READ
Read What You Hear: Reference-Free Hypotheses Evaluation with Acoustic Discrepancy
READ is a reference-free metric that evaluates ASR hypotheses by measuring acoustic discrepancy between speech and text using a pretrained autoregressive TTS model. It uniquely grounds evaluation in the speech signal, enabling effective hypothesis refinement and error localization without extra training.
Links
Paper & demos
Impact
Abstract
Automatic speech recognition systems commonly rely on reference transcriptions for evaluation, while reference-free approaches often depend on internal confidence estimation or auxiliary language models. We propose READ (Reference-free Hypothesis Evaluation with Acoustic Discrepancy), a novel metric that evaluates ASR hypotheses directly from the speech signal. READ emphasizes the acoustic grounding of hypotheses. It uses a pretrained auto-regressive TTS model to compute the conditional likelihood of speech tokens given a text hypothesis, to measure fine-grained acoustic discrepancy between speech and text. Without additional training, READ can be applied for hypothesis refinement. Experiments show that READ correlates with specific recognition errors and improves ASR outputs, achieving up to 20\% relative error rate reduction, with particularly strong gains under noisy conditions.
1. Problem Setting and Motivation
The paper addresses ASR hypothesis evaluation when reference transcripts are unavailable. In that setting, a system still needs a way to decide which hypothesis is better, where errors occur, and how to refine outputs without supervision. The authors argue that common reference-free alternatives are incomplete: internal confidence scores are often poorly calibrated, language-model rescoring measures only linguistic plausibility, and quality-estimation models usually require supervised training and provide limited localization of specific errors.
The core motivation behind READ is to restore the role of the acoustic model in evaluation. Rather than asking whether a hypothesis is simply fluent, READ asks whether the observed speech can be acoustically grounded by that hypothesis. This follows an analysis-by-synthesis perspective: if the transcript is faithful to the utterance, a generative speech model should be able to explain the corresponding speech tokens with high likelihood.
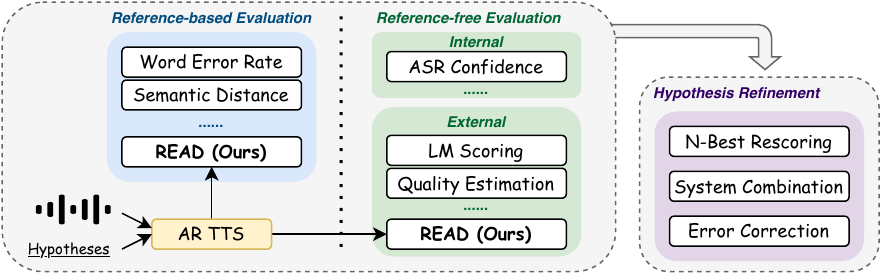
The resulting method, READ (Reference-Free Hypotheses Evaluation with Acoustic Discrepancy), is presented as a training-free, model-agnostic metric that can be used both for scoring hypotheses and for improving them through rescoring or system combination.
2. Method: Acoustic Discrepancy from an Auto-Regressive TTS Model
2.1 Core scoring idea
READ is built on a pretrained auto-regressive text-to-speech model that works over discrete speech tokens. Let $X=(X_1,\dots,X_N)$ be a text token sequence and $Y=(Y_1,\dots,Y_T)$ be a speech-token sequence. The TTS model defines the causal conditional distribution $P_\theta(Y_t \mid X, Y_{<t})$.
In teacher-forcing mode, the model assigns each speech token a conditional likelihood
$$\ell_t(x,y)=P_\theta(Y_t=y_t \mid X=x, Y_{<t}=y_{<t}).$$
READ turns this likelihood into an acoustic discrepancy score:
$$\operatorname{READ}_t(x,y)=-\log \ell_t(x,y), \qquad \operatorname{READ}(x,y)=\sum_{t=1}^{T}\operatorname{READ}_t(x,y)=-\log P_\theta(y\mid x).$$
Thus, the global READ score is the negative conditional log-likelihood of the speech tokens given the text hypothesis, while the per-token sequence $\operatorname{READ}_t$ forms a localized discrepancy map over time. Lower READ means the speech is better explained by the hypothesis.
2.2 Why this is different from confidence or LM rescoring
The paper frames READ as an external evaluation signal rather than an internal decoder confidence. Compared with confidence estimation, it does not depend on the ASR model’s own posterior calibration. Compared with LM rescoring, it uses the speech signal directly rather than only text fluency. Compared with supervised quality estimation, it does not require labeled error data. The key distinction is that READ uses a generative speech model to measure acoustic grounding rather than just linguistic plausibility.
2.3 Locality and alignment back to text
A central claim of the paper is that READ is local: discrepancies in the speech-text pair should create peaks in the corresponding temporal region of $\operatorname{READ}_t$. To transfer these frame-level discrepancy values back onto text spans, the authors extract a monotonic speech-text alignment from the same decoder-only TTS model used for scoring.
The concatenated sequence has length $T+N$, with text tokens first and speech tokens second under causal masking. From the full self-attention matrix, they take the $T\times N$ submatrix from speech positions to text positions, denoted $A\in\mathbb{R}^{T\times N}$. A monotonic alignment $\pi:\{1,\dots,T\}\to\{1,\dots,N\}$ is then found by dynamic programming:
$$\pi^*=\arg\max_{\pi\in\mathcal{M}}\sum_{t=1}^{T}A_{t,\pi(t)},$$
where $\mathcal{M}$ contains monotonic maps satisfying $\pi(t+1)\ge \pi(t)$ and the boundary conditions $\pi(1)=1$ and $\pi(T)=N$.
Once this alignment is available, token-level discrepancy can be aggregated to any text segment:
$$\operatorname{READ}^{\text{text}}_{[n_1,n_2]}=\sum_{t:\,n_1\le \pi^*(t)\le n_2}\operatorname{READ}_t.$$
This gives the method an interpretable diagnostic property: regions of the transcript that are poorly supported by the speech should accumulate larger READ values.
2.4 Refinement modes enabled by READ
The paper uses the same score in three refinement settings:
- Sentence-level rescoring. For an $N$-best list or multiple system outputs, each candidate hypothesis $x^{(i)}$ is scored as $\operatorname{Score}(x^{(i)}\mid y)=-\operatorname{READ}(x^{(i)},y)$. The hypothesis with the smallest acoustic discrepancy is preferred.
- Segment-level combination. Because READ is temporally localized, the authors split utterances into disputed and consensus intervals. Each segment is chosen from the candidate hypothesis with the lowest READ on that segment.
- Integration with ROVER. The segment-level output can be treated as an additional candidate and fed into ROVER, so READ provides a segment-level acoustic prior while ROVER still performs token-level voting.
The segment-level strategy is explicitly greedy and relies on a locality assumption, but the paper reports that more than $98\%$ of merged outputs achieve simultaneous READ reduction within each segment.

3. Experimental Setup
The experiments use CosyVoice2 as the pretrained auto-regressive TTS model and specifically rely on the official checkpoints without any additional training on the evaluation datasets. This is important because the paper’s claim is that the metric comes from the intrinsic knowledge of an off-the-shelf speech generator, not from task-specific adaptation.
The ASR candidate systems include Whisper (medium and large-v3), NVIDIA NeMo, and Qwen2.5-Omni. For $N$-best rescoring, the authors generate candidates using Whisper large-v3 with beam size $60$, then remove duplicates caused by case, punctuation, and timestamps, and keep the top $5$ unique candidates.
Evaluation spans both clean and challenging speech settings. The test sets are LibriSpeech test-clean and test-other for standard English speech; SPGISpeech, Switchboard, and TEDLIUM3 for diverse conversational and read speech; VCTK-noisy for noisy speech; and the Mandarin–English code-switching test sets from ASRU2019 and TALCS. To further stress acoustic robustness, the paper creates noisy variants by adding WHAM! noise at $0$, $10$, and $20$ dB SNR.
The reported metrics are WER for English test sets and MER for code-switching test sets.
4. Results and Analysis
4.1 READ as a reference-based diagnostic metric
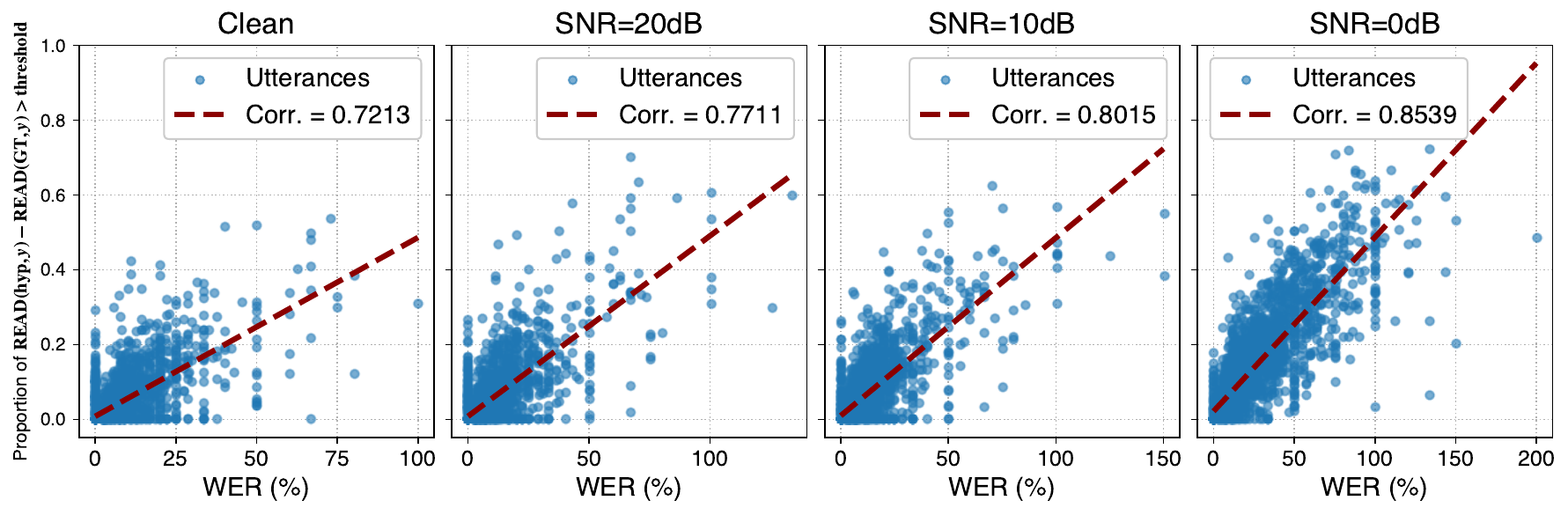
The paper first checks whether READ tracks actual recognition quality when a reference transcript is available. For each hypothesis-reference pair, the authors compare READ sequences and define an error-rate-like statistic based on the proportion of utterance duration where the hypothesis READ exceeds the ground-truth READ by a threshold. Figure 2 shows that this quantity correlates with WER, though not perfectly, because acoustic mismatch and lexical edit distance are not identical notions of error.
A key empirical trend is that the correlation becomes stronger under heavier noise. The interpretation is that as acoustic conditions worsen, recognition failures are more likely to stem from acoustic modeling rather than purely linguistic ambiguity, so a metric that explicitly measures acoustic grounding becomes more predictive of WER.
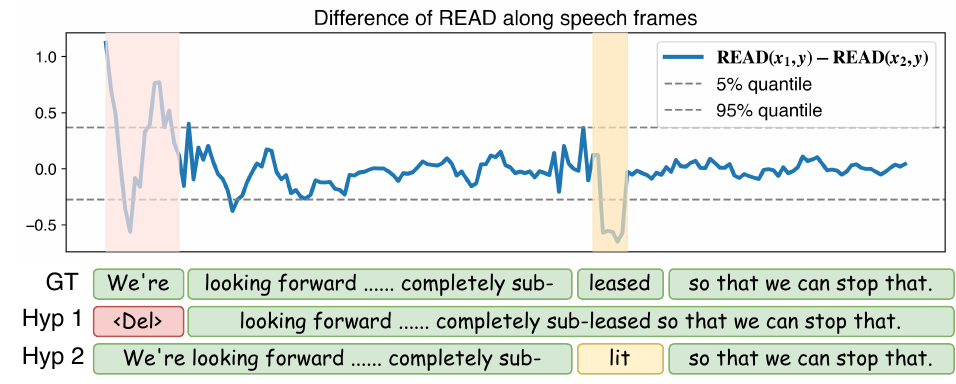
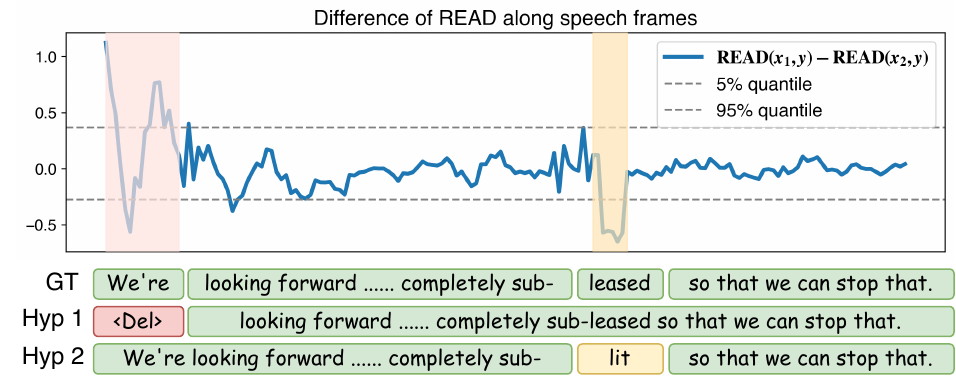
4.2 Locality case study
The paper includes a case study on an utterance from SPGISpeech, comparing one hypothesis from Qwen2.5-Omni and another from Whisper medium. The difference between their $\operatorname{READ}_t$ sequences exhibits clear positive and negative spikes, with each spike aligned to a temporal region where one hypothesis is better supported by the speech than the other.
This is the main qualitative evidence for locality: the discrepancy is not smeared uniformly over the utterance but instead concentrates around the problematic segment. When the alignment extracted from the TTS decoder is applied, those peaks map back to the responsible text spans. The authors note, however, that the capability to cleanly distinguish substitution, deletion, and insertion errors remains to be explored.
4.3 Sentence-level rescoring on $N$-best hypotheses
The first refinement experiment uses Whisper large-v3 $N$-best lists. READ is used purely as a sentence-level score, and the lowest-READ candidate is selected. Across all reported datasets, this rescoring improves over the original top-1 hypothesis from the ASR system.
The table below reproduces the paper’s reported WER values. The main pattern is that READ generally recovers better hypotheses from the candidate list, with especially large relative gains on the more difficult and noisier datasets.
| Dataset | 1st | 2nd | 3rd | 4th | 5th | Rescoring w/ READ | Oracle |
|---|---|---|---|---|---|---|---|
| LS-clean | 2.06 | 2.74 | 3.10 | 3.57 | 4.12 | 1.91 (-7.28%) | 1.15 |
| LS-other | 3.66 | 4.71 | 5.37 | 5.63 | 6.06 | 3.48 (-4.92%) | 2.15 |
| VCTK-noisy | 7.41 | 8.76 | 9.21 | 10.85 | 12.18 | 7.19 (-2.97%) | 6.14 |
| ASRU-test | 9.96 | 11.97 | 12.64 | 13.39 | 14.42 | 9.67 (-2.91%) | 6.20 |
| TALCS-test | 18.94 | 18.56 | 18.57 | 18.93 | 19.69 | 14.98 (-20.91%) | 13.07 |
| SWBD-test | 15.02 | 15.18 | 15.22 | 15.48 | 15.51 | 11.93 (-20.57%) | 10.51 |
| TEDLIUM3-test | 4.22 | 3.95 | 4.26 | 4.51 | 4.69 | 3.40 (-19.43%) | 2.71 |
| SPGI-val | 4.24 | 4.42 | 4.84 | 4.93 | 5.62 | 3.33 (-21.46%) | 2.15 |
The overall takeaway is that READ is effective at ranking candidate transcriptions by acoustic faithfulness. It does not merely reorder candidates arbitrarily: the gains appear consistently across clean, conversational, noisy, and code-switching settings, with the strongest relative improvements on TALCS, Switchboard, TEDLIUM3, and SPGI.
4.4 System combination across multiple ASR systems
The second refinement experiment combines outputs from Whisper large-v3, Whisper medium, NeMo, and Qwen2.5-Omni. Here the paper compares vanilla ROVER, sentence-level selection, segment-level combination, and ROVER augmented with the segment-level READ candidate.
A major result is that the segment-level approach often outperforms sentence-level selection because it exploits the locality of READ, not just the global score. However, the paper also reports that on some datasets the segmented intervals are too long, so the method degenerates toward sentence-level selection. This is one of the reasons the authors present the segment-level scheme as a first step rather than a complete solution.
| Dataset | Whisper large-v3 | Whisper medium | NeMo | Qwen2.5-Omni | ROVER | Sen. | Seg. | R+ |
|---|---|---|---|---|---|---|---|---|
| LS-clean | 2.20 | 2.79 | 1.67 | 1.74 | 1.51 | 1.67 | 1.66 | 1.49 |
| LS-other | 4.16 | 7.52 | 3.65 | 3.45 | 3.18 | 3.39 | 3.35 | 2.97 |
| VCTK-noisy | 8.87 | 18.33 | 2.85 | 2.47 | 1.84 | 2.36 | 2.18 | 1.52 |
| ASRU-test | 10.35 | 11.98 | 21.70 | 8.00 | 9.04 | 7.60 | 7.27 | 7.60 |
| TALCS-test | 16.77 | 20.74 | 44.47 | 9.21 | 20.84 | 9.61 | 8.22 | 16.55 |
| SWBD-test | 12.57 | 14.53 | 5.16 | 12.78 | 10.36 | 5.23 | 5.53 | 8.65 |
| TEDLIUM3-test | 3.37 | 6.69 | 4.21 | 3.91 | 3.85 | 3.27 | 3.34 | 3.71 |
| SPGI-val | 3.60 | 7.25 | 4.40 | 2.76 | 3.15 | 3.14 | 3.01 | 2.80 |
The table shows several useful patterns. On LS-clean, LS-other, VCTK-noisy, and SPGI-val, the ROVER+READ variant is best among the listed combination methods. On ASRU-test, TALCS-test, and TEDLIUM3-test, the segment-level READ combination is strongest. On SWBD-test, sentence-level selection is slightly better than segment-level combination. Overall, the paper’s claim is not that READ always dominates every baseline in every row, but that it provides a consistent and useful acoustic bias that improves system combination in many cases.
The authors also report that ROVER augmented with the READ-based candidate steadily improves upon vanilla ROVER, showing that READ can be complementary to token-level voting rather than only a standalone ranking metric.
4.5 Robustness under noisy speech
The paper further evaluates how combination behaves when the test speech is corrupted by WHAM! noise at $20$, $10$, and $0$ dB SNR. In this experiment, the authors use the direct segment-level combination without ROVER, since ROVER can be sensitive to fragile systems.
The main qualitative observation is that as SNR decreases, the advantage of READ-based combination becomes more visible. This supports the paper’s thesis that acoustic discrepancy is especially useful when recognition errors are driven by difficult acoustic conditions.
| Dataset | SNR = 20 dB | SNR = 10 dB | SNR = 0 dB | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Best | ROVER | Ours | Best | ROVER | Ours | Best | ROVER | Ours | |
| LS-clean | 1.78 | 1.62 | 1.73 | 2.28 | 2.00 | 2.14 | 6.81 | 11.53 | 4.87 |
| LS-other | 4.06 | 3.65 | 3.98 | 5.37 | 4.87 | 5.12 | 17.17 | 21.96 | 16.15 |
| VCTK-noisy | 2.03 | 2.09 | 2.20 | 2.71 | 3.40 | 2.68 | 13.28 | 17.65 | 12.77 |
| ASRU-test | 8.38 | 9.60 | 7.44 | 9.60 | 10.65 | 8.28 | 19.78 | 21.86 | 17.51 |
| TALCS-test | 11.95 | 23.27 | 10.09 | 22.84 | 29.08 | 13.70 | 41.63 | 46.31 | 30.03 |
| SWBD-test | 6.26 | 10.30 | 6.36 | 11.21 | 12.62 | 9.71 | 23.10 | 27.90 | 21.79 |
| TEDLIUM3-test | 3.37 | 3.95 | 3.27 | 3.65 | 4.41 | 4.15 | 7.98 | 14.31 | 7.74 |
| SPGI-val | 3.65 | 3.59 | 3.43 | 4.11 | 4.70 | 4.06 | 11.69 | 18.11 | 11.26 |
The reported trend is clear: at lower SNR, READ-based selection increasingly outperforms the competing combination strategies. The strongest improvements appear on TALCS and the heavily degraded versions of LibriSpeech, where acoustic ambiguity is high and a strong generative speech model is most helpful.
5. What READ Adds Beyond Prior Evaluation and Refinement Methods
The paper’s novelty is not simply that it uses a speech model, but that it repurposes a pretrained discrete auto-regressive TTS model as a reference-free evaluator. The metric is model-agnostic, requires no error-labeled training, and is directly tied to the speech signal rather than to decoder confidence or text fluency alone. This makes READ suitable for scenarios where the system must assess and revise its own output without access to references.
Another important contribution is the local, interpretable nature of the score. Because $\operatorname{READ}_t$ is aligned to the speech sequence and then projected back onto text via monotonic attention-derived alignment, the metric is useful not only for ranking whole hypotheses but also for diagnosing which segments are poorly grounded acoustically. That locality is what enables the segment-level combination method.
In the paper’s framing, this is particularly valuable for conversational and noisy speech settings, where linguistic priors alone can over-favor fluent but acoustically unsupported hypotheses. READ is intended to restore the balance between acoustic evidence and textual plausibility.
6. Limitations and Open Questions
- The paper explicitly notes that the ability of READ to distinguish substitution, deletion, and insertion errors remains to be explored.
- The segment-level combination method depends on a locality assumption and uses a greedy selection strategy. When disputed regions are long, the method can collapse toward sentence-level selection.
- The authors state that a finer-grained scheme remains future work.
- READ does not reproduce WER exactly; the paper emphasizes that there is an inherent gap between acoustic modeling mismatch and lexical edit distance, so correlation is helpful but imperfect.
- The method depends on the availability of a strong pretrained discrete auto-regressive TTS model. The paper’s experiments use CosyVoice2 as the concrete instantiation.
7. Bottom Line
READ is a reference-free ASR hypothesis evaluation method that scores how well a transcript acoustically explains the speech through the conditional likelihood of a pretrained auto-regressive TTS model. Its strengths are model-agnostic scoring, frame-level locality, direct applicability to rescoring and system combination, and improved robustness in noisy conditions. Empirically, the paper reports consistent gains over baseline top-1 outputs, meaningful improvements in multi-system combination, and especially strong behavior under severe noise. The main open limitation is that the current locality-driven combination strategy is still coarse and does not yet fully resolve fine-grained error types.