SALSA
SALSA: Speech Aware LLM Adaptation via Learned Steering Activation Vectors
SALSA adapts speech-aware large language models by learning layer-wise steering vectors with a supervised objective, boosting out-of-domain speech robustness. It aligns acoustic representations with pretrained language models without tuning model weights, enabling efficient, effective speech adaptation.
Links
Paper & demos
Abstract
Speech-aware large language models often generalize poorly to out-of-domain settings. We propose SALSA (Speech-Aware LLM Adaptation via Learned Steering Activations), a lightweight adaptation method that learns layer-wise steering vectors. Unlike commonly used steering approaches that rely on contrastive activation differences, SALSA directly optimizes steering vectors using a supervised objective. Across children's speech, multilingual speech, and Mandarin-English code-switching benchmarks, SALSA substantially improves performance over zero-shot inference and speech in-context learning baselines, achieving up to 46.8% relative improvements over zero-shot. Analysis further demonstrates that steering the encoder, particularly the later layers, is more effective than steering the LLM backbone. These findings suggest that steering improves downstream ASR performance by adapting higher-level acoustic and phonetic representations to better align with the pretrained language model representation space, rather than by modifying the decoder itself.
Introduction
SALSA addresses a recurring failure mode of speech-aware large language models (SALLMs): strong in-domain performance but weak robustness when the audio distribution shifts. The paper argues that, for automatic speech recognition (ASR), the key challenge is often not the absence of linguistic knowledge in the pretrained model, but a mismatch between acoustic/phonetic representations and the pretrained language model's decoding space. This mismatch becomes especially visible on out-of-domain speech such as children's speech, multilingual speech, and Mandarin-English code-switching.
The proposed method, SALSA (Speech-aware LLM Adaptation via Learned Steering Activations), is a lightweight adaptation approach that learns layer-wise steering vectors directly from supervision. Unlike contrastive steering methods that derive a direction from paired positive/negative examples, SALSA optimizes the steering vectors end-to-end using transcript supervision, while keeping the entire speech-language backbone frozen. This makes the method especially attractive when paired contrastive speech examples are scarce or noisy.
The paper's main empirical claims are:
- SALSA improves ASR performance over both zero-shot prompting and speech in-context learning (TICL) on children's speech, multilingual speech, and code-switched speech.
- It can deliver very large gains, reaching up to 46.8% relative improvement over zero-shot on SEAME with Qwen2-Audio-7B-Instruct.
- Encoder steering is substantially more effective than steering the language-model backbone, and later encoder layers matter more than earlier ones.
- The learned interventions are data-efficient: useful gains appear with only a few hundred adaptation examples in several settings.
Background and problem setting
The paper situates SALSA in the broader SALLM design pattern: a pretrained speech encoder is coupled to a pretrained LLM backbone, with a lightweight projection layer bridging the two modalities. Systems in this family include SALMONN, WavLLM, Qwen-Audio/Qwen2-Audio, and Granite-Speech. They can be effective for a variety of speech tasks, but they are often trained on relatively limited speech data and skew toward a small set of languages, which leaves them vulnerable to hallucination and poor generalization on underrepresented or out-of-domain speech.
Prior adaptation options have trade-offs. Full fine-tuning and parameter-efficient methods such as LoRA update model weights and therefore still require gradient-based weight adaptation. In-context learning is training-free, but the speech modality is hard for retrieval-based prompting because acoustic examples vary by speaker, accent, prosody, and recording conditions. The paper argues that this variability makes demonstrations less reliable than in text-only settings.
Representation steering is the alternative foundation used here. In a generic form, if a model has a hidden state $h_l$ at layer $l$, steering modifies it as
$$ \tilde{h}_l = f(h_l, v, \alpha), $$
where $v$ is a direction or learned transformation and $\alpha$ controls strength. A common additive form is $\tilde{h}_l = h_l + \alpha v$. Earlier steering work often computed $v$ from contrastive activation differences, for example by averaging $h_l^+ - h_l^-$ over paired examples. The paper's key methodological move is to replace that contrastive construction with direct supervised learning over ASR transcripts.
Method: learned steering vectors for speech adaptation
SALSA learns a set of steering vectors $\mathcal{V} = \{v_l\}_{l=1}^{L}$, one per selected layer, where each $v_l \in \mathbb{R}^d$ and $L$ is the number of steered layers. The backbone model parameters $\theta$ remain frozen throughout training. The hidden representation at layer $l$ is modified by an additive intervention:
$$ \tilde{h}_l = h_l + v_l. $$
To stabilize the intervention, the paper applies a norm-preserving update:
$$ \tilde{h}_l = \frac{h_l + v_l}{\|h_l + v_l\|} \cdot \|h_l\|. $$
This keeps the activation magnitude fixed and changes only the direction of the representation. The intuition is that steering should shift the representation geometry without causing the optimization to exploit trivial norm inflation.
Training uses the autoregressive cross-entropy loss over the transcript:
$$ \mathcal{L}(\mathcal{V}) = -\mathbb{E}_{(x, y^\star)}\left[\sum_{t=1}^{|y^\star|} \log p_{\theta,\mathcal{V}}\left(y_t^\star \mid x, y^\star_{<t}\right)\right]. $$
All optimization happens in the steering vectors; the speech encoder, projection modules, and LLM backbone are frozen. This is what makes SALSA lightweight relative to fine-tuning.
The training configuration is intentionally simple: AdamW, learning rate in $\{10^{-4}, 5 \times 10^{-4}\}$, batch size 1, gradient clipping at norm 1.0, up to 20 epochs, and early stopping with patience 3 based on validation WER. At inference time, the learned vectors are injected into the chosen layers using the same norm-preserving update. The paper studies three intervention locations:
- Encoder-only steering: applied to the audio encoder hidden states.
- Decoder-only steering: applied to the audio-conditioned hidden states inside the language-model backbone.
- Joint steering: applied to both modules simultaneously.
The central empirical question is whether adaptation should happen in the acoustic encoder, in the language-model backbone, or in both.
Datasets, models, baselines, and evaluation
The experimental design spans three speech conditions: children's speech, multilingual speech, and code-switched speech. The datasets and split statistics reported in the appendix are:
| Dataset | Train | Dev | Test |
|---|---|---|---|
| MyST | 73425 | 11732 | 12744 |
| OGI | 50439 | 5482 | 16078 |
| RSR | 13222 | 1467 | 2027 |
| SEAME dev-man | 48297 | 4763 | 0 |
| SEAME dev-sge | 48297 | 1749 | 0 |
| CommonVoice Russian (cv-ru) | 26920 | 10282 | 10283 |
| CommonVoice Twi (cv-tw) | 213 | 0 | 30 |
Children's speech includes three corpora. MyST is conversational American English speech from elementary-school children interacting with a virtual science tutor. OGI Kids' Speech contains read and spontaneous speech from children spanning grades K-10. RSR is a speech recall dataset collected from K-3 children during a screening task for developmental language disorder.
Multilingual speech is evaluated on CommonVoice 25.0 Russian and Twi. Russian is used as a language that the paper says is represented during pretraining of both the Qwen2-Audio encoder and the LLM backbone, while Twi is described as absent from both models' pretraining. SEAME is used as a Mandarin-English code-switching benchmark, testing whether the model can handle intra-utterance switching between languages that are individually known.
The two backbone models are:
- Qwen2-Audio-7B-Instruct: an open-weight SALLM with a Whisper-based speech encoder and the QwenLM backbone. It supports voice chat and audio analysis, and is instruction-tuned for audio-related prompts.
- Granite-Speech-3.3-8B: a SALLM with 10 conformer encoder blocks trained with CTC on ASR-focused data, a two-layer Q-Former projector, and LoRA adapters (rank 64) on the query and value projections.
The primary baseline is TICL (speech in-context learning), which retrieves semantically similar demonstrations from a candidate set. In the scaling experiments, the corresponding training split is used as the retrieval candidate set. For Qwen2-Audio, demonstrations are prepended directly; for Granite-Speech, they are inserted as prior dialogue turns to match the model's input format. The paper also reports zero-shot inference as the no-adaptation baseline.
Performance is measured using word error rate (WER) and mixed error rate (MER). If $S$, $D$, and $I$ are substitutions, deletions, and insertions, and $N$ is the number of reference tokens, then
$$ \mathrm{ErrorRate} = \frac{S + D + I}{N}. $$
WER is computed at the word level. MER follows standard Mandarin-English code-switched evaluation, using word tokens for English and character tokens for Mandarin. All decoding is greedy autoregressive decoding. WER and MER are computed with jiwer under standard normalization settings. Results are reported as mean and standard deviation over five independently sampled training subsets, using seeds 42-46.
The paper also notes that experiments were run on NVIDIA A40 GPUs, and that SALSA remains computationally efficient because only the steering vectors are trained.
Main experimental results
The central result is that learned steering vectors can match or beat retrieval-based adaptation in several out-of-domain speech settings, especially when the target distribution is acoustically different but still related to the pretraining distribution.
| Model | n | System | MyST | OGI | RSR | SEAME dev-man | SEAME dev-sge |
|---|---|---|---|---|---|---|---|
| Granite-Speech-3.3-8B | -- | zero-shot | 27.14 | 28.11 | 27.94 | 88.02 | 72.63 |
| 500 | TICL | 33.81 ± 2.16 | 24.91 ± 1.77 | 42.70 ± 9.43 | 365.61 ± 25.31 | 248.86 ± 10.11 | |
| SALSA | 24.56 ± 0.03 | 14.95 ± 1.13 | 17.13 ± 0.43 | 87.22 ± 0.26 | 73.49 ± 1.17 | ||
| 2000 | TICL | 31.78 ± 5.34 | 17.35 ± 0.20 | 38.85 ± 3.85 | 336.97 ± 33.02 | 224.39 ± 11.39 | |
| SALSA | 24.10 ± 0.07 | 12.28 ± 0.37 | 14.46 ± 0.39 | 87.40 ± 0.50 | 73.88 ± 1.57 | ||
| Qwen2-Audio-7B-Instruct | -- | zero-shot | 30.51 | 20.51 | 28.60 | 88.46 | 73.05 |
| 500 | TICL | 21.97 ± 0.12 | 16.14 ± 0.66 | 30.29 ± 6.48 | 188.75 ± 18.93 | 174.46 ± 17.76 | |
| SALSA | 24.92 ± 0.40 | 14.69 ± 1.32 | 18.89 ± 0.24 | 52.87 ± 1.61 | 44.10 ± 2.30 | ||
| 2000 | TICL | 22.09 ± 0.23 | 14.40 ± 9.54 | 28.19 ± 2.26 | 173.59 ± 4.36 | 159.12 ± 11.32 | |
| SALSA | 38.68 ± 8.24 | 12.07 ± 0.45 | 15.84 ± 0.33 | 47.03 ± 1.67 | 40.12 ± 1.42 |
On Granite-Speech-3.3-8B, SALSA consistently improves over zero-shot inference on children's speech. The largest gains are on OGI and RSR at $n=2000$, where the paper reports relative WER reductions of 56.3% and 48.2%, respectively. SALSA is also much more stable than TICL on SEAME, where TICL catastrophically degrades performance and SALSA stays close to the zero-shot baseline. MyST improves at both steering sizes on Granite, with SALSA reducing WER from 27.14 to 24.56 at $n=500$ and to 24.10 at $n=2000$.
On Qwen2-Audio-7B-Instruct, SALSA strongly improves OGI, RSR, and SEAME, but MyST behaves differently: the method improves MyST at $n=500$ yet degrades sharply by $n=2000$. This is one of the paper's most important caveats: steering vectors are shared across all utterances, so highly heterogeneous speech distributions can produce less coherent adaptation when more data is added. The paper interprets MyST as a case where intra- and inter-speaker variability may make the learned direction noisy or inconsistent.
For SEAME on Qwen2-Audio, SALSA is one of the strongest results in the paper: the model reaches 47.03 MER on dev-man and 40.12 MER on dev-sge at $n=2000$, which the authors describe as up to a 46.8% relative improvement over zero-shot. This supports the paper's claim that steering can adapt higher-level acoustic and phonetic representations to better align with multilingual language-model space, rather than modifying the decoder directly.
The paper also reports results on CommonVoice Russian and Twi:
| Dataset | n | Zero-shot | TICL | SALSA |
|---|---|---|---|---|
| cv-tw | 200 | 108.36 | 106.32 ± 0.00 | 87.54 ± 2.10 |
| cv-ru | 200 | 87.50 | 122.07 ± 3.21 | 28.33 ± 0.49 |
| cv-ru | 500 | 87.50 | 121.90 ± 3.79 | 26.84 ± 0.34 |
| cv-ru | 2000 | 87.50 | 119.29 ± 1.28 | 24.65 ± 0.07 |
These CommonVoice results reinforce the same theme: TICL often offers little benefit or hurts performance, while SALSA can recover large gains, especially on Russian, where the paper argues that the main problem is not language acquisition but alignment between the encoder and decoder spaces.
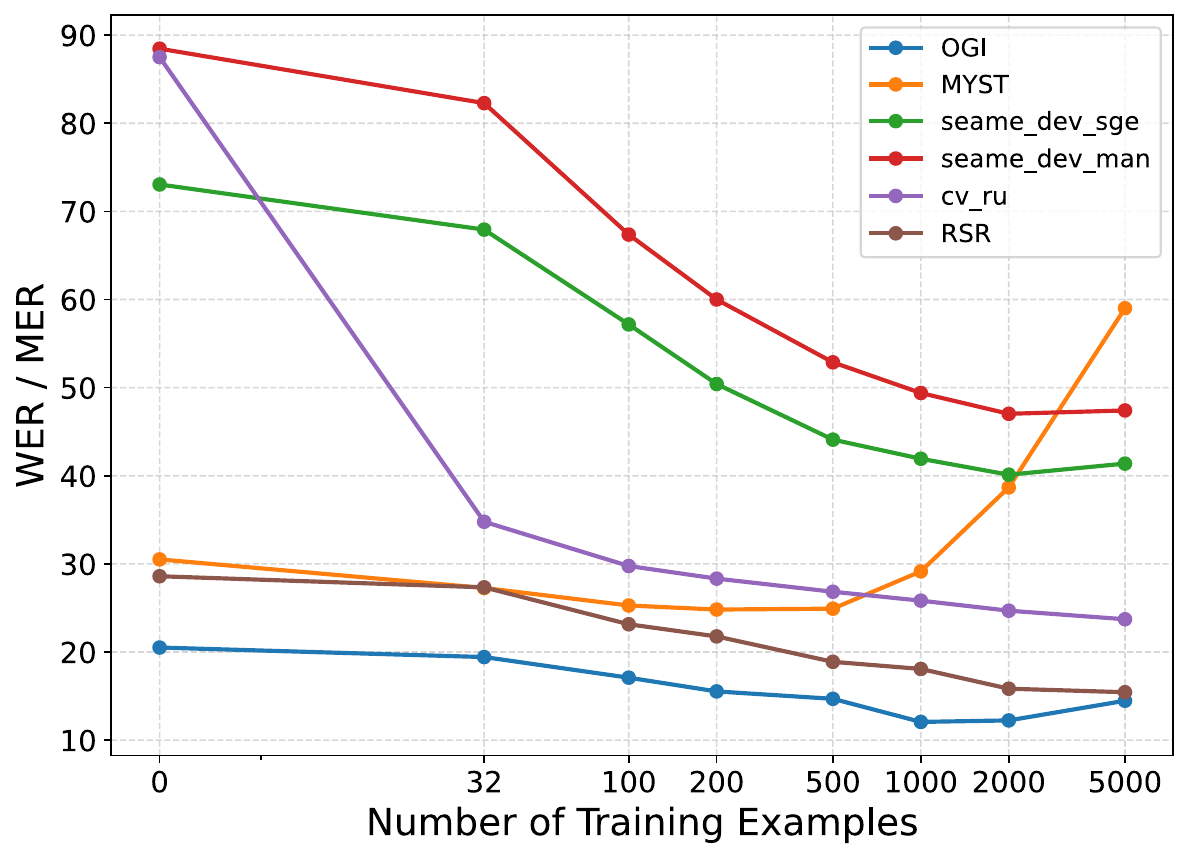
The scaling plot above shows that SALSA is data-efficient: large fractions of the improvement on OGI, RSR, and SEAME appear with only a few hundred examples, and gains tend to saturate beyond roughly 2000 examples. The strongest monotonic improvements are on RSR and SEAME. MyST is the exception, where more data eventually hurts performance, highlighting sensitivity to heterogeneity.
Analysis: where steering helps and why
The paper decomposes SALSA's behavior along three axes: training set size, the model module being steered, and the depth of the steered encoder layers. The overall conclusion is that adaptation works best when the intervention changes higher-level encoder representations, not the decoder.
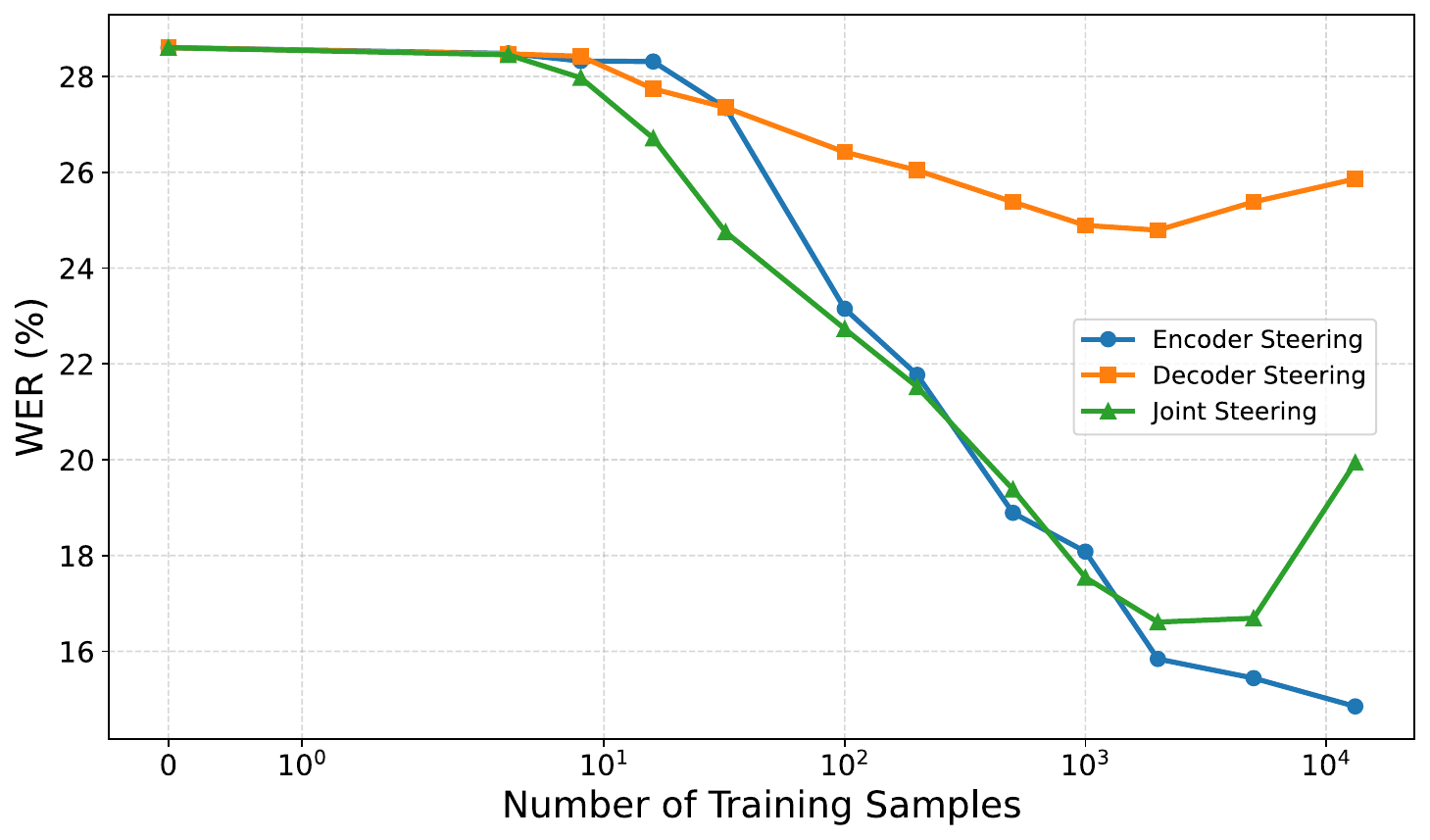
The module-level analysis on RSR shows that encoder steering is consistently better than decoder-only steering. Decoder steering provides only modest gains and saturates quickly, whereas encoder steering keeps improving as the training set grows. Joint steering does not reliably outperform encoder-only steering; in the paper's interpretation, intervening in the decoder can interfere with the pretrained linguistic representations of the backbone.
This is an important architectural conclusion: when the encoder and the LLM backbone already have some exposure to the target languages during pretraining, the best adaptation path is usually to modify the acoustic side before projection into the language model. That is, SALSA appears to work by better aligning speech representations with the decoder's existing space, not by rewriting the decoder itself.
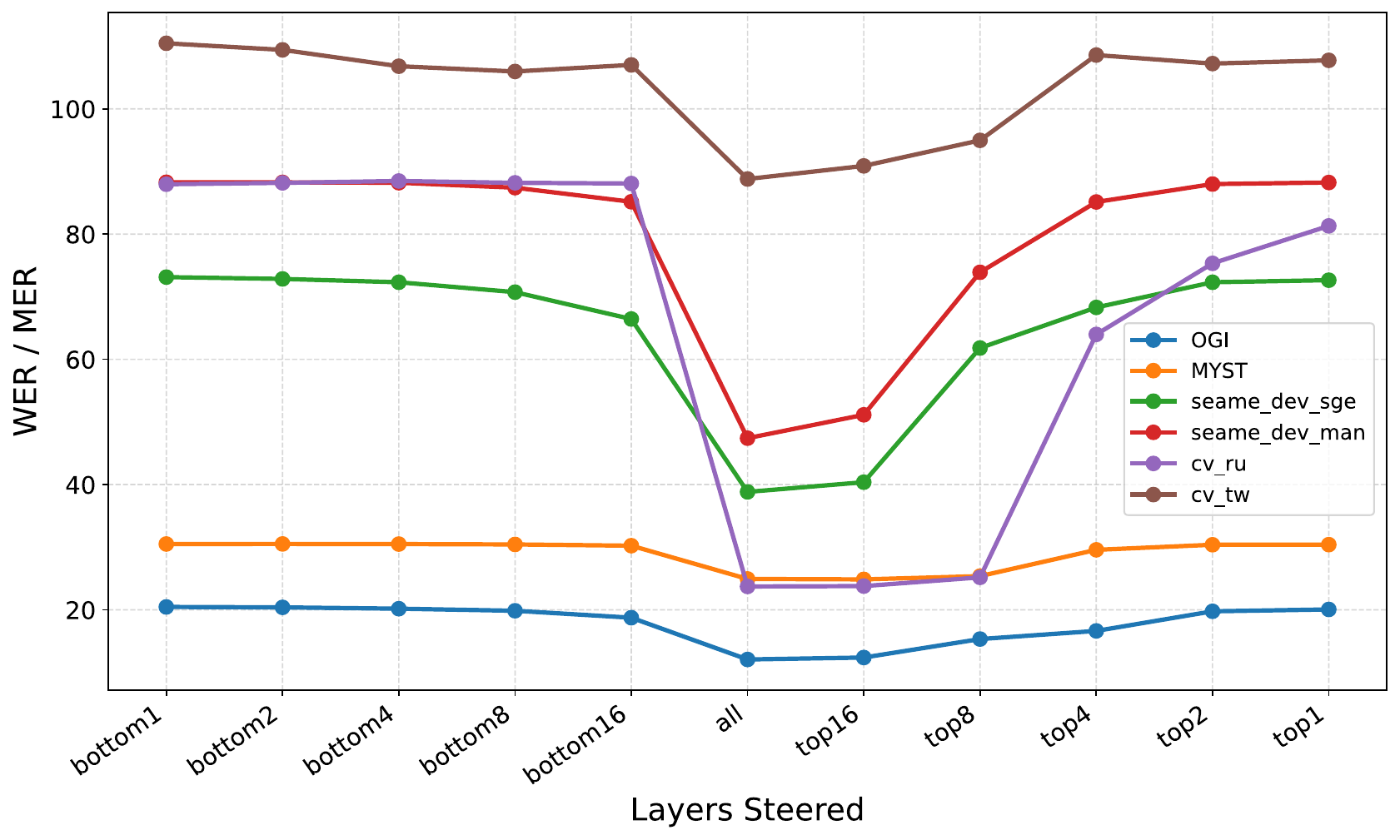
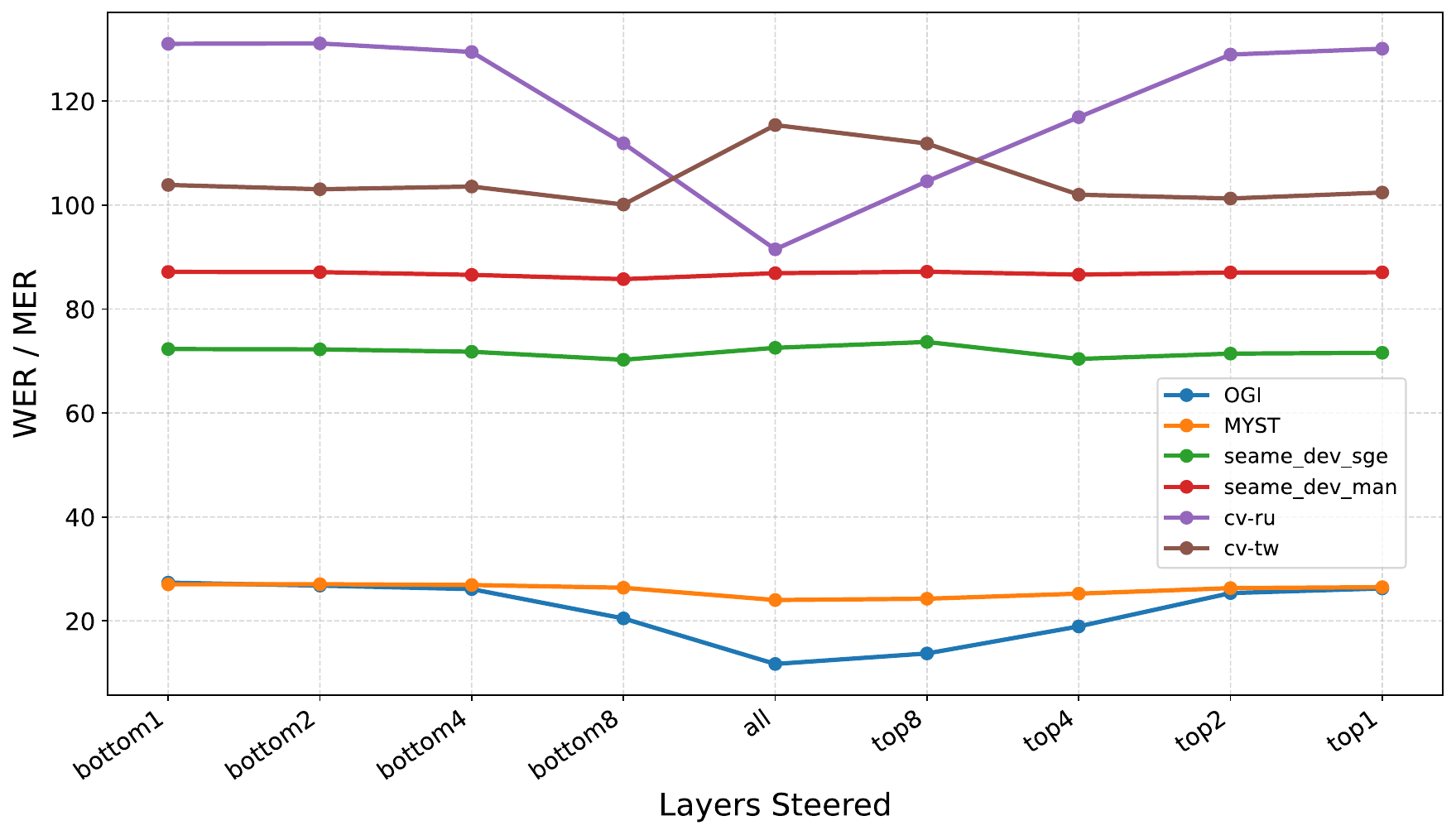
The layer-level ablation shows a consistent pattern for Qwen2-Audio: steering later encoder layers is much more effective than steering only the earliest layers. As progressively larger upper-layer subsets are steered, performance approaches that of steering the full encoder. Lower-layer steering alone yields limited benefit. The same trend is visible for Granite-Speech, though somewhat less sharply.
The paper's interpretation is grounded in the usual abstraction hierarchy of speech encoders: earlier layers retain lower-level acoustic detail, while later layers encode more task-relevant phonetic and linguistic structure. SALSA is therefore most useful when it shifts the representations that are closest to the projection interface with the LLM.
There is one notable exception: on Granite-Speech with Twi, lower-layer steering can outperform upper-layer steering. Since Twi is absent from the pretraining exposure of both modules, the authors interpret this as evidence that when higher-level linguistic structure is weak or absent, adaptation may need to work through more primitive acoustic representations. This exception does not negate the main result, but it does suggest that the best steering depth depends on how much target-language structure the pretrained model already contains.
For Qwen2-Audio, the appendix tables provide detailed layer-ablation values. Steering the full encoder yields the best or near-best results on the main datasets, while steering only the bottom layers can be dramatically worse. For example, on OGI, full steering reaches 12.07 WER, while steering only the first 1, 2, 4, or 8 layers leaves WER much higher. Similar gaps appear on MyST, SEAME, and CommonVoice Russian. These numbers reinforce the paper's core argument that later encoder layers are the most useful adaptation target.
The paper also presents scaling tables for module choice. On RSR, encoder steering improves as the number of examples increases from a few dozen to the full training set, decoder steering stays comparatively flat, and joint steering does not create a consistent advantage. The fine-grained numbers are less important than the overall shape: encoder-side interventions dominate.
Interpretation and contributions
The paper's contributions are methodological and empirical:
- A new training-based steering method for speech. SALSA learns steering vectors directly from ASR supervision instead of extracting them from contrastive pairs.
- A lightweight adaptation mechanism. Only the steering vectors are trained, and the backbone remains frozen, making the method substantially cheaper than full fine-tuning.
- Evidence that encoder-side steering is the right place to intervene. The best results come from modifying speech encoder representations, especially in later layers.
- Cross-condition validation. The method is evaluated on children's speech, multilingual speech, and code-switched speech, showing that the technique generalizes across distinct out-of-domain scenarios.
Conceptually, the paper's strongest claim is that adaptation in SALLMs is often an alignment problem rather than a knowledge-acquisition problem. If the language model already knows the target language to some extent, the adaptation bottleneck may be the acoustic representation interface. SALSA attacks exactly that bottleneck.
Limitations and ethical considerations
The authors explicitly limit the scope of the paper to ASR on two SALLMs. They caution that the best steering location may depend on architecture and training objective, so the findings may not transfer unchanged to other models. Another limitation is that SALSA learns a single shared set of steering vectors for all utterances in a dataset; highly heterogeneous speech distributions may therefore require input-dependent or speaker-specific steering.
The paper also emphasizes that its experiments cover only a limited set of languages, speech conditions, and tasks. Broader evaluation is needed to understand generalization and fairness implications.
From an ethical perspective, the authors note that speech recognition systems remain susceptible to demographic and linguistic bias. They also point out a subtle but important asymmetry: steering helps much more for languages already represented in pretraining than for completely unseen languages, which means such methods could reinforce existing inequalities in multilingual resource coverage if used uncritically. Finally, the paper states that all pretrained models and datasets were used according to their licenses and access agreements, and that some datasets carry restrictions on redistributing annotations or transcriptions.
Conclusion
SALSA shows that a simple, supervised, layer-wise steering intervention can be a strong adaptation mechanism for speech-aware LLMs. Without changing backbone weights, the method substantially improves ASR on children's speech, multilingual speech, and code-switched speech, often outperforming in-context learning baselines. The detailed ablations make the paper's broader point clear: the most effective adaptation path is usually to steer later encoder layers, which suggests that the critical mismatch lies in higher-level acoustic/phonetic representations rather than in the decoder itself.
The paper closes by proposing future work on input-dependent steering, where the intervention could adapt dynamically to each utterance's acoustics, and on extending steering-based adaptation beyond ASR.