Sparse Autoencoders for Emotion Control
Sparse Autoencoders for Interpretable Emotion Control in Text-to-Speech
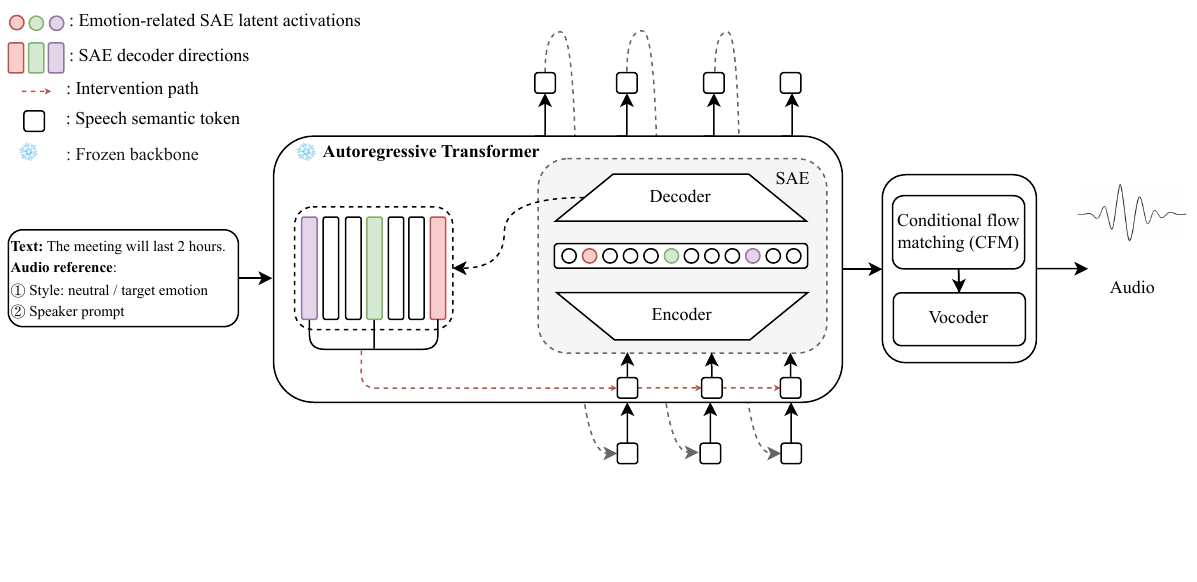
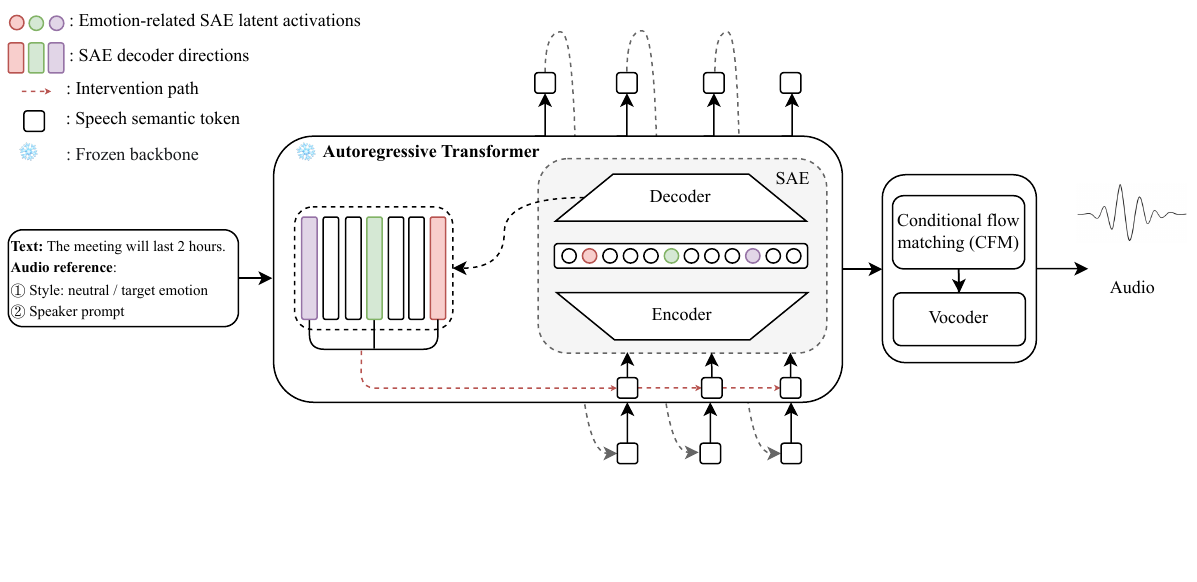
This paper introduces sparse autoencoders to identify and steer interpretable latent features related to emotion in LLM-based text-to-speech systems, enabling fine-grained bidirectional emotional control by intervening on a small subset of model internals rather than relying on global or external signals.
Links
Paper & demos
Impact
Abstract
Integrating large language models (LLMs) into text-to-speech (TTS) systems has improved speech expressiveness, yet interpretable emotional control remains challenging. Existing approaches primarily rely on external conditioning or global activation steering, offering limited insight into the internal representations underlying emotional control. In this work, we analyze emotion-related variation in the semantic hidden states of LLM-based TTS models using sparse autoencoders (SAEs) to identify sparse latent features. Our analysis shows that emotional variation is distributed across multiple sparse latent features, while intervening on a small subset enables interpretable emotion control. Building on this observation, we introduce a feature-level intervention framework for bidirectional emotion induction and suppression without modifying backbone parameters. We further show that distinct latent features are associated with specific acoustic attributes (e.g., pitch), suggesting that emotional expression arises from coordinated latent contributions rather than a single global shift. Empirically, steering these sparse latent features achieves comparable or superior emotion induction and suppression performance relative to global steering and existing TTS baselines.
Problem Setup and Main Idea
This paper studies interpretable emotional control in LLM-based text-to-speech (TTS) systems. The central question is not only whether emotion can be induced or suppressed at inference time, but where emotional variation lives inside the model and whether that variation can be decomposed into sparse, human-interpretable latent factors.
The authors argue that existing emotion-controllable TTS systems are limited in two ways. Label-based and prompt-based methods rely on external conditioning signals and tend to blur nuanced affective variation into predefined categories. Reference-based style transfer can sound natural, but it is instance-dependent and opaque. Activation steering is more direct, but prior TTS work mostly uses dense mean-difference directions in hidden space, which provides a global control vector rather than a feature-level explanation.
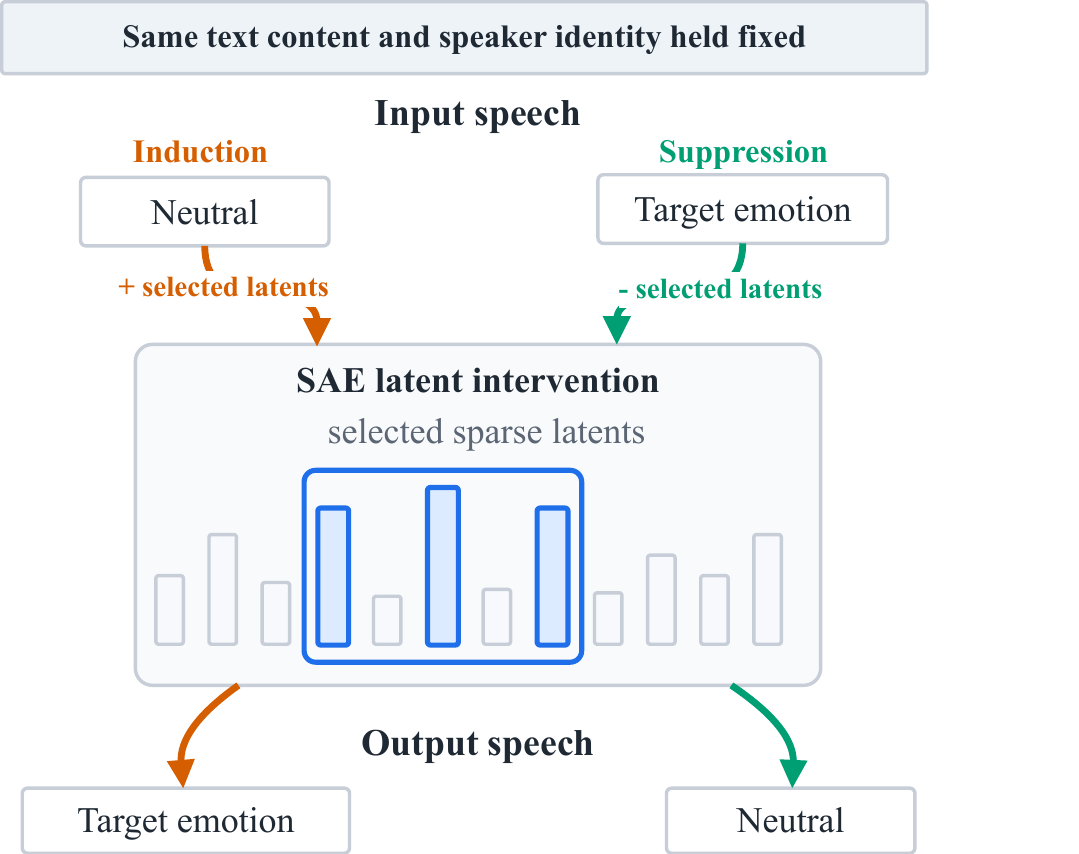
To address this, the paper analyzes the semantic backbone of an autoregressive LLM-based TTS model with a sparse autoencoder (SAE). The core hypothesis is that emotional variation is not a single monolithic direction in representation space; instead it is distributed across a small number of sparse latent features. If true, then intervening on those features should enable bidirectional emotion control: increasing selected features should induce a target emotion, while decreasing them should suppress it toward neutral speech.
Modeling Approach
Where the SAE is inserted
The SAE is trained on hidden activations from the semantic backbone of IndexTTS2, a GPT-style autoregressive text-to-semantic model. The intervention point is the layer-16 pre-LayerNorm residual stream during decode-phase semantic-token generation. The authors intentionally focus on this upstream semantic stage rather than modifying downstream flow-matching or vocoder modules, so the analysis targets representations before acoustic synthesis.
At each semantic-token position, the residual activation is a dense vector $x \in \mathbb{R}^d$. The SAE learns an overcomplete sparse dictionary of latent features and reconstructs the residual stream from a small set of active latents.
SAE parameterization and objective
The paper uses a $k$-sparse autoencoder with an overcomplete latent space of size $n > d$. The encoder centers the input and projects it into latent space, then applies ReLU and a Top-$k$ operator:
The decoder maps the sparse latent vector back into the residual stream:
Training minimizes reconstruction error, with an auxiliary loss to reduce the dead-latent problem:
The auxiliary term uses selected inactive features to model residual reconstruction error, encouraging better utilization of the overcomplete dictionary. Decoder columns are constrained to unit norm, and the implementation also uses gradient projection, decoder renormalization, and exponential moving average stabilization.
Intervention rule
Once the SAE is trained, emotion control is achieved by modifying only a selected subset of emotion-related latent features. If $\mathcal{F}_e$ denotes the set of features associated with emotion $e$, then the activation update is:
Positive $\alpha_e$ induces the target emotion; negative $\alpha_e$ suppresses it. The modified latent vector is decoded back to the residual stream and passed to the acoustic generator. Under linear approximation, the update corresponds to steering the residual representation along a sparse sum of decoder directions rather than a single dense global direction.
How Emotion-Related Features Are Identified
To identify emotion-related latents, the paper uses a carefully controlled paired setup: text and speaker identity are held fixed, and only the emotional style reference changes. Neutral speech is treated as the baseline, and each target emotion is contrasted against its matched neutral sample.
For each latent feature $i$, the authors define a sentence-level activation indicator that counts whether the feature fires at least once anywhere in the generated semantic-token sequence. The selectivity score is the paired emotion-minus-neutral difference in activation rate:
Features with the largest positive $\Delta_i^{(e)}$ are selected as emotion-related features. The authors justify the sentence-level criterion as more stable than token-level or magnitude-based alternatives, because emotion is generally sustained across an utterance rather than expressed by isolated token spikes.
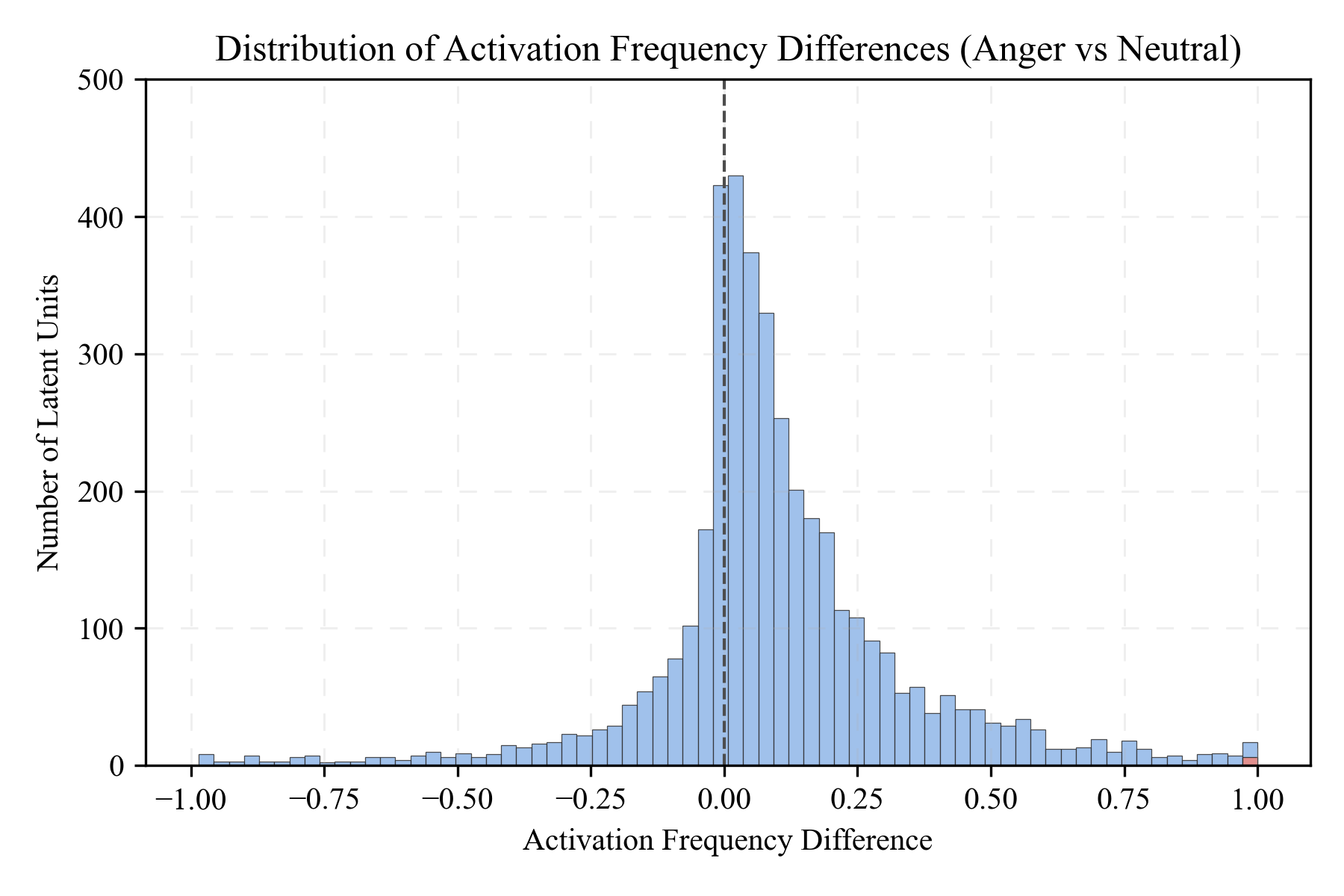
The selectivity distributions for happiness and sadness are similar: they are sharply centered near zero, with only a sparse tail of strongly emotion-selective features. This supports the paper’s core claim that emotional information is distributed across multiple sparse components, but concentrated enough that a small subset can be used for controllable intervention.
Training Data, Backbone, and SAE Setup
The SAE is trained on 56,000 emotion-controlled TTS generations from IndexTTS2. The training set is evenly distributed across seven emotions: anger, disgust, fear, happiness, neutral, sadness, and surprise. It is constructed from 400 English texts, each synthesized under all combinations of seven emotions and 20 speaker-timbre references. The paper states that each generation specifies a target emotion, text content, an emotion-specific style reference, and a neutral IEMOCAP utterance used to fix speaker timbre. This fully crossed design is intended to isolate emotion from lexical content and speaker identity.
SAE optimization uses Adam for 30,000 steps with learning rate $10^{-4}$ and $\epsilon = 6.25 \times 10^{-16}$, processing a target of 16,384 tokens per update. The latent dimension is 4,096 and Top-$k$ sparsity is set to $k=32$ active features per token. The paper reports a usage-based sparsity regularizer with weight $0.01$, an auxiliary loss weight $\lambda_{\mathrm{aux}}=0.1$, decoder-column unit norm constraints, gradient projection onto the orthogonal subspace of decoder weights, and EMA with decay $0.99$.
The authors also trained a 10,240-dimensional SAE. Although reconstruction error improved, emotion-related features became more fragmented and spread across more sparse directions, making the control space less interpretable. For that reason, the main paper focuses on the 4,096-dimensional SAE.
All experiments were run on a single NVIDIA H100 GPU. The trained SAE is reported to have about 10.5M parameters and approximately 40 MB footprint in fp32.
Intrinsic SAE Quality
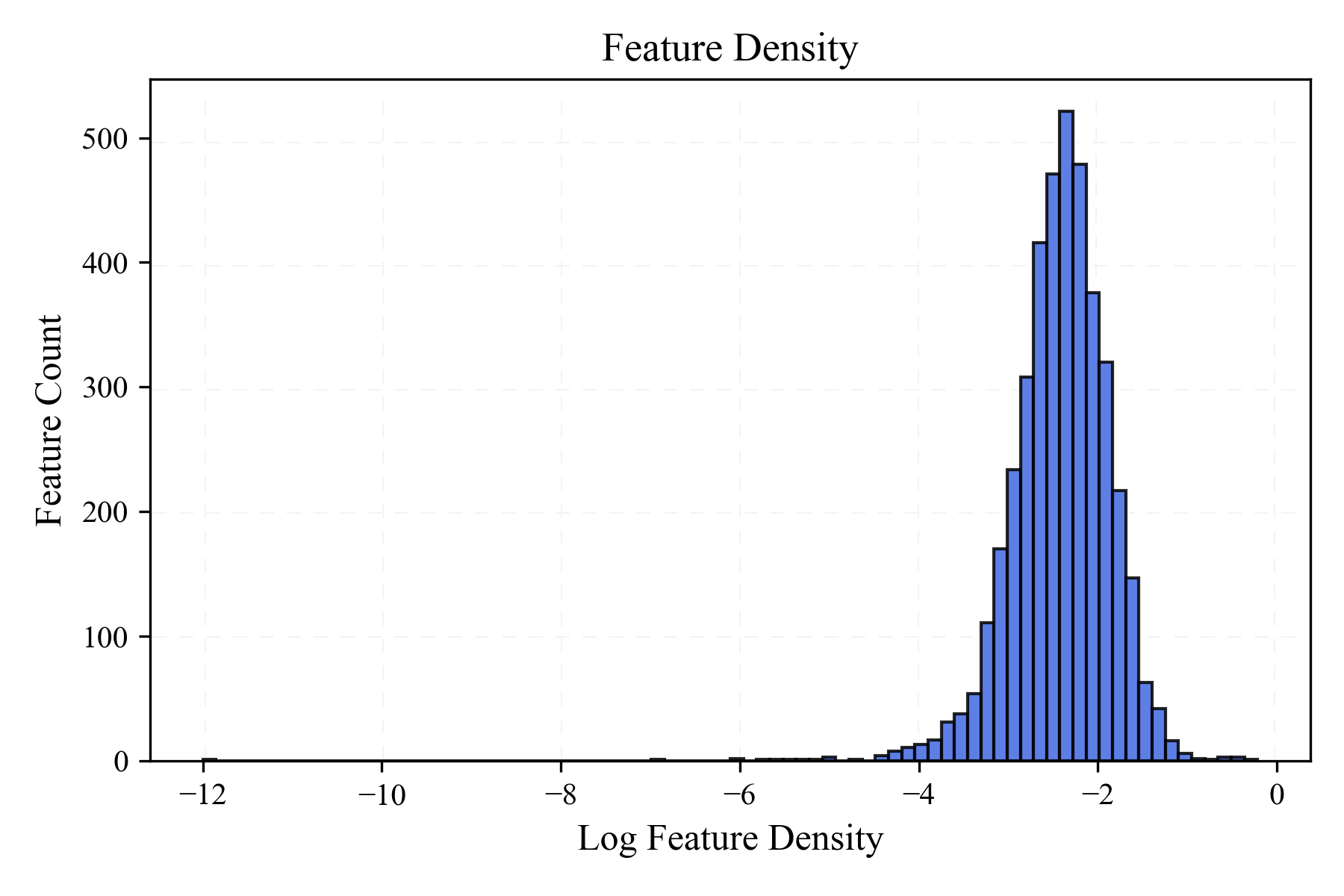
The SAE reconstructs centered, unit-normalized residual representations with normalized MSE 0.129. The average activation fraction per token matches the expected Top-$k$ rate $32/4096 \approx 0.0078$, and the density distribution is long-tailed without a large mass of dead features. Under the paper’s inactivity criterion, no dead latents are observed. These results suggest that the dictionary is sparse but still well utilized.
What the Learned Features Do Acoustically
The paper goes beyond latent selectivity and checks whether selected features correspond to meaningful acoustic changes. A representative example is latent feature #24, whose intervention produces localized mid- to high-frequency amplification and increases short-time energy while leaving the overall time-frequency structure largely intact.
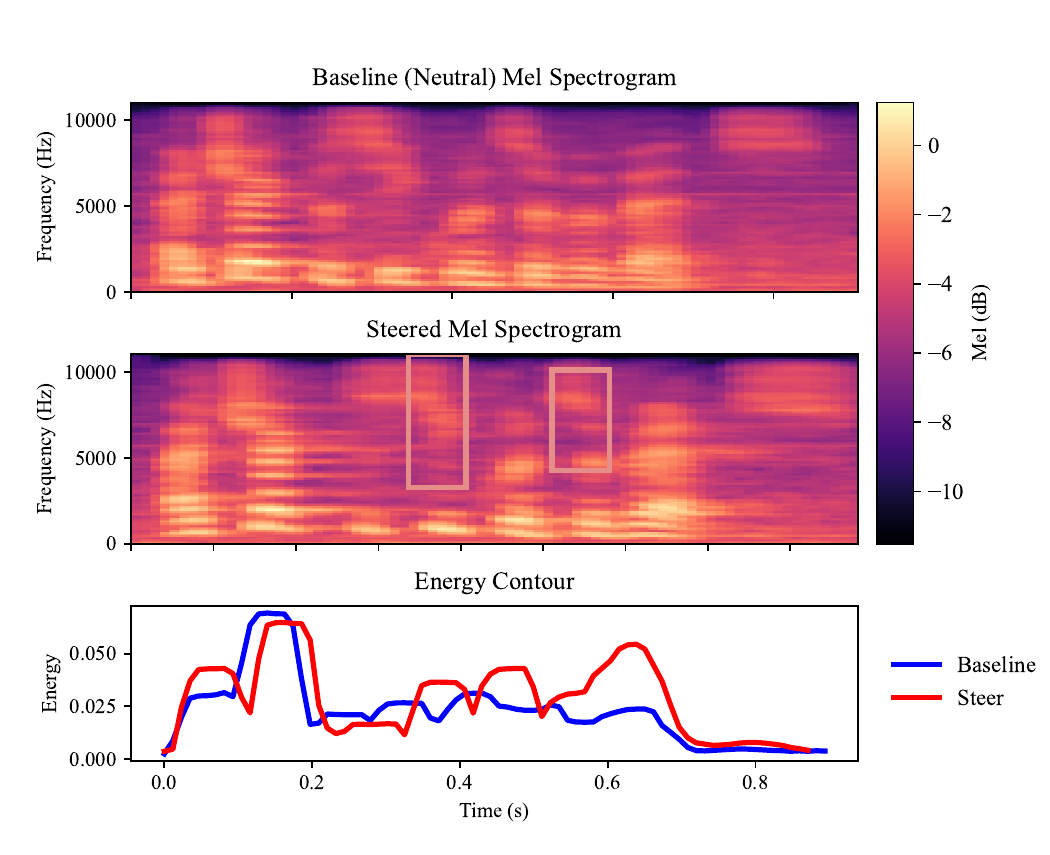
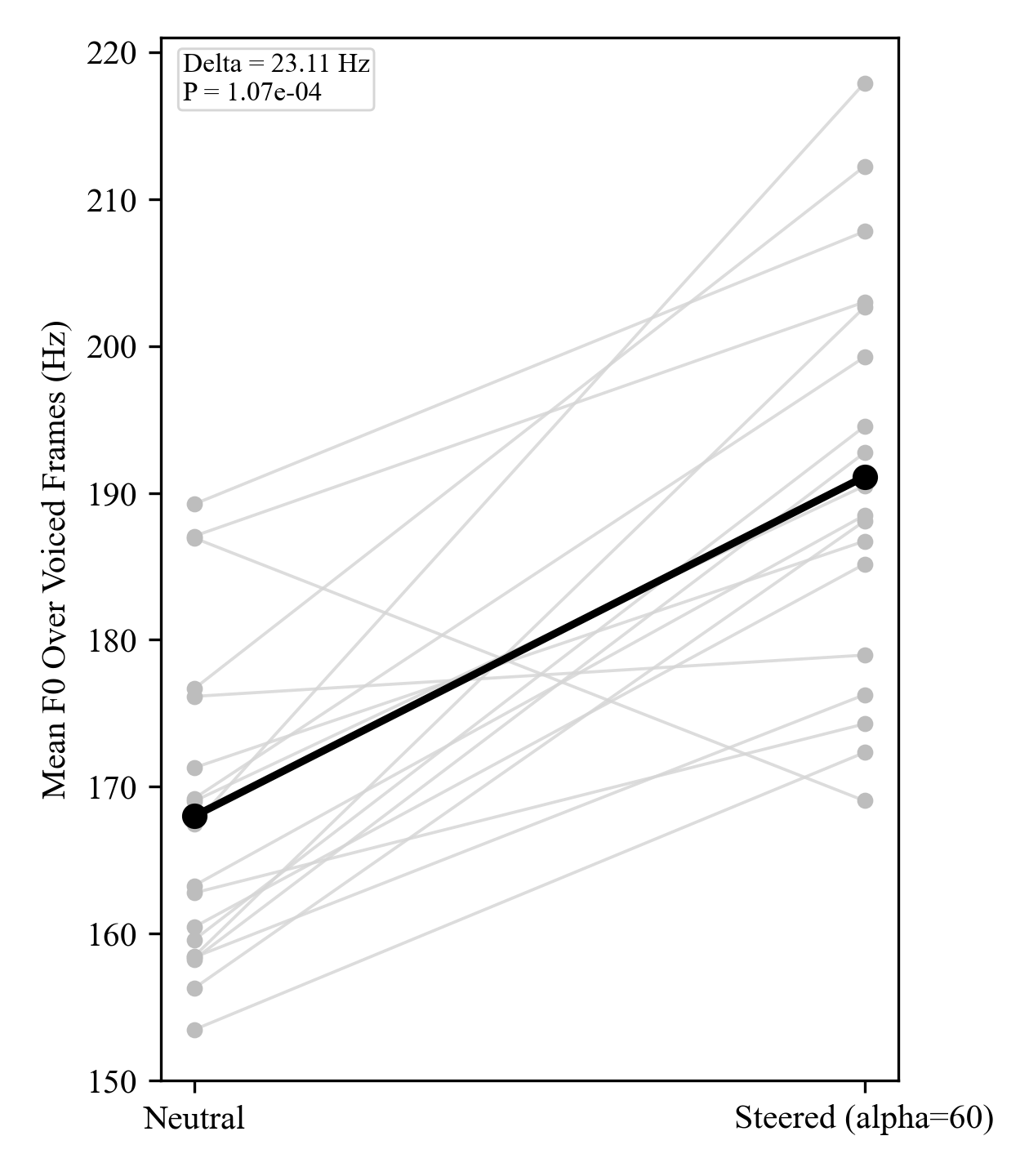
Quantitatively, under matched text and speaker identity, steering significantly increases mean F0 by +23.11 Hz ($p = 1.07 \times 10^{-4}$) and RMS energy by +0.00435 ($p = 0.00769$), while duration changes are not significant ($p = 0.687$). This supports the interpretation that the selected feature primarily modulates pitch and intensity rather than speech length.
| Feature | Baseline Mean | Baseline Std | Steered Mean | Steered Std | Delta | p-value |
|---|---|---|---|---|---|---|
| F0 (Hz) | 167.99 | 11.20 | 191.10 | 14.06 | +23.11 | 1.07e-4 |
| Duration (s) | 1.685 | 0.234 | 1.662 | 0.259 | -0.023 | 0.687 |
| RMS Energy | 0.02712 | 0.00354 | 0.03146 | 0.00479 | +0.00435 | 0.00769 |
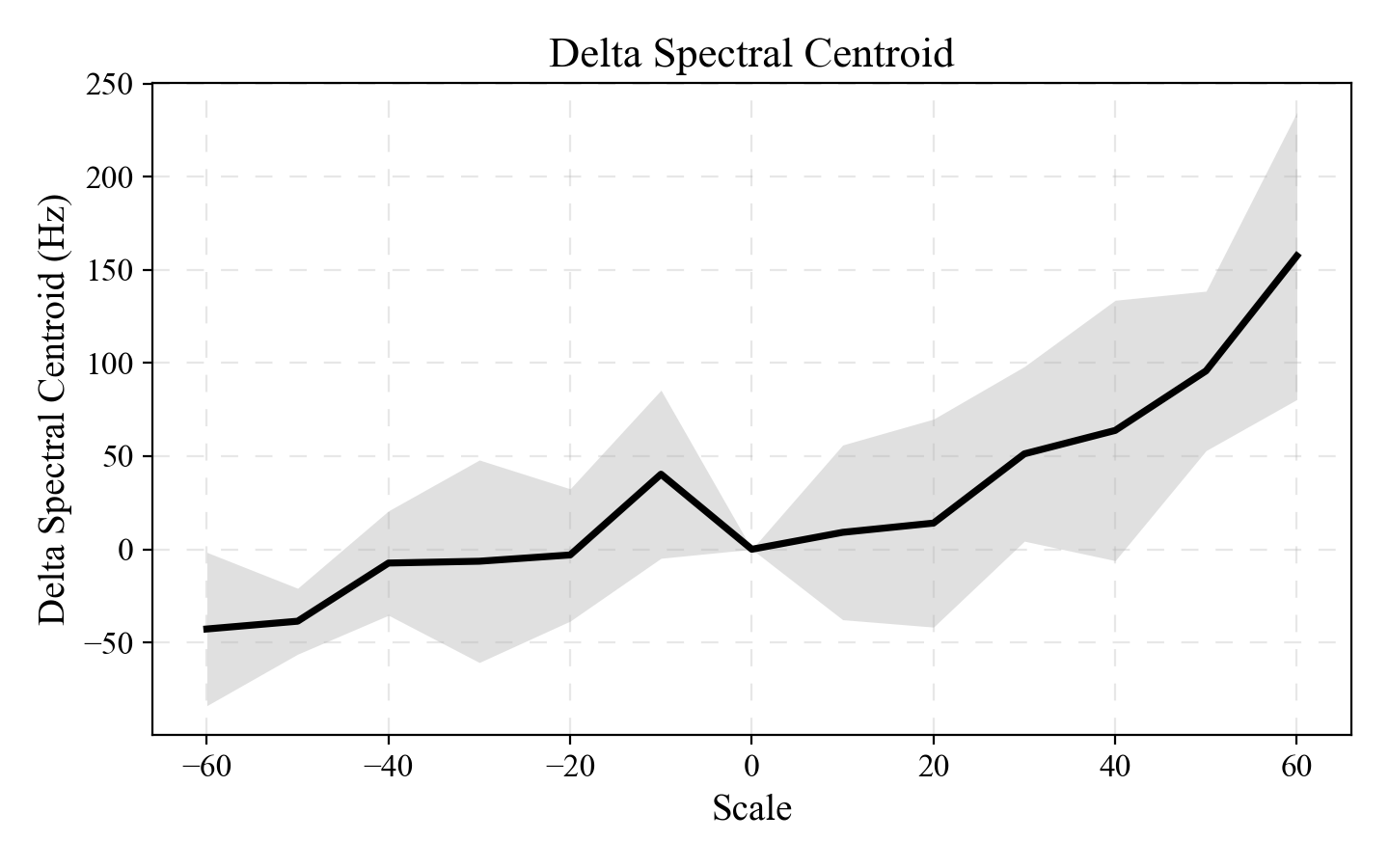
The authors also sweep steering scale from $-60$ to $+60$ and measure spectral centroid. Negative scale lowers the centroid, while positive scale raises it, indicating modulation of spectral brightness. This is important because it suggests that affective expression is not a single global change; rather, different sparse features align with different acoustic dimensions such as pitch, energy, and brightness.
Steering Behavior and Main Evaluation Results
The paper evaluates bidirectional emotion control on a paired dataset where each case is synthesized twice with the same text and speaker timbre: once under a neutral style reference and once under a target-emotion style reference. The evaluation covers emotion induction ($\text{Neutral} \rightarrow \text{Target}$) and emotion suppression ($\text{Target} \rightarrow \text{Neutral}$) for anger, happiness, and sadness.
Three metrics are used:
- Emo-SIM: emotional similarity from emotion2vec embeddings, with prototypes derived from IEMOCAP reference utterances.
- WER: word error rate computed with Whisper-Large V3.
- Spk-SIM: speaker similarity using ERes2Net; the authors note that this is a conservative proxy because prosody can affect speaker embeddings.
Compared methods include Global Steering (dense mean-difference direction in residual space), Random SAE (six random latent features), and existing TTS baselines such as VALL-E-X, Spark-TTS, EmoVoice, and CosyVoice. For the proposed method, the steering vector is built from the top-6 emotion-related SAE features ranked by sentence-level selectivity and combined with equal weights.
| Method | Anger | Happiness | Sadness | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Emo-SIM | WER | Spk-SIM | Emo-SIM | WER | Spk-SIM | Emo-SIM | WER | Spk-SIM | |
| Emotion induction: Neutral → Target | |||||||||
| VALL-E-X | 0.831 | 3.1 | 0.302 | 0.697 | 5.3 | 0.320 | 0.869 | 7.8 | 0.352 |
| Spark-TTS | 0.857 | 2.7 | 0.488 | 0.770 | 8.6 | 0.463 | 0.907 | 2.3 | 0.523 |
| EmoVoice | 0.806 | 4.1 | 0.358 | 0.728 | 3.4 | 0.342 | 0.850 | 4.0 | 0.386 |
| CosyVoice | 0.813 | 3.9 | 0.569 | 0.712 | 2.9 | 0.597 | 0.799 | 2.4 | 0.605 |
| Random SAE ($m=6$) | 0.892 | 1.4 | 0.628 | 0.813 | 6.0 | 0.461 | 0.858 | 1.7 | 0.637 |
| Global Steering | 0.910 | 0.1 | 0.552 | 0.879 | 4.0 | 0.495 | 0.876 | 1.9 | 0.516 |
| SAE-Emotion (ours) | 0.912 | 0.3 | 0.569 | 0.885 | 2.2 | 0.515 | 0.880 | 1.5 | 0.481 |
| Emotion suppression: Target → Neutral | |||||||||
| Random SAE ($m=6$) | 0.841 | 0.8 | 0.342 | 0.886 | 2.14 | 0.343 | 0.939 | 0.77 | 0.427 |
| Global Steering | 0.915 | 2.6 | 0.392 | 0.920 | 1.48 | 0.379 | 0.933 | 1.63 | 0.436 |
| SAE-Emotion (ours) | 0.939 | 2.8 | 0.374 | 0.924 | 2.31 | 0.301 | 0.941 | 0.80 | 0.441 |
Overall, the proposed method matches or exceeds the baselines on emotion similarity while keeping transcription quality and speaker similarity competitive. The biggest gains are not only in induction but also in suppression, showing that the sparse latent features can be used as a two-way control interface rather than only as an emotion amplifier.
Human evaluation
The authors also run a blind listening study with 20 raters, scoring emotion accuracy (EMOS) and naturalness (NMOS) on a 0--5 scale. SAE-Emotion achieves the best scores among the compared steering methods.
| Method | EMOS | NMOS |
|---|---|---|
| SAE-Emotion | 3.22 | 3.49 |
| Global Steering | 3.10 | 3.38 |
| Random SAE | 1.82 | 3.22 |
Ablations and Additional Analyses
Single-scalar intensity control
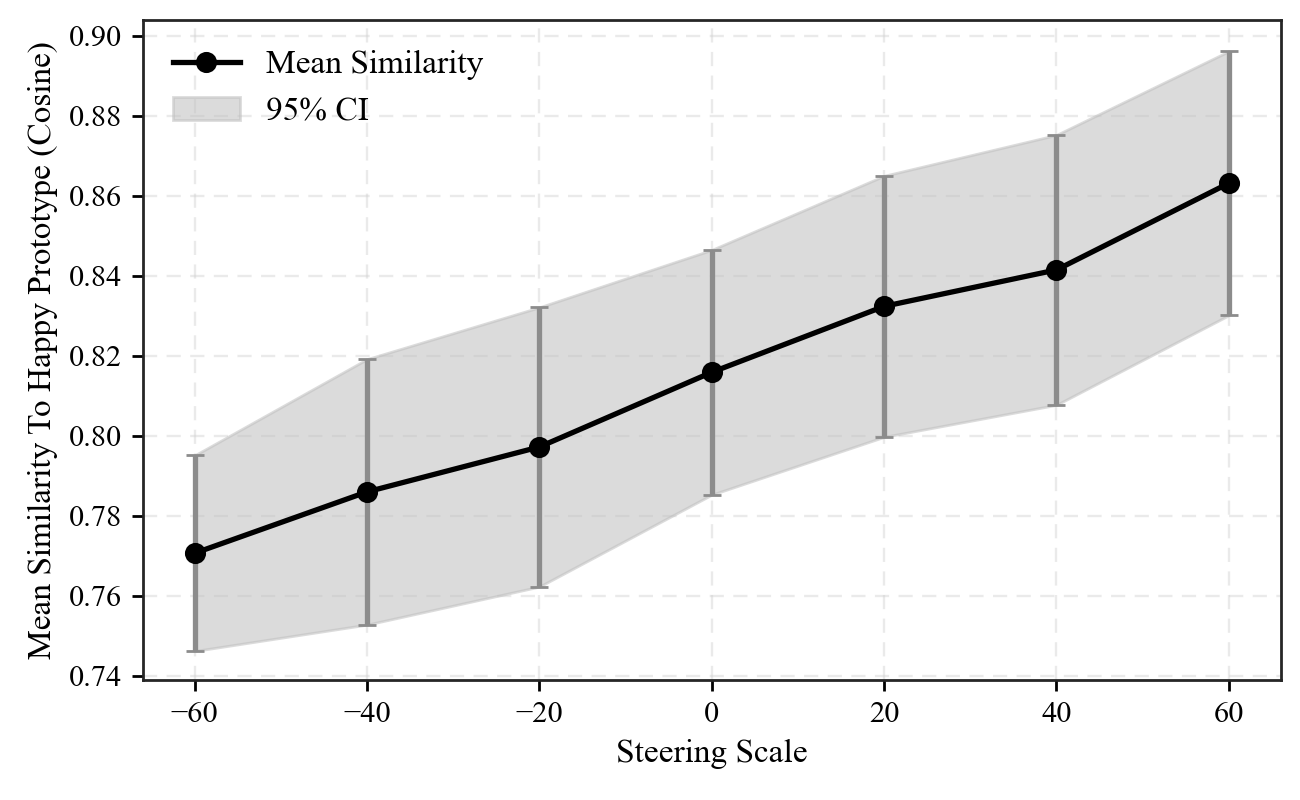
The steering coefficient $\alpha_e$ serves as a continuous intensity knob. For a fixed target emotion feature, similarity to the target emotion prototype increases smoothly as $\alpha_e$ moves from $-60$ to $+60$, rising from roughly 0.77 to 0.86 in the appendix experiment. This shows that the method supports not only categorical directionality but also graded emotional strength.
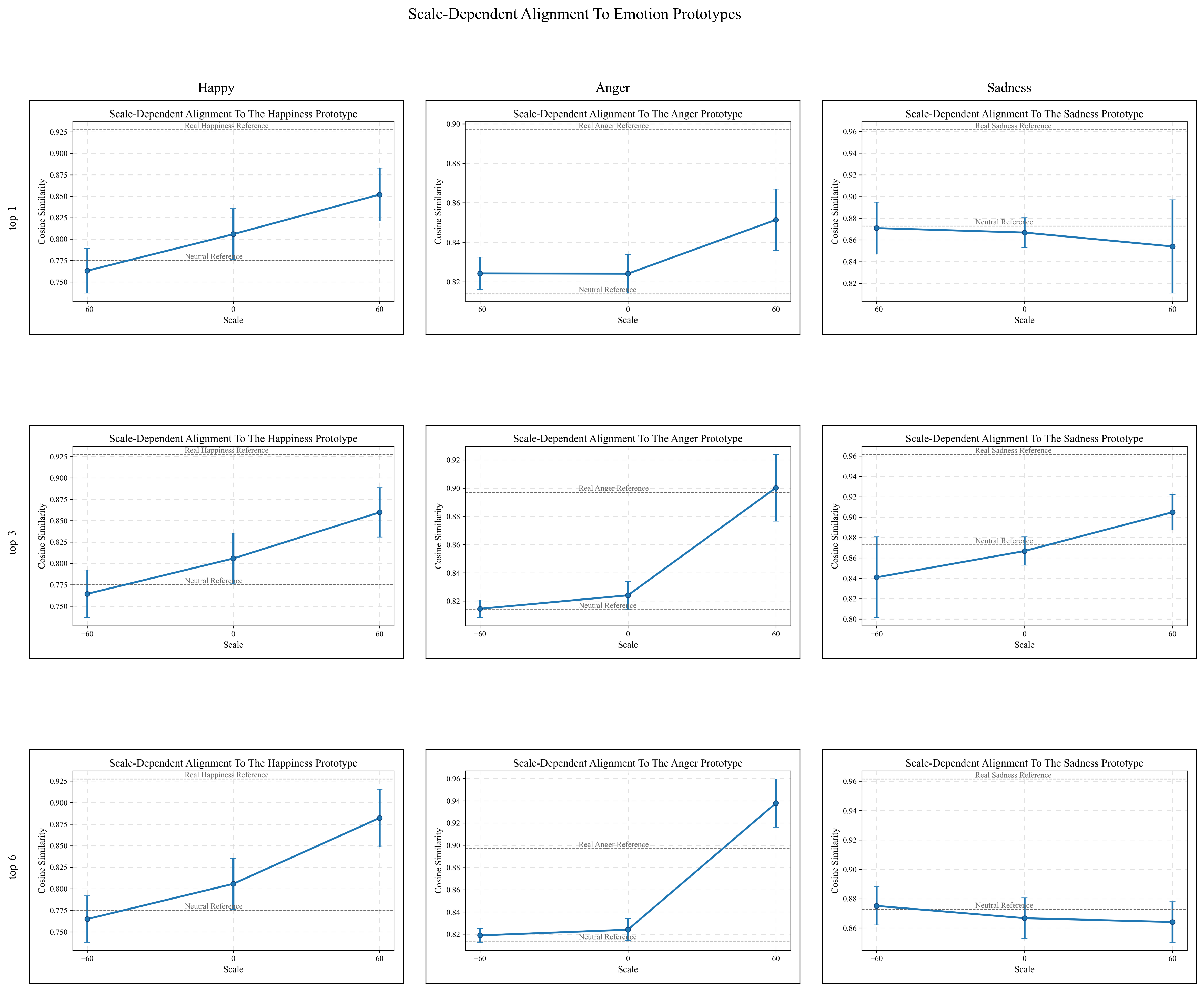
Emotion-specific latent budgets
The paper studies how many latent features are needed to steer different emotions. Happiness is relatively concentrated and can be controlled even with a top-1 feature, while anger and sadness benefit from larger latent budgets such as top-3 or top-6. This supports the claim that emotion is sparse but not uniformly single-feature across categories.
Comparison with alternative feature selection criteria
To validate the sentence-level selectivity criterion, the paper compares it with magnitude-based and token-level alternatives. The proposed criterion consistently performs best in emotion alignment.
| Selection criterion | Anger | Happiness | Sadness |
|---|---|---|---|
| Sentence-level selectivity | 0.912 | 0.885 | 0.880 |
| Magnitude-based selection | 0.822 | 0.820 | 0.866 |
| Token-level selection | 0.825 | 0.811 | 0.864 |
Strong steering robustness
Under high steering strength, sparse SAE intervention is substantially more robust than dense global steering. The appendix reports mean WER of 0.57% for SAE steering versus 2.86% for global steering, along with zero deletion errors for SAE steering and nonzero deletion errors for the dense baseline. This suggests that sparse feature-level intervention causes less decoding interference.
| Method | Mean WER | Mean Deletion | Max Deletion |
|---|---|---|---|
| Global Steering | 2.86% | 2.05% | 14.89% |
| SAE Steering | 0.57% | 0.00% | 0.00% |
Bidirectional intervention variant
The appendix also examines a bidirectional variant that increases target-emotion features while decreasing opposing or neutral-associated ones. Compared with positive-only steering, this yields a larger increase in mean F0. The authors treat this as a supplementary analysis rather than the main protocol.
Cross-backbone evidence
Although the main study centers on IndexTTS2, the appendix includes a cross-backbone analysis on LLaSA. The scale-dependent alignment trend persists: increasing the steering scale shifts generations from the neutral region toward the anger prototype. This supports the broader claim that sparse latent emotion control can generalize beyond a single backbone, though the paper still notes that the main controlled evaluation is performed on one primary model.
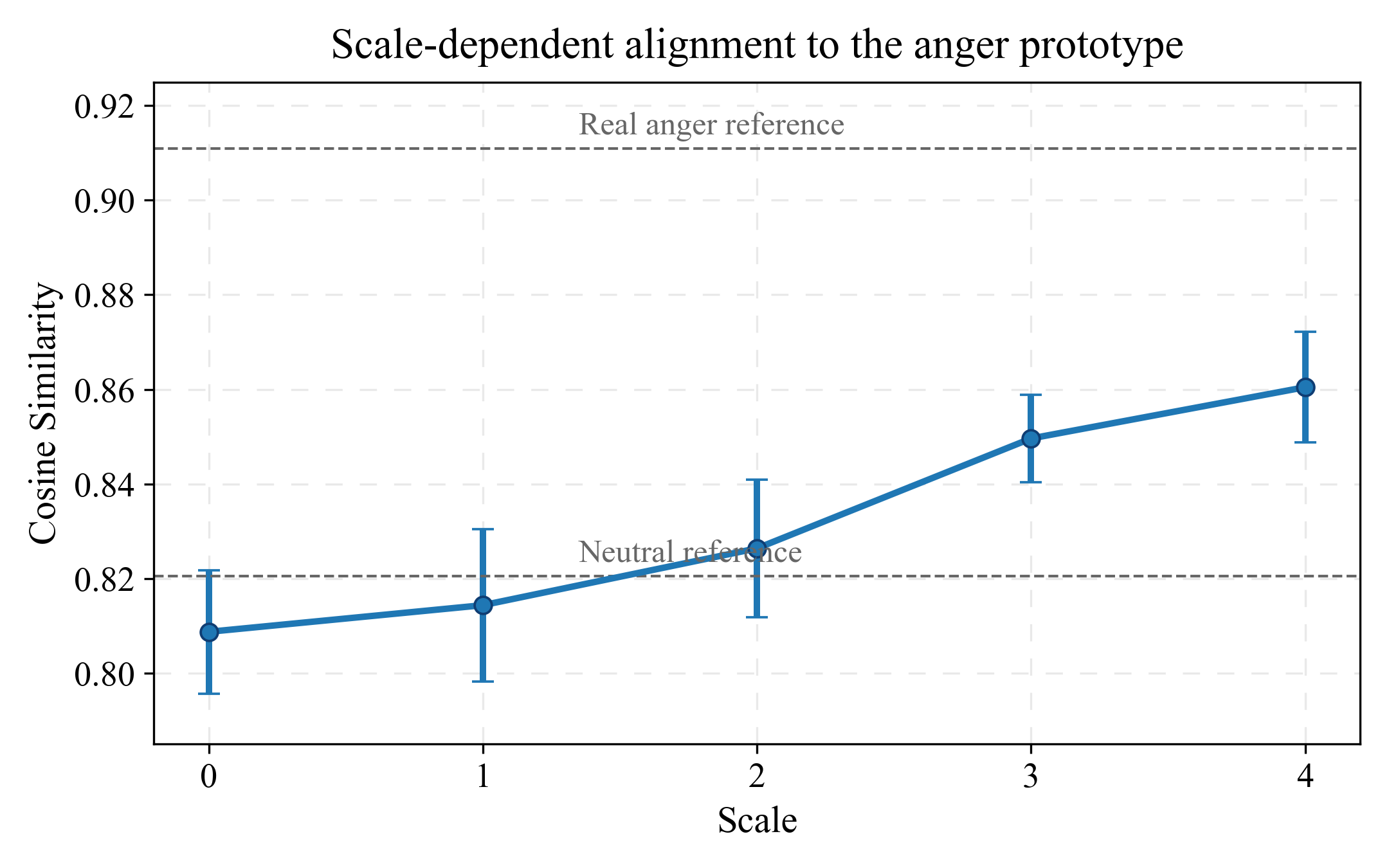
Limitations
The paper is explicit about several limitations. First, training SAEs on large-scale activation data introduces nontrivial compute and storage overhead, so the full analysis is conducted on a single primary backbone configuration. Second, emotional latent features in speech are inherently difficult to quantify because speech emotion is multidimensional and perceptual; the paper focuses on representative, clearly observable features rather than a complete taxonomy of the latent space. Third, the authors note that extending the method to additional architectures with equally controlled evaluation would be important for broader validation.
Takeaway
The paper’s main contribution is a mechanistic reinterpretation of emotional control in LLM-based TTS. Instead of treating emotion as a dense global shift, the authors show that it can be decomposed into sparse latent features in the semantic backbone. By selecting features with strong emotion-versus-neutral selectivity and steering them directly, they obtain interpretable, bidirectional emotion control without modifying backbone parameters. Empirically, this sparse feature-level intervention matches or outperforms dense steering and several TTS baselines, while preserving content, speaker identity, and perceived naturalness reasonably well.