ST-DRC
Spatial-Temporal Decoupled Reference Conditioning for Identity-Preserving Text-to-Video Generation

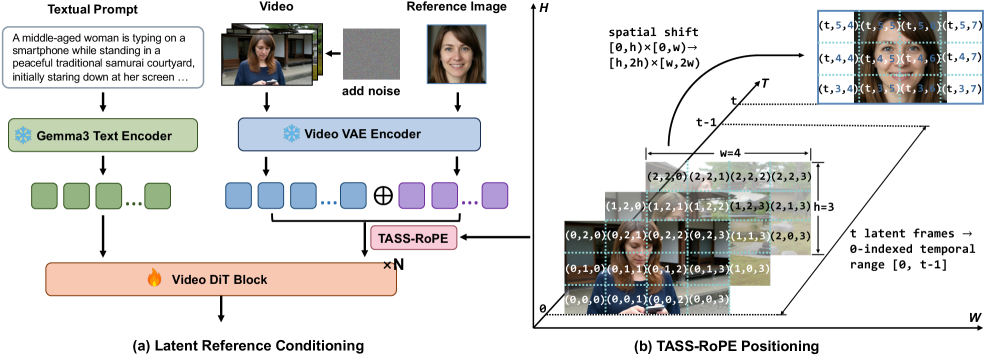
ST-DRC is a spatial-temporal decoupled reference conditioning method for identity-preserving text-to-video generation. It encodes the reference as latent memory and separates spatial-temporal cues to balance text adherence with facial identity preservation, avoiding common copy-paste artifacts.
Demos
The demos showcase ST-DRC's ability to generate videos that maintain a reference face's identity while following textual prompts for actions and scenes. Watch for consistent identity preservation across frames and how well the video content reflects the prompt without pixel-level copying. The method overview explains the spatial-temporal decoupled conditioning enabling this quality.

Links
Paper & demos
Code & resources
Impact
Abstract
Identity-preserving video generation (IPVG) aims to synthesize high-fidelity videos that follow text prompts while faithfully preserving a reference identity. Despite recent progress, existing IPVG methods still struggle to balance high-level semantic control and low-level identity fidelity. To bridge this gap, we propose ST-DRC, an effective Spatial-Temporal Decoupled Reference Conditioning framework for identity-preserving text-to-video generation. At the framework level, ST-DRC performs latent in-context feature injection by encoding the reference image with the video VAE and concatenating it with noisy video latents, enabling rich low-level identity details to be accessed without additional adapters. To separate identity-aware reference retrieval from appearance copying, we introduce TASS-RoPE, a Temporal-Adjacent Spatial-Shifted RoPE scheme that places reference tokens near the video sequence in time but shifts them in space, allowing reference information to flow through spatio-temporal attention while suppressing pixel-level copy-paste shortcuts. To further prevent shortcut learning and strengthen the otherwise diluted identity supervision in the diffusion objective, we combine appearance-invariant reference augmentation with face-guided identity objectives, encouraging the model to preserve identity under variations in color, pose, and layout. At inference time, we introduce a three-stream reference classifier-free guidance strategy that independently controls text adherence and reference fidelity. Experiments demonstrate that ST-DRC achieves strong identity preservation, prompt alignment, temporal consistency, and video quality with a lightweight design built on LTX-2.3. Our method ranks among the top submissions in the facial identity-preserving video generation track, validating the effectiveness of spatial-temporal decoupled reference conditioning.
Introduction
Identity-preserving text-to-video generation (IPVG) asks a generative model to satisfy two requirements at once: the video must follow a text prompt, and it must preserve the identity of a reference subject over time. The paper argues that these goals are still in tension for existing IPVG methods. Methods that compress the reference into a semantic embedding can be robust for global control but may lose fine-grained facial details. Methods that inject the reference in latent space keep richer spatial information, but they often entangle identity with nuisance appearance factors such as pose, illumination, background, and layout, leading to copy-paste artifacts and weaker prompt following.
To address this, the paper proposes ST-DRC (Spatial-Temporal Decoupled Reference Conditioning), built on the video branch of LTX-2.3. The core idea is to treat the reference image as a non-decoded latent memory inside the video model itself, rather than as an external identity encoder output or a decoded frame. ST-DRC then decouples where reference information is placed in spatio-temporal coordinates from what the model should learn from it, with additional training-time robustness and inference-time guidance to balance identity fidelity against prompt adherence.

At a high level, the method combines four elements:
- latent in-context reference injection through the same video VAE latent space as the noisy video;
- a spatial-temporal positional scheme called TASS-RoPE that keeps reference tokens temporally adjacent but spatially shifted;
- reference-robust training via appearance-invariant augmentation and face-guided identity losses;
- three-stream decoupled classifier-free guidance at inference for independent control of text adherence and reference fidelity.
The paper’s empirical story is that these pieces are complementary: reference concatenation gives the model access to low-level identity details, TASS-RoPE discourages pixel-level copy shortcuts, augmentation removes nuisance appearance cues, the auxiliary identity loss strengthens face-level supervision that is otherwise diluted by the global diffusion objective, and the decoupled guidance lets users tune the text/reference trade-off at inference.
Problem Setting and Design Goals
ST-DRC is designed for facial IPVG. The input is a reference image $I_{\mathrm{ref}}$ and a text prompt $y$, and the goal is to generate a video whose motion, scene, and style follow the prompt while the depicted identity remains consistent with the reference. The paper emphasizes two coupled challenges:
- High-level prompt controllability: the model should respond to action, scene, and temporal instructions from text.
- Low-level identity fidelity: the model should preserve identity-bearing facial details without copying irrelevant appearance factors.
The authors position their method as a middle ground between semantic reference injection and latent reference injection. ST-DRC follows the latent route, but adds explicit spatial-temporal decoupling so that latent reference conditioning behaves more like memory retrieval than frame copying.
Method Overview
ST-DRC operates on noisy video latents $z_t$ and a reference image $I_{\mathrm{ref}}$. The reference image is encoded with the same video VAE used for the video branch:
$$z_{\mathrm{ref}} = E_{\mathrm{vae}}(I_{\mathrm{ref}}).$$
The noisy video latent and the reference latent are concatenated along the temporal axis:
$$\tilde z_t = [z_t, z_{\mathrm{ref}}],$$
with $\tilde z_t \in \mathbb{R}^{(T+1) \times H \times W \times C}$. The output corresponding to the reference token stream is discarded, so the reference is not decoded into a video frame and is not directly included in the training loss. The paper describes this as a non-decoded identity memory that the Video DiT can access through native spatio-temporal attention.
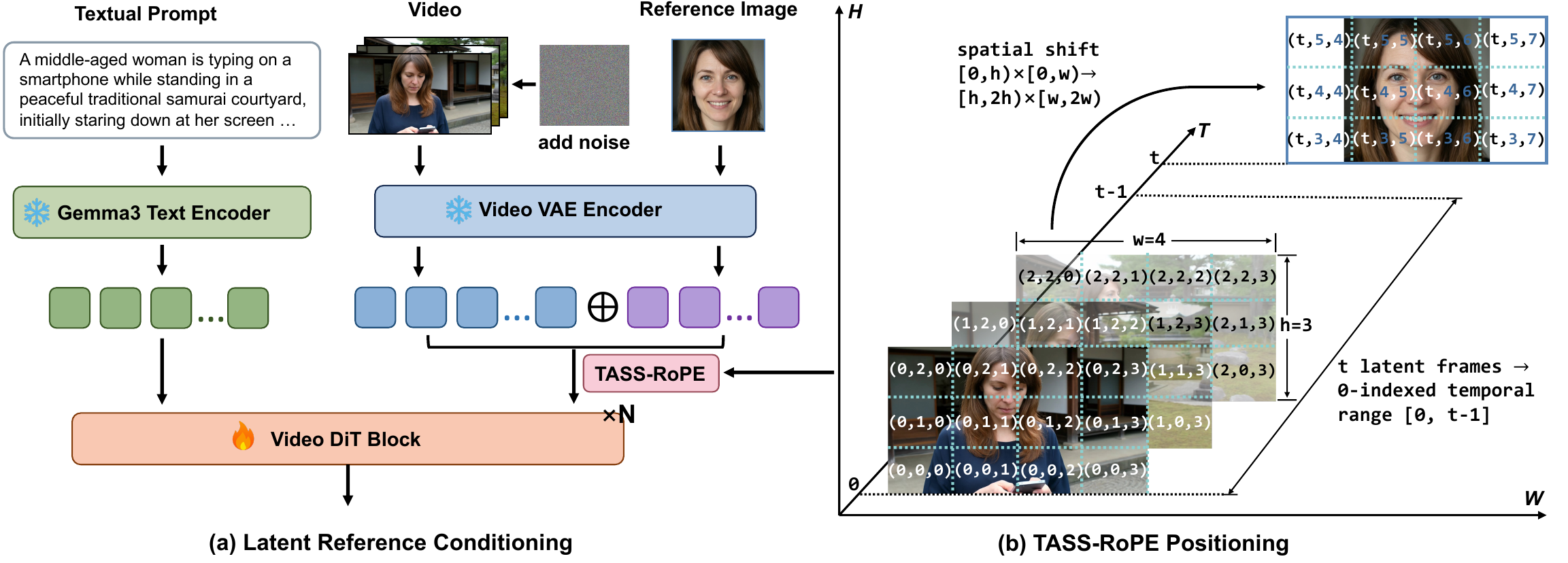
Because the model uses 3D RoPE in attention, the reference tokens also need explicit spatio-temporal coordinates. The design is:
$$p_v(t,i,j) = (t,i,j), \quad t=0,\ldots,T-1,$$
for video tokens, and
$$p_r(i,j) = (T, H+i, W+j)$$
for reference tokens. The paper calls this Temporal-Adjacent Spatial-Shifted RoPE (TASS-RoPE). The temporal index $T$ places the reference just outside the video sequence, so it is temporally close but does not overlap with any true video frame. The spatial shift moves the reference into a separate coordinate block $[H,2H) \times [W,2W)$, preserving the reference’s internal geometry while preventing shared coordinates with video tokens. The intended effect is to preserve reference retrieval through attention while suppressing direct spatial copy-paste.
1. Latent In-Context Reference Injection
The first contribution is to represent the reference portrait in the same latent space as the video, rather than compressing it into a face embedding or decoding it as a frame. This gives the model access to richer low-level visual details through its own attention mechanism. The paper notes that this avoids the need for additional adapters and stays aligned with the native latent representation of LTX-2.3’s video branch.
2. Temporal-Adjacent Spatial-Shifted RoPE
TASS-RoPE is the key mechanism that decouples identity retrieval from appearance copying. The temporal coordinate is chosen as the nearest out-of-frame position $T$ rather than a fixed large index. The paper gives two reasons: it avoids collision with actual frames and keeps the reference temporally close, while a large offset would weaken attention because RoPE tends to decay with distance. The spatial shift retains the relative layout inside the reference image but moves the entire latent away from the video’s coordinate grid, reducing coordinate-aligned shortcuts.
3. Reference-Robust Identity Enhancement
The authors argue that latent conditioning alone is still vulnerable to appearance leakage, so they add two training strategies.
Image-level reference augmentation. During training, the reference image is randomly augmented before VAE encoding using identity-preserving geometric and photometric transforms. The paper explicitly lists horizontal flipping, slight rotation, mild spatial cropping, and color jittering. At inference time, augmentation is disabled and the original reference is used. This makes nuisance appearance factors unreliable and encourages the model to learn identity features that survive perturbations.
Face-guided auxiliary identity loss. The main flow-matching objective supervises all video tokens, so identity signals from the face can be diluted. To add an explicit identity constraint, the model estimates a clean latent from the noisy latent and predicted velocity:
$$\hat z_0 = z_t - t \hat v_\theta(\tilde z_t, t, y).$$
The estimated latent is decoded with the frozen VAE decoder, face boxes are detected with InsightFace, and aligned crops are encoded by a frozen ArcFace model $\Phi$. Let $e_f$ denote the generated face embedding in frame $f$ and $e_{\mathrm{ref}}$ the reference embedding from the original unaugmented image. The identity loss is the masked cosine distance
$$\mathcal{L}_{\mathrm{id}} = \frac{\sum_{f \in \mathcal{F}} m_f \left(1 - \cos(e_f,e_{\mathrm{ref}})\right)}{\sum_{f \in \mathcal{F}} m_f + \epsilon},$$
where $m_f$ indicates whether a valid face is detected in frame $f$. The paper also adds a temporal identity consistency term that pulls per-frame embeddings toward their masked mean:
$$\bar e = \frac{\sum_{f \in \mathcal{F}} m_f e_f}{\sum_{f \in \mathcal{F}} m_f + \epsilon},$$
$$\mathcal{L}_{\mathrm{tic}} = \frac{\sum_{f \in \mathcal{F}} m_f \left(1 - \cos(e_f,\bar e)\right)}{\sum_{f \in \mathcal{F}} m_f + \epsilon}.$$
The total training loss is
$$\mathcal{L} = \mathcal{L}_{\mathrm{flow}} + w_{\mathrm{aux}}(t)\left(\lambda_{\mathrm{id}}\mathcal{L}_{\mathrm{id}} + \lambda_{\mathrm{tic}}\mathcal{L}_{\mathrm{tic}}\right),$$
with the auxiliary weight defined from an SNR-like term for rectified flow interpolation $z_t = (1-t)z_0 + t\epsilon$:
$$\mathrm{SNR}(t) = \left(\frac{1-t}{t+\epsilon}\right)^2, \qquad w_{\mathrm{aux}}(t) = \left(\frac{\mathrm{SNR}(t)}{\mathrm{SNR}(t)+1}\right)^\gamma.$$
The paper uses $\lambda_{\mathrm{id}} = 0.1$, $\lambda_{\mathrm{tic}} = 0.05$, and $\gamma = 1.0$. The intent is to emphasize the auxiliary identity signal at low-noise timesteps where the clean-latent estimate is more reliable.
4. Decoupled Text-Reference Guidance
At inference time, ST-DRC uses a three-stream classifier-free guidance scheme that explicitly separates text adherence from reference fidelity. The model predicts three velocities per denoising step: unconditional $\hat v_{\emptyset}$, text-only $\hat v_y$, and text-reference $\hat v_{y,r}$. The guided velocity is
$$\hat v_{\mathrm{cfg}} = \hat v_{\emptyset} + s_y\left(\hat v_y - \hat v_{\emptyset}\right) + s_r\left(\hat v_{y,r} - \hat v_y\right).$$
This decomposes the guidance direction into a text component and a reference component, so the two can be tuned independently. The paper reports using $s_y = 5.0$ and $s_r = 7.5$ unless otherwise stated. To support the three-stream setup, training uses independent condition dropout with probabilities $p_y = 0.05$ for text and $p_r = 0.20$ for reference.
Implementation Details
ST-DRC is built by fully fine-tuning the video branch of LTX-2.3 on VIP-200K. The audio branch is not used because the paper’s setting does not involve audio input or output. Training runs for 20K optimization steps with batch size 32 on H20 GPUs, using AdamW with learning rate $5 \times 10^{-5}$.
The reported hyperparameters for the auxiliary losses are $\lambda_{\mathrm{id}} = 0.1$, $\lambda_{\mathrm{tic}} = 0.05$, and $\gamma = 1.0$. For inference guidance, the default strengths are $s_y = 5.0$ and $s_r = 7.5$.
Evaluation Setup
The paper evaluates along three axes:
- Identity preservation via FaceSim-Arc and FaceSim-Cur, which measure facial similarity between generated frames and the reference image.
- Prompt alignment via CLIP-Score.
- Video quality via AQ, IQ, MS, and DD, following the VBench-style quality breakdown.
Specifically, AQ refers to aesthetic quality, IQ to imaging quality, MS to motion smoothness, and DD to dynamic degree. The metrics are reported on the VIP-200K test set.
Quantitative Results
The paper compares ST-DRC against representative IPVG and subject-to-video baselines, including ConsisID, Phantom, VACE, and IPVG-STD. The central conclusion is that ST-DRC achieves the best identity preservation while also improving prompt alignment and most quality metrics, giving the best overall balance.
| Method | FaceSim-Arc ↑ | FaceSim-Cur ↑ | CLIP-Score ↑ | AQ ↑ | IQ ↑ | MS ↑ | DD ↑ |
|---|---|---|---|---|---|---|---|
| ConsisID | 0.566 | 0.593 | 31.47 | 0.526 | 0.670 | 0.982 | 0.51 |
| Phantom | 0.537 | 0.627 | 31.55 | 0.532 | 0.668 | 0.982 | 0.87 |
| VACE | 0.423 | 0.444 | 32.61 | 0.564 | 0.688 | 0.986 | 0.71 |
| IPVG-STD | 0.492 | 0.519 | 31.82 | 0.561 | 0.683 | 0.986 | 0.88 |
| ST-DRC | 0.631 | 0.671 | 33.04 | 0.576 | 0.682 | 0.992 | 0.93 |
Relative to the strongest identity-oriented baselines, ST-DRC improves FaceSim-Arc/Cur from 0.566/0.593 for ConsisID and 0.537/0.627 for Phantom to 0.631/0.671. It also achieves the highest CLIP-Score, indicating better adherence to the input prompt. For video quality, ST-DRC reports the best AQ, MS, and DD, while maintaining competitive IQ. VACE has the highest IQ at 0.688, but its identity similarity is substantially weaker, which the paper uses to argue that frame-level quality alone is insufficient for facial IPVG.
Qualitative Analysis
The qualitative comparison on VIP-200K supports the quantitative trend. The paper reports that ConsisID exhibits severe copy-paste artifacts and visible visual artifacts, Phantom shows lower visual quality and weaker temporal identity consistency, VACE produces plausible videos but with weaker identity similarity, and IPVG-STD still transfers non-face environmental details from the reference into the output. In contrast, ST-DRC preserves the target identity more faithfully while remaining prompt-consistent and visually coherent.

Ablation Study
The paper performs cumulative ablations to isolate five design choices: reference concatenation, TASS-RoPE, reference augmentation, auxiliary identity loss, and decoupled CFG. These experiments are useful because they show that each component contributes differently to the final balance of identity, prompt alignment, and quality.
| Variant | Ref. concat | TASS | Aug. | ID loss | CFG | FaceSim-Arc ↑ | FaceSim-Cur ↑ | CLIP-Score ↑ | AQ ↑ | IQ ↑ | MS ↑ | DD ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LTX-2.3-Base | No | No | No | No | No | 0.284 | 0.317 | 32.18 | 0.558 | 0.681 | 0.985 | 0.87 |
| + Ref. Concat. | Yes | No | No | No | No | 0.541 | 0.579 | 31.76 | 0.548 | 0.674 | 0.961 | 0.83 |
| + TASS-RoPE | Yes | Yes | No | No | No | 0.573 | 0.612 | 31.94 | 0.555 | 0.677 | 0.972 | 0.86 |
| + Ref. Aug. | Yes | Yes | Yes | No | No | 0.592 | 0.631 | 32.12 | 0.563 | 0.679 | 0.979 | 0.89 |
| + Aux. ID Loss | Yes | Yes | Yes | Yes | No | 0.618 | 0.658 | 32.28 | 0.568 | 0.680 | 0.986 | 0.88 |
| + Decoupled CFG | Yes | Yes | Yes | Yes | Yes | 0.631 | 0.671 | 33.04 | 0.576 | 0.682 | 0.992 | 0.93 |
The progression is informative. Starting from the LTX-2.3 base model, adding reference concatenation drastically improves identity similarity, but also causes some quality degradation and lower prompt alignment, consistent with the appearance-entanglement argument. TASS-RoPE recovers better identity retrieval while reducing direct copying. Reference augmentation improves robustness against pose, color, and background shortcuts. The auxiliary identity loss gives another clear step up in FaceSim scores and stabilizes identity across frames. Finally, decoupled CFG produces the best final trade-off, especially for prompt alignment and overall quality.
One useful observation from the ablation table is that not every component improves every metric monotonically. For example, reference concatenation alone reduces CLIP-Score and some quality indicators compared with the base model, which supports the paper’s claim that naive latent reference injection can be too entangled. The full system is needed to convert the latent memory from a copying shortcut into a controllable identity signal.
What the Paper Claims as Its Main Contributions
- A unified latent reference conditioning framework that uses the video VAE to encode the reference image directly into the latent token stream, avoiding extra identity encoders or per-subject tuning.
- TASS-RoPE, a temporal-adjacent and spatial-shifted positional scheme that keeps reference tokens reachable by attention while discouraging spatial copy-paste.
- A training recipe that combines appearance-invariant reference augmentation with face-guided identity supervision to reduce nuisance leakage and improve identity learning.
- A three-stream decoupled classifier-free guidance strategy that independently controls prompt adherence and reference fidelity during inference.
Limitations and Scope
The paper does not include a separate limitations section, so the following points are best understood as scope boundaries stated or implied by the reported setup rather than as formal limitations claims.
- The evaluation is reported on VIP-200K, with the paper emphasizing facial identity-preserving video generation rather than broader subject categories such as objects or animals.
- The implementation is built on the video branch of LTX-2.3; the audio branch is not used.
- The auxiliary identity loss relies on face detection and face alignment, so the training signal is explicitly face-centric.
- The method is presented as lightweight and non-adapter-based, but it still requires full fine-tuning of the video branch on the target dataset.
Conclusion
ST-DRC reframes identity-preserving video generation as a problem of spatial-temporal reference conditioning. Its main technical contribution is not simply injecting more reference information, but structuring that information so the model can retrieve identity details without being encouraged to copy nuisance appearance. The combination of latent in-context reference memory, TASS-RoPE, robustness-oriented augmentation, face-guided supervision, and decoupled inference guidance yields strong identity preservation, improved prompt adherence, and competitive video quality on VIP-200K. In the paper’s experiments, the full system outperforms the compared baselines on identity similarity and most quality measures, making a strong case for spatial-temporal decoupling as a practical design principle for facial IPVG.
Code & Implementation
The current repository serves as a placeholder for the implementation of Spatial-Temporal Decoupled Reference Conditioning for Identity-Preserving Text-to-Video Generation (ST-DRC). As of now, the repository includes only the project README and visual assets illustrating the method and results, but does not contain any source code for training or inference.
The README clearly outlines the methodology, describing the spatial-temporal decoupled reference conditioning framework, the TASS-RoPE scheme, and identity enhancement techniques introduced in the paper. Additionally, it notes that the authors plan to release the inference code, training code, and model checkpoints in due course, following their stated timeline.
In summary, this repository is in preparation stages and will be updated with the full code and models. For now, users interested in the work can refer to the paper and project page linked in the README for detailed descriptions and results.