SplatShot
Splatshot: 3D Face Avatar Generation from a Single Unconstrained Photo

SplatShot is a training-free method that combines 3D Gaussian Splatting with diffusion models to generate photorealistic 3D face avatars from a single photo. It uses 3D feedback during diffusion to ensure multi-view consistency and faithful identity without task-specific training.
Demos
The demo showcases SplatShot's ability to generate photorealistic 3D face avatars from a single unconstrained in-the-wild photo, highlighting its no per-subject training requirement and rendering from arbitrary viewpoints. Watch for the avatar's realism, 3D consistency across different angles, and the preservation of identity and facial details from the input photo.

Links
Paper & demos
Code & resources
Abstract
Reconstructing a photorealistic 3D face avatar from a single unconstrained photograph is challenging: feed-forward 3D Gaussian Splatting (3DGS) models degrade on out-of-distribution inputs, while pretrained diffusion models produce high-fidelity images but lack multi-view consistency. We observe that these paradigms are fundamentally complementary: explicit 3D representations guarantee geometric consistency, whereas 2D diffusion priors ensure photorealism. Building on this, we propose SplatShot, a training-free framework that couples these representations directly within the denoising process. Given a base 3DGS face model and a single reference image, we jointly denoise all target views using a per-step 3D feedback loop. At each timestep, we predict clean images from the noisy latents, refit the 3DGS to these multi-view predictions, and back-propagate the photometric discrepancy between the 3DGS re-renderings and 2D predictions into the noise estimate. This steers the sampling trajectory toward strictly 3D-coherent, identity-faithful outputs. Experiments on diverse in-the-wild images demonstrate that SplatShot produces 3D avatars with superior identity preservation, photorealism, and multi-view consistency.
Overview and Core Idea
SplatShot is a training-free framework for generating a photorealistic, multi-view consistent 3D face avatar from a single unconstrained photograph. The paper starts from a simple but important observation: two paradigms that are usually treated separately are in fact complementary. Explicit 3D representations such as 3D Gaussian Splatting (3DGS) provide geometric consistency across viewpoints, but their quality depends strongly on the images used to fit them. By contrast, pretrained diffusion models provide strong image priors and can synthesize realistic face images, but they do not inherently coordinate multiple views of the same subject. SplatShot couples these two ingredients directly inside the denoising loop so that the diffusion process is continuously corrected by a 3D-consistency signal.
The key design choice is to treat the 3DGS avatar as a feedback controller during sampling. At each denoising step, the method predicts clean multi-view images from noisy latents, refits the 3DGS model to those predictions, re-renders the updated 3DGS, and backpropagates the photometric discrepancy into the diffusion noise estimate. This makes the sampling trajectory move toward outputs that are simultaneously identity-faithful, photorealistic, and coherent as a single 3D object. The method requires no task-specific training or fine-tuning of the diffusion model, the 3DGS model, or the identity-conditioning module.

Problem Setting and Preliminaries
The goal is to reconstruct a 3D face avatar from a single in-the-wild input photograph $I_{\mathrm{in}}$. The paper emphasizes that this is difficult because the input may contain arbitrary pose, lighting, background clutter, accessories, partial occlusions, and other out-of-distribution factors that break feed-forward 3D avatar methods. The method is designed to output an explicit 3DGS model rather than only a set of 2D views, because the final representation should remain consistent under novel-view rendering.
The method relies on two standard components. First, a 3DGS model $\mathcal{M}$ is represented as a set of anisotropic Gaussians with centers, opacity, spherical-harmonic color coefficients, and covariance parameters. Rendering from camera view $v$ is differentiable: $\hat{I} = \mathcal{R}(\mathcal{M}, v)$. The 3DGS parameters are optimized with a photometric loss combining $L_1$ and SSIM terms:
$$ \mathcal{L}_{\mathrm{photo}}(I, \hat{I}) = \lambda_1 \lVert I - \hat{I} \rVert_1 + \lambda_2 \bigl(1 - \mathrm{SSIM}(I, \hat{I})\bigr). $$
Second, the paper uses DDIM-style latent diffusion. Forward noising is written as $\mathbf{x}_t = \alpha_t \mathbf{x}_0 + \sigma_t \boldsymbol{\epsilon}_{\mathrm{gt}}$, and the reverse process predicts noise $\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t, \mathbf{c})$ conditioned on an identity code $\mathbf{c}$. The clean latent estimate is recovered by
$$ \hat{\mathbf{x}}_0 = \frac{\mathbf{x}_t - \sigma_t \boldsymbol{\epsilon}_\theta^t}{\alpha_t}, $$
and the next latent is computed as
$$ \mathbf{x}_{t-1} = \alpha_{t-1} \hat{\mathbf{x}}_0 + \sigma_{t-1} \boldsymbol{\epsilon}_\theta^t. $$
Method: 3DGS-Guided Iterative Denoising
The central method is a per-step feedback loop that operates over a set of $V$ target views. SplatShot begins by selecting a pretrained base 3DGS face model whose appearance and geometry are closest to the input image. This base model acts as a structured initialization and soft geometric anchor. The paper makes a point that the base is important, especially for hairstyle and head shape, because these factors are only partially controlled by the identity image encoder and are also harder to deform in 3DGS.
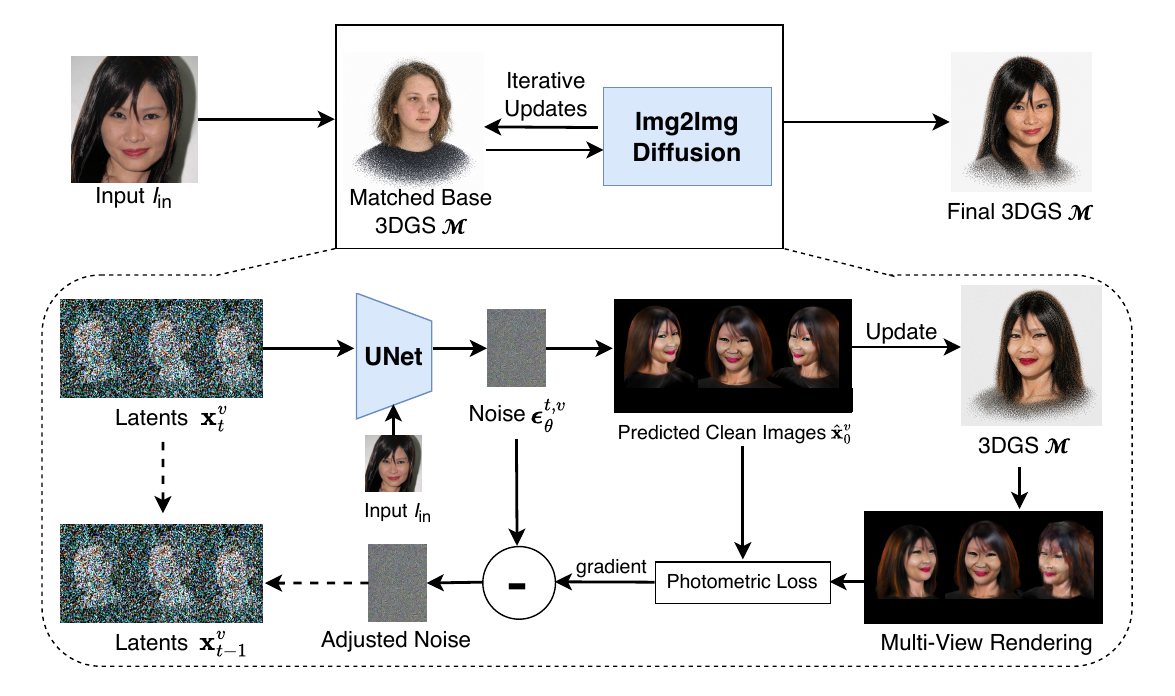
The method proceeds in three repeated stages at each diffusion timestep:
- Per-view diffusion prediction. The input views are encoded into latent space and noised to a starting timestep $t_s = \lfloor sT \rfloor$, where $s \in (0,1]$ is the denoising strength. For each view $v$, the UNet predicts a noise tensor $\boldsymbol{\epsilon}_\theta^{t,v}$ conditioned on the input identity image through an image adapter such as IP-Adapter.
- 3DGS refitting. The predicted clean images $\hat{I}^v$ are used to update all Gaussian parameters of the base model for $N$ gradient steps using the photometric reconstruction loss. This lets the 3D model absorb the current multi-view estimate rather than forcing the diffusion model to satisfy a fixed geometry.
- Noise adjustment by 3D feedback. The updated 3DGS is re-rendered, and the mismatch between re-renderings and diffusion predictions is differentiated back into the noise estimate:
$$ \boldsymbol{\epsilon}_\theta^{t,v} \leftarrow \boldsymbol{\epsilon}_\theta^{t,v} - \lambda \frac{\partial \mathbf{g}}{\partial \boldsymbol{\epsilon}_\theta^{t,v}}, $$
where $\mathbf{g}$ is the photometric discrepancy between the current diffusion prediction and the 3DGS re-rendering. The chain rule is used through the decoder so that gradients can flow from the image-space loss back into the latent noise estimate.
Conceptually, the diffusion model is asked to improve realism while the 3DGS model enforces consistency. Because the 3DGS model is refit repeatedly across timesteps, it can resolve transient per-view inconsistencies into a single coherent avatar rather than being locked to one noisy prediction.
Early-step instability and the hybrid noise formulation
A major technical issue arises early in denoising, when the predicted $\hat{\mathbf{x}}_0$ is still highly corrupted. The paper reports that directly refitting 3DGS to these early predictions can catastrophically move Gaussian parameters toward over-saturated colors and incoherent backgrounds, harming convergence. The authors therefore introduce a hybrid noise estimate:
$$ \boldsymbol{\epsilon}_{\mathrm{mix}}^{t,v} = w\,\boldsymbol{\epsilon}_\theta^{t,v} + (1-w)\,\boldsymbol{\epsilon}_{\mathrm{gt}}^v, $$
where $\boldsymbol{\epsilon}_{\mathrm{gt}}$ is the actual noise used to initialize the latent and $w \in [0,1]$. This preserves gradient flow through the predicted-noise branch while injecting enough ground-truth noise to keep early clean predictions stable enough for 3DGS refitting. The paper’s ablations show that this is not a minor detail: without the mixture, the 3D feedback loop becomes unstable, especially at high noise levels.

Why the Method Uses Explicit 3D Feedback Instead of Attention Sharing
The paper explicitly analyzes an alternative design based on cross-attention sharing across views, inspired by text-guided 3DGS editing methods. The authors argue that this approach breaks down for identity-conditioned generation. The reason is that text tokens are usually semantically localized and view-invariant, whereas image-conditioning tokens from IP-Adapter activate broadly across the face and encode view-dependent appearance. As a result, sharing attention maps blends incompatible information across views instead of aligning them. The paper includes a visualization that contrasts the structured behavior of text tokens with the diffuse overlap of image tokens.
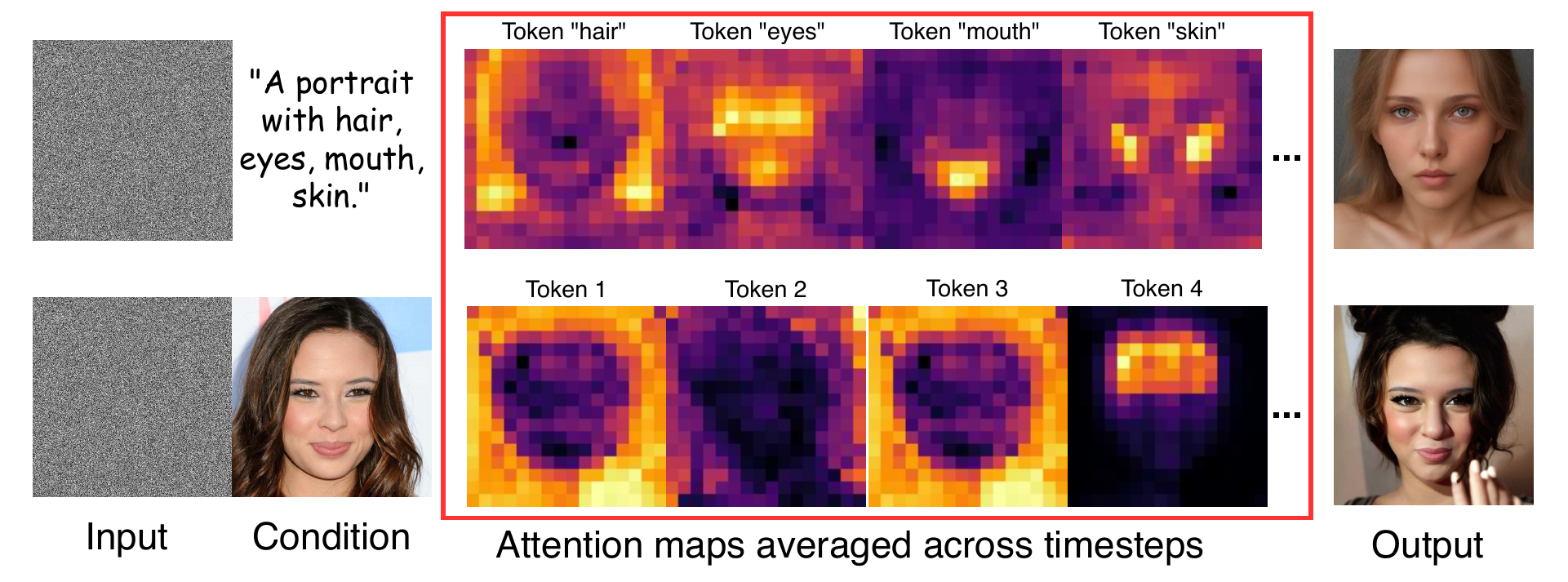
This analysis is an important part of the paper’s argument. SplatShot chooses explicit 3D guidance in image space because it allows both geometry and appearance to evolve during denoising, rather than freezing the base structure and trying to coerce the diffusion model through token-level attention manipulation. In the context of identity transfer, the paper claims that this explicit geometry loop is more appropriate than attention injection.
Implementation Details
The paper’s implementation uses Stable Diffusion v1.5 with the Realistic Vision V4.0 checkpoint and the $\texttt{stabilityai/sd-vae-ft-mse}$ VAE. Identity conditioning is provided by IP-Adapter Plus Face with a CLIP ViT-H/14 image encoder, and pose control is provided by ControlNet with an openpose model. The diffusion backbone runs in float16. For the 3D representation, the authors use gsplat and base models pretrained on NeRSemble sequences. Each base model uses degree-3 spherical harmonics and contains about 100K Gaussians, stored in PLY format, with black backgrounds during rendering.
Training is not performed in the usual sense: the method is inference-time only and training-free. However, the method still has substantial optimization inside the loop. The paper uses a DDIM scheduler with $T = 1000$ timesteps and a linear beta schedule from $0.00085$ to $0.012$, performs 50 inference steps, and uses a denoising strength of $s = 0.6$ so that the starting timestep is $t_s = 600$. Classifier-free guidance scale is $4.0$, and the text input is null. The hybrid weight is fixed to $w = 0.4$, and the 3D guidance weight is $\lambda = 50{,}000$.
At each guidance step, the 3DGS model is refit with separate Adam optimizers per parameter group. The paper gives explicit learning rates for positions, scales, rotations, opacities, and spherical-harmonic coefficients. The first guidance step uses $1{,}000$ refit iterations, while subsequent steps use $200$. The photometric loss is the standard $L_1$ and SSIM combination, and one random view is sampled per iteration. The method does not perform Gaussian densification during refitting because that creates tensor-size mismatches when the parameters are carried across timesteps.
The paper reports that the full pipeline takes about 3 minutes per identity on a single NVIDIA A100 GPU, with a peak memory footprint of about 24 GB.
Experimental Setup
The evaluation is intentionally broad for a face-avatar paper. The authors test on 6,279 randomly selected images from CelebA and FFHQ, spanning a diverse range of ages, ethnicities, poses, lighting conditions, and accessories. They also collect 300 base 3DGS models pretrained on multi-view sequences from NeRSemble. The output of SplatShot is always the final 3DGS avatar; the diffusion predictions are intermediate signals only.
The reported baselines cover three categories:
- Single-image to 3DGS: LAM, DreamGaussian, GAGAvatar, and FastAvatar.
- Diffusion-based methods: Human-3Diffusion, FaceLift, and Arc2Avatar.
- 3DGS editing: Intergsedit, reimplemented for image-based editing on top of its text-editing framework.
The metrics span three axes. Identity fidelity is measured by CSIM, the ArcFace cosine similarity between the reference image and near-frontal generated views, and AKD, the average normalized landmark distance estimated by DECA. 3D consistency is measured by CV-CSIM, the pairwise ArcFace similarity across views, and AED, expression coefficient drift estimated by DECA. Photorealism and image quality are measured by FID on near-frontal views against FFHQ and by CLIP-IQA. The paper notes that FID is used comparatively, since the outputs are rendered avatars rather than ordinary photographs.
Qualitative Results
The main visual comparison demonstrates the paper’s central claim: SplatShot produces outputs that are simultaneously more identity-faithful than diffusion baselines and more consistent than feed-forward 3D methods. In the main figure, the authors compare against Intergsedit, LAM, Human-3Diffusion, FaceLift, Arc2Avatar, DreamGaussian, GAGAvatar, and FastAvatar. The observed failure modes of the baselines are consistent with the paper’s framing: feed-forward 3D methods can produce visible artifacts and synthetic textures on in-the-wild photos, while diffusion-based methods often produce individually plausible views that are not mutually consistent.

The paper also includes additional multi-view comparisons between the final 3DGS renderings and the intermediate diffusion outputs. These examples show that the diffusion views can retain fine texture details, but the final 3DGS renderings are smoother and more geometrically stable. This is an important distinction in the paper’s presentation: SplatShot does not claim the diffusion views alone are the final deliverable. Rather, the final output is the explicit 3DGS avatar, and the diffusion process is a mechanism for refining it.

The paper also shows a large set of additional CelebA-3D results with six views per identity. These appendix figures are useful because they demonstrate the model on a wide variety of ages, ethnicities, hairstyles, and lighting conditions rather than only cherry-picked examples.



Quantitative Results
The main quantitative table is reported on 100 FFHQ identities, with 16 rendered views per identity. SplatShot is best or highly competitive on all metrics. In particular, it obtains the best CV-CSIM, the best AKD, the best FID, and the best CLIP-IQA. It ranks second on CSIM, which the paper interprets as still strong identity preservation, and remains competitive on AED, indicating reasonable expression stability. The main takeaway is that the 3D feedback loop improves cross-view coherence and image quality without sacrificing identity to the extent seen in purely generative baselines.
| Method | CSIM $\uparrow$ | CV-CSIM $\uparrow$ | AKD $\downarrow$ | AED $\downarrow$ | FID $\downarrow$ | CLIP-IQA $\uparrow$ |
|---|---|---|---|---|---|---|
| Intergsedit | 0.525 | 0.592 | 1.96 | 0.285 | 288 | 0.239 |
| LAM | 0.584 | 0.623 | 1.80 | 0.270 | 277 | 0.369 |
| Human-3Diffusion | 0.481 | 0.546 | 1.20 | 0.179 | 268 | 0.399 |
| FaceLift | 0.648 | 0.664 | 1.22 | 0.246 | 242 | 0.399 |
| Arc2Avatar | 0.608 | 0.801 | 1.12 | 0.240 | 257 | 0.621 |
| DreamGaussian | 0.663 | 0.661 | 2.16 | 0.276 | 262 | 0.290 |
| GAGAvatar | 0.701 | 0.577 | 1.07 | 0.190 | 246 | 0.566 |
| FastAvatar | 0.345 | 0.811 | 1.85 | 0.266 | 230 | 0.549 |
| SplatShot | 0.698 | 0.832 | 0.92 | 0.202 | 216 | 0.633 |
Two details matter when reading this table. First, the paper evaluates the final 3DGS renderings, not intermediate diffusion predictions, because the final representation is the explicit avatar. Second, the gains are not isolated to a single metric: the method improves cross-view coherence, geometric stability, and perceptual quality simultaneously, which is precisely the combination the paper argues is hard to obtain with any one prior class alone.
Ablations and Design Choices
The ablation study is one of the most informative parts of the paper because it separates the role of each component in the pipeline. The authors ablate the geometry guidance weight $\lambda$, the hybrid noise weight $w$, denoising strength $s$, the number of views $V$, the number of 3DGS refit iterations $M$, and the presence of ControlNet pose conditioning. The overall pattern is straightforward: the full system performs best only when geometry guidance is strong enough to enforce consistency, but not so strong that it over-constrains the diffusion output; the noise mixture is needed to stabilize early steps; and pose conditioning helps both identity and consistency.

Geometry guidance weight $\lambda$
The default value is $\lambda = 5 \times 10^4$. Setting $\lambda = 0$ removes the 3D feedback loop, which causes a sharp drop in cross-view consistency even if identity similarity remains moderate. Increasing $\lambda$ from $10^4$ to $5 \times 10^4$ improves the balance between fidelity and coherence. Pushing it to $10^5$ over-constrains generation and hurts performance.
| Setting | CSIM $\uparrow$ | CV-CSIM $\uparrow$ | CLIP-IQA $\uparrow$ |
|---|---|---|---|
| $\lambda = 0$ | 0.56 | 0.38 | 0.45 |
| $\lambda = 10^4$ | 0.60 | 0.57 | 0.52 |
| $\lambda = 5 \times 10^4$ | 0.70 | 0.83 | 0.63 |
| $\lambda = 10^5$ | 0.64 | 0.84 | 0.61 |
Hybrid noise weight $w$
The hybrid prediction is essential for stable early guidance. The paper reports that using predicted noise alone ($w = 1$) produces unstable geometry because the early clean predictions are too corrupted. Mixing in ground-truth noise progressively stabilizes the images. The default $w = 0.4$ performs best overall.
| Setting | CSIM $\uparrow$ | CV-CSIM $\uparrow$ | CLIP-IQA $\uparrow$ |
|---|---|---|---|
| $w = 1$ | 0.64 | 0.82 | 0.39 |
| $w = 0.7$ | 0.69 | 0.82 | 0.48 |
| $w = 0.4$ | 0.70 | 0.83 | 0.63 |
| $w = 0.1$ | 0.69 | 0.81 | 0.63 |
Denoising strength $s$
Denoising strength controls the trade-off between preserving the base model and transferring the input identity. Lower values retain more of the base appearance and geometry. Higher values enable stronger identity transfer, including changes in facial structure. The paper uses $s = 0.6$ as the default, which gives strong transfer with only a modest consistency penalty.
| Setting | CSIM $\uparrow$ | CV-CSIM $\uparrow$ | CLIP-IQA $\uparrow$ |
|---|---|---|---|
| $s = 0.3$ | 0.41 | 0.89 | 0.67 |
| $s = 0.6$ | 0.70 | 0.83 | 0.63 |
| $s = 0.8$ | 0.74 | 0.74 | 0.56 |
Number of views $V$ and refit iterations $M$
The paper uses $V = 16$ rendered views as the default. Fewer views reduce the quality of the 3D consensus, while more views improve consistency at greater compute cost. Similarly, refitting the 3DGS for $M = 200$ iterations at later guidance steps is a good trade-off; increasing to $500$ iterations produces only diminishing returns. The first guidance step uses $1{,}000$ refit iterations because the base model needs a larger initial correction.
| Setting | CSIM $\uparrow$ | CV-CSIM $\uparrow$ | CLIP-IQA $\uparrow$ |
|---|---|---|---|
| $V = 8$ | 0.68 | 0.61 | 0.59 |
| $V = 16$ | 0.70 | 0.83 | 0.63 |
| $V = 32$ | 0.67 | 0.86 | 0.60 |
| $M = 50$ | 0.64 | 0.69 | 0.52 |
| $M = 200$ | 0.70 | 0.83 | 0.63 |
| $M = 500$ | 0.73 | 0.83 | 0.65 |
ControlNet pose conditioning
The paper reports that removing ControlNet hurts both identity and consistency because the generated faces drift from the intended viewpoint configuration. In the reported ablation table, the default with ControlNet performs better than the no-ControlNet variant on both CSIM and CV-CSIM.
| Setting | CSIM $\uparrow$ | CV-CSIM $\uparrow$ | CLIP-IQA $\uparrow$ |
|---|---|---|---|
| Without ControlNet | 0.65 | 0.74 | 0.45 |
| With ControlNet | 0.70 | 0.83 | 0.63 |
Base Model Selection and Its Role
A distinct contribution of the paper is its treatment of the base 3DGS model not as a nuisance but as a useful prior. The method selects a NeRSemble base avatar using weighted DINO-ViT feature similarity over three semantic regions: hair, skin, and overall face shape, with weights $0.4$, $0.3$, and $0.3$ respectively. Hair gets the highest weight because it is both geometrically challenging and strongly inherited from the base model. The paper argues that this is necessary because the identity encoder crops tightly around the face and therefore does not reliably capture hairstyle.



The supplementary experiments show two important behaviors. When the base is fixed and the input image changes, the method transfers facial identity, skin tone, and facial structure, but hairstyle remains largely inherited from the base. When the input is fixed and the base changes, the reference identity is still preserved, but hairstyle and clothing vary with the base. This supports the authors’ claim that the base model acts as a soft anchor rather than a rigid template. Facial features can change substantially if the identity signal is strong enough, but hair and some accessories are still partly controlled by the initialization.
Novel-View Consistency Analysis
The paper goes beyond standard qualitative rendering and explicitly tests whether baseline outputs can be refit into a coherent 3DGS. This is a strong diagnostic because some methods can look good as individual rendered images while still failing to represent a true 3D object. The authors show that GAGAvatar’s outputs, when refit to a 3DGS and rendered from new viewpoints, contain floaters, fragmentation, and inconsistent structure. By contrast, SplatShot’s outputs remain coherent under the same refitting procedure. This provides direct evidence that the method does not just synthesize plausible per-view images; it produces multi-view outputs that are already compatible with a 3D representation.

Negative Results and Efficiency Trade-offs
The appendix includes several negative results that clarify why the final design looks the way it does. One is an attempt to accelerate the method using PeRFlow-style rectified flow sampling. In principle, fewer sampling steps should reduce runtime, but in practice the method loses too many guidance opportunities. Because SplatShot’s geometry correction is applied at each denoising step, sampling in only 4--8 steps does not allow enough iterative refinement for the multi-view predictions to become consistent.

The authors also tried a more elaborate guided forward diffusion strategy in which noise is added incrementally and the 3DGS is refit during the forward noising process. This was theoretically appealing and did not degrade output quality, but it doubled inference time and gave only marginal gains over the simpler single-step noise addition. The final paper therefore keeps the simpler strategy.
Discussion, Limitations, and Broader Impacts
The paper’s main conclusion is that single-image avatar generation benefits from combining image-space priors with an explicit 3D representation. The diffusion model improves realism, while the 3DGS model repeatedly projects the solution back into a consistent geometric space. This is what enables SplatShot to outperform methods that are either purely 2D-generative or purely feed-forward 3D predictors on difficult in-the-wild photos.
The authors also include a small demographic analysis. They report similar CSIM across groups, with values around $0.72$ for Caucasian identities, $0.69$ for African and Asian identities, $0.70$ for Hispanic identities, $0.66$ for children, and $0.67$ for elderly subjects, compared with $0.70$ on the full dataset. The paper interprets this as evidence that the method does not strongly favor a single subgroup in the reported evaluation, although this is still limited by the specific dataset and model choices.
The limitations are practical and important. First, the iterative refitting makes the pipeline slower than feed-forward methods: roughly 3 minutes per identity on an A100, compared with seconds for FastAvatar or GAGAvatar. Second, the geometric prior comes from NeRSemble, which mainly covers the frontal $180^\circ$ range, so back-view avatars were not evaluated. Third, hairstyle is heavily inherited from the selected base model, so a poor base match can create noticeable discrepancies. Fourth, hats remain difficult; the paper suggests this is due both to missing hat examples in NeRSemble and to the identity encoder entangling headwear with person identity.
The broader-impacts section also notes that the same technology could be used for beneficial applications such as AR/VR, gaming, telepresence, and digital content creation, but could also enable unauthorized digital replicas or deepfakes. The authors recommend consent-aware deployment and mention that their system embeds watermarks into generated images to support tracing and provenance verification.
Takeaway
SplatShot’s central contribution is not a new face generator in the usual sense, but a new inference-time coupling between diffusion and 3D reconstruction. By letting a 3DGS avatar supervise the diffusion trajectory step by step, the method obtains outputs that are both visually realistic and genuinely coherent as a 3D object. The paper’s strongest evidence comes from the combination of quantitative gains, ablation studies, and the novel-view refitting test, which together support the claim that explicit 3D feedback is the crucial ingredient for single-image unconstrained 3D face avatar generation.
Code & Implementation
The SplatShot repository implements the method described in the paper for generating 3D face avatars from a single unconstrained photo using a combination of 3D Gaussian Splatting (3DGS) and diffusion models.
The main inference pipeline is provided in inference.py, which serves as the entry point to the method. This script takes a single input photo and outputs a photorealistic 3D Gaussian Splatting model along with multi-view diffusion images and camera data needed for rendering. The script handles selection of a base 3DGS face template, preprocessing, and orchestration of the joint denoising and 3DGS fitting steps.
The core diffusion model integration is wrapped in core/diffusion_wrapper.py, which sets up Stable Diffusion pipelines enhanced with ControlNet and IP-Adapter for identity conditioning and multi-conditioning (pose, segmentation). This enables the diffusion prior to guide the denoising process towards photorealistic, identity-faithful images.
The tightly coupled 3DGS-guided denoising loop is implemented in pipelines/_shared_3dgs_guidance.py. It coordinates multi-view denoising steps, re-fitting the 3D Gaussian Splatting model at each timestep to the updated denoised images, and backpropagating photometric discrepancies to steer the sampling trajectory towards multi-view consistency and geometric fidelity.
Users can run the full pipeline simply by invoking python inference.py --image <input_photo> after setup. The output includes a refined 3DGS avatar model as avatar.ply suitable for visualization in external 3DGS viewers, illustrating the paper's contribution of joint 3D-diffusion optimization without per-subject training.