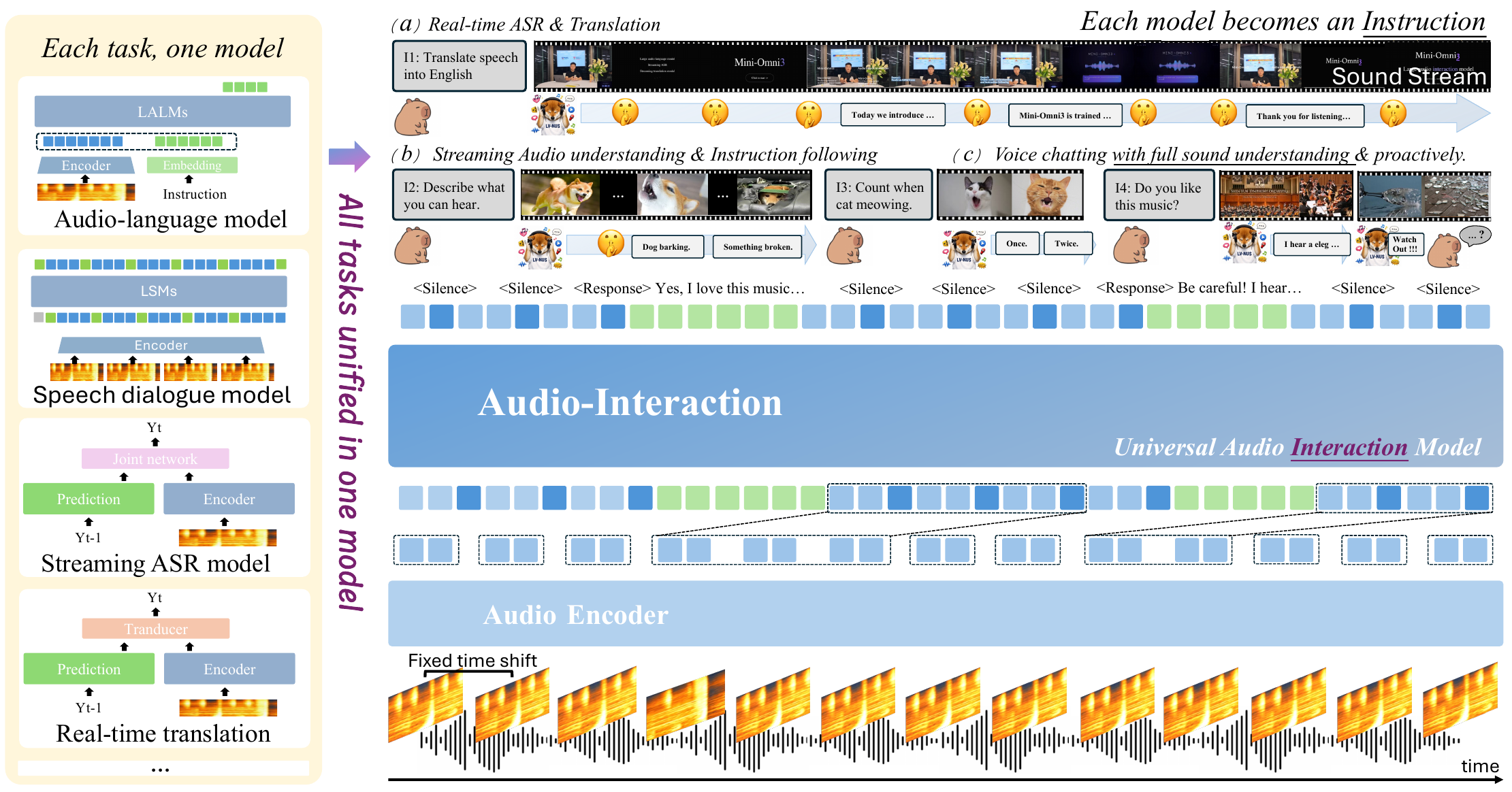
Audio-Interaction
Audio Interaction Model
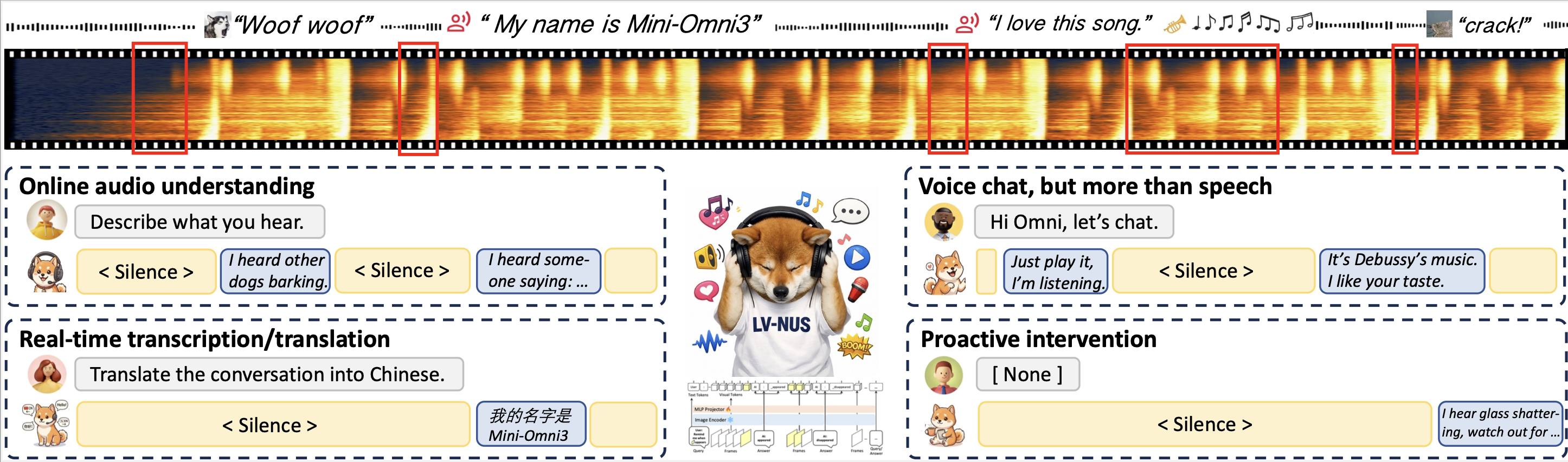
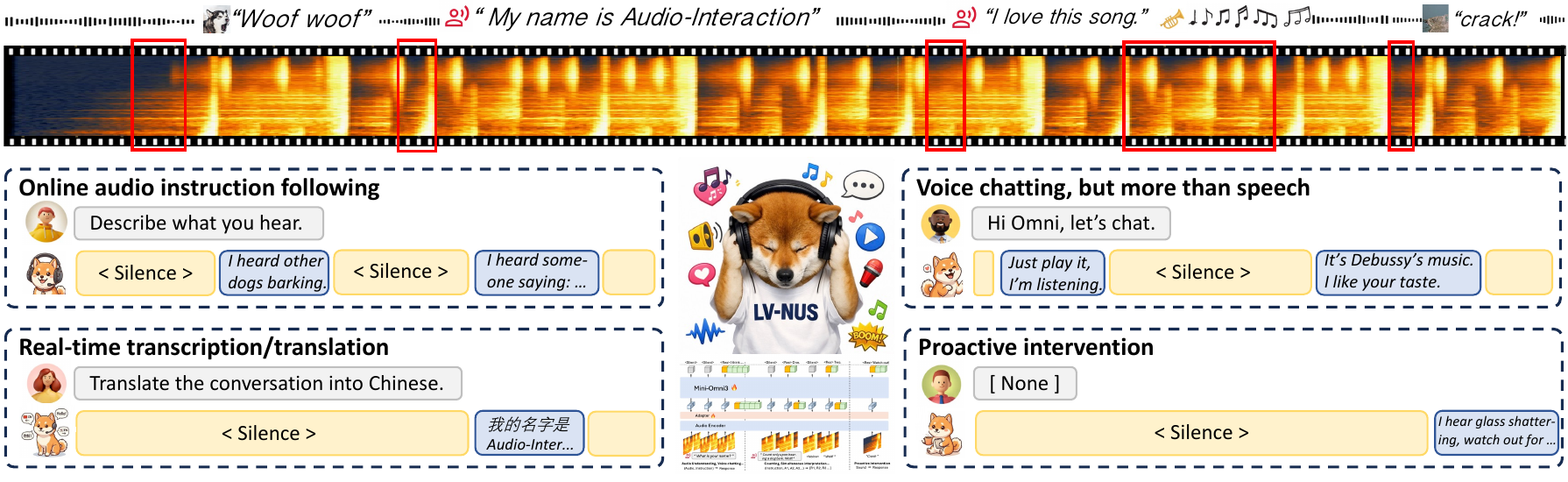
Audio-Interaction is a unified streaming audio-language model that listens continuously and decides when to respond in real time. It combines ASR, dialogue, translation, and proactive help, enabling interactive, timely multi-task audio understanding and response beyond offline models.
Demos
These demos show the Audio Interaction Model’s ability to listen, decide, and respond to live audio streams in real-time. It unifies tasks like speech recognition, translation, and proactive chatting in one system. Watch for its timely, context-aware responses and strong proactive interventions that outperform other models while keeping offline task quality.
Links
Paper & demos
Code & resources
Abstract
Audio is an inherently interactive modality, yet today's Large Audio Language Models (LALMs) are offline, and streaming audio models each handle only a single task such as streaming ASR or voice chatting. It is time to unify them into one online LALM: a model that, through an always-on perceive-decide-respond loop, listens to sound, environment, and instructions in real time and reacts on the fly. We formalize this regime as the Audio Interaction Model, and realize it with Audio-Interaction, a unified streaming model that retains offline task execution while adding online general audio instruction following, from dialogue to full voice chatting, deciding when to respond from the semantics of the stream. To enable this, we propose SoundFlow, a framework that instantiates the perceive-decide-respond loop end to end, from data to training to deployment, through streaming-native data construction, comprehension-aware training, and asynchronous low-latency inference for stable real-time interaction. We further construct StreamAudio-2M, a 2.6M-item streaming corpus spanning 7 fundamental abilities and 28 sub-tasks, and Proactive-Sound-Bench for evaluating proactive audio intervention. Across 8 benchmarks, Audio-Interaction preserves competitive performance on mainstream audio tasks while unlocking capabilities inaccessible to offline LALMs, including real-time ASR, streaming audio instruction following, and proactive help.
1. Problem Setting and Main Thesis
The paper argues that audio should not be treated as an offline input that is fully observed before any response is produced. Instead, it frames audio as an inherently interactive and real-time modality that calls for an always-on model that can continuously listen, decide whether to remain silent, and respond only when the semantics of the stream justify intervention. The authors name this new regime the Audio Interaction Model and implement it with Audio-Interaction, a unified streaming audio-language model that aims to preserve standard large audio language model capabilities while adding online behaviors such as streaming ASR, simultaneous interpretation, audio instruction following, voice chatting, and proactive assistance.
The central shift is from the offline formulation $y = f(x, \mathcal{A})$ to a streaming control loop that acts on a chunked audio stream. At each step, the model outputs a control decision and, if appropriate, a response. This is presented as a perceive--decide--respond loop, where the key novelty is not just generating text from audio, but deciding when to speak based on the unfolding acoustic context.
The paper positions this work as moving beyond two unsatisfactory extremes: offline LALMs that wait for a complete clip and then answer once, and task-specific streaming models that handle only one capability at a time. The intended destination is a single streaming audio-language system that can support both conventional audio understanding and genuinely online interaction.
2. Problem Formulation and Streaming Interface
The paper formalizes a streaming interaction regime in which the model consumes audio in fixed-length chunks and maintains a running context over prior chunks and prior decisions. Let $a_t$ denote the current audio chunk, $d_t$ the streaming intervention decision, and $r_t$ the generated response. The model is written as a sequential decision process:
$$ (d_t, r_t) = f\!\left(a_{\leq t}, d_{<t}, r_{<t}\right), $$
with the practical implementation reducing this to a control-token prediction over each chunk:
$$ d_t, r_t = f_{\mathrm{det}}(a_t, C_t), \qquad r_t = \begin{cases} \varnothing, & d_t = \langle \texttt{silent} \rangle, \\ f_{\mathrm{resp}}(a_t, C_t), & d_t = \langle \texttt{response} \rangle, \end{cases} $$
where $C_t$ is the streaming context accumulated up to step $t$. The decision token is a single special control symbol, and the training objective explicitly supervises both the language model output and the streaming control output.
3. SoundFlow: End-to-End Framework for Streaming Audio Interaction
The implementation framework is called SoundFlow. The paper decomposes it into three pieces: (1) streaming-native data construction, (2) comprehension-aware training, and (3) asynchronous low-latency inference. The point is to solve the entire pipeline end to end rather than bolting a streaming wrapper onto an offline audio LLM.
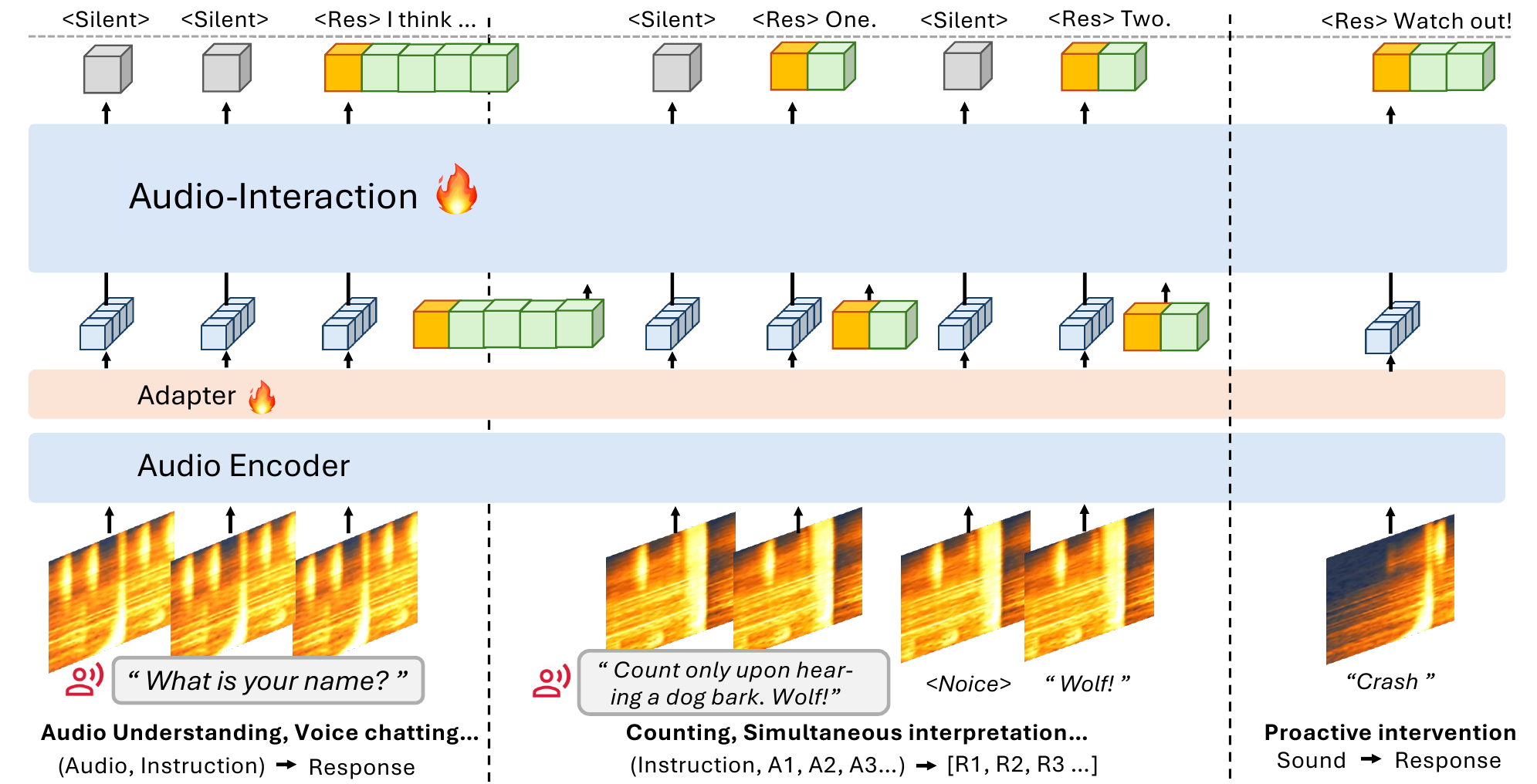
3.1 Streaming-native data construction
The data pipeline is built to synthesize long, coherent streams from shorter clips while preserving acoustic plausibility and context-dependent intervention cues. It has two main pieces: a time-frequency joint preprocessing module and a hierarchical event curation pipeline.
The time-frequency preprocessing module, called TFJP in the paper, regularizes clip boundaries and reduces artifacts so clips can be stitched into longer streams. In the appendix, TFJP is described as a sequence of operations over a shared STFT representation: silence trimming, stationary-noise estimation from low-energy regions, spectral subtraction, core-span localization, boundary snapping to a half-chunk grid, and short Hann-window smoothing at the edges. The core timing constants are a chunk size of $400$ ms, a half-chunk alignment of $200$ ms, a smoothing window of $20$ ms, and a silence limit of $300$ ms.
The hierarchical event curation pipeline avoids naive random concatenation, which would create contradictory or implausible scene compositions. Instead, it uses an LLM to plan a coherent scenario, then refines each sub-event into a retrieval query and fallback caption, and finally grounds each clip by verifying whether it matches identity, cleanliness, duration fit, and continuity. Retrieved clips are checked against top-3 candidates, and if retrieval fails the pipeline falls back to generated audio from AudioX or ElevenLabs before verification.
3.2 Comprehension-aware training
The paper identifies two training-time failure modes: insufficient long-range context retention and false triggering on irrelevant sounds. To address them, it adds two forms of auxiliary supervision. First, history review inserts questions about content at least three turns earlier in the stream, forcing the model to retrieve older context. Second, silent-audio verification provides many non-speech examples that should not elicit a response, reducing over-triggering. This is intended to teach the model not just what to say, but whether it should say anything at all.
The training loss is a dual objective:
$$ \mathcal{L} = \frac{1}{N} \sum_{j=1}^{N} \left( -\log p_\theta(t_j \mid \mathcal{H}_j) + \lambda\,[-\log p_\theta(s_j \mid \mathcal{H}_j)] \right), $$
where $t_j$ is the target text token, $s_j$ is the target streaming control token, $\mathcal{H}_j$ is the decoding context, and $\lambda$ controls the balance between language modeling and streaming control. The selected value is $\lambda = 1.0$.
3.3 Asynchronous inference with FIFO scheduling
At inference time, the paper separates encoding and decoding using an asynchronous FIFO queue. The encoder continuously appends chunk embeddings to a queue, and the decoder only consumes them when the last emitted token indicates silence or end-of-response. This avoids the encoder/decoder waiting conflicts that arise in complex interaction patterns and is reported to reduce first-frame latency after a response by $4.5\times$.
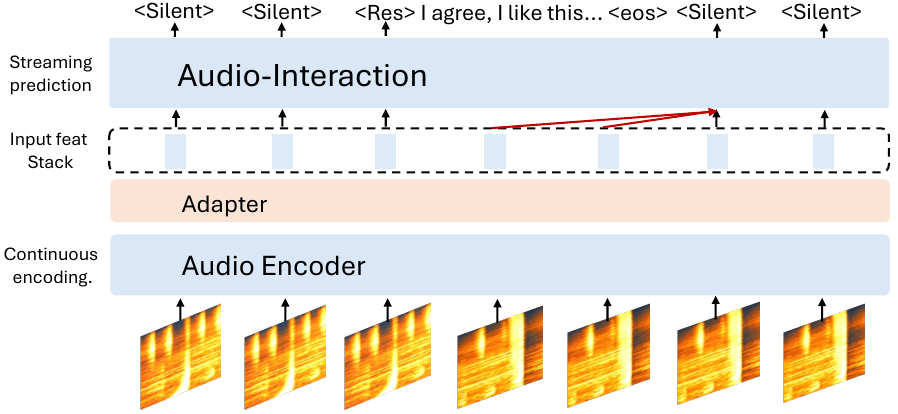
In the ablation table, the FIFO design reduces average first-chunk latency from $831$ ms to $392$ ms and eliminates stalls entirely, whereas removing FIFO introduces a $5.2\%$ stall rate.
4. StreamAudio-2M: The Streaming Training Corpus
The paper’s major data contribution is StreamAudio-2M, a streaming-native corpus designed for the perceive--decide--respond regime rather than the short clip triplets common in conventional audio datasets. The main text describes it as a $2.6$M-item corpus totaling about $302$k hours, spanning $7$ major capability groups and $28$ sub-tasks. The dataset is organized around long, multi-turn streams with sparse response cues, so the model learns both when to intervene and what to generate.

4.1 Capability taxonomy and composition
The seven reported capability families and their item counts in the main figure are:
| Capability | Items | Share |
|---|---|---|
| Voice chatting | 539k | 23.1% |
| Streaming instruction following | 487k | 20.8% |
| Streaming audio understanding | 382k | 16.4% |
| Streaming translation | 357k | 15.3% |
| Real-time ASR | 270k | 11.6% |
| Proactive response | 171k | 7.3% |
| Environment audio agent | 130k | 5.5% |
The paper also reports a source-data breakdown of 2.34M items, 7.49M rounds, and 66.7K source hours in the figure that summarizes the construction pipeline. The main point is that the corpus is assembled from many shorter resources and then converted into longer streaming interactions with token-level labels.
4.2 Source corpora and how they are used
The corpus draws from dialogue sources such as MOSS and GammaCorpus-Fact-QA; speech corpora such as CommonVoice, GigaSpeech, LibriSpeech, and VoxPopuli; speech translation corpora such as CoVoST2 and AISHELL; audio understanding sources such as AudioSet and FMA; event sources such as AudioSet events, AudioX, and ElevenLabs; and noise corpora such as MUSAN, WHAM!, and DNS-Challenge. Text sources are converted into speech with CosyVoice, then checked by ASR and rewriting verification to keep the round trip within a WER threshold of $0.10$.
Importantly, the dataset is not just a mixture of tasks. It is composed into long streams with interleaved foreground, background, and ambient events, role-dependent gains, and mixed noise tracks so that the model sees realistic acoustic continuity and has to learn selective silence.
4.3 ProactiveSound-Bench
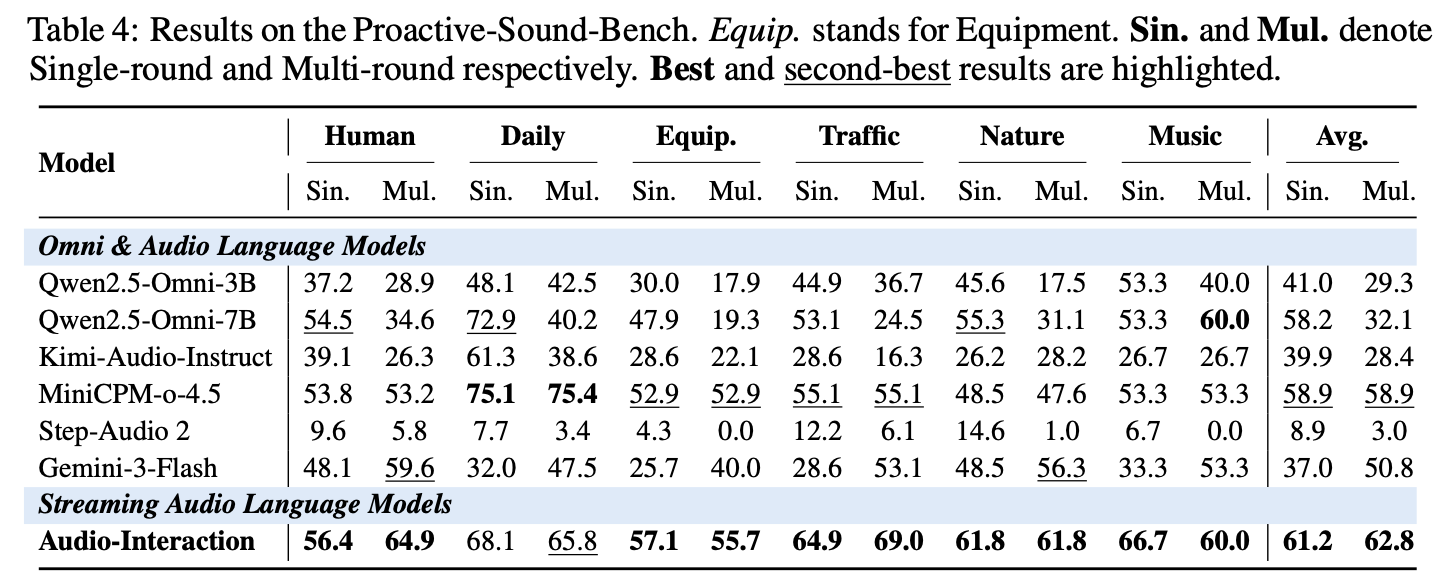
The second dataset contribution is ProactiveSound-Bench, a benchmark for proactive audio intervention. It contains $644$ human-designed events, arranged into $6$ top-level categories and $17$ sub-categories, and uses two evaluation tiers: Single and Multiple. The model must decide whether to respond at all, and if it does, generate a useful natural-language intervention rather than a generic acknowledgment.
The benchmark targets high-stakes triggers such as acute human distress, severe weather, equipment damage, fire indicators, and other safety-critical signals. It is designed specifically to test the selectivity of response, not just recognition. The paper emphasizes that the benchmark is different from sound event detection or captioning because it jointly evaluates intervention and response quality.
5. Training Recipe and Optimization Details
Audio-Interaction is initialized from Qwen2.5-Omni-3B, chosen as a compact but capable base model. Training is organized into four stages, with progressively more streaming-specific supervision. The paper gives the following recipe:
| Stage | Trainable modules | Main purpose |
|---|---|---|
| Stage 1: format training | LM head + new embedding | Teach sequence formatting and the control token on offline data |
| Stage 2: adapter training | Adapter only | Map chunk-wise acoustic representations into LM space |
| Stage 3: large-scale streaming SFT | Adapter + LM | Jointly train core capabilities: audio understanding, ASR, dialogue, and translation |
| Stage 4: instruction-following fine-tuning | Adapter + LM | Learn complex streaming behavior, proactive response, and interleaved multi-turn interaction |
The implementation uses $400$ ms chunks, a $24$ s maximum stream length ($60$ chunks), bf16 mixed precision, gradient checkpointing, and DeepSpeed ZeRO-2 on $32$ NVIDIA H100 $80$ GB GPUs. The reported total wall-clock training time is about $10$ days. Learning rates range from $10^{-4}$ in the early stages to $10^{-5}$ in the final instruction-following stage, and the optimizer is AdamW with cosine decay and linear warmup.
6. Experimental Setup
The evaluation suite spans $8$ benchmarks covering the core large audio language model space: MMAU for general audio understanding, four spoken-dialogue benchmarks under the VoiceBench setting, LibriSpeech for ASR, CoVoST2 for speech-to-text translation, and ProactiveSound-Bench for proactive intervention. The paper compares against three broad baseline families: specialized task models, audio LLMs, and omni multimodal models, plus streaming spoken-dialogue systems such as Moshi and Freeze-Omni.
7. Main Results
7.1 General audio understanding on MMAU
| Model | Stream. | Multi-turn | Text instr. avg. | Audio instr. avg. |
|---|---|---|---|---|
| Audio Flamingo 2 | No | No | 62.40 | 1.16 |
| Qwen2-Audio | No | Yes | 49.20 | 19.41 |
| Voxtral-Mini | No | Yes | 50.60 | 37.24 |
| Audio-Reasoner | No | No | 61.71 | 20.57 |
| Qwen2.5-Omni 3B | No | Yes | 57.81 | 42.51 |
| Qwen2.5-Omni 7B | No | Yes | 65.60 | 49.58 |
| Phi-4-multimodal | No | Yes | 55.56 | 31.75 |
| Baichuan-Omni-1.5 | No | Yes | 59.90 | 40.40 |
| Audio-Interaction | Yes | Yes | 55.68 | 58.15 |
The main claim here is not that the streaming model dominates every offline setting. Rather, it preserves strong general audio understanding while becoming dramatically better under spoken instructions: the audio-instruction average of $58.15$ is the headline result, and it exceeds the base Qwen2.5-Omni-3B audio-instruction score of $42.51$ by a large margin. The paper also notes that the model remains competitive on text-instruction MMAU and is smaller than several 7B baselines.
7.2 Spoken dialogue
| Model | LLaMA Q. | Web Q. | AlpacaEval | SD-QA |
|---|---|---|---|---|
| Moshi | 62.20 | 26.30 | 2.01 | 15.01 |
| Freeze-Omni | 72.00 | 44.73 | 4.14 | 50.16 |
| Baichuan-Omni-1.5 | 78.50 | 59.10 | 4.50 | 43.40 |
| Qwen2-Audio | 69.67 | 45.20 | 3.74 | 35.71 |
| Qwen2.5-Omni 3B | 66.00 | 27.95 | 4.32 | 49.37 |
| Qwen2.5-Omni 7B | 75.33 | 62.80 | 4.49 | 55.71 |
| Phi-4-multimodal | 60.20 | 26.60 | 3.81 | 39.78 |
| Audio-Interaction | 67.31 | 54.34 | 4.28 | 52.14 |
On spoken dialogue, Audio-Interaction is a strong 3B-scale system, but not a universal winner. It is competitive with the 3B and mid-scale baselines and notably strong on SD-QA, while some larger offline models still score higher on certain dialogue subsets. The key point is that the streaming model does not collapse on these tasks despite being trained for online interaction.
7.3 ASR and speech translation
| Model | LibriSpeech clean WER | LibriSpeech other WER | CoVoST2 en$\to$zh BLEU | CoVoST2 zh$\to$en BLEU |
|---|---|---|---|---|
| Canary | 1.48 | 2.93 | -- | -- |
| Canary-Qwen | 1.49 | 3.10 | -- | -- |
| Qwen2-Audio | 1.60 | 3.60 | 45.20 | 24.40 |
| Qwen2.5-Omni 3B | 2.87 | 5.90 | 39.50 | 18.17 |
| Qwen2.5-Omni 7B | 1.80 | 3.40 | 41.40 | 29.40 |
| Phi-4-multimodal | 1.69 | 3.82 | 46.30 | 22.39 |
| Baichuan-Omni-1.5 | 5.71 | 10.09 | -- | -- |
| Audio-Interaction | 3.17 | 6.04 | 55.22 | 35.21 |
This is one of the clearest wins in the paper. Audio-Interaction does not beat dedicated ASR systems on WER, which is expected given that it is a general streaming model, but it achieves the strongest reported translation BLEU on both directions and remains broadly competitive on recognition. The authors explicitly characterize the ASR WER regression relative to the offline base model as a modest cost of chunk-wise streaming decoding.
7.4 Proactive intervention
| Model | Single avg. | Multiple avg. | Key pattern |
|---|---|---|---|
| Qwen2.5-Omni 3B | 41.0 | 29.3 | Falls with longer streams |
| Qwen2.5-Omni 7B | 58.2 | 32.1 | Strong single-shot, collapses in long streams |
| Kimi-Audio-Instruct | 39.9 | 28.4 | Moderate, still unstable |
| MiniCPM-o-4.5 | 58.9 | 58.9 | Very high over-triggering; poor selectivity |
| Step-Audio 2 | 8.9 | 3.0 | Very weak on this benchmark |
| Gemini-3-Flash | 37.0 | 50.8 | Improves in multi-round setting |
| Audio-Interaction | 61.2 | 62.8 | Best overall; stable over long streams |
The proactive benchmark is where the streaming paradigm is most clearly differentiated. Audio-Interaction achieves the best average score on both Single and Multiple tiers and is the only model that the paper claims combines balanced category coverage with stability as stream length grows. The paper also reports that its trigger accuracy reaches $96.77\%$ in the ablation setting.
8. Ablations and Internal Analyses
The paper includes several ablations to isolate which pieces of the pipeline matter. The main findings are: FIFO scheduling is necessary for stable low-latency inference; streaming training and the synthetic-stream data pipeline contribute cumulatively; chunk size trades off accuracy against latency; and the dual-loss coefficient balances response triggering and understanding.
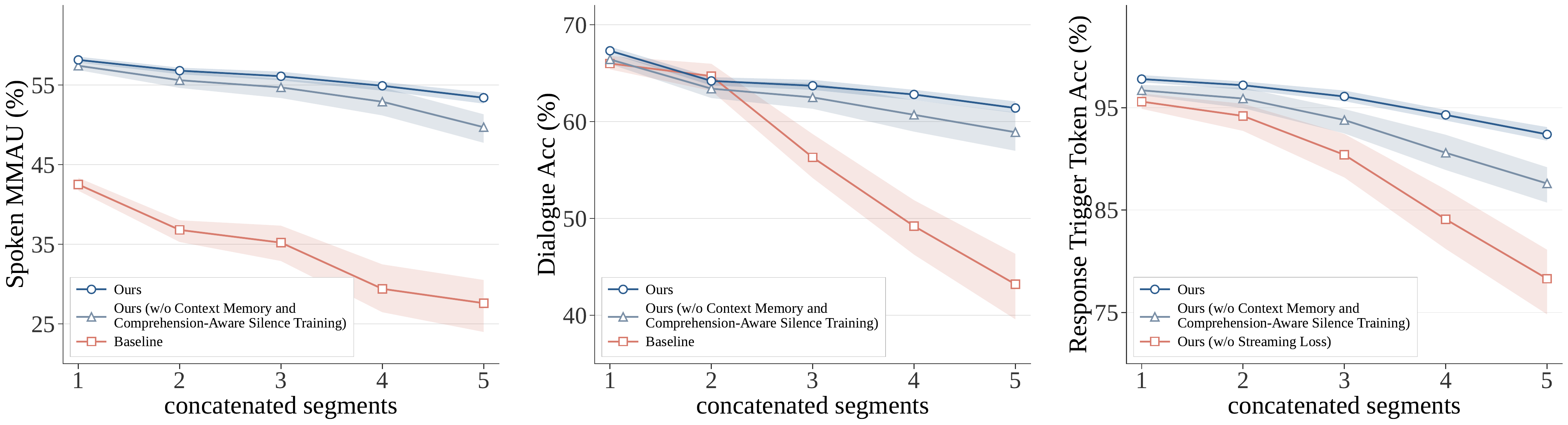
8.1 Core ablation findings
| Variant | MMAU | AlpacaEval | Trigger accuracy | Latency / stall note |
|---|---|---|---|---|
| Baseline | 57.81 | 4.32 | -- | -- |
| + Streaming SFT | 58.56 | 4.17 | 92.42% | Improves control |
| V2 without TFJP | 57.74 | 4.19 | 85.35% | Boundary smoothing matters |
| V2 without event selection | 55.11 | 4.25 | 88.51% | Semantic coherence matters |
| Audio-Interaction | 58.15 | 4.28 | 96.77% | Best overall |
The paper also reports that removing FIFO raises average first-chunk latency from $392$ ms to $831$ ms and increases stall rate from $0.0\%$ to $5.2\%$. For chunk size, $0.2$ s is too small and harms accuracy, while $0.6$ s and $0.8$ s improve accuracy but increase latency to $674$ ms and $786$ ms respectively. The chosen $0.4$ s setting is the best overall trade-off, reaching $58.15$ MMAU and $392$ ms latency.
The dual-loss coefficient ablation shows that increasing $\lambda$ improves trigger accuracy but can slightly harm comprehension at high values. The selected $\lambda=1.0$ is the paper’s balance point: it keeps MMAU near its peak while achieving very high trigger accuracy.
8.2 Continuity reconstruction and control-head localization
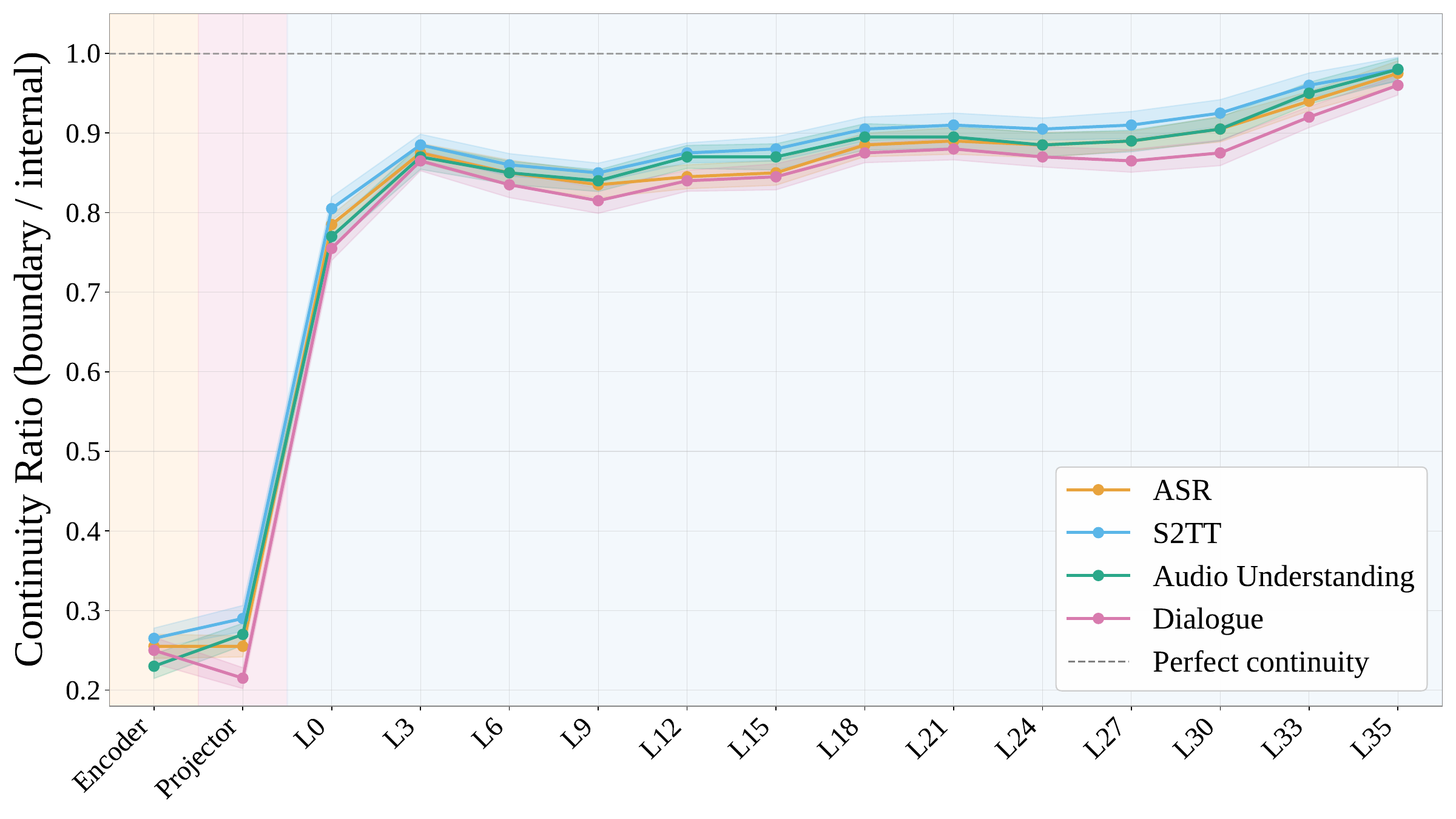
Beyond benchmark scores, the authors probe where the offline-to-streaming transition happens inside the model. They compute a continuity ratio defined as the cosine similarity of boundary pairs relative to intra-chunk pairs. The audio encoder starts low, around $0.25$, the projector changes this very little, and the earliest GPT block reconstructs continuity sharply, lifting the ratio to about $0.80$. This suggests that streaming continuity is not imposed by the frontend but reconstructed in the decoder through cross-chunk key-value cache access.
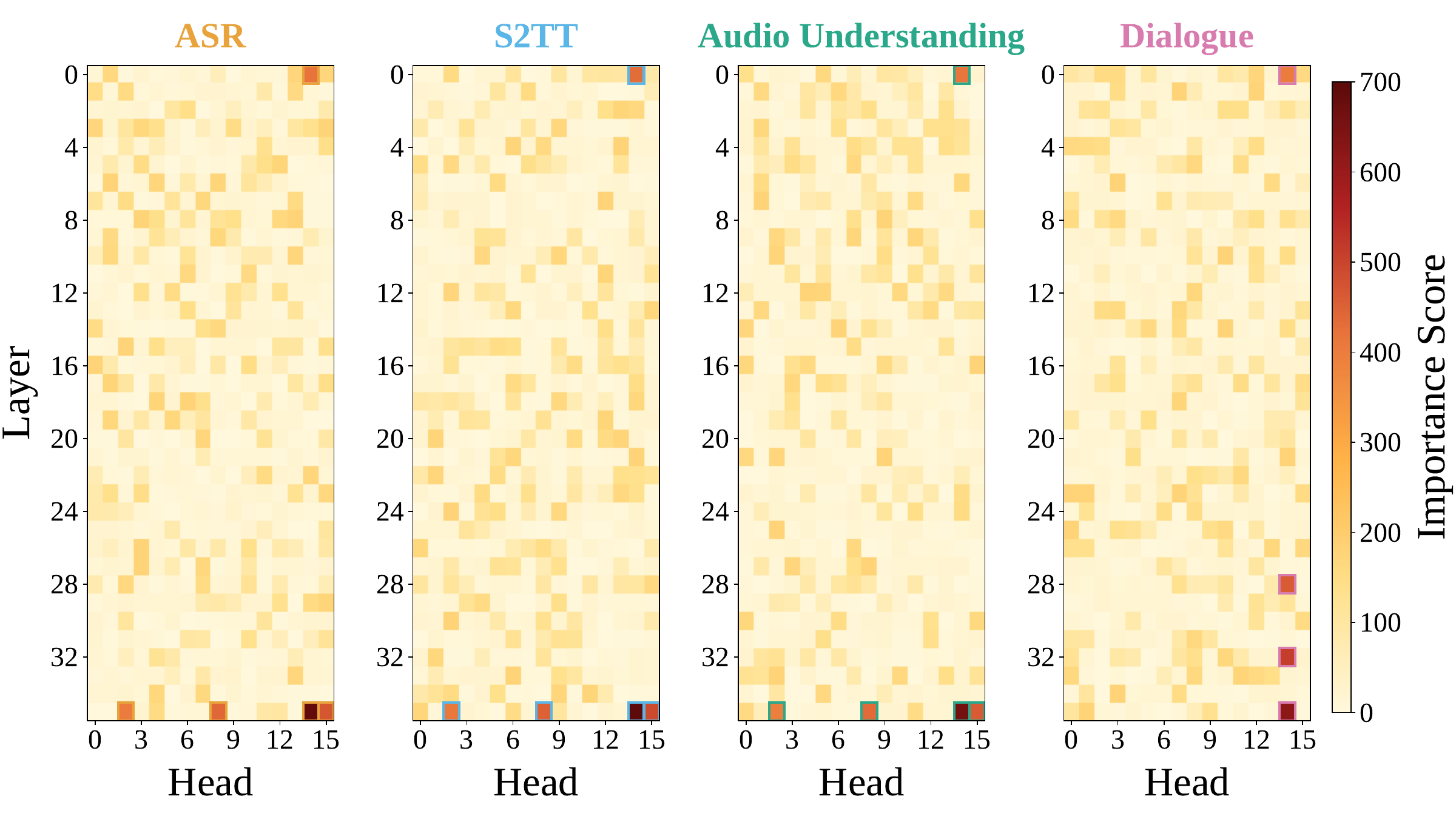
For the silent-vs-response control decision, the paper performs single-head ablation over $576$ attention heads and finds that one head, identified as L35H14, dominates across tasks. Removing it alone reduces the S2TT token-match score by $0.88$, and the task-specific rankings are highly correlated. The conclusion is that streaming control is concentrated in a narrow, shared pathway rather than split into separate circuits for each task.
9. Qualitative Case Study and Real-World Validation
The appendix extends the synthetic-stream evaluation to roughly $2$ hours of naturally recorded audio from four deployment scenarios: travel, work, home, and commute. These recordings were captured on consumer devices and were not processed by TFJP, so they test the model in more realistic conditions. The model retains most of its synthetic-stream behavior: average trigger accuracy is $58.9\%$ versus $62.0\%$ on a matched synthetic split; first-chunk latency stays within about $\pm 25$ ms of the synthetic measurement; per-chunk silence rates correlate at $0.91$ with the synthetic split; and the dominant control head and continuity metrics remain similar. Performance degrades most in travel and commute because crowd noise and non-stationary audio make both recognition and trigger selectivity harder.

The qualitative case study underscores a recurring theme: some streaming baselines rely too heavily on transcript-like cues, while Audio-Interaction is intended to react to the audio event itself. This matches the broader motivation of the paper, which is to move from spoken-text surrogates to genuinely audio-native interaction.
10. Error Analysis and Practical Weaknesses Reported by the Paper
The paper does not present a formal limitations section, but it does report several failure modes in the appendix that are useful for understanding where the model is still weak.
- LibriSpeech ASR: the largest error class is local token deviation, followed by rare-word and long-utterance degradation, then function-word bias and decoding loops.
- CoVoST2 translation: low-BLEU outputs are dominated by semantic hallucinations, with some incomplete or mixed-language translations.
- MMAU: about $20\%$ of errors are generation collapse, and the rest are genuine recognition or reasoning mistakes.
- SpokenQA: factual hallucination is the dominant issue, followed by irrelevant or generalized responses and numerical/temporal mistakes.
- VoiceBench: low-score outputs often reflect hallucination or inappropriate refusal, while SD-QA errors include hallucination, miscomprehension, and over-refusal.
- ProactiveSound-Bench: false positives dominate the errors, meaning the model sometimes overreacts to benign sounds; false negatives still occur for safety-critical cues.
These error patterns matter because they align with the paper’s central objective: the hard part of streaming audio interaction is not just recognition, but calibrated intervention. The reported weaknesses show that the model is still vulnerable to hallucination, over-triggering, and long-tail recognition errors, especially in noisy or ambiguous contexts.
11. What the Paper Concludes
The paper’s conclusion is that moving from offline LALMs to an always-on audio interaction model is both feasible and useful. With SoundFlow, StreamAudio-2M, and ProactiveSound-Bench, the authors show that a single model can retain competitive performance on mainstream audio tasks while unlocking streaming-native capabilities that offline models cannot express. The strongest claims supported by the reported experiments are: (1) streaming training can preserve much of the general audio understanding of the base model; (2) audio instruction following and proactive response are materially improved by native streaming supervision; and (3) the streaming control policy can be learned as a compact, internalized decision mechanism rather than an external scheduler.