Temporally-Aligned Evaluation
Temporally-Aligned Evaluation for Audio-Driven Talking Head Generation

Introduces a sequence-alignment approach using Soft-DTW to evaluate audio-driven talking-head generation, robustly handling timing shifts in speech motion. This unified metric framework benchmarks 20 methods across diverse datasets, revealing clearer trade-offs in key performance aspects.
Demos
These demo videos showcase MuseTalk's high-quality audio-driven lip synchronization, emphasizing precise mouth shapes, natural head and facial movements, and expressive animation fidelity. Watch for artifact-free generation, real-time smoothness, and robustness across speaking styles, reflecting MuseTalk's lip-sync accuracy, clarity, and temporal consistency.
Links
Paper & demos
Code & resources
Abstract
Audio-driven talking-head generation has advanced rapidly, yet existing evaluation protocols mainly rely on frame-wise metrics that assume strict temporal correspondence between generated and reference videos. This assumption does not match speech-driven facial motion, which naturally includes slight timing shifts, different speaking speeds, and stylistic variations. As a result, conventional metrics may treat harmless timing differences as quality errors, making it harder to fairly compare methods and understand their trade-offs. In this work, we argue that evaluation of dynamic generative models should be formulated as a sequence-alignment problem rather than independent frame comparison. We introduce a unified sequence-level reformulation that integrates Soft Dynamic Time Warping into established evaluation pipelines. By aligning feature trajectories while preserving temporal order, the proposed framework provides robustness to bounded temporal misalignments without altering the underlying perceptual, identity, or synchronization encoders. We show that frame-wise evaluation can be viewed as a special case under rigid alignment, while sequence-level alignment provides improved stability, lower sensitivity to timing differences, and clearer separation between modeling paradigms. Building on this principled formulation, we conduct a large-scale benchmark of 20 methods across seven datasets spanning canonical, in-the-wild, and style-diverse scenarios under standardized protocols. Extensive experiments show that temporally aligned metrics are more robust to timing differences, provide more consistent results across datasets, and better reveal systematic trade-offs between modeling paradigms, such as synchronization versus realism and expressiveness versus stability.
Introduction
This paper is an evaluation and benchmarking study for audio-driven talking-head generation. It does not propose a new video generator. Instead, it argues that the dominant evaluation practice in the field is structurally mismatched to the problem: most metrics compare generated and reference videos frame by frame, implicitly assuming strict temporal correspondence. In talking-head synthesis, however, a visually good result may differ from the reference by small phase shifts, speaking-rate variation, or stylistic motion changes. Under rigid frame pairing, those harmless timing differences can be counted as errors.
The central claim is that evaluation should be reframed as a sequence-alignment problem. The paper introduces a unified reformulation of several commonly used metrics using Soft Dynamic Time Warping (Soft-DTW), so that feature trajectories are aligned while preserving temporal order. This preserves the original perceptual, identity, and synchronization encoders, but changes how their outputs are aggregated: from independent frame averaging to temporally aligned sequence matching.
The benchmark is large for this subfield: the authors evaluate 20 methods across seven datasets, spanning canonical benchmarks and two curated stress-test subsets called Wild and Avatar. The reported results are meant to clarify trade-offs between motion paradigms, such as synchronization versus realism and expressiveness versus stability.

Problem Statement and Core Motivation
Audio-driven talking-head generation has advanced quickly, but evaluation remains fragmented. Prior work typically reports a mixture of LPIPS, CSIM, SyncNet-based scores, pixel reconstruction measures such as PSNR and SSIM, and motion smoothness metrics. The paper’s critique is that these metrics are usually computed under the assumption that generated and reference frames should correspond one-to-one in time. That assumption is often too strict for speech-driven facial motion, which naturally contains small timing deviations.
The paper distinguishes between two desired properties of evaluation:
- Temporal order preservation: the metric should not allow arbitrary reordering of facial motion.
- Temporal elasticity: the metric should tolerate bounded, perceptually acceptable timing shifts.
Soft-DTW is selected because it gives a monotonic, globally aligned, differentiable trajectory distance. In the authors’ framing, frame-wise evaluation is just the rigid special case; sequence-level alignment is the more general and more appropriate formulation for dynamic generation.
Unified Temporal Reformulation of Metrics
The paper’s main methodological contribution is a metric-side reformulation. It keeps the underlying feature encoders fixed and only changes how framewise features are matched across time.
For a generated video $\mathbf{X} = \{\mathbf{x}_t\}_{t=1}^{T}$ and a reference video $\mathbf{Y} = \{\mathbf{y}_t\}_{t=1}^{S}$, the standard framewise distance is written as
$$ \mathrm{Dist}_{\mathrm{frame}}(\mathbf{X}, \mathbf{Y}) = \frac{1}{T} \sum_{t=1}^{T} d\big(\phi(\mathbf{x}_t), \phi(\mathbf{y}_t)\big), $$
where $\phi(\cdot)$ is the relevant encoder and $d(\cdot, \cdot)$ is a feature-space distance, typically squared $\ell_2$.
The sequence-level version replaces this diagonal pairing with Soft-DTW over monotonic alignment paths $\Pi$:
$$ \mathrm{SoftDTW}_{\gamma}(\mathbf{F}, \mathbf{G}) = -\gamma \log \sum_{\pi \in \Pi} \exp\left(-\frac{1}{\gamma} \sum_{(t,s) \in \pi} d(\mathbf{F}_t, \mathbf{G}_s)\right), $$
where $\mathbf{F} = \{\phi(\mathbf{x}_t)\}_{t=1}^{T}$ and $\mathbf{G} = \{\phi(\mathbf{y}_s)\}_{s=1}^{S}$. The sequence distance is then normalized by $T_{\max} = \max(T,S)$:
$$ \mathrm{Dist}_{\mathrm{seq}}(\mathbf{X}, \mathbf{Y}) = \frac{\mathrm{SoftDTW}_{\gamma}(\mathbf{F}, \mathbf{G})}{T_{\max}}. $$
The authors emphasize that this reformulation does not modify the encoders. LPIPS still uses perceptual network features, CSIM still uses face-recognition embeddings, and synchronization still relies on SyncNet-style embeddings. The only change is the introduction of sequence alignment before aggregation.
Metric instantiations
- Perceptual quality: LPIPS is computed in a temporally aligned feature space rather than averaged frame by frame.
- Identity preservation: CSIM is applied to face embeddings and aligned as a sequence, reducing sensitivity to transient pose or detector noise.
- Audio-visual synchronization: SyncNet-based scores are turned into sequence-level distances, allowing for variable speaking rate and minor asynchrony.
- Motion naturalness: the paper replaces interpolation-based pixel smoothness with semantic trajectories for pose and expression.
Semantic Motion Trajectory Modeling
In addition to perceptual, identity, and synchronization metrics, the paper redesigns motion smoothness evaluation. Rather than measuring pixel-space interpolation errors, it extracts explicit motion features from a motion encoder and separates them into rigid head pose and non-rigid expression deformation.

The motion feature vector is described as 70-dimensional, with a 7D rigid component and a 63D expression component. The rigid part includes three Euler rotations, one scale term, and a 3D translation vector. The expression part encodes 21 keypoints in 3D, spanning regions such as the forehead, eyebrows, cheeks, eyes, nose, mouth, chin, and neck. The paper evaluates these components separately using Soft-DTW:
$$ \mathrm{Dist}^{\mathrm{pose}}_{\mathrm{seq}}(\mathbf{X}, \mathbf{Y}) = \frac{\mathrm{SoftDTW}_{\gamma}(\mathbf{P}, \mathbf{P}^{\mathrm{ref}})}{T_{\max}}, $$
$$ \mathrm{Dist}^{\mathrm{expr}}_{\mathrm{seq}}(\mathbf{X}, \mathbf{Y}) = \frac{\mathrm{SoftDTW}_{\gamma}(\mathbf{K}, \mathbf{K}^{\mathrm{ref}})}{T_{\max}}. $$
This makes motion evaluation more interpretable: pose smoothness and expression smoothness are no longer collapsed into a pixel-level proxy, and the score is less sensitive to short-term jitter or slight timing offsets.
Theoretical Properties of the Sequence-Level Formulation
The paper provides three conceptual properties of the Soft-DTW reformulation.
- Frame-wise evaluation as a special case: if the alignment path is restricted to the identity diagonal, sequence distance collapses to the ordinary framewise average.
- Monotonicity: admissible alignment paths are monotonic, so temporal order is preserved.
- Bounded sensitivity to shifts: if one sequence is a temporally shifted version of the other with bounded shift magnitude, the alignment path can deviate only locally, and the change in score is bounded proportionally to the shift size and the typical feature distance.
These properties are important because they explain why sequence-level metrics are more robust without becoming indifferent to genuine errors. The score remains sensitive to structural mismatches, but it is less dominated by harmless phase offsets.
In the paper’s interpretation, the key theoretical point is that the temporal evaluation problem should not be reduced to independent frame comparisons. Instead, the evaluation itself should be treated as a trajectory-matching problem in feature space.
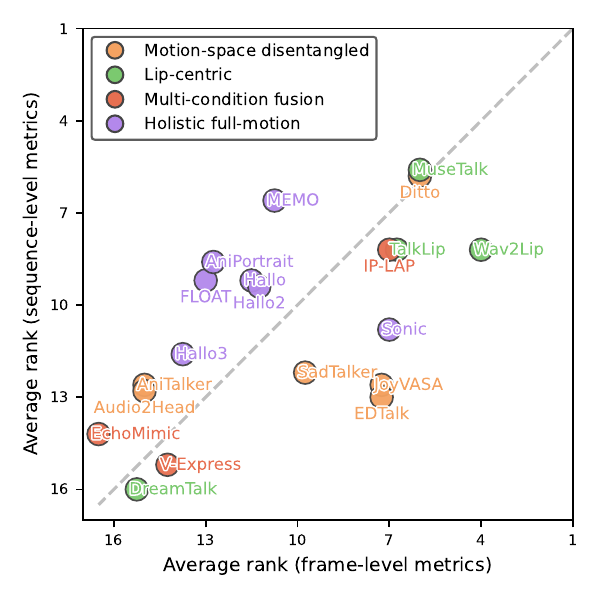
Benchmark Design
The benchmark is constructed to support fair, reproducible, cross-dataset evaluation. The authors first survey 117 candidate methods and then filter them using three criteria: publication quality, public code availability, and availability of pretrained checkpoints. This leaves 20 representative methods for the final benchmark.
The methods are grouped by motion-modeling paradigm, which the paper argues is a more meaningful comparison axis than individual architectural details. The four paradigms are:
- Lip-centric methods, which focus on mouth dynamics and speech synchronization.
- Motion-space disentangled methods, which decompose motion into interpretable components such as pose, latent motion bases, or dense motion fields.
- Multi-condition fusion methods, which combine audio with identity, pose, landmarks, emotions, or other control signals.
- Holistic full-motion methods, which map audio and optional conditions directly to full facial motion without explicit factorization.
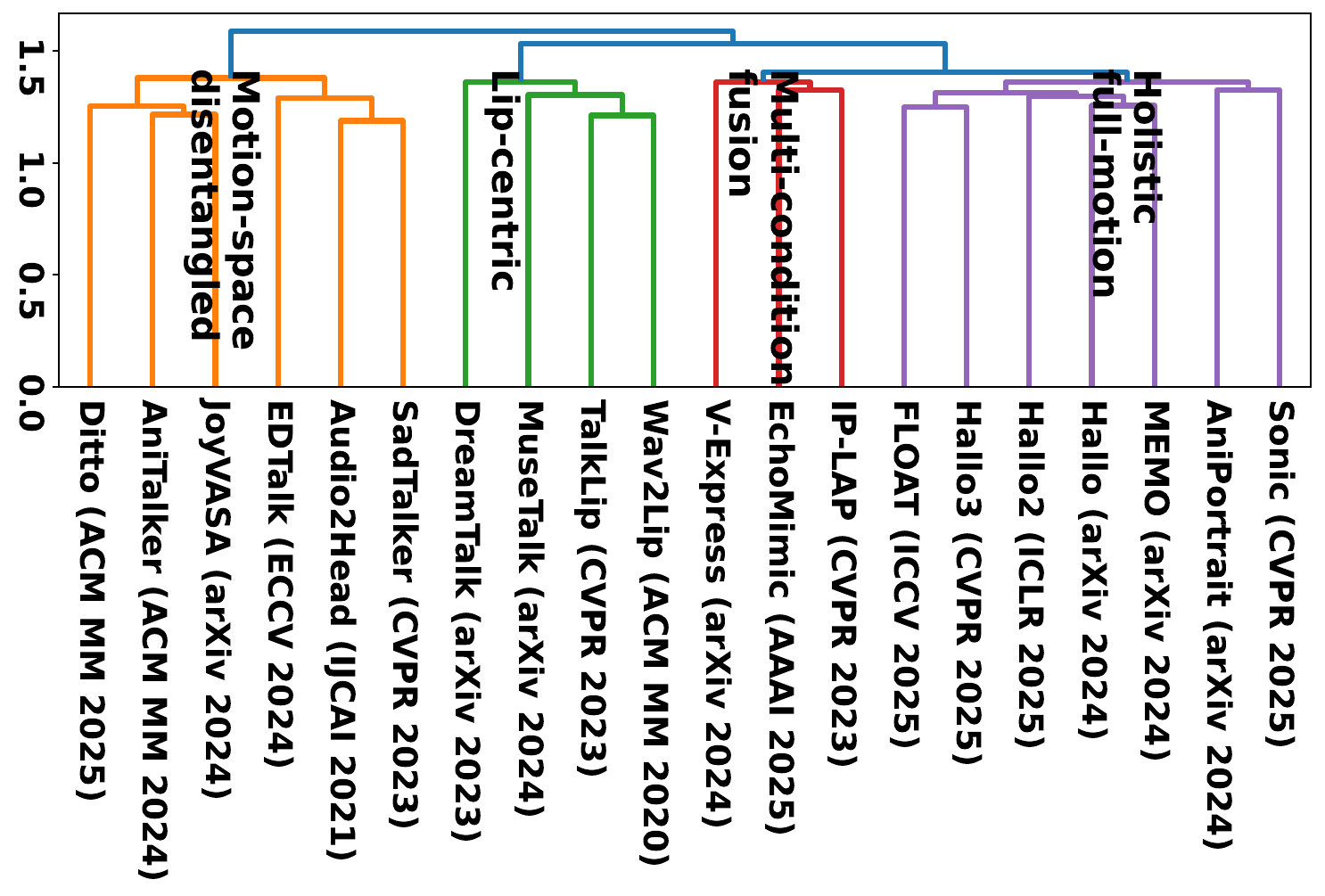
To validate the taxonomy, the paper also runs unsupervised semantic clustering on paper titles and abstracts using TF-IDF features and Ward linkage. The resulting dendrogram is reported to align with the manually defined paradigms, supporting the claim that the grouping reflects genuine structure in the literature rather than subjective choice.
Dataset Construction
The benchmark uses five canonical public datasets plus two curated subsets designed to stress robustness and distribution shift. The canonical datasets are HDTF, VoxCeleb2, CelebV-HQ, MEAD, and RAVDESS. For HDTF, VoxCeleb2, and CelebV-HQ, the paper selects 100 videos each. VoxCeleb2 is restricted to high-quality interview recordings to reduce compression artifacts. For RAVDESS, both speaking and singing scenarios are included, again yielding 100 videos. For MEAD, 47 identities are sampled with at least two videos per identity, also totaling 100 videos.
All selected clips are trimmed to 4-10 seconds, with the first frame and corresponding audio track extracted, and audio resampled to 16 kHz. This standardization is intended to keep the comparison focused on dynamic talking-head behavior rather than long-sequence artifacts or dataset-specific preprocessing differences.
Two additional subsets are introduced:
- Wild contains 60 videos with real-world challenges such as occlusion, rapid head motion, expressive speech, and dynamic gestures.
- Avatar contains 40 videos spanning photorealistic AI-generated faces, 2D and 3D animation, artistic portraits, sculptures, sketches, animals, and humanoids.
The purpose of these subsets is not to replace the canonical benchmarks, but to test generalization under difficulty-driven and style-driven distribution shifts. According to the paper, these two shifts affect different aspects of model behavior: Wild stresses robustness to noise and motion variability, while Avatar stresses appearance transfer and stylistic generalization.
| Dataset group | Datasets | Size / construction | Why it matters |
|---|---|---|---|
| Canonical benchmarks | HDTF, VoxCeleb2, CelebV-HQ, MEAD, RAVDESS | 100 videos per dataset, 4-10 s clips, audio resampled to 16 kHz | Compatibility with prior work and standardized cross-method comparison |
| Robustness subset | Wild | 60 videos | Challenging real-world motion, occlusion, and expression variability |
| Style-diversity subset | Avatar | 40 videos | Appearance shift across photorealistic, animated, artistic, and non-human subjects |
Evaluation Protocol and Metric Families
The benchmark covers six metric families, organized to capture different dimensions of talking-head quality:
- Perceptual visual quality: FID, FVD, LPIPS, IQA, VQA, CPBD.
- Pixel-level reconstruction fidelity: PSNR, SSIM, MS-SSIM, L1.
- Identity preservation: CSIM.
- Audio-visual synchronization: Sync-C and Sync-D.
- Expression and motion naturalness: Smooth, plus the sequence-level pose and expression variants.
- Computational efficiency: FPS.
The paper’s radar plots and discussion emphasize that these metrics are complementary, not interchangeable. In particular, frame-level metrics and sequence-level metrics tend to capture different notions of quality and are not tightly correlated.
Results and Analysis
The experimental section is organized around four themes: sensitivity to the Soft-DTW temperature, paradigm-level performance, robustness under dataset shift, and interactions among different metric families.
Sensitivity to the Soft-DTW temperature
The Soft-DTW temperature $\gamma$ trades off between rigid alignment and smooth aggregation over multiple alignment paths. The paper evaluates the sequence-level metrics across a range of $\gamma$ values, and reports that the metrics are stable over a broad regime, especially for $\gamma \in [10^{-4}, 0.05]$. This is important because it suggests the method does not depend on a delicate hyperparameter choice.
The key comparison is between the original framewise scores and their sequence-level counterparts. The paper reports that the rigid baseline consistently deviates from the aligned variants, especially on Avatar, where timing and appearance shifts are more pronounced. The stabilization effect is strongest for synchronization and motion-related metrics, while LPIPS changes less because it is less temporally sensitive. The pose- and expression-based motion metrics are reported to be nearly invariant to $\gamma$.
Paradigm-level performance
The strongest high-level finding is that no single paradigm dominates all metrics. Instead, each paradigm specializes in a subset of quality dimensions:
- Lip-centric methods perform best on pixel reconstruction and synchronization metrics. They are especially strong on PSNR, SSIM, MS-SSIM, L1, Sync-C, and Sync-D.
- Multi-condition fusion methods lead on identity preservation, achieving the strongest CSIM and CSIM$_{\mathrm{seq}}$ values across datasets.
- Motion-space disentangled methods tend to be most efficient and often score well on frame-level smoothness, reflecting reduced short-term jitter.
- Holistic full-motion methods achieve the best perceptual realism and stronger long-range temporal coherence, particularly in FID, FVD, IQA, and VQA.
The paper repeatedly stresses that these are not contradictory results: they reflect different modeling biases. For example, a model can achieve excellent lip-audio synchronization without necessarily obtaining the best holistic realism or identity stability.
![Normalized performance comparison. Each column corresponds to a quantitative metric and each row to a method. Methods are grouped by paradigm using color-coded labels. For each metric, scores are min-max normalized across methods to the range [0, 1], where higher values indicate better performance. Metrics in which lower values denote better quality ( , FID, LPIPS) are inverted to ensure consistent interpretation. The figure provides a unified view of cross-metric consistency and paradigm-level performance trends. Darker colors indicate better performance.](https://akapulu-public-assets.s3.us-west-1.amazonaws.com/blogs/research-digest/p/2606.01031/arxiv/fig/_preview/imgs__normalized_matrix_heatmap.png)
Robustness to dataset difficulty and diversity
When moving from canonical benchmarks to the Wild subset, the paper reports gradual degradation rather than catastrophic failure. That is, metrics contract somewhat under real-world noise and motion variability, but the relative ordering of paradigms remains stable. This suggests that the learned inductive biases generalize reasonably well under realistic recording conditions.
The Avatar subset behaves differently. Stylized and synthetic faces often look visually clean, which can improve perceptual measures such as IQA, VQA, and CPBD. At the same time, distributional metrics such as FID and FVD become less favorable because the visual statistics move away from real human videos. Synchronization remains comparatively stable across datasets, indicating that mouth articulation quality depends more on motion modeling than on the underlying appearance domain.
The paper’s conclusion from these comparisons is that dataset difficulty and dataset diversity are not the same thing. Wild mostly probes robustness to noise and motion complexity, while Avatar probes transfer across appearance styles and subject types.
Metric-level trade-offs and interactions
The authors emphasize that the metric space itself reveals important trade-offs:
- Pixel versus perceptual: strong reconstruction scores do not imply high perceptual realism.
- Frame versus sequence: sequence-level metrics suppress transient timing noise, but can also hide short-lived instability that frame-level scores expose.
- Sync versus realism: accurate lip synchronization is not sufficient for globally realistic or temporally coherent video.
- Quality versus speed: stronger realism and identity preservation often come with lower FPS, while lighter disentangled models are faster.
These findings support the paper’s broader message: talking-head evaluation is inherently multi-objective, and no single metric captures all dimensions of quality.
Interpretation of the Main Empirical Claims
Across the benchmark, the proposed temporally aligned metrics are reported to be more robust to timing differences, more consistent across datasets, and better at revealing trade-offs between modeling paradigms. Several concrete effects are highlighted:
- Sequence-level LPIPS, CSIM, Sync-D, and motion metrics are less sensitive to small temporal offsets than their framewise counterparts.
- Rankings change meaningfully when moving from framewise to temporally aligned evaluation, which indicates that some apparent wins under conventional metrics are artifacts of alignment assumptions.
- Frame-level metrics are often strongly correlated with one another, while the sequence-level metrics provide complementary information.
- Paradigm differences are clearer under the proposed evaluation, especially for synchronization and motion coherence.
The paper’s ranking scatter plot shows that many methods move away from the diagonal when sequence-level metrics are used, meaning the new evaluation can promote or demote methods relative to conventional framewise scoring. This is presented as evidence that temporal alignment is not a minor implementation detail, but a substantive part of fair evaluation.
Limitations and Scope
The paper is explicit about several limitations:
- No method fine-tuning: all systems are evaluated in their publicly available pretrained form. This is fair and reproducible, but it does not measure adaptation capacity.
- Coverage is still incomplete: the benchmark does not yet include some harder cases such as extreme head poses, heavy occlusion, multi-speaker interaction, conversational dynamics, or cross-lingual audio.
- Automated metrics are incomplete: even with temporally aware scoring, automatic evaluation cannot fully replace human judgment of expressiveness or communicative quality.
- Taxonomy is current-state dependent: the four-paradigm organization reflects the present landscape of 2D methods and will need to evolve as diffusion-based, 3D-aware, and multimodal systems mature.
These limitations are framed as future benchmark directions rather than flaws in the proposed evaluation principle. The authors argue that the key contribution is the shift toward standardized, temporally aware, and paradigm-aware comparison.
Takeaway
The paper’s main takeaway is straightforward but important: talking-head evaluation should respect temporal structure. By turning framewise scores into Soft-DTW-aligned sequence distances, the benchmark better matches the dynamics of speech-driven facial motion. The resulting evaluation is more stable under small timing shifts, more interpretable across motion categories, and more revealing about the actual trade-offs between lip synchronization, realism, identity preservation, motion smoothness, and speed.
For a conversational-AI or talking-head team, the practical implication is that a model’s apparent ranking can change once evaluation becomes temporally aware. Therefore, any serious comparison across systems should consider sequence alignment, cross-dataset robustness, and multiple metric families rather than relying on a single framewise score.