LaSR
LaSR: Context-Aware Speech Recognition via Latent Reasoning
LaSR proposes a training method that embeds latent reasoning within the speech token stream to enable context-aware recognition of specialized terminology. This approach improves transcription accuracy on rare academic terms without adding inference latency by aligning reasoning supervision to the acoustic timeline.
Links
Paper & demos
Abstract
Recent advances in Speech Large Language Models (Speech LLMs) have significantly enhanced spoken language understanding and reasoning. However, their contextual awareness is limited, struggling to perform speech recognition that effectively reflects the speaker's intent and topical context. In this paper, we propose LaSR (Latent Speech Reasoning), a novel training paradigm featuring a context-aware reasoning trajectory that leverages the latent reasoning process. Instead of generating explicit intermediate tokens, LaSR aligns chain-of-thought (CoT) supervision around the acoustic feature region of the targeted word, and introduces latent reasoning periods for context information grounding and transcriptional transition. Furthermore, to effectively benchmark contextual recognition on specialized vocabulary, we propose Spoken Darwin-Science, a large-scale corpus focusing on academic terminologies. Preliminary experiments on Fun-Audio-Chat demonstrate that LaSR significantly improves terminology recognition without introducing additional latency and consistently outperforms standard supervised fine-tuning baselines. Our findings highlight the potential of latent reasoning in building efficient, context-aware speech assistants.
1. Problem Setting and High-Level Idea
The paper studies contextual automatic speech recognition (CASR) for speech large language models (Speech LLMs). The central challenge is that standard speech recognition systems often transcribe acoustically plausible words, but not necessarily the word that best matches the speaker’s intent, the topic, or the broader semantic context. This is particularly visible for rare or specialized terminology, where local audio evidence may be ambiguous and the model must use surrounding context to choose the intended transcription.
The authors argue that simply adding explicit chain-of-thought (CoT) output is not ideal for speech applications. In speech-to-text settings, visible reasoning tokens increase decoding latency and can destabilize transcription quality. Their goal is therefore to gain the benefits of reasoning without paying the runtime cost of generating explicit intermediate text.
Their proposed solution is LaSR (Latent Speech Reasoning), a training paradigm that injects CoT supervision into the latent processing of a Speech LLM. Instead of asking the model to emit the reasoning steps at inference time, LaSR aligns the reasoning supervision with the acoustic time region of the target word, so the model learns to ground context and pronunciation internally while keeping the external decoding path unchanged.
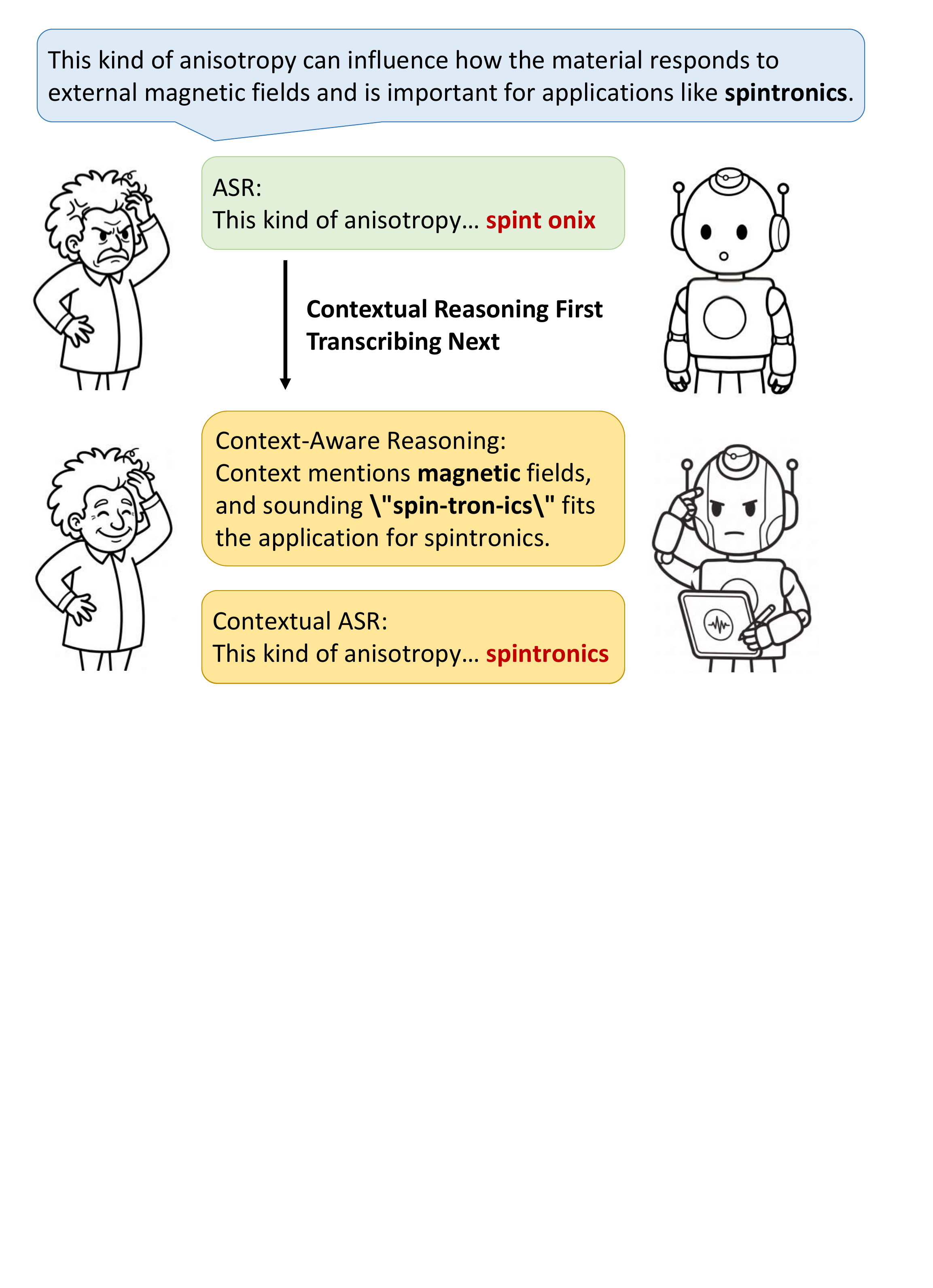
The motivating picture is that CASR should not simply recognize sounds, but should behave like a context-aware assistant that can infer the intended terminology from the local utterance and the conversation/topic background. The paper positions this as a natural testbed for Speech LLM reasoning: if a model can resolve scientific terminology from context, it suggests the model is able to integrate acoustic evidence with semantic inference in a time-sensitive setting.
2. Main Contributions
- A new training strategy, LaSR, that places latent reasoning and CoT supervision into the speech token stream around the target term, rather than generating explicit reasoning at inference time.
- A new benchmark corpus, Spoken Darwin-Science, designed specifically for contextual recognition of academic terminology in speech.
- An empirical demonstration that latent, time-aligned reasoning can improve terminology recognition on real scientific speech recordings without adding decoding latency in the standard inference setup.
3. Spoken Darwin-Science: Dataset Design and Construction
A major part of the paper is the creation of Spoken Darwin-Science, a terminology-centric speech corpus intended to make CASR genuinely challenging for modern Speech LLMs. The authors explicitly reject the common evaluation pattern of using generic conversational speech and then selecting low-frequency words from it. They argue that in the era of large-scale speech pretraining, rarity alone is no longer enough: models can often absorb frequent rare-word patterns simply through scale. To make contextual recognition harder and more relevant, they focus on scientific and academic terminology.
3.1 Terminology Definition
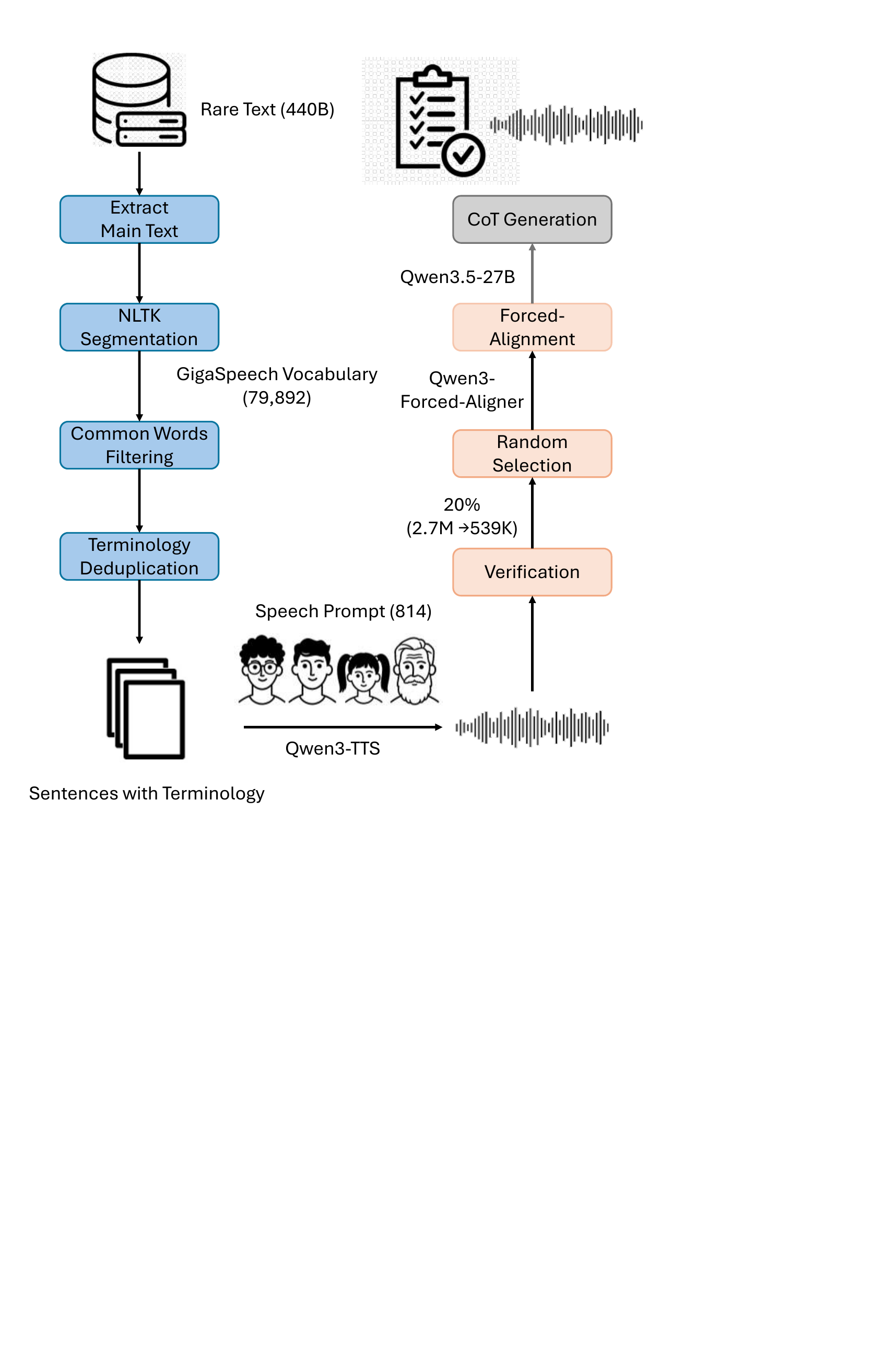
Terminologies are defined using the GigaSpeech-XL training vocabulary. The authors count word frequencies in GigaSpeech and define a terminology as a word that appears fewer than 10 times. They note that this threshold is manually verified. The vocabulary size referenced in the appendix is 79,892 words.
This definition creates a list of domain-relevant words that are uncommon in everyday speech but important in academic discourse, such as names from biology, chemistry, physics, engineering, medicine, and other scientific fields.
3.2 Training Corpus
The training corpus is built from Darwin-Science, a large collection of scientific papers that has already been cleaned through multiple stages. The paper states that the source text spans roughly 440B tokens. The authors keep the main text, remove around 200 characters from the beginning and end of each document, segment text into sentences with NLTK, and retain only sentences containing at least one terminology. They further keep at most five sentences per terminology and prioritize sentences containing a single term.
The resulting corpus contains 2,695,953 training instances and about 6,424.337 hours of synthesized speech. A randomly selected 20% subset used in most experiments contains 539,082 instances and 1,284.519 hours.
Speech is synthesized using Qwen3-TTS-1.7B. The appendix says the pipeline uses 814 different voice clips as prompts, and clips with DNSMOS Pro above 3 from CV3-Eval and seed-tts-eval are selected as speech prompts to ensure quality. The authors emphasize that Qwen3-TTS handles scientific terminology well because many terms are compositionally pronounceable from common phonetic units and compound-word structure.
3.3 Evaluation Set
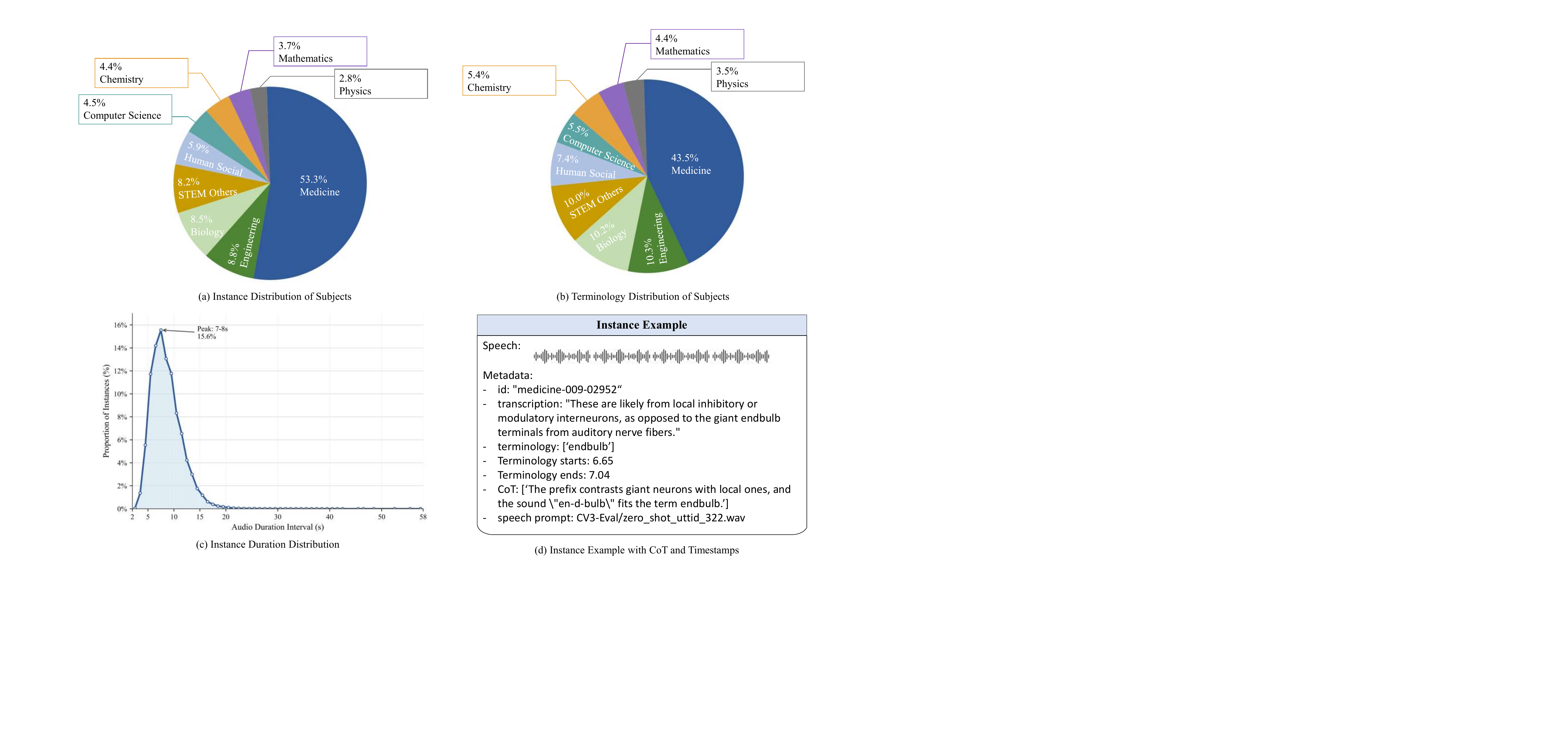
The evaluation set contains 2,000 real-world scientific speech segments totaling 6.081 hours. These are sourced from publicly available YouTube videos, including lectures, popular-science talks, documentaries, and TED talks with human-annotated subtitles. The domains include biology, medicine, chemistry, physics, geography, and general sciences. The authors parse metadata into timestamped segments, merge them using punctuation and interval constraints, keep segments that contain terminologies, and restrict clip length to at most 30 seconds.
3.4 CoT Annotation Strategy
For CoT supervision, the authors annotate only 20% of the training instances, corresponding to 539K examples. They describe this as a listen-while-think strategy: instead of using the entire full-text context to generate reasoning, they provide the terminology and its preceding text when prompting the reasoning model. The reasoning model is Qwen3.5-27B, which is instructed to infer the context and intent, decompose the pronunciation of the terminology, and then transcribe the word.
The paper also uses Qwen3-ForcedAligner to produce word-level timestamps so that the target terminology can be anchored to an approximate audio region during training.
3.5 Human Verification
To validate synthesis quality, the authors randomly sample 1,000 training examples and ask four English-fluent humans to verify pronunciation using mainstream online dictionaries. On average, the experts judge 96.8% of terminologies to be synthesized correctly and with normal pronunciation.
3.6 Subject Composition
Spoken Darwin-Science spans 9 scientific domains: medicine, engineering, biology, STEM (Others), human social, computer science, chemistry, mathematics, and physics. Medicine dominates the dataset, accounting for 53.3% of entries and 43.5% of the terminology. Engineering, biology, and STEM (Others) are the next most represented in terms of terminology contribution. The authors interpret this imbalance as a property of domain language: some fields contain more everyday vocabulary and therefore fewer specialized terms.
4. LaSR Method
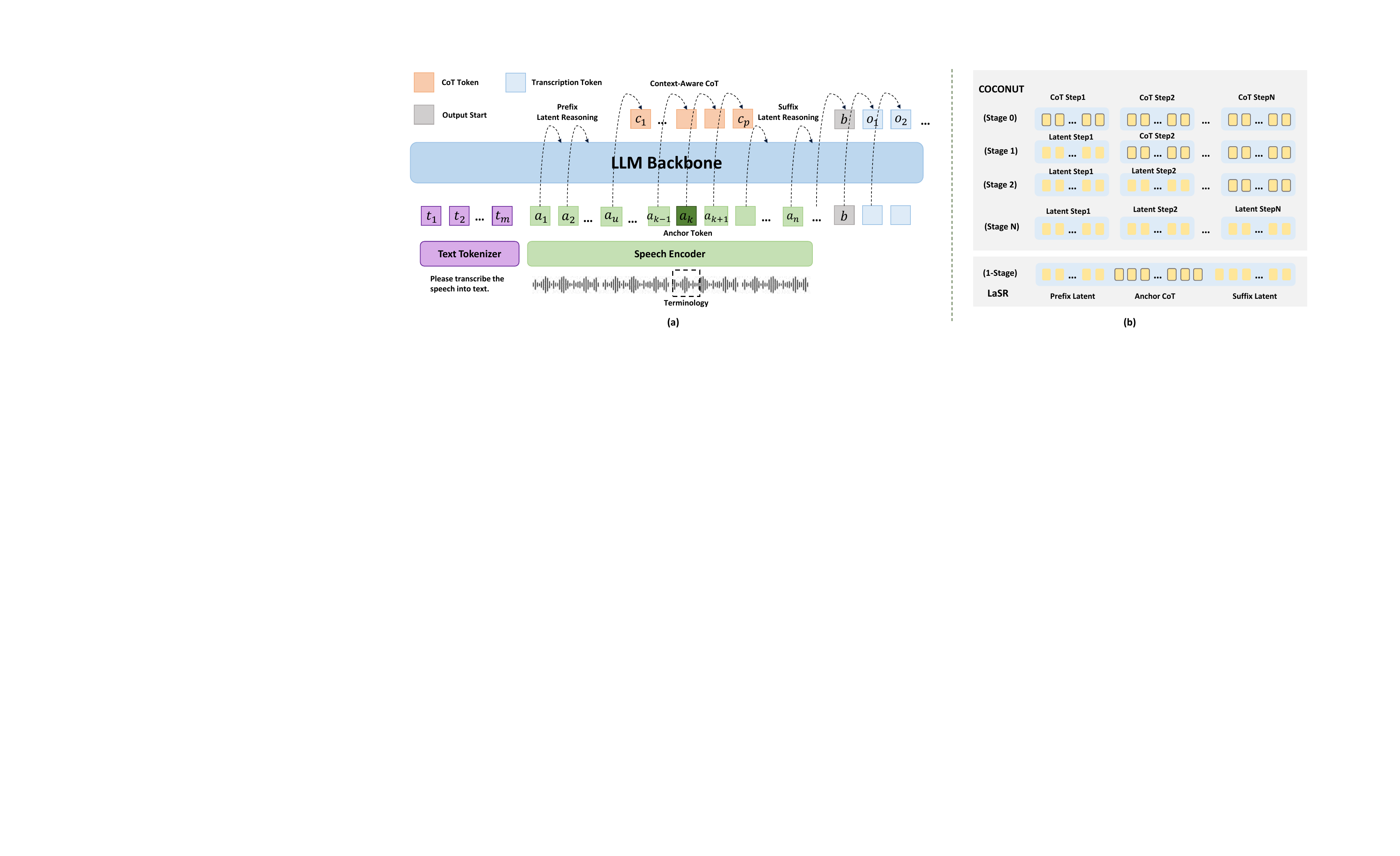
LaSR modifies training, not inference. The key idea is to treat reasoning as a latent trajectory aligned to the speech timeline. During training, the speech input is tokenized/encoded into a sequence of audio features, and the model is exposed to a structured causal pattern with three phases:
- Prefix latent reasoning before the anchor region.
- Explicit CoT supervision around the target terminology’s acoustic region.
- Suffix latent reasoning after the CoT span, before the final transcription output.
This is intended to help the model ground contextual information before the terminology is heard, reason about pronunciation and identity when the acoustics of the term become salient, and then smoothly transition into the final transcription.
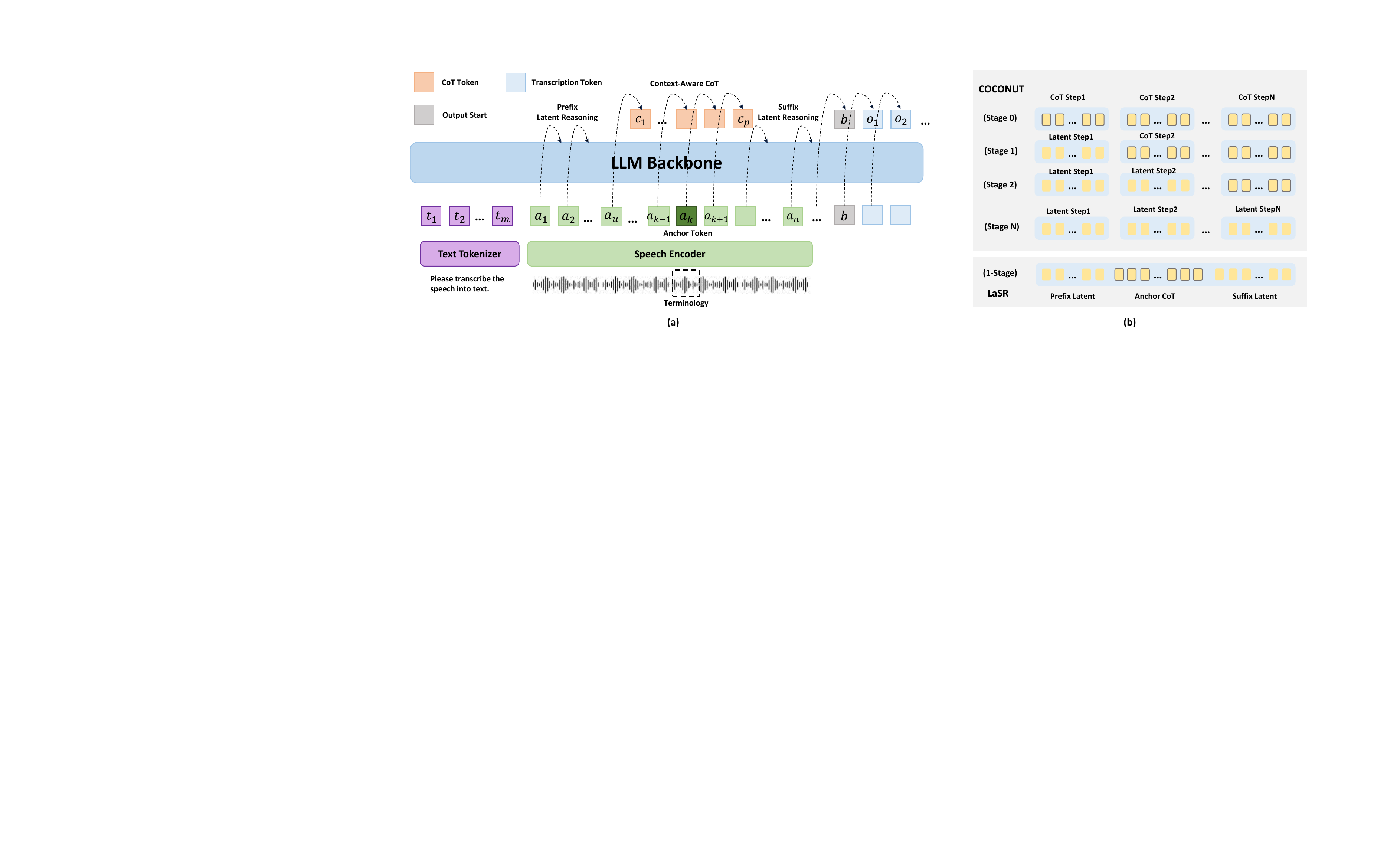
4.1 Anchor-Time Alignment
The paper defines a terminology start time $\tau$ obtained by forced alignment. For a speech input of duration $d_a$ represented with $n$ audio tokens, the anchor token index is computed in the non-streaming setting as
$$k = \left\lfloor \frac{\tau}{d_a} n \right\rfloor$$
This anchor is the key time point at which the terminology is most influential in the input stream. The CoT supervision is placed around this anchor rather than being generated as a visible textual rationale. The authors consider three alignment variants in experiments:
- After-anchor: shift CoT to the right by about $0.15$ s.
- Before-anchor: shift CoT to the left by about $0.50$ s.
- Random: place CoT earlier than the anchor while ensuring the anchor token remains inside the CoT region.
The paper argues that the model should first perceive the topic and intent, then infer the terminology pronunciation and grapheme, and only then move on to the final transcription. This is why the CoT region is time-aligned rather than simply appended as a separate textual explanation.
4.2 Training Objective
Implementation-wise, audio placeholder labels are overwritten with tokenized latent CoT labels across a contiguous region, until the CoT sequence ends or the audio suffix runs out. The visible assistant output contains only the transcription target. Therefore, the latent reasoning is trained as hidden supervision rather than emitted output.
The language-model loss is a standard next-token cross-entropy computed over the union of the ASR transcription positions and the latent CoT positions:
$$\mathcal{L}_{\mathrm{LM}} = - \frac{1}{L} \sum_{i\in \Omega_{\mathrm{ASR}} \cup \Omega_{\mathrm{CoT}}} \log p_\theta(y_i \mid x_{
where $L = |\Omega_{\mathrm{ASR}} \cup \Omega_{\mathrm{CoT}}|$ and the input sequence contains text instruction tokens, audio features, a response-start token $b$, and the output transcription $O = (o_1, \dots, o_q)$.
The authors emphasize that LaSR differs from text-only latent reasoning methods such as COCONUT. Those methods usually compress or replace explicit reasoning trajectories in language. LaSR instead exploits the temporal structure of speech: it fixes anchor points in the acoustic stream and lets the model think before and after those points. The intention is to make reasoning compatible with streaming-like speech semantics while avoiding explicit reasoning output.
A practical point is that LaSR does not require token-by-token generation of reasoning at inference time. The latent supervision is only used during training, so standard batched prefill and autoregressive transcription remain available at test time.
The paper evaluates LaSR on contextual terminology recognition using both ASR backbones and a stronger speech-LLM backbone. The primary benchmark backbone is Fun-Audio-Chat-8B, and the authors also report results on Qwen3-ASR-0.6B and Qwen3-ASR-1.7B. As a non-LLM reference, they also report Whisper-large-v3 on the evaluation set.
For the ASR models, training uses 1 NVIDIA A100 GPU; Fun-Audio-Chat uses 8 A100 GPUs through LLaMA-Factory. The authors evaluate with two metrics: WER for overall transcription accuracy and EER for terminology recognition. EER is reported for the Base set, the Hard set, and the combined All set.
The Base set consists of terminology with frequency between 1 and 9 in GigaSpeech-XL, while the Hard set consists of out-of-vocabulary words.
These results establish the starting point for the contextual recognition study. Whisper-large-v3 has the lowest WER among the reported baselines, while the Speech LLM baseline Fun-Audio-Chat-8B provides a strong platform for reasoning-based intervention because it already supports multimodal interaction and post-training.
The core result is that LaSR improves terminology recognition without adding inference latency, and it does so more effectively than standard SFT or explicit autoregressive CoT generation when applied to the Fun-Audio-Chat-8B backbone.
The key comparisons are as follows:
The improvement is especially strong on the hard terminology set: the hard-set EER falls from 32.74% to 25.00%. The paper stresses that this is more than twice the improvement obtained by non-thinking SFT.
The paper’s main conceptual ablation is where to place the latent CoT span relative to the anchor word. The results suggest that giving the model more room to absorb the surrounding acoustic evidence before the CoT span starts is beneficial. In particular, the before-anchor configuration at $-0.50$ s performs best. The authors interpret this as evidence that contextual reasoning should begin early enough to capture topic and intent, while still staying aligned to the target word region.
By contrast, placing the CoT too aggressively after the anchor or using explicit reasoning tokens in an autoregressive manner can hurt recognition. The overall takeaway is that the speech model benefits not from visible reasoning output, but from time-aligned latent supervision.
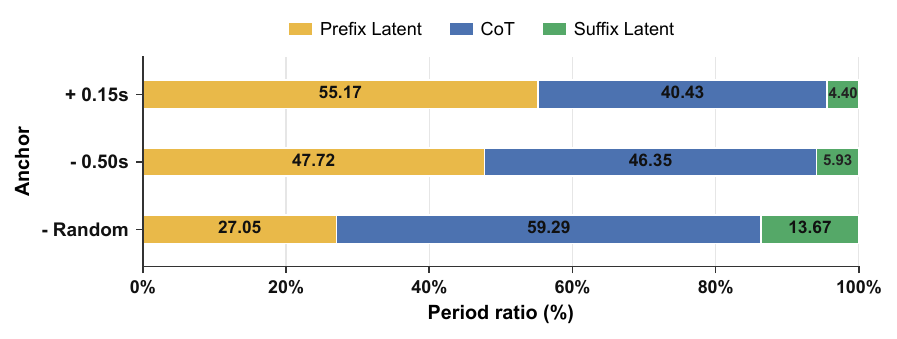
The authors further analyze how much of the sequence is spent in prefix latent reasoning, CoT supervision, and suffix latent reasoning under different anchor strategies. Their conclusion is that the prefix latent reasoning phase and the CoT region should receive the largest share of the reasoning budget.
The reported trend is that a longer prefix reasoning stage helps the model capture context and produce more plausible reasoning behavior. The suffix latent stage is the smallest and can even be absent in some samples. In the random pre-position experiments, extending suffix latent reasoning slightly degrades performance. The authors interpret this as evidence that the model should spend more of its latent capacity on contextual perception and acoustic grounding than on late-stage response planning.
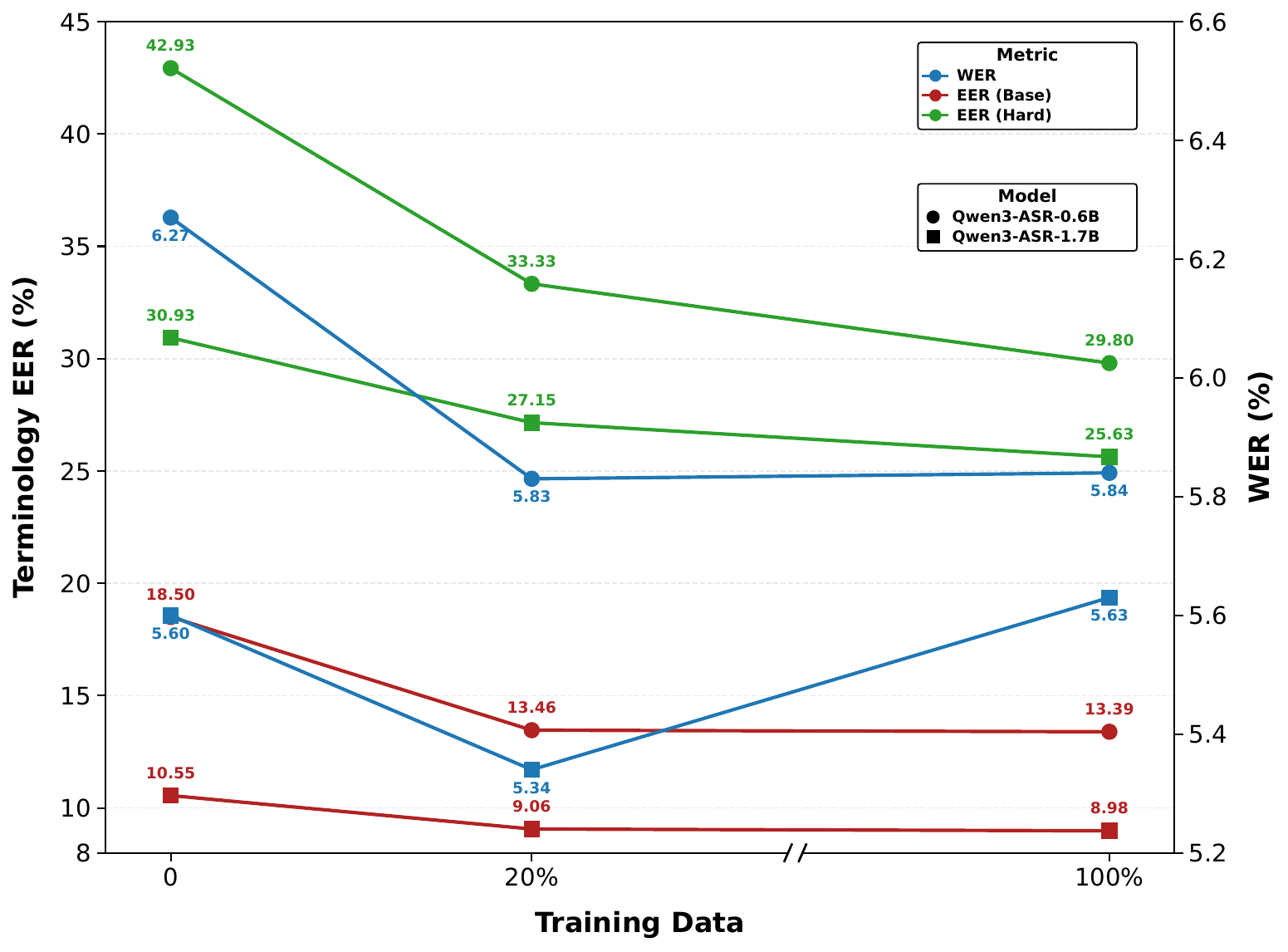
The paper also tests LaSR on Qwen3-ASR-1.7B to understand how model capacity affects the usefulness of latent reasoning. This is important because a reasoning-heavy training scheme may help a more capable backbone while interfering with a smaller one.
On this backbone, SFT is clearly the strongest method. Explicit AR CoT severely degrades both WER and terminology recognition. LaSR is better than AR CoT, but it still underperforms the non-thinking SFT baseline. The paper uses this to make a nuanced point: LaSR requires sufficient reasoning capability in the backbone. If the model is too small or too weak in latent reasoning, adding additional thinking content can become interference rather than help.
A central claim of the paper is that LaSR improves contextual recognition without adding extra latency. The appendix explains that at inference time LaSR does not decode latent CoT tokens. The latent reasoning exists only as training supervision on selected audio-placeholder positions, so standard non-streaming ASR decoding can use a single batched prefill pass followed by autoregressive transcription.
The authors compare two decoding modes and show that the recognition differences are negligible, while the real-time factor changes substantially when the decoding scheme is made sequential.
The reported RTF increase in the sequential mode is large, but the accuracy differences are small. This supports the paper’s claim that LaSR itself does not impose an inference-time cost when used as intended: the model need not emit latent reasoning tokens during decoding.
The empirical story across datasets and ablations is fairly consistent. First, training on the proposed terminology-centric corpus transfers to real recordings and improves recognition of scientific terms. Second, visible CoT generation is not suitable for speech transcription because it adds latency and can destabilize recognition. Third, latent reasoning is most effective when it is time-aligned to the speech stream, especially around the terminology region. Finally, the gains are strongest when the backbone has enough capacity to absorb the reasoning signal.
The paper’s broader message is that context-aware speech assistants should not be forced to choose between reasoning quality and latency. LaSR provides one concrete way to push some of the reasoning burden into latent training-time supervision so that the deployed model remains fast.
LaSR is a training-only method for contextual speech recognition that uses time-aligned latent reasoning to make a Speech LLM more sensitive to topic and intent when transcribing difficult terminology. Its main value is that it achieves better terminology recognition than plain SFT and explicit AR CoT on the reported backbone, while preserving the normal low-latency inference path. The accompanying Spoken Darwin-Science dataset provides a large terminology-centric benchmark for evaluating this behavior on real scientific speech.
5. Experimental Setup
5.1 Baseline Performance
Model
CoT
WER (%)
EER (Base, %)
EER (Hard, %)
EER (All, %)
Qwen3-ASR-0.6B No 6.27 18.50 42.93 27.84 Qwen3-ASR-1.7B No 5.60 10.55 30.93 18.37 Whisper-large-v3 No 4.50 8.35 30.56 16.86 Fun-Audio-Chat-8B No 6.25 12.68 32.74 20.37 6. Main Results on Fun-Audio-Chat
Training strategy
Anchor relation
WER (%)
EER (Base, %)
EER (Hard, %)
EER (All, %)
Base
—
6.25
12.68
32.74
20.37
SFT
—
6.90
13.23
26.64
18.32
AR CoT
—
7.93
18.83
28.08
22.39
LaSR
+ 0.15 s
6.97
12.05
26.64
17.64
LaSR
- 0.50 s
6.09
10.79
25.00
16.23
LaSR
Random
6.17
11.10
25.13
16.42
6.1 Interpretation of the CoT Timing Ablation
7. Latent Reasoning Period Analysis
8. Parameter Sensitivity and Model Capacity
Method
WER (%)
EER (Base, %)
EER (Hard, %)
EER (All, %)
Base 5.60 10.55 30.93 18.37 SFT 5.34 9.06 27.15 15.99 AR CoT 6.26 22.70 38.38 28.73 LaSR 5.83 10.79 31.69 18.80 9. Inference Latency
Model
Mode
RTF
WER (%)
EER (Base, %)
EER (Hard, %)
EER (All, %)
Base 1-Forward 0.1033 6.25 12.68 32.74 20.37 A 1-Forward 0.1036 6.09 10.79 25.00 16.23 A N-Forward 0.2705 6.06 10.63 24.87 16.08 B 1-Forward 0.1037 6.17 11.10 25.13 16.42 B N-Forward 0.2706 6.17 11.34 25.00 16.52 10. What the Results Suggest
11. Limitations
12. Bottom Line