M2S-AVSR
M2S-AVSR: Modality-aware Multi-view Self-supervised Representation for Robust Audio-Visual Speech Recognition
M2S-AVSR improves audio-visual speech recognition by learning view-invariant visual features and adaptively gating visual input based on quality and timing. It boosts robustness against viewpoint changes, occlusion, and asynchrony, and introduces a real-world multi-view AV dataset for challenging environments.
Links
Abstract
Audio-Visual Speech Recognition (AVSR) enhances speech recognition robustness by leveraging visual cues, while real-world scenarios remain challenging due to viewpoint variation, audio distortion, and visual occlusion, which degrade modality quality and increase audio-visual asynchrony. In this paper, we propose a novel Modality-aware Multi-view Self-supervised representation framework for robust Audio-Visual Speech Recognition (M2S-AVSR). First, we introduce a multi-view representation learning encoder to learn view-invariant visual speech representations. Next, we employ a modality-aware module that explicitly models modality quality and cross-modal synchrony to perform fine-grained modality-aware fusion, enabling fine-grained visual information injection during decoding. In addition, we release AISHELL8-RealScene, a public multi-scenario, multi-view conversational audio-visual dataset recorded in real-world environments, and establish a speech recognition benchmark on it. Experiments on English and Mandarin benchmarks demonstrate the effectiveness of the proposed method under challenging conditions. On LRS3, M2S-AVSR achieves up to 29.4% relative improvement under viewpoint perturbation and visual degradation settings. Our method also achieves new state-of-the-art performance on the MISP2021-AVSR test set. On AISHELL8-RealScene, it achieves the best result in outdoor scenes. The proposed method and dataset provide useful support for future research on robust speech and multimodal tasks under realistic conditions.
1. Problem Setting and High-Level Idea
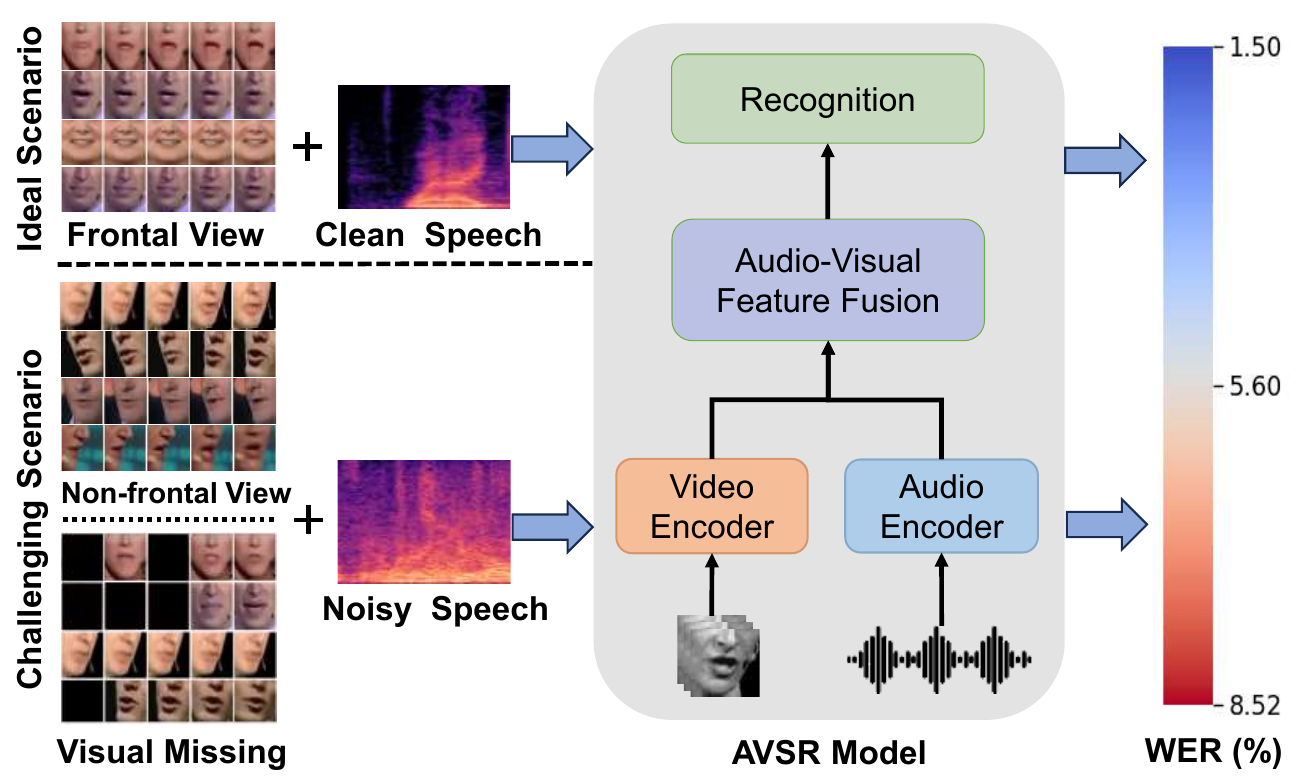
This paper addresses robust audio-visual speech recognition (AVSR) in realistic environments, where the visual stream is not guaranteed to be stable or aligned. The motivating failure modes are threefold: viewpoint variation (non-frontal or changing camera angle), visual degradation (occlusion, blur, missing lip regions), and audio-visual asynchrony or inconsistency. The authors argue that standard AVSR fusion methods are often too uniform: they combine audio and video without explicitly estimating when the visual stream is trustworthy or synchronized.
The proposed solution, M2S-AVSR (Modality-aware Multi-view Self-supervised representation for robust AVSR), has two main components: (1) a multi-view self-supervised visual encoder that learns view-invariant lip representations from real and synthesized views, and (2) a modality-aware fusion mechanism that gates visual injection based on visual quality and cross-modal synchrony.
The paper also contributes a new dataset, AISHELL8-RealScene, a multi-scenario, multi-view conversational AV corpus recorded in real-world environments, and uses it to establish a benchmark for realistic speech recognition.
2. Main Contributions
- Multi-view self-supervised visual representation learning. The MVL encoder is trained on real and synthesized multi-view pairs using consistency and domain-alignment objectives, so that the visual representation becomes more robust to camera pose changes.
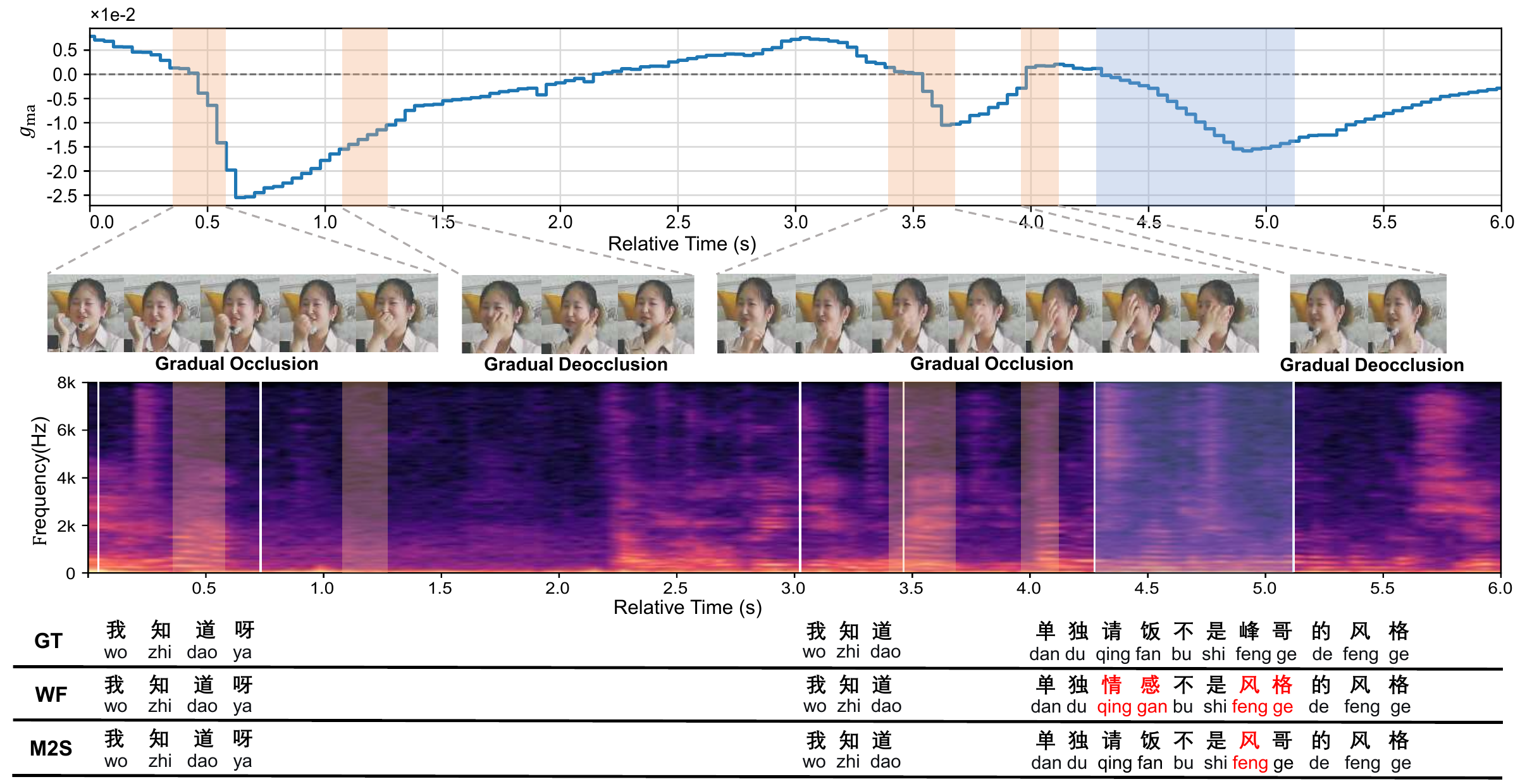
- Modality-aware fusion. The decoder does not blindly inject visual features. Instead, it estimates a frame-wise visual quality gate $g_q(t)$ and a synchrony gate $g_s(t)$, then combines them into a modality-aware gate $g_{\mathrm{ma}}(t)$ to regulate visual cross-attention.
- New real-world benchmark. AISHELL8-RealScene contains 102.19 hours of synchronized audio and video from 171 foreground speakers across five locations and both indoor and outdoor settings.
- Strong empirical results. On LRS3, the method improves robustness under viewpoint perturbation and masking; on MISP2021-AVSR it reaches new state of the art; and on AISHELL8-RealScene it performs best in outdoor scenes.
3. Overall Architecture
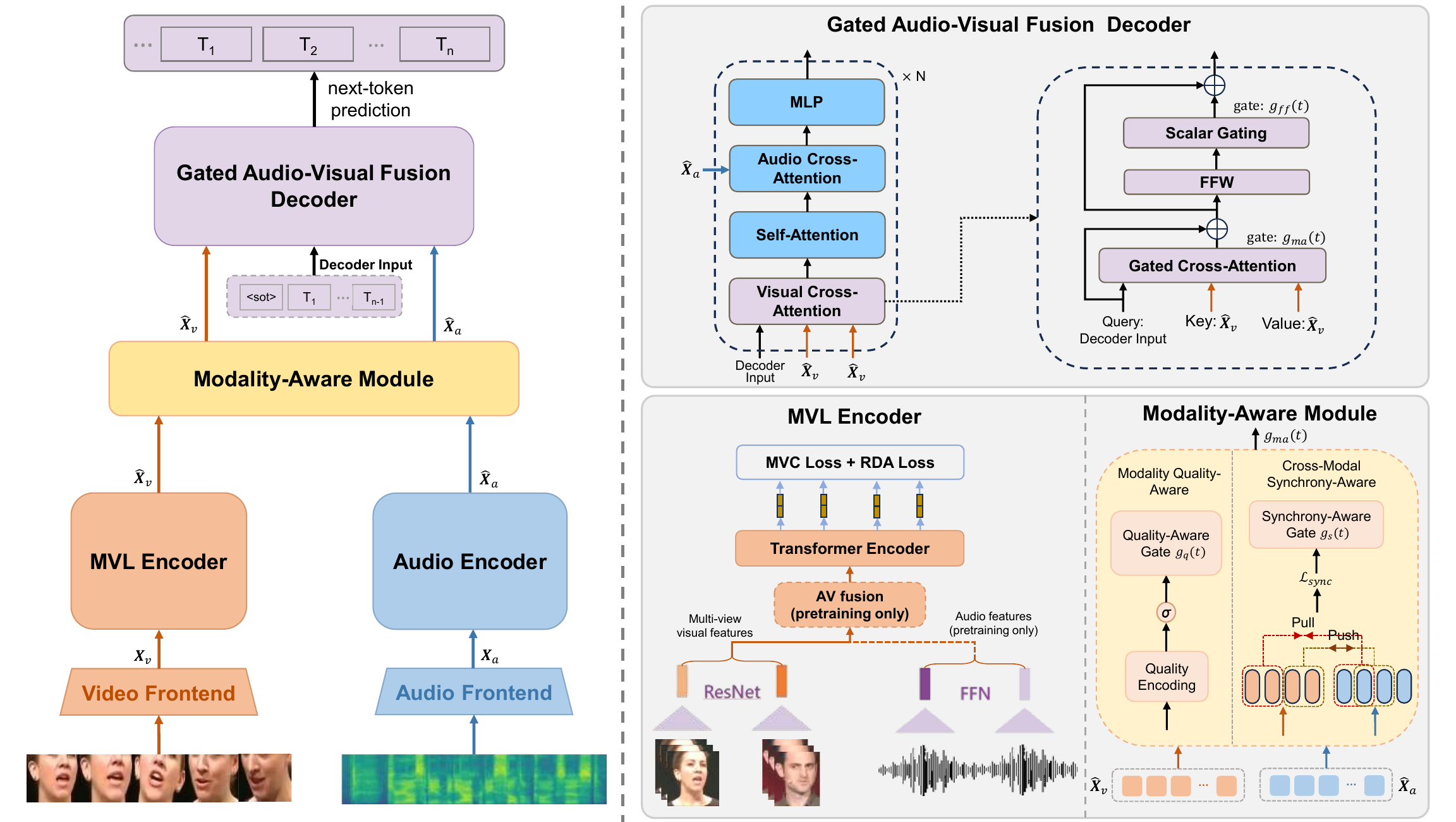
The full system uses a Whisper Large encoder as the audio backbone and an AV-HuBERT-initialized multi-view visual encoder as the visual backbone. The decoder is based on Whisper, but each decoder block is modified by inserting visual cross-attention before self-attention and by controlling the visual contribution with modality-aware gates.
In the architecture figure, the visual encoder is called the MVL encoder. During AVSR training and inference, it consumes only multi-view visual features; the extra audio branch used in multi-view pretraining is disabled. The method is trained in three stages: visual multi-view pretraining, audio-only Whisper adaptation, and AVSR fusion training with frozen encoders.
4. Multi-View Self-Supervised Visual Representation Learning
The visual side is where the paper makes its most distinct representation-learning contribution. Rather than relying on a standard pretrained AV-HuBERT visual encoder, the authors build a multi-view representation learning (MVL) encoder initialized from AV-HuBERT Large and then further optimized using a mix of real and synthesized views. The purpose is to make the lip encoder robust to viewpoint changes and to align representations across domains.
4.1 Multi-View Consistency Loss
For each utterance, the paper pairs a real view $\mathbf{x}_{r,i}$ with a synthesized view $\mathbf{x}_{s,i}$ and compares their embeddings $\mathbf{X}_{r,i}=f(\mathbf{x}_{r,i})$ and $\mathbf{X}_{s,i}=f(\mathbf{x}_{s,i})$. Two alignment terms are used:
$$L_{\mathrm{mse}} = \frac{1}{N}\sum_{i=1}^{N} \lVert \mathbf{X}_{r,i} - \mathbf{X}_{s,i} \rVert_2^2$$
and a correlation-matching term based on normalized embeddings $\mathbf{Z}_{r,i}$ and $\mathbf{Z}_{s,i}$:
$$L_{\mathrm{corr}} = \frac{1}{N}\sum_{i=1}^{N} \left\| \operatorname{Corr}(\mathbf{Z}_{r,i}) - \operatorname{Corr}(\mathbf{Z}_{s,i}) \right\|_F^2$$
These are combined as
$$L_{\mathrm{MVC}} = \alpha L_{\mathrm{corr}} + (1-\alpha)L_{\mathrm{mse}}$$
so the encoder matches both pointwise features and their internal relational structure. The paper emphasizes that the correlation term is intended to preserve structural dependencies, not just low-level similarity.
4.2 Representation Domain Alignment
To reduce the gap between real and synthesized views, the authors add a contrastive representation domain alignment objective. A real sample and its corresponding synthesized sample from the same utterance form a positive pair, while other utterances in the batch serve as negatives. Using cosine similarity, the loss is
$$L_{\mathrm{RDA}} = -\frac{1}{N}\sum_{i=1}^{N} \log \frac{\exp(\operatorname{sim}(\mathbf{X}_{r,i},\mathbf{X}_{s,i})/\tau)}{\sum_{j=1}^{M}\exp(\operatorname{sim}(\mathbf{X}_{r,i},\mathbf{X}_{n,j})/\tau)}$$
with temperature $\tau$. This encourages the encoder to focus on speech-related motion patterns rather than view-specific artifacts introduced by simulation.
4.3 Full MVL Objective
The MVL encoder is trained with the weighted sum
$$L_{\mathrm{MVL}} = \lambda_{\mathrm{MVC}}L_{\mathrm{MVC}} + \lambda_{\mathrm{RDA}}L_{\mathrm{RDA}} + \lambda_{\mathrm{MMP}}L_{\mathrm{MMP}}$$
where $L_{\mathrm{MMP}}$ is the masked multimodal cluster prediction objective inherited from AV-HuBERT pretraining. In other words, the encoder is not trained from scratch: it retains AV-HuBERT’s masked prediction behavior while being explicitly adapted to multi-view robustness.
5. Modality-Aware Fusion
After the MVL encoder produces view-robust visual features $\hat{\mathbf{X}}_v$, the paper tackles the more difficult question of when and how to inject visual information into decoding. This is important because visual input may be unreliable due to occlusion, blur, or changes in viewpoint, and because even high-quality lip features can be misaligned with audio.
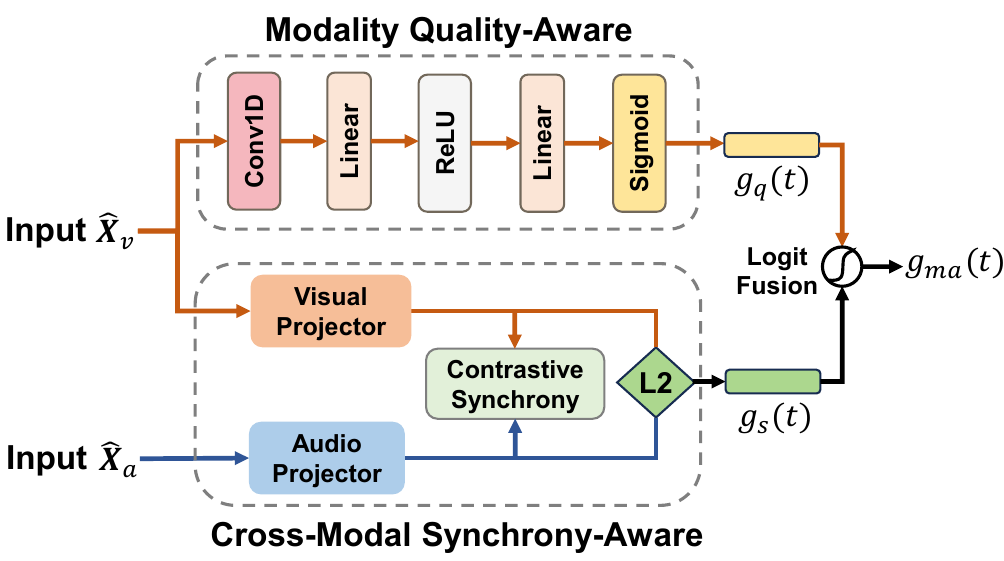
5.1 Quality-Aware Gate
The first branch estimates frame-level visual reliability. A temporal convolution is applied to the visual features, followed by a lightweight MLP and sigmoid output to produce a gate $g_q(t) \in [0,1]$. Intuitively, this gate is larger when the visual stream is cleaner and more useful for decoding, and smaller when the lips are occluded or otherwise degraded.
5.2 Synchrony-Aware Gate
The second branch measures cross-modal consistency. The audio and visual streams are projected into a shared embedding space using modality-specific projectors, and their local-window distance is computed as
$$D_s(t) = \frac{1}{2T_w+1}\sum_{k=t-T_w}^{t+T_w} \lVert \mathbf{E}_a(k) - \mathbf{E}_v(k) \rVert_2$$
The corresponding synchrony gate is
$$g_s(t) = \frac{\gamma}{\gamma + D_s(t)}$$
so that higher synchrony yields a larger gate. The local temporal window $T_w$ gives some tolerance to slight misalignment, which is important in practice.
5.3 Fused Modality-Aware Gate
The two gates are combined through logit-space fusion:
$$g_{\mathrm{ma}}(t) = \tanh\Big(w_q\,\operatorname{logit}(g_q(t)) + w_s\,\operatorname{logit}(g_s(t))\Big)$$
This final scalar modulates visual cross-attention in the decoder. The paper’s design choice is to keep the audio backbone as the stable foundation and use the visual stream as an adaptively injected refinement rather than a uniformly fused signal.
5.4 Gated Audio-Visual Fusion Decoder
In each decoder block, the hidden state attends to the visual features via cross-attention, and the result is scaled by $g_{\mathrm{ma}}(t)$ before being added back to the residual stream. The block also uses a learnable feed-forward gate $g_{\mathrm{ff}}$ bounded by $\tanh(\cdot)$, and all gating parameters are initialized near zero to prevent destabilizing the pretrained Whisper decoder early in training.
6. Training Strategy and Objectives
The system is trained in three stages:
- MVL pretraining. The visual encoder is initialized from AV-HuBERT Large and trained on multi-view data with the MVL loss.
- Whisper adaptation. The Whisper encoder is fine-tuned on audio-only data for domain adaptation, following the paper’s audio-pretraining recipe.
- AVSR fusion training. Both encoders are frozen, and only the modality-aware module plus the visual cross-attention layers in the decoder are trained.
During the final fusion stage, the paper adds a contrastive synchrony regularizer for temporally aligned audio-visual segments versus shifted mismatched segments:
$$L_{\mathrm{sync}} = \frac{1}{T_s}\sum_{t=1}^{T_s} \left(y_t D_s^2 + (1-y_t)[\max(m-D_s,0)]^2\right)$$
The AVSR objective is then
$$L_{\mathrm{avsr}} = L_{\mathrm{att}} + \lambda_{\mathrm{sync}}L_{\mathrm{sync}}$$
where $L_{\mathrm{att}}$ is the autoregressive cross-entropy on target tokens. The authors set $\lambda_{\mathrm{sync}} = 0.1$.
Key implementation choices reported in the paper include: initialization from the 5th-iteration AV-HuBERT Large model, pretraining on $\text{ms433h}$ and $\text{ms1759h}$, fine-tuning on $\text{ms30h}$ or $\text{ms433h}$, a two-stage loss schedule with $\tau = 0.07$ and $\alpha = 0.6$, decay of $\lambda_{\mathrm{RDA}}$ from $0.3$ to $0.1$ in the last 70% of training, Adam optimization with weight decay $0.01$, learning rate $0.002$ for MVL pretraining, and a beam size of 25 at inference.
7. AISHELL8-RealScene Dataset
AISHELL8-RealScene is presented as a public, multi-scenario, multi-view conversational AV corpus recorded in real-world environments. It contains 102.19 hours of synchronized audio and video from 171 foreground speakers. The collection includes both indoor and outdoor scenes and is explicitly designed to capture realistic background activity and interference.
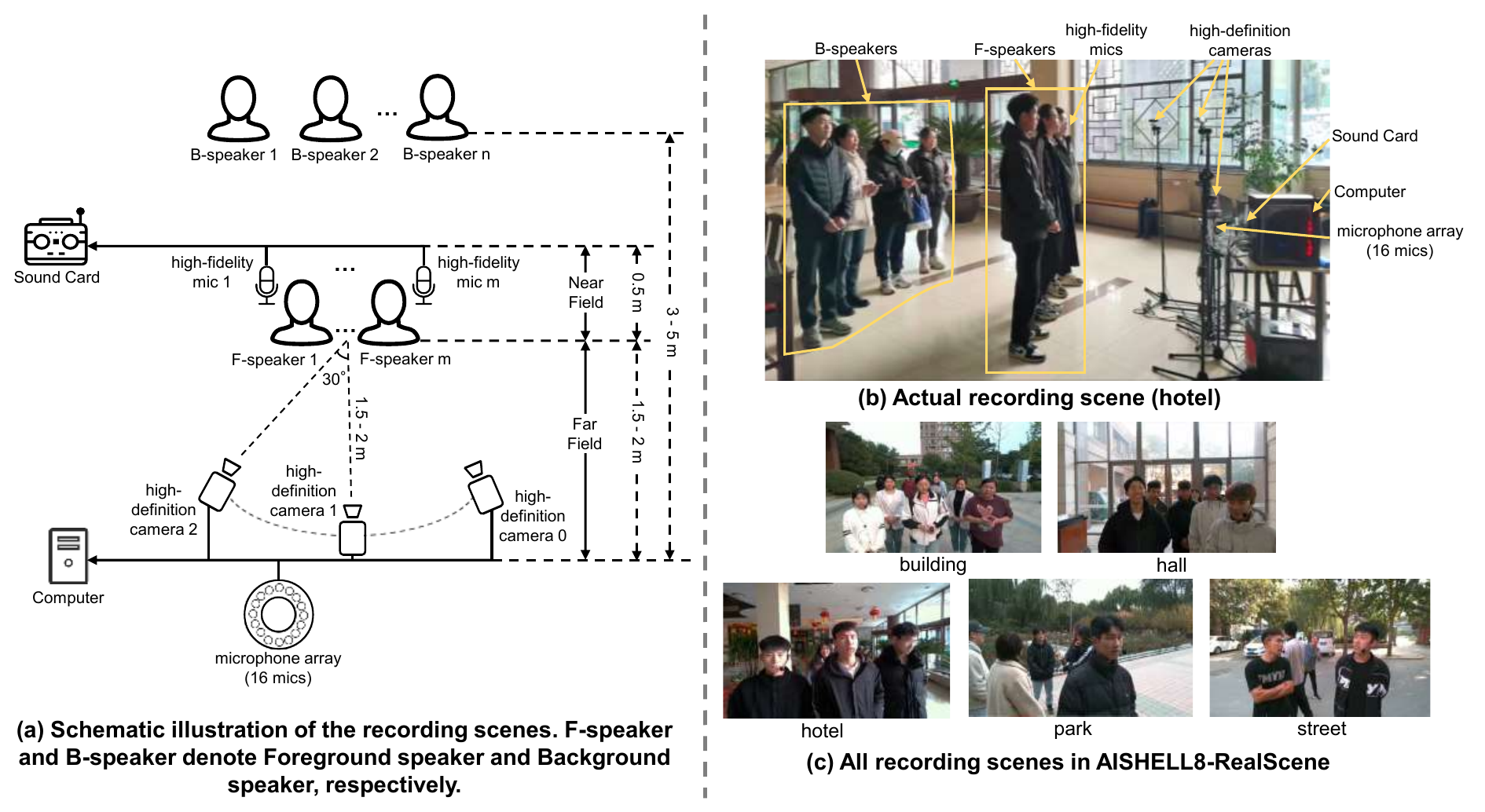
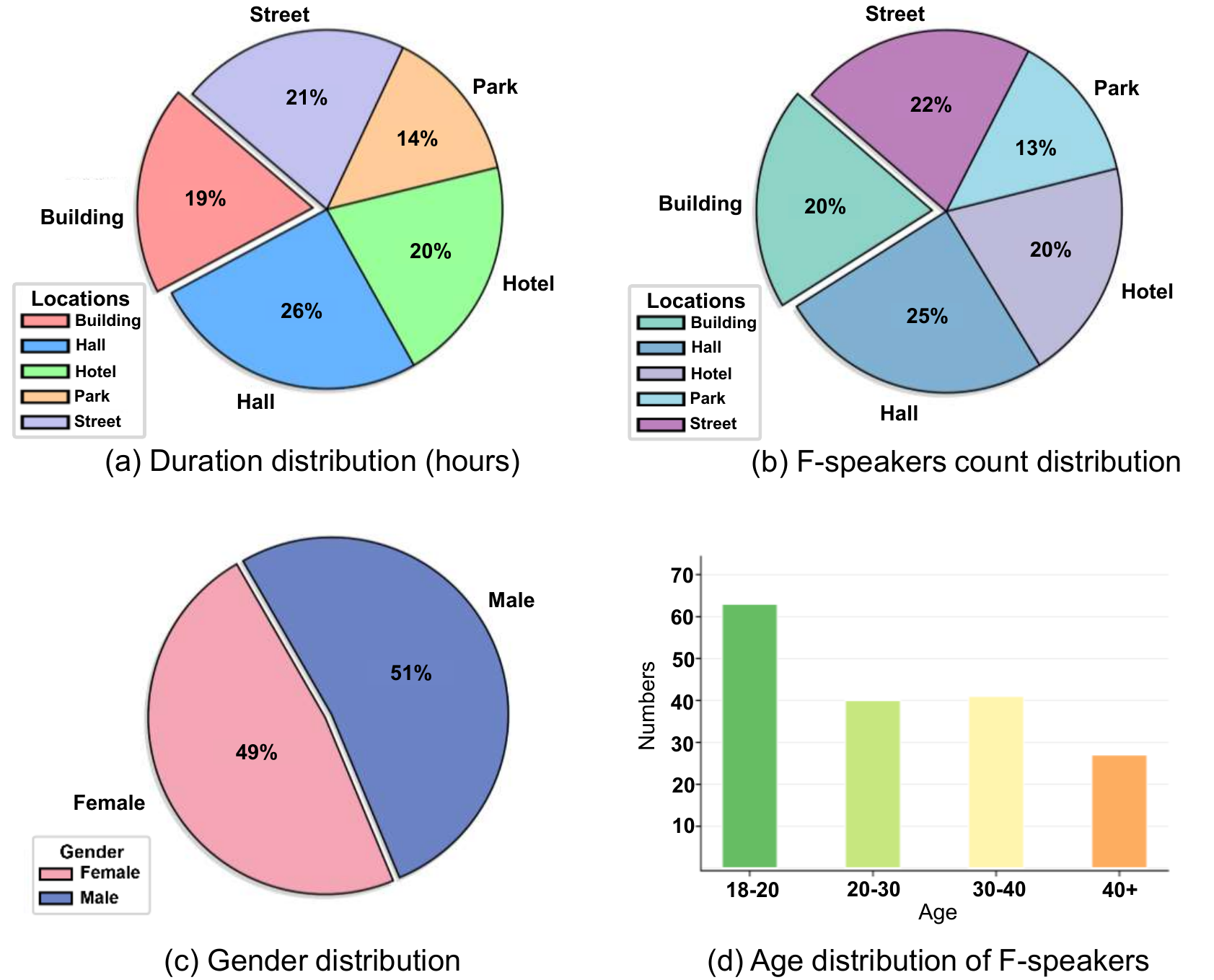
7.1 Recording Setup
Audio is captured with a circular microphone array of 16 microphones at 16 kHz / 16-bit, and the release includes 8-channel far-field audio chosen by uniform angular subsampling. Foreground speakers also wear near-field close-talking microphones for transcription. Video is captured by three HD cameras at 25 fps from roughly $30^\circ$ separated viewpoints; face detection, face recognition, and face re-identification are used to extract foreground-speaker face crops at $256\times256$ resolution.
The corpus covers five locations: building, hall, hotel, park, and street. The paper defines five permutation patterns (P1--P5) that vary the number of foreground and background speakers to create different conversational and interference settings. The resulting split is balanced across locations, with no speaker overlap across train/dev/eval subsets.
7.2 Dataset Splits
| Split | Duration (h) | Indoor (h) | Outdoor (h) | Sessions | Groups | F-speakers | Gender ratio (M/F) |
|---|---|---|---|---|---|---|---|
| Train | 79.84 | 36.74 | 43.10 | 133 | 56 | 133 | 1:1.18 |
| Dev | 10.70 | 5.03 | 5.67 | 18 | 7 | 18 | 1:0.29 |
| Eval | 11.65 | 5.28 | 6.37 | 20 | 7 | 20 | 1:0.82 |
| Total | 102.19 | 47.05 | 55.14 | 171 | 70 | 171 | 1:0.99 |
The paper notes that the overlapping-speech ratio is about 25%, making the benchmark suitable for realistic conversational modeling rather than isolated speech only.
8. Experimental Setup
The paper evaluates on LRS3, VoxCeleb2, MISP2021-AVSR, OuluVS2, and the new AISHELL8-RealScene benchmark. For English AVSR, LRS3 is split into 433 h train / 1 h validation / 1 h test, and the 433 h LRS3 training set is combined with 1,326 h of VoxCeleb2 for large-scale pretraining. For LRS3 robustness tests, babble noise at $0$ dB SNR is applied, and synthetic test conditions include view offsets of $5^\circ$ and $15^\circ$ and visual masking ratios of $0.1$ and $0.3$.
The paper also builds multi-view training variants by mixing synthesized and real data. In the reported setup, $\text{ms30h}$ and $\text{ms433h}$ contain 30% and 40% synthesized data, respectively, while $\text{ms1759h}$ is the larger pretraining set. For Mandarin evaluation, the paper reports character error rate (CER), and for LRS3 it reports word error rate (WER).
9. Main Results on LRS3
The LRS3 table shows that M2S-AVSR is particularly strong under adverse conditions. Compared with AV-HuBERT and CMA, it lowers noisy WER from $5.80\%$ and $4.40\%$ to $3.00\%$ in the 433 h setting, and further to $2.12\%$ in the 1,759 h setting. Under viewpoint perturbation and masking, it consistently beats prior AVSR and LLM-based baselines.
The paper also reports that, when multi-view data are used, M2S-AVSR improves further and achieves up to 29.4% relative improvement under challenging visual conditions. In the table below, values are shown exactly as reported.
| Model | Modality | Total params | Training data | Clean WER (%) | Noisy WER (%) | View $5^\circ$ | View $15^\circ$ | Mask 0.1 | Mask 0.3 |
|---|---|---|---|---|---|---|---|---|---|
| AV-HuBERT | A+V | 477M | 433/1,759 h | 1.40 | 5.80 | 9.60 | 14.08 | 7.29 | 11.14 |
| Whisper-Flamingo | A+V | 2.5B | 433/1,759 h | 1.50/2.00 | 5.60/5.60 | 6.86/6.37 | 7.39/7.26 | 6.72/6.17 | 8.52/8.22 |
| Llama-AVSR | A+V | 8.7B | 1,759/1,759 h | 0.77 | 4.00 | 6.00 | 9.48 | 4.73 | 6.75 |
| MMS-Llama | A+V | 3.2B | 433/1,759 h | 0.90/0.72 | 2.4/1.9 | 4.90/3.95 | 6.93/6.19 | 4.79/4.53 | 6.17/5.90 |
| M2S-AVSR | A+V | 2.6B | 433/1,759 h | 0.82/0.68 | 3.00/2.12 | 5.58/4.00 | 6.78/5.95 | 5.38/4.64 | 7.23/5.84 |
| M2S-AVSR with multi-view data | A+V | 2.6B | ms433/ms1,759 h | 0.82/0.65 | 2.84/2.02 | 4.83/3.86 | 5.78/4.05 | 5.30/4.60 | 6.01/5.77 |
The key takeaway is that the proposed fusion scheme adds robustness without relying on very large language-model backbones. The authors explicitly note that noisy-condition comparisons are not perfectly apples-to-apples across methods because some baselines use different babble-noise generation protocols.
10. Visual Robustness Analysis and Multi-View Learning Results
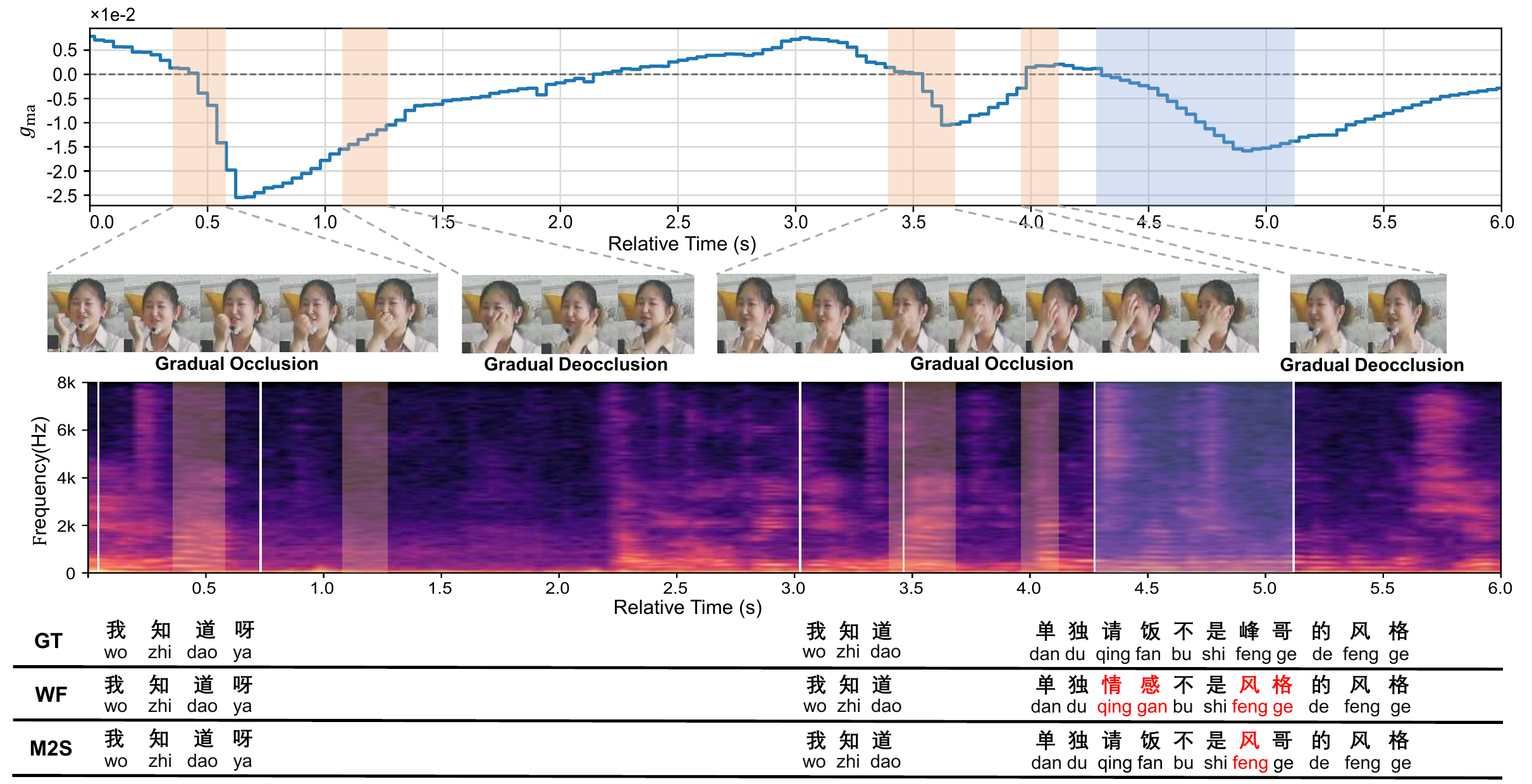
To understand what the MVL encoder learns, the paper includes both qualitative and quantitative analyses. The occlusion-based sensitivity plot shows that the proposed encoder keeps its attention concentrated on lip regions even when the view changes, whereas AV-HuBERT becomes less stable under simulated viewpoint shifts. The authors interpret this as evidence that MVL learns more view-consistent lip representations.

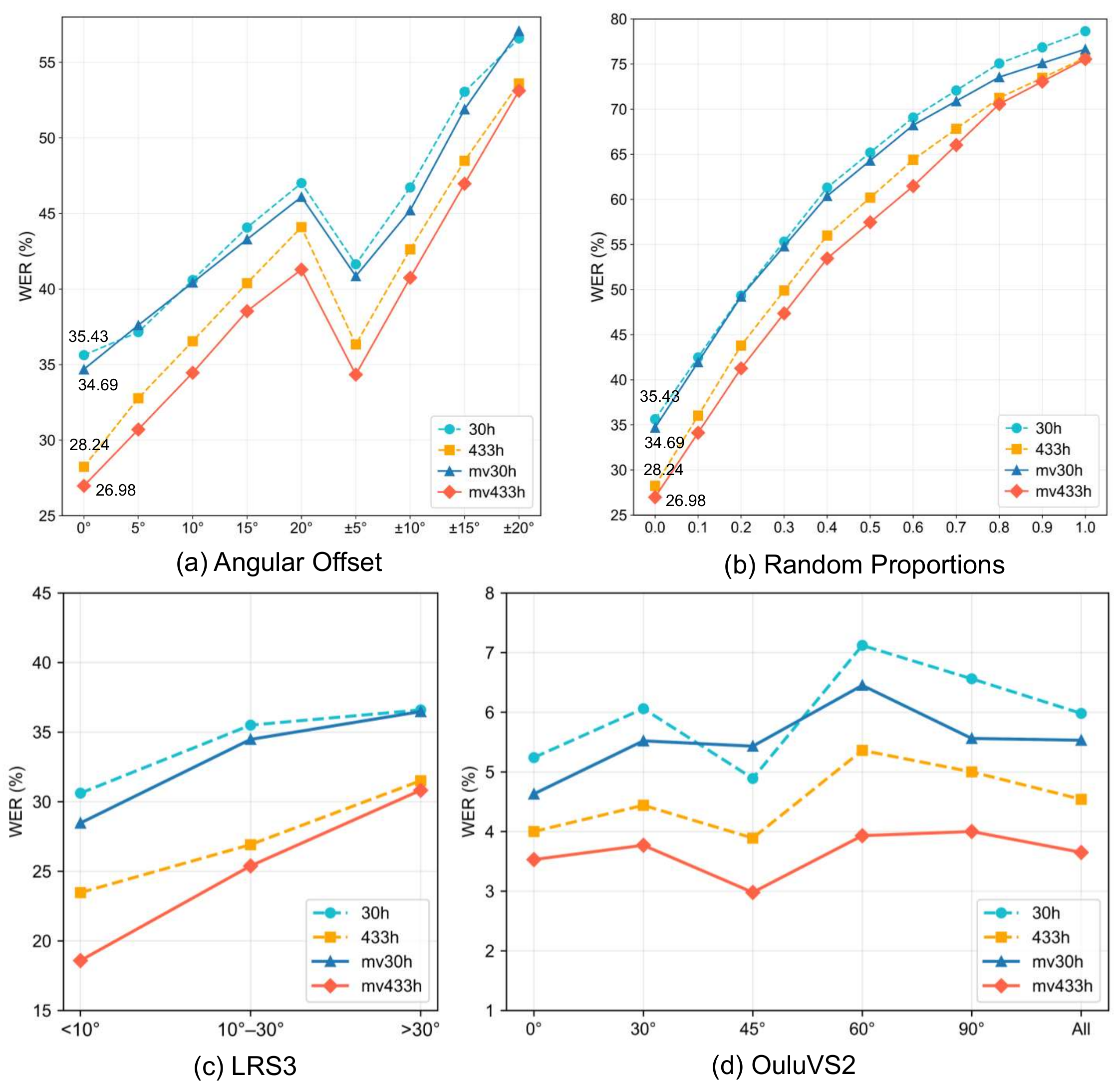
In supplementary experiments, the MVL encoder consistently outperforms the original AV-HuBERT under synthetic and real multi-view settings. Reported examples include a WER of $41.29\%$ versus $44.09\%$ at $+20^\circ$ on the synthesized-view test, and $3.65\%$ versus $4.54\%$ on the full OuluVS2 set. The paper also reports relative reductions of up to $20.8\%$ on yaw-grouped LRS3 subsets.
11. Modality-Aware Fusion Results on MISP2021-AVSR
The MISP2021-AVSR benchmark is used to test the modality-aware fusion module under realistic indoor conversational conditions. The paper reports a CER of 21.95% for the full M2S-AVSR model, which is better than all listed prior systems, including ModalBiasAVSR at 22.13% and Whisper-Flamingo at 26.08% in the compared setup. With ROVER post-processing, CER drops further to 18.82%, which the paper describes as a 12.6% relative reduction over the previous best ROVER result.
| System | Year | Audio data (h) | Visual data | Backbone | CER (%) |
|---|---|---|---|---|---|
| SJTU | 2022 | 300 | LRW-1000 | Conformer | 34.02 |
| NIO | 2022 | 3300 | LRW-1000 | Transformer | 25.07 |
| USTC | 2023 | 500 | w/o extra | Conformer | 24.58 |
| ModalBiasAVSR | 2024 | 1000 | w/o extra | Conformer | 22.13 |
| Whisper-Flamingo | 2025 | 600 | LRS3+Vox2(En) | Transformer | 26.08 |
| M2S-A | 2026 | 600 | -- | Transformer | 25.08 |
| M2S-V | 2026 | -- | LRS3+Vox2(En) | Transformer | 76.35 |
| M2S-AV | 2026 | 600 | LRS3+Vox2(En) | Transformer | 21.95 |
| M2S-AV with ROVER | 2026 | 600 | LRS3+Vox2(En) | Transformer | 18.82 |
12. AISHELL8-RealScene Benchmark Results
The AISHELL8-RealScene benchmark is split into indoor and outdoor subsets, and the paper reports both overall and camera-view-specific performance. The main conclusion is that the proposed model helps most in the harder outdoor scenes, where both background noise and visual interference are stronger. The authors note that audio-only systems remain competitive indoors, but visual information becomes more helpful in outdoor conditions.
| Model | Indoor CER (%) | Outdoor CER (%) | Overall CER (%) |
|---|---|---|---|
| Whisper-finetuned | 29.49 | 42.01 | 35.75 |
| Fun-ASR-Nano | 34.63 | 49.94 | 42.74 |
| FireRed-ASR | 23.66 | 38.69 | 31.19 |
| Qwen3-ASR | 23.98 | 38.76 | 31.39 |
| Whisper-Flamingo | 28.30 | 41.64 | 34.97 |
| LLaMA-AVSR | 27.43 | 40.82 | 34.13 |
| MMS-LLaMA | 25.52 | 39.16 | 32.34 |
| M2S-AVSR (audio-only) | 26.70 | 40.56 | 33.64 |
| M2S-AVSR | 25.35 | 37.47 | 31.41 |
On the outdoor subset, M2S-AVSR achieves the best CER, and the paper reports that this corresponds to a 7.3% relative reduction compared with the mean CER of Whisper-Flamingo and MMS-LLaMA. The result supports the paper’s thesis that the visual stream is especially useful when the acoustic scene is difficult.
A supplementary view-specific table further shows that training on all three camera views makes M2S-AVSR nearly view-invariant on AISHELL8-RealScene, with identical reported CER across D0/D1/D2 in the final row, while Whisper-Flamingo remains less robust across views.
| Model | Training views | D0 | D1 | D2 | Avg |
|---|---|---|---|---|---|
| Whisper-Flamingo | Single, Front D1 | 35.05 | 34.48 | 34.75 | 34.76 |
| Whisper-Flamingo | All | 35.12 | 34.76 | 35.03 | 34.97 |
| M2S-AVSR | Single, Front D1 | 32.04 | 31.73 | 31.99 | 31.92 |
| M2S-AVSR | All | 31.41 | 31.41 | 31.41 | 31.41 |
13. Ablation Study
The ablation study isolates the effects of the MVL encoder, the consistency/domain-alignment losses, and the modality-aware gates. The baseline without MVL or modality-aware fusion reaches 5.55% noisy WER. Adding only the MVL encoder gives modest gains, but combining both $L_{\mathrm{MVC}}$ and $L_{\mathrm{RDA}}$ is better than using either alone. The biggest improvements come from the modality-aware fusion block, especially the quality-aware gate and synchrony-aware gate together.
| System | Multi-view data | $L_{\mathrm{MVC}}$ | $L_{\mathrm{RDA}}$ | $g_q$ | $g_s$ | Clean WER | Noisy WER | View $15^\circ$ | Mask |
|---|---|---|---|---|---|---|---|---|---|
| w/o MVL + MAF | -- | -- | -- | -- | -- | 1.32 | 5.55 | 7.16 | 8.50 |
| w/ MVC | ✓ | ✓ | -- | -- | -- | 1.32 | 5.47 | 7.04 | 8.41 |
| w/ RDA | ✓ | -- | ✓ | -- | -- | 1.32 | 5.60 | 6.94 | 8.45 |
| w/ MVC + RDA | ✓ | ✓ | ✓ | -- | -- | 1.32 | 5.43 | 6.05 | 8.42 |
| w/ QualityGate | ✓ | ✓ | ✓ | ✓ | -- | 1.10 | 2.93 | 6.14 | 6.37 |
| w/ SynchronyGate | ✓ | ✓ | ✓ | -- | ✓ | 0.88 | 2.88 | 6.10 | 6.51 |
| w/ Modality-Aware | -- | ✓ | ✓ | ✓ | ✓ | 0.82 | 2.90 | 6.78 | 7.23 |
| w/ Modality-Aware | ✓ | ✓ | ✓ | ✓ | ✓ | 0.82 | 2.84 | 5.78 | 6.01 |
The ablation supports three conclusions. First, multi-view training alone is not sufficient; the MVL objectives are needed to translate synthetic diversity into useful view invariance. Second, the quality and synchrony gates both matter, and each improves robustness in slightly different ways. Third, the combination of multi-view representation learning and modality-aware fusion gives the best overall result, reducing noisy WER by 48.8% relative to the system without these components.
14. Practical Takeaways
- The paper’s core design principle is to separate representation robustness from fusion reliability: first learn view-invariant lip features, then decide how much to trust them at decode time.
- The modality-aware module is explicitly designed for realistic failure modes, not just synthetic noise. It uses both visual quality and audio-visual synchrony rather than a single confidence signal.
- AISHELL8-RealScene fills an important gap by providing a real-world multi-view conversational benchmark with indoor/outdoor settings and interfering background speakers.
- The results suggest that the method is especially valuable when the visual stream is unstable or the acoustic scene is corrupted; on clean data, gains are smaller, but robustness improves substantially.
15. Limitations and Scope
The paper does not present a dedicated failure-analysis section, so the limitations must be read from the experimental scope. The reported improvements are concentrated in challenging conditions: viewpoint perturbation, visual masking, noisy audio, and real-world scene variation. The method is still built on large pretrained backbones and a multi-stage training pipeline, so its computational footprint is non-trivial. In addition, the strongest gains are demonstrated on the paper’s chosen benchmarks and evaluation protocols; the paper does not claim broader generalization beyond the tested AVSR datasets and conditions.
16. Bottom Line
M2S-AVSR is a robust AVSR system that combines multi-view self-supervised visual representation learning with a modality-aware gated fusion decoder. The method is carefully engineered around the two main sources of real-world AVSR failure: viewpoint-dependent visual variation and unreliable audio-visual coupling. Across LRS3, MISP2021-AVSR, and AISHELL8-RealScene, the paper shows that this design improves robustness, especially in noisy, occluded, and multi-view conditions, and that the newly released AISHELL8-RealScene benchmark is a meaningful testbed for future work in realistic multimodal speech recognition.