Neuromorphic SpeechMamba
Spiking and Event-driven Neuromorphic Mamba Models for Efficient Speech Recognition
Introduces spiking and event-driven neuromorphic variants of SpeechMamba to improve activation sparsity for efficient edge speech recognition. It uniquely combines hardware-aware simulation with sparse neural design, bridging theory and practical benefits on resource-constrained devices.
Links
Paper & demos
Code & resources
Impact
Abstract
Deep learning has greatly advanced automatic speech recognition (ASR), enabling widespread deployment on edge devices such as smartphones and smart home systems. However, the computational and energy demands of deep neural networks pose significant challenges for such resource-constrained deployments, introducing latency and limiting real-time interaction. Neuromorphic computing offers a promising solution by introducing activation sparsity through spiking neural networks (SNNs) and event-driven neural networks, converting dense operations into sparse computations. However, a study that evaluates the hardware benefits of different neuromorphic strategies remains lacking for ASR. This paper explores spiking and event-driven neuromorphic neural networks to improve activation sparsity in the state-of-the-art SpeechMamba model for ASR. We introduce an event-driven SpeechMamba with FATReLU activation, achieving over 60% activation sparsity with less than 1% accuracy degradation on LibriSpeech. We also propose a spiking SpeechMamba that attains over 70% sparsity while using 30% fewer parameters than comparable SNNs. Finally, we develop a cycle-accurate event-driven simulator enabling flexible algorithm-hardware co-exploration, which helps us identify computational bottlenecks and yields over 10% additional efficiency improvements.
Introduction
This paper studies how to make a modern speech recognition backbone more suitable for edge deployment by introducing activation sparsity into SpeechMamba, a state-of-the-art speech model that combines Mamba state-space blocks with self-attention. The motivation is practical: automatic speech recognition has become important on smartphones and smart-home devices, but dense deep neural networks still impose substantial latency, memory traffic, and energy cost. The paper argues that neuromorphic computing offers a better fit for resource-constrained ASR because sparse activations can replace dense computation with event-driven or spike-driven execution.
The central gap the paper identifies is not just how to increase sparsity, but how to evaluate whether sparsity actually translates into hardware benefit. Prior ASR neuromorphic work typically reports algorithmic metrics such as synaptic operations or theoretical energy estimates, which do not account for irregular sparsity, state maintenance, and data movement overhead on realistic digital hardware. To address this, the paper proposes two sparse variants of SpeechMamba and a cycle-accurate simulator for event-driven execution on a RISC-V Ibex core.
The reported contributions are threefold: an event-driven SpeechMamba with FATReLU activations, a spiking SpeechMamba with leaky integrate-and-fire neurons and spike-based attention, and a hardware-aware simulator that supports algorithm-hardware co-exploration at the operation level. The overarching theme is that sparsity must be designed, trained, and measured with hardware behavior in mind rather than treated as a purely algorithmic property.
Background and architectural context
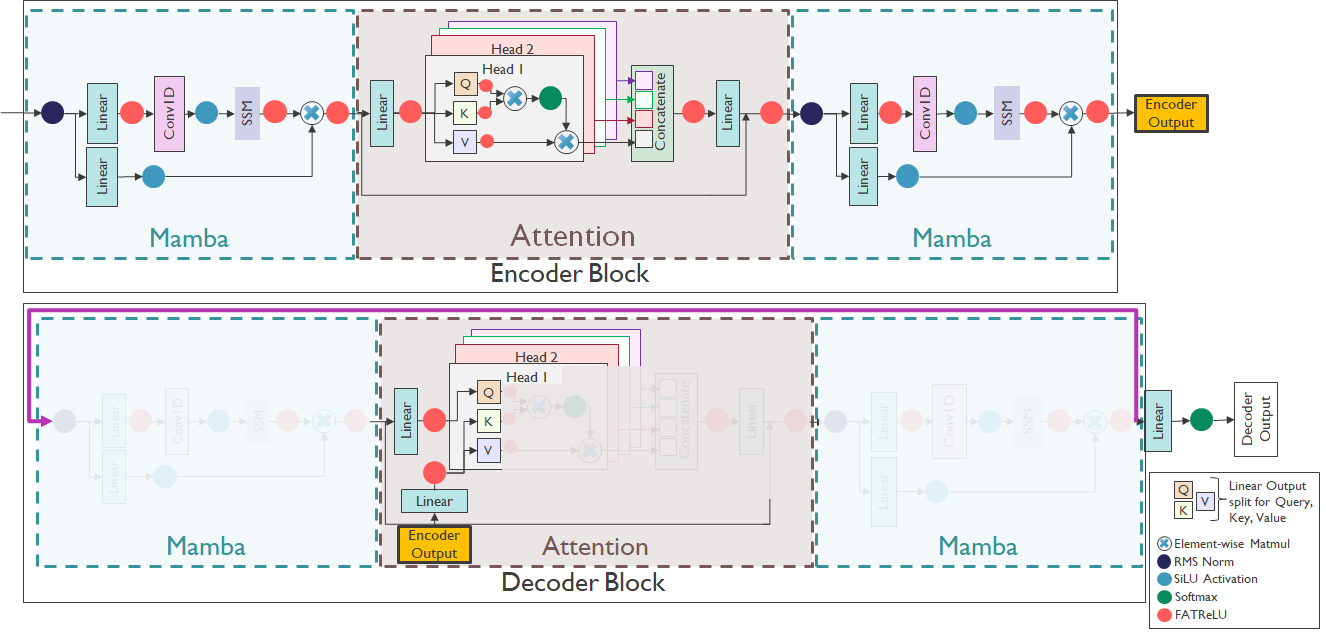
SpeechMamba is the paper’s starting point because it already combines strong speech-recognition performance with a compact sequence model. In the cited SpeechMamba design, the encoder-decoder architecture is organized into repeated units, and each unit contains two Mamba blocks interleaved with self-attention layers. The Mamba blocks are used to capture long-range temporal dependencies, while the attention layers model lower-level temporal structure. The paper leverages this hybrid structure as a foundation for sparse and neuromorphic variants.
The paper also situates itself relative to attention-based spiking networks. It draws on Spikformer for spike-based self-attention and on SpikMamba for spiking Mamba blocks, both of which show that sequence modeling can be adapted to sparse binary or event-driven computation. However, instead of simply transferring those designs into speech recognition, the paper adapts them to the specific structure of SpeechMamba and evaluates the resulting models on LibriSpeech.
A second line of background is event-driven digital neuromorphic processing. The paper emphasizes that event-driven computation is most useful when activations are sparse enough that downstream operations and memory accesses can be skipped. It also notes that recent work has generalized the idea beyond binary spikes to graded activations, which can retain some of the efficiency benefits while reducing the quantization burden of strictly binary SNNs. The paper’s event-driven design is therefore not just a conceptual analogy to spiking neurons; it is a concrete attempt to use sparsity to reduce real execution cost.
Method
Event-driven SpeechMamba with FATReLU
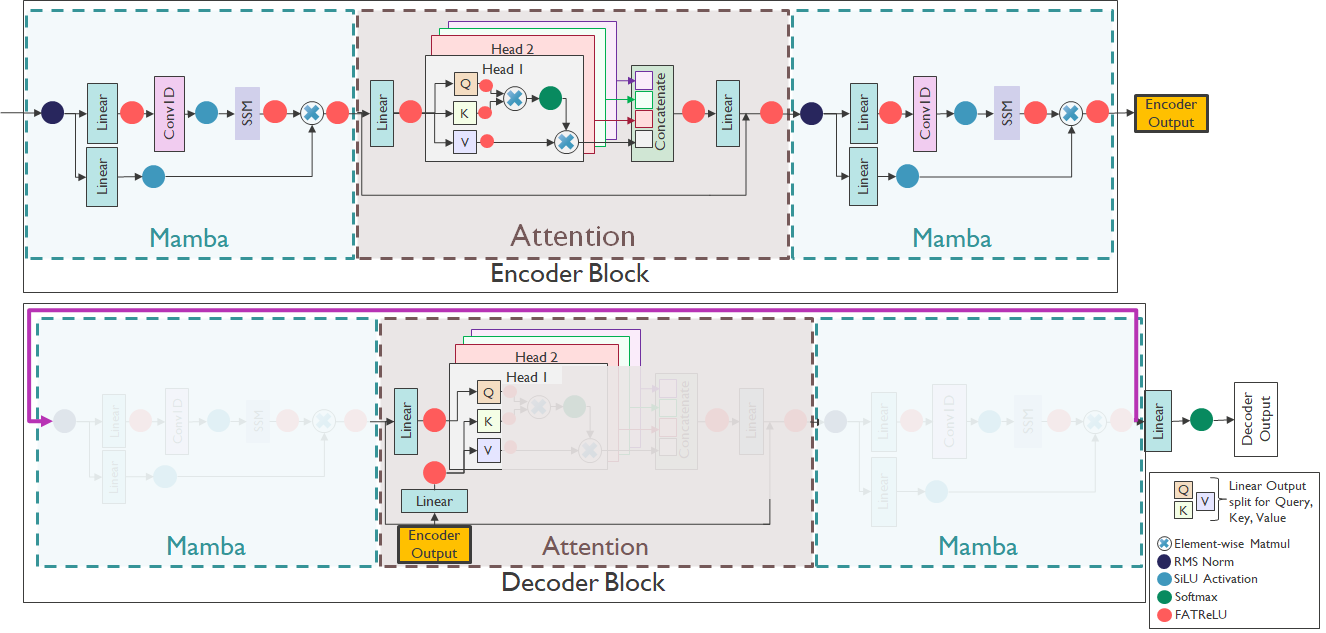
The event-driven variant, E-SpeechMamba, introduces FATReLU activations at carefully chosen bottleneck points in the SpeechMamba architecture. The purpose of these activations is to suppress small values so that downstream operations can be skipped when activations fall below a threshold. The paper states that activations are inserted after each linear layer, convolutional layer, and SSM block, but the insertion points inside SSM blocks are chosen carefully so as not to disrupt the learning dynamics of the SSM parameters $A$, $B$, $C$, and $D$.
The FATReLU function is defined as
$$ \operatorname{FATReLU}(x) = \begin{cases} x & \text{if } x \ge T, \\ 0 & \text{otherwise}, \end{cases} $$
where $T > 0$ is a learnable or tuned threshold. The paper’s implementation uses a three-stage sparsification pipeline:
- ReLU pre-training. ReLU is inserted at key bottleneck points and the model is trained with a sparsity loss to establish a sparse baseline without yet using thresholded FATReLU.
- FATReLU threshold initialization. ReLU layers are replaced with FATReLU, and thresholds are initialized from data using activation statistics and loss-constrained threshold sweeping.
- FATReLU threshold finetuning. Thresholds are further updated during training with an explicit sparsity regularizer.
The threshold initialization procedure is important because it turns sparsification into a controlled optimization problem rather than an ad hoc pruning step. The paper evaluates a representative batch on the ReLU-pretrained model to obtain a reference loss, called the base loss, then collects activation statistics at each insertion point. Each FATReLU threshold is initialized to the mean of the lowest 10% of recorded activations. The model is then re-evaluated to obtain an updated loss, and thresholds are progressively increased by sweeping activation deciles so long as the normalized loss ratio $\text{updated\_loss} / \text{base\_loss}$ remains below a tolerance $K$. This lets the method push sparsity aggressively while bounding degradation.
During finetuning, the paper adds a sparsity-inducing term
$$ L_{\mathrm{spar}} = \sum_i \left( \operatorname{FATReLU}(\mathbf{x}_i) + \left( \frac{1}{T_i} \right)^2 \right), $$
where $i$ indexes the FATReLU layers. This term jointly discourages large activations and very small thresholds, both of which reduce the chance that downstream computations can be skipped. In effect, the objective encourages the model to move information through a smaller number of larger, more decisive events.
Spiking SpeechMamba
The second sparse variant, S-SpeechMamba, replaces the event-driven Mamba modules with spiking Mamba blocks inspired by SpikMamba and uses spiking self-attention inspired by Spikformer. The model uses leaky integrate-and-fire neurons and binary spike trains instead of graded activations. In the attention block, the input is linearly projected into query, key, and value representations, normalized, and passed through LIF layers to produce spikes. Attention is then computed from the similarity between spiking queries and keys, without softmax normalization, and applied to the spiking values.
The paper emphasizes that this preserves global dependency modeling while replacing dense arithmetic with binary event propagation. Compared with the event-driven FATReLU approach, the spiking design is more aggressively sparse but also introduces state maintenance overhead because membrane potentials must be preserved across time steps.
To train the spiking model, the paper adds a firing-rate regularization term with two components:
$$ L_{\text{quiet}} = \frac{1}{L} \sum_{l=1}^{L} \max\left(0, r_{\min} - \bar{r}^{(l)}\right), $$
$$ L_{\text{burst}} = \frac{1}{L} \sum_{l=1}^{L} \max\left(0, \bar{r}^{(l)} - r_{\max}\right), $$
where $\bar{r}^{(l)}$ is the average firing rate in spiking layer $l$, and $r_{\min}$ and $r_{\max}$ define a target firing-rate window. The paper states that $L_{\text{quiet}}$ prevents dead or nearly silent layers, while $L_{\text{burst}}$ prevents overly active layers and thereby promotes sparsity. The overall firing-rate regularization is the sum of these two terms.
Cycle-accurate event-driven simulator
A key novelty of the paper is its simulator for operation-level, event-driven dataflow execution on a RISC-V Ibex core. The simulator is designed to emulate generic digital neuromorphic processors such as SENECA and SpiNNaker2 rather than a single fixed chip. It models atomic inputs and partial-sum computation inside layers, so that the effect of unstructured sparsity can be captured more faithfully than by a purely analytical estimate.
In the simulation framework, both E-SpeechMamba and S-SpeechMamba are adapted to an event-driven dataflow where each layer forwards partial outputs to downstream layers as soon as atomic events are available. For the spiking model, spikes and non-spikes are represented as integer values $1$ and $0$. This allows the simulator to skip multiplications involving zeros, while non-zero spikes propagate the corresponding real-valued weights. The result is a hardware-aware execution model that reflects when sparse computation can and cannot be exploited.
The event-driven networks are lowered onto a simple Ibex-based system and compiled with the lowRISC GCC toolchain. Execution is modeled on an RV32IMC Ibex core with unified instruction and data memory, implemented in Verilator and instrumented with performance counters. The simulator therefore provides cycle counts, instruction counts, memory access counts, and latency estimates for the sparse models.
The paper then uses simulation feedback for further optimization. After profiling, it identifies bottlenecks in the Mamba block and inserts additional FATReLU points to obtain an optimized E-SpeechMamba. This makes the simulator not just a measurement tool but a design-space exploration tool.
Experimental setup
All experiments are conducted on LibriSpeech, a large-scale English speech corpus of approximately 1,000 hours sampled at 16 kHz. The paper uses all training splits, about 980 hours, for training. Evaluation is reported on the standard dev-clean, dev-other, test-clean, and test-other splits.
Training and pre-training are performed with SpeechBrain on a single NVIDIA A100 GPU in full precision. The random seed is fixed to 74443 for reproducibility. Models are trained for 100 epochs with Adam using $\beta_1 = 0.9$, $\beta_2 = 0.98$, and $\epsilon = 10^{-9}$. The initial learning rate is $10^{-3}$ and is scheduled with Noam warmup for 25,000 steps. Gradient accumulation with factor 4 is used, gradients are clipped at 5.0, and dynamic batching is enabled with a maximum batch length of 1024 frames.
For E-SpeechMamba and E-SpeechMamba (Optimized), threshold initialization is performed on an Intel Xeon CPU, followed by an additional 20 epochs of finetuning. Event-driven simulations are then executed on an Intel Core i7-9750H CPU hosting the Ibex simulator.
Main results on LibriSpeech
The paper compares the sparse SpeechMamba variants against both dense speech recognition systems and prior spiking models. The main metric is word error rate (WER); lower is better. The paper also reports parameter count and average activation sparsity.
| Model | dev-clean WER (%) | dev-other WER (%) | test-clean WER (%) | test-other WER (%) | Parameters (M) | Sparsity (%) |
|---|---|---|---|---|---|---|
| Whisper-Large-V2 | -- | -- | 2.7 | 5.2 | 1550 | -- |
| Pruned Conformer | -- | -- | 3.27 | 6.89 | 71.5 | 50 |
| SpeechMamba | 2.16 | 5.13 | 2.32 | 5.23 | 67.6 | -- |
| Spike-driven Transformer | 8.7 | 20.7 | 8.9 | 22.3 | 99.4 | -- |
| IML-Spikeformer | 3.1 | 8.3 | 3.4 | 7.9 | 99.4 | -- |
| Base Model (SpeechMamba) with naive sparsification | 2.30 | 5.51 | 2.47 | 5.86 | 67.6 | 20 |
| E-SpeechMamba | 2.90 | 7.40 | 3.20 | 7.80 | 67.6 | 62 |
| S-SpeechMamba | 4.27 | 9.34 | 4.71 | 9.98 | 67.8 | 72 |
| E-SpeechMamba (Optimized) | 3.10 | 7.80 | 3.60 | 8.30 | 67.6 | 64 |
The dense SpeechMamba baseline achieves 2.32% WER on test-clean and 5.23% on test-other. The naively sparsified base model degrades slightly to 2.47% and 5.86% while reaching 20% sparsity, showing that naïve ReLU insertion alone does not deliver substantial sparsity. E-SpeechMamba increases sparsity to 62% while keeping test-clean WER at 3.20% and test-other WER at 7.80%. The paper characterizes this as less than 1% accuracy degradation on LibriSpeech relative to the dense baseline in the summary sense, and stresses that the model achieves over 60% activation sparsity.
S-SpeechMamba reaches the highest sparsity at 72% and uses 67.8 million parameters, which the paper describes as 30% fewer parameters than comparable SNNs. Its WER is higher than the event-driven model, with 4.71% on test-clean and 9.98% on test-other, but it demonstrates that a highly sparse spiking SpeechMamba is feasible at the scale of large-vocabulary ASR. The optimized E-SpeechMamba improves over the original event-driven variant in hardware-relevant ways while keeping sparsity high at 64%.
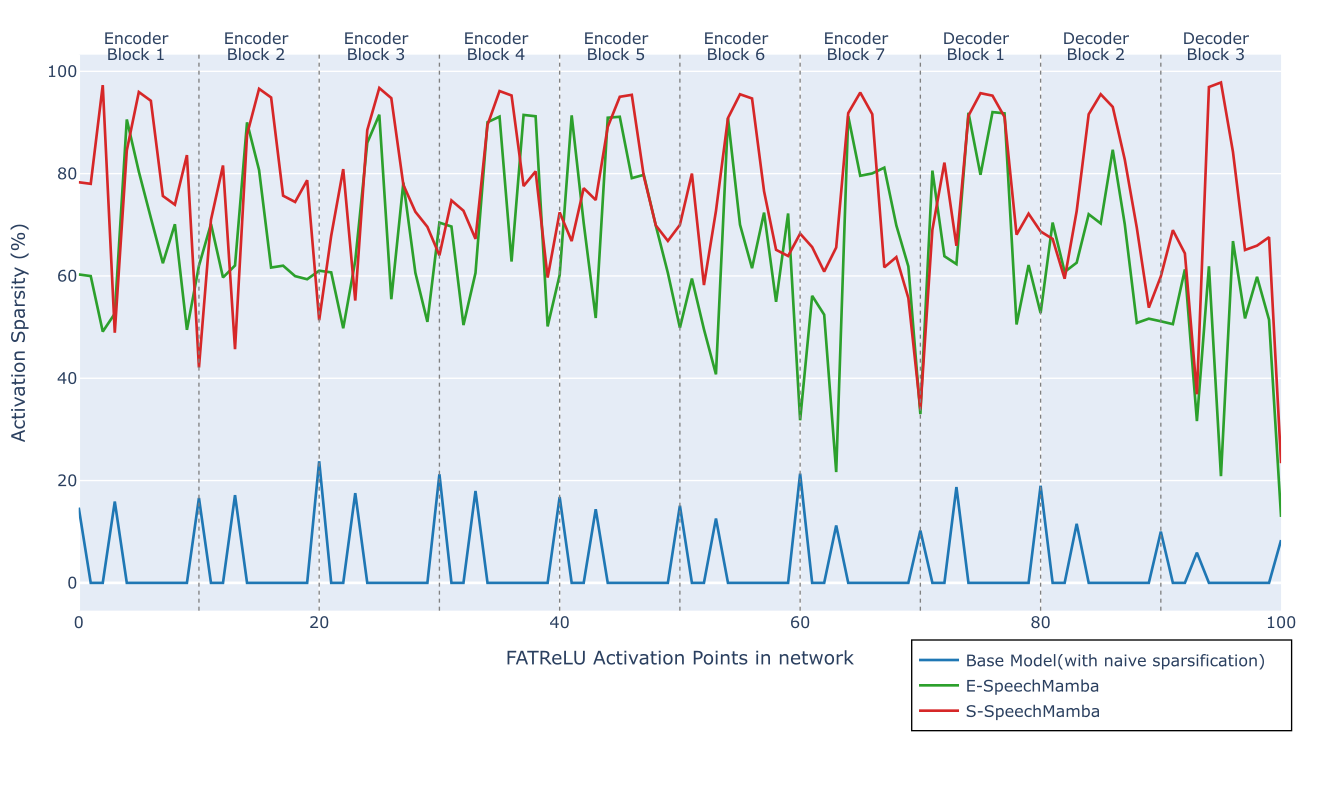
The paper also analyzes internal activation sparsity on the first 10% of the test-clean set. Sparsity varies substantially across layers and insertion points, ranging from above 90% at some points to below 40% at others. This uneven distribution is important because hardware gains depend not only on average sparsity, but also on where that sparsity occurs and how much work each layer represents.
Hardware-aware simulation results
The simulator evaluates four metrics relative to the naively sparsified base model: CPU cycles, CPU instructions, memory accesses, and latency. The paper reports percentage improvement rather than absolute counts. These measurements are crucial because they expose the difference between abstract sparsity and realized efficiency.
| Model | CPU cycles improvement (%) | CPU instructions improvement (%) | Memory access improvement (%) | Latency improvement (%) |
|---|---|---|---|---|
| E-SpeechMamba | 32.32 | 14.30 | 17.57 | 29.78 |
| S-SpeechMamba | 19.58 | 14.0 | 7.63 | 17.9 |
| E-SpeechMamba (Optimized) | 46.13 | 26.9 | 28.50 | 37.5 |
These results show that algorithmic sparsity and hardware efficiency are related but not equivalent. E-SpeechMamba’s cycle reduction does not scale directly with its average sparsity because different FATReLU points have different dimensions and sparsity levels; high-dimensional points with only moderate sparsity can dominate runtime. The paper also notes that some Mamba operations cannot be sparsified without hurting accuracy, especially if sparsifying the input to the SSM Scan module causes significant degradation.
The spiking model illustrates a different trade-off. Even though S-SpeechMamba reaches higher sparsity than E-SpeechMamba, it achieves smaller cycle and memory-access reductions. The paper attributes this to the hidden cost of maintaining membrane state in LIF neurons. Unlike stateless activations, LIF layers require additional memory loads and stores across time steps, which erodes hardware gains even when activation sparsity is high.
The optimized event-driven model is the strongest result from a hardware standpoint. By profiling the simulator and then inserting additional FATReLU points where the Mamba block remains expensive, the paper increases cycle reduction to 46.13%, instruction reduction to 26.9%, memory-access reduction to 28.5%, and latency reduction to 37.5%. This is the clearest evidence that the simulator can guide useful architecture modifications rather than merely quantify existing ones.
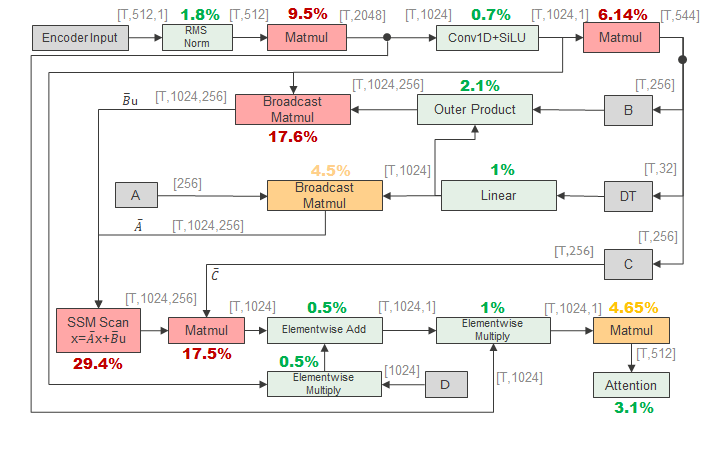
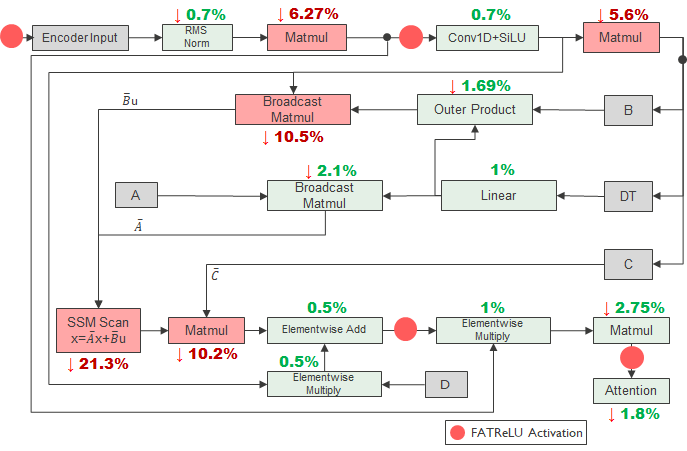
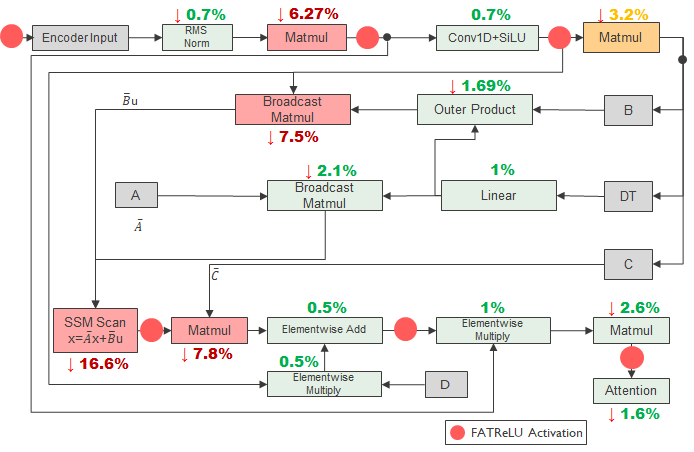
At the submodule level, the simulator identifies the SSM Scan module and several matrix multiplications as the main computational hotspots in the encoder Mamba block. The optimized design reduces these hotspots after adding more sparsity points, which explains the larger end-to-end gains in the hardware table. The paper’s profiling-first workflow is therefore a central methodological contribution: measure where the cycles go, then sparsify the places that matter most.
Discussion and limitations
The paper’s most important qualitative lesson is that high activation sparsity does not automatically imply strong hardware speedup. Sparse execution still has to pay for irregularity, memory traffic, and any dense submodules that remain on the critical path. In the event-driven model, uneven sparsity across activation points limits the achievable cycle savings; in the spiking model, state retention creates memory overhead that offsets some of the gain from binary computation. The authors explicitly use these observations to argue for hardware-aware analysis rather than relying only on sparsity percentages or theoretical synaptic-operation counts.
Another limitation is that the hardware results are simulator-based rather than measurements on a finished neuromorphic chip. The simulator is cycle accurate for the modeled Ibex-based execution flow and is intended to emulate generic digital neuromorphic processors, but it remains an abstraction of any particular silicon implementation. The paper positions this as a strength for flexibility and co-exploration, but it also means the results should be interpreted as hardware-aware estimates rather than direct chip measurements.
Finally, the paper shows that there is no single best sparse strategy for ASR under all constraints. E-SpeechMamba offers better accuracy-efficiency balance, while S-SpeechMamba maximizes sparsity and parameter efficiency at the cost of higher WER and state-management overhead. The optimized event-driven model demonstrates that sparsity points can be moved and expanded to improve hardware efficiency, but the resulting gains depend on the structure of the backbone and on where sparsity can be introduced without breaking the model’s temporal modeling.
Conclusion
The paper presents a careful study of spiking and event-driven neuromorphic strategies for speech recognition using SpeechMamba as the base architecture. Its main technical result is that both FATReLU-based event-driven computation and spiking computation can produce substantial activation sparsity on LibriSpeech, but the realized efficiency depends on architectural placement, state overhead, and bottleneck modules. The event-driven model is the best compromise for maintaining accuracy while substantially increasing sparsity, the spiking model achieves the highest sparsity with fewer parameters, and the simulator-driven optimized model delivers the strongest hardware-efficiency gains. Overall, the paper argues that realistic, cycle-accurate co-exploration is necessary to turn sparse model design into tangible efficiency improvements for ASR on edge-class systems.
Code & Implementation
This repository implements the neuromorphic SpeechMamba models for efficient speech recognition as presented in the paper. It is organized into two main parts reflecting the paper's scope:
- Training: PyTorch training recipes based on SpeechBrain for three model variants 64E-SpeechMamba, E-SpeechMambaOpt (optimized event-driven), and S-SpeechMamba (spiking neural network). The training scripts and hyperparameter configurations are found under
training/speechbrain/recipes/LibriSpeech/ASR/transformer/. - Event-driven simulation: A two-phase workflow that converts trained models into event-driven format and simulates them on a RISC-V based architecture. This part includes Python code to export model weights (
python/encoder/main.py) and C++ code for cycle-accurate event-driven simulation with variants for base, spiking, and optimized event-driven SpeechMamba models. The C++ simulation sources reside inevent-driven-simulation/cpp/src/.
Typical use involves training or loading pretrained models with the provided PyTorch recipes, exporting weights with the Python encoder scripts, and then compiling and running the event-driven simulation on local or lowRISC Ibex simulators following the documented steps.