Mamba-Enhanced Implicit Motion
Mamba-Enhanced Implicit Motion Learning for Audio-Driven Portrait Animation

A two-stage implicit motion learning framework for audio-driven portrait animation. It predicts detailed motion features without explicit landmarks using Mamba-enhanced diffusion, delivering high-quality, coherent talking-head and gesture animations from a single image and audio.
Links
Paper & demos
Abstract
Audio-driven human motion video generation aims to synthesize realistic and temporally coherent human animations from a single static image, with applications in talking-head synthesis, co-speech gesture generation, and dynamic presentations. Moving beyond conventional keypoint-based methods that often struggle to capture subtle motion dynamics, We propose a novel implicit-motion framework for generating realistic and temporally coherent human motion videos from a single static image and audio. Our approach uses a two-stage pipeline that decouples motion prediction from rendering. The first stage integrates appearance priors and hierarchical depth cues into a region-aware attention mechanism to model latent motion features. The second stage employs a Mamba-enhanced diffusion model to directly predict these features from audio and the source image, enabling unsupervised learning of fine-grained motion patterns. This decoupled architecture enhances flexibility and efficiency. Trained on a new 380-hour high-quality dataset, our method outperforms prior work across multiple public benchmarks and our collected data in accuracy, naturalness, and temporal coherence, setting a new state-of-the-art.
Overview
This paper tackles audio-driven human motion video generation from a single static portrait and speech audio, with the target use cases of talking-head synthesis, co-speech gesture generation, and other portrait-animation settings. The central motivation is that explicit keypoint- or landmark-based pipelines often struggle to represent subtle, long-range, and depth-dependent motion, and they can introduce artifacts such as jitter, ghosting, and unnatural deformation under large pose changes. The proposed answer is an implicit motion framework that separates motion prediction from rendering and trains in two stages: first, it learns a latent representation of motion deviations from paired video data; second, it uses a Mamba-enhanced diffusion model to predict those latent motion features from audio and the source image at inference time.
The paper’s key claim is that this decoupled design improves both flexibility and efficiency. Stage 1 learns how to decode latent motion into frames without relying on explicit landmarks, while Stage 2 replaces the motion encoder at inference with a conditional generative model that directly synthesizes the latent motion features. The reported result is a system that achieves strong visual fidelity, temporal coherence, and audio-visual synchronization on both talking-head and co-speech benchmarks, while also being competitive in runtime for audio-to-video generation.
The paper also reports a new self-collected 380-hour high-quality dataset called DiverseHeads, which is used in the two-stage training pipeline and in evaluation. The final system is described as outperforming prior work on multiple public benchmarks and on the collected dataset.
Figure-driven architecture at a glance
Method
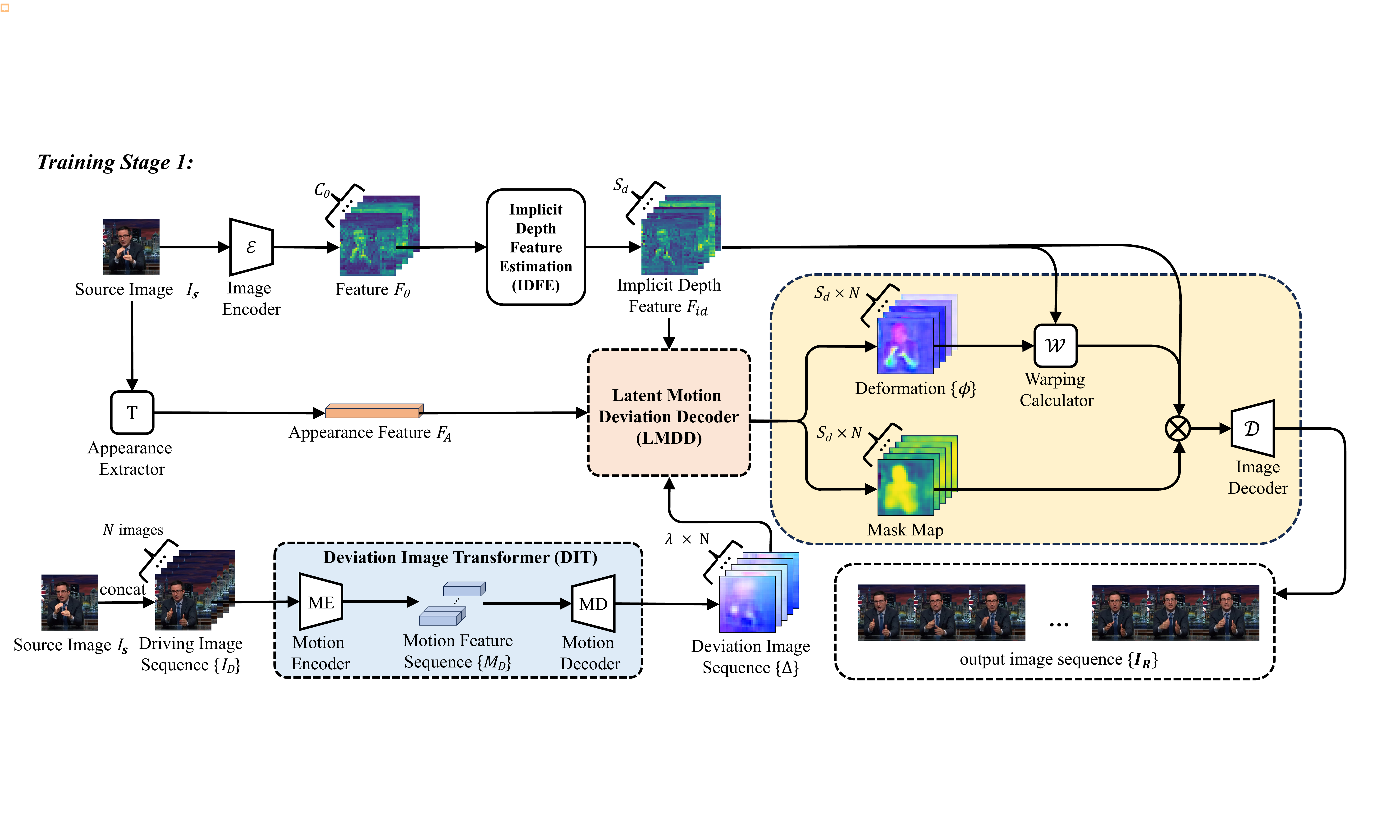
The input to the system is a source image $I_S$ and an audio signal $a$. During training, Stage 1 uses a source image and a driving video sequence $I_D$ to learn a base model that maps motion features into pixel space. Stage 2 then learns to generate those motion features from audio and image conditioning, enabling audio-driven inference without requiring a driving video at test time.
The paper explicitly positions the method against conventional keypoint-driven and 3D-model-based approaches. Instead of encoding motion as sparse landmarks, the method learns an implicit motion representation and uses a region-aware mechanism to preserve identity and control spatial deformation.
Stage 1: base model learning with implicit motion deviation
Stage 1 is trained from scratch on video sequences. The goal is to learn a robust mapping from motion features to frames, so that later stages can synthesize coherent and identity-preserving portraits by predicting latent motion rather than explicit landmarks.
A central design choice is implicit depth feature estimation. The method introduces a depth axis with $S_d$ sectioning planes to model the fact that different facial and body regions move differently in depth: nearby parts such as fingers can exhibit larger displacements and faster motion, while more central regions such as the torso tend to move more smoothly. The source image encoder produces features that are expanded along this depth axis, yielding a depth-partitioned tensor $F_m \in \mathbb{R}^{H \times W \times C \times S_d}$. A global pooling operation aggregates these depth slices, and the resulting compact representation is transformed into depth-wise weights:
$$ \omega_m = \sigma\left( \operatorname{FC}\left( \frac{1}{S_d H W} \sum_{s=1}^{S_d} \sum_{h=1}^{H} \sum_{w=1}^{W} F_m \right) \right) $$
These weights are used to form a depth-aware identity feature $F_{id} = \omega_m \cdot F_m$, which is then refined by a ResNet3D module. The intent is to stratify motion according to depth rather than collapsing all motion into a single flat representation.
The paper also introduces an Appearance Extractor to preserve biometric details that are often corrupted by displacement-field methods, such as moles and wrinkles. This extractor encodes identity information from the source portrait into a compact appearance vector $F_A$, helping keep identity cues separate from motion deformation.
The main motion module in Stage 1 is the Deviation Image Transformer (DIT). The authors describe it as a mechanism for generating spatial motion offsets from video motion features, with the goal of eliminating landmark artifacts and improving temporal stability under large motion. The source image $I_S$ and driving sequence $\{I_D\}$ are first processed by a motion encoder, producing motion features $\{M_D^i\}_{i=0}^{N} \in \mathbb{R}^{768 \times (N+1)}$, where $M_D^0$ corresponds to the source image. Each feature is reshaped to $V_D^i \in \mathbb{R}^{8 \times 8 \times 12}$ and normalized. The model then applies $n$ layers of 3D convolution, together with scale and shift terms $k_{sc}^i$ and $k_{sh}^i$, to produce deviation maps:
$$ \Delta_i = \frac{V_{nor}^i - V_{nor}^0}{\sqrt{\delta^2 + \epsilon}} \cdot k_{sc}^i + k_{sh}^i, $$
where $\delta$ is the standard deviation and $\epsilon = 10^{-5}$ avoids division by zero. The paper further states that it generates $\lambda$ deviation maps per frame, one per motion region of interest, to support pixel-level deformation guidance through implicitly represented displacement fields. This region decomposition is meant to reduce artifacts caused by overly sparse or rigid motion controls.
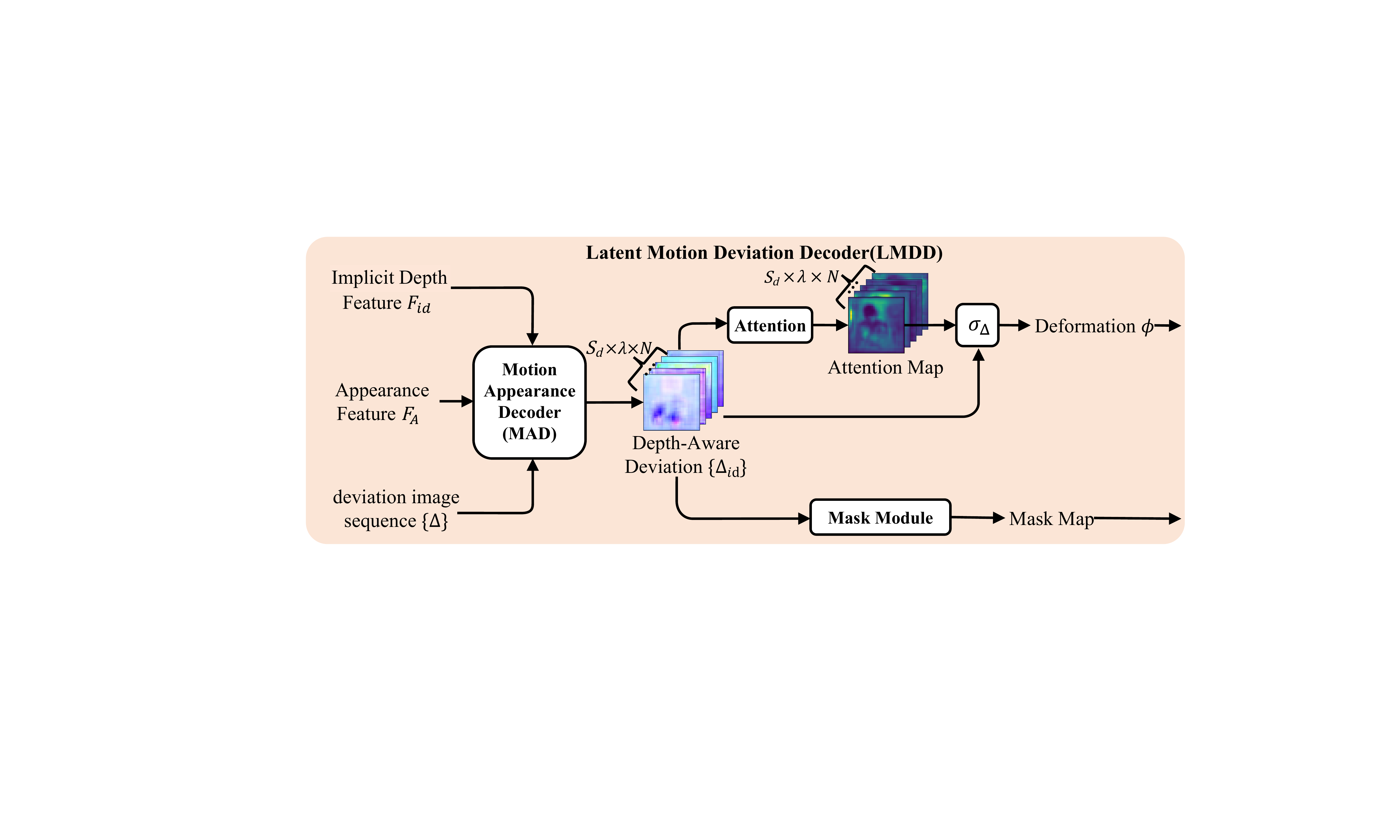
The Latent Motion Deviation Decoder (LMDD) then fuses depth information, motion deviation maps, and identity features. According to the text, LMDD performs motion-depth decoupling and attention-guided deformation. It produces depth-aware deviation sequences aligned with the $S_d$ depth layers, then applies attention to obtain focus maps over motion-relevant regions. A softmax over the $\lambda$ motion regions yields probabilities for precise control, and a mask module adds spatial constraints to handle occlusions and avoid overextending motion into irrelevant areas. In the paper’s description, this module is designed to make movement of the characters more natural and to resolve occlusion artifacts by combining stratified depth and region-aware attention.
The decoder reconstructs the final image from the deformation features. Before decoding, the deformation feature $\phi$ is warped with the depth-aware identity features to form $\phi'$, then blended with a mask $\delta_\phi$:
$$ \phi_m = \delta_\phi \phi' + (1 - \delta_\phi) F_{id}. $$
A nonlinear activation then modulates the blended feature:
$$ \phi_r = \max(0, \phi_m) + \beta \cdot \min(0, \phi_m), \qquad I_R = U(\phi_r), $$
where $U$ is the image decoder and $\beta$ controls articulation intensity. The output is the reconstructed frame $I_R$.
The Stage 1 objective combines three losses. First, a VGG-19-based multiresolution perceptual reconstruction loss $\mathcal{L}_{per}$ compares generated frames and ground truth. Second, a patch discriminator provides an adversarial loss $\mathcal{L}_{adv}^{G}$. Third, the authors propose a threshold mask loss to emphasize motion differences above a threshold $\tau$. They define a binary mask from the mean absolute difference between ground-truth features $v^{gt}$ and source-deviation features $v^{dev}$:
$$ \ell_{mask} = \mathbf{1}\left( \operatorname{mean}(|v^{gt} - v^{dev}|) > \tau \right), $$
and use it to form a weighted perceptual-geometric term:
$$ \mathcal{L}_{pg} = \sqrt{\operatorname{mean}\left((v^{gt} - v^{dev})^2\right)} \cdot \ell_{mask}. $$
The total Stage 1 loss is:
$$ \mathcal{L}_{total}^{Stage1} = \alpha_1 \mathcal{L}_{per} + \alpha_2 \mathcal{L}_{adv}^{G} + \alpha_3 \mathcal{L}_{pg}. $$
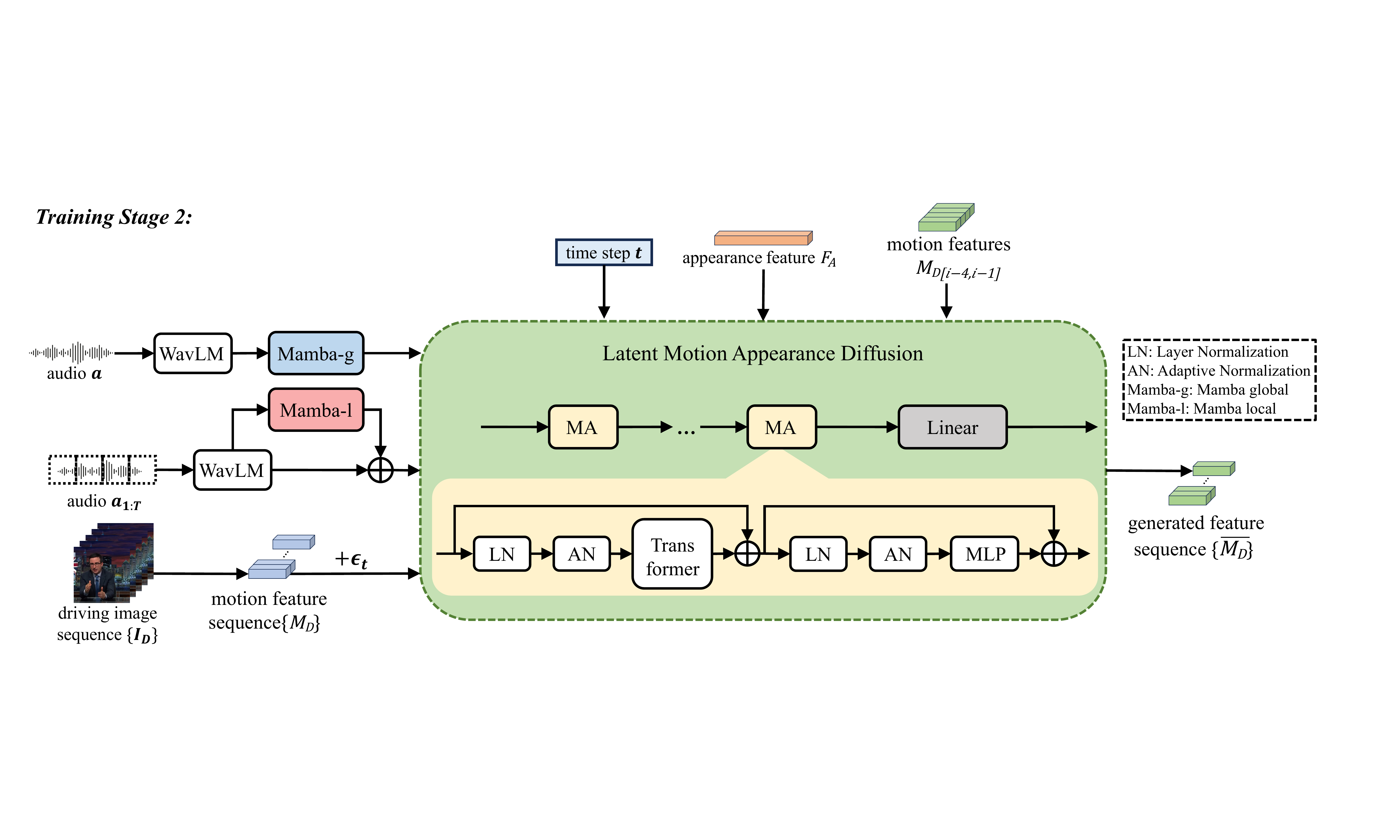
Stage 2: Mamba-enhanced motion feature generation
Stage 2 replaces the motion encoder at inference with a conditional diffusion model that directly predicts motion features. The authors adapt a latent motion diffusion model and train it on motion feature sequences $M_D$ encoded from driving videos, with Gaussian noise $\epsilon_t$ added at diffusion timestep $t$. The diffusion model learns to recover clean motion features under multiple conditioning signals.
The conditioning signal is composite: the appearance feature $F_A$ preserves identity, the audio is decomposed into global and local embeddings, and the preceding four predicted motion features are used as weak temporal context. More specifically, the audio path uses a Mamba global extractor to obtain $F_{ag}$ from the raw speech waveform and a Mamba local extractor to obtain $F_{al}$ from sliced audio segments $a_{1:T}$. The text describes this as a fuzzy inference strategy that supports continuous feature learning without explicit classification, helping the generated motion track both coarse speaking style and fine-grained local variations.
The model also conditions on the previous four motion features $\overline{M_D}_{[i-4,i-1]}$ when generating frame $i$; these are initialized to zeros for the earliest frames. This weak temporal supervision is intended to suppress frame skipping, motion jitter, and discontinuities during speech transitions. The complete conditioning tuple is
$$ c = (F_{ag}, F_{al}, \overline{M_D}_{[i-4,i-1]}, F_A). $$
The diffusion objective is the standard $\epsilon$-prediction loss:
$$ \mathcal{L}_{simple} = \mathbb{E}_{M_D, t, \epsilon \sim \mathcal{N}(0,I)} \left[ \left\| \epsilon - \epsilon_\theta\left( \sqrt{\bar{\alpha}_t} M_D + \sqrt{1-\bar{\alpha}_t} \epsilon, t, c \right) \right\|^2 \right]. $$
In addition, the paper imposes motion smoothness constraints through velocity and acceleration terms. Using the frame-wise difference function $f_k(x) = x^{(k)} - x^{(k-1)}$, the implicit velocity loss is:
$$ \mathcal{L}_{impvel} = \frac{1}{M-1} \sum_{m=1}^{M-1} \left\| f_{m+1}(M_D) - f_{m+1}(\overline{M_D}) \right\|_2^2, $$
and the acceleration loss is:
$$ \mathcal{L}_{accel} = \frac{1}{M-2} \sum_{m=1}^{M-2} \left\| \big( f_{m+2}(M_D) - f_{m+1}(M_D) \big) - \big( f_{m+2}(\overline{M_D}) - f_{m+1}(\overline{M_D}) \big) \right\|_2^2. $$
Together, these losses encourage the synthesized motion features to remain physically plausible while preserving identity and speech alignment. The paper’s emphasis is that motion dynamics are learned implicitly from video-encoded features, rather than from explicit kinematic targets.
Training protocol and data
The paper uses a two-stage training paradigm. Stage 1 trains the base image-to-motion decoding system from scratch on paired source/driving video data. Stage 2 trains the latent motion appearance diffusion module on motion features extracted from the Stage 1 driving sequences.
For the talking-head task, the paper reports experiments on CREMA-D, RAVDESS, HDTF, MEAD, CMLR, and the authors’ self-collected DiverseHeads dataset, which contains 380 hours of high-quality audio-visual material and covers diverse speaking scenarios. For co-speech gesture generation, the paper uses PATS, described as about 84k clips and 250 hours, following the standard preprocessing protocol from S2G-MDDiffusion for four identities: Chemistry, Oliver, Jon, and Seth.
The reported evaluation operates at $256 \times 256$ resolution and $25$ fps for both talking-head and gesture generation settings.
| Task | Dataset | What the paper reports |
|---|---|---|
| Talking head | CREMA-D | Used in experiments; no additional dataset size details given in the paper text. |
| Talking head | RAVDESS | Used in experiments; no additional dataset size details given in the paper text. |
| Talking head | HDTF | Used in experiments; no additional dataset size details given in the paper text. |
| Talking head | MEAD | Used as a benchmark for quantitative comparison. |
| Talking head | CMLR | Used in experiments; no additional dataset size details given in the paper text. |
| Talking head | DiverseHeads | Authors’ self-collected dataset, 380 hours, diverse speaking scenarios. |
| Co-speech gesture | PATS | Approximately 84k clips, 250 hours; standard preprocessing used for four identities. |
Experimental results
The paper evaluates the method using image quality, video quality, temporal coherence, motion naturalness, diversity, and audio-visual synchronization metrics. Specifically, it reports FID, FVD, Headpose error, PSNR, SSIM, LPIPS, DIV, Temporal Gesture Distance (TGD), LSE-D, and LSE-C depending on the task. Lower is better for FID, FVD, LPIPS, Headpose, TGD, and LSE-D; higher is better for PSNR, SSIM, DIV, and LSE-C.
Talking-head results
On the talking-head benchmark, the paper compares against AniPortrait, DaGAN, FOMM, LivePortrait, MCNet, TPSMM, and in the experiment discussion also references X-Portrait. The main quantitative table shows that the proposed method attains the best results on almost all metrics on both MEAD and DiverseHeads, with the only exception being Headpose, where LivePortrait is slightly better because it explicitly optimizes for that metric.
| Method | MEAD | DiverseHeads | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Headpose ↓ | PSNR ↑ | SSIM ↑ | FID ↓ | FVD ↓ | LSE-D ↓ | LSE-C ↑ | Headpose ↓ | PSNR ↑ | SSIM ↑ | FID ↓ | FVD ↓ | LSE-D ↓ | LSE-C ↑ | |
| AniPortrait | 1.476 | 27.446 | 0.880 | 64.755 | 218.258 | 10.430 | 1.408 | 1.920 | 23.245 | 0.804 | 42.941 | 225.998 | 10.040 | 1.605 |
| DaGAN | 8.008 | 31.811 | 0.934 | 34.834 | 129.180 | 10.775 | 1.214 | 5.159 | 26.119 | 0.863 | 31.567 | 115.952 | 10.177 | 1.579 |
| FOMM | 7.977 | 29.236 | 0.899 | 37.022 | 143.790 | 10.437 | 1.447 | 5.134 | 22.990 | 0.803 | 33.465 | 150.046 | 10.177 | 1.608 |
| LivePortrait | 1.348 | 32.518 | 0.941 | 34.125 | 102.980 | 10.463 | 1.048 | 1.339 | 26.216 | 0.872 | 25.401 | 108.540 | 9.814 | 2.098 |
| MCNet | 7.397 | 32.804 | 0.940 | 33.141 | 135.458 | 10.038 | 1.812 | 4.207 | 27.759 | 0.885 | 27.730 | 113.583 | 10.075 | 1.739 |
| TPSMM | 7.874 | 31.924 | 0.940 | 34.619 | 136.075 | 10.486 | 1.370 | 5.148 | 26.997 | 0.879 | 27.389 | 121.976 | 10.096 | 1.717 |
| Ours | 1.465 | 34.661 | 0.953 | 30.501 | 92.179 | 9.025 | 2.672 | 1.826 | 29.213 | 0.908 | 23.718 | 77.267 | 9.248 | 2.777 |
The key talking-head takeaways are: on MEAD, the method reaches PSNR $34.661$, SSIM $0.953$, FID $30.501$, FVD $92.179$, LSE-D $9.025$, and LSE-C $2.672$; on DiverseHeads, it reaches PSNR $29.213$, SSIM $0.908$, FID $23.718$, FVD $77.267$, LSE-D $9.248$, and LSE-C $2.777$. The Headpose metric is slightly behind LivePortrait on both datasets, but the paper emphasizes that LivePortrait is specifically optimized for that metric, whereas this method achieves strong results without task-specific supervision.
Co-speech gesture results
On PATS, the paper compares against S2G-MDDiffusion and TANGO. The proposed method improves over S2G-MDDiffusion on all reported metrics and is competitive with TANGO on temporal gesture distance and synchronization, although the authors note that a fully fair comparison with TANGO is not possible for some metrics because TANGO relies on a driving-video pipeline and Wav2Lip-based synthesis.
| Method | Headpose ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | FID ↓ | FVD ↓ | DIV ↑ | TGD ↓ | LSE-D ↓ | LSE-C ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| S2G-MDDiffusion | 1.333 | 28.500 | 0.894 | 0.040 | 25.325 | 109.424 | 6.280 | 6.610 | 11.010 | 0.971 |
| TANGO | - | - | - | - | 42.863 | 168.313 | 5.217 | 1.883 | 10.365 | 1.736 |
| Ours | 1.115 | 28.835 | 0.905 | 0.027 | 19.246 | 54.456 | 7.159 | 5.027 | 10.257 | 1.531 |
The strongest co-speech improvements are in perceptual quality and temporal coherence: FID drops to $19.246$, FVD to $54.456$, and LPIPS to $0.027$, while diversity rises to $7.159$. The model also improves synchronization compared with S2G-MDDiffusion, with LSE-D decreasing to $10.257$ and LSE-C increasing to $1.531$. TANGO still has better TGD and LSE-C in the reported table, but that method is not directly comparable across all metrics because of its different generation setup.
Inference efficiency
The paper additionally reports runtime for generating a one-second $25$-FPS video. For audio-to-video generation, the proposed method is the fastest among the audio-driven methods in the table, with $1.515$ seconds per second of video, compared with $11.816$ seconds for AniPortrait and $22.088$ seconds for Hallo2. For image-to-image generation, it runs in $1.322$ seconds, which is slightly slower than FOMM and LivePortrait but much faster than several other baselines.
| Method | img2img (s) | audio2video (s) |
|---|---|---|
| X-Portrait | 36.973 | - |
| Hallo2 | - | 22.088 |
| FOMM | 0.828 | - |
| LivePortrait | 1.127 | - |
| AniPortrait | 11.498 | 11.816 |
| DaGAN | 2.126 | - |
| MCNet | 2.663 | - |
| TPSMM | 2.752 | - |
| Ours | 1.322 | 1.515 |

Qualitatively, the paper argues that the model preserves lip motion and eye gaze more faithfully, handles larger head poses more stably, and better maintains source identity than competing approaches. The qualitative examples are used to support the numerical gains on MEAD and DiverseHeads.
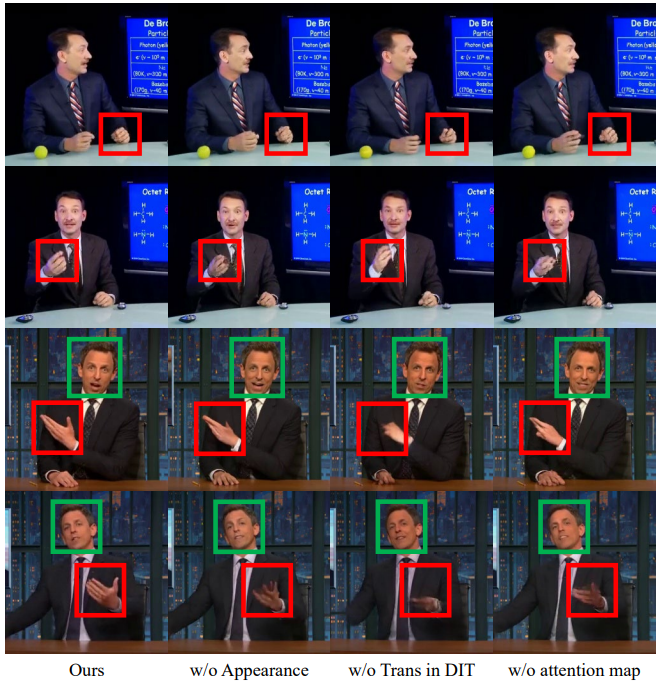
Ablation analysis
The ablation studies isolate the role of the appearance branch, the transformer component in DIT, the attention map in LMDD, and the Mamba audio extractors. The paper reports that removing appearance conditioning makes motions stiffer and causes loss of hand details. Removing the transformer in DIT degrades motion detail and lowers PSNR, SSIM, and FVD. Removing the attention map worsens lip and gesture fidelity, which is reflected in poorer synchronization metrics. The audio ablations show that both the global and local Mamba branches matter, and that the full model performs best overall.
| Method | Headpose ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | FID ↓ | FVD ↓ | DIV ↑ | TGD ↓ | LSE-D ↓ | LSE-C ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| w/o Appearance | 1.694 | 26.299 | 0.869 | 0.043 | 28.194 | 90.955 | 6.511 | 6.887 | 11.260 | 0.721 |
| w/o Trans. in DIT | 1.576 | 24.790 | 0.854 | 0.057 | 32.234 | 153.641 | 5.800 | 7.213 | 11.692 | 0.309 |
| w/o attention map | 1.500 | 25.801 | 0.863 | 0.047 | 29.148 | 133.441 | 6.405 | 6.597 | 11.780 | 0.296 |
| w/o mamba-g | - | - | - | - | 31.136 | 70.773 | 6.139 | 6.697 | 11.038 | 1.230 |
| w/o mamba-l | - | - | - | - | 30.587 | 71.032 | 4.706 | 5.593 | 11.000 | 1.090 |
| Ours | 1.115 | 28.835 | 0.905 | 0.027 | 19.246 | 54.456 | 7.159 | 5.027 | 10.257 | 1.531 |
The most important ablation conclusion is that the full combination of appearance conditioning, DIT-based motion deviation modeling, attention-based region focusing, and both Mamba audio branches is needed to achieve the best balance of realism, temporal stability, and synchronization. In particular, the global audio branch appears to be especially helpful for overall quality, while the local branch supports diversity and fine motion variation.
Stated contribution and interpretation
The paper’s stated contributions are: (1) a novel implicit multimodal cross-domain framework for portrait generation that avoids explicit keypoint modeling, (2) an unsupervised implicit motion representation learning strategy with latent motion-region attention and Mamba-enhanced diffusion, and (3) a 380-hour high-quality audio-visual dataset supporting the two-stage training paradigm. The method is designed around the idea that motion should be represented as a latent, region-aware deviation process rather than as sparse landmarks, which is particularly relevant for talking-head and co-speech settings where expression, lip motion, and head pose must remain coherent over time.
The conclusion notes three future directions rather than a formal limitations section: decoupling facial animation control using physiological signals and expert submodules, integrating neural radiance fields for dynamic real-time rendering, and building multimodal affective cognition models to drive emotional expression. The paper does not present a separate limitations subsection, so these future-work items are the clearest indication of what remains unresolved in the authors’ view.