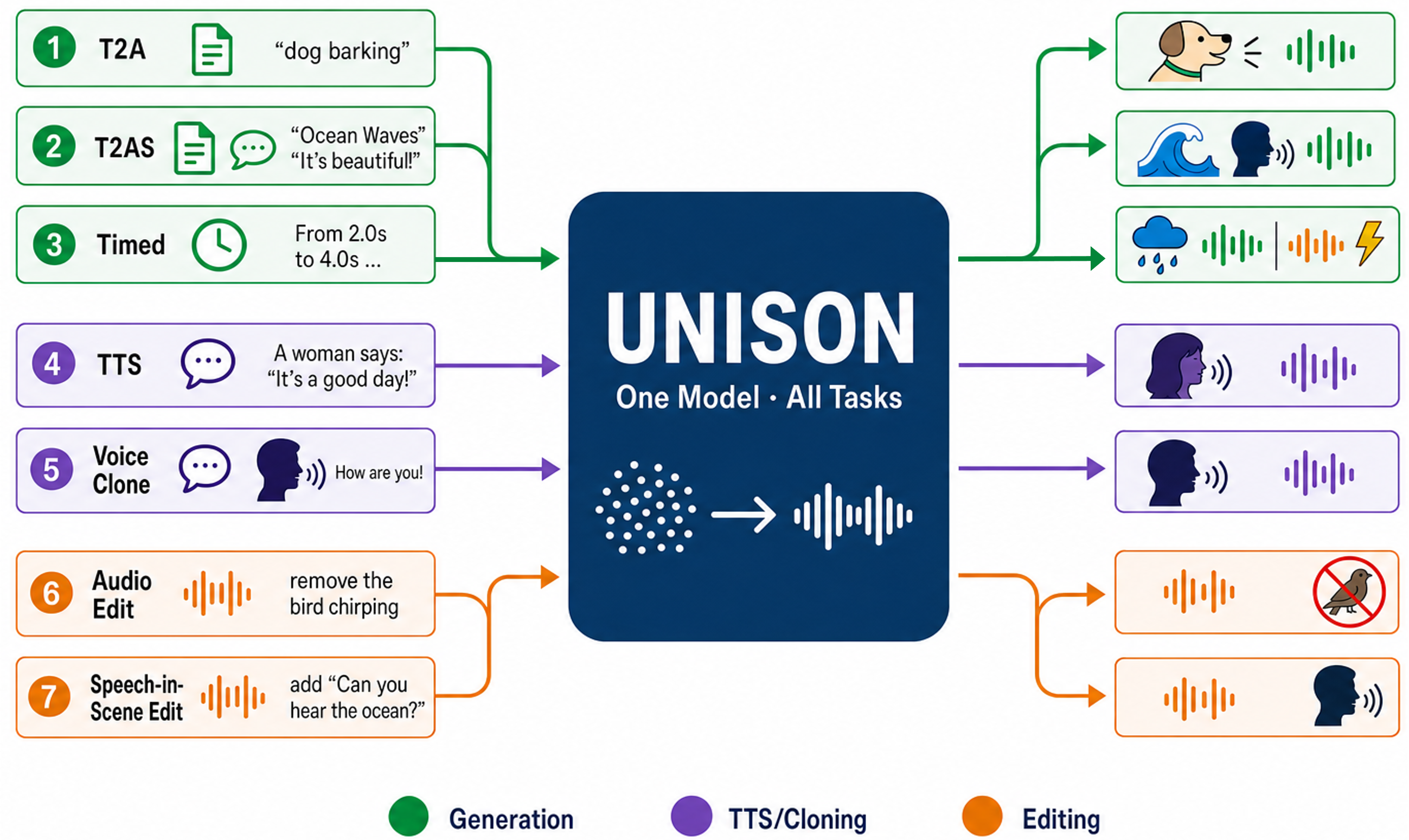
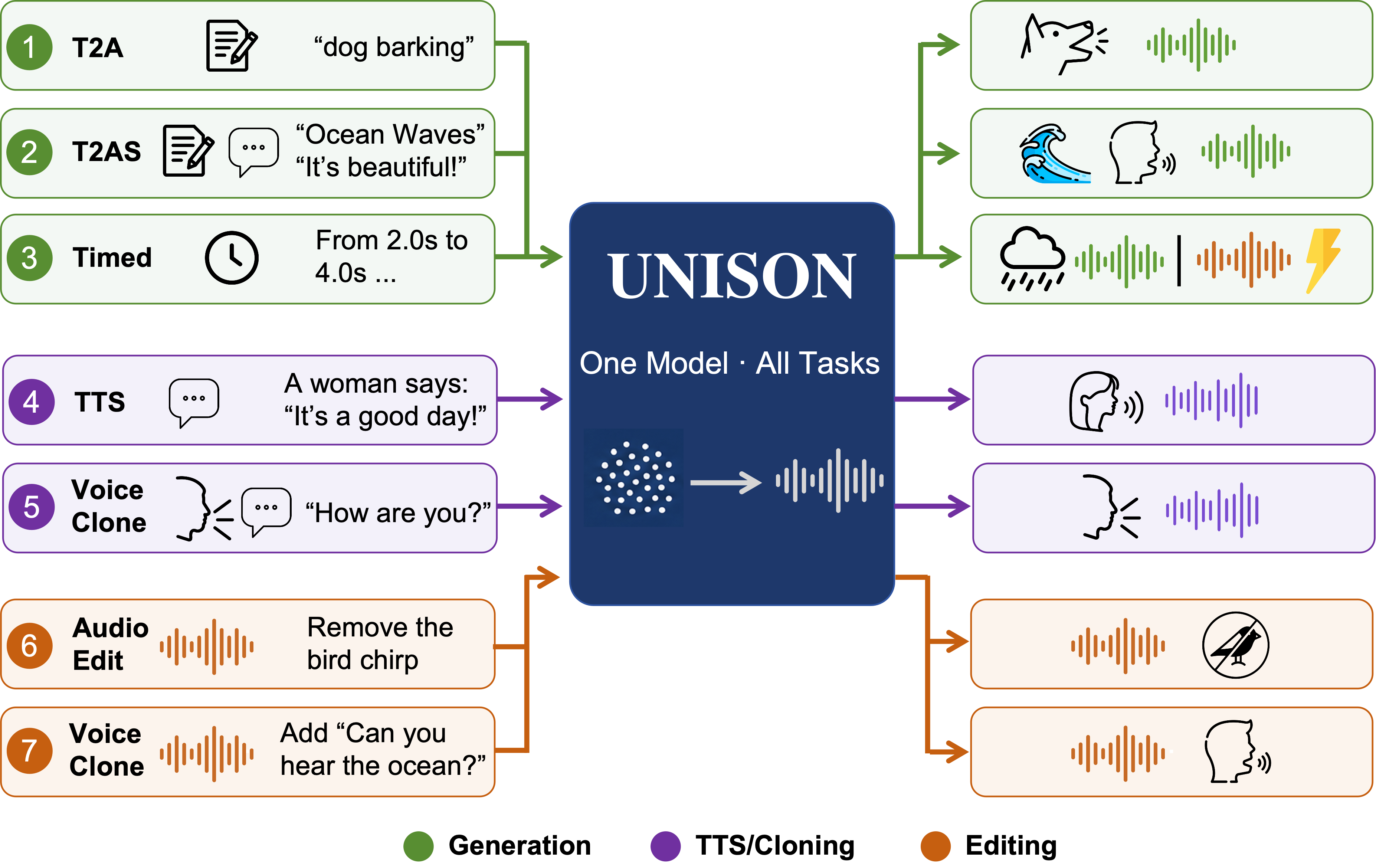
UNISON unifies speech, sound generation, and audio editing into a single model using layer-wise deep LLM fusion, enabling versatile tasks like text-to-audio and zero-shot speaker cloning efficiently with one architecture.
Demos
These demos showcase UNISON's unified audio generation and editing, covering text-to-audio, zero-shot TTS, mixed speech+audio, audio editing, and timed composition. Watch for the model's ability to follow detailed instructions, manage speaker voice and gender, and perform precise edits using one shared model. The demos highlight the deep LLM fusion enabling flexible, high-quality compositional audio outputs across tasks and languages.
Links
Paper & demos
Abstract
We present UNISON, a latent diffusion framework that unifies speech generation, sound generation, and audio editing within a single model. A single model handles text-to-audio, text-to-speech, zero-shot speaker cloning, mixed speech-and-sound generation, scene-level audio editing, speech-in-scene editing, and timed temporal composition, all of which share a single set of weights. Our architecture features two core designs: (1) Layer-wise deep LLM fusion, which injects hidden states from uniformly sampled layers of a frozen MLLM into corresponding MM-DiT blocks via learned projections, providing depth-matched semantic conditioning that improves instruction following over single-layer baselines; and (2) a unified multi-task architecture where task identity is encoded solely by a channel-wise mask and source audio is provided through VAE-encoded channel concatenation. Training is stabilized by an online GPU-side multi-task data synthesis pipeline with task-homogeneous batching and a two-stage curriculum. With 621M--732M trainable parameters, UNISON achieves results competitive with or exceeding task-specialist models across evaluated domains, while being roughly $4\times$ smaller than comparable unified systems.
Introduction and Core Idea
UNISON proposes a single latent-diffusion-style framework that unifies speech generation, sound generation, and audio editing under one set of weights. The same model is used for text-to-audio, text-to-speech, zero-shot speaker cloning, mixed speech-and-sound generation, scene-level audio editing, speech-in-scene editing, and timed temporal composition. The key design goal is to remove the fragmented, task-specific conditioning pipelines that are common in prior unified audio systems.
The paper argues that two limitations dominate earlier approaches: first, different tasks often depend on different auxiliary modules such as phoneme encoders, mel encoders, inversion stacks, or duration predictors, which fractures the latent space and complicates joint training; second, most systems condition the generative backbone on a single final text layer, which discards the hierarchical structure of language-model representations. UNISON addresses both by routing all tasks through the same VAE, the same MM-DiT backbone, and the same forward pass, while injecting multi-layer LLM features at matching depths of the diffusion transformer.
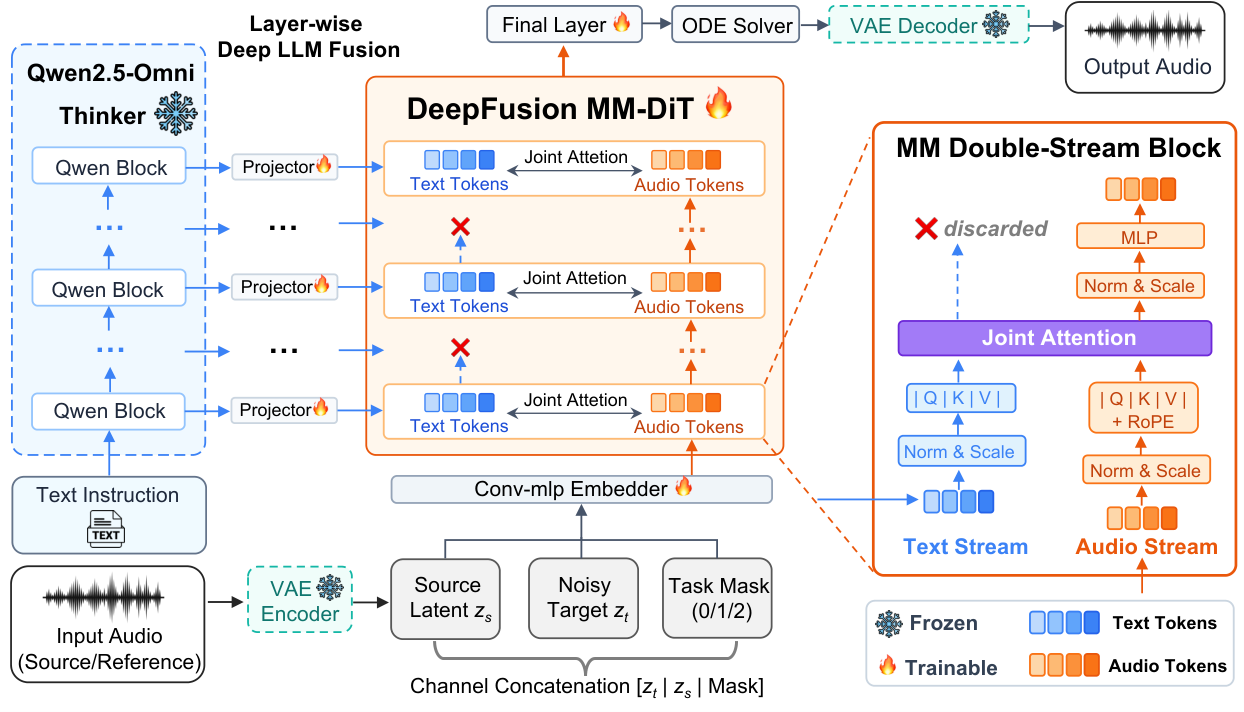
At a high level, the model uses a frozen continuous audio VAE for both targets and sources, a frozen Qwen2.5-Omni-7B text backbone for instruction encoding, and a trainable DeepFusion MM-DiT that predicts a flow-matching velocity field. The paper reports two main variants: D20 at 44.1 kHz with 20 double-stream blocks and 621M trainable parameters, and D24 at 16 kHz with 24 double-stream blocks and 732M trainable parameters. Both variants are substantially smaller than comparable unified systems while covering a broader task set.
Method
Overall pipeline and notation
For each sample, UNISON builds a text instruction and, when needed, an optional source waveform. Waveforms are encoded into latents using the frozen VAE, giving a target latent $\mathbf{z}$ and a source/reference latent $\mathbf{z}_s$. A flow time $t$ is sampled and the target is noised to produce $\mathbf{z}_t$. These three parts are concatenated channel-wise into an input tensor
$$\mathbf{X} = [\mathbf{z}_t \,\|\, \mathbf{z}_s \,\|\, \mathbf{m}]$$
where $\mathbf{m}$ is a per-frame task tag. The trainable MM-DiT maps $(\mathbf{X}, \{\tilde{\mathbf{E}}_k\}, t)$ to a velocity prediction on the target channels, and an ODE solver is used at inference to generate the final latent before VAE decoding.
The paper’s notation is intentionally simple: $C$ is the latent channel count, $T'$ is the latent frame length, $D$ is the number of double-stream blocks, $L=28$ is the number of Qwen layers, and the DiT hidden width is $d=1024$. The D20 variant uses $C=40$ at 44.1 kHz, while D24 uses $C=20$ at 16 kHz.
Audio VAE and unified task encoding
UNISON adopts the MMAudio continuous VAE. A waveform is converted to a mel spectrogram and encoded into a latent representation. The same VAE is used for target audio, edit sources, and speaker reference audio. This is a major part of the paper’s unification story: rather than using separate modules for different tasks, all tasks share the same latent representation space.
Task identity is conveyed by a single scalar channel $\mathbf{m}$ broadcast across frames, with the paper using three values:
- $\mathbf{m}=0$ for generation tasks, including T2A, TTS, T2AS, and timed composition, with $\mathbf{z}_s=\mathbf{0}$.
- $\mathbf{m}=1$ for editing tasks, where $\mathbf{z}_s$ contains the source scene latent and $\mathbf{z}$ is the edited target.
- $\mathbf{m}=2$ for zero-shot TTS, where the reference prefix is encoded with the same VAE and the loss is masked so that gradients apply only to synthesized frames.
The authors emphasize that no separate duration predictor is used. Inputs are fixed-length padded latents, and trailing silence is learned implicitly. For timed tasks, the LLM is expected to parse timestamps from natural-language instructions.
Layer-wise deep LLM fusion
The central modeling contribution is layer-wise deep LLM fusion. A frozen Qwen2.5-Omni-7B model is run once on the prompt and provides hidden states from all 28 layers. These are mapped into the MM-DiT at depth-matched positions using learned linear projections:
$$\tilde{\mathbf{E}}_k = \mathbf{E}^{(i_k)} \mathbf{W}_k, \qquad i_k = \left\lfloor 1 + k \frac{L-1}{D-1} \right\rfloor$$
This means earlier diffusion blocks see shallower language representations, which the paper associates with lexical and syntactic structure, while later blocks receive more abstract semantics. The authors argue that this aligns the hierarchical structure of the language model with the depth of the generative transformer, improving instruction following for compositional audio prompts.
Inside each double-stream block, audio and text tokens interact through joint attention. Only the audio stream is updated by the block MLP; text tokens are refreshed at each depth from the frozen LLM rather than being propagated through the DiT. This design avoids forcing the generative backbone to re-learn full language structure and also saves compute. Rotary position embeddings are applied only to the audio tokens.
![UNISON Architecture. Left: Layer-wise deep LLM fusion injects per-layer Qwen hidden states into corresponding DiT blocks via learned projectors. Middle: Each double-stream block performs joint attention; text tokens are refreshed per block while audio tokens pass through the MLP. Bottom: [z_t | z_s | m] are channel-concatenated and embedded; the ODE solver denoises the latent, which is VAE-decoded to waveform. See Section Method.](https://akapulu-public-assets.s3.us-west-1.amazonaws.com/blogs/research-digest/p/2605.31530/arxiv/fig/_preview/fig2.png)
Training objective and inference
The flow-matching target velocity is defined as $\mathbf{u} = \boldsymbol{\epsilon} - \mathbf{z}$. The training objective is an $L_2$ loss on the predicted velocity, with masking for the zero-shot TTS prefix:
$$\mathcal{L} = \mathbb{E}\left[ \left\| v_\theta(\mathbf{X}, \{\tilde{\mathbf{E}}_k\}, t) - \mathbf{u} \right\|_2^2 \odot \mathbf{M}_{\text{loss}} \right]$$
Text conditioning is dropped with probability 0.1 for classifier-free guidance. At inference, the model starts from Gaussian noise, integrates the learned velocity with a 100-step Euler ODE solver, and decodes the final latent with the frozen VAE. The CFG scale used in the paper is 4.5.
Online multi-task synthesis and curriculum
Instead of relying on static task-specific datasets, UNISON constructs training tuples online on the GPU during data loading. The pipeline assembles task-specific combinations of source latents, target latents, and instruction templates for T2A, TTS, zero-shot TTS, T2AS, several audio-editing modes, speech-in-scene editing, and timed composition. For editing tasks, the pipeline handles RMS normalization, randomized temporal offsets, and fade-in/fade-out boundaries.
The paper uses a two-stage curriculum and task-homogeneous batching to stabilize multi-task training. Stage 1 trains only generation tasks for the first 150K steps. Stage 2 introduces editing tasks and uses a mixed sampling distribution of roughly 70% generation and 30% editing. Each mini-batch contains only one task type, which the authors say reduces gradient conflicts between opposing objectives such as add-versus-remove editing.
| Task | Stage 1 | Stage 2 probability |
|---|---|---|
| TTS (gender-controlled) | Yes | 0.15 |
| Zero-shot TTS | Yes | 0.25 |
| T2A (single event) | Yes | 0.10 |
| T2A (mix) | Yes | 0.08 |
| Speech + audio mix (T2AS) | Yes | 0.08 |
| Timed composition | Yes | 0.04 |
| Audio edit — add | No | 0.04 |
| Audio edit — remove | No | 0.04 |
| Audio edit — replace | No | 0.03 |
| Speech-in-scene — insert | No | 0.04 |
| Speech-in-scene — delete | No | 0.03 |
| Speech-in-scene — rewrite | No | 0.04 |
| Denoise | No | 0.04 |
| Other editing variants | No | 0.04 |
Implementation Details and Training Data
The paper reports two main configurations. D20 uses 20 double-stream blocks, 40 latent channels, and a 44.1 kHz VAE, giving 621M trainable parameters. D24 uses 24 double-stream blocks, 20 latent channels, and a 16 kHz VAE, giving 732M trainable parameters. Both use the same frozen Qwen2.5-Omni-7B text encoder with 28 layers and hidden size 3584. The DiT hidden width is 1024 with 8 attention heads. The training setup uses AdamW with $\beta_1=0.9$, $\beta_2=0.95$, learning rate $10^{-4}$ with cosine decay and 2000 warmup steps, weight decay 0.01, gradient clipping 1.0, BF16 mixed precision, and EMA decay 0.999 updated every 10 steps.
Both base models are trained on 10-second clips, then fine-tuned for 22-second long speech. Training is done on 8 H800 GPUs with batch size 56 per GPU. The authors note that the same training recipe is used across the ablation variants, making the comparisons mostly architectural rather than optimization-driven.
| Hyperparameter | D20S0-44kHz | D24S0-16kHz |
|---|---|---|
| Audio VAE | MMAudio 44.1 kHz VAE | MMAudio 16 kHz VAE |
| VAE latent channels | 40 | 20 |
| Input channels | 81 | 41 |
| Sample rate | 44,100 Hz | 16,000 Hz |
| Double-stream blocks | 20 | 24 |
| Trainable parameters | 621M | 732M |
| Inference steps | 100 | 100 |
| CFG scale | 4.5 | 4.5 |
The training corpus contains about 36M clips, totaling roughly 57K hours. The audio side is built from WavCaps, AudioSet, and VGGSound, while speech comes from LibriTTS, WenetSpeech, and large Emilia English and Chinese subsets. The paper reports about 2.34M audio clips after filtering and 33.7M speech clips, with approximately 6.4K audio hours and 50.7K speech hours.
| Domain | Dataset | Clips | Hours |
|---|---|---|---|
| Audio | WavCaps | 841K | 2,189 |
| AudioSet (with labels) | 1,718K | 4,772 | |
| VGGSound | 174K | 482 | |
| Audio subtotal (after filter) | 2,342K | about 6,400 | |
| Speech | LibriTTS | 281K | 332 |
| WenetSpeech | 8,133K | 7,693 | |
| Emilia-EN (20M subset) | 11,560K | 19,802 | |
| Emilia-ZH (20M subset) | 13,759K | 22,892 | |
| Speech subtotal | 33,733K | about 50,700 | |
| Total | about 36M | about 57K | |
For evaluation, the paper uses standard public benchmarks where available and constructs fixed-seed test sets for tasks without common benchmarks. The primary metrics are FAD and FD for distributional quality, KL and IS for classifier-based evaluation, CLAP for semantic alignment, WER/CER for speech intelligibility, LSD for spectral fidelity, gender accuracy for gender-controlled TTS, and speech removal rate for delete-style editing.
Main Experimental Results
Text-to-audio generation
On AudioCaps test, the D24 model achieves the best FAD and CLAP among the compared systems, while D20 achieves the best FD and IS. The authors interpret this as a trade-off between the two variants: D24’s larger latent abstraction tends to help semantic alignment, while D20’s 44.1 kHz VAE preserves more spectral detail and improves distributional metrics tied to realism.
| Model | Params | FAD ↓ | FD ↓ | KL ↓ | IS ↑ | CLAP ↑ |
|---|---|---|---|---|---|---|
| AudioLDM 2-Large | 712M | 3.097 | 29.68 | 1.490 | 7.98 | 0.452 |
| Tango | 866M | 1.846 | 24.52 | 1.305 | 7.45 | 0.498 |
| Stable Audio Open | 1.06B | 10.83 | 52.03 | 3.049 | 6.13 | 0.203 |
| Make-An-Audio 2 | 937M | 2.142 | 20.14 | 1.597 | 10.02 | 0.441 |
| GenAU-L | 1.25B | 1.591 | 18.41 | 1.290 | 11.94 | 0.561 |
| Audio-Omni | 3.05B | 2.535 | 31.42 | 1.337 | 9.55 | 0.486 |
| MMAudio-L | 1.03B | 5.893 | 16.53 | 1.421 | 11.98 | 0.441 |
| UniSonate | 1.34B | 4.210 | 30.21 | 2.440 | 8.22 | — |
| UNISON (D24, 16 kHz) | 732M | 1.558 | 16.28 | 1.459 | 10.90 | 0.503 |
| UNISON (D20, 44 kHz) | 621M | 1.756 | 15.82 | 1.455 | 12.04 | 0.467 |
The paper highlights that D24 attains the best FAD of 1.558 and the best CLAP of 0.503 among comparable models, while D20 attains the best FD of 15.82 and the best IS of 12.04. Both variants outperform much larger unified baselines such as Audio-Omni and MMAudio-L in FAD, despite being roughly four times smaller than Audio-Omni.
Text-to-speech and zero-shot speaker cloning
UNISON performs strongly on Seed-TTS in both pure TTS and zero-shot TTS settings, and the paper stresses that it does so without a phoneme encoder or explicit G2P pipeline. D24 is the strongest variant: it obtains the lowest WER and CER in both English and Chinese, with 1.27% pure WER, 1.50% zero-shot WER, 0.92% pure CER, and 0.89% zero-shot CER. These numbers are better than the larger Audio-Omni system on pure English TTS and better than specialized zero-shot systems such as ZipVoice and F5-TTS in the zero-shot setting.
| Model | Params | Pure WER ↓ | ZS WER ↓ | Pure CER ↓ | ZS CER ↓ |
|---|---|---|---|---|---|
| MaskGCT | 1.05B | — | 2.62 | — | 2.27 |
| CosyVoice 2 | 618M | — | 2.57 | — | 1.45 |
| ZipVoice | 123M | — | 1.70 | — | 1.40 |
| E2-TTS | 333M | — | 2.19 | — | 1.97 |
| F5-TTS | 336M | — | 1.83 | — | 1.56 |
| InstructAudio | 1.30B | 1.52 | — | 1.35 | — |
| UniSonate | 1.34B | 1.47 | — | 1.25 | — |
| Audio-Omni | 3.05B | 1.35 | 1.77 | — | — |
| UNISON (D24) | 732M | 1.27 | 1.50 | 0.92 | 0.89 |
| UNISON (D20) | 621M | 1.42 | 1.80 | 1.11 | 1.71 |
The paper also reports gender-controlled TTS on a balanced bilingual test set of 300 samples. Both variants achieve 100% gender accuracy purely from text instructions, with low intelligibility degradation. D24 obtains 1.21% English WER and 1.00% Chinese CER, while D20 obtains 1.47% English WER and 1.02% Chinese CER.
| Metric | D24 | D20 |
|---|---|---|
| Gender accuracy | 100% | 100% |
| WER-EN ↓ | 1.21 | 1.47 |
| CER-ZH ↓ | 1.00 | 1.02 |
| WER (male) ↓ | 1.64 | 1.31 |
| WER (female) ↓ | 0.74 | 1.65 |
| CER (male) ↓ | 1.30 | 1.05 |
| CER (female) ↓ | 0.71 | 0.99 |
Mixed speech-and-sound generation
For T2AS, the model is asked to generate a unified output that contains intelligible speech together with a matching soundscape. The test set is constructed by pairing Seed-TTS speech with AudioCaps sound clips and mixing them at 0 dB SNR as a pseudo ground truth. D24 achieves CLAP 0.444, which the paper reports as 93.3% of the pseudo-GT CLAP of 0.476. It also achieves WER 2.04% and CER 3.64% measured directly on the mixed output. D20 has slightly lower intelligibility but lower LSD, reflecting a fidelity-versus-intelligibility trade-off similar to the one seen in other tasks.
| Metric | D24 | D20 |
|---|---|---|
| CLAP ↑ (GT: 0.476) | 0.444 | 0.430 |
| WER-EN ↓ | 2.04 | 3.44 |
| CER-ZH ↓ | 3.64 | 5.80 |
| LSD ↓ | 2.44 | 2.36 |
Audio editing
UNISON treats audio editing as conditional generation in the shared latent space. Instead of DDPM inversion, a separate mel encoder, or a task-specific decoder, the source audio is encoded with the same VAE as the target, and the model receives the source latent concatenated with the noised target and the task mask. This design is evaluated on add, remove, and replace sub-tasks.
D24 is the strongest editing model overall. It achieves the best overall FD and CLAP, with overall FD 12.38 and overall CLAP 0.364, which the paper says is 82% of the pseudo-GT CLAP. It also preserves non-edited content well, with overall LSD 1.77. D20 often attains slightly lower LSD, especially in some replacement settings, but tends to have worse FD and CLAP.
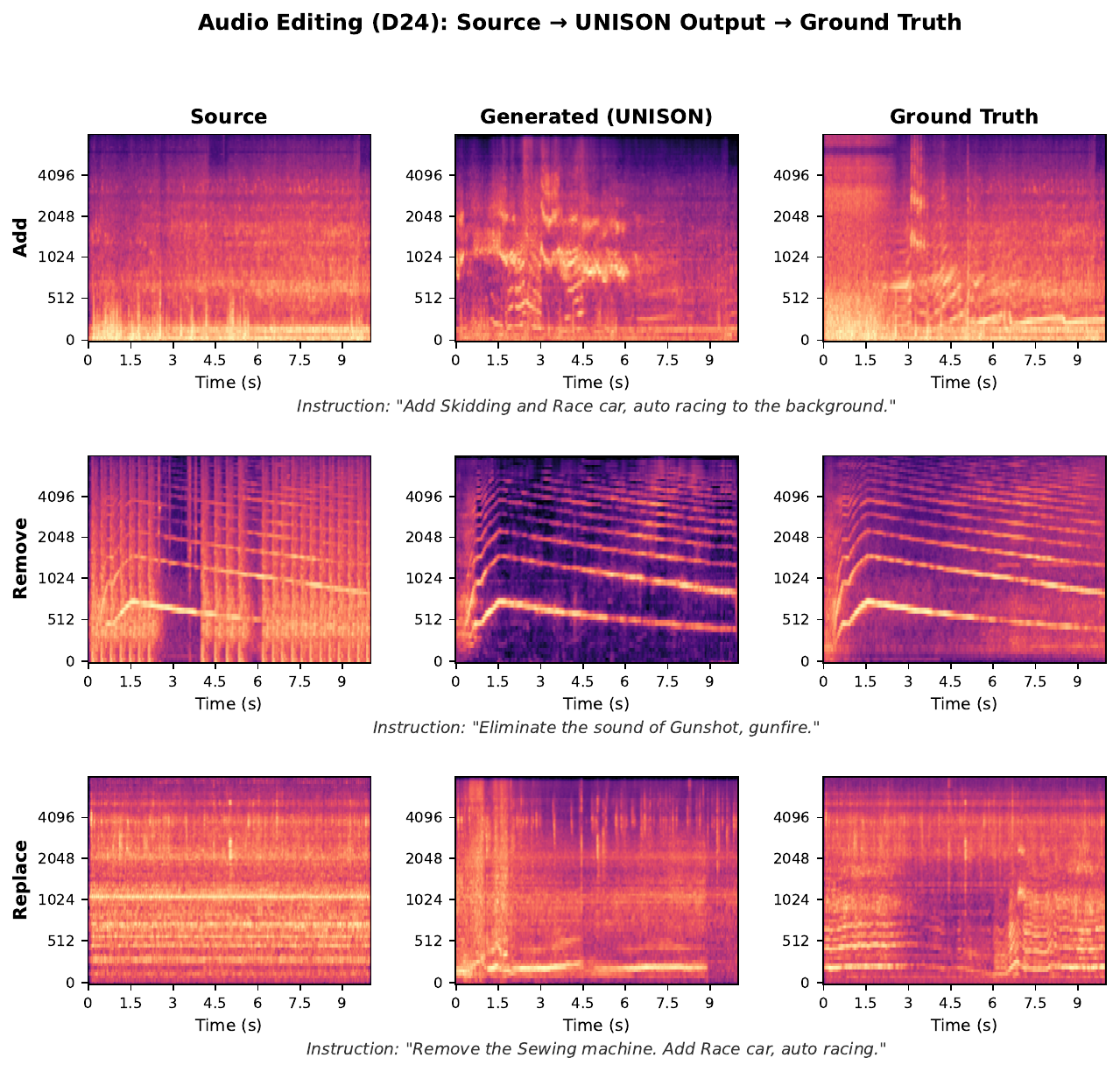
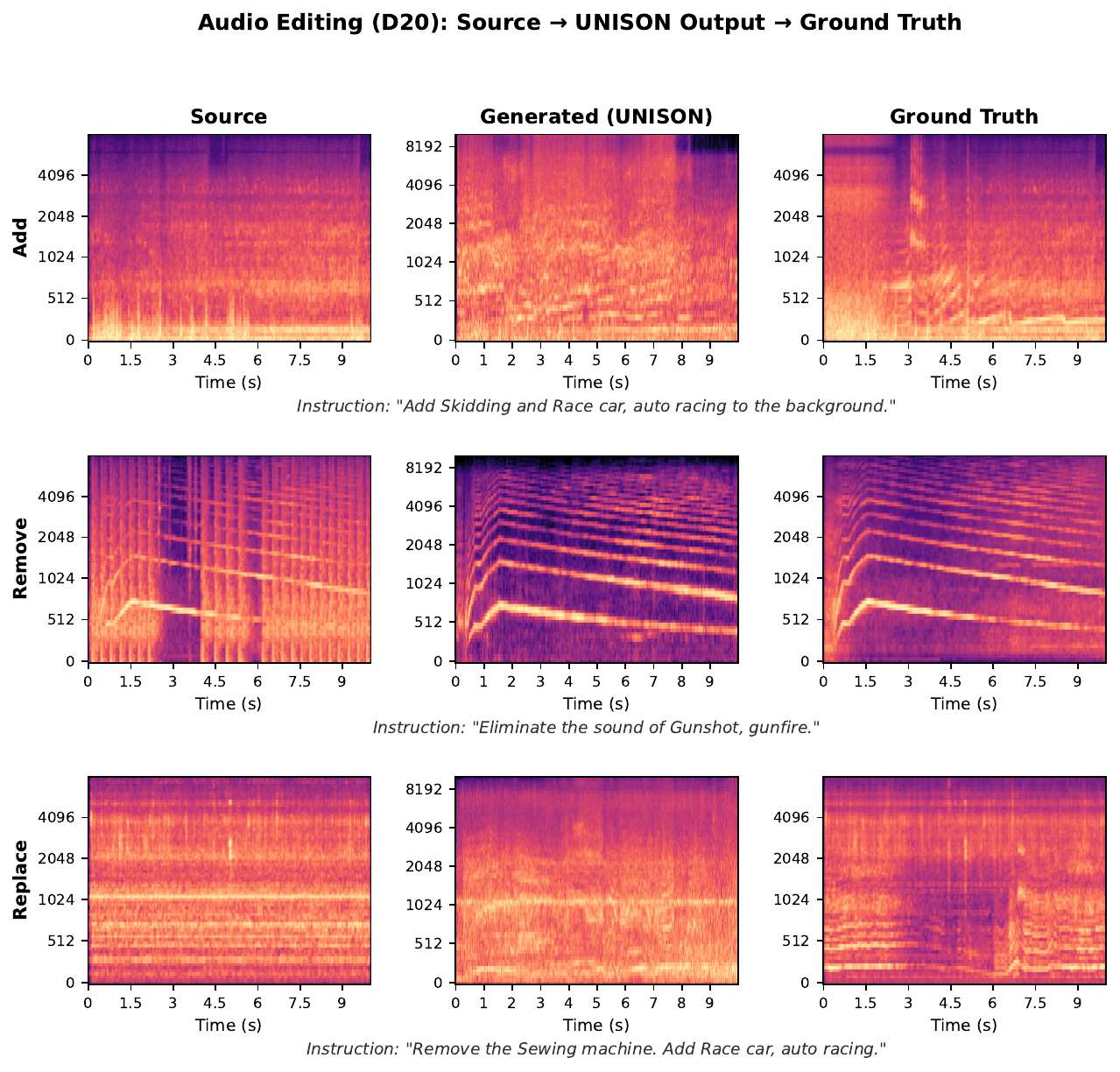
| Task | Model | FD ↓ | LSD ↓ | CLAP ↑ |
|---|---|---|---|---|
| Add (GT CLAP 0.429) | SDEdit | 78.86 | 2.21 | 0.168 |
| ZETA | 67.27 | 2.18 | 0.243 | |
| MMEDIT | 25.98 | 2.23 | 0.339 | |
| Audio-Omni | 34.92 | 1.99 | 0.332 | |
| UNISON (D24) | 19.26 | 1.49 | 0.416 | |
| UNISON (D20) | 20.18 | 1.43 | 0.391 | |
| Remove (GT CLAP 0.485) | SDEdit | 87.65 | 2.11 | 0.053 |
| ZETA | 66.34 | 2.09 | 0.141 | |
| MMEDIT | 45.25 | 3.86 | 0.221 | |
| Audio-Omni | 64.00 | 2.51 | 0.112 | |
| UNISON (D24) | 33.20 | 2.15 | 0.308 | |
| UNISON (D20) | 37.93 | 2.18 | 0.169 | |
| Replace (GT CLAP 0.417) | SDEdit | 79.09 | 1.90 | 0.119 |
| ZETA | 62.71 | 1.89 | 0.180 | |
| MMEDIT | 27.56 | 2.77 | 0.210 | |
| Audio-Omni | 55.39 | 1.82 | 0.202 | |
| UNISON (D24) | 21.31 | 1.68 | 0.368 | |
| UNISON (D20) | 23.09 | 1.57 | 0.307 | |
| Overall (GT CLAP 0.444) | SDEdit | 73.85 | 2.07 | 0.114 |
| ZETA | 57.27 | 2.05 | 0.189 | |
| MMEDIT | 20.60 | 2.95 | 0.257 | |
| Audio-Omni | 36.29 | 2.11 | 0.217 | |
| UNISON (D24) | 12.38 | 1.77 | 0.364 | |
| UNISON (D20) | 13.44 | 1.73 | 0.289 |
Speech-in-scene editing
This task manipulates speech embedded in a background scene, with insert, delete, and rewrite operations. The paper reports that D24 achieves 99.16% speech removal in the delete setting and keeps WER below 1.35% in insert and rewrite. D20 generally achieves lower LSD but lower CLAP and weaker removal, again mirroring the trade-off between spectral fidelity and task adherence.
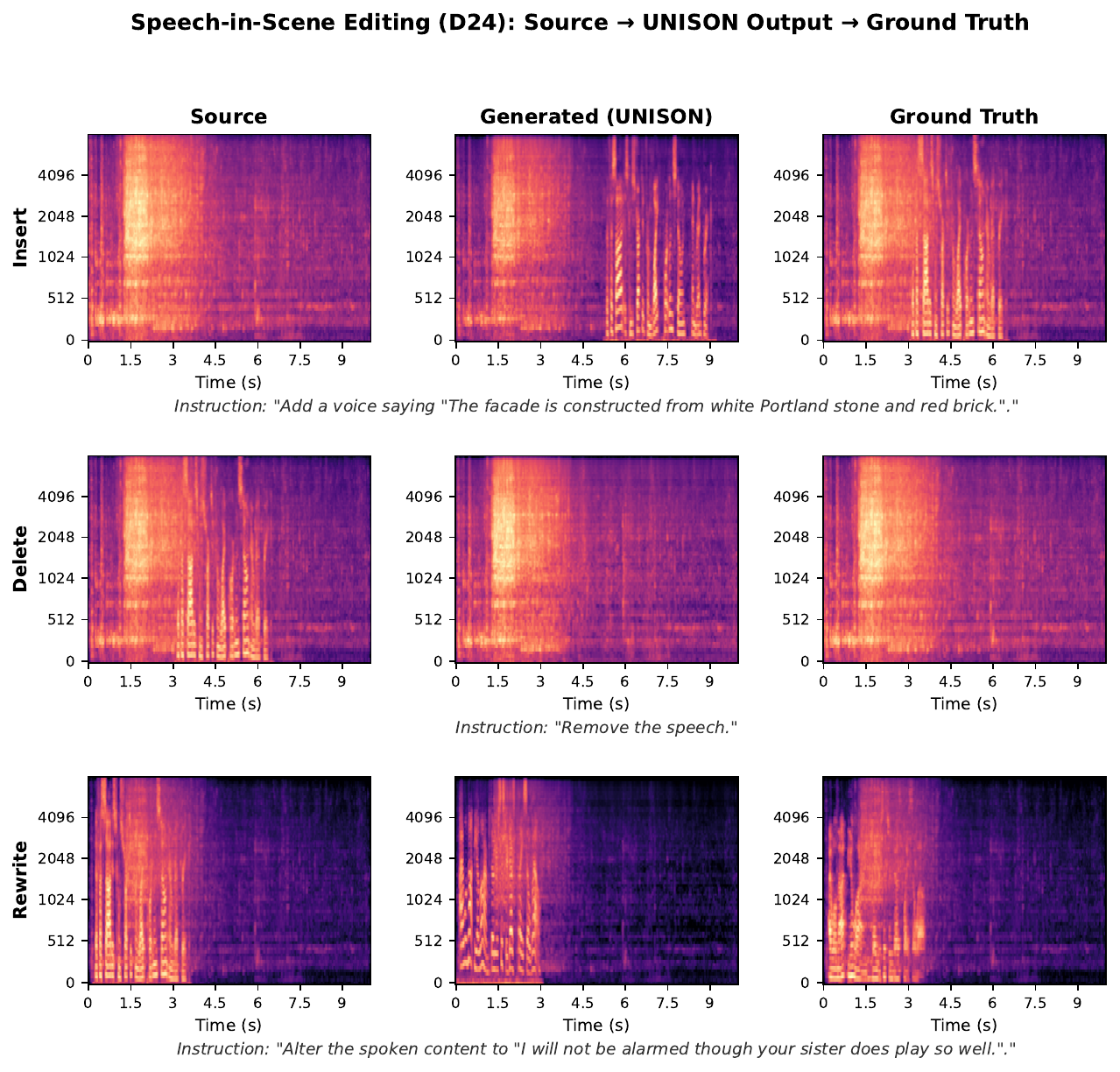
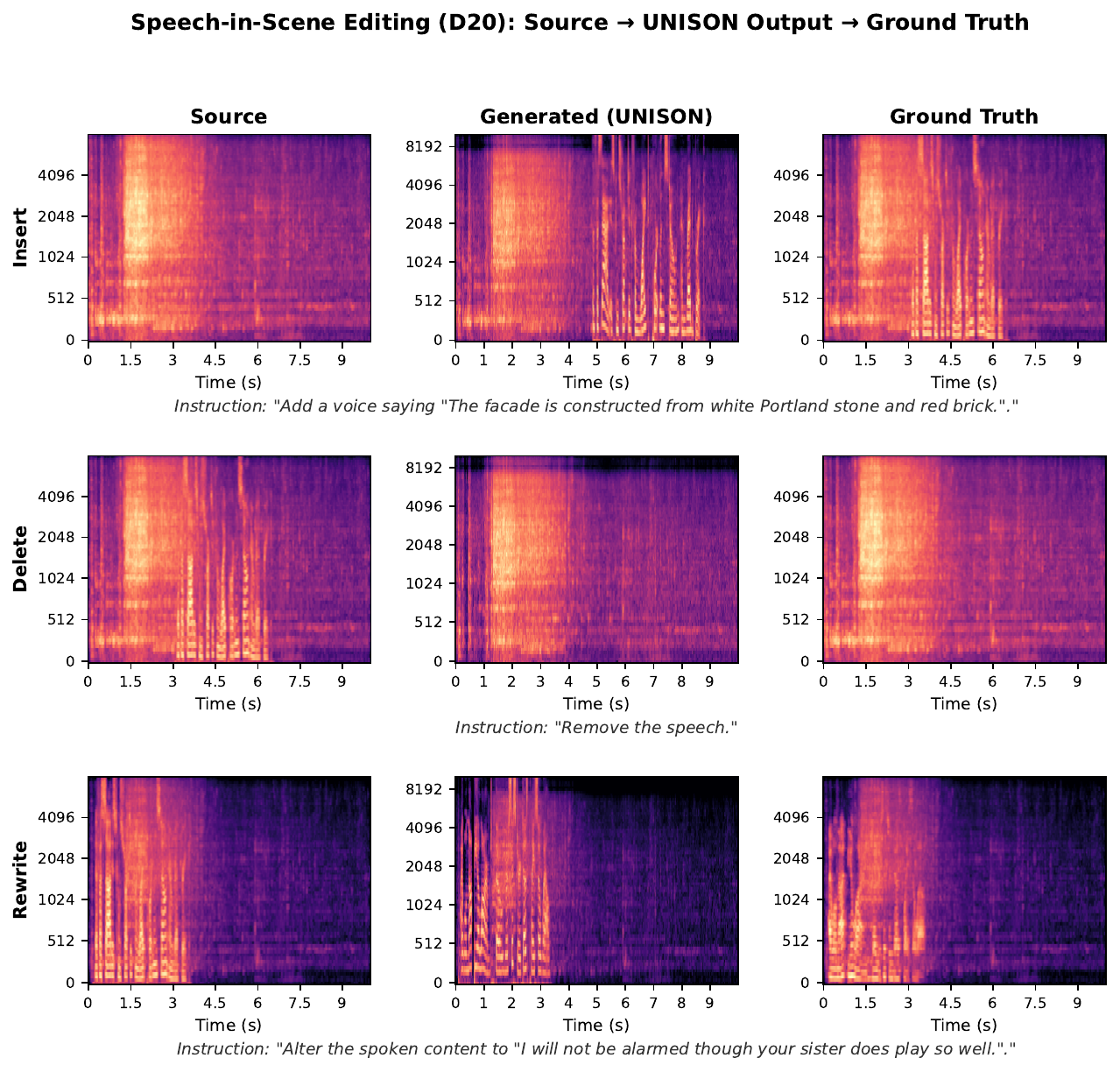
| Sub-task | Model | CLAP ↑ | GT CLAP | LSD ↓ | WER ↓ | CER ↓ | Removal ↑ |
|---|---|---|---|---|---|---|---|
| Insert | D24 | 0.433 | 0.459 | 1.70 | 1.35 | 0.65 | — |
| D20 | 0.429 | 0.459 | 1.66 | 1.70 | 1.08 | — | |
| Delete | D24 | 0.412 | 0.468 | 1.56 | — | — | 99.16% |
| D20 | 0.320 | 0.468 | 1.52 | — | — | 95.72% | |
| Rewrite | D24 | 0.408 | 0.456 | 1.60 | 0.98 | 0.95 | — |
| D20 | 0.396 | 0.456 | 1.46 | 1.35 | 1.09 | — |
Timed composition
Timed generation asks the model to produce audio events at specified time intervals using only natural-language timestamp instructions. The paper does not add a dedicated alignment head; instead, the frozen LLM parses the timing cues. D20 and D24 both achieve per-segment CLAP around 0.31, and their overall CLAP is higher than the per-segment score, suggesting coherent global scenes despite some boundary softening.
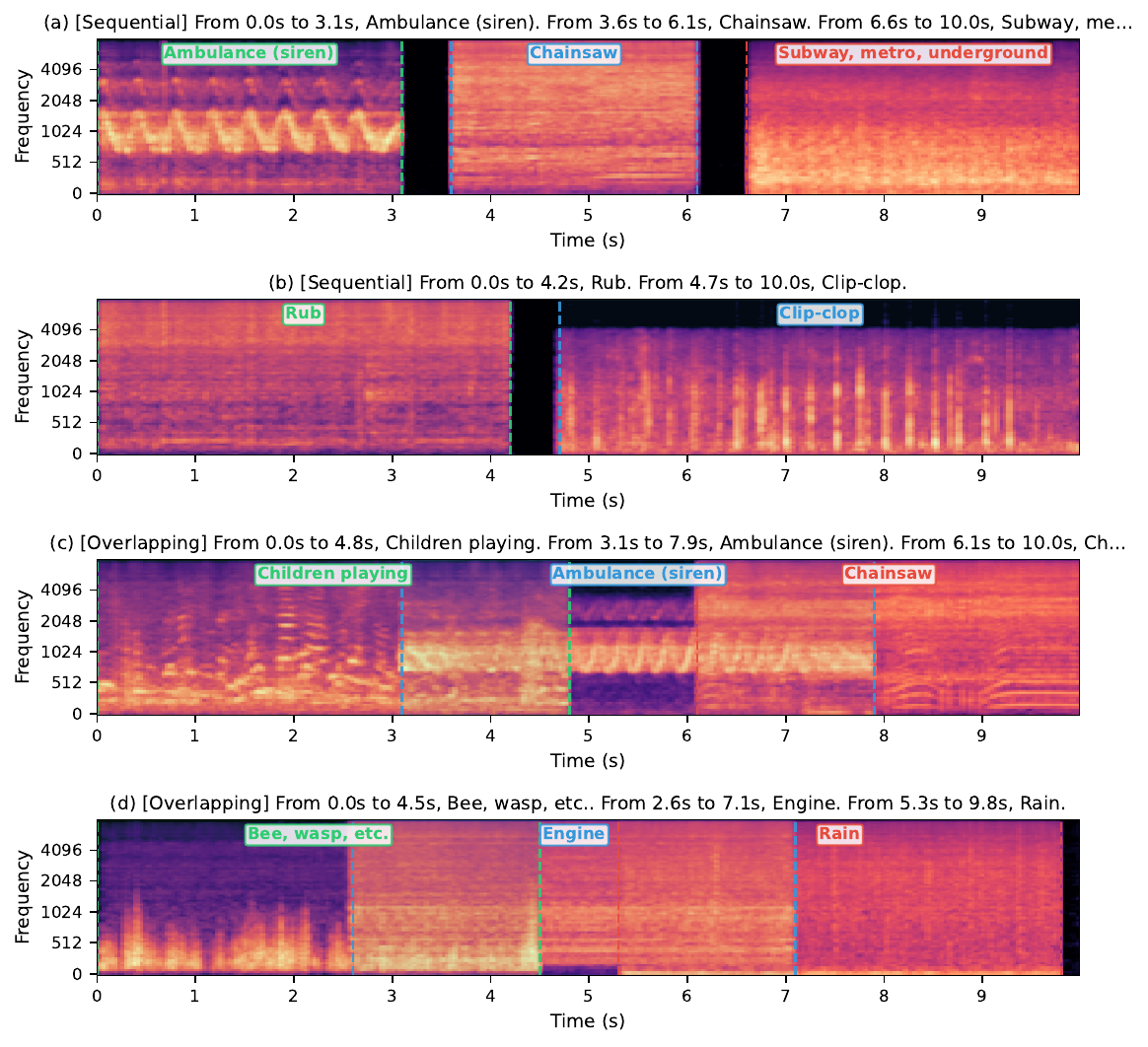
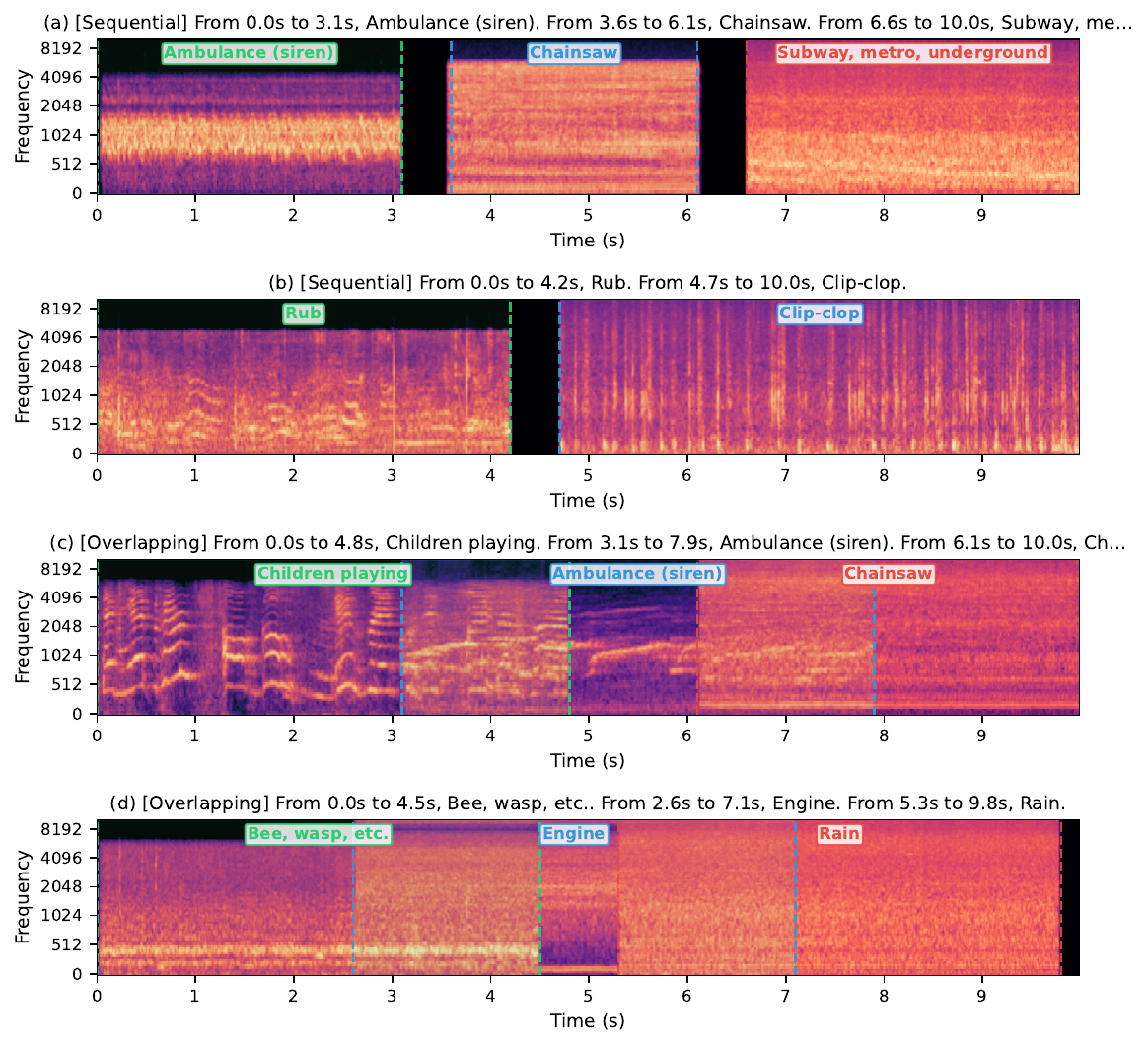
| Metric | D24 | D20 |
|---|---|---|
| Per-segment CLAP ↑ | 0.308 | 0.311 |
| Overall CLAP ↑ | 0.345 | 0.405 |
Ablation Studies
The paper studies three ablation axes: the LLM conditioning strategy, the stream architecture, and the size of the frozen LLM. All ablations are trained with the same data and hyperparameters for 80K steps, so differences are attributed mainly to architectural choices.
Deep fusion versus single-layer conditioning. Broadcasting a single penultimate LLM layer to all DiT blocks performs worse than injecting per-block hidden states. The paper’s D24-L setting has lower CLAP and higher FD than the deep-fusion-only setting D24-O, supporting the idea that depth-matched fusion better preserves hierarchical semantic cues.
Redundant text streams can hurt TTS. The D24-OL variant adds both deep fusion and a persistent penultimate-layer text stream. This gives the best FD and CLAP in the ablation table, but it also produces the worst WER, suggesting that duplicated text conditioning can inject noise into speech synthesis even if it helps text-audio alignment.
Double-stream blocks matter. A single-stream alternative with comparable compute performs worse than the double-stream architecture, with poorer FD, lower CLAP, and higher WER. The authors interpret this as evidence that separating modality-specific normalization and projections is important for keeping audio and text representations distinct before they interact via joint attention.
LLM scale matters. Replacing the default 7B Qwen model with a 3B variant degrades all reported metrics. The conclusion is that richer frozen language representations directly improve both semantic adherence and speech intelligibility.
| Conditioning | Arch | Params | FD ↓ | CLAP ↑ | WER-EN ↓ |
|---|---|---|---|---|---|
| O (deep fusion, 7B) | D24 | 732M | 20.46 | 0.180 | 4.33 |
| L (penultimate-layer, 7B) | D24 | 975M | 22.71 | 0.175 | 4.44 |
| OL (deep + penultimate, 7B) | D24 | 1,063M | 20.18 | 0.187 | 5.52 |
| O (deep fusion, 7B) | S32 | 685M | 23.19 | 0.169 | 4.84 |
| O (deep fusion, 3B) | D24 | 694M | 21.53 | 0.174 | 5.61 |
These ablations reinforce the paper’s main narrative: depth-matched deep fusion is better than a single-layer broadcast, the double-stream design is necessary for modality separation, and more capable frozen language models yield better audio generation and editing behavior.
Architectural Positioning Relative to Prior Unified Audio Systems
The paper positions UNISON against systems such as Audio-Omni and UniSonate. Compared with Audio-Omni, which uses a penultimate MLLM layer via cross-attention and a separate mel stream for some tasks, UNISON uses layer-wise fusion, plain-text instructions, and the same VAE for source and target audio. Compared with UniSonate, which relies on phoneme/G2P front-ends and does not support editing or reference-based cloning, UNISON keeps text as plain language instructions, supports bilingual zero-shot TTS, and includes scene-level editing and timed composition. The authors argue that this gives a cleaner and more general unified architecture.
Limitations
- VAE reconstruction quality is a bottleneck. The pre-trained MMAudio VAE was designed for environmental audio, so speech details such as high-frequency formants, fine prosody, and breathy or whispered qualities can be smoothed out. This especially affects zero-shot TTS.
- Editing data is synthetic. The editing and T2AS data are algorithmically mixed from open-source clips. The authors note that this does not capture real-room acoustics, reverberation, occlusion, Lombard effects, or naturally verified captions.
- Scale is moderate. The model is smaller than some recent large unified systems and trained on about 36M clips. The paper suggests that the architecture should scale further with larger backbones and more data.
- Language and domain coverage are limited. The system supports English and Chinese speech, but not other languages without added data. Music generation is explicitly not targeted in this work.
Conclusion
UNISON demonstrates that a single 621M--732M parameter checkpoint can cover speech generation, sound generation, speaker cloning, mixed speech-and-sound synthesis, and several editing modes without task-specific modules. Its main technical ideas are the shared latent-space formulation, the channel-mask representation for task identity, and the layer-wise deep fusion of a frozen large language model into a diffusion transformer. Across the reported benchmarks, the model is competitive with or better than specialist baselines, and in several settings it surpasses much larger unified systems. The paper’s overall message is that multi-task audio generation can benefit from architectural simplicity, depth-aligned language conditioning, and a well-controlled online synthesis curriculum rather than from proliferating modality-specific branches.