HumanNOVA
HumanNOVA: Photorealistic, Universal and Rapid 3D Human Avatar Modeling from a Single Image
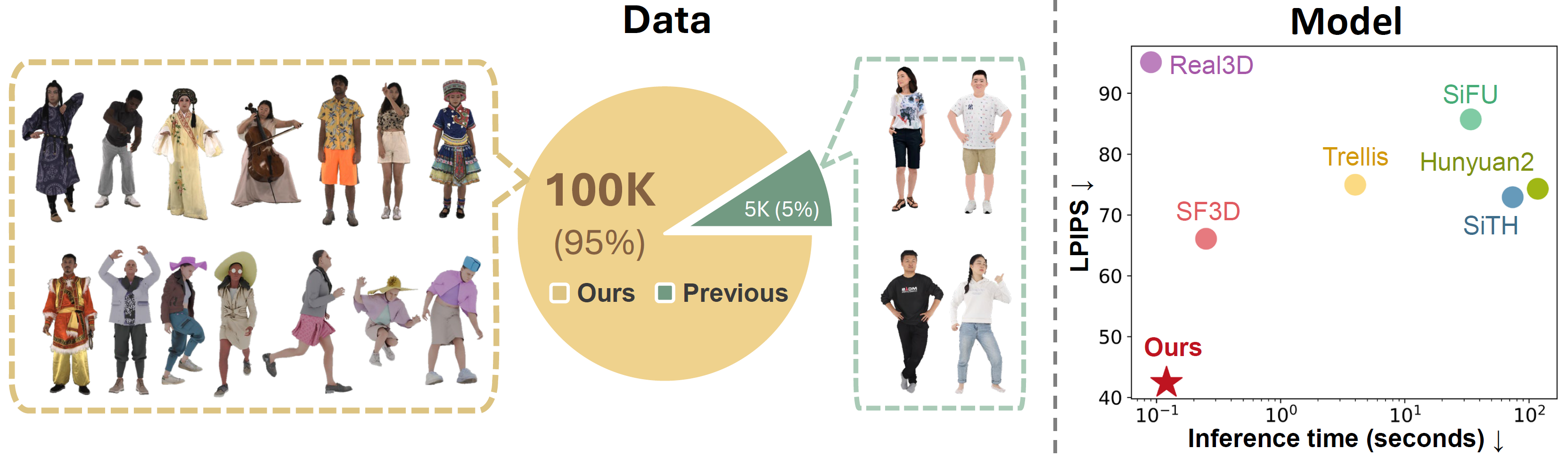
HumanNOVA is a photorealistic, universal, and rapid method for creating 3D human avatars from a single image without test-time optimization. It uses large-scale synthetic and real training data plus token-conditioned feed-forward modeling, enabling fast and robust 3D human reconstructions in diverse conditions.
Demos
These demos showcase HumanNOVA's rapid, photorealistic 3D human avatar modeling from a single image without requiring test-time tuning. Watch for the detailed texture quality, accurate geometry, and robustness to diverse poses and viewpoints, demonstrating superior synthesis from the feed-forward, token-conditioned framework enabled by large-scale training data.
Links
Paper & demos
Abstract
In this paper, we present HumanNOVA, a photorealistic, universal, and rapid model for generating 3D human avatars from a single RGB image. Achieving both photorealism and generalization is challenging due to the scarcity of diverse, high-quality 3D human data. To address this, we build a scalable data generation pipeline that follows two strategies. The first one is to leverage existing rigged assets and animate them with extensive poses from daily life. The second strategy is to utilize existing multi-camera captures of humans and employ fitting to generate more diverse views for training. These two strategies enable us to scale up to 100k assets, significantly enhancing both the quantity and the diversity of data for robust model training. In terms of the architecture, HumanNOVA adopts a feed-forward, token-conditioned avatar modeling framework that allows fast inference in less than one second and requires no test-time optimization. Given an input image and an estimated simplified human mesh (SMPL) without detailed geometry or appearance, the model first encodes both inputs into compact token representations. These tokens then act as conditioning signals and are fused through cross-attention to construct a triplane-based 3D avatar representation. Extensive experiments on multiple benchmarks demonstrate the superiority of our approach, both quantitatively and qualitatively, as well as its robustness under diverse input image conditions. Project page at https://HumanNOVA.github.io .
1. Problem Setting and Main Idea
HumanNOVA addresses single-image 3D human avatar reconstruction, with the explicit goals of being photorealistic, universal, and rapid. The task is ill-posed because an image only reveals one side of the person, yet the model must infer hidden geometry, clothing, and texture. The paper argues that prior human-avatar methods often rely on per-instance optimization, diffusion-based hallucination, or multi-stage pipelines that are too slow for interactive use. HumanNOVA instead follows the feed-forward large reconstruction model paradigm and aims to recover a complete avatar in less than one second, with no test-time optimization.
The core observation is that scaling data and injecting human-specific priors can move large reconstruction models from general objects to humans. HumanNOVA combines an input RGB image with an estimated simplified human mesh, specifically an SMPL mesh predicted by an off-the-shelf estimator, and maps these conditions to a triplane representation that is decoded into a 3D avatar.
2. Why This Problem Is Hard
The paper highlights two bottlenecks for human-oriented large reconstruction models. First, high-quality 3D human training data is scarce relative to general 3D object datasets such as Objaverse. Second, generic large reconstruction architectures are not built with human priors, even though humans have strong structure, pose, and clothing regularities that should be exploited. HumanNOVA therefore treats both data and architecture as necessary ingredients.
The intended use cases include virtual reality, telepresence, and human-computer interaction, where fast reconstruction and realistic rendering matter. The authors also explicitly note the task is difficult under in-the-wild inputs, unusual viewpoints, occlusions, and challenging garments such as dresses and overalls.
3. Overview of the HumanNOVA Pipeline
HumanNOVA follows a single feed-forward reconstruction pipeline with three major stages: multi-modal encoding, 2D-to-3D mapping, and rendering. The model consumes an RGB image $I \in \mathbb{R}^{H \times W \times 3}$ and an estimated SMPL mesh. The image is tokenized with DINOv2 into visual tokens, and the mesh is tokenized with PTv3 into mesh tokens. These token sets are fused by a mapping network into a triplane $\mathbf{T} \in \mathbb{R}^{3hw \times d}$, from which images can be rendered by standard ray marching at any target viewpoint.
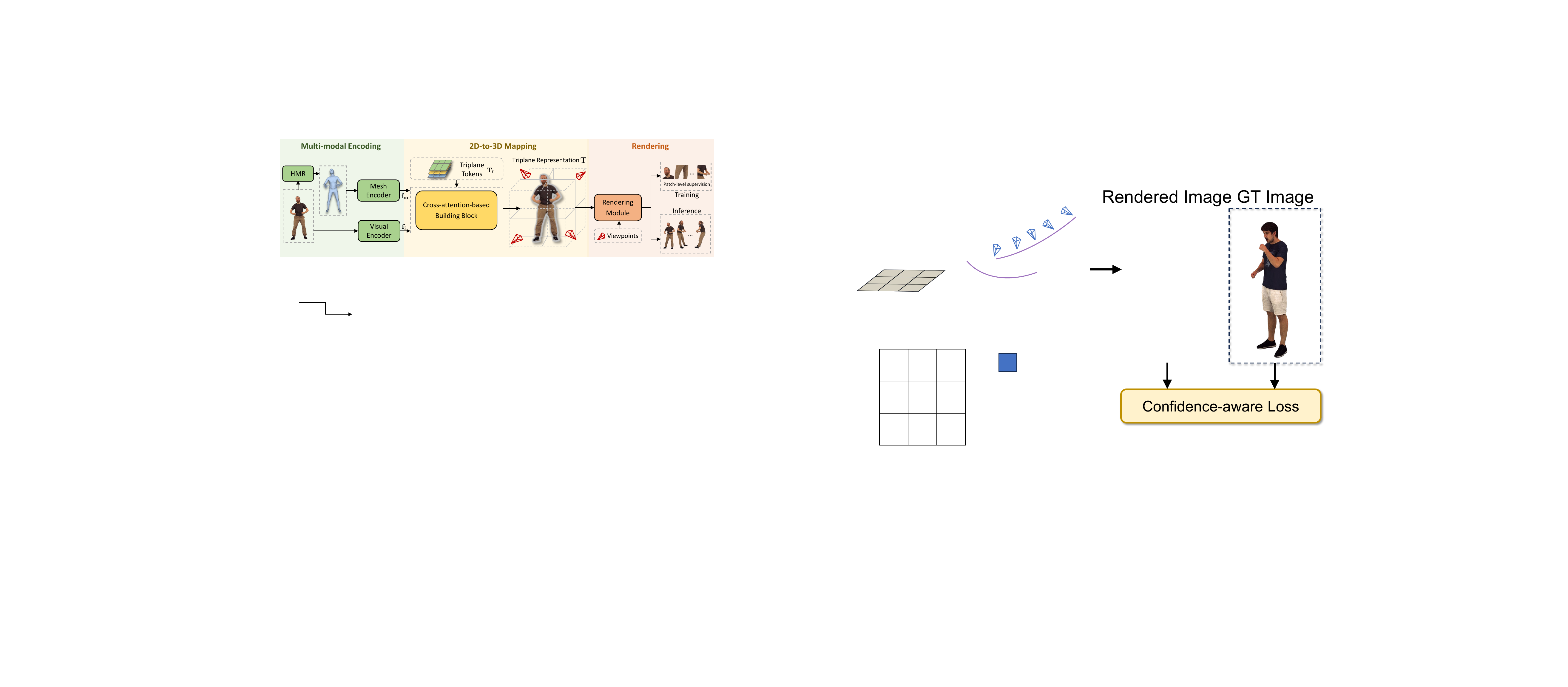
3.1 Multi-modal tokenization
The image encoder is DINOv2, which converts the input image into feature tokens $\mathbf{f}_i \in \mathbb{R}^{N_i \times d}$. The mesh prior comes from an estimated SMPL body surface, tokenized by PTv3 into mesh tokens $\mathbf{f}_m \in \mathbb{R}^{N_m \times d}$. The mesh is described as a coarse but robust human shape and pose prior rather than detailed geometry or appearance.
The paper emphasizes that this prior is helpful but not brittle: it improves structural reconstruction, yet the system can still lean on appearance cues when the mesh estimate is imperfect.
3.2 Mapping tokens to a triplane
The mapping module is based on PointInfinity-style transformer blocks and is inspired by SF3D. It updates a learnable triplane token set through cross-attention between the condition tokens and the triplane tokens. In each block, the paper describes a three-step fusion/refinement process:
$$ \mathbf{L}^l = \operatorname{CrossAttn}(\text{q} = \mathbf{f}_i \| \mathbf{f}_m,\, \text{kv} = \mathbf{T}^l), $$ $$ \mathbf{L}^l = \operatorname{CrossAttn}(\text{q} = \mathbf{L}^l,\, \text{kv} = \mathbf{f}_i \| \mathbf{f}_m), $$ $$ \mathbf{T}^{l+1} = \operatorname{CrossAttn}(\text{q} = \mathbf{T}^l,\, \text{kv} = \mathbf{L}^l). $$
Conceptually, the condition tokens query the current triplane, the resulting latent is refined by querying the conditions again, and then the triplane is updated from that refined latent. This design lets the model directly lift 2D appearance and coarse body structure into a 3D latent volume.
3.3 Triplane rendering
After mapping, the triplane is rendered with the standard ray-marching procedure used by large reconstruction models. Given a target camera viewpoint $\Phi$, the renderer produces an image $\hat{I}_\Phi = \pi(\mathbf{T}, \Phi)$. The paper uses a NeRF-style MLP decoder for volumetric rendering, with 10 layers, width 60, SiLU activations, and 128 samples per ray.
3.4 Training losses
HumanNOVA is trained with a weighted sum of RGB reconstruction loss, mask loss, and LPIPS loss:
$$ \mathcal{L} = \frac{1}{N} \sum_{n=1}^{N} \left( \mathcal{L}_r^n + \lambda_m \mathcal{L}_m^n + \lambda_p \mathcal{L}_p^n \right), $$
where $N$ is the number of rendered supervision views. The paper sets $\lambda_m = 0.5$ and $\lambda_p = 0.5$. The mask loss enforces consistency between the accumulated density and the foreground mask, while RGB and LPIPS encourage accurate appearance and perceptual fidelity. To reduce memory usage, the authors compute the losses on foreground-biased image patches rather than full images.
4. Data Generation: The Main Enabler
The paper’s main technical contribution is not just the model, but the data pipeline used to make human reconstruction feasible at LRM scale. The authors generate a training set of about 100k assets in total, combining synthetic and real-world sources. This is reported as roughly 20 times larger than the combined size of the existing human datasets they compare against.
4.1 Synthetic data from rigged assets
For synthetic data, the paper uses rigged human assets and animates them with poses sampled from AMASS. In the supplementary material, the authors specify that they use all 1,000 publicly released SynBody characters, spanning diverse body shapes, skin tones, and about 68 clothing templates, including dresses, T-shirts, coats, and pants. The generated synthetic subset contains 78k assets. On average, about 26 views are rendered per asset from camera positions randomly distributed on a sphere, with azimuth in $[0^\circ, 360^\circ]$ and elevation in $[-45^\circ, 60^\circ]$.
The synthetic pipeline is straightforward: sample SMPL-X parameters from AMASS, animate the rigged asset, re-center the animated human, and render multiple canonical views. This strategy produces broad pose variation and helps the model learn diverse clothing configurations while retaining geometry consistency.
4.2 Real-world data from multi-camera capture
The real-world subset is built from multi-camera human capture datasets such as DNA-Rendering and MVHumanNet. The authors fit a 3D Gaussian Splatting representation to the captured subject, initializing one Gaussian per mesh vertex using the subject’s SMPL-X mesh. The optimization is driven by a photometric loss over the captured views, with adaptive density control to improve convergence and coverage. After fitting, they re-render the fitted subject from canonical viewpoints to obtain additional supervision images.
In the supplementary material, they report that this subset contains 22k assets and that the Gaussian optimization only lasts 4,000 iterations, with densification performed between iterations 400 and 1,500. They also report a quantitative self-check on the re-rendered fitted data of average $36.23 / 0.9881 / 16.57$ for PSNR / SSIM / LPIPS, suggesting the fitted data remains high quality.
A notable implementation detail is that the SMPL-X-based initialization is far better than standard COLMAP initialization for this setting. On a 10-sample test, the paper reports PSNR / SSIM / LPIPS of $36.38 / 0.9886 / 16.36$ for the proposed initialization versus $16.49 / 0.9025 / 68.79$ for COLMAP. The authors also state that the improved initialization reduces optimization time from about 40 minutes to about 4 minutes.

4.3 Why both synthetic and real data matter
The paper repeatedly shows that the two data sources are complementary. Synthetic assets contribute pose diversity and large scale, while real-world captures provide realistic appearance statistics and details that are hard to synthesize. Ablations show that removing either component hurts performance, and increasing the proportion of generated data improves results consistently.
5. Training Setup and Evaluation Protocol
HumanNOVA is implemented in PyTorch and trained on 64 NVIDIA H100 GPUs using AdamW with learning rate $6 \times 10^{-4}$ and batch size 64. The triplane spatial size is 96, and the input resolution is $512 \times 512$. During training, the model supervises 4 rendered views per instance. Patches of size $180 \times 180$ are used for loss computation, selected according to foreground coverage so that supervision focuses on the human body rather than background.
For the human-scan datasets THuman2, CustomHuman, and 2K2K, the paper follows a unified preprocessing protocol: each mesh is placed in a canonical camera setup and rendered into 36 multiview images at 10-degree intervals around a full horizontal circle. Importantly, supervision uses rendered images rather than mesh geometry directly.
Evaluation is performed on CustomHuman, THuman2, and 2K2K. The main image metrics are PSNR, SSIM, and LPIPS. For geometry, the paper reports Chamfer Distance (CD), Normal Consistency (NC), and F-Score. For fair comparison with mesh-based methods, the authors align the predicted meshes to the ground truth using scale alignment and ICP before rendering and geometry evaluation.
6. Main Quantitative Results
The paper compares HumanNOVA against both human-specific methods and general 3D reconstruction methods. The baselines include Real3D, SF3D, Trellis, Hunyuan2, PaMIR, SiFU, and SiTH for rendering quality, and additional mesh/shape methods for geometry evaluation. The central result is that HumanNOVA is consistently best on all reported benchmarks, under both frontal-view and side-view inputs.
| Method | CustomHuman | THuman2 | 2K2K | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| Real3D | 17.13 | 0.8990 | 95.12 | 19.14 | 0.9094 | 87.68 | 18.06 | 0.9020 | 81.78 |
| SF3D | 19.46 | 0.9113 | 66.09 | 22.28 | 0.9287 | 57.20 | 20.47 | 0.9142 | 58.14 |
| Trellis | 18.59 | 0.9123 | 74.98 | 20.77 | 0.9218 | 65.67 | 19.21 | 0.9140 | 68.25 |
| Hunyuan2 | 19.42 | 0.9094 | 74.34 | 21.44 | 0.9257 | 66.19 | 19.87 | 0.9145 | 65.62 |
| PaMIR | 18.15 | 0.9070 | 88.12 | 21.03 | 0.9229 | 70.91 | 18.89 | 0.9113 | 73.90 |
| SiFU | 17.94 | 0.9091 | 85.75 | 19.44 | 0.9157 | 79.62 | 16.82 | 0.9039 | 87.51 |
| SiTH | 19.13 | 0.9173 | 72.94 | 20.92 | 0.9231 | 66.90 | 18.49 | 0.9095 | 73.55 |
| HumanNOVA | 22.29 | 0.9360 | 42.42 | 23.96 | 0.9382 | 42.13 | 22.65 | 0.9336 | 41.72 |
The paper highlights that, relative to the best competitor SiTH, HumanNOVA achieves LPIPS improvements of 41.8% on CustomHuman, 37.0% on THuman2, and 43.3% on 2K2K in the frontal-view setting. The authors emphasize that the gains come from both stronger human priors and the much larger training dataset.
| Method | CustomHuman | THuman2 | 2K2K | ||||||
|---|---|---|---|---|---|---|---|---|---|
| CD | NC | F-Score | CD | NC | F-Score | CD | NC | F-Score | |
| SF3D | 1.738/2.040 | 0.847 | 39.585 | 1.441/1.745 | 0.833 | 43.820 | 1.204/1.412 | 0.829 | 50.900 |
| Trellis | 2.125/2.175 | 0.801 | 32.846 | 1.799/1.832 | 0.796 | 37.939 | 1.446/1.359 | 0.805 | 48.826 |
| Hunyuan2 | 1.799/1.762 | 0.837 | 38.365 | 1.562/1.541 | 0.808 | 43.868 | 1.237/1.217 | 0.829 | 53.946 |
| ICON | 2.468/2.915 | 0.779 | 27.731 | 2.568/3.168 | 0.752 | 26.453 | 2.211/3.331 | 0.728 | 28.805 |
| ECON | 2.160/2.813 | 0.804 | 33.429 | 2.240/3.931 | 0.763 | 31.294 | 2.066/6.232 | 0.732 | 32.927 |
| SiFU | 2.440/3.203 | 0.789 | 27.553 | 2.509/3.778 | 0.760 | 27.487 | 2.136/5.331 | 0.732 | 29.823 |
| SiTH | 1.792/2.215 | 0.826 | 36.822 | 1.741/2.082 | 0.805 | 39.666 | 1.518/1.896 | 0.798 | 42.859 |
| HumanNOVA | 1.062/1.102 | 0.867 | 61.379 | 1.027/1.098 | 0.840 | 61.939 | 1.045/1.110 | 0.836 | 60.673 |
The geometry results are especially strong. The paper reports that HumanNOVA attains the best CD, NC, and F-Score on all three benchmarks, and on side-view inputs it achieves a 94.3% relative F-Score gain over SiTH on CustomHuman.
7. Ablation Studies and What They Show
The ablations are useful because they separate the contributions of the data pipeline from the model design. Unless otherwise stated, these ablations are run for 70% of the main training iterations and evaluated on CustomHuman using frontal-view input.
7.1 Data ablations
| Setting | PSNR | SSIM | LPIPS |
|---|---|---|---|
| w/o gen-data (assets) | 21.84 | 0.9333 | 46.51 |
| w/o gen-data (multi-cam) | 21.76 | 0.9326 | 47.83 |
| 25% generated data | 21.98 | 0.9313 | 50.14 |
| 50% generated data | 22.02 | 0.9338 | 47.03 |
| HumanNOVA | 22.07 | 0.9344 | 45.18 |
These experiments show that both synthetic assets and multi-camera real data are important. More generated data consistently improves results, and the synthetic component is particularly helpful for pose diversity, while the real component helps photorealism.
The paper also verifies the utility of the generated dataset by fine-tuning Real3D on it. Across CustomHuman, THuman2, and 2K2K, Real3D improves substantially both for frontal and side-view input. This supports the claim that the dataset itself is a meaningful contribution, not just a training trick for the proposed architecture.
| Method | CustomHuman | THuman2 | 2K2K | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| Real3D | 17.13 | 0.8990 | 95.12 | 19.14 | 0.9094 | 87.68 | 18.06 | 0.9020 | 81.78 |
| Real3D + our data | 20.97 | 0.9268 | 58.54 | 23.10 | 0.9325 | 55.30 | 20.91 | 0.9202 | 58.22 |
7.2 Model ablations
| Setting | PSNR | SSIM | LPIPS |
|---|---|---|---|
| w/o mesh prior | 21.89 | 0.9334 | 46.26 |
| small triplane size (32) | 21.78 | 0.9323 | 48.33 |
| HumanNOVA | 22.07 | 0.9344 | 45.18 |
The mesh prior improves LPIPS by about 2.3% relative, showing that coarse body structure remains valuable even with large-scale training. Reducing the triplane spatial size from 96 to 32 causes a noticeable drop, indicating that human reconstruction benefits from a higher-capacity 3D latent than what is often sufficient for general object LRMs.
| Setting | PSNR | SSIM | LPIPS |
|---|---|---|---|
| Visual encoder: DINOv2 -> Sapiens | 21.98 | 0.9327 | 46.52 |
| Fusion layers: 4 -> 2 | 21.42 | 0.9301 | 50.65 |
| Supervision views: 4 -> 2 | 22.07 | 0.9344 | 45.18 |
The most important takeaway from these extra ablations is that sufficient cross-modal fusion depth matters. Reducing the number of fusion layers hurts performance the most, especially LPIPS. Using fewer supervision views also degrades quality, showing the value of richer multiview supervision during training.
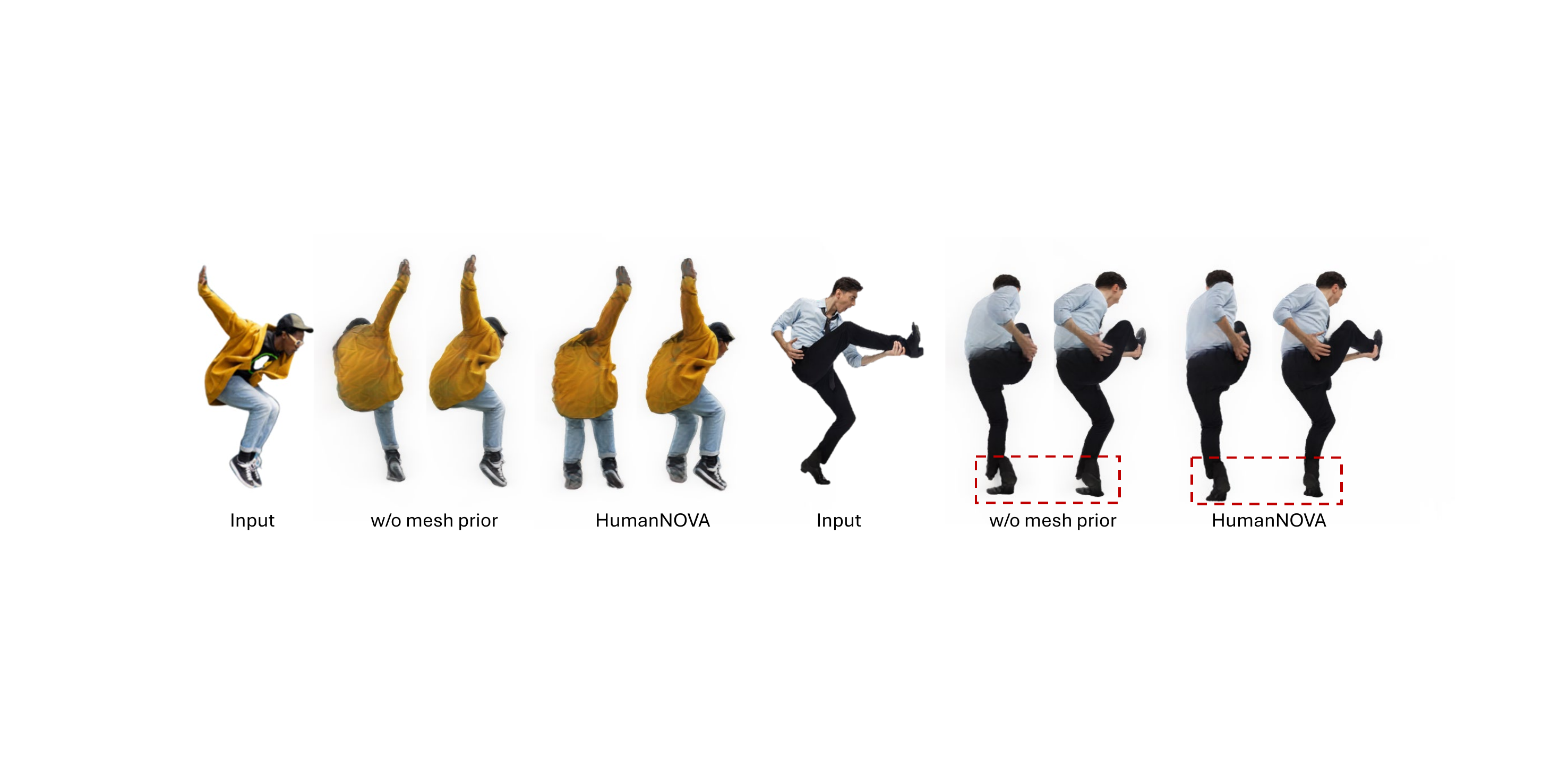
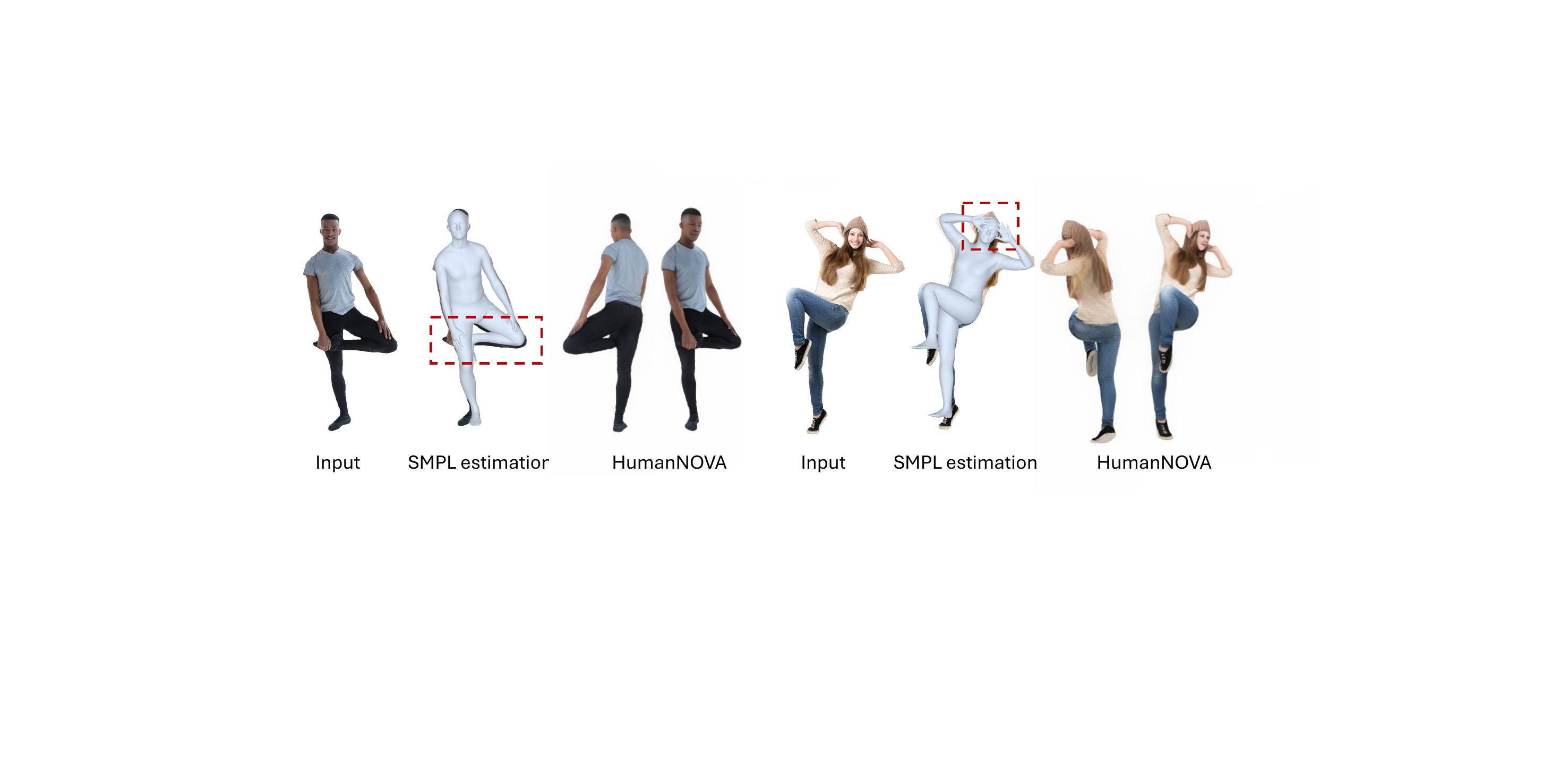
8. Qualitative Findings and Failure Modes
The qualitative comparisons reinforce the quantitative trends. HumanNOVA reconstructs sharper clothing boundaries, more plausible body structure, and more stable appearance across viewpoints than the baselines. This is shown both on benchmark images and on in-the-wild images with more challenging backgrounds and poses.



The failure cases are informative: the model can struggle to infer plausible back-side textures for especially ambiguous garments, such as dresses and overalls. The supplementary material also notes that extremely inaccurate SMPL estimates can still cause failures, even though the system is generally robust and tends to prioritize appearance cues when the mesh prior is noisy.
9. Supplementary Analysis
The supplementary section adds three useful points. First, it compares HumanNOVA with animation-based methods such as SHERF and LHM, which target a related but different setting: animatable avatar reconstruction that depends heavily on accurate pose alignment. HumanNOVA is more challenging because it must work from only a single image and off-the-shelf SMPL estimation. On the reported comparison, HumanNOVA substantially outperforms both methods, with PSNR / SSIM / LPIPS of $22.29 / 0.9360 / 42.42$ versus SHERF’s $16.83 / 0.9037 / 87.99$ and LHM’s $17.75 / 0.9083 / 76.85$.
Second, a leave-one-out experiment on CustomHuman shows that the model generalizes well to unseen settings. The leave-one-out result is $21.99 / 0.9344 / 44.22$, close to the full model’s $22.29 / 0.9360 / 42.42$.
Third, the authors discuss the Janus problem in their video results and argue that HumanNOVA is less affected because it models the full 3D human directly rather than separately generating front and back views and merging them heuristically.
10. Limitations, Broader Impact, and Practical Takeaways
The paper is candid about remaining limitations. HumanNOVA still struggles when the input image contains severe occlusion, when the back side of the clothing is highly ambiguous, or when the estimated SMPL mesh is completely wrong. The authors also note that extending the method to human-human or human-object interactions is a promising direction for future work.
The supplementary broader-impact discussion flags misuse concerns. Because the method lowers the barrier to producing realistic 3D human reconstructions, it could potentially be used for deceptive content, harassment, or privacy violations. The paper therefore calls for both technical safeguards and regulatory attention.
The practical takeaway is that the paper’s gains are driven by a clear recipe: scale human data aggressively, combine synthetic pose diversity with real capture realism, and adapt a large reconstruction backbone with a human-specific mesh prior and a sufficiently expressive triplane. Within that design space, HumanNOVA is presented as a strong proof that feed-forward LRM-style models can work well for humans, not just for generic objects.
11. Summary of Contributions
- A feed-forward single-image human avatar model that reconstructs photorealistic 3D humans in under one second, with no test-time optimization.
- A scalable data pipeline that combines synthetic rigged assets animated with AMASS poses and real multi-camera captures fitted with 3D Gaussian Splatting.
- A token-conditioned transformer architecture that fuses DINOv2 image tokens and PTv3 mesh tokens into a triplane representation.
- Strong quantitative improvements over prior human-specific and general reconstruction methods on rendering and geometry metrics across CustomHuman, THuman2, and 2K2K.
- Ablations showing that both data sources, the mesh prior, sufficient triplane capacity, and adequate fusion depth are important for the final quality.