Task-Vector Arithmetic for Emotional Control
Task-Vector Arithmetic for Emotional Expressivity Control in Language-Model-Based Text-to-Speech
This paper finds that emotional prosody in language-model TTS is localized in the speaker embedding. It introduces a training-free method to control emotional intensity via arithmetic on this embedding, enabling cross-lingual emotional expressivity without retraining.
Links
Paper & demos
Code & resources
Abstract
We investigate whether task-vector arithmetic, successful for cross-speaker emotional intensity control in modular text-to-speech (TTS), transfers to large-scale TTS systems built on language-model backbones with in-context learning (LM-TTS). Through a systematic elimination study over four progressively narrower operands on Qwen3-TTS-12Hz-1.7B - model weights via LoRA fine-tuning, continuous codec embeddings, discrete codec tokens, and the speaker embedding (x-vector) produced by an ECAPA-TDNN encoder jointly trained with the synthesis backbone - we localize the dominant carrier of emotional prosody to the x-vector. Building on this finding, we propose a training-free method based on centroid arithmetic in x-vector space: an emotion direction $τ= \mathbb{E}_i[x(s_i,\text{emo})] -\mathbb{E}_i[x(s_i,\text{neutral})]$ applied to an unseen target speaker as $x_{\text{new}} = x(\text{target},\text{neutral}) + α\cdotτ$. Using ESD (English) as the $τ$ source and emoUERJ (Brazilian Portuguese) as a cross-lingual ground-truth target, we observe average gains of $+0.29$ in emotion2vec cosine over the ICL baseline on English held-out speakers and $+0.09$ on Brazilian Portuguese held-out speakers, while largely preserving identity (WavLM SECS $\gtrsim 0.88$ for the multi-speaker $τ$ variant) and intelligibility (WER $\approx 0$ in PT-BR). These results offer initial evidence that the dominant carrier of emotional prosody in this class of models is localizable, by elimination, to the co-trained speaker embedding, where training-free centroid arithmetic remains effective even under cross-lingual transfer.
Overview
This paper asks whether task-vector arithmetic, which worked in modular text-to-speech systems for cross-speaker emotional control, also works in modern language-model-based TTS (LM-TTS) systems with in-context learning. The central finding is negative for weight-space arithmetic and positive for a different operand: in Qwen3-TTS-12Hz-1.7B-Base, the dominant carrier of emotional prosody is localized, by elimination, to the learnable speaker embedding (the x-vector) produced by an ECAPA-TDNN encoder that is co-trained with the synthesis backbone.
The practical implication for conversational-AI and talking-head pipelines is that emotional expressivity can be controlled without retraining by manipulating the speaker embedding directly, using a simple centroid direction and a single inference-time knob $\alpha$. The method preserves speaker identity reasonably well and transfers across languages from English to Brazilian Portuguese.
- Architectural question: where does emotion live in an LM-TTS stack that conditions generation on codec tokens and a speaker embedding?
- Empirical strategy: progressively eliminate candidate operands: backbone weights, codec embeddings, discrete codec tokens, then the x-vector.
- Outcome: only x-vector arithmetic yields controllable emotional transfer.
- Method: training-free centroid arithmetic in x-vector space, with intensity controlled by $\alpha$.
- Validation: English held-out speakers and cross-lingual English $\to$ Brazilian Portuguese transfer with ground truth references.
Model and architectural setting
The target system is Qwen3-TTS-12Hz-1.7B-Base, an LM-TTS architecture built around a pretrained language-model backbone rather than a modular acoustic stack. The pipeline shown in the paper is: text $\to$ text tokenizer $\to$ a $28$-layer Transformer backbone with hidden size $2048$ $\to$ a semantic codec token $k=0$ $\to$ a code predictor with $15$ multi-token prediction heads $\to$ codec tokens $k=1..15$ $\to$ vocoder $\to$ audio.
In parallel, reference audio is encoded by an ECAPA-TDNN speaker encoder (SE-Res2Net variant) into a $2048$-dimensional x-vector. That x-vector is used as global conditioning through the in-context-learning path and is injected directly into the sequence of codec embeddings that conditions the language model. The authors emphasize that, unlike frozen verification encoders, this speaker encoder is learnable and co-trained with the synthesis backbone.
Candidate operands tested in the elimination study
| Step | Operand | Intervention | What it tests | Reported outcome |
|---|---|---|---|---|
| 1 | Backbone weights | Full fine-tuning and LoRA task vectors over single-speaker/single-emotion ESD data | Whether emotion can be captured in model weights as in modular TTS | No useful emotional window: high learning rates produced noise, low rates produced calm speech, and some LoRA settings caused off-task laughter |
| 2 | Continuous codec embeddings | Per-codebook centroid differences added to codec embeddings | Whether emotion is encoded as a linear direction in the codec embedding space | Abrupt transition from no effect to degenerate noise; no stable emotional regime |
| 3 | Discrete codec tokens | Token substitution, including full angry-token swap with neutral x-vector | Whether emotion is carried by the discrete token sequence itself | Controlled dissociation: angry tokens plus neutral x-vector still produced calm, coherent speech |
| 4 | X-vector | Centroid arithmetic in speaker-embedding space | Whether emotional prosody is linearly accessible in the speaker embedding | Yes: the dominant carrier is localized to the x-vector |
Data and evaluation protocol
The study uses two corpora. For source-direction estimation $\tau$, the authors use the English Emotional Speech Database (ESD), which provides $350$ parallel utterances per emotion per speaker. For the multi-speaker direction they choose four speakers, $\{0011, 0014, 0017, 0020\}$, balancing gender and using $50$ utterances per speaker per emotion. The single-speaker variant uses only speaker $0017$.
For held-out English testing, the paper follows the same unseen split used in prior work and evaluates on two unseen ESD speakers, $\{0013, 0019\}$, with $n=30$ sentences from the official test split. For cross-lingual validation, the target corpus is emoUERJ in Brazilian Portuguese, using speakers m03 and m04 with parallel pairs and w04 in a cross-text design because complete parallel pairs are not available.
All audio is resampled to $24$ kHz. The original emoUERJ recordings are $44.1$ kHz stereo and are converted to $24$ kHz mono with $-1$ dB headroom to avoid clipping.
Metrics
- Emotion embedding cosine similarity (EECS): cosine between the synthesized audio embedding from
emotion2vec_plus_largeand the paired emotional ground truth. - Speaker embedding cosine similarity with WavLM ($\mathrm{SECS}_W$): cosine between WavLM speaker embeddings from synthesized audio and the paired neutral reference, using an encoder external to the TTS pipeline to avoid circularity.
- Word error rate (WER): obtained with Whisper-large-v3, normalized with language-specific normalizers.
- Naturalness: UTMOSv2
fusion_stage3, used as a relative within-experiment proxy, especially because it is not trained on PT-BR. - Cross-lingual falsification metric: ECAPA-TDNN cosine between the synthesized x-vector and the ground-truth emotional recording of the same PT-BR speaker, denoted $\text{xvec\_cos\_GT}$ in the paper.
For every table, the paper also reports a natural-ceiling row from real recordings. For EECS, the trivial self-similarity ceiling is not informative, so the authors use within-class variance instead. The baseline throughout is the pure ICL system at $\alpha=0$.
Elimination study: localizing the emotion carrier
The elimination study is the core methodological contribution. It progressively removes candidate locations where emotion might live in Qwen3-TTS: weights, continuous codec embeddings, and discrete codec tokens. Only after these candidates are ruled out does x-vector arithmetic succeed.
Step 1: weight-space task vectors fail in this LM-TTS setting
To replicate earlier modular-TTS work on emotion arithmetic, the authors fine-tune Qwen3-TTS on ESD speaker $0017$ with a single emotion using either full fine-tuning or LoRA. They sweep learning rates over $\{1\mathrm{e}{-6}, 2\mathrm{e}{-6}, 5\mathrm{e}{-6}, 1\mathrm{e}{-5}, 2\mathrm{e}{-5}, 5\mathrm{e}{-5}, 1\mathrm{e}{-4}\}$ and epochs from $4$ to $39$.
Two LoRA target-module configurations are used: attention only ($\texttt{q/k/v/o\_proj}$, rank $r=64$, LoRA scale $128$, about $29$M trainable parameters) and attention plus $\texttt{codec\_head}$ and the $15$ heads of the code predictor, totaling about $60$M trainable parameters. Full fine-tuning is also tested with learning rates in $\{2\mathrm{e}{-6}, 2\mathrm{e}{-5}\}$.
The reported behavior is not an intermediate controllable emotional regime, but a failure mode bifurcation: high learning rates yield noise or instability, low learning rates leave the model close to the base system and therefore calm, and some settings involving the codec heads produce generic expressivity such as laughter rather than the intended emotion. The authors interpret this as evidence that, in this LM-TTS regime, backbone weights are not a useful locus for linear emotional control.
Step 2: continuous codec embeddings do not yield a usable linear emotional direction
Next, the paper asks whether emotion lives in the continuous embeddings of the codec tokens. For each codebook, the authors compute an emotion centroid and a neutral centroid over angry and neutral ESD utterances from speaker $0017$, then form per-codebook differences $\tau_k$. These directions are injected either as a single summed perturbation or as independent per-layer perturbations.
The key observation is that even though one codebook has the largest individual direction magnitude and the summed perturbation has norm $\lVert \tau \rVert_2 = 0.293$, sweeping $\alpha$ produces only a jump from no visible effect to degenerate noise. There is no stable region where the codec-embedding manipulation produces intelligible emotional speech. The paper argues that the perturbation likely moves embeddings off the manifold of valid discrete token embeddings, making the resulting conditioning out of distribution.
Step 3: discrete-token substitution isolates the x-vector as the decisive carrier
The most direct elimination test is the token-swap experiment. Using parallel utterance pairs from ESD, the authors combine angry or neutral token sequences with either angry or neutral x-vectors, plus partial substitutions over subsets of the $16$ codebooks. The critical condition is full_swap: all angry codec tokens are paired with a neutral x-vector.
The outcome is striking: despite the angry codec tokens carrying the acoustic signal of anger, the system outputs calm, coherent speech when the x-vector is neutral. The inverse condition sounds angry. This controlled dissociation indicates that the language model is prioritizing the x-vector over the emotional coloring present in the token stream. Partial substitutions, where codebooks are mixed from different utterances, usually become internally inconsistent and degenerate, reinforcing the idea that coherence depends on a self-consistent token set.
X-vector centroid arithmetic
After localizing the emotional signal to the speaker embedding, the paper proposes a training-free arithmetic method in x-vector space. For a speaker $s$ and emotion label $\text{emo}$, the emotional direction is
$$\tau_{\text{emo}}^{(s)} = \mathbf{x}(s, \text{emo}) - \mathbf{x}(s, \text{neutral}),$$
and the manipulated vector for an unseen target speaker is
$$\mathbf{x}_{\text{new}} = \mathbf{x}(\text{target}, \text{neutral}) + \alpha \cdot \tau_{\text{emo}}^{(s)}.$$
The multi-speaker variant estimates the direction from centroids over a source set $\mathcal{S}$:
$$\tau_{\text{emo}}^{\text{avg}} = \mathbb{E}_{s \in \mathcal{S}}\big[\mathbf{x}(s, \text{emo})\big] - \mathbb{E}_{s \in \mathcal{S}}\big[\mathbf{x}(s, \text{neutral})\big].$$
The paper evaluates two versions of this operand: single0017, where $\mathcal{S}=\{0017\}$, and avg4spk, where $\mathcal{S}=\{0011, 0014, 0017, 0020\}$. Because the method is purely additive at inference time, emotional intensity is controlled by the scalar $\alpha$ without any retraining.
The authors also consider three operational modes: same-speaker interpolation, cross-speaker interpolation, and cross-speaker task arithmetic. The last one is the main setting: the target speaker remains a held-out speaker, while the emotional direction is imported from source speakers.
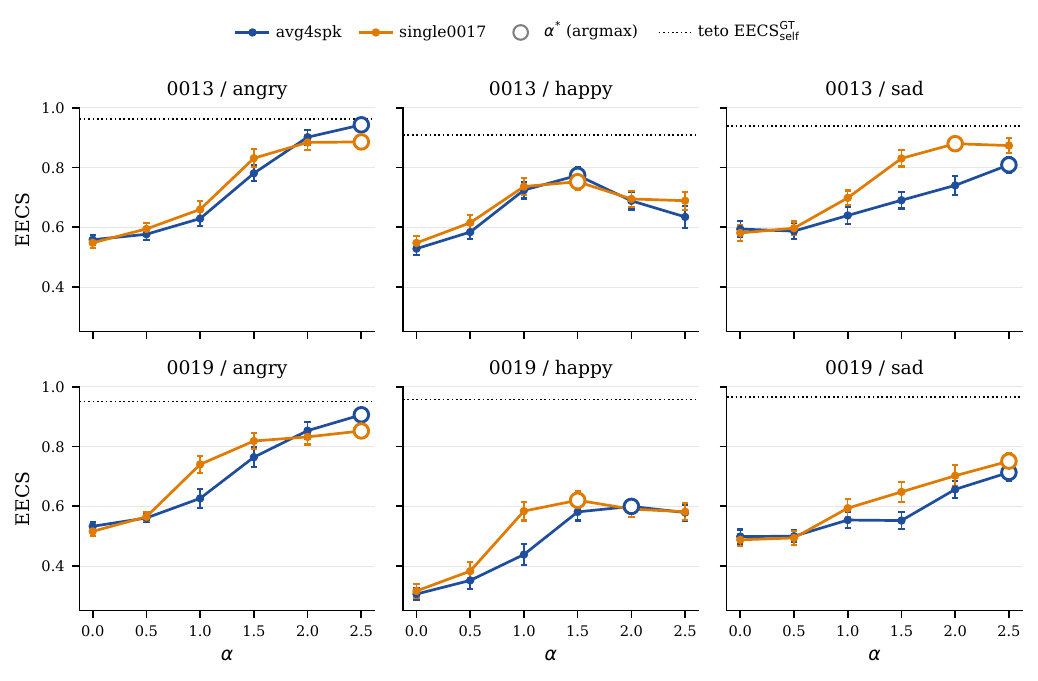
Geometrically, the paper finds that emotion is a small but meaningful perturbation within the x-vector space. For speaker $0017$, the neutral and angry x-vectors have norms $16.70$ and $16.89$, respectively, and their cosine is $0.988$. The emotional direction norm is only about $15\%$ of the neutral x-vector norm, so the emotion axis is close to orthogonal to the dominant identity axis. Averaging over speakers reduces the norm of $\tau$ by roughly $36\%$ to $60\%$ relative to the single-speaker direction, because speaker-specific residuals cancel out.
The pairwise cosine structure between emotion directions is not orthogonal but becomes less correlated in the multi-speaker setting. The paper reports pairwise cosines in the range $[0.35, 0.72]$ for single0017 and $[0.21, 0.61]$ for avg4spk, with the happy-sad pair dropping from $0.58$ to $0.24$. This decorrelation is important because it suggests that multiple emotional directions may later be composed linearly.
English held-out results
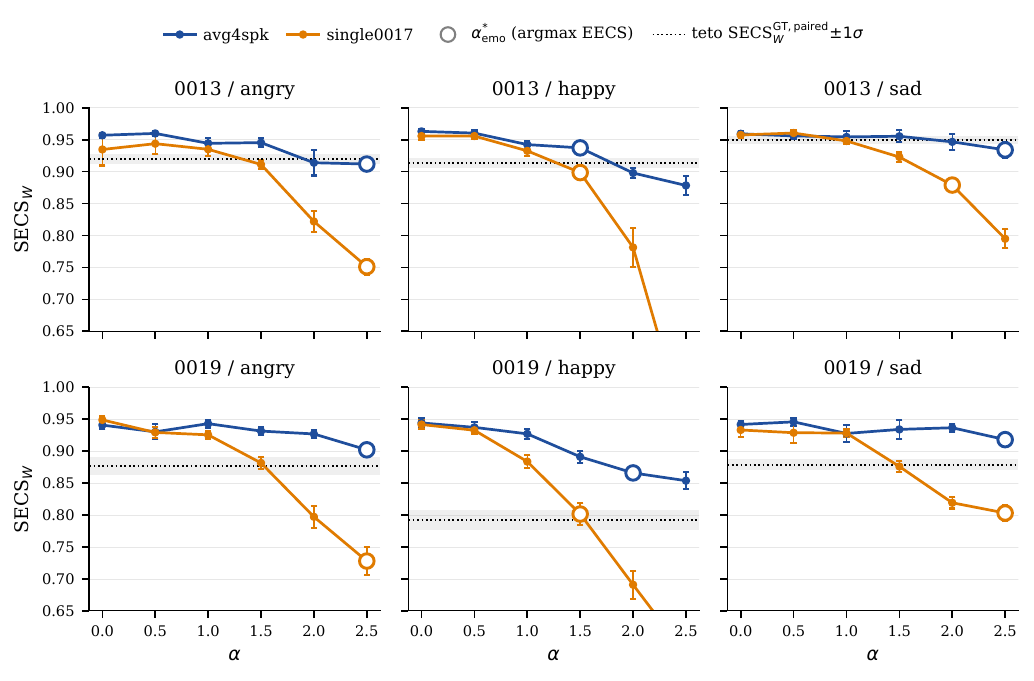
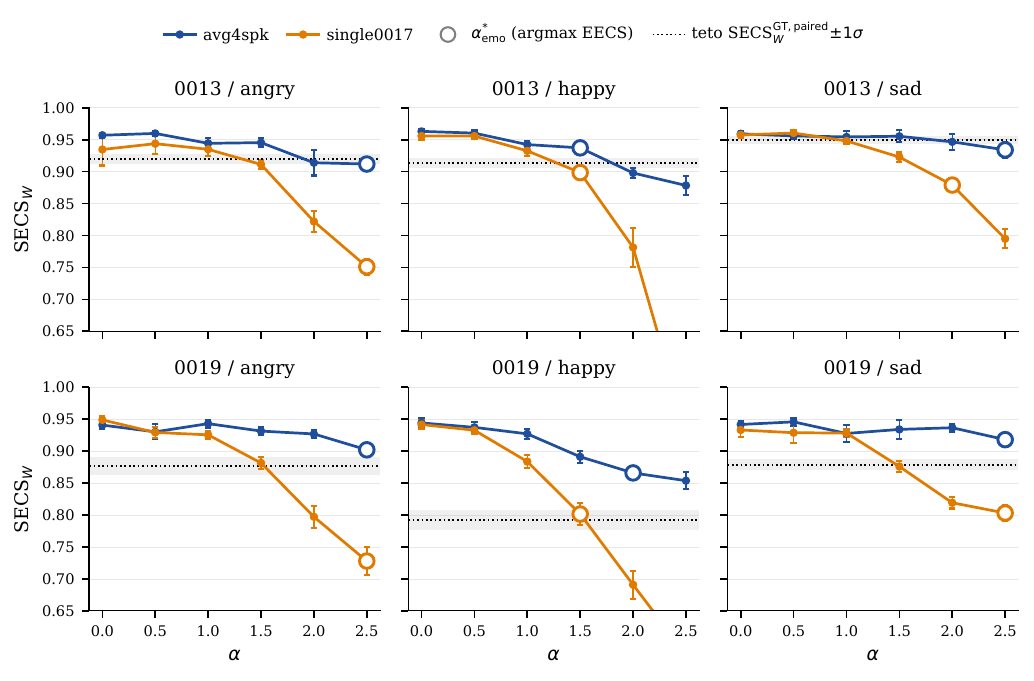
For English held-out speakers $\{0013, 0019\}$, the paper reports consistent gains over the pure ICL baseline for all three emotions: angry, happy, and sad. The average EECS improvement is about $+0.291$ for single0017 and $+0.288$ for avg4spk, so the multi-speaker centroid preserves the transfer gain while improving identity and naturalness.
In aggregate, the multi-speaker direction improves identity preservation by about $0.102$ points in $\mathrm{SECS}_W$ compared with the single-speaker direction ($0.912$ versus $0.810$ on average over the six target-by-emotion combinations) and also improves UTMOS by about $0.20$ ($3.23$ versus $3.03$). WER stays around the $5\%$ to $7\%$ range, similar to the human ceiling reachable by the automatic recognizer.
| Emotion | System | EECS $\uparrow$ | $\mathrm{SECS}_W \uparrow$ | UTMOS $\uparrow$ | WER $\downarrow$ |
|---|---|---|---|---|---|
| Angry | Ceiling | 0.957 | 0.898 | 3.048 | 0.069 |
| Base | 0.539 | 0.945 | 3.378 | 0.061 | |
| avg4spk | 0.925 | 0.907 | 3.268 | 0.055 | |
| single0017 | 0.869 | 0.740 | 3.025 | 0.032 | |
| Happy | Ceiling | 0.933 | 0.853 | 2.984 | 0.058 |
| Base | 0.425 | 0.951 | 3.391 | 0.056 | |
| avg4spk | 0.687 | 0.902 | 3.111 | 0.059 | |
| single0017 | 0.686 | 0.850 | 3.104 | 0.065 | |
| Sad | Ceiling | 0.953 | 0.914 | 3.235 | 0.053 |
| Base | 0.540 | 0.948 | 3.397 | 0.059 | |
| avg4spk | 0.761 | 0.926 | 3.325 | 0.055 | |
| single0017 | 0.816 | 0.841 | 2.913 | 0.086 |
Several qualitative patterns follow from the English table. First, emotional transfer is strongest for angry, where avg4spk reaches EECS close to the human ceiling while keeping WavLM identity above the baseline. Second, the single-speaker direction can improve EECS but at the cost of identity leakage, visible in the lower $\mathrm{SECS}_W$ values and in some cases lower naturalness. Third, the baseline ICL system already has relatively strong speaker preservation, so the main role of $\tau$ is to move the output toward the emotional reference rather than to fix identity.
Cross-lingual EN $\to$ PT-BR validation
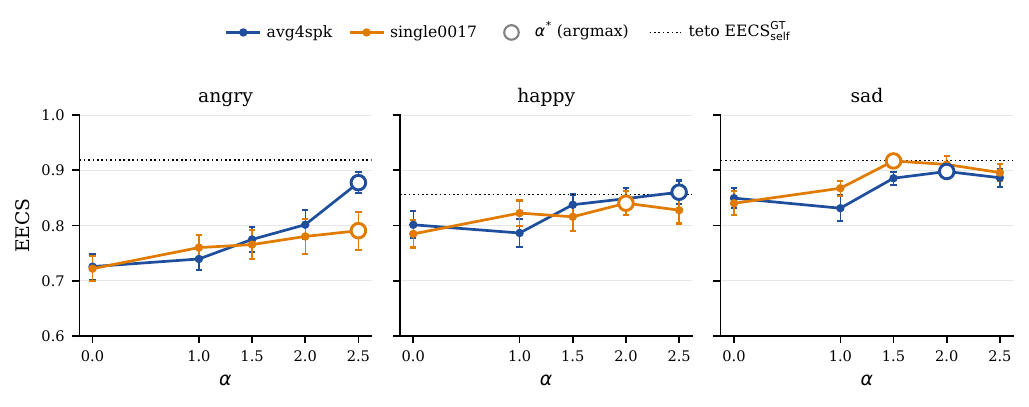
The cross-lingual validation is important because it tests whether the English emotional direction generalizes to unseen Brazilian Portuguese speakers. The paper uses emoUERJ and compares synthesized outputs against ground-truth emotional recordings. The main result is that transfer still works, but the gain is smaller than in English: the mean EECS improvement is about $+0.092$, with stronger gains for high-arousal anger and weaker gains for happy and sad.
The smaller gain is not interpreted as a failure of the method. Instead, the authors note that the PT-BR baseline starts from a much higher EECS floor than the English baseline. They attribute this to two effects: emoUERJ neutral speech is not always truly neutral in perceptual terms, and emotion2vec_plus_large is less discriminative on PT-BR than on English. Thus the headroom for improvement is smaller.
In absolute terms, the best $\alpha$ values still reach EECS in approximately the same range as English, around $0.76$ to $0.97$. That is, the final quality is competitive even if the improvement over baseline is smaller.
| Emotion | System | EECS $\uparrow$ | $\mathrm{SECS}_W \uparrow$ | UTMOS $\uparrow$ | WER $\downarrow$ |
|---|---|---|---|---|---|
| Angry | Ceiling | 0.919 | 0.916 | 2.335 | 0.018 |
| Base | 0.724 | 0.949 | 3.345 | 0.003 | |
| avg4spk | 0.877 | 0.929 | 3.162 | 0.000 | |
| single0017 | 0.844 | 0.868 | 3.007 | 0.000 | |
| Happy | Ceiling | 0.856 | 0.922 | 2.530 | 0.070 |
| Base | 0.786 | 0.936 | 3.309 | 0.017 | |
| avg4spk | 0.867 | 0.902 | 2.996 | 0.000 | |
| single0017 | 0.865 | 0.847 | 2.939 | 0.033 | |
| Sad | Ceiling | 0.918 | 0.925 | 2.850 | 0.077 |
| Base | 0.855 | 0.940 | 3.419 | 0.000 | |
| avg4spk | 0.902 | 0.939 | 3.267 | 0.002 | |
| single0017 | 0.923 | 0.917 | 3.060 | 0.000 |
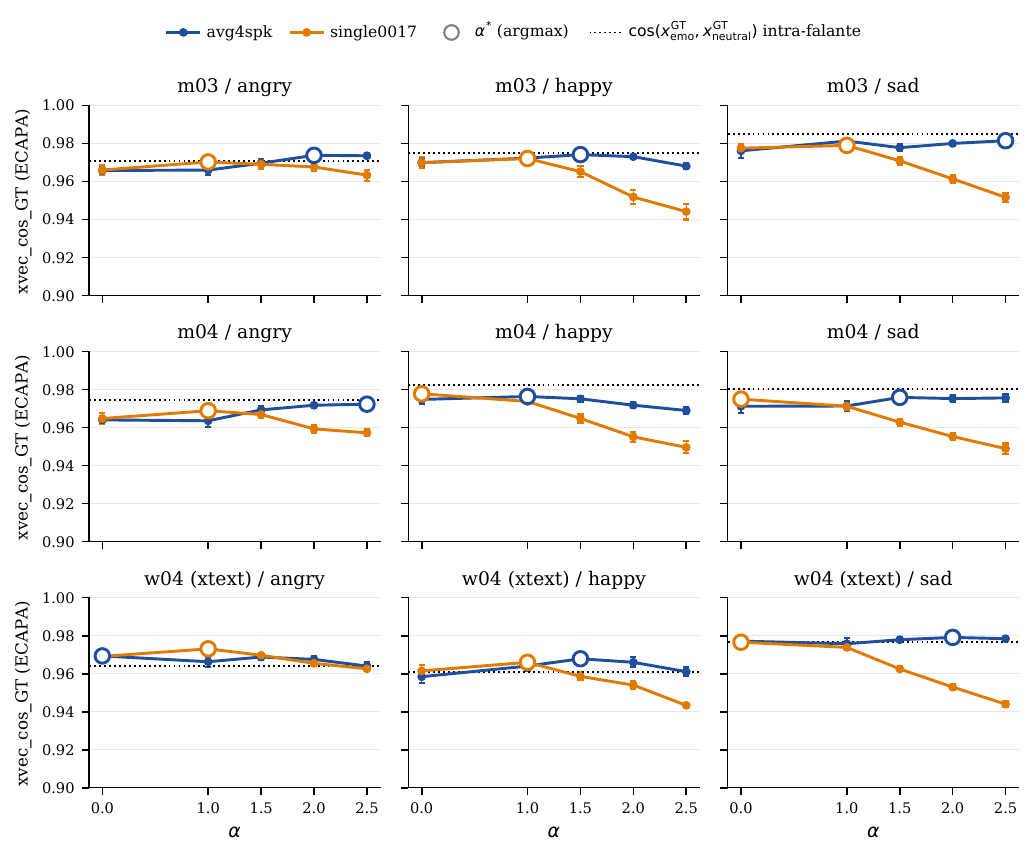
The paper adds a useful falsification test for the cross-lingual case: $\text{xvec\_cos\_GT}$. Because this metric compares two PT-BR utterances from the same speaker in an ECAPA-TDNN space, it is language-agnostic by construction. It saturates near the natural within-speaker limit, which is expected because ECAPA is dominated by identity and compresses prosodic variation. The more informative signal is the contrast between the two variants: avg4spk stays on the reference line across the whole $\alpha$ grid, whereas single0017 drops below it at high $\alpha$, indicating source-speaker timbre leakage.
WER remains essentially zero across PT-BR conditions, with a mean of about $0.006$, showing that the manipulations do not compromise intelligibility in the reported setting.
Discussion
The authors argue that the failure of weight-space arithmetic in LM-TTS is structural rather than incidental. In modular TTS systems such as CFS2 and VITS, emotion has an explicit functional locus in a parameterized module, so weight differences can meaningfully represent style. In Qwen3-TTS, by contrast, prosody emerges from autoregressive continuation conditioned on the x-vector and codec tokens; there is no dedicated emotional submodule whose weights can be shifted in the same way. In the tested single-speaker/single-emotion regime, fine-tuning therefore collapses to either noise or near-baseline speech, not to a controllable emotional axis.
The x-vector result is more subtle. Speaker embeddings are usually treated as identity representations, but here the speaker encoder is co-trained with the synthesis backbone rather than frozen for verification. That means the embedding must preserve enough information to reconstruct expressive speech, not just identity. The paper argues that this is why a low-dimensional, approximately linear emotional direction remains accessible in the x-vector, even though the dominant role of that vector is still identity. The baseline ICL system already captures some emotional prosody, which is why the embedding is not a pure identity code.
The multi-speaker centroid $\tau$ is the most practical version of the method because it cancels the source speaker residual that otherwise leaks timbre into the target. This is visible in the cross-speaker and cross-lingual tables: avg4spk is generally more identity-preserving and more natural than single0017, even when the latter occasionally attains slightly higher emotion scores on some cells. In other words, the multi-speaker centroid is the better engineering choice for conversational systems where identity stability matters.
The paper also points out that the method is not magically universal. The emotion directions are only approximately linear and not perfectly orthogonal, so composition of multiple emotions is an open question. Likewise, the metric behavior can saturate: EECS can become less sensitive at high values, especially in PT-BR, and WavLM-based identity metrics compress within-speaker variation. The authors therefore read the numbers as evidence of useful transfer, not as proof of perfect disentanglement.
Limitations
- Model-specific validation: experiments are limited to Qwen3-TTS-12Hz-1.7B-Base; the architectural argument is broader, but direct validation on other LM-TTS systems remains future work.
- Encoder assumption: the method assumes the speaker encoder preserves emotional information in approximately linear directions. Encoders trained strictly for speaker verification, or explicitly disentangled encoders, may behave differently.
- Cross-lingual metric caveat:
emotion2vec_plus_largeis not equally strong in PT-BR as in English, which contributes to score saturation and reduces apparent gains. - No human PT-BR listening test yet: the paper explicitly notes that a PT-BR human evaluation is still pending.
- Weight-space negative result is not absolute: Step 1 used a single-speaker/single-emotion, relatively low-variability regime. The authors do not rule out that larger multi-speaker, multi-emotion fine-tuning could open a window, although Step 3 is the stronger evidence for x-vector localization.
- When explicit conditioning exists, it may be preferable: systems trained with instruction-speech pairs or dedicated emotion modules can offer finer control. The paper positions x-vector arithmetic as a low-compute alternative for base models that do not expose explicit emotional control.
Conclusion
The paper’s main conclusion is that task-vector arithmetic does not transfer in a useful way to the backbone weights of the tested LM-TTS system, but emotional expressivity can still be controlled training-free once the operand is moved to the co-trained speaker embedding. The proposed x-vector centroid arithmetic uses
$$\mathbf{x}_{\text{new}} = \mathbf{x}(\text{target}, \text{neutral}) + \alpha \cdot \tau_{\text{emo}}$$
to move along an emotion axis while largely preserving identity. On held-out English speakers, the method improves EECS by about $+0.29$ over the ICL baseline; on Brazilian Portuguese it still improves by about $+0.09$ under cross-lingual transfer. For a conversational-AI team, the key practical takeaway is that expressive control can be exposed as a lightweight inference-time knob on the speaker embedding, rather than as a retrained emotion module in the backbone.
Code & Implementation
This repository provides reproducibility code for the paper Task-Vector Arithmetic for Emotional Expressivity Control in Language-Model-Based Text-to-Speech. It focuses on localizing emotional prosody control within a large-scale LM-TTS system, specifically pinpointing the speaker x-vector as the dominant carrier of emotional information.
The implementation includes scripts for a systematic four-step elimination study and demonstrates training-free emotional control by arithmetic in the x-vector space. Key methods described in the paper, such as computing the emotional direction vector (tau) and applying it to target speaker embeddings, are implemented in scripts under scripts/repro/ and scripts/elimination/.
The repository also provides precomputed tau vectors (data/tau/*.pt) and deployment utilities that apply emotion transfer to arbitrary input audio without retraining (notably scripts/deploy/emotionize_audio.py), reflecting the paper's proposed training-free approach.
The paper's primary experiments and reproduction steps are organized as command-line scripts, with environment variables managing dataset paths. The emotional arithmetic and inference are encapsulated in the src.emotionize module, supporting a programmatic API.
Overall, the repo aligns closely with the paper's modular study and emotional control technique, enabling reproduction and deployment of the evaluations and demonstrations presented in the paper.