MOSS-Audio
MOSS-Audio Technical Report

MOSS-Audio is a unified audio-language model for speech, environmental sounds, and music understanding. It preserves multi-level acoustic details and uses explicit time markers for advanced audio captioning, time-aware transcription, and reasoning beyond typical speech recognition.
Demos
MOSS-Audio demos showcase its unified audio understanding: speech recognition with timestamps, speaker emotion analysis, environmental sound, music interpretation, and complex reasoning. Watch for transcription accuracy, detailed event detection, and temporal reasoning. Demos highlight architecture preserving audio details and time context for advanced understanding.


Links
Paper & demos
Code & resources
Abstract
MOSS-Audio is a unified audio-language model for speech, environmental sound, and music understanding, supporting audio captioning, time-aware question answering, timestamped transcription, and audio-grounded reasoning. MOSS-Audio couples a dedicated audio encoder with a modality adapter and a large language model: the encoder produces 12.5 Hz temporal representations, the adapter projects them into the decoder space, and the decoder generates autoregressive text outputs. Two design choices are central to the system: DeepStack cross-layer feature injection, which exposes the decoder to acoustic information from multiple encoder depths, and time markers, which provide explicit temporal cues by inserting timestamp markers into the audio-token stream. At the data level, we design an event-preserving audio annotation pipeline that segments raw audio at coherent event boundaries, applies branch-specific annotation to speech, music, and general audio, and merges the results into unified captions for pretraining. The intermediate branch-specific captions are further retained to support the construction of task-oriented SFT data. The model is pretrained on large-scale audio-language data, with time-aware objectives incorporated to support temporal grounding, and then undergoes multi-stage post-training to enhance instruction following and audio-grounded reasoning. We release 4B and 8B variants in both Instruct and Thinking configurations. MOSS-Audio achieves strong performance across general audio understanding, speech captioning, ASR, and timestamped ASR, positioning it as a promising understanding foundation for future voice agents.
Introduction
MOSS-Audio is a unified audio-language model family for speech, environmental sound, and music understanding. The report positions it as an understanding-centric foundation model for tasks that require not only recognition, but also descriptive captioning, temporal grounding, and audio-grounded reasoning. In particular, the system is designed to support automatic speech recognition (ASR), speech captioning, audio captioning, timestamped transcription, time-aware question answering, and more complex reasoning over heterogeneous audio.
The core motivation is that audio is not merely a transcript carrier. A speech recording contains lexical content, speaker traits, prosody, emotion, turn-taking cues, and temporal structure; real-world audio may also contain overlapping events, music, environmental sounds, and long-range dependencies. The paper argues that these capabilities cannot be obtained by simple ASR-style adaptation. Instead, the model should preserve multi-level acoustic information and make temporal information explicit during generation.

The report’s main contributions are fourfold:
- a dedicated audio encoder trained from scratch on diverse audio-language data;
- DeepStack cross-layer feature injection to expose the decoder to multiple levels of acoustic representation;
- explicit time markers interleaved into the audio token stream for temporal grounding;
- a branched data construction and post-training recipe that supports both direct instruction following and reasoning-oriented audio understanding.
The authors release 4B and 8B variants in both Instruct and Thinking configurations. Empirically, the Thinking variants are strongest on broad general audio understanding, while the Instruct variants are best on speech captioning, ASR, and timestamped ASR.
Model Architecture
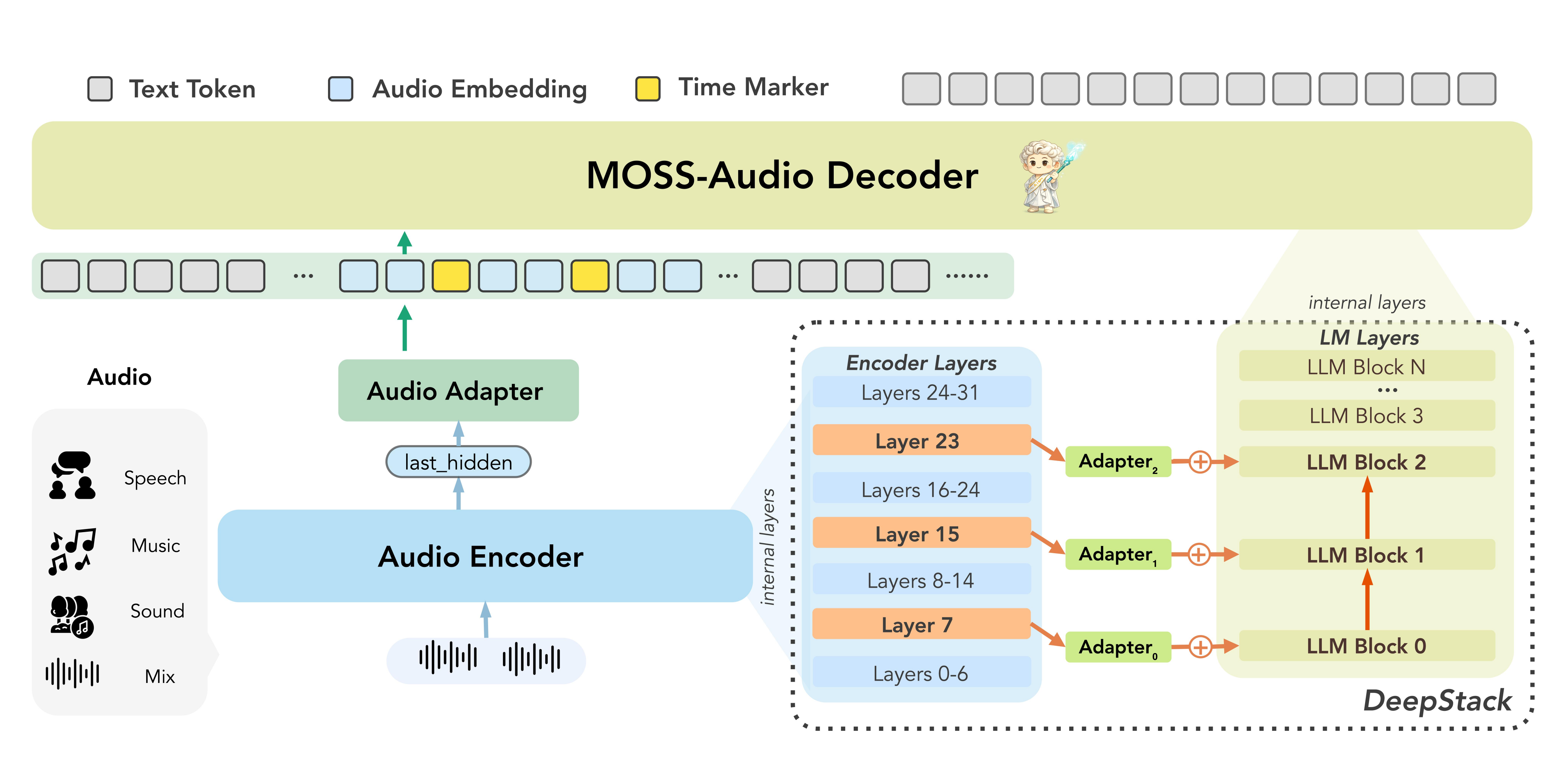
MOSS-Audio uses an encoder-adapter-decoder design built around a Qwen3 language backbone. The trainable components are: a dedicated audio encoder, two GatedMLP-based cross-modal adapters, and the decoder. Given a waveform, the model first converts it into log-mel features, then maps them into a sequence of temporal audio embeddings, and finally conditions the language model on those embeddings together with the user instruction.
Audio encoder
The audio encoder is trained from scratch on millions of hours of diverse audio data with ASR, audio speech translation, and audio caption tasks. It has approximately $0.6$B parameters, processes $128$-channel log-mel spectrograms, and uses three stride-$2$ convolutional layers to achieve an $8\times$ temporal downsampling. This yields a compact $12.5$ Hz token rate. The encoder then applies a $32$-layer Transformer with hidden size $1280$.
To manage long audio efficiently, the encoder uses sliding-window attention rather than global self-attention. The window is limited to $100$ frames, corresponding to about $8$ seconds. This makes the encoder more memory-efficient and compatible with real-time KV caching, while leaving long-range semantic integration to the language model.
DeepStack cross-layer feature injection
The paper argues that relying only on the final encoder layer tends to suppress low-level acoustic detail such as prosody, transient events, and local time-frequency structure. To address this, MOSS-Audio adopts DeepStack-style cross-layer injection. The final encoder output is consumed by a primary adapter, while intermediate hidden states are additionally extracted, merged by a second adapter, and injected into early decoder layers. Both adapters use the same GatedMLP projection form.
The goal is to expose the decoder to both semantic and sub-semantic acoustic evidence: final layers are better for speech semantics, whereas lower and intermediate layers retain more timbral, temporal, and environmental cues. The architecture is intended to preserve this information without enlarging the audio backbone.
Explicit time markers
For temporal grounding, MOSS-Audio interleaves explicit numeric time markers into the audio-conditioned sequence. Since the encoder operates at $12.5$ Hz, the system inserts a marker after every $25$ audio features, i.e. every $2$ seconds. These markers provide absolute temporal anchors for timestamped transcription, event localization, and time-aware audio question answering.
In effect, the decoder does not have to infer timing only from relative positions in a long audio prefix. Instead, timing becomes part of the context that the model can directly attend to and generate against.
Data Pipeline and Annotation Design
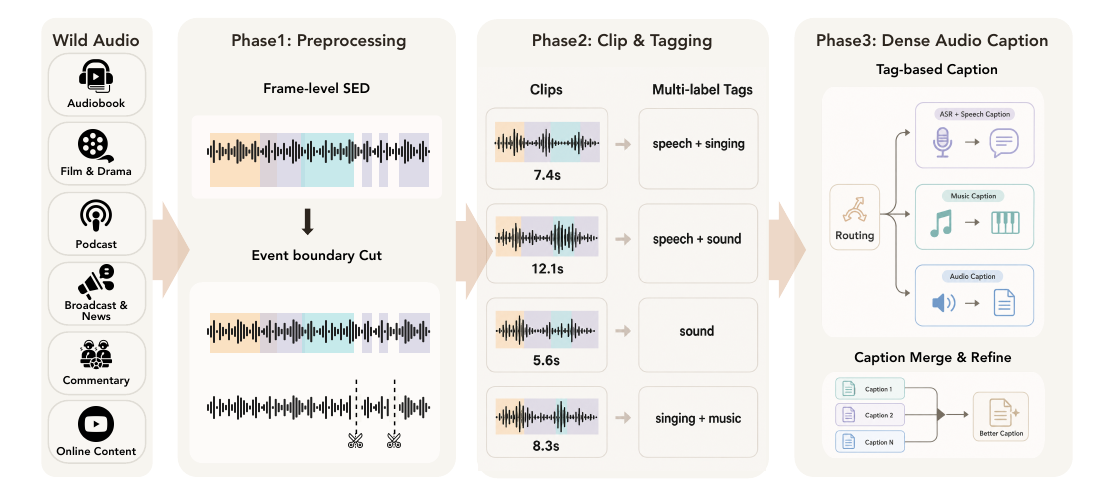
The data pipeline is one of the central technical contributions of the paper. Rather than treating every audio clip with a single generic captioning process, the authors build a branched annotation engine that preserves event structure and routes clips to speech, music, and general-audio annotation branches. The branch outputs are later merged into a unified caption target for pretraining, and the intermediate branch-specific captions are retained for task-oriented supervised fine-tuning.
Event-preserving segmentation
The pipeline begins by running a frame-level sound event detector on each file using a BEATs backbone within the PretrainedSED framework. Instead of fixed-window chopping, clips are segmented at natural event boundaries. Vocal and speech-related events are merged with gap tolerance to preserve speaker turns and continuous utterances. Non-speech events longer than $60$ seconds are excluded from boundary computation because they often represent persistent ambient conditions rather than discrete events, although their annotations are still kept for downstream use.
The remaining events are overlap-merged, padded at the boundaries, and cut at event gaps. A maximum segment length cap and a hard-cut fallback are used to keep the output compatible with training. Each segment is also mapped to nine coarse AudioSet-derived categories: speech, human voice (non-speech), singing, music, natural sounds, source-ambiguous sounds, sounds of things, channel/environment/background, and animal. Per-category durations are computed by interval merging to avoid double-counting overlaps.
ASR and timestamp alignment branch
Segments containing speech or singing are routed to the ASR branch. The paper uses an ensemble of ASR systems, including Qwen3-Omni-Instruct, FunASR Nano, and Qwen3-ASR, to generate pseudo-labels. The outputs are compared across systems, and the inter-system word error rate serves as a consistency signal: low-disagreement clips are preserved, while clips with strong disagreement are discarded to reduce noise.
Language identification is cross-validated using fastText on the recognized text and MMS-LID on the waveform, which helps handle short utterances and mixed-language cases. For temporal grounding, the authors use the TorchAudio MMS_FA forced-alignment model to align the consensus transcript to the waveform, producing word-level timestamps that are later aggregated into sentence-level segments using punctuation and temporal heuristics.
Speech caption branch
The speech-caption branch is designed for paralinguistic description rather than transcription. A segment is routed to this branch when either its predicted speech score or singing score is at least $0.5$. The segment is then diarized with DiariZen so that speaker-specific regions can be captioned individually. This matters because the target attributes are speaker-dependent: gender, age, accent, pitch, volume, speed, emotion, tone, personality, clarity, fluency, texture, and summary are all captured at the speaker-region level.
The annotation process is bootstrapped in two stages. First, an internally trained single-speaker speech-caption model is applied to diarized regions to create initial multi-speaker speech-caption data. Second, that bootstrapped data is used to train a final multi-speaker speech-caption annotator, which produces the speaker-aware captions used later in the unified caption merge.
General audio caption branch
The general-audio branch targets environmental sounds, open-domain acoustic scenes, and mixed real-world audio. It combines local event evidence from PretrainedSED and Detect Any Sound with global semantic anchors extracted by Qwen3-Omni-Captioner. Qwen3-Omni-30B-Thinking then acts as the fusion-based dense-caption generator, integrating the audio, event metadata, and global semantic cues into a natural-language description that includes scene semantics, foreground/background relations, source interactions, acoustic attributes, and temporal context.
To improve reliability, candidate captions are verified against ASR annotations for speech regions, TimeAudio outputs, and event metadata. An LLM-based judge checks scene consistency, vocal activity, event correctness, source entities, acoustic attributes, and temporal coherence, and decides whether each sample should be kept, revised, or filtered. The pipeline also includes synthetic timestamped audio-caption construction for rare event combinations, overlapping sounds, and long-context transitions.
Music caption branch
The music branch converts musical audio into musically grounded supervision rather than generic audio description. A holistic base caption is first obtained from an audio-language model such as Qwen3-Omni, MusicFlamingo, or Audio-Flamingo. In parallel, dedicated music-analysis tools estimate chord sequences, beats, tempo, key, melody-related descriptors, active instruments, and song structure. SongFormer predicts structure labels such as intro, verse, chorus, bridge, instrumental, and outro.
These structure boundaries are used to segment the track, and segment-level lyrics ASR and key analysis provide aligned tuples of structure label, timestamp, key, chord progression, and lyrics. The final caption is generated by an instruction LLM that is explicitly constrained to synthesize a listener-facing description of style, tempo, tonal center, harmonic movement, instrumentation, production texture, vocal and lyrical content when available, structure, dynamics, and mood.
Caption merge and refine
Because a single clip can produce multiple branch outputs, the paper defines a canonical merge step. All annotations are normalized into a shared tool_results interface with slots such as asr, event_caption, speech_caption, and music_caption. Global audio-class scores are normalized to $[0,1]$ and compressed into three coarse priors: speech, music, and event.
A lightweight routing policy called Router-R1 uses those priors, the top-$k$ predictions, and residual uncertainty to decide which evidence branches should be included and in what order. The router is deliberately conservative and includes quality-control rules such as removing empty or repetitive ASR hypotheses, suppressing speech evidence when the speech prior is negligible, preventing non-linguistic vocalizations from being treated as lexical speech, and suppressing music claims when the music branch indicates that music is absent.
The selected evidence is then synthesized by a two-stage LLM procedure. A planning prompt first generates a structured JSON object with the primary theme, evidence sources, merge order, and rationale. A generation prompt then converts that plan into a single English caption. A deterministic fallback caption is also produced to improve robustness. This merged target becomes the core pretraining caption for holistic audio understanding.
Pretraining and Post-Training Recipe
Pretraining is intended to establish a robust audio-language interface before the model is exposed to more complex instruction-following and reasoning tasks. The pretraining mixture has three objective groups:
- ASR-related tasks for precise audio-to-text transcription, including ordinary ASR, word-level timestamp ASR, and sentence-level timestamp ASR;
- audio captioning for open-ended understanding using the merged captions produced by the data pipeline;
- text-only language modeling to preserve general text generation, knowledge expression, and reasoning capability.
The default sampling ratio is $30\%$ ASR-related tasks, $40\%$ audio captioning, and $30\%$ text-only language modeling. The paper states that pretraining uses approximately $1.2$T training tokens. Within each objective group, datasets are sampled with a square-root strategy so that very large datasets do not dominate the mixture.
| Stage | Data mixture | Main optimization focus |
|---|---|---|
| Pretraining Stage 1 | ASR-related tasks + audio captioning | Stabilize the audio-prefix pathway; mainly train the modality adapter and DeepStack modules |
| Pretraining Stage 2 | Full mixture including text-only language modeling | End-to-end optimization of the audio encoder, adapters, DeepStack injection, and language model |
After pretraining, the system undergoes multi-stage post-training to produce two operating modes: Instruct models for direct task execution and Thinking models for reasoning-heavy audio understanding.
Supervised fine-tuning
The first post-training stage is supervised fine-tuning. The SFT mixture contains audio question answering data, captioning data, ASR and timestamp ASR data, and self-identity data. The QA data is generated from speech captions, music captions, and general audio captions, and covers speech understanding, speaker-attribute analysis, acoustic-event understanding, music understanding, temporal reasoning, and scene-level audio comprehension. This stage teaches the model instruction formats and stable task execution.
Reasoning cold start
The second post-training stage is a reasoning cold start. It includes both audio-centered reasoning data and text-only reasoning data. The audio-centered data encourages the model to connect final answers to evidence such as spoken content, speaker attributes, prosody, emotion, acoustic events, temporal relations, music structure, instrumentation, vocal characteristics, and lyrics. The text-only reasoning data transfers general reasoning patterns from text to audio-language modeling.
Reinforcement learning
The final stage uses DAPO-based reinforcement learning to improve correctness, reasoning robustness, and format compliance. Rollouts are generated with temperature $1.0$, top-$p$ $1.0$, and top-$k$ $50$. Each prompt is expanded into $16$ sampled responses, the rollout batch size is $128$, the maximum response length is $2048$ tokens, and each training round uses $160$ rollouts for policy optimization.
The policy objective uses asymmetric clipping with lower and upper coefficients of $0.2$ and $0.28$, respectively. Token-level importance sampling correction is enabled with a clipping threshold of $2.0$ and a lower bound of $0.0$. The training procedure dynamically filters rollout groups whose reward standard deviation is near zero, because such groups do not provide a useful within-group advantage signal.
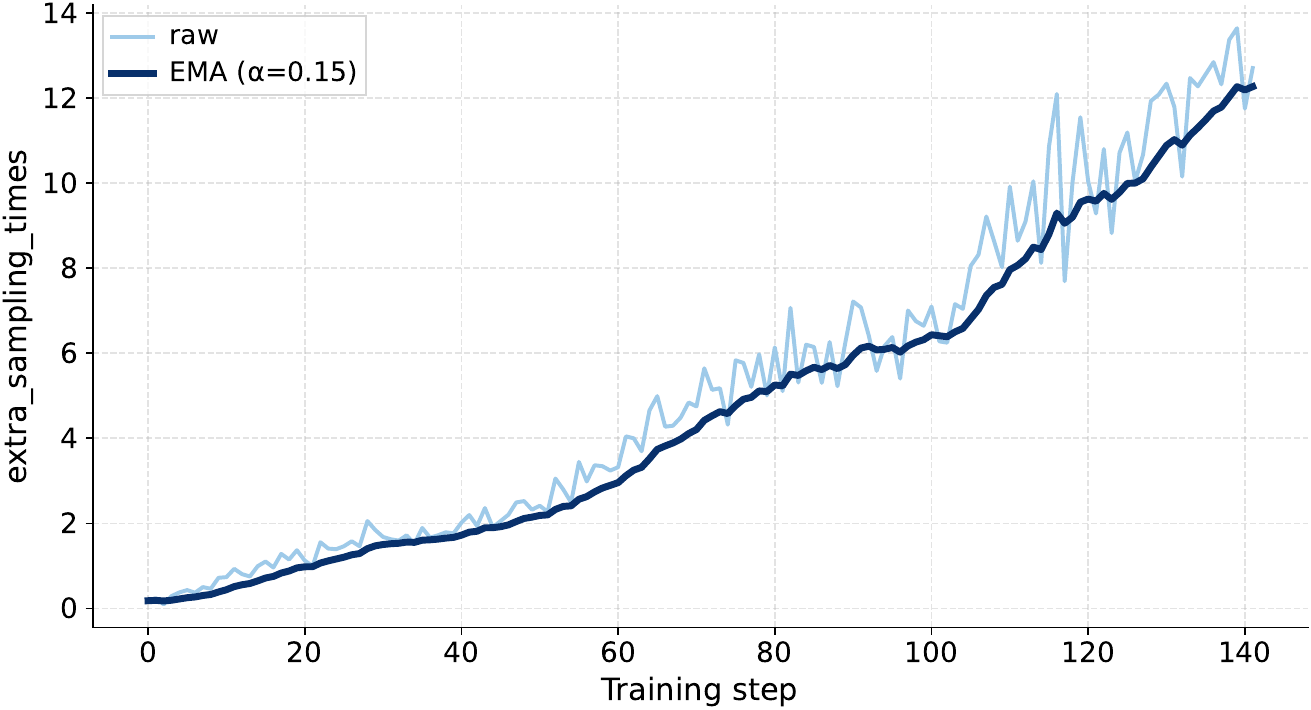
The appendix explains that this dynamic filtering increasingly triggers extra over-sampling as training progresses. The number of extra over-sampling rounds rises from $1$ to a maximum of $14$ at step $139$, indicating that more sampled groups are filtered out as the policy becomes more consistently correct.
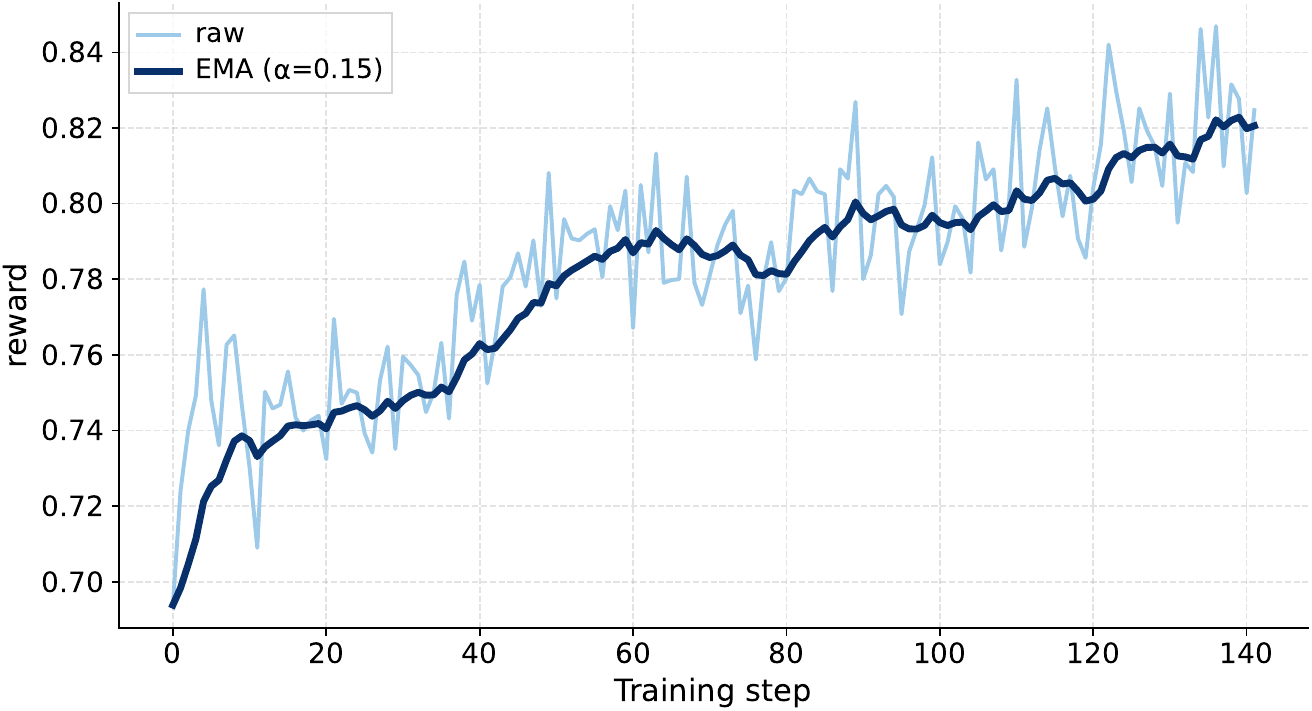
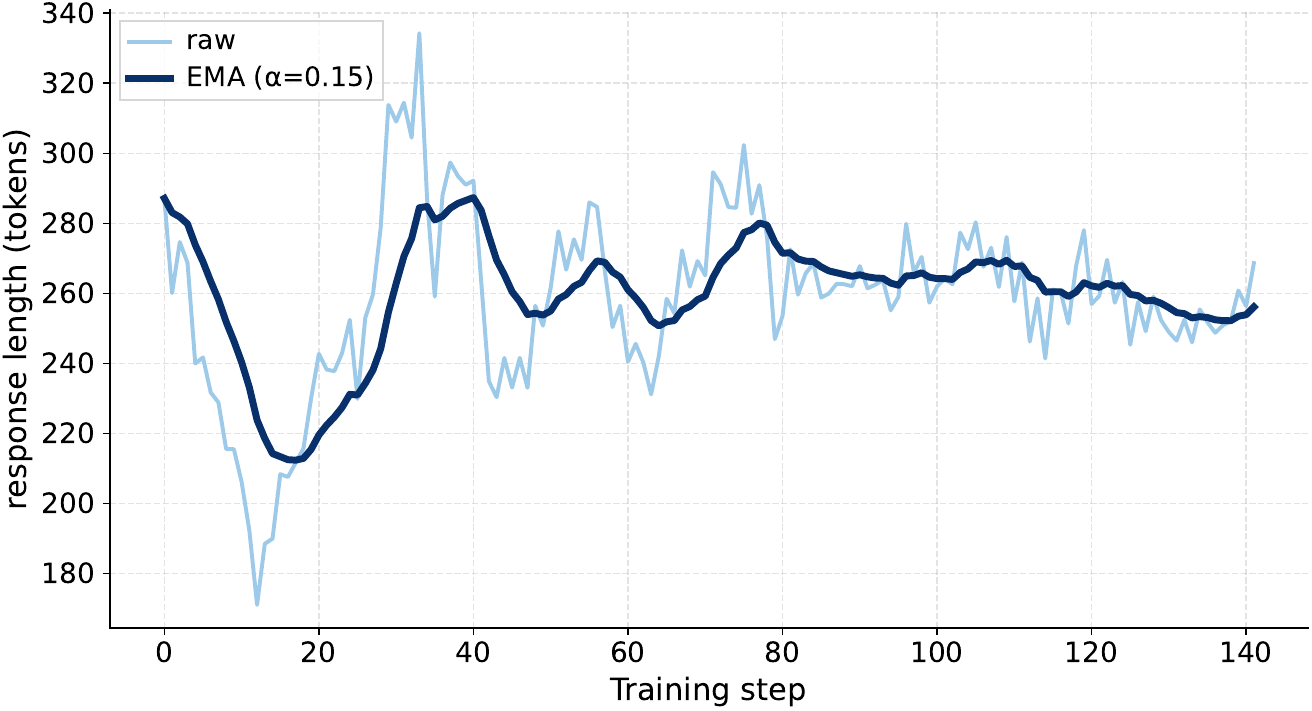
The reported DAPO curves show a steady rise in rollout raw reward, with the EMA moving from about $0.69$ at the beginning to above $0.82$ near the end and the maximum raw reward reaching $0.847$ at step $136$. Response length does not simply increase: it first drops to $171.065$ tokens at step $12$, then peaks at $334.324$ tokens around step $33$, and later stabilizes around $250$ to $270$ tokens. The authors interpret this as evidence that the policy improves quality without relying on unnecessarily long outputs.
Evaluation Setup and Main Results
The report evaluates four groups of tasks: general audio understanding, speech captioning, ASR, and timestamp-aware ASR. General audio understanding is measured on MMAU, MMAU-Pro, MMAR, and MMSU. Speech captioning uses a dedicated benchmark with $2,000$ speech samples and $13$ judged dimensions. ASR is reported as character error rate (CER), while timestamp ASR is reported as accumulated average shift (AAS), measured in milliseconds.
General audio understanding
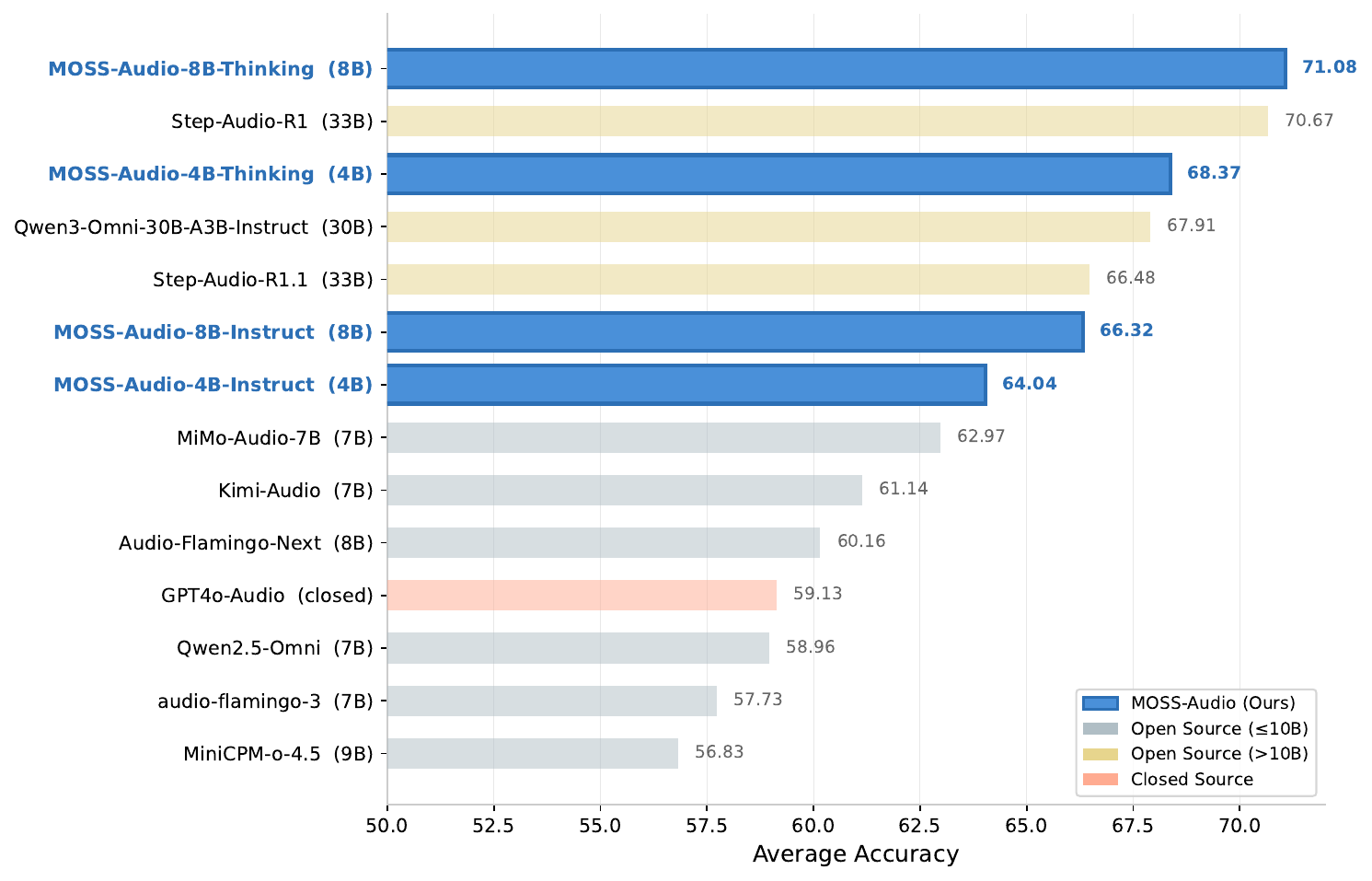
The general audio benchmark compares MOSS-Audio with both open-source and closed-source models. The key result is that MOSS-Audio-8B-Thinking achieves the best open-source average score, $71.08$, across the four benchmark tasks. The Thinking variants outperform the corresponding Instruct variants at both model scales, which is consistent with the paper’s claim that the reasoning-oriented branch is better suited for broad audio understanding.
| Model | Size | MMAU | MMAU-Pro | MMAR | MMSU | Avg |
|---|---|---|---|---|---|---|
| GPT4o-Audio | -- | 65.66 | 52.30 | 59.78 | 58.76 | 59.13 |
| Gemini-3-Pro | -- | 80.15 | 68.28 | 81.73 | 81.28 | 77.86 |
| Gemini-3.1-Pro | -- | 81.10 | 73.47 | 83.70 | 81.30 | 79.89 |
| Qwen3-Omni-30B-A3B-Instruct | 30B | 75.00 | 61.22 | 66.40 | 69.00 | 67.91 |
| Step-Audio-R1 | 33B | 78.67 | 59.68 | 69.15 | 75.18 | 70.67 |
| Step-Audio-R1.1 | 33B | 72.18 | 60.80 | 68.75 | 64.18 | 66.48 |
| MOSS-Audio-4B-Instruct | 4B | 75.79 | 58.16 | 62.54 | 59.68 | 64.04 |
| MOSS-Audio-4B-Thinking | 4B | 77.64 | 60.75 | 63.91 | 71.20 | 68.37 |
| MOSS-Audio-8B-Instruct | 8B | 77.03 | 57.48 | 64.42 | 66.36 | 66.32 |
| MOSS-Audio-8B-Thinking | 8B | 77.33 | 64.92 | 66.53 | 75.52 | 71.08 |
The paper’s main qualitative takeaway is that MOSS-Audio is the strongest open-source model on this suite, although the best proprietary systems still lead. The Thinking variants are consistently better than the Instruct variants on the broad open-ended benchmark, showing the value of the reasoning-oriented post-training branch.
Speech captioning
Speech captioning is evaluated on a custom benchmark with $2,000$ samples. Each sample is annotated along $13$ dimensions: gender, age, accent, pitch, volume, speed, texture, clarity, fluency, emotion, tone, personality, and summary. The model output is judged against human references by a text-based judge model, and the final score averages dimension-level matches across all samples.
| Model | Average speech-caption score |
|---|---|
| Audio-Flamingo-Next | 2.683 |
| Qwen3-Omni-Instruct | 3.599 |
| Qwen3-Omni-Thinking | 3.567 |
| Gemini-3-Pro | 3.376 |
| Gemini-3.1-Pro | 3.577 |
| MOSS-Audio-4B-Instruct | 3.711 |
| MOSS-Audio-8B-Instruct | 3.725 |
MOSS-Audio-8B-Instruct obtains the best overall score, while MOSS-Audio-4B-Instruct is extremely close. In the per-dimension breakdown, the 4B model is especially strong on gender, volume, texture, tone, and personality, while the 8B model leads on accent, pitch, clarity, fluency, and summary.
ASR
The ASR benchmark evaluates $12$ dimensions spanning health-condition speech, dialect, singing, non-speech vocalizations, code-switching, clean and noisy environments, whisper speech, far-field and near-field audio, multi-speaker audio, age-related subsets, and semantic-content subsets. Lower CER is better.
| Model | Average CER |
|---|---|
| Paraformer-Large | 15.77 |
| GLM-ASR-Nano | 17.29 |
| Fun-ASR-Nano | 12.04 |
| SenseVoice-Small | 14.50 |
| Kimi-Audio-7B-Instruct | 14.12 |
| Audio-Flamingo-Next | 30.19 |
| Qwen2.5-Omni-3B | 15.26 |
| Qwen2.5-Omni-7B | 15.05 |
| Qwen3-Omni-Instruct | 11.39 |
| MOSS-Audio-4B-Instruct | 11.58 |
| MOSS-Audio-8B-Instruct | 11.30 |
MOSS-Audio-8B-Instruct achieves the best overall CER in this benchmark, narrowly outperforming Qwen3-Omni-Instruct and MOSS-Audio-4B-Instruct. The paper highlights that MOSS-Audio preserves strong transcription accuracy while retaining broader audio-language capability.
The appendix provides a more detailed dataset-level ASR table over $38$ speech test sets. Those results show that MOSS Audio Encoder paired with Qwen3-1.7B reduces the average CER/WER from $17.61\%$ to $16.31\%$ versus the AuT baseline, and is better on $36$ of the $38$ datasets. The largest gains are reported for whispered speech, singing voice, and severe stammering.
Timestamp ASR
Timestamp ASR is measured with accumulated average shift, defined as
$$ \mathrm{AAS} = \frac{1}{N} \sum_{i=1}^{N} \lvert \hat{t}_i - t_i \rvert, $$
where $N$ is the number of timestamp slots, $\hat{t}_i$ is the predicted timestamp, and $t_i$ is the reference timestamp. Lower AAS indicates better temporal alignment. The benchmark is built from the official AISHELL-1 and LibriSpeech test sets, with CTC alignment used to create word-level timestamp references.
| Model | AISHELL-1 (zh) | LibriSpeech (en) |
|---|---|---|
| Audio-Flamingo-Next | -- | 211.15 |
| Qwen3-Omni-Instruct | 833.66 | 646.95 |
| Gemini-3.1-Pro | 708.24 | 871.19 |
| MOSS-Audio-4B-Instruct | 76.96 | 358.13 |
| MOSS-Audio-8B-Instruct | 35.77 | 131.61 |
MOSS-Audio-8B-Instruct is the strongest timestamp ASR system among the reported models, with a particularly large improvement over the general omni-model baselines. This is the clearest evidence in the report that the explicit time-marker design improves not only transcription quality but also the placement of content in time.
Ablations and Detailed Analysis
Audio encoder capability
The appendix studies the audio encoder in isolation using the XARES-LLM framework. Two tracks are evaluated: Task 1 covers audio understanding across $15$ benchmarks, and Task 2 covers generative tasks including ASR and captioning. The comparison is against Whisper-large-v3 and the AuT encoder used in Qwen3-Omni.
| Encoder | Task 1 AVG$_1$ | Task 2 AVG$_2$ |
|---|---|---|
| Whisper-large-v3 | 0.743 | 0.492 |
| AuT | 0.809 | 0.661 |
| MOSS Audio Encoder | 0.760 | 0.673 |
The Task 1 result is mixed: MOSS Audio Encoder is not uniformly dominant on the overall average, but it does win on several harder datasets such as ASVspoof, ESC-50, FSD50k, and VoxCeleb1. On Task 2, the encoder is clearly the strongest, especially for speech transcription and captioning, which supports the paper’s claim that the pretraining strategy preserves rich acoustic information for generation.
In-depth ASR capability analysis
To probe the speech-recognition ceiling more carefully, the authors pair the MOSS Audio Encoder and the AuT baseline with a Qwen3-1.7B language model and pretrain both for $100$k steps on the same data. Across $38$ speech test sets, the MOSS encoder reduces the average CER/WER from $17.61\%$ to $16.31\%$. The most dramatic gains are reported on whispered speech, singing voice, and severe stammering, which is consistent with the claim that the encoder better preserves difficult acoustic detail.
- Whispered speech: $12.45\% \rightarrow 7.87\%$ on AISHELL6-Whisper;
- Singing voice: $4.91\% \rightarrow 3.43\%$ on Opencpop;
- Severe stammering: $17.31\% \rightarrow 14.99\%$ on AISHELL-6A severe.
The appendix states that the MOSS encoder wins on $36$ of the $38$ datasets, which is strong evidence that the encoder itself is materially better suited to broad speech recognition than the baseline AuT front end.
DeepStack ablation
The DeepStack ablation uses the MOSS Audio Encoder with a lightweight Qwen3-0.6B-base language model. The baseline consumes only the final encoder layer, while the proposed variant injects intermediate layers. Both models use the same two-stage training pipeline: ASR alignment first, then fine-tuning on MECAT-Caption.
| Method | Overall DATE | Speech pure | Speech mixed | Music pure | Music mixed | Pure sound | Mixed sound | Environment |
|---|---|---|---|---|---|---|---|---|
| Baseline | 0.4823 | 0.4861 | 0.4922 | 0.4705 | 0.2800 | 0.4015 | 0.1936 | 0.1586 |
| DeepStack | 0.4831 | 0.4791 | 0.4838 | 0.4927 | 0.2844 | 0.4255 | 0.1938 | 0.1594 |
The result is nuanced but informative. DeepStack slightly improves the overall DATE score and improves all non-speech categories, but it slightly degrades the speech-dominated settings. The paper interprets this as evidence that the final encoder layer becomes highly specialized for speech semantics after ASR alignment, while intermediate features rescue low-level acoustic, timbral, and environmental cues.
Limitations, Scope, and Takeaways
The report does not include a dedicated limitations section. The most visible scope boundaries are empirical rather than explicitly framed as limitations: closed-source systems still outperform MOSS-Audio on some benchmark aggregates, and the DeepStack ablation shows a small speech-focused trade-off even as it improves non-speech acoustic categories. The audio encoder ablation is also mixed on the general audio understanding track, which suggests that the benefits of the representation are task-dependent rather than universally dominant.
At the same time, the paper’s overall message is strong and internally consistent. MOSS-Audio combines a purpose-built audio encoder, cross-layer feature injection, explicit time markers, a carefully structured annotation pipeline, and staged post-training to produce a single model family that covers descriptive understanding, transcription, temporal grounding, and reasoning over heterogeneous audio. The strongest reported variants are MOSS-Audio-8B-Thinking for broad general audio understanding and MOSS-Audio-8B-Instruct for speech captioning, ASR, and timestamp ASR. The authors therefore present MOSS-Audio as a promising foundation for future voice agents that need audio perception, temporal grounding, and reasoning in one model stack.
Code & Implementation
This repository contains the full code implementation for MOSS-Audio, the unified audio-language model described in the paper. The codebase is primarily written in Python and organized into source modules under src/ along with fine-tuning scripts under finetune/.
The key model components outlined in the paper map directly to modules in the source code:
- Audio Encoder: Implemented in
src/modeling_moss_audio.pyas theMossAudioEncoderclass. This module contains convolutional layers and Whisper transformer layers to extract multi-layer acoustic features with deepstack cross-layer injections, consistent with the paper's description. - Modality Adapter and Language Model Integration: Also managed within
src/modeling_moss_audio.pythrough interactions with large language model backbones (e.g., Qwen3), supporting the cross-modal projection and autoregressive text generation described. - Fine-tuning and Training: The
finetune/finetune.pyscript provides functionality for supervised fine-tuning of the MOSS-Audio model using LoRA or full-parameter updates. It handles audio feature extraction, input construction, and training loop management consistent with task-specific data formats.
Additional supporting code such as configuration definitions, audio processing utilities, and inference wrappers are organized under src/. The README includes usage examples and links to pretrained model weights for inference or fine-tuning.
Overall, the repository delivers a comprehensive, modular implementation of the MOSS-Audio system integrating audio encoding, temporal feature injection, and large language model conditioning to enable unified audio understanding and generation tasks as presented in the paper.