Sympatheia
Sympatheia: Emotionally Adaptive Voice Assistant with Continuous Affect Conditioning
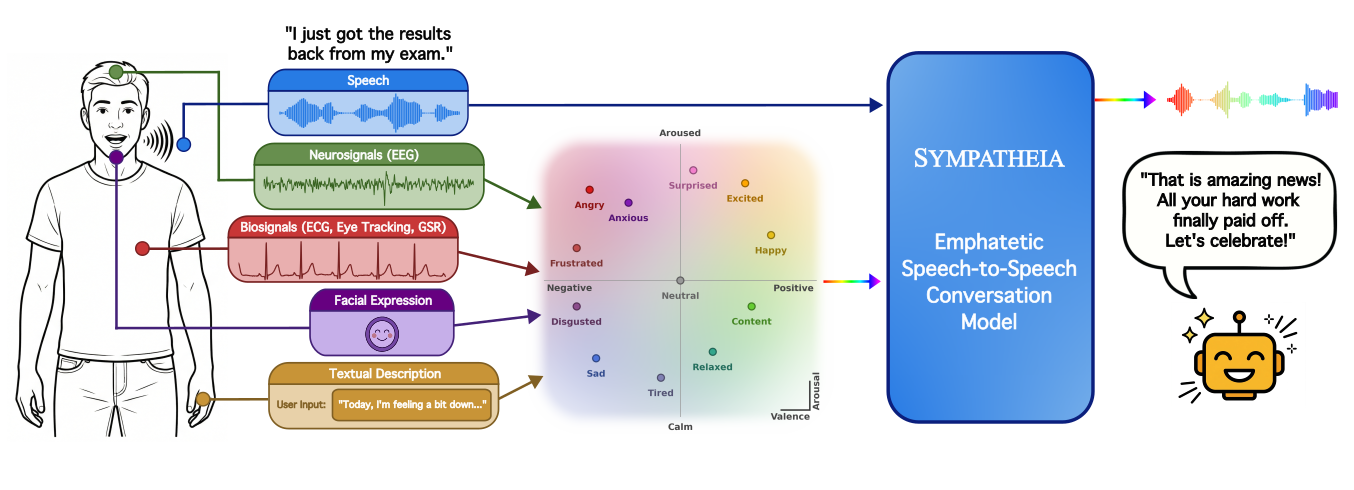
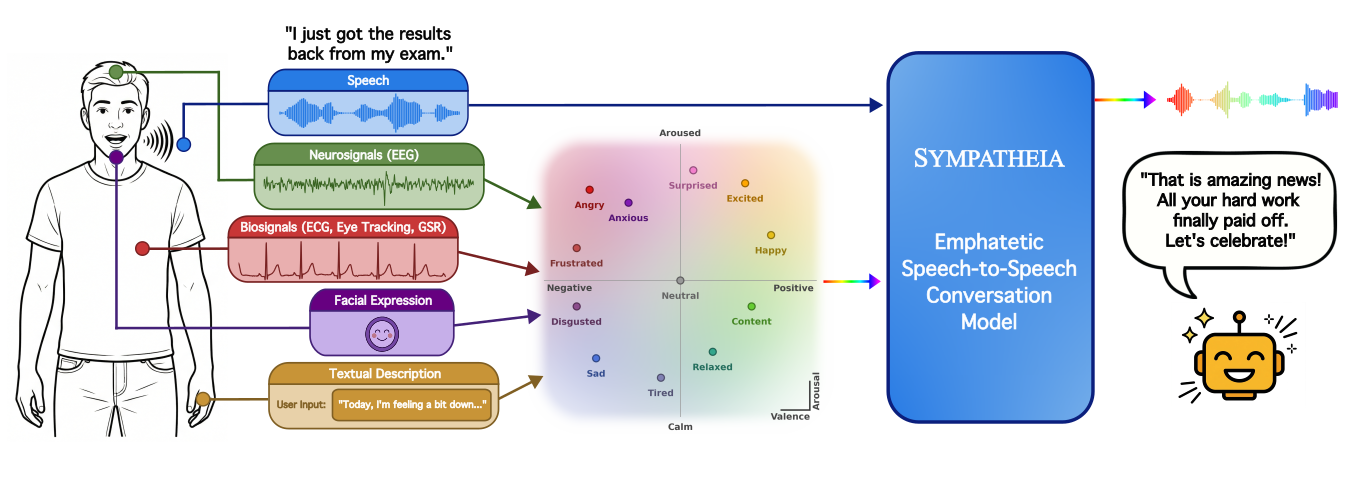
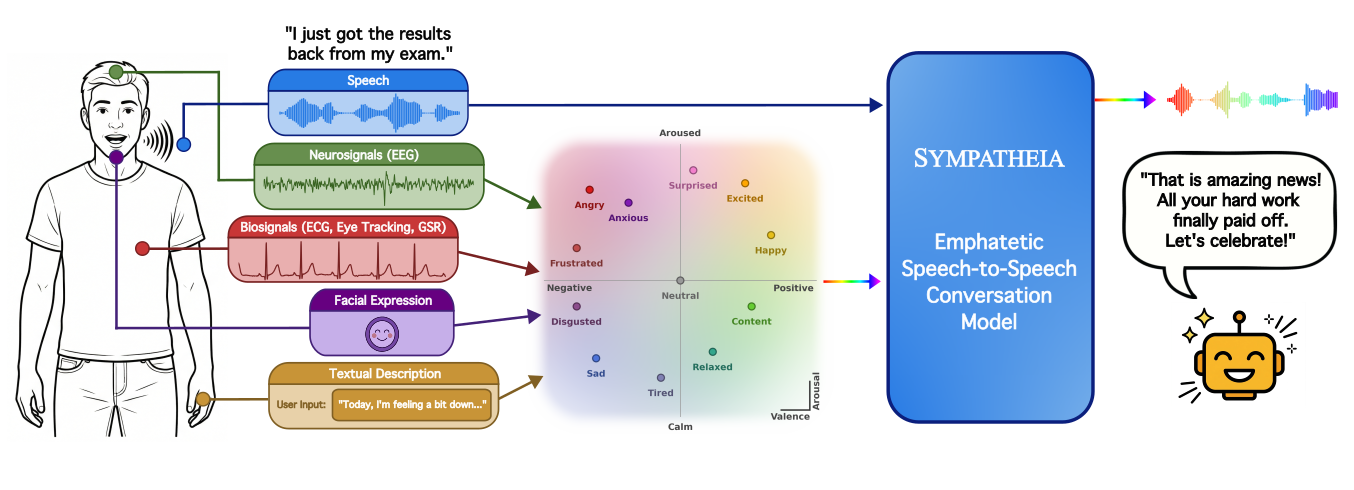
Sympatheia is a speech-to-speech dialogue system that adapts voice assistant responses using continuous valence-arousal affect signals from user speech or multimodal sensors. It combines implicit emotional inference with explicit affect control for nuanced empathetic conversation.
Demos
The demos showcase Sympatheia's ability to generate emotionally adaptive voice assistant responses conditioned on continuous valence-arousal affect inputs from user speech and multimodal sensing modules. Focus on emotional and semantic alignment of responses, especially with subtle emotional cues, and observe smooth interpolation between emotional states for fine-grained tonal control.
Links
Paper & demos
Code & resources
Impact
Abstract
Empathetic spoken dialogue systems must infer a user's emotional state to respond appropriately, yet everyday speech often carries weak, neutral, or ambiguous affective cues. To address this, we introduce Sympatheia, a speech-to-speech dialogue framework conditioned on affect inferred from the user's speech and, when available, explicit affect specifications provided as a continuous valence--arousal (VA) control signal by a multimodal sensing module or user interface. To train our model, we construct Sympatheia-18k, an emotion-conditioned synthetic spoken dialogue corpus with 12 emotion anchors. This dataset includes an emotional split for learning affective speech behavior, and a neutral split that pairs emotionally neutral queries with multiple emotion-conditioned responses to isolate explicit emotion control in emotionally ambiguous cases. Empirical results show that Sympatheia outperforms speech conversational baselines in generating responses whose semantic content and spoken delivery are both emotionally appropriate. We further show that the same VA interface can integrate emotion estimates from diverse sensing modules, including facial expression, biosignals, and textual affect descriptions, improving response alignment when speech alone provides limited emotional evidence. These results suggest that continuous affect conditioning is an effective practical step for building emotionally adaptive voice assistants.
Introduction
This paper addresses a practical limitation of current spoken dialogue systems: they can generate fluent and semantically correct answers, yet still sound emotionally mismatched when the user’s affect is weak, neutral, subtle, or ambiguous. The authors argue that empathetic voice assistants need two complementary capabilities: implicit affect inference from speech itself, and explicit affect control when external cues are available from other sensing channels or a user interface.
The central proposal is Sympatheia, a speech-to-speech dialogue framework conditioned on a continuous valence–arousal (VA) control signal. The model accepts user speech, optionally receives an external VA pair $z=(v,a)$ with $v,a \in [-1,1]$, and generates a spoken response whose content and prosody are intended to match the inferred or supplied emotional state.

The paper’s motivation is that everyday speech often does not carry strong affective cues. In those cases, discrete emotion labels are brittle, because real affect is graded, mixed, and speaker-dependent. The authors therefore treat VA as a more flexible interface for emotion sensing and control than a small fixed label set. Their design goal is not just to make the assistant “emotion-aware,” but to make affect an explicit, controllable dimension of response generation.
The paper claims three main contributions:
- a speech-native empathetic dialogue model with optional continuous affect conditioning;
- a synthetic emotion-conditioned speech dialogue corpus, Sympatheia-18k, with both expressive and neutral-query splits;
- a modular multimodal emotion-sensing interface that maps face, physiological, and text-based affect predictions into the same VA space.
System Overview
Sympatheia is best understood as a two-part system:
- Core dialogue model: a speech-to-speech generator that consumes input speech tokens and produces response speech tokens.
- Optional affect sensing modules: external recognizers that convert observations from other modalities into the same continuous VA representation used by the dialogue model.
The key design choice is that sensing and generation are decoupled. The dialogue model does not need to be modified for each modality; instead, any sensor that can estimate affect can be mapped into the shared VA interface. This makes the system modular and practical for deployment settings where some inputs may be available only sometimes.
Architecture and Affect Conditioning
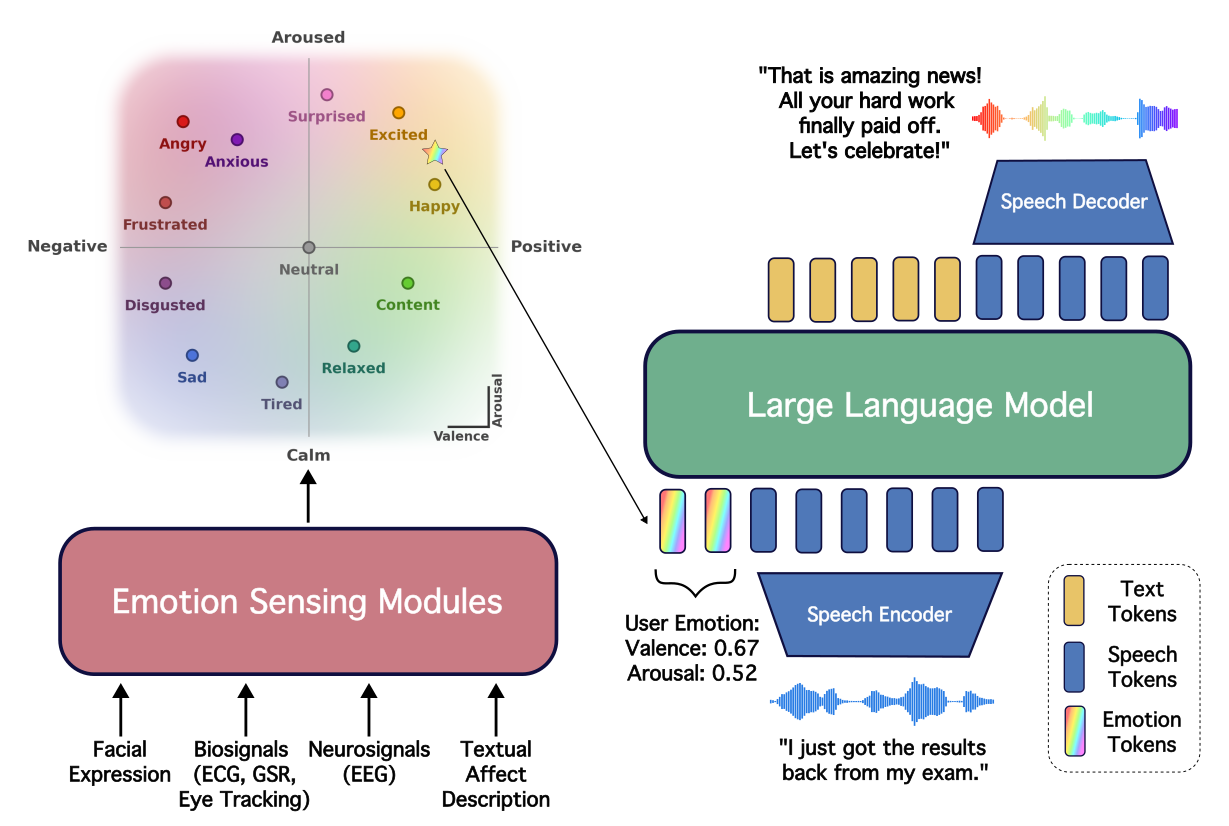
The backbone follows GLM-4-Voice. It has three stages:
- Speech tokenization: a WhisperVQ tokenizer converts input audio into ultra-low-bitrate discrete tokens at 12.5 Hz.
- Autoregressive response generation: GLM-4-Voice-9B processes the speech-token sequence and generates response tokens.
- Speech decoding: a streaming flow-matching decoder synthesizes waveform audio from the generated tokens.
To condition generation on affect, the model inserts the VA values into the system prompt in the form of a user-emotion specification. The prompt encodes the pair as something like: “User emotion (valence=$v$, arousal=$a$).” During fine-tuning, the model learns to associate regions of the VA plane with both content choice and spoken delivery.
The training objective is ordinary autoregressive negative log-likelihood over response speech tokens:
where $\mathbf{x}$ are the input speech tokens, $z=(v,a)$ is the affect condition, and $\mathbf{y}$ are the target response tokens.
The affect supervision is not a single-point classification problem. The paper uses 12 emotion anchors in the VA plane:
| Emotion | Valence | Arousal |
|---|---|---|
| Happy | +0.85 | +0.35 |
| Excited | +0.75 | +0.90 |
| Content | +0.60 | -0.20 |
| Relaxed | +0.25 | -0.60 |
| Surprised | +0.10 | +0.80 |
| Neutral | 0.00 | 0.00 |
| Tired | -0.15 | -0.75 |
| Anxious | -0.40 | +0.65 |
| Disgusted | -0.82 | -0.20 |
| Sad | -0.75 | -0.65 |
| Frustrated | -0.80 | +0.35 |
| Angry | -0.85 | +0.85 |
The authors treat these as fixed design anchors rather than universal psychological coordinates. The point is to provide a consistent operating space that covers the major affective regions and allows interpolation between them. At inference time, the model can accept explicit continuous VA values, discrete emotions mapped to anchors, or estimates from external sensors.
To make the model robust to absent or noisy affect cues, the VA condition is randomly dropped for one third of the non-neutral training samples. This encourages the model to remain a capable speech dialogue system even when no external emotion estimate is provided, and to learn to use speech-internal cues when they are the only signal.
Training Data: Sympatheia-18k
The paper’s dataset is a synthetic emotion-conditioned spoken dialogue corpus with two complementary splits:
- Emotional split: roughly 12,000 examples across the 12 target emotions, about 1,000 per emotion.
- Neutral split: 500 neutral user queries, each paired with 12 emotion-conditioned assistant responses, for 6,000 examples total.
Together these yield about 18,000 query–response pairs. The emotional split teaches the model how emotionally expressive user speech should influence response style. The neutral split isolates explicit control: the input speech is neutral, so the desired response emotion must be supplied primarily through the VA prompt.
Construction is fully synthetic and proceeds in stages. First, Qwen3-32B-Instruct generates natural spoken-style user queries and empathetic response texts. The response prompts are designed so that the assistant acknowledges the user’s emotional state and still answers the actual request. Second, Qwen3-TTS synthesizes speech in emotion-consistent styles, providing prosody and pacing that match the intended affect. Finally, each example is paired with the corresponding VA metadata used during training.
The paper emphasizes that the response strategy is not simple emotion mirroring. For example, a frustrated user should receive calm and useful help, an anxious user should get reassurance and concrete guidance, and a tired user should receive low-energy, gentle support. The dataset thus teaches both emotional alignment and task completion.
Important data-generation details include:
- query generation with thinking mode disabled;
- response generation with thinking mode enabled;
- temperature 0.85 for query generation and 0.7 for response generation;
- a 70/30 train–evaluation split at the unique-query level;
- deduplication using all-MiniLM-L6-v2 embeddings with cosine similarity threshold 0.85.
The neutral split is especially important for evaluation: because the query itself contains little affective evidence, the model must rely on the explicit VA control signal. This is the main testbed for controllable emotional response generation.
Multimodal Emotion Sensing Interface
A major contribution of the paper is a shared mechanism for turning heterogeneous emotion recognizers into the same VA representation. For a modality $m$, the classifier outputs a distribution over its native labels, and the system computes a probability-weighted expected anchor coordinate:
where $p_m(y_k \mid x_m)$ is the class probability, and $\mu(y_k)$ is the VA coordinate associated with that class. This has two benefits: it preserves uncertainty, and it allows continuous interpolation between emotions instead of forcing a hard class decision.
The paper groups external affect sources into three families:
- Facial expression: AffectNet+ validation images, using an EfficientNet-style HSEmotion classifier.
- Biosignals: EEG and eye tracking from SEED-VII; ECG and GSR from YAAD.
- Textual affect descriptions: ISEAR self-reports, classified with a DistilRoBERTa-based model.
The system also maps some label sets to nearby anchors when the dataset’s taxonomies do not align exactly. For example, joy/happiness is mapped to happy, fear to anxious, and contempt to disgusted.
Standalone sensing accuracies reported in the appendix are:
- facial expression: 62.9%
- ECG: 41.7%
- GSR: 44.1%
- EEG: 48.4%
- eye tracking: 46.1%
- textual affect description: 64.7%
These are not the main focus of the paper, but they help explain why some sensing pathways improve response quality more than others.
Training Setup
Sympatheia is initialized from GLM-4-Voice-9B and fine-tuned with LoRA. The reported optimization details are:
- LoRA rank 32, $\alpha=32$, dropout 0.1;
- adapters inserted into fused Q/K/V projections, attention output projection, and both feed-forward projections;
- AdamW with $\beta_1=0.9$, $\beta_2=0.999$, $\epsilon=10^{-8}$;
- maximum sequence length 2048 tokens;
- learning rate $10^{-4}$;
- weight decay 0.01;
- batch size 1 per device, 4 gradient accumulation steps across 4 GPUs, for an effective batch size of 16;
- 50 warmup steps and 5 epochs;
- checkpoints and evaluation every 200 steps;
- final checkpoint selected at step 2800 based on evaluation loss and manual inspection.
Training uses DeepSpeed ZeRO Stage 3, bfloat16 precision, and gradient clipping at 1.0. In the reported experiments, fine-tuning ran on 4 NVIDIA L40 GPUs and took about 8 hours. Dataset generation was more expensive: about 8 hours for query generation, 2 days for response generation, and 12 hours for TTS synthesis.
Evaluation Protocol
The paper evaluates the system from several angles: empathy, emotional appropriateness, prosody, multimodal conditioning, and preservation of general conversational ability. The main automated judge is Qwen3-Omni 30B, which listens to the generated audio so that prosody and pacing are evaluated alongside textual content. The paper also includes a human Emotion MOS study.
The core evaluation settings are:
- Sympatheia-Neutral: neutral user speech, with an explicit target emotion in the system prompt;
- Sympatheia-Emotional: expressive user speech, with no external emotion prompt;
- VoiceBench-CommonEval: real neutral spoken queries from VoiceBench.
For neutral-query settings, Sympatheia uses continuous VA prompts while baselines typically receive a discrete emotion label such as “the user is angry.” For the emotional setting, the model must infer affect from the spoken input itself. The evaluation also compares whether models actually vary their answers across target emotions by measuring pairwise semantic and lexical similarity between responses under different prompts.
The human study uses 20 native English speakers recruited through Prolific. Each participant rates one six-query batch; the full study contains 120 query–emotion trials per system and 840 response-level ratings in total. The study focuses on the neutral-query case, where the user’s speech is emotionally neutral and the target emotion is externally specified. Participants rate how well the response fits and supports the target emotion on a 1–5 scale.
Main Results
The headline result is that Sympatheia outperforms the spoken-dialogue baselines across all three automated empathy settings and in the human Emotion MOS evaluation. The largest gains appear when explicit affect conditioning matters most, but the model also does well when it has to infer emotion from expressive speech alone.
| Model | Sympatheia-Neutral ↑ | Sympatheia-Emotional ↑ | VoiceBench-CommonEval ↑ | Emotion MOS ↑ | Semantic Similarity ↓ | Lexical Similarity ↓ |
|---|---|---|---|---|---|---|
| Sympatheia | 4.37 | 4.74 | 4.22 | 3.86 | 0.801 | 0.223 |
| GLM-4-Voice | 1.76 | 3.80 | 1.51 | 2.23 | 0.866 | 0.459 |
| Qwen3-Omni | 2.59 | 4.69 | 1.88 | 3.32 | 0.857 | 0.397 |
| Qwen2.5-Omni | 1.75 | 3.53 | 1.54 | 2.56 | 0.919 | 0.650 |
| Kimi-Audio | 3.64 | 4.03 | 3.75 | 2.95 | 0.835 | 0.381 |
| OpenS2S | 2.34 | 4.08 | 1.55 | 2.42 | 0.863 | 0.441 |
| OSUM-EChat | 1.77 | 3.93 | 2.03 | 2.18 | 0.844 | 0.391 |
Two patterns stand out. First, Sympatheia’s advantage is especially large in the neutral-query regime, where explicit affect conditioning is needed. Second, the lower semantic and lexical similarity values mean that the model is changing its response content more across target emotions, rather than recycling a near-template answer for every emotion.
Two additional baseline comparisons reinforce the same conclusion:
- A cascaded Qwen3-Omni → Qwen3-TTS system improves over direct Qwen3-Omni in the neutral setting, but still remains far below Sympatheia.
- Providing Qwen3-Omni with a face image or text self-report helps, but Sympatheia still performs better when the same cues are mapped into the VA interface.
In other words, the gain is not just from having a stronger general-purpose model or better prompting. The learned continuous affect conditioning seems to matter.
Prosody Analysis
The paper checks whether the model’s emotional control is reflected in speech acoustics, not only in text. For each generated response, it measures mean and standard deviation of $F_0$, the central 80% range of $F_0$, mean and standard deviation of RMS energy, speaking rate, and spectral centroid. It then computes Spearman correlations with the target valence and arousal values.
The main qualitative pattern is that higher arousal targets produce more dynamic pitch, stronger pitch range, faster rate, and brighter spectral characteristics, while valence also influences energy-related features. Sympatheia shows the strongest and most consistent affect–prosody relationships among the compared systems.
| Model | F0 mean | F0 std | F0 range | Energy mean | Energy std | Rate | Spectral centroid |
|---|---|---|---|---|---|---|---|
| Sympatheia | 0.28 / 0.40 | 0.23 / 0.46 | 0.23 / 0.45 | 0.34 / 0.19 | 0.31 / 0.06 | 0.01 / 0.29 | 0.08 / 0.28 |
| GLM-4-Voice | 0.22 / 0.12 | 0.13 / 0.08 | 0.19 / 0.09 | 0.13 / 0.16 | 0.12 / 0.07 | -0.10 / 0.06 | 0.03 / 0.06 |
| Qwen3-Omni | 0.21 / 0.10 | 0.04 / 0.07 | 0.15 / 0.07 | 0.19 / 0.05 | 0.10 / 0.02 | 0.04 / -0.01 | 0.07 / 0.04 |
| Qwen2.5-Omni | 0.22 / 0.03 | 0.08 / 0.00 | 0.16 / 0.03 | 0.01 / 0.09 | 0.09 / 0.08 | -0.11 / -0.04 | 0.17 / -0.06 |
| Kimi-Audio | 0.01 / 0.06 | 0.22 / 0.14 | 0.22 / 0.14 | -0.06 / -0.05 | 0.01 / 0.00 | -0.18 / -0.21 | 0.07 / 0.16 |
| OpenS2S | 0.05 / 0.18 | 0.00 / 0.11 | 0.02 / 0.16 | -0.01 / 0.10 | -0.04 / 0.09 | -0.13 / -0.12 | -0.07 / -0.05 |
| OSUM-EChat | 0.13 / 0.09 | -0.13 / 0.04 | -0.05 / 0.08 | 0.20 / 0.07 | 0.13 / 0.03 | -0.23 / 0.06 | -0.18 / -0.03 |
These results suggest that VA conditioning is not only changing lexical choices but also influencing the acoustic realization of the response. In particular, arousal appears to be reflected strongly in pitch and energy dynamics, which is exactly what one would want if the goal is emotionally adaptive spoken interaction.
Multimodal Emotion Sensing Results
The sensing experiments test the system in the complementary scenario where the user’s speech is neutral or ambiguous, but another modality provides affect information. The evaluation is conducted as a three-stage pipeline: estimate a VA cue from the sensing modality, feed that cue to Sympatheia along with a neutral query, and score the response using the audio judge.
Every sensing modality improves response quality relative to omitting the cue. Facial expression and textual self-report produce the largest gains, while physiological signals still help despite being noisier and more person-dependent.
| Condition | Face (offline) | Face (live) | EEG | Eye tracking | ECG | GSR | Text description |
|---|---|---|---|---|---|---|---|
| w/ cue | 3.64 | 3.39 | 3.14 | 3.05 | 2.76 | 2.74 | 3.57 |
| w/o cue | 1.92 | 1.98 | 1.75 | 1.75 | 1.84 | 1.84 | 1.63 |
The live facial-expression study is particularly important because it tests the end-to-end pipeline on recordings from 10 human subjects who acted prompted emotions while speaking neutral queries. The live system also improves over the no-cue control, validating that the VA interface can operate in a more realistic interactive setting rather than only on offline datasets.
Ablation Studies and Additional Analyses
The paper includes two targeted ablations. The first asks whether emotion fine-tuning harms ordinary conversational ability. The second tests whether the learned VA space is smooth and robust to noise.
| Model | UTMOS ↑ | BERT F1 ↑ | ROUGE-L ↑ | ASR-WER ↓ |
|---|---|---|---|---|
| Sympatheia | 4.18 | 0.627 | 0.228 | 5.42 |
| GLM-4-Voice (base) | 4.02 | 0.569 | 0.223 | 5.73 |
This result argues that affect fine-tuning does not damage the backbone’s general question-answering behavior. In fact, the fine-tuned model slightly improves naturalness and text/audio consistency.
| Noise level $\sigma$ | 0.0 | 0.1 | 0.2 | 0.3 | 0.5 |
|---|---|---|---|---|---|
| Judge score | 4.32 | 3.79 | 3.59 | 3.51 | 3.30 |
The VA-noise analysis shows a smooth degradation rather than a brittle collapse. As the injected Gaussian noise on valence and arousal increases, the judge score decreases gradually. That suggests the model can tolerate imperfect upstream affect estimates and can use off-anchor conditions meaningfully.
Qualitatively, the paper also reports that the model’s responses vary across target emotions rather than staying nearly invariant. This supports the claim that the model is learning a genuine affect-control mapping, not just a few generic response templates.
Interpretation and Broader Takeaways
The paper’s main technical message is that continuous affect conditioning is a useful intermediate design point between rigid emotion classification and unconstrained dialogue generation. Compared with discrete labels, VA is easier to share across sensors and easier to interpolate across ambiguous states. Compared with unconditioned speech generation, it gives the model a direct handle on emotional style.
Sympatheia’s improvements appear in both semantic and acoustic dimensions. The model does not merely say “I understand you are upset”; it also changes the character of the response, including pitch, energy, and speaking style. The multimodal sensing experiments further show that the same VA interface can integrate very different sources of emotional evidence without changing the dialogue backbone.
The authors also make a careful distinction between emotion recognition and emotion-conditioned response generation. The sensing modules may be imperfect, but the dialogue model is trained to use their outputs as soft, continuous cues rather than hard decisions. This is important because in real systems, affect estimation will often be uncertain.
Limitations and Responsible Deployment
The paper is explicit that the work is still limited by the synthetic nature of the training data and by the compactness of the VA representation. Synthetic dialogue may not capture the full diversity, disfluency, and long-horizon dynamics of real conversation. A single VA coordinate also cannot fully represent blended emotions, fast shifts within a turn, or culturally variable interpretations of emotion labels.
Evaluation is another limitation. Much of the scoring relies on an audio-capable LLM judge, and the paper notes that the data, TTS, and judge are all Qwen3-based, which can introduce family-specific style bias. The authors partially mitigate this by including Qwen3-Omni as a baseline and by reporting human Emotion MOS, but they still call for independent audio judges and broader comparisons.
Deployment raises privacy and safety concerns. Facial expressions, speech, EEG, ECG, eye tracking, and self-reported emotion are all sensitive signals. The paper recommends opt-in sensing, disclosure of what is being collected, minimal retention of raw sensor data, and user override of affect conditioning. It explicitly warns against covert emotion surveillance, diagnosis, manipulation, protected-attribute inference, and high-stakes decisions without separate validation and governance.
Overall, the paper’s conclusion is that continuous affect conditioning is a practical step toward more emotionally adaptive voice assistants, but that robust deployment will require personalized calibration, better real-world human studies, and more careful handling of sensor uncertainty and consent.
Code & Implementation
This repository implements the Sympatheia emotionally adaptive voice assistant described in the paper. The core code is in the src/ directory, which contains scripts for training, inference, dataset creation, evaluation, and integration with external emotion sensing modules.
The main training script, src/train_sympatheia.py, fine-tunes the GLM-4-Voice-9B model using LoRA adapters on the Sympatheia-18k dataset. Training hyperparameters are configurable via src/config.yaml. The dataset is pre-encoded into a JSONL format with audio tokens and dialogue text that includes continuous valence-arousal (VA) affect conditioning.
Inference is performed by src/inference_sympatheia.py, which loads fine-tuned checkpoints and generates speech responses conditioned on 12 discrete emotion anchors and interpolated affect states via continuous VA coordinates. The system supports running inference over multiple checkpoints with audio output saved in designated result directories.
Additional components include dataset creation pipelines under src/dataset_creation/, evaluation scripts with LLM-based judging under src/eval/, and modules for emotion input integration such as face or textual emotion sensing in src/integration/. The TTS vocoder and codec components are located in src/vocoder_src/ and src/cosyvoice/.
The README provides detailed instructions for setup, including acquiring the pretrained GLM-4-Voice base model and decoder weights, as well as running training, inference, demo, and evaluation pipelines. Model checkpoints and the synthetic Sympatheia-18k dataset are available via HuggingFace links listed in the README.