AvatarMix
AvatarMix: Identity-Preserving Cross-Avatar Composition for Outfit Personalization
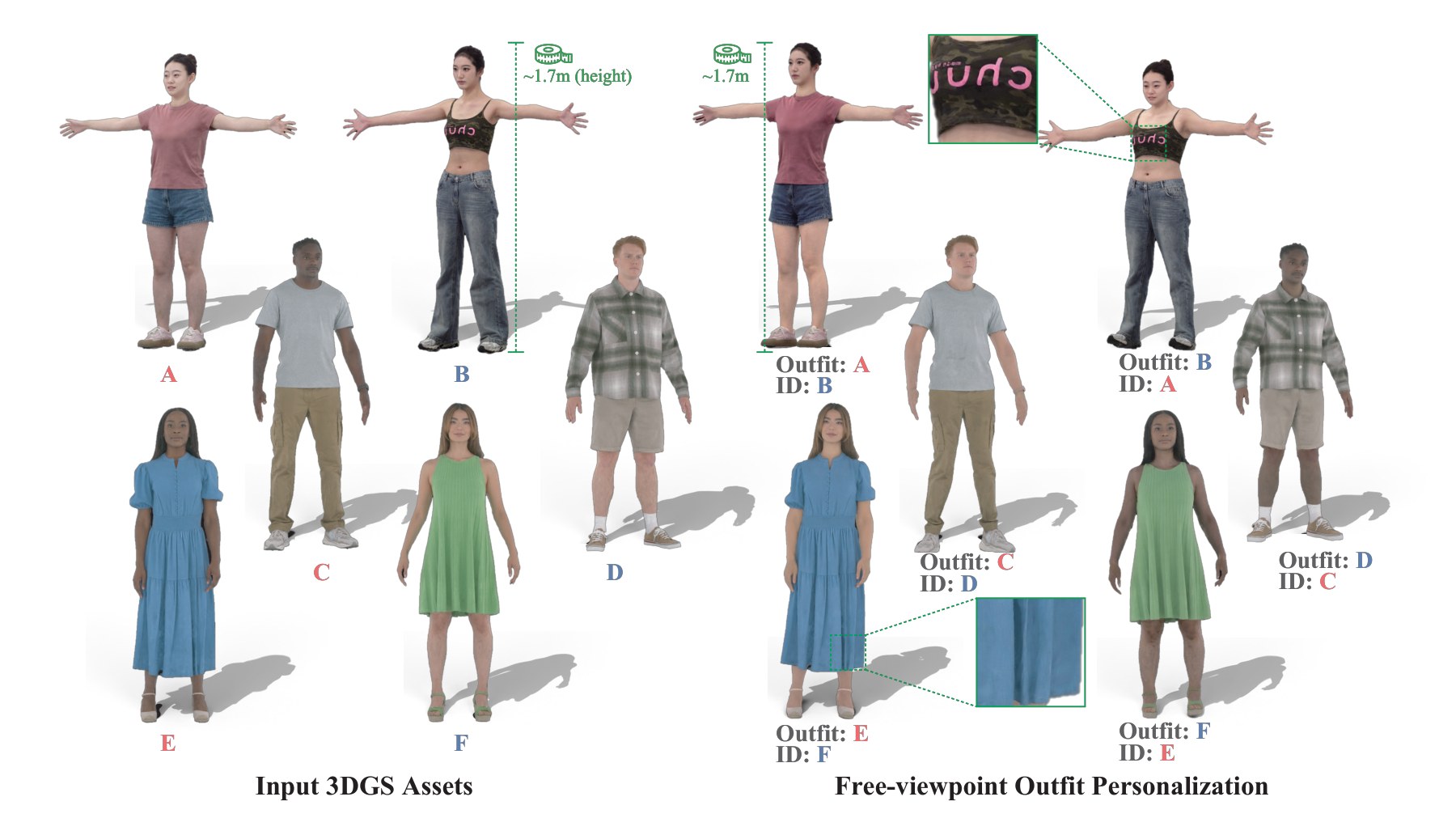
AvatarMix is a compositional method for 3D avatar outfit personalization that preserves both identity and garment quality by directly combining head and body from two Gaussian avatars. It uses a two-tier diffusion refinement and mesh retargeting to ensure seamless joins and adapt garments to diverse body shapes.
Demos
AvatarMix demos highlight identity-preserving outfit personalization by combining a user's face, body shape, and skin tone with a model's clothed 3D Gaussian avatar. Look for seamless joins, preserved garment details, natural body retargeting, and free-viewpoint consistency. Comparisons show improved texture fidelity and fewer artifacts versus prior methods.

Links
Paper & demos
Abstract
Existing 3D avatar outfit transfer methods face distinct challenges: approaches that lift 2D edits to 3D often suffer from outfit or identity quality degradation, while those that separately model body and clothing layers are prone to intersection artifacts. We introduce AvatarMix, a compositional paradigm that bypasses these issues by directly composing the head and body from two high-fidelity Gaussian avatars. While this paradigm inherently preserves outfit quality and avoids intersections, it introduces challenges in creating a seamless join and maintaining appearance fidelity after body reshaping. To this end, we propose a two-tier refinement strategy: SeamFix, a localized diffusion module that refines hair and neck to ensure an artifact-free join, and an optional full-body refinement, FullbodyFix, that restores garment appearance when retargeting degrades the clothed body. Both operate on renders from an already 3D-consistent Gaussian avatar, which limits multi-view artifacts compared to 2D-to-3D lifting. To preserve the user's body identity, our mesh-based Gaussian representation enables the adaptation of a robust mesh retargeting technique, precisely reshaping the clothed body to the user's physique and robustly handling diverse body shapes. Extensive experiments demonstrate that our method achieves state-of-the-art results in outfit fidelity and identity preservation, providing a new perspective for realistic 3D outfit personalization. Project page: https://larsph.github.io/avatarmix/
1. Problem Setting and Core Idea
AvatarMix addresses 3D avatar identity transfer for outfit personalization: given two high-fidelity 3D Gaussian avatars, one representing the user and one representing the model, the goal is to transfer the user’s identity cues—face, head/neck region, body shape, and skin tone—onto the model’s outfit without sacrificing garment fidelity or introducing cross-layer intersection artifacts. The paper positions this as a distinct task from 2D garment-image try-on and from layer-based 3D clothing transfer. Existing approaches either lift 2D edits into 3D and therefore inherit multi-view inconsistency and appearance degradation, or explicitly separate body and clothing layers and then struggle with mesh intersections and exposed-skin rendering when coverage differs.
The central design choice in AvatarMix is compositional rather than generative: instead of synthesizing an edited avatar from scratch, it directly composes the final result from two existing 3D Gaussian avatars. The user avatar contributes the head, neck, body shape, and skin tone; the model avatar contributes the clothed body and garment geometry. This preserves the original 3D consistency and high-frequency detail of both sources by construction, while shifting the remaining problem to two targeted issues: making the head–body join seamless and adapting the model body to the user’s physique.
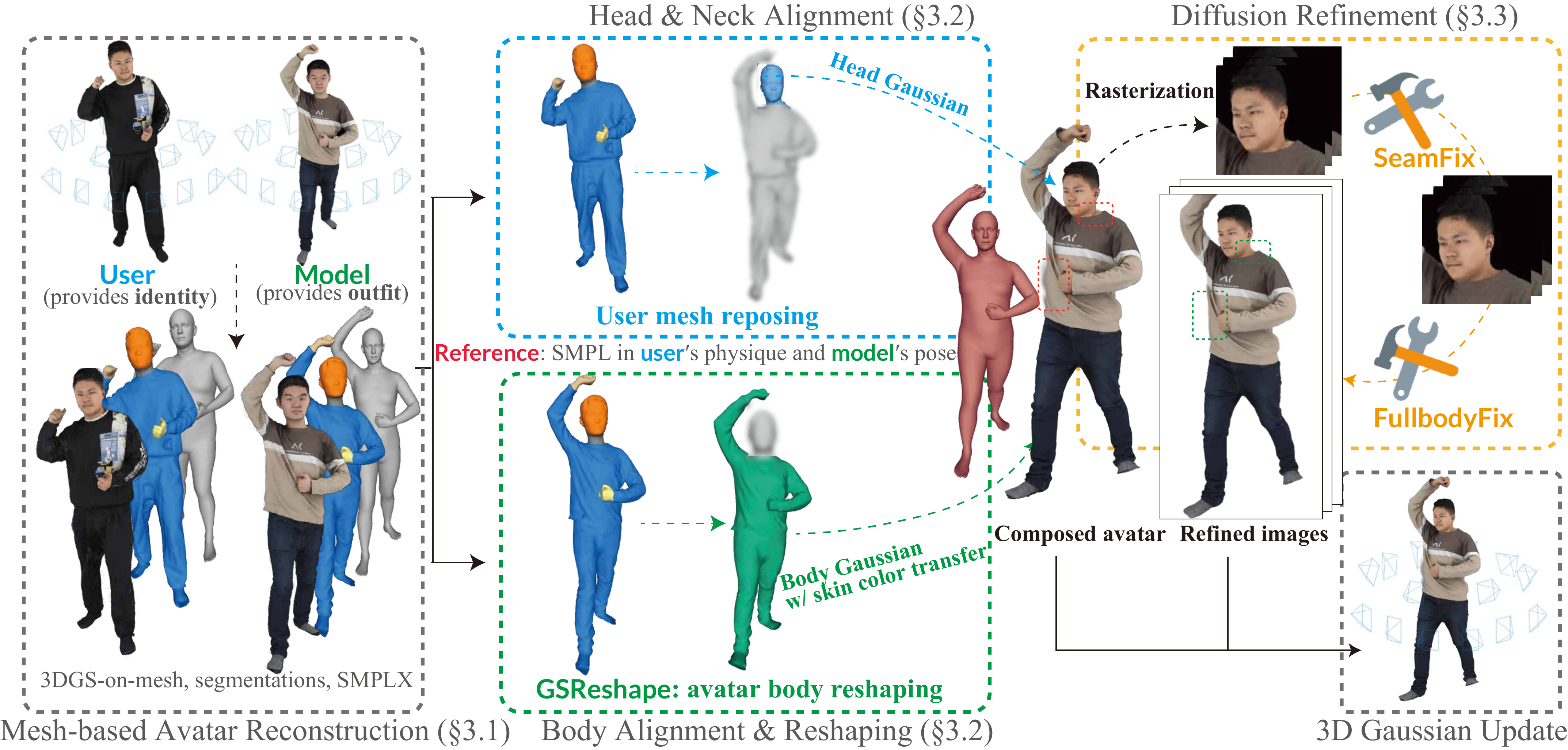
The method is organized into three stages: (1) mesh-based avatar reconstruction with semantic segmentation; (2) cross-avatar geometric composition, including head/neck alignment and body reshaping; and (3) diffusion refinement on rendered images, using a localized seam fixer and an optional whole-body restoration module. The overall aim is to preserve the model’s outfit quality, the user’s identity, and multi-view consistency simultaneously.
2. Representation and Reconstruction
AvatarMix requires high-fidelity source avatars with explicit geometry. The paper therefore reconstructs each subject as a mesh-based Gaussian avatar. Given multi-view images of the user and the model, NeuS2 is used to reconstruct a mesh $\mathcal{M} \in \mathbb{R}^{N_v \times 3}$ for each avatar. The authors specifically choose a mesh representation because the outfit personalization stage needs a geometric substrate that can be retargeted robustly across diverse body shapes, including loose clothing and non-watertight surfaces.
On top of the mesh, they place 3D Gaussians using the SplattingAvatar formulation: each mesh vertex $\mathbf{v}_i$ is associated with a Gaussian whose position is constrained to that vertex, along with covariance, color, and opacity. This keeps the representation photorealistic while preserving an explicit structural link to the mesh, which later enables retargeting and editing.
For semantic decomposition, the paper uses a modified 4D-Dress pipeline to segment vertices into head, torso skin, left/right arm skin, left/right leg skin, and clothing. The modification removes SAM-based voting to improve face and hand separation, especially to avoid over-aggregation of skin regions. The pipeline also assumes fitted SMPL-X parameters for each subject, which act as a body model and pose guide during composition.
3. Cross-Avatar Geometric Composition
3.1 Head and Neck Alignment
The user’s head and neck are transferred to the model pose rather than synthesized. The paper first transfers linear blend skinning weights from the user’s SMPL-X model to the high-resolution user mesh via nearest-neighbor mapping, then reposes the mesh to match the model’s pose. The head and neck vertices are extracted using the semantic segmentation. Including the neck is deliberate: it preserves more identity information, and any mismatch at the boundary is later handled by diffusion refinement.
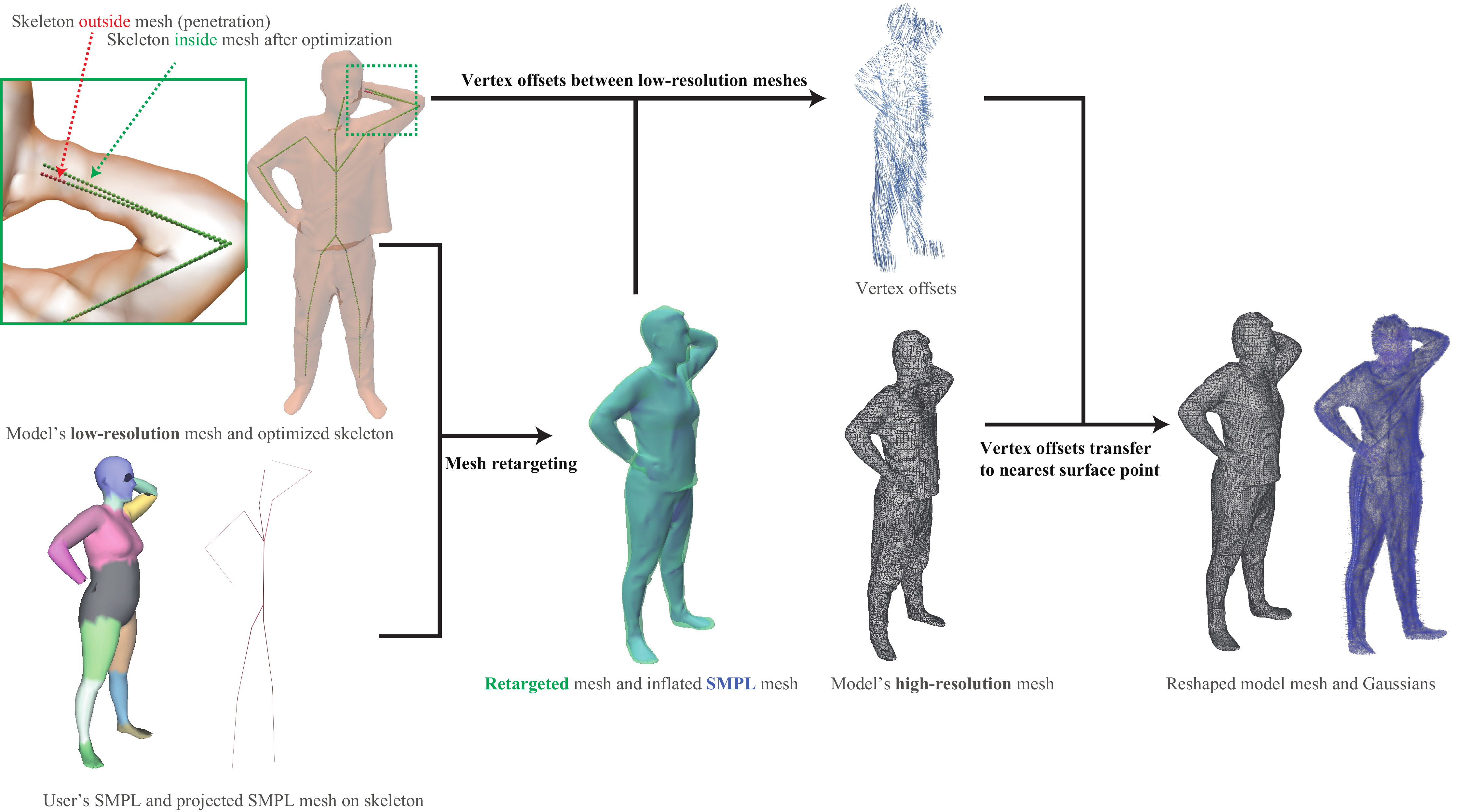
3.2 GSReshape: Body Reshaping via Mesh Retargeting
The most technically involved component is GSReshape, which adapts a garment retargeting method originally designed for fitting clothes to a body shape. In AvatarMix, the method is repurposed to reshape the model’s clothed body mesh, including both clothing and exposed skin, so that it matches the user’s body shape represented by the user’s SMPL-X mesh. Because the retargeting is performed in explicit mesh space, the deformation can be transferred back to the attached Gaussians and thus to the rendered avatar.
The paper highlights three implementation challenges and corresponding fixes:
- Hand-aware skin tightness. The original retargeting objective can overconstrain the hands. High fit weights on hand skin can push the mesh unnaturally and distort attached Gaussians, while low fit weights can produce a glove-like mismatch. AvatarMix resolves this by removing hand geometry from the SMPL-X mesh during retargeting, which prevents the SDF-based barrier from inflating the hands, and by using low fit weights on hand vertices. The method intentionally sacrifices explicit hand-shape adaptation to preserve visual cleanliness; the authors acknowledge this as a limitation.
- Intersection-free initialization. The retargeting method requires an initialization in which the clothed mesh and skeleton do not intersect. Because clothed avatars intersect the skeleton more easily than isolated garments, the paper optimizes the SMPL skeleton vertices with an as-rigid-as-possible deformation so that they remain inside the clothed avatar while preserving bone rigidity.
- Computational efficiency. The optimization is carried out on simplified meshes, and the resulting deformation is transferred to the original high-resolution mesh by nearest-surface projection. The Gaussians move with the mesh deformation.
The supplementary material gives the body-reshaping objective in more detail. The skeleton optimization combines three terms: an inside penalty that keeps bone samples inside the clothed mesh’s signed distance field, a bone-length regularizer, and a root anchor term. In the notation of the paper, if $X = \{x_k\}_{k=1}^{N_s}$ denotes the skeleton vertices and $\phi(\cdot)$ is the SDF of the clothed mesh, then the optimization uses
$$ E_{\text{pre}}(X) = w_{\text{inside}} E_{\text{inside}}(X) + w_{\text{len}} E_{\text{length}}(X) + w_{\text{anch}} E_{\text{anchor}}(X), $$
with paper-reported weights $w_{\text{inside}} = 50.0$, $w_{\text{len}} = 5.0$, and $w_{\text{anch}} = 10.0$, and a margin $\delta = 0.1$ in the inside penalty.
Once reshaping is complete, the user’s aligned head and neck replace the model’s corresponding region, and the method also performs a global skin-tone transfer in Lab color space. The skin-tone transfer computes opacity-weighted means and variances of the user face and model skin Gaussians, then applies a channel-wise affine transform so the model body’s skin color matches the user’s while largely preserving shading and high-frequency detail.
The result is a composite mesh-based Gaussian avatar that combines the user’s identity with the model’s outfit while retaining a consistent 3D representation.

4. Diffusion Refinement: SeamFix and FullbodyFix
Cross-avatar composition is geometrically valid, but the paper emphasizes two visual failure modes that remain after composition and retargeting: seam artifacts at the head–neck boundary and appearance degradation in the clothed body after reshaping. AvatarMix addresses these with a two-tier diffusion refinement strategy operating on rendered images from the already 3D-consistent Gaussian avatar. This is an important design choice: the refiner does not edit raw 2D inputs before reconstruction, which reduces the opportunity for multi-view inconsistency.
4.1 SeamFix
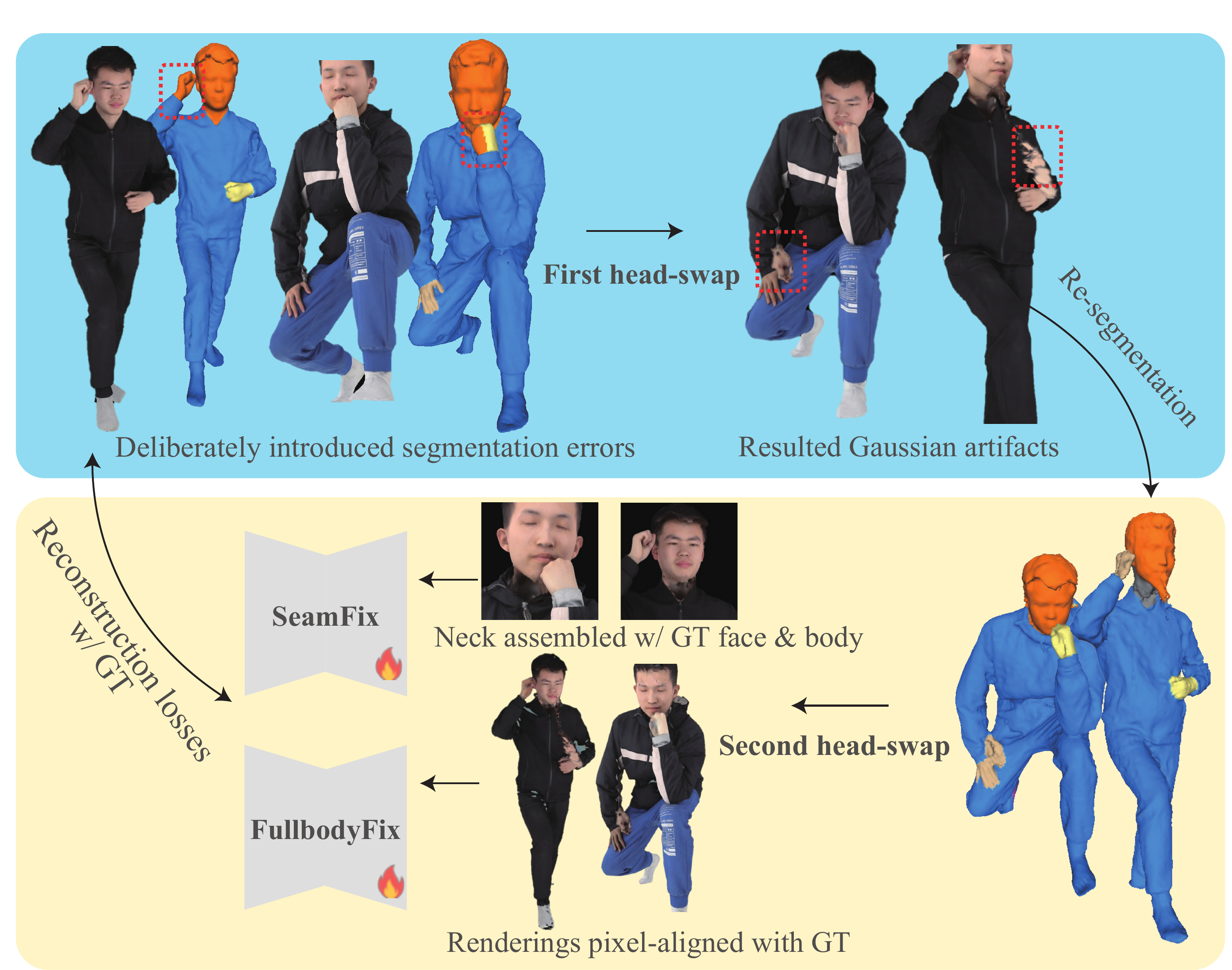
SeamFix is a localized diffusion module that targets only the hair and neck region. Its training data are generated through a double-swapping procedure. Starting from two avatars $A$ and $B$, the pipeline first composes $A \rightarrow B$, then reverses the process with $B \rightarrow A$. This creates realistic seam artifacts without manual annotation. Because the two composition operations return the geometry to alignment with the ground truth, the rendered double-swapped head and neck can serve as noisy inputs while the original avatar renderings provide supervision.
The paper also augments training by using 2D segmentation masks extracted from the second swap rendering. These masks may have missing neck pixels, which helps simulate real segmentation failures. The refinement crop includes the head and neck, with a dilated boundary to provide collar context. At inference, the refined crop is pasted back into the original image using feathered blending.
4.2 FullbodyFix
FullbodyFix is an optional full-body restoration module used when body reshaping visibly degrades the clothed body. It is trained on full-body renders from double-swapped avatars, which contain a mixture of garment and skin artifacts induced by repeated composition. Unlike SeamFix, it restores the full human region rather than only the seam. The paper notes that FullbodyFix is applied manually in the current implementation when visual inspection suggests it is needed; no automatic trigger is used.
4.3 Backbone and Training Design
Both SeamFix and FullbodyFix are implemented on top of the pretrained Difix3D+ backbone. The paper freezes the original Difix LoRA weights and adds new trainable LoRA adapters to the UNet and VAE decoder. The two refinement modules share this structure but use different adapter capacities: SeamFix uses rank-8 adapters, while FullbodyFix uses rank-16 adapters. The supplementary material further states that rank-4 LoRA adapters are attached to the VAE decoder and that the VAE skip connections are fine-tuned in the Difix3D style.
In the supplementary implementation details, SeamFix is trained for 10 epochs and FullbodyFix for 5 epochs on approximately 19k multi-view double-swapped samples generated from the THUman2.0 training subjects, with batch size 1. SeamFix operates on a cropped square head-and-neck region resized to $512 \times 512$, and FullbodyFix uses a tight body crop resized to $488 \times 896$. Training is done on a single NVIDIA RTX A6000 Ada GPU, taking roughly 16 hours for SeamFix and 28 hours for FullbodyFix.
5. Experimental Setup
5.1 Dataset and Pair Construction
Evaluation is performed on the THUman2.0 dataset, which contains 526 reconstructed clothed human subjects with diverse body shapes, clothing styles, and poses. Following the split used by VTON360, the paper uses 110 subjects as the test set and the remaining subjects for training the reconstruction and diffusion networks. For the 110 test subjects, the authors create user–model pairs by random identity/garment sampling and render 36 viewpoints per pair. AvatarMix and VTON360 are evaluated on all test pairs and all 36 views; TIP-Editor is evaluated on a subset of pairs under the same view protocol.
5.2 Baselines
The paper compares against two recent baselines that address related but not identical tasks: VTON360 and TIP-Editor. VTON360 performs 3D virtual try-on by applying upper garments to target avatars via per-view 2D generation followed by 3D lifting. TIP-Editor is a localized 3D Gaussian splatting editing method that can be configured for head replacement. AvatarMix differs in that it performs explicit cross-avatar identity transfer with body-shape adaptation and seam/appearance refinement.
5.3 Metrics
Three quantitative metrics are reported on per-view edited images, plus a user study. Editing Target DINO measures preservation of the edited region using DINO similarity against the relevant reference: the upper garment for VTON360 and the clothed body for AvatarMix. Head and Neck DINO measures facial identity and seam quality using a head-and-neck mask against the ground-truth user avatar. Warping-based RMSE measures multi-view consistency by warping neighboring views into each other using dense correspondences and computing image-space RMSE. Lower RMSE indicates better view consistency. The paper explains that the CLIP Direction Consistency Score used by VTON360 is not well matched to the identity-transfer setting because pose and body changes can occur, so the authors choose a more direct image-space metric.
The user study involves 23 participants and asks forced-choice questions over 15 identity-transfer cases per participant, covering overall realism, view consistency, and facial/seam quality.
6. Quantitative Results
On THUman2.0, AvatarMix reports the best result on every metric it is evaluated on. The numbers below are taken directly from the paper’s main quantitative table.
| Method | Editing Target DINO $\uparrow$ | Head+Neck DINO $\uparrow$ | Warping RMSE $\downarrow$ | Vote Overall $\uparrow$ | Vote Consistency $\uparrow$ | Vote Facial $\uparrow$ |
|---|---|---|---|---|---|---|
| VTON360 | 0.633 | 0.786 | 0.0276 | 8.70% | 10.43% | 7.83% |
| TIP-Editor | N/A | 0.356 | 0.0388 | 2.61% | 2.61% | 0% |
| AvatarMix | 0.883 | 0.818 | 0.0175 | 88.69% | 86.96% | 92.17% |
The paper’s interpretation is straightforward: AvatarMix preserves the edited region better than the baselines, preserves head/neck identity better than the baselines, and yields the lowest warping RMSE, which indicates stronger multi-view consistency. The user study mirrors the quantitative results, with AvatarMix receiving overwhelming preference for overall realism, consistency, and facial quality.

The qualitative comparisons emphasize three recurring strengths: the user’s facial identity is preserved, SeamFix removes visible neck discontinuities, and the outfit remains close to the source model garment. The comparison also shows that VTON360 can introduce view inconsistency and garment artifacts, while TIP-Editor can preserve only the head region and does not solve outfit personalization in the same way.

7. Ablation Findings
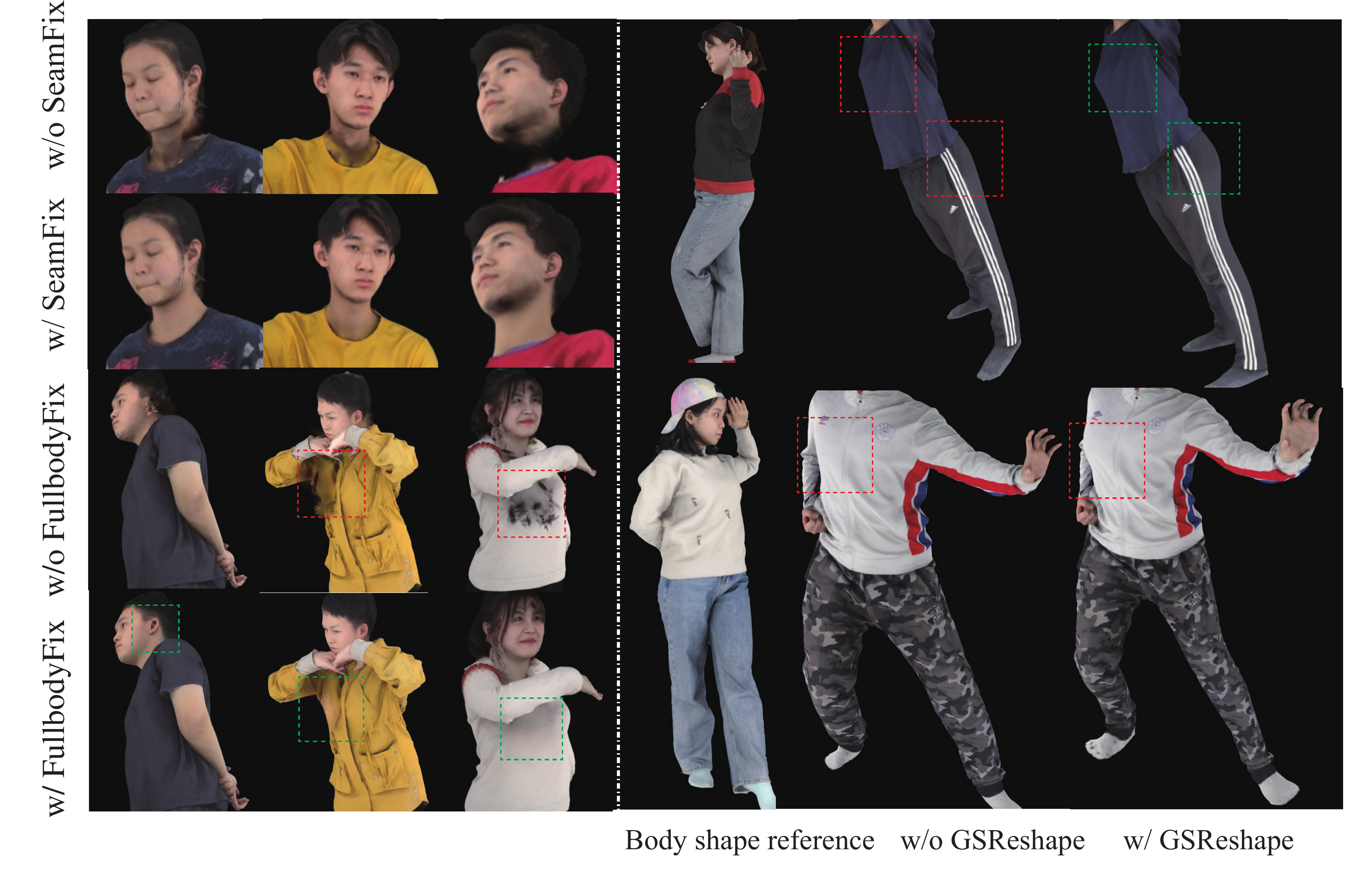
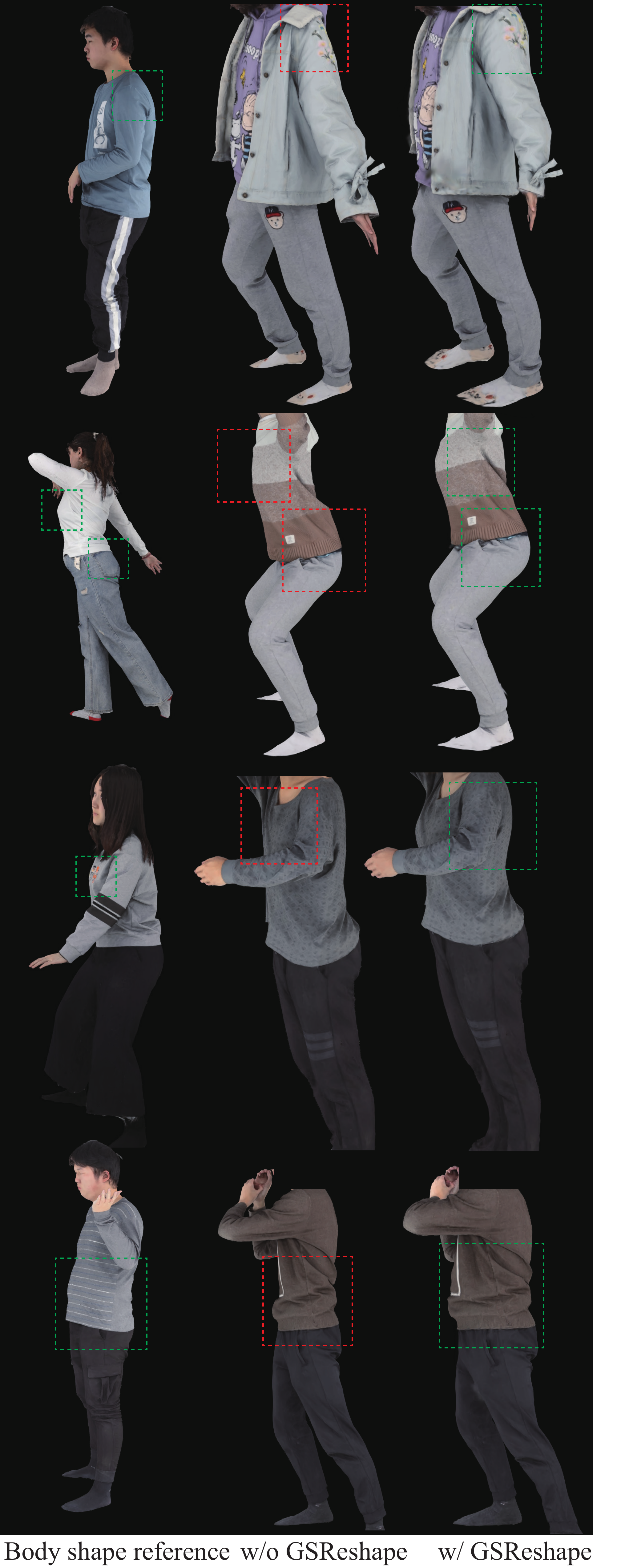
The ablation study isolates the effect of the two refinement modules and GSReshape. Without SeamFix, the head–neck join exhibits visible artifacts; adding SeamFix cleans the seam while leaving the unaffected regions intact. Without FullbodyFix, some examples keep the garment appearance degradation introduced by body reshaping; FullbodyFix restores the outfit more faithfully. On the geometric side, removing GSReshape leaves the model body shape largely unchanged and can lead to poor fit for the user physique, whereas GSReshape adapts the garment and body consistently, producing smoother alignment to the user’s shape while preserving clothing details.
The supplementary hand examples further support the claim that the semantic weighting strategy in GSReshape strikes a better balance than either extreme: overly strong fit weights can cause Gaussian artifacts, while overly weak weights produce glove-like hands. The paper’s chosen design reduces these failures but does not fully model hand-shape adaptation.
8. Limitations and Future Work
The paper is explicit about two limitations. First, GSReshape does not explicitly model detailed hand-shape adaptation, so extreme body-shape differences can still create mismatches around the hands. Second, very loose garments or highly complex accessories may remain difficult for the retargeting stage and can lead to wrinkles or folds that differ from the original model outfit.
The authors suggest two future directions: evaluating on datasets beyond THUman2.0 to test generalization across broader clothing styles, and extending the framework to avatar reposing from reconstructed 3D Gaussians so that users can control pose after personalization.
9. Takeaway
AvatarMix’s main contribution is a practical paradigm shift: it treats outfit personalization as a composition problem over high-fidelity 3D Gaussian avatars rather than as 2D garment synthesis or layered 3D garment modeling. By combining explicit geometric composition, mesh-based body reshaping, and diffusion-based seam/full-body refinement, the method achieves stronger identity preservation, better garment fidelity, and better multi-view consistency than the reported baselines on THUman2.0.