DyaPlex
DyaPlex: Full-Duplex Speech-Motion Model for Dyadic Interaction
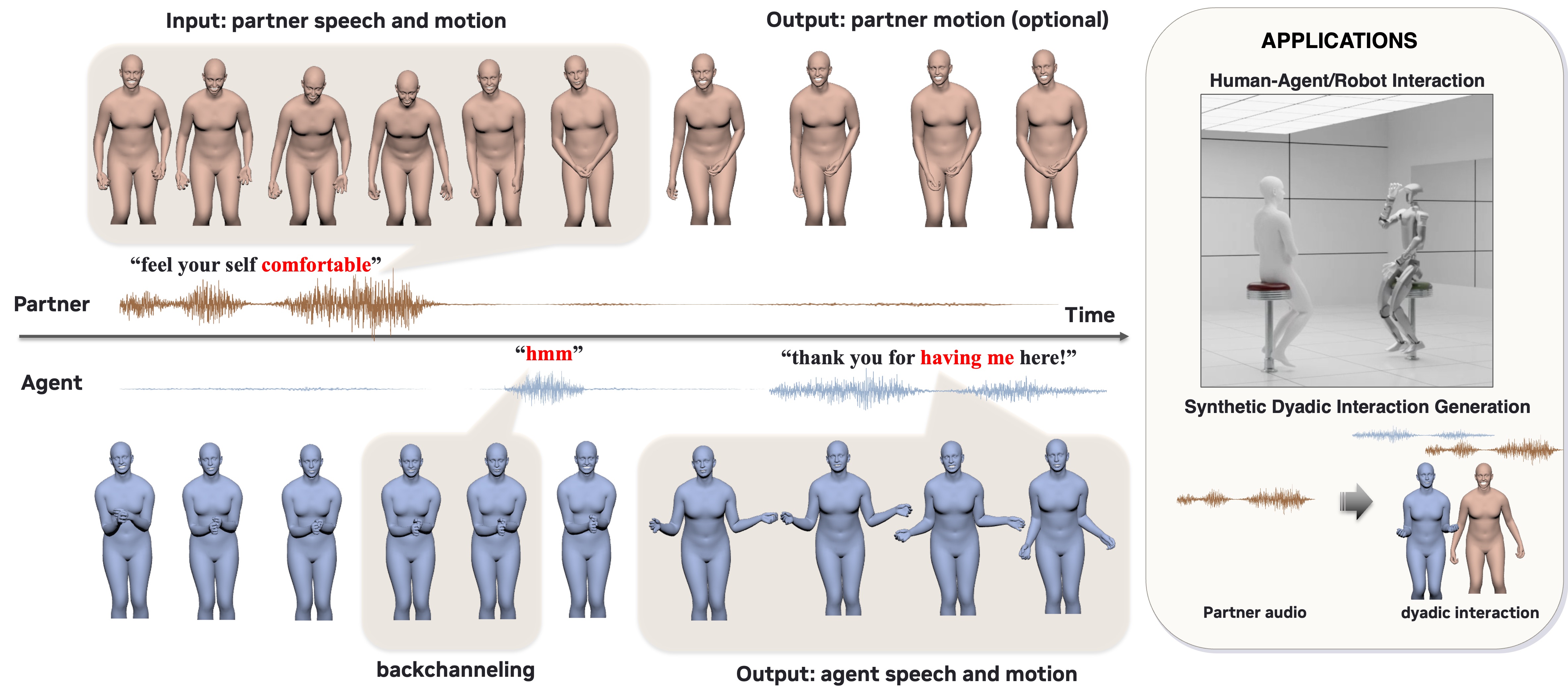
DyaPlex is a streaming full-duplex model that generates synchronized speech and full-body motion for dyadic interactions. It perceives and responds to both partners' speech and motion in real time, enabling natural continuous communication with improved multi-modal coherence for conversational AI agents.
Demos
These demos highlight DyaPlex's ability to generate synchronized speech and motion in real-time dyadic interactions. Watch for its full-duplex capability to listen and speak simultaneously with coherent gestures, including reciprocal behaviors like gesture mirroring and visual backchanneling. The demos also show applications in human-robot interaction and synthetic dyadic data generation, plus comparisons to baseline methods.
Links
Paper & demos
Abstract
We present DyaPlex, a streaming, full-duplex speech-and-motion model designed for dyadic interaction. To capture the continuous and reciprocal nature of human communication, this full-duplex capability empowers the agent to simultaneously perceive and generate both speech and physical motion in a streaming fashion. At its core, our method leverages the strong priors of a foundational full-duplex speech model and integrates a novel motion pathway, thereby achieving fully synchronized multi-modal interaction. Specifically, we design a dual-tower Transformer architecture that preserves the zero-shot conversational reasoning of a frozen base speech model while constructing a deeply coupled, streaming motion pathway. By introducing a unified dyadic token interleaving mechanism and guiding cross-attention via a time-aligned speech-motion RoPE, our model effectively aligns autoregressive motions with rich latent speech features. Trained on the 4,000-hour Seamless Interaction dataset, our model effectively captures cross-speaker dependencies and establishes new state-of-the-art performance across both monadic and dyadic human interaction benchmarks.
Introduction
DyaPlex addresses streaming, full-duplex speech-and-motion generation for dyadic interaction. The core problem is that natural conversation is not a turn-based exchange of isolated utterances, but a continuous closed loop in which each participant simultaneously perceives speech, perceives body motion, and produces their own speech and motion responses. The paper argues that previous dyadic systems typically miss at least one of these ingredients: some are high quality but offline and non-causal, some stream speech but not motion, and some model motion only for a single person rather than for both speakers in a reciprocal conversational setting.
The proposed system combines a frozen full-duplex speech backbone, PersonaPlex, with a trainable motion tower that consumes both the partner's motion and the speech model's internal hidden states. The result is a causal model that can be used in two modes: both-speaker mode for synthetic dyadic data generation, and agent-only mode for human-agent or robot interaction where the partner motion is observed and the agent motion is generated autoregressively. The paper's central claim is that this is the first model to make the motion pathway itself full-duplex: it both perceives partner motion and generates agent motion in a streaming fashion, while also inheriting full-duplex speech from the frozen speech tower.
The model is trained on the large-scale Seamless Interaction corpus, and the paper reports new state-of-the-art results on both monadic motion realism and dyadic interaction metrics. The design choices that make this possible are: a dyadically interleaved motion token stream, a time-aligned speech-motion rotary embedding for cross-attention, and a causal RVQ-VAE tokenizer that aligns motion tokens to the same $12.5$ Hz rate as the speech tokens.
Problem setting and high-level design
The paper frames dyadic interaction as time-aligned autoregressive generation for two interacting partners, denoted $A$ (the partner) and $B$ (the agent). At each frame $t$, the speech model receives Mimi tokens for both speakers, $\mathbf{s}^A_{1:T}$ and $\mathbf{s}^B_{1:T}$, sampled at $f_s = 12.5$ Hz. The motion side uses RVQ-VAE codes $\mathbf{m}^A_{1:T}$ and $\mathbf{m}^B_{1:T}$, also at $f_m = 12.5$ frames per second, so the architecture can align the two modalities on a shared temporal axis.
The overall architecture has three pieces:
- a frozen PersonaPlex speech tower that exposes per-layer residual-stream hidden states,
- a body-part-aware streaming RVQ-VAE tokenizer/decoder that converts motion into discrete codes, and
- a causal motion tower that autoregressively models a unified dyadic motion sequence and cross-attends to the speech tower at every transformer block.
The paper emphasizes that the key novelty is not merely to condition motion on audio, but to preserve the speech model's conversational reasoning while adding a deeply coupled motion pathway that can represent partner motion and agent motion jointly. This lets the motion generator use speech context and partner motion context together, instead of collapsing them into a single weakly coupled feature stream.
![Architecture overview. DyaPlex consists of three components: (a) part-aware RVQ-VAE decoders and (b) a frozen speech tower, and a trainable motion tower. The speech tower (PersonaPlex) takes in dyadic speech, emits agent speech autoregressively, and exposes its per-layer residual-stream hidden states $\_ \_ =1^32$. For training, we precompute $\_ $ once ( ) to serve as cross-attention keys and values for the motion tower. The $32$-layer causal motion tower ($d_m=1024$, $h_m=16$) operates on a dyadically interleaved stream at $12.5$\,fps: $[ , ^A_t, , ^B_t, ]$. Each block applies dyadic causal self-attention on the motion stream, followed by cross-attention to the speech states using a learned projection ($h_c=12$, $d_c=64$) and time-aligned speech-motion RoPE. The LM head outputs motion tokens (supervised on 18 SMPL-H body codes for our body-only base model) at $12.5$\,fps, which the RVQ-VAE decoders with $2 $ temporal upsampling then finally reconstruct into SMPL-X pose parameters at 25\,fps.](https://akapulu-public-assets.s3.us-west-1.amazonaws.com/blogs/research-digest/p/2606.03874/arxiv/fig/fig/pipeline.jpg)
Representations and preprocessing
DyaPlex uses two tokenizers: the frozen Mimi speech codec and a causal body-part-aware RVQ-VAE for motion. The motion tokenizer is adapted from GestureLSM and is retrained on Seamless Interaction. The paper modifies it so that a $25$ fps motion stream is downsampled by $2\times$ to a $12.5$ Hz token stream, exactly matching the speech token rate. On decode, the tokenizer upsamples back to $25$ fps.
The motion representation is part-aware and split into four independent codec streams: upper body, hands, lower body plus translation, and face. The body-only base model used for the main experiments supervises $18$ body code positions per frame, corresponding to the SMPL-H body and hands annotations that Seamless provides. A separate face-aware variant is described in the appendix and used only for qualitative face demonstrations.
The per-part codec design is summarized as follows:
| Part | Input dim | Joints / fields | Quantizers | Codebook band |
|---|---|---|---|---|
| Upper | 78 | 13 joints $\{3, 6, 9, 12{-}21\} \times 6$D rotation | $K_b = 6$ | $[0, 1024)$ |
| Hands | 180 | 30 joints $\{25{-}54\} \times 6$D rotation | $K_b = 6$ | $[1024, 2048)$ |
| Lower + translation | 57 | 9 joints $\{0,1,2,4,5,7,8,10,11\} \times 6$D rotation + $3$D translation velocity | $K_b = 6$ | $[2048, 3072)$ |
| Face | 56 | 6D jaw rotation + $50$D FLAME expression | $K_f = 4$ | $[3072, 4096)$ |
Each part has its own encoder, decoder, and codebook; the four streams are only unified at the motion-tower input by interleaving their token IDs into one shared vocabulary of size $V_{\text{mot}} = 4096$. The appendix also states that the encoders are made causal by left-padding dilated convolutions, and that the temporal downsampling is reduced from $4\times$ to $2\times$ so that the token rate becomes $12.5$ Hz and aligns one-to-one with speech.
The paper applies several dataset filters before training. At the clip level, it removes landscape, rotated, unreadable, or corrupt clips, dropping approximately $1.5\%$ of dyadic pairs. At the frame level, frames with invalid HMR2 fits are masked out; about $2.4\%$ of frames fail this validity check, and pairs with fewer than $8$ valid frames after masking are removed entirely. For the face experiments, SPECTRE-extracted FLAME parameters are also filtered: any pair with at least $20\%$ zero-face frames in either speaker is excluded from the face-codec training subset.
Speech tower and motion tower coupling
The speech side is PersonaPlex, a causal Transformer built on Moshi and kept frozen throughout training. It uses hidden dimension $d_s = 4096$ and $L_s = 32$ layers. PersonaPlex receives a hybrid prompt format containing both text and voice priors, and at every block exposes residual-stream hidden states $\mathcal{H}_\ell \in \mathbb{R}^{T \times d_s}$. DyaPlex uses all $32$ layers rather than a single final embedding, so the motion tower can attend to a hierarchy of speech representations rather than one compressed summary.
The motion tower is a causal decoder-only Transformer with $L_m = 32$ layers, model width $d_m = 1024$, $16$ self-attention heads, RoPE self-attention, and SwiGLU feed-forward layers. It uses a shared token embedding matrix and a vocabulary consisting of the motion code vocabulary plus two special speaker tags, $\mathtt{[A]}$ and $\mathtt{[B]}$. The motion stream is flattened into a single interleaved sequence:
$$ \mathbf{M} = [\mathtt{[A]}, \mathbf{m}^A_1, \mathtt{[B]}, \mathbf{m}^B_1, \mathtt{[A]}, \mathbf{m}^A_2, \mathtt{[B]}, \mathbf{m}^B_2, \dots]. $$
Since each motion frame contains two speaker tags and $K = 22$ RVQ codes per speaker, the flattened step length is $L_{\text{step}} = 2(K+1) = 46$ tokens. This interleaving gives causal self-attention access to three kinds of structure at once: within-speaker code coherence, immediate cross-speaker reactions within the same frame, and long-range temporal continuity across frames. The paper explicitly notes that this makes the two sides of a dyad share a single autoregressive motion prior, which is a major difference from models that only predict one speaker's motion from the other's speech.
Cross-attention is used to inject speech context into every motion block. Each motion block is paired one-to-one with the corresponding PersonaPlex layer. Queries come from the motion stream, while keys and values are projected from the speech hidden states using learned matrices. The cross-attention uses $12$ heads of dimension $64$ per head. In other words, the motion tower does not merely concatenate audio features; it learns a structured cross-modal retrieval mechanism over the speech tower's internal latent states.
The crucial alignment mechanism is the paper's time-aligned speech-motion RoPE. Each motion token is assigned a query position equal to its frame index,
$$ q_{\text{pos}}(t) = \left\lfloor \frac{t}{L_{\text{step}}} \right\rfloor, $$
and rotary positional embeddings are applied to queries and keys using these positions. Because the speech and motion streams run on the same $12.5$ Hz clock, the relative offset between a motion token and a speech token directly expresses whether the motion is attending to the current frame or the past. The paper says this creates a strong inductive bias toward diagonal alignment, so that each motion frame prefers to attend to the concurrent speech frame instead of learning the alignment implicitly from scratch.
A causal mask ensures that motion tokens can only attend to speech frames at or before their own frame index, which preserves real-time streaming behavior. The receptive field is bounded to a $4096$-token speech context, corresponding to $89$ frames or about $7.1$ seconds at $12.5$ fps. The paper argues that this preserves strict causality while still allowing a reasonably long spoken context window.
Training objective and optimization
DyaPlex is trained by teacher forcing over the flattened dyadic token stream. The main objective is masked next-token cross-entropy on the valid supervised motion positions, with out-of-band logits set to $-\infty$ so that the model cannot assign probability mass to impossible codes from the wrong RVQ band. The core loss is:
$$ \mathcal{L}_{\mathrm{CE}}(\theta) = -\sum_{t \in \mathcal{S}} \log p_\theta(x_{t+1} \mid x_{\le t}; \{\mathcal{H}_\ell\}), $$
where $\mathcal{S}$ is the set of supervised body code positions. The paper uses a body-only base model for the main quantitative results; the face-predicting variant is reserved for supplementary qualitative examples.
In addition to next-token prediction, the model includes a voice-activation head that predicts the speaking/listening state $v_t$ at each valid code position. This contributes a binary cross-entropy auxiliary loss $\mathcal{L}_{\mathrm{VA}}$, and the final objective is:
$$ \mathcal{L} = \mathcal{L}_{\mathrm{CE}} + \beta \mathcal{L}_{\mathrm{VA}}, \qquad \beta = 0.01. $$
The appendix gives the motion-tower training recipe: AdamW with $\beta_1 = 0.9$, $\beta_2 = 0.95$, weight decay $0.1$, gradient clipping at $1.0$, learning rate $3 \times 10^{-4}$, effective batch size $512$, and training on $64$ NVIDIA H100 GPUs for $30$K iterations. The inference recipe uses streaming autoregressive sampling with temperature $1.0$; the main method section describes top-$k$ sampling with $K_{\text{top}} = 200$, while the appendix summarizes inference as using no top-$k$ truncation.
During training, speech hidden states are precomputed in a teacher-forced pass through the frozen speech tower. During inference, the speech states are produced autoregressively online. This keeps the entire system streaming from the audio input through the final motion decoding stage.
Streaming inference modes
The paper distinguishes between two deployment settings. In both-speaker mode, the model autoregressively samples motion tokens for both $\mathtt{[A]}$ and $\mathtt{[B]}$ slots, which is useful for generating fully synthetic dyadic interaction data. In agent-only mode, the observed partner-motion prefix is copied into the $\mathtt{[A]}$ slots and the model samples only the agent's $\mathtt{[B]}$ motion tokens. This is the mode relevant for live human-agent or robot interaction.
The paper stresses that strict causality is maintained end to end: the speech tower is causal, the motion tower is causal, and the part-aware RVQ decoders are also causal. Therefore the entire pipeline can be executed chunk-wise in real time.
Datasets, filtering, and evaluation protocol
The main dataset is Seamless Interaction, a roughly $4000$-hour corpus of dyadic conversations. After filtering invalid and corrupted data, the paper reports $57{,}947$ usable training pairs, corresponding to $3435$ hours of dyadic motion. For evaluation, a $330$-pair test subset is used, totaling about $18$ hours, and the first $20$ seconds of the test set are used for the reported metrics. Audio and motion are both tokenized at $12.5$ Hz using Mimi and the causal RVQ-VAE, respectively.
The paper compares DyaPlex against two retrained baselines on the same Seamless body dataset: Audio2Photoreal and DualTalk. Audio2Photoreal represents a diffusion-based offline approach, while DualTalk represents a transformer-based dyadic model. The paper also includes ground-truth references and a randomly paired ground-truth baseline for the dyadic metric.
Evaluation metrics are grouped into monadic and dyadic categories. For monadic quality, the paper reports Fr\'echet distance on raw $22 \times 3 = 66$-D joint positions per frame (FGD), diversity measured as the mean pairwise $L_2$ distance between randomly sampled frames, and BeatAlign for audio-motion synchronization. For dyadic quality, the paper reports Paired Fr\'echet Distance (P-FD) on the concatenated two-person motion vector of size $132$, plus $\Delta$-User, which measures how much P-FD changes when the partner-motion track is shuffled. The main text defines $\Delta_{\text{User}}$ as the relative P-FD improvement from matched to shuffled user motion; baselines that do not use partner motion by design have $0\%$.
The paper evaluates all methods at $25$ fps, sets root translation to zero for all methods, and uses only the $22$ SMPL-X body joints for these metrics, excluding hands and face. The ground-truth body joints are obtained from the Seamless SMPL-H annotations via SMPL-X forward kinematics.
Main quantitative results
DyaPlex achieves the best overall performance among the reported methods on both monadic and dyadic criteria. The paper highlights that it is best on FGD and P-FD, second-best on BeatAlign, and closest to ground truth on the diversity metric among the learned models. The authors also use the random ground-truth pairing baseline to verify that P-FD behaves as intended: pairing mismatched two-person motions substantially worsens the score.
| Method | FGD $\downarrow$ ($\times 10^{-3}$) | Diversity $\rightarrow$ GT | BeatAlign $\rightarrow$ GT | P-FD $\downarrow$ ($\times 10^{-3}$) | $\Delta$-User $\uparrow$ |
|---|---|---|---|---|---|
| GT | --- | 0.633 | 0.049 | --- | --- |
| GT (Random) | 13 | 0.683 | 0.050 | 33 | 0\%$^\dagger$ |
| Audio2Photoreal | 57 | 0.395 | 0.051 | 72 | 0\%$^\dagger$ |
| DualTalk | 161 | 0.305 | --- | 163 | +0.3\% |
| w/o Self-Attn | 41 | 0.416 | 0.132 | 45 | 0\%$^\dagger$ |
| w/o Partner | 39 | 0.725 | 0.064 | 41 | 0\%$^\dagger$ |
| w/o Cross-Attn | 41 | 0.708 | 0.080 | 44 | +15\% |
| w/o Cross-RoPE | 8.4 | 0.582 | 0.064 | 10 | +31\% |
| DyaPlex (body-only) | 5.6 | 0.611 | 0.059 | 7.3 | +31\% |
The strongest monadic gains are seen in FGD, where the body-only DyaPlex model reaches $5.6 \times 10^{-3}$, much better than Audio2Photoreal's $57 \times 10^{-3}$ and DualTalk's $161 \times 10^{-3}$. On the dyadic side, DyaPlex reaches a P-FD of $7.3 \times 10^{-3}$, far below the baselines. The paper also reports that DualTalk collapses to a near-constant pose on this dataset, which explains its poor FGD and P-FD and its undefined BeatAlign.
Ablations and interpretability analyses
The ablation table isolates the contribution of each architectural decision. Removing motion self-attention substantially harms all metrics, indicating that the unified dyadic motion sequence is not optional: the model needs self-attention over the interleaved partner/agent stream to capture both within-speaker and cross-speaker dependencies. Removing partner motion also degrades results sharply, confirming that the model is genuinely using the observed partner's body motion rather than relying only on speech.
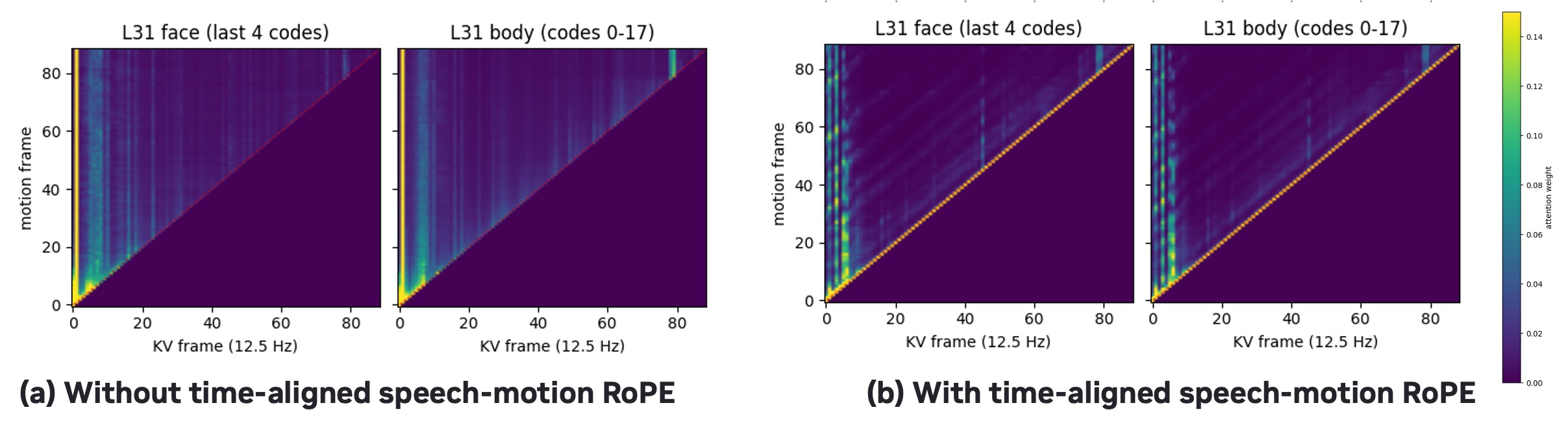
The paper gives two more important ablations: removing cross-attention and removing the time-aligned speech-motion RoPE. Both reduce speech-motion synchronization, but the RoPE removal is especially informative. The supplement visualizes the cross-attention map and shows that without RoPE the motion stream does not cleanly attend to speech at the same time frame, whereas with RoPE the attention becomes diagonally aligned. This supports the paper's claim that time alignment is not just a convenience, but a useful inductive bias that the model exploits.
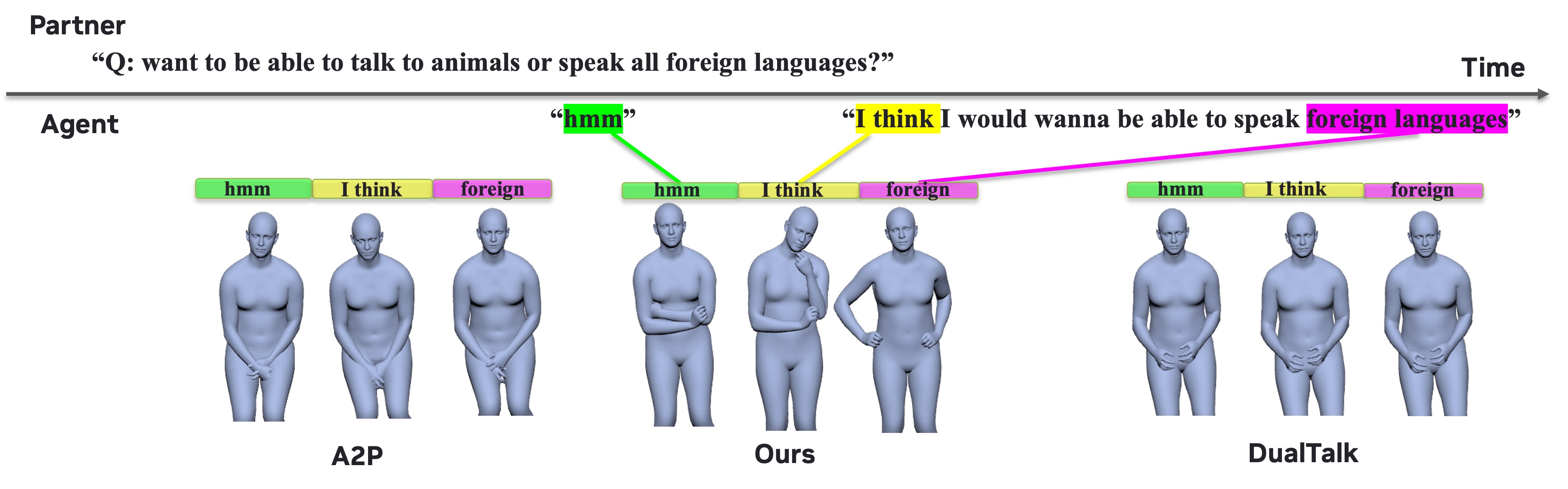
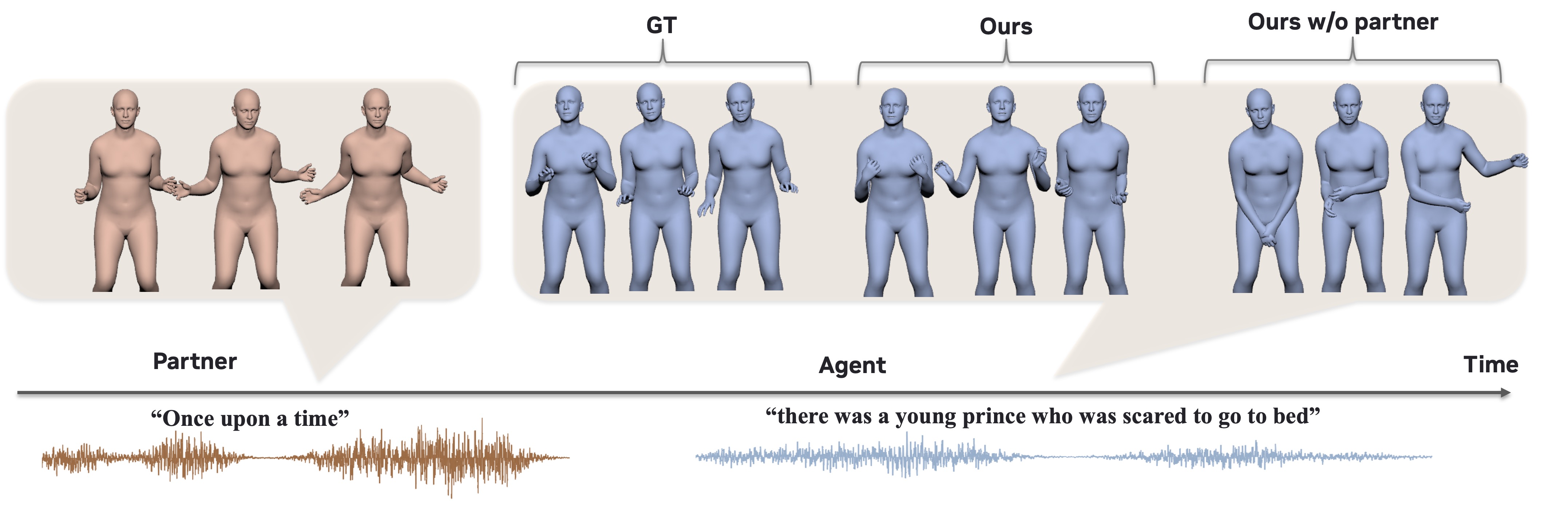
The qualitative comparisons reinforce the metric results: DyaPlex produces more diverse and conversation-appropriate gestures, while the baselines are either less expressive or collapse toward repetitive motion. The paper also notes that its agent-only mode can mirror partner gestures and support reciprocal behavior in a way that models without partner-motion perception cannot.
User study and runtime
The user study uses a web-based interface that plays two comparison videos side by side, with the participant able to toggle independently between them. The videos render the partner mesh in peach and the generated agent in blue, and the audio is split so that the partner is on the left channel and the generated agent on the right channel. Participants are instructed to focus on body motion and to ignore face and audio. Thirty-two participants compared DyaPlex against ground truth, Audio2Photoreal, and DualTalk.
The reported preferences for DyaPlex are $29.4\%$ versus ground truth, $66.3\%$ versus Audio2Photoreal, and $97.5\%$ versus DualTalk. The authors interpret this as strong perceptual evidence that the model produces more natural motion than the baselines, while still being distinguishable from real data in direct comparison with the ground truth.
Runtime is also reported. On a single RTX A6000 Ada GPU at $12.5$ Hz, the speech tower runs in about $30$ ms per frame and the RVQ-VAE decoder in about $0.8$ ms per frame. The motion tower is the bottleneck at $173$ ms per frame when using the full $4096$-token context. Reducing the motion context to $1024$ tokens, while keeping the full $7.1$ s speech context, lowers motion-tower latency to $80$ ms per frame and enables real-time inference.
Limitations, future work, and societal impact
The paper is explicit about several limitations. First, the model currently decodes one body token at a time for $22$ codes, which may not be optimal for inference speed. The authors suggest that chunk-by-chunk decoding, for example decoding multiple upper-body tokens at once, could improve deployment performance. They also mention a possible depth-transformer-based design similar to Moshi as another route to faster inference, and they note that diffusion backbones could be worth exploring as an alternative generative design.
Second, the current system handles only two users. Extending the approach from dyadic to polyadic interaction is identified as future work. This is a meaningful limitation because many real social settings involve more than two participants.
The appendix also discusses potential negative societal impacts. DyaPlex itself generates generic SMPL-X body parameters rather than photorealistic pixels, so it does not directly output identity-bearing video. However, the generated motion could be paired with identity-conditioned downstream video diffusion systems to fabricate realistic-looking dyadic videos, creating a deepfake risk. The authors argue that one mitigation is that the model is identity-agnostic: it is not conditioned on a subject identifier, so impersonating a specific person would require an additional avatar or voice pipeline. They also note that the frozen speech tower is used in its public release configuration and is not fine-tuned toward specific real-world voices.
On the positive side, the paper positions the model as useful for scalable synthetic dyadic interaction data, social robotics, and embodied conversational agents that need low-latency, reciprocal speech-and-motion behavior.
Takeaway
The technical contribution of DyaPlex is the combination of three ingredients: a frozen full-duplex speech backbone, a causal dyadically interleaved motion transformer, and time-aligned speech-motion rotary embeddings. Together these let the model preserve streaming conversational reasoning while adding full-body motion perception and generation on both sides of the interaction. The empirical results show that the design matters: partner-motion perception, cross-attention, and temporal alignment all produce measurable gains, and the full system achieves the best reported performance on the Seamless dyadic benchmarks in this paper.