PolySpeech-100
PolySpeech-100: A Large-Scale Benchmark for Speech Understanding Across 100+ Languages and Dialects
PolySpeech-100 is a benchmark measuring speech understanding across 100+ languages and dialects with human and synthetic data. It highlights end-to-end models' strengths on dialects and reveals gaps in low-resource language comprehension beyond transcription.
Links
Paper & demos
Code & resources
Impact
Abstract
While End-to-End (E2E) Speech-Large Language Models (Speech-LLMs) are rapidly evolving, their evaluation methodologies remain limited to the era of simple transcription. Existing benchmarks suffer from three critical limitations: a pronounced bias towards high-resource languages, a focus on low-level recognition (ASR) rather than semantic reasoning, and a neglect of regional dialects. To bridge this gap, we introduce PolySpeech-100, a massive-scale benchmark designed to assess `native-level' speech comprehension across 110 linguistic variants. We employ a novel hybrid construction pipeline that augments gold-standard human recordings with instruction-driven synthetic speech, allowing us to cover 19 distinct Chinese dialects and over 80 low-resource languages. Extensive evaluation of 22 state-of-the-art models (including Gemini-3, GPT-Audio, and Qwen2.5-Omni) yields pivotal insights. First, we demonstrate that open-source E2E models outperform Cascade (ASR+LLM) systems on heavy dialects, proving that direct audio processing preserves critical paralinguistic cues and prosodic features (e.g., intonation, stress) that are often lost in standard transcription. Second, we reveal a significant performance gap: while commercial models maintain robustness, open-source models suffer catastrophic degradation on low-resource languages. Finally, counter-intuitively, we observe that under standard zero-shot settings, Chain-of-Thought prompting frequently degrades speech understanding performance for most evaluated models, revealing a potential modality alignment gap in current architectures. PolySpeech-100 establishes a rigorous standard for the next generation of inclusive, omni-capable Speech-LLMs. The data, demo, and code are publicly available at https://github.com/YoungSeng/PolySpeech-100.
Introduction
PolySpeech-100 is a benchmark for speech understanding across 110 linguistic variants, designed to move evaluation beyond transcription and toward spoken question answering and semantic comprehension. The paper argues that most existing Speech-LLM benchmarks are still anchored in the ASR era: they overemphasize high-resource languages, measure recognition rather than reasoning, and largely ignore dialectal variation. PolySpeech-100 is positioned as a corrective to that gap by explicitly testing whether models can understand speech in a more native-level sense across major languages, regional dialects, and low-resource languages.
The benchmark is built around the Belebele reading-comprehension format, so each example contains a passage, a question, and four answer options. This allows the authors to hold semantics constant across languages while varying the acoustic realization. Their headline claim is that the resulting task is substantially harder and more realistic than standard transcription-oriented benchmarks because success requires the model to preserve information that can be erased by ASR normalization, especially in dialects and under-resourced languages.
The paper’s central empirical thesis is that end-to-end speech models can outperform cascaded ASR+LLM pipelines on heavy dialects, while commercial models still dominate on low-resource languages. A second, more surprising result is that Chain-of-Thought prompting often hurts speech understanding rather than helping it, suggesting a modality alignment problem between acoustic perception and text-based reasoning.
Benchmark Design and Data Construction
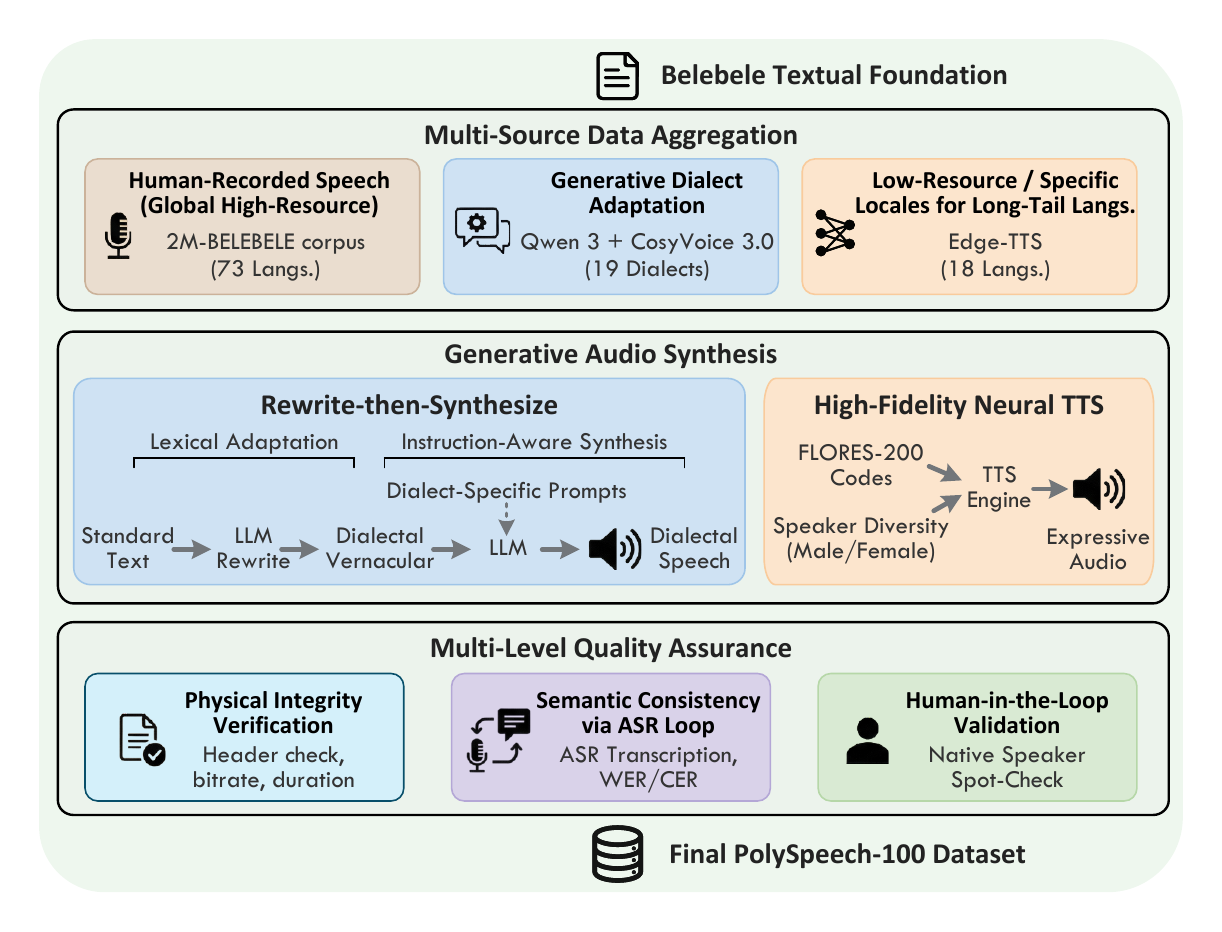
The data construction pipeline is the paper’s main methodological contribution. It follows three stages: multi-source data aggregation, generative audio synthesis, and multi-level quality assurance. The goal is to maximize linguistic coverage without sacrificing semantic fidelity or evaluation validity.
Textual backbone: Belebele
The textual foundation is the multilingual Belebele benchmark, which provides parallel reading-comprehension passages and multiple-choice questions across many languages. The authors emphasize that this parallel structure is crucial: it avoids semantic drift across languages and makes it possible to compare acoustic modeling quality in a controlled way.
At the dataset level, the paper describes the benchmark as covering 110 linguistic variants and organizes evaluation into three groups:
- High-resource languages: 10 major languages, including English, Simplified Chinese, Traditional Chinese, Spanish, French, German, Japanese, Russian, Italian, and Portuguese.
- Chinese dialects: 19 regional variants, including Cantonese, Wu, Minnan, Sichuan, Dongbei, Tianjin, Shanghai, Hubei, Hunan, Shaanxi, and others.
- Low-resource languages: 81 long-tail languages from Belebele, such as Zulu, Yoruba, Lao, Khmer, Burmese, Amharic, and Guarani.
Track 1: human-recorded speech
For the core high-resource portion, the paper uses 2M-BELEBELE as the source of professionally recorded human speech. The authors treat this as the gold-standard track because it preserves natural prosody and authentic pronunciation. The extracted tuples are aligned as (passage, question, options), which keeps the downstream task format consistent across all language groups.
Track 2: dialect generation via Rewrite-then-Synthesize
The paper’s most distinctive data-generation strategy targets Chinese regional dialects. Instead of using plain TTS, the authors employ CosyVoice 3.0 with a two-stage Rewrite-then-Synthesize procedure:
- Lexical adaptation: a language model rewrites standard text into dialectal vernacular while preserving meaning. The paper specifically cites Qwen3-Instruct for this rewriting stage.
- Instruction-aware synthesis: the rewritten text is synthesized with dialect-specific prompts so that the output audio exhibits dialectal accent, intonation, and phonological traits.
This track covers 19 Chinese regional variants, including broad groupings such as Cantonese, Wu, and Minnan, as well as Mandarin-accented regional varieties such as Sichuan, Dongbei, and Tianjin. The authors explicitly argue that this approach is not just data augmentation but a valid evaluation proxy when human recordings are scarce.
Track 3: neural synthesis for long-tail languages
For low-resource languages where human recordings are not feasible, the benchmark uses neural TTS. The paper describes a mapping from FLORES-200 language codes to available voice locales and uses voice randomization to reduce speaker overfitting. The authors note that synthetic audio is a practical necessity for achieving coverage over the linguistic long tail.
Quality assurance and validity checks
The benchmark is filtered through three validation layers:
- Physical integrity verification: the corpus is scanned for corruption, invalid headers, bitrate issues, truncated clips, and silent files. Samples must contain a complete passage-question-options chain.
- Semantic consistency via ASR loop: synthetic audio is transcribed back to text using multiple ASR systems, including Qwen3-ASR, SenseVoice, Whisper, and TeleASR. The authors compute WER and CER against the source text and remove or regenerate samples above a strict threshold.
- Human-in-the-loop validation: native speakers manually spot-check dialectal samples to verify prosody and lexical naturalness.
The appendix strengthens the validity argument with several concrete measurements: two native linguists blind-audited 500 generated samples, achieving a 92.4% acceptance rate and Cohen’s kappa of 0.78. In addition, a real-world test set of 300 human-recorded samples across five dialects produced a strong correlation with benchmark scores of $r=0.83$. For high-resource languages, the synthetic-vs-human accuracy gap is reported as less than 2.0%.
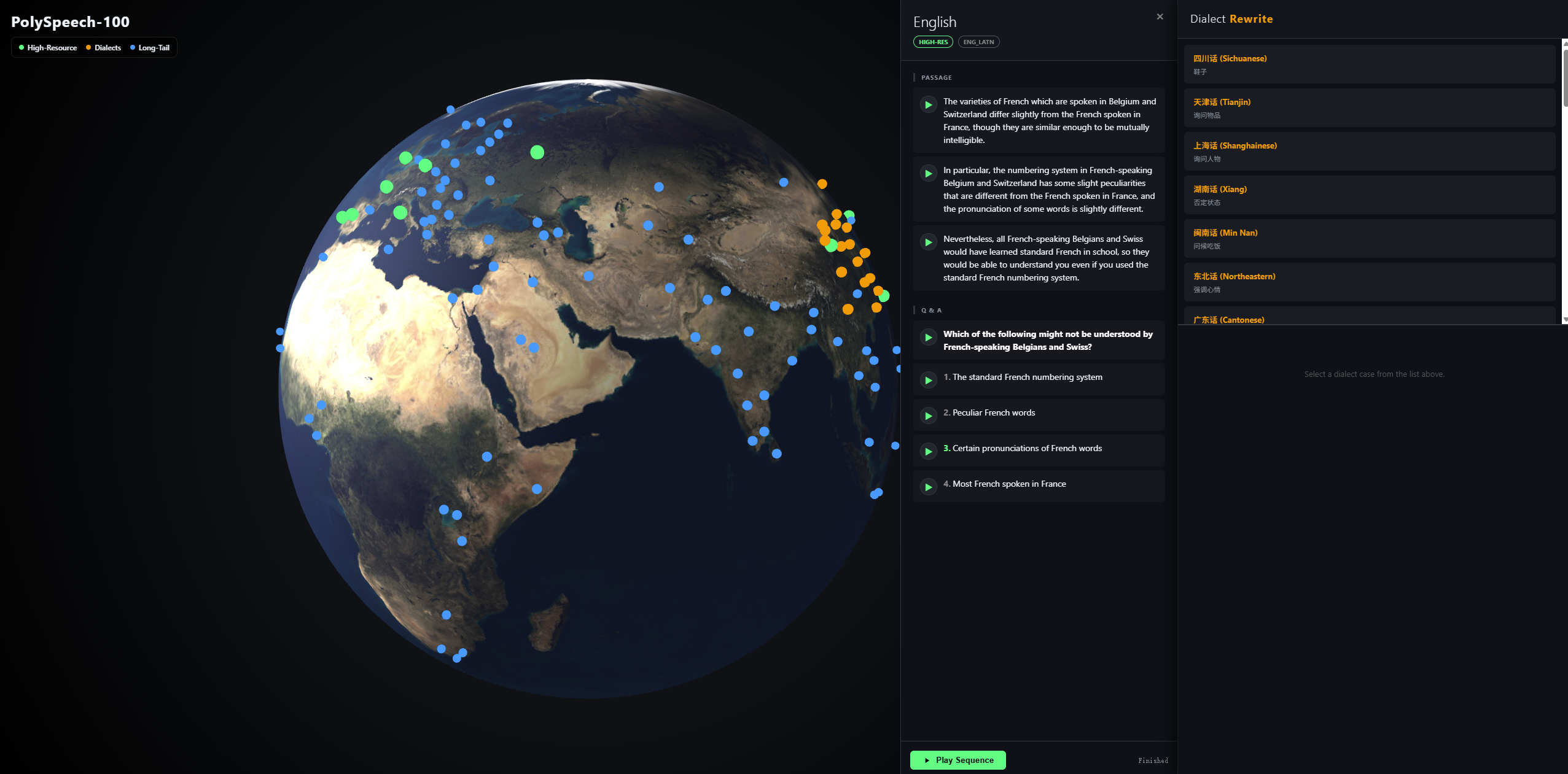
Demo and interaction format
The appendix also describes an interactive demo that lets users inspect the benchmark’s geographic language coverage and listen to dialectal synthesis examples. This is mainly a transparency and auditability feature, not part of the benchmark itself.
Evaluation Protocol
The benchmark evaluates 22 state-of-the-art audio systems, spanning closed-source APIs, open-source end-to-end speech models, prompt-to-speech variants, and classical cascaded ASR+LLM pipelines. The benchmark uses macro-average accuracy within each language group, so that languages with more samples do not dominate the aggregate score.
Formally, for a category $c$ with language set $L_c$, the reported score is:
$$\text{Score}_c = \frac{1}{|L_c|} \sum_{l \in L_c} \text{Accuracy}(l).$$
The paper reports all results as multiple-choice accuracy on a four-way selection task, so random guessing corresponds to 25%.
Prompting setup
The authors adapt prompting to each model’s interface:
- Models that support system instructions receive a text prompt that asks for a single answer letter only.
- For Chain-of-Thought experiments, the prompt requests a brief summary, explanation of wrong options, and then the final answer.
- For models that cannot accept textual system prompts, the instruction is converted to speech and concatenated to the beginning of the input audio.
This detail matters because it affects the behavior of some audio-native systems: the paper later shows that models that rely on spoken instructions can collapse badly when instruction and content are mixed in the same audio stream.
Main Results
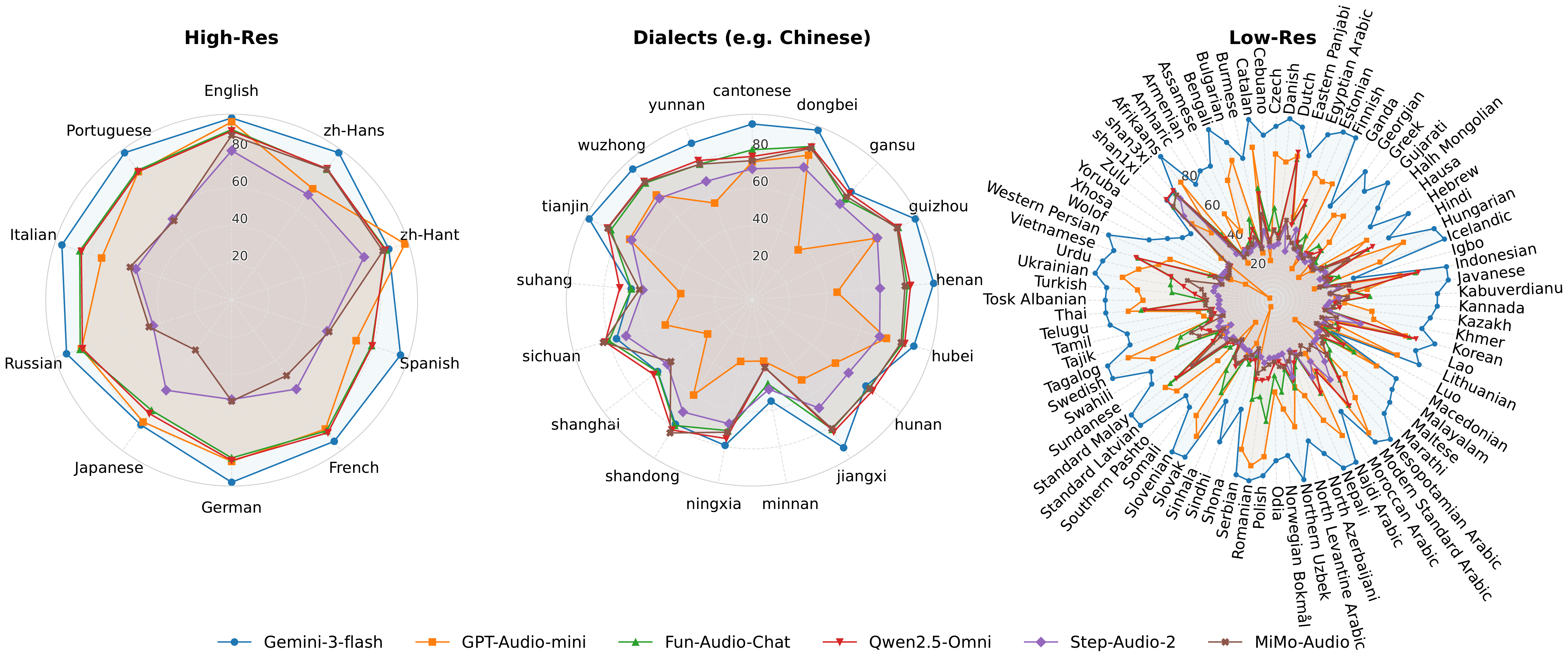
The headline result is that Gemini-3-flash is the strongest system overall, with a macro-average accuracy of 85.30%. It also leads in each category: 94.26% on high-resource languages, 83.54% on Chinese dialects, and 84.61% on low-resource languages. The strongest open-source end-to-end systems are Fun-Audio-Chat and Qwen2.5-Omni, but they remain far behind Gemini on the hardest low-resource setting.
| Model | Type | Overall | High-Res | CN-Dialect | Low-Res |
|---|---|---|---|---|---|
| Gemini-3-flash | Closed-source | 85.30 | 94.26 | 83.54 | 84.61 |
| GPT-Audio-mini | Closed-source | 56.63 | 83.56 | 55.58 | 53.56 |
| Fun-Audio-Chat | Open-source E2E | 52.88 | 84.82 | 77.06 | 43.26 |
| Qwen2.5-Omni | Open-source E2E | 50.89 | 84.94 | 78.61 | 40.18 |
| MiniCPM-o 4.5 | Open-source E2E | 50.57 | 78.25 | 59.24 | 45.12 |
| Audio-Omni | Open-source E2E | 46.62 | 77.50 | 71.95 | 36.86 |
| MiMo-Audio | Open-source E2E | 43.51 | 61.09 | 76.03 | 33.72 |
| Step-Audio-2 | Open-source E2E | 40.52 | 60.44 | 68.17 | 31.57 |
| Whisper-v3 + Qwen2.5 | Cascade | 53.86 | 83.74 | 62.62 | 48.12 |
| Whisper-v3 + Qwen3 | Cascade | 51.56 | 80.17 | 59.82 | 46.09 |
| Qwen3-ASR + Qwen2.5 | Cascade | 52.29 | 81.80 | 72.36 | 43.94 |
| Qwen3-ASR + Qwen3 | Cascade | 52.66 | 84.28 | 73.93 | 43.77 |
The paper draws several concrete conclusions from these results:
- Open-source end-to-end models beat cascades on heavy Chinese dialects. For example, Qwen2.5-Omni reaches 78.61% on dialects, above Whisper-v3 + Qwen2.5 at 62.62% and above GPT-Audio-mini at 55.58%.
- End-to-end models preserve paralinguistic information. The authors argue that direct audio processing retains tone, stress, and other cues that ASR can erase before the LLM ever sees the content.
- Commercial models remain much more robust on low-resource languages. Gemini stays at 84.61% on the low-resource group, while the best open-source E2E models fall into the 30-43% range.
- Prompt-to-speech systems that lack a text system prompt interface collapse toward chance. Mini-Omni, LLaMA-Omni2, and Moshi score around 20-22%, below the 25% random baseline for a four-choice task.
The paper also highlights efficiency. On the full benchmark of 88,000 samples, Fun-Audio-Chat is the fastest model at about 11 hours on a single NVIDIA 4090 GPU, while LLaMA-Omni2, MiMo-Audio, and Qwen2.5-Omni are moderate in cost, and Mini-Omni, Qwen2-Audio, and Moshi are much slower. The efficiency discussion is framed as a practical trade-off between accuracy and inference cost rather than a primary benchmark criterion.
Robustness, Prompt Sensitivity, and Failure Modes
The authors stress-test the benchmark along three axes: noise, speaking rate, and input duration. Their key message is that real-world speech understanding is not just about clean recognition; it is about maintaining semantic stability under acoustic distortions.

Noise robustness
The augmentation pipeline adds Gaussian white noise at two levels: a low-noise setting around 20 dB SNR and a high-noise setting around 0–5 dB SNR. The results show that noise can be highly destructive, especially for high-resource language samples that otherwise look easy in clean conditions.
- Fun-Audio-Chat drops from 84.82% to 65.73% on high-resource languages under high noise, a loss of 19.1 points.
- Qwen2.5-Omni is more robust, dropping only 9.0 points on high-resource languages and 8.1 points on Chinese dialects under high noise.
- MiMo-Audio loses 11.8 points on high-resource languages under high noise.
- Step-Audio-2 drops 13.1 points in the high-resource group.
For the low-resource category, the paper notes a floor effect: because many systems are already near random-guess territory, absolute drops are numerically smaller, but this should not be interpreted as genuine robustness.
Speaking-rate robustness
Speed perturbations are less damaging than additive noise overall. Still, the paper observes that temporal compression can impair dialect recognition for some architectures; for example, Fun-Audio-Chat is noticeably hurt by the fast-speed condition in the dialect setting.
Duration robustness
The duration analysis shows a general negative correlation between utterance length and accuracy. High-resource languages remain fairly stable for Fun-Audio-Chat and Qwen2.5-Omni even as duration approaches 140 seconds, whereas MiMo-Audio and Step-Audio-2 degrade more sharply. The authors interpret this as evidence that long-context speech modeling is still fragile, especially when sample counts are low in the long-duration bins.
Prediction bias
The bias analysis is especially notable for Step-Audio-2. Unlike the other models, which produce broadly balanced option distributions, Step-Audio-2 shows a persistent preference for option B, and this bias survives prompt suffix changes. The paper treats this as an architectural or instruction-following bias rather than ordinary prompt sensitivity.
Advanced Reasoning: Chain-of-Thought and In-Context Learning
A major and counterintuitive result is that standard Chain-of-Thought prompting does not reliably help speech models. In many cases it hurts performance, sometimes by a large margin. This is one of the most important findings in the paper because it directly challenges the assumption that text-LLM reasoning tricks transfer to audio.
Across alternative CoT templates, the authors report that performance consistently degrades by about 7.5% to 12.1% relative to the direct-answer baseline. The negative effect appears robust to prompt format, including both a looser step-by-step prompt and a structured JSON prompt. The paper’s interpretation is that current speech models are not well aligned for intermediate text generation during audio understanding.
- Fun-Audio-Chat falls by about 9.46 points on high-resource languages under CoT.
- Qwen2.5-Omni falls by about 10.88 points on high-resource languages under CoT.
- MiMo-Audio falls by about 10.98 points on high-resource languages under CoT.
- Step-Audio-2 is the exception: it improves by 7.10 points on high-resource languages with CoT, although it also shows sensitivity to other settings.
The appendix provides a deeper failure decomposition and claims that more than 85% of CoT errors arise in the logical reasoning phase rather than the acoustic perception phase. The authors separate failures into three categories:
- Semantic conflation: the model hears the right facts but merges separate causal links into one incorrect explanation.
- Logic inversion: the model understands a negated question but answers the true statement instead of the false one.
- Reasoning-output disconnect: the reasoning text is internally correct, but the final answer token contradicts that reasoning.
Few-shot audio in-context learning also looks weak. The paper prepends three audio demonstrations of the [passage, question, answer] form and finds that gains are negligible or negative for most systems. Qwen2.5-Omni shows a small positive transfer in some settings, but the improvement is modest relative to the extra compute and context length.
| Model | Group | Base | High noise | Fast speed | CoT | 3-shot |
|---|---|---|---|---|---|---|
| Fun-Audio-Chat | High-Res | 84.82 | 65.73 (-19.1) | 82.24 (-2.6) | 75.36 (-9.46) | 82.69 (-2.13) |
| Qwen2.5-Omni | High-Res | 84.94 | 75.90 (-9.0) | 85.15 (+0.2) | 74.06 (-10.88) | 86.64 (+1.70) |
| MiMo-Audio | High-Res | 61.09 | 49.29 (-11.8) | 57.88 (-3.2) | 50.11 (-10.98) | 54.04 (-7.05) |
| Step-Audio-2 | High-Res | 60.44 | 47.37 (-13.1) | 59.61 (-0.8) | 67.54 (+7.10) | 45.39 (-15.05) |
| Fun-Audio-Chat | CN-Dialect | 77.06 | 66.37 (-10.7) | 68.27 (-8.8) | 77.14 (+0.08) | 76.55 (-0.51) |
| Qwen2.5-Omni | CN-Dialect | 78.61 | 70.50 (-8.1) | 77.17 (-1.4) | 68.32 (-10.29) | 77.82 (-0.79) |
| Fun-Audio-Chat | Low-Res | 43.26 | 30.95 (-12.3) | 38.09 (-5.2) | 39.06 (-4.20) | 41.52 (-1.74) |
| Qwen2.5-Omni | Low-Res | 40.18 | 32.97 (-7.2) | 36.53 (-3.7) | 33.37 (-6.81) | 40.57 (+0.39) |
Two details are worth emphasizing. First, the paper argues that CoT failures are usually not acoustic mishearing; the model often knows what it heard but fails once it starts producing intermediate text. Second, the authors explicitly frame this as a modality alignment gap: the model is aligned to answer directly, but not to reason over audio in a text-like way.
Dialect and Language-Specific Case Studies
The paper devotes substantial attention to Chinese dialects and Arabic dialects because they expose different strengths of end-to-end and cascaded architectures.
Chinese dialects
For Chinese regional varieties, open-source end-to-end models are especially competitive. Qwen2.5-Omni reaches 78.61% on the Chinese dialect group, and Fun-Audio-Chat reaches 77.06%, both above Whisper-v3 + Qwen2.5 at 62.62%. The authors interpret this as evidence that ASR can erase acoustic cues that matter for dialect semantics, whereas end-to-end models can exploit those cues directly.
The appendix’s Cantonese case study makes this concrete. A proper noun for “Eskimos” is phonetically distorted by ASR into semantically unrelated characters, which breaks the cascade pipeline’s link between passage and answer choice. The end-to-end model, by contrast, can still map the acoustic signal to the correct option, which the authors use as a qualitative demonstration that audio-native representations can preserve dialectal meaning better than transcription-based systems.
Arabic dialects
The Arabic case study reveals an important asymmetry: the conclusion that end-to-end models beat cascades on Chinese dialects does not generalize to Arabic dialects. Here, the paper finds that cascade systems often outperform open-source end-to-end models, reversing the Chinese trend. Whisper-v3 + Qwen2.5 achieves an average dialect accuracy of 62.13%, higher than the best open-source E2E model in that table (Fun-Audio-Chat at 52.11%).
The appendix also reports striking dialect-specific gaps. Gemini-3-flash is strongest on Arabic varieties overall, with near-perfect performance on some dialects such as Najdi and Mesopotamian Arabic, while GPT-Audio-mini is much less stable: it scores well on Modern Standard Arabic but collapses on Moroccan Arabic. The paper uses this to argue that Arabic dialect evaluation remains a separate and difficult frontier because the diglossic gap between formal and regional speech is especially large.
Limitations, Ethics, and What the Benchmark Does Not Cover
The authors are explicit about the limitations of the benchmark design. First, the task is entirely multiple choice. This is intentional: it avoids the subjectivity and judge-model noise of open-ended evaluation, but it does not capture the full complexity of open-ended conversation, turn-taking, interruption handling, or duplex interaction.
Second, the textual backbone is reading comprehension. That makes the benchmark ideal for controlled cross-lingual comparison, but it also means the task is more structured than spontaneous dialogue. The authors note that casual social speech, highly colloquial conversation, and other open-ended settings remain outside the benchmark scope.
Third, although synthetic data is a necessary part of the long-tail coverage strategy, the paper recognizes that synthesis cannot completely replace human speech. The authors mitigate this with ASR-based validation, blind human auditing, and correlation checks, but they still frame the synthetic track as a pragmatic approximation rather than a perfect substitute.
On the ethics side, the benchmark is released under a CC-BY-SA license, with text sourced from Flores200 and Belebele and human speech sourced from 2M-BELEBELE. The synthetic components rely on CosyVoice3.0 and edge-tts under their respective usage conditions. The paper’s stated ethical goal is to move from standard-centric AI toward systems that are inclusive of accent and dialect variation.
Conclusion
PolySpeech-100 is best understood as a large-scale, cross-lingual speech comprehension benchmark that directly targets the weak points of current Speech-LLMs: dialect robustness, low-resource coverage, and reasoning alignment. Its strongest empirical claims are that end-to-end models can outperform cascaded ASR+LLM systems on heavy dialects, that commercial models still maintain a large advantage on low-resource languages, and that CoT prompting is currently unreliable in the audio modality. The benchmark’s construction pipeline, validity checks, and case studies collectively argue that speech understanding should be evaluated as a semantic and acoustic problem, not merely as transcription quality.
In short, the paper positions PolySpeech-100 as a stricter and more inclusive standard for the next generation of speech-native conversational systems.
Code & Implementation
This repository hosts the codebase and scripts for the PolySpeech-100 benchmark, which evaluates speech understanding across 100+ languages and dialects. The code mainly facilitates downloading, preparing, and evaluating the large-scale PolySpeech-100 dataset, as well as running inference on different speech-to-text and speech-to-semantic models.
Key scripts include:
prepare_dataset.py: Handles downloading and restoring the dataset from Hugging Face to local .wav and .txt files.inference_qwen2_5_omni.pyandinference_covoaudio.py: Provide wrappers to run zero-shot and few-shot inference for different model architectures on PolySpeech-100 data.evaluate.py: Computes accuracy and generates performance reports against the benchmark.
The repo focuses on evaluation and benchmarking rather than training or model architecture release. Users run inference using pre-trained weights available from separate official sources as described in the README. This design aligns with the paper's goal of establishing a rigorous evaluation standard rather than proposing new model training code.