Reference-Guided Deep Compression VAEs
Real-Time Generation of Streamable Talking Portrait Video with Reference-Guided Deep Compression VAEs

A new framework for real-time, streamable talking portrait video generation using speech audio and reference images. It uses a reference-guided causal video VAE to compress dynamics efficiently, enabling high-quality, low-latency video suited for interactive AI communication.
Demos
These demos showcase real-time generation of talking portrait videos conditioned on speech and reference images using Reference-Guided Deep Compression VAEs. Watch for high-quality lip synchronization, vivid details, smooth temporal consistency, and the system's ability to maintain realism while running efficiently for streaming scenarios. This method balances speed and video quality, outperforming or matching large baseline models.

Links
Paper & demos
Abstract
Video diffusion models have significantly advanced portrait video generation, yet their high computational demands limit their use in interactive applications. This work presents a framework for streamable talking portrait video generation conditioned on speech audio and reference images. Designed meticulously for streaming scenarios, it features a causal video VAE for deep latent compression and an autoregressive latent denoising model. Our causal VAE integrates a variable number of reference images as guidance, allowing the network to focus on dynamic information rather than static appearance, thereby enhancing compression efficacy and reconstruction quality. Additionally, we extend the residual auto-encoding paradigm to improve spatial-temporal causality handling in our VAE. The generator is based on a Rectified Flow Transformer architecture and produces video latents in a blockwise auto-regressive manner. Our method enables the real-time generation of high-quality talking portrait videos, achieving speeds significantly faster than baseline models. Furthermore, comprehensive experiments demonstrate that it is on par with or even outperforms these large models in realism, vividness, and video quality.
Introduction
This paper addresses streamable, real-time talking portrait generation from speech audio and one or more reference images. The target application is interactive human-AI communication, where a system must synthesize lifelike portrait video with low latency, high visual fidelity, and temporal continuity over arbitrarily long sequences. The paper argues that prior talking-head systems are often restricted by strong face/head priors, while large video diffusion models can produce richer torso-level motion and lighting effects but are too expensive for real-time use.
The core idea is to shift most of the complexity into a deep-compression causal video VAE and then generate in the compressed latent space with a blockwise autoregressive Rectified Flow Transformer. This design is explicitly tailored to streaming: the VAE is causal so that decoding can proceed without future-frame leakage, and the generator is autoregressive with KV caching so inference can be run window by window.
The paper’s main novelty is not simply higher compression, but reference-guided deep compression: the VAE decoder receives one or multiple reference images so the latent space can focus on dynamic information instead of static identity and background details. A second key contribution is a causal residual video auto-encoding scheme that adapts the residual encoding ideas of DC-AE to spatiotemporal data while preserving causality, especially for the first frame. The result is a very high overall compression ratio of 768, substantially above the ratio used in popular video diffusion systems.
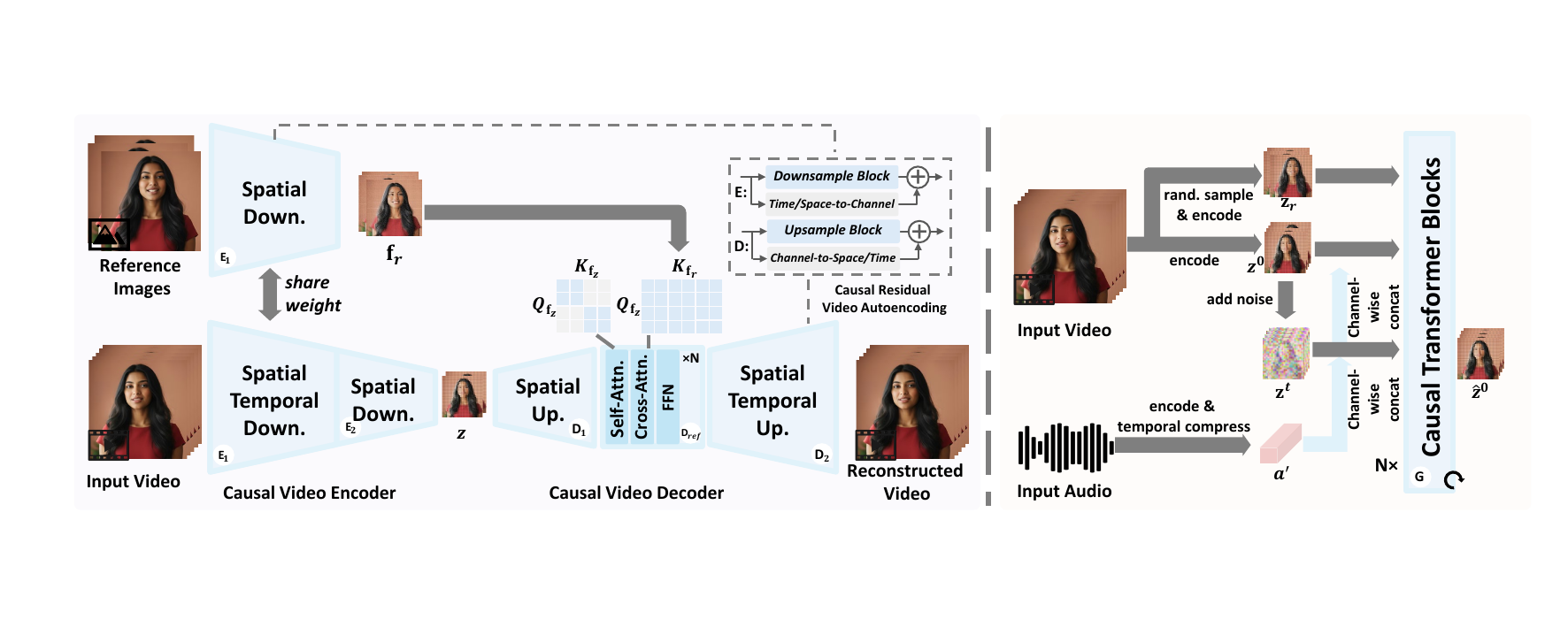
Method
Problem formulation
The task is defined as conditional portrait video generation: given a reference image set $\mathbf{r} = \{\mathbf{x}_1, \ldots, \mathbf{x}_m\}$ and an audio signal $\mathbf{a}$, generate a portrait video $\mathbf{y} = [\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_n]$ from the conditional distribution
$$ \mathbf{y} \sim p(\mathbf{y} \mid \mathbf{r}, \mathbf{a}). $$
The method decomposes this into two stages: first encode the video into compact latents $\mathbf{z}$ conditioned on audio; then decode $\mathbf{z}$ back into frames. The entire system is designed so that both the latent generation and the video decoding can be streamed sequentially.
Reference-guided deep video compression
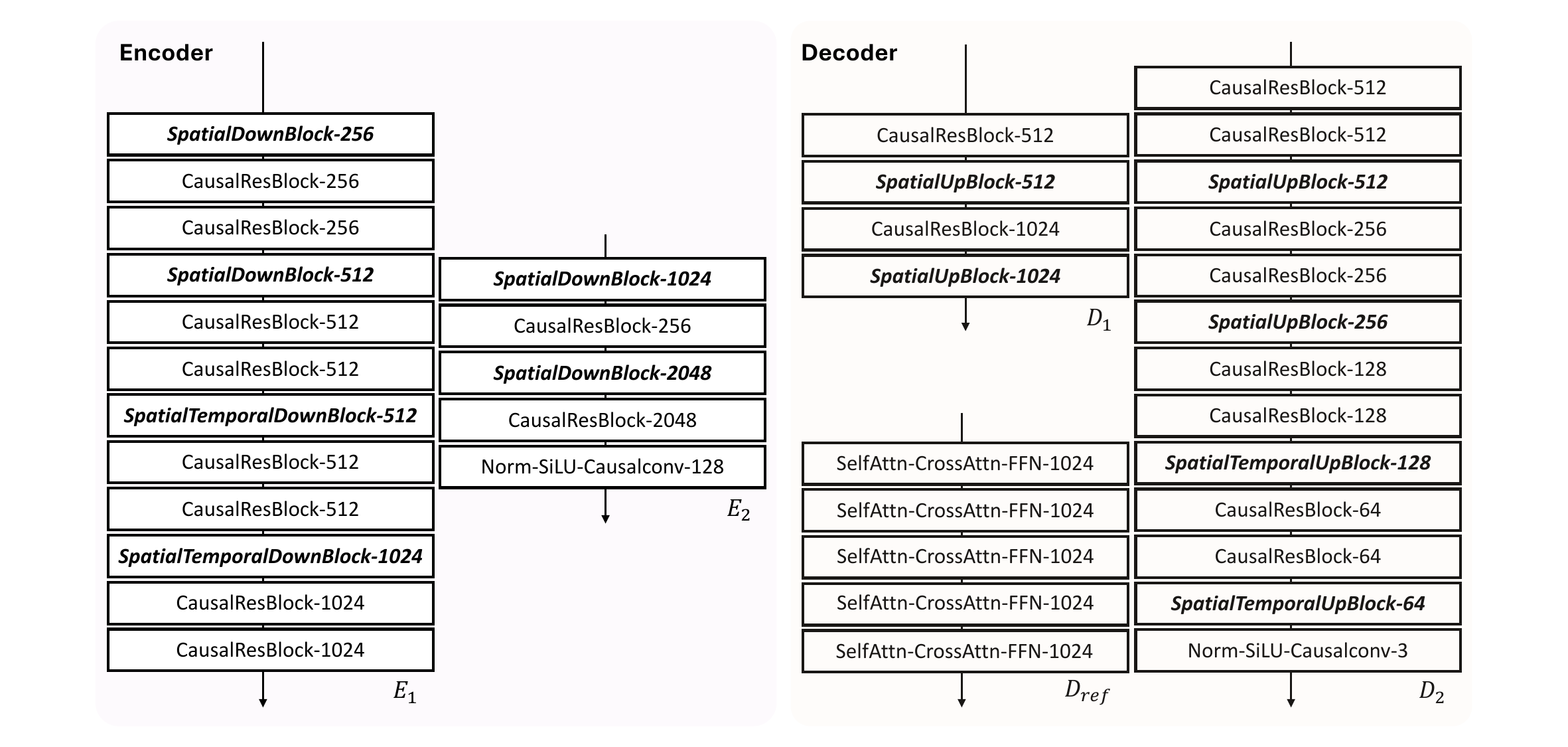
The VAE uses a two-stage causal auto-encoder with an encoder $E_1$ that performs joint spatial-temporal downsampling and a second encoder $E_2$ that further compresses spatial resolution. The decoder mirrors this hierarchy with $D_1$ and $D_2$. All main modules are built from causal convolutional residual blocks, and the paper notes the use of RMSNorm to preserve temporal causality.
The input video has shape $3 \times (T+1) \times H \times W$, where the extra frame reflects the common causal-VAE convention of treating the first frame as a single-image case. The latent tensor has shape $C_z \times T_z \times H_z \times W_z$, with $C_z = 64$, temporal downsampling by $4$, and spatial downsampling by $64$. This yields an overall compression ratio of 768.
A key departure from ordinary video VAEs is reference guidance inside the decoder. The first encoder $E_1$ is reused frame-by-frame on the reference images to obtain mid-level appearance features. Between $D_1$ and $D_2$, a transformer fusion module $D_{\text{ref}}$ combines the upsampled latent features with reference features using frame-wise self-attention followed by cross-attention. During training, the model randomly samples different numbers of references, so at inference it can accept a variable number of user-provided reference images. The paper’s intuition is that because the subject is largely fixed, the reference images let the VAE spend capacity on dynamics rather than reconstructing static appearance.
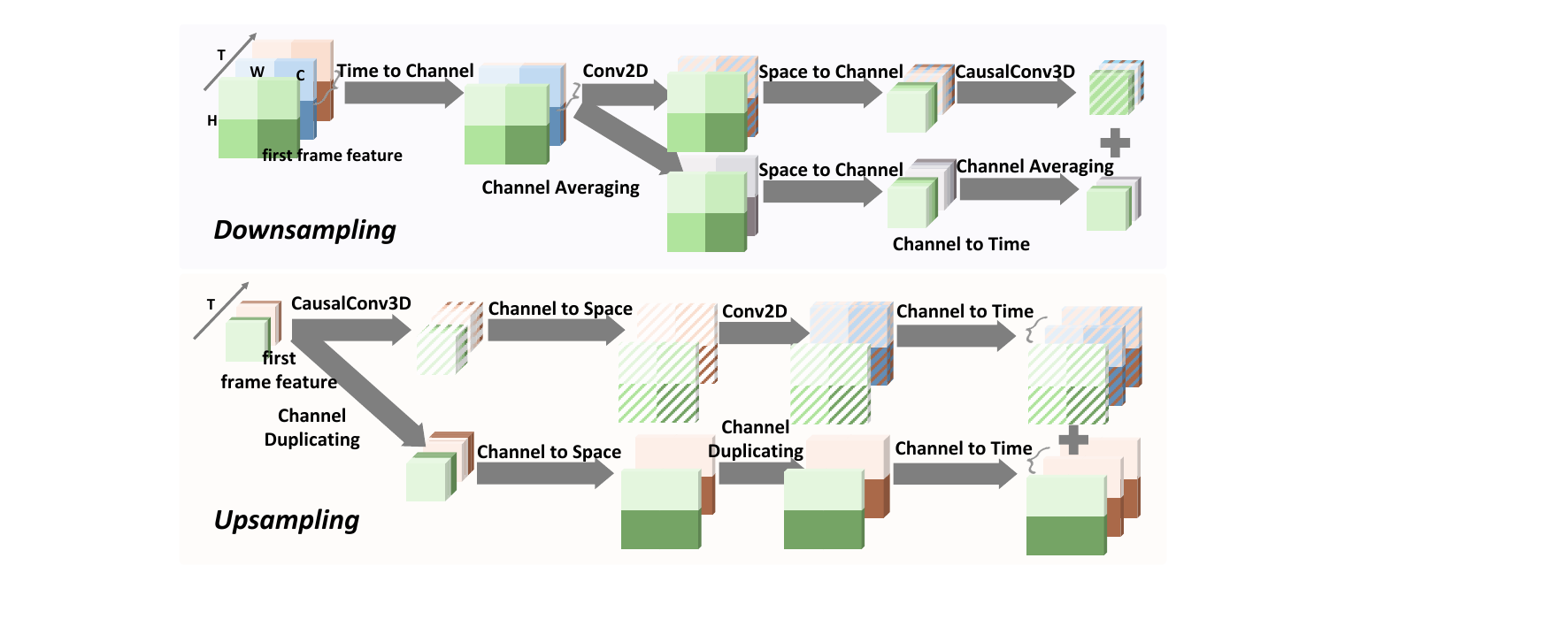
Causal residual video auto-encoding
To improve reconstruction quality at very high compression, the paper extends DC-AE-style residual auto-encoding to the causal video setting. Resolution changes are decomposed into two steps: a temporal residual encoding step and a spatial residual encoding step. The first frame is treated separately so temporal causality is never violated.
Conceptually, the downsampling path applies temporal residual processing first, excluding the first frame, and then spatial residual processing. The upsampling path reverses this order. The supplementary material makes the implementation concrete using parameter-free shortcuts based on $\text{PixelUnshuffle3d}$ and channel averaging for downsampling, and channel duplication plus $\text{PixelShuffle3d}$ for upsampling. The main residual branch uses causal convolutions to match dimensions, while the shortcut branch matches dimensions without learnable parameters.
The VAE training objective combines pixel reconstruction, perceptual similarity, and KL regularization:
$$ \mathbb{E}\left[\lambda_1 \lVert \hat{\mathbf{y}} - \mathbf{y} \rVert_1 + \lambda_2 \operatorname{LPIPS}(\hat{\mathbf{y}}, \mathbf{y})\right], $$
with a KL penalty on the latent code $\mathbf{z}$. The paper emphasizes that the combined reference guidance plus causal residual encoding gives the VAE substantially better reconstructions than a causal VAE without reference injection.
Blockwise autoregressive latent generation
Once the compact latent space is learned, the generator $G$ models the conditional distribution of video latents given audio and references. The generator is a Rectified Flow Transformer: generation is formulated as solving an ODE that transports a noise distribution to the target latent distribution via a learned velocity field.
Reference images are encoded frame-wise to reference latents $\mathbf{z}_r$. Audio is processed with a pretrained audio encoder and then temporally compressed by a trainable embedder so that audio features align with video latents. These audio features are broadcast spatially and concatenated with the noised latent input. A denoising timestep embedding is injected via AdaLN.
For streaming efficiency, the latent sequence is generated blockwise autoregressively. The paper uses non-overlapping blocks of size $k = 4$ latent frames. Attention is full within a block, but inter-block attention is causal, restricted to preceding blocks only. This preserves temporal causality while reducing memory and compute. During inference, KV caching is used so the model can reuse previously generated context.
The generator is trained with teacher forcing. During training, the model conditions on ground-truth previous latents, which are lightly noised to reduce train-inference mismatch. The conditional flow-matching objective is
$$ \mathbb{E}\left\lVert G(\mathbf{z}^t, \mathbf{z}_r, \mathbf{a}', t) - (\boldsymbol{\epsilon}^t - \mathbf{z}^0) \right\rVert_2^2, $$
where $\mathbf{z}^0$ is the clean latent and $\mathbf{z}^t$ is the noisy version used for denoising. The model also randomly replaces the audio and reference conditions with null embeddings to enable classifier-free guidance at inference time. The reference latents are randomly masked during training so the model can handle a variable number of references.
Streaming inference
At inference, the system proceeds window by window. Audio frames are accumulated, the generator predicts latent blocks autoregressively, and the decoder turns them into video frames while preserving causality. The previous window’s last block is reused as context for the next window, which keeps the stream continuous across long sequences. The supplementary material reports that using the longest KV window, the audio encoder plus the generator takes $0.288$ seconds to produce $4$ latent frames, corresponding to $16$ video frames, and the decoder takes another $0.09$ seconds, for a total latency of $0.378$ seconds or 42.3 FPS.
Implementation details
The main implementation choices are as follows. In the causal video VAE, $E_1$ contains eight residual blocks; every two blocks perform spatial downsampling, and temporal downsampling occurs at the 4th and 6th blocks. The output feature dimension of $E_1$ is 1024. $E_2$ further compresses the latent with two residual blocks. The decoder is symmetric. The reference fusion module $D_{\text{ref}}$ uses six transformer blocks with 16 attention heads and head dimension 64.
The generator $G$ uses 24 transformer blocks with 12 attention heads and head dimension 128. The paper also uses 3D Rotary Positional Embedding to encode spatiotemporal positions. The model has substantial capacity: the VAE encoder, decoder, and generator have approximately 497M, 406M, and 1B parameters, respectively.
Training is progressive for the VAE. It is first trained on $256^2$ clips of 5 frames, then on longer clips of 17 and 73 frames, and finally fine-tuned at $512^2$. The denoising model is trained on latent windows of 32 frames, with 1 to 3 reference images, using teacher forcing and classifier-free dropping of audio and reference conditions.
Experiments
Datasets and evaluation protocol
The training data combine filtered VoxCeleb2 and an in-house talking portrait dataset. The paper reports about 50 hours from VoxCeleb2, 280 hours from the in-house dataset, and roughly 10K unique identities in total. Videos are cropped to portrait regions and segmented into clips up to 10 seconds long.
Evaluation is conducted on two main benchmarks. HDTF is processed similarly to the training data; the test set contains 123 segments from 66 unseen identities. PortraitOneMin contains 32 one-minute clips from 16 unseen identities, sourced from online coaching and educational lectures. For the reconstruction ablation, the paper also uses a VoxCeleb2 test split with around 1K clips.
The main metrics are SyncNet confidence $S_C$ and SyncNet feature distance $S_D$ for audio-lip synchronization, CAPP for audio-pose alignment, and $\operatorname{FVD}_{25}$ computed over 25 consecutive frames for overall video quality. Higher $S_C$ and CAPP are better, while lower $S_D$ and $\operatorname{FVD}_{25}$ are better. Speed is reported as FPS on a single GPU.
Main quantitative results
The paper compares against EchoMIMIC, EchoMIMIC-Distilled, Hallo, Hallo2, Hallo3, Sonic, and FantasyTalking. The baselines are largely diffusion-based and offline; the paper stresses that they are not real-time. FantasyTalking could not report PortraitOneMin because its implementation failed to handle long video generation.
| Method | HDTF | PortraitOneMin | FPS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| $S_C$ | $S_D$ | CAPP | $\operatorname{FVD}_{25}$ | $S_C$ | $S_D$ | CAPP | $\operatorname{FVD}_{25}$ | ||
| EchoMIMIC | 5.291 | 9.557 | 0.341 | 143.620 | 4.863 | 9.594 | 0.208 | 177.141 | 1.4 |
| EchoMIMIC-Distilled | 5.513 | 9.350 | 0.348 | 174.061 | 5.531 | 9.187 | 0.201 | 201.899 | 13.3 |
| Hallo | 7.457 | 7.841 | 0.242 | 90.880 | 6.721 | 8.275 | 0.210 | 179.072 | 1.2 |
| Hallo2 | 7.547 | 7.819 | 0.247 | 88.170 | 6.829 | 8.244 | 0.196 | 162.672 | 1.2 |
| Hallo3 | 7.256 | 8.596 | 0.337 | 76.430 | 6.836 | 8.724 | 0.301 | 175.340 | 0.27 |
| Sonic | 8.799 | 6.602 | 0.689 | 43.920 | 8.185 | 7.031 | 0.598 | 95.047 | 1.7 |
| FantasyTalking | 4.167 | 11.144 | 0.407 | 89.726 | -- | -- | -- | -- | 0.36 |
| Ours, $M=1$ | 8.943 | 6.286 | 0.699 | 62.300 | 8.537 | 6.619 | 0.648 | 91.964 | 42.3 |
| Ours, $M=2$ | 9.056 | 6.175 | 0.739 | 49.400 | 8.438 | 6.688 | 0.677 | 81.517 | |
| Ours, $M=3$ | 8.998 | 6.226 | 0.739 | 43.270 | 8.546 | 6.648 | 0.659 | 73.693 | |
The headline result is that the proposed method is both fast and competitive in quality. With $M=1$, it achieves the best lip-sync and head-audio alignment among the compared methods on the two benchmarks, while also being far faster than the diffusion baselines. As more reference images are added, the method improves further, especially in $\operatorname{FVD}_{25}$, suggesting that reference frames help both the VAE reconstruction and the generation problem itself. The paper reports an inference speed of 42.3 FPS on a single H100 GPU, which is more than $25\times$ faster than the reported diffusion-based talking portrait systems in the table.

Ablation: reference guidance and causal residual video auto-encoding
The central ablation evaluates two components of the VAE: reference guidance and causal residual video auto-encoding (CR-VA). The table below reports reconstruction on VoxCeleb2 and HDTF. The main pattern is clear: adding reference guidance significantly improves PSNR and LPIPS, and CR-VA further increases the benefit as more reference images are provided.
| Setting | $M$ | VoxCeleb2 | HDTF | ||||||
|---|---|---|---|---|---|---|---|---|---|
| $L_1$ | PSNR | $\Delta$PSNR | LPIPS | $L_1$ | PSNR | $\Delta$PSNR | LPIPS | ||
| w/o CR-VA, no ref. | 0 | 0.020 | 29.071 | -- | 0.088 | 0.021 | 28.306 | -- | 0.087 |
| w/o CR-VA | 1 | 0.014 | 31.676 | 2.605 | 0.051 | 0.013 | 32.068 | 3.762 | 0.040 |
| w/o CR-VA | 2 | 0.013 | 32.305 | 3.234 | 0.043 | 0.012 | 32.663 | 4.357 | 0.035 |
| w/o CR-VA | 3 | 0.012 | 32.766 | 3.695 | 0.039 | 0.012 | 33.149 | 4.843 | 0.032 |
| w. CR-VA, no ref. | 0 | 0.018 | 29.604 | -- | 0.087 | 0.020 | 28.678 | -- | 0.086 |
| w. CR-VA | 1 | 0.013 | 32.354 | 2.750 | 0.045 | 0.012 | 33.469 | 4.791 | 0.032 |
| w. CR-VA | 2 | 0.012 | 33.281 | 3.677 | 0.036 | 0.010 | 34.510 | 5.832 | 0.027 |
| w. CR-VA | 3 | 0.011 | 33.979 | 4.375 | 0.031 | 0.010 | 35.374 | 6.696 | 0.023 |
From these numbers, three conclusions follow. First, reference guidance alone improves reconstruction strongly: on VoxCeleb2, PSNR rises from 29.071 to 31.676 with one reference image, and on HDTF it rises from 28.306 to 32.068. Second, increasing the number of reference images yields additional gains. Third, CR-VA and reference guidance are complementary: with CR-VA, the gain from $M=0$ to $M=3$ is larger than without CR-VA on both datasets, showing that the residual encoding scheme amplifies the value of reference conditioning.

Additional supplementary experiments
The supplementary material also evaluates the method in a head-cropped setting against SadTalker and VASA-1. With the same general framework and a recropped dataset, the paper reports that the method matches VASA-1 closely on lip-sync and audio-pose alignment, while producing better overall video quality according to $\operatorname{FVD}_{25}$. In that setting, the reported speed is 23.3 FPS for the proposed method versus 37.9 FPS for VASA-1, but the proposed model remains substantially more flexible because it is aimed at broader portrait generation rather than only the head region.
The supplementary text also studies classifier-free guidance. Increasing audio guidance improves lip-sync but can reduce diversity; increasing reference guidance similarly sharpens identity alignment and stability but may hurt diversity if pushed too far. The default setting is $\lambda_a = \lambda_r = 2$, which gives the best balance in the reported ablation.
Limitations
The paper is explicit about two limitations. First, the method does not provide fine-grained control over attributes such as eye gaze and head pose; the authors suggest adding more motion-conditioning signals during denoising as a possible remedy. Second, the current framework does not support hand motion or larger-scale body movement. The paper suggests that broader datasets with richer human-region coverage and more expressive motion patterns would be needed to address that limitation.
Conclusion
The paper presents a streamable audio-driven talking portrait system that combines a causal, reference-guided deep-compression VAE with a blockwise autoregressive Rectified Flow Transformer. The design is explicitly optimized for real-time inference: the latent compression ratio is very high, reference images improve reconstruction fidelity, and the generator can be cached and streamed block by block. Across the reported benchmarks, the method achieves strong synchronization and video quality while running at real-time speed, and the paper positions this as a practical alternative to heavy diffusion-based portrait generators for interactive applications.