GLASS
GLASS: GRPO-Trained LoRA for Acoustic Style Steering in Zero-Shot Text-to-Speech
GLASS is a zero-shot TTS framework that controls speaking rate and pitch via LoRA adapters trained from post-generation rewards, not style labels. This modular approach enables smooth style edits and multi-axis composition without changing speaker prompts, preserving speaker identity and naturalness.
Links
Paper & demos
Impact
Abstract
We propose GLASS, a framework for composable acoustic style control in zero-shot autoregressive text-to-speech (TTS) that learns controls from post-generation rewards rather than style labels. In zero-shot TTS, a speaker prompt often entangles speaker identity with prosodic attributes such as speaking rate and pitch, making it difficult to change style without changing the prompt itself. GLASS instead treats each acoustic attribute as a reward-defined control direction. For each control axis, GLASS freezes the TTS backbone and trains one lightweight LoRA adapter with Group Relative Policy Optimization (GRPO), using speech-token length and mean F0 as style rewards and WER as an intelligibility anchor. Because each control is represented as a LoRA weight update, independently trained adapters can be swapped, interpolated, and composed through linear LoRA arithmetic without retraining the backbone. Experiments on speaking rate and pitch control show targeted style shifts while preserving naturalness, speaker similarity, and intelligibility, and demonstrate smooth interpolation and multi-axis composition across independently trained adapters.
Introduction
GLASS targets a practical gap in zero-shot autoregressive text-to-speech (TTS): a speaker prompt usually entangles who is speaking with how they speak. In modern zero-shot systems, the same prompt that preserves speaker identity also implicitly carries acoustic style information such as speaking rate and pitch. That makes style editing awkward: changing style often requires changing the prompt itself, and prompt-based control does not naturally support continuous interpolation or multi-axis composition.
The paper’s central idea is to turn acoustic style into a reward-defined control problem rather than a label-conditioned generation problem. Instead of training on style annotations or reference examples, GLASS learns style directions from post-generation measurements. The method freezes the TTS backbone and trains one lightweight LoRA adapter per control axis using Group Relative Policy Optimization (GRPO). Each axis is defined by a reward function computed after waveform generation, using speech-token length for speaking rate, mean $F_0$ for pitch, and an intelligibility anchor based on Whisper-derived WER.
This yields a modular representation of style: each control axis is stored as a LoRA weight update, so independently trained adapters can be swapped, linearly blended, and composed without retraining the backbone. The paper’s experiments focus on two measurable axes, speaking rate and pitch, and show that the resulting adapters can shift those attributes while largely preserving speaker similarity, naturalness, and intelligibility.
- Problem: zero-shot TTS prompts conflate speaker identity and style.
- Goal: modify speaking rate and pitch while keeping the speaker prompt fixed.
- Key novelty: style control learned from rewards, not style labels.
- Modularity claim: reward-trained LoRAs support swapping, interpolation, and composition.
Method
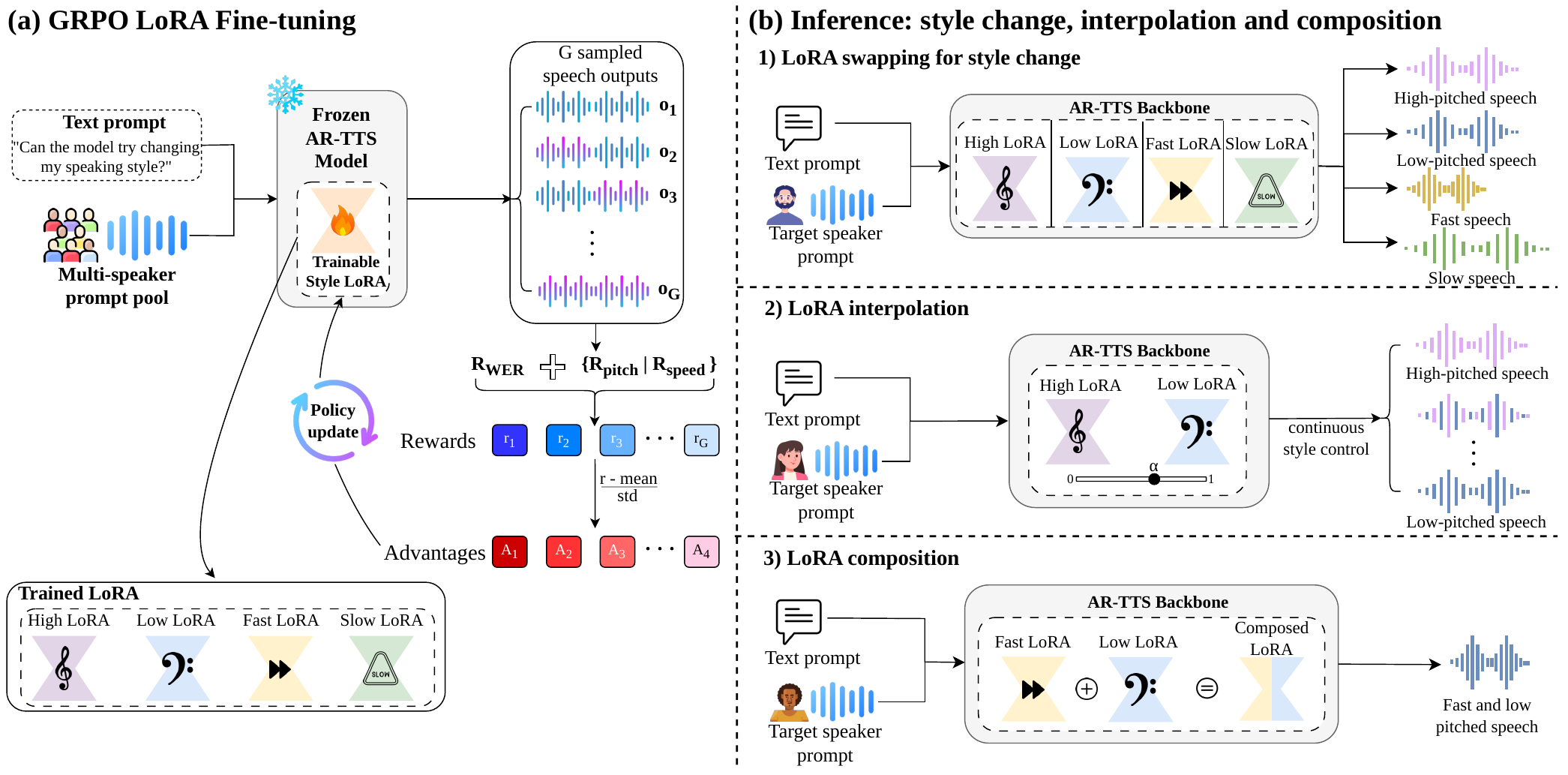
Backbone, policy view, and adapterization
The model is framed as a speech-token policy $\pi(\mathbf{y} \mid \mathbf{x})$, where $\mathbf{x}$ contains text plus a speaker prompt and $\mathbf{y}$ is a sequence of discrete speech tokens. GLASS freezes the base TTS system and learns one LoRA adapter for each style direction $k$. In the implementation details, the backbone is CosyVoice2-0.5B, and LoRA is attached only to the Qwen2 autoregressive token model while the speech embeddings, token decoder, flow-matching acoustic model, and vocoder remain frozen.
The targeted modules are the attention projections $q_{\mathrm{proj}}$ and $v_{\mathrm{proj}}$, with rank $r=16$, scaling $\alpha=32$, and dropout $0.05$. This yields 1.08M trainable parameters, or 0.22% of the 495M-parameter autoregressive backbone, which is important for keeping each style direction lightweight and modular.
GRPO objective
For each input $\mathbf{x}$, GLASS samples a group of $G$ completions from the same text and speaker prompt. Each completion receives a reward from an axis-specific reward model $R_k$, and the training update uses within-group relative advantages rather than absolute reward values:
$$ \mathbf{y}_1,\ldots,\mathbf{y}_G \sim \pi_{\theta_k}(\cdot\mid\mathbf{x}),\qquad r_i = R_k(\mathbf{y}_i,\mathbf{x}) $$
$$ A_i = \frac{r_i - \mu_r}{\sigma_r + \epsilon_{\mathrm{adv}}},\qquad \mu_r = \frac{1}{G} \sum_{j=1}^{G} r_j $$
The token-level likelihood ratio is computed against the sampled policy and clipped in PPO style:
$$ \rho_{i,t} = \exp(\ell_{\theta,i,t} - \ell_{\mathrm{old},i,t}),\qquad \bar\rho_{i,t} = \operatorname{clip}(\rho_{i,t},1-\varepsilon,1+\varepsilon) $$
The paper optimizes the following GRPO loss for each adapter:
$$ \mathcal{L}_{\mathrm{GRPO}} = \frac{1}{G}\sum_{i=1}^{G}\frac{1}{T_i}\sum_{t=1}^{T_i} \left[-\min(\rho_{i,t}A_i,\bar\rho_{i,t}A_i) + \beta\left(e^{\Delta_{i,t}} - \Delta_{i,t} - 1\right)\right] $$
with $\Delta_{i,t} = \ell_{0,i,t} - \ell_{\theta,i,t}$, where $\ell_{0,i,t}$ is the frozen reference policy obtained by disabling LoRA layers in the same model. The first term is the clipped policy-gradient objective and the second term penalizes token-level drift from the backbone. Only LoRA parameters receive gradients.
A key design choice is that rewards are computed after waveform generation, which makes the method applicable to non-differentiable signals such as ASR-based WER, generated token length, and estimated $F_0$.
Reward design
Each adapter is trained with a reward that mixes intelligibility and style:
$$ R_k(\mathbf{y},\mathbf{x}) = \eta R_{\mathrm{WER}}(\mathbf{y},\mathbf{x}) + (1-\eta)R_k^{\mathrm{style}}(\mathbf{y}) $$
The intelligibility anchor is $R_{\mathrm{WER}} = 1 - \tanh(\gamma\,\mathrm{WER}(\mathbf{x},\mathbf{y}))$, where WER is computed from Whisper transcripts. For style, GLASS uses min-max normalization within the sampled GRPO group:
$$ m(z_i)= \begin{cases} \dfrac{z_i-z_{\min}}{z_{\max}-z_{\min}}, & z_{\max}>z_{\min},\\ 0.5, & \text{otherwise}. \end{cases} $$
For speaking rate, the target statistic $z_i$ is generated speech-token length. The fast adapter receives $1-m(z_i)$, while the slow adapter receives $m(z_i)$. For pitch, $z_i$ is utterance-level mean $F_0$; the high-pitch adapter uses $m(z_i)$ and the low-pitch adapter uses $1-m(z_i)$.
LoRA arithmetic for modular control
Because each control axis is stored as a low-rank weight update $\Delta W_k$, GLASS can compose controls directly in weight space:
$$ \Delta W(\mathbf{w}) = \sum_k w_k\,\Delta W_k $$
This lets the same adapter library support three distinct usage modes:
- Swapping: choose one adapter for one style direction.
- Interpolation: blend opposite adapters, e.g. $\Delta W(\alpha)=\alpha\Delta W_{\mathrm{fast}} + (1-\alpha)\Delta W_{\mathrm{slow}}$.
- Multi-axis composition: combine separate speed and pitch adapters, e.g. $\Delta W = w_1\Delta W_{ \mathrm{fast}} + w_2\Delta W_{\mathrm{high}}$.
The paper uses $w=0.5$ as a stable composition point because full-strength addition can overshoot, especially on pitch.
Experimental setup
GLASS is trained on LibriTTS-R using multi-speaker prompts. For each style adapter, the authors sample prompts from 50 randomly selected speakers in the LibriTTS-R train-clean-100 subset, with 25 male and 25 female speakers and at least 20 utterances per speaker. Target texts are drawn from a 3,000-sentence pool from the same corpus. For each batch item, a fresh speaker is sampled uniformly and then kept fixed across all $G=8$ generations in the GRPO group, so that within-group reward normalization compares samples under the same text and speaker condition.
Optimization uses AdamW for 500--750 update steps per adapter, with batch size 4, group size $G=8$, two PPO epochs, $\varepsilon=0.2$, $\beta=0.01$, $\eta=0.5$, and $\gamma=1$. Whisper-large-v3 provides transcripts for the WER reward, token length is computed from generated speech tokens, and pitch rewards use voiced-frame $F_0$ estimated with pyworld.
Evaluation is performed on Seed-TTS-eval test_en, which contains 1,088 prompt-text pairs from Common Voice and is out of domain relative to the LibriTTS-R training data. This tests whether the learned adapters act as speaker-agnostic style directions that transfer to unseen prompts. The paper reports syllables per second (SPS), mean voiced-frame $F_0$, WER, speaker similarity (SpkSim), UTMOSv2, S-MOS, and N-MOS. SpkSim is computed as cosine similarity between prompt and generated speech embeddings from a WavLM-large speaker-verification model, following the Seed-TTS protocol. For MOS, 15 human raters scored 25 utterances per transformed system on 1--5 S-MOS and N-MOS scales, with five ratings per utterance.
The baselines are the unmodified CosyVoice2-0.5B model and DSP-based transformations of its outputs: time-stretching for speed and pitch shifting for pitch. For the DSP baselines, the authors use librosa time-stretching with rates 1.5 and 0.6 and pitch shifts of $\pm 4$ semitones.
Results
Individual style control on unseen speakers
On Seed-TTS-eval test_en, the LoRA adapters achieve style shifts comparable to the DSP baselines while preserving much better perceptual quality. The paper emphasizes that speed and pitch directions remain largely separable: off-axis statistics stay near the baseline, and WER remains close to the original model. By contrast, DSP manipulation strongly damages UTMOS and speaker similarity, especially for pitch shifting.
| Method | SPS | $F_0$ M | $F_0$ F | WER $\downarrow$ | SpkSim $\uparrow$ | UTMOS $\uparrow$ | S-MOS $\uparrow$ | N-MOS $\uparrow$ |
|---|---|---|---|---|---|---|---|---|
| Baseline (CosyVoice2-0.5B) | 3.65 | 120.4 | 192.2 | 2.81 | 0.655 | 3.28 | -- | -- |
| DSP speed-up | 5.48 | 121.2 | 195.7 | 3.50 | 0.475 | 1.56 | 3.08 | 2.76 |
| Fast LoRA (ours) | 5.59 | 120.4 | 191.0 | 3.49 | 0.617 | 3.30 | 4.72 | 4.68 |
| DSP slow-down | 2.19 | 121.7 | 193.7 | 2.67 | 0.500 | 1.45 | 2.76 | 2.28 |
| Slow LoRA (ours) | 2.30 | 122.1 | 194.3 | 3.18 | 0.650 | 3.05 | 4.56 | 4.24 |
| DSP pitch-up | 3.65 | 150.9 | 239.9 | 2.59 | 0.173 | 1.57 | 1.40 | 2.28 |
| High-pitch LoRA (ours) | 3.61 | 156.1 | 241.0 | 3.01 | 0.609 | 3.37 | 4.12 | 4.40 |
| DSP pitch-down | 3.65 | 98.0 | 155.4 | 3.28 | 0.158 | 1.49 | 1.40 | 2.00 |
| Low-pitch LoRA (ours) | 3.68 | 108.9 | 164.6 | 3.11 | 0.632 | 3.16 | 4.60 | 4.84 |
The paper’s main qualitative finding is that the reward-trained adapters move the intended statistic while keeping the rest of the system stable. For speed control, Fast LoRA reaches 5.59 SPS and Slow LoRA 2.30 SPS, both close to the DSP targets, but with much higher UTMOS and SpkSim. For pitch, High-pitch LoRA raises mean $F_0$ to 156.1 Hz for male and 241.0 Hz for female prompts, while Low-pitch LoRA lowers them to 108.9 Hz and 164.6 Hz. Across all adapters, WER stays within 0.7 percentage points of the baseline.
Human and automatic quality metrics strongly separate GLASS from DSP. DSP baselines collapse UTMOS to 1.45--1.57 and, for pitch shifting, drive speaker similarity below 0.18. In contrast, LoRA-based controls remain near the baseline on UTMOS and only modestly reduce SpkSim. The human S-MOS and N-MOS scores also favor LoRA substantially, with values in the 4.12--4.72 and 4.24--4.84 ranges, versus 1.40--3.08 and 2.00--2.76 for DSP.
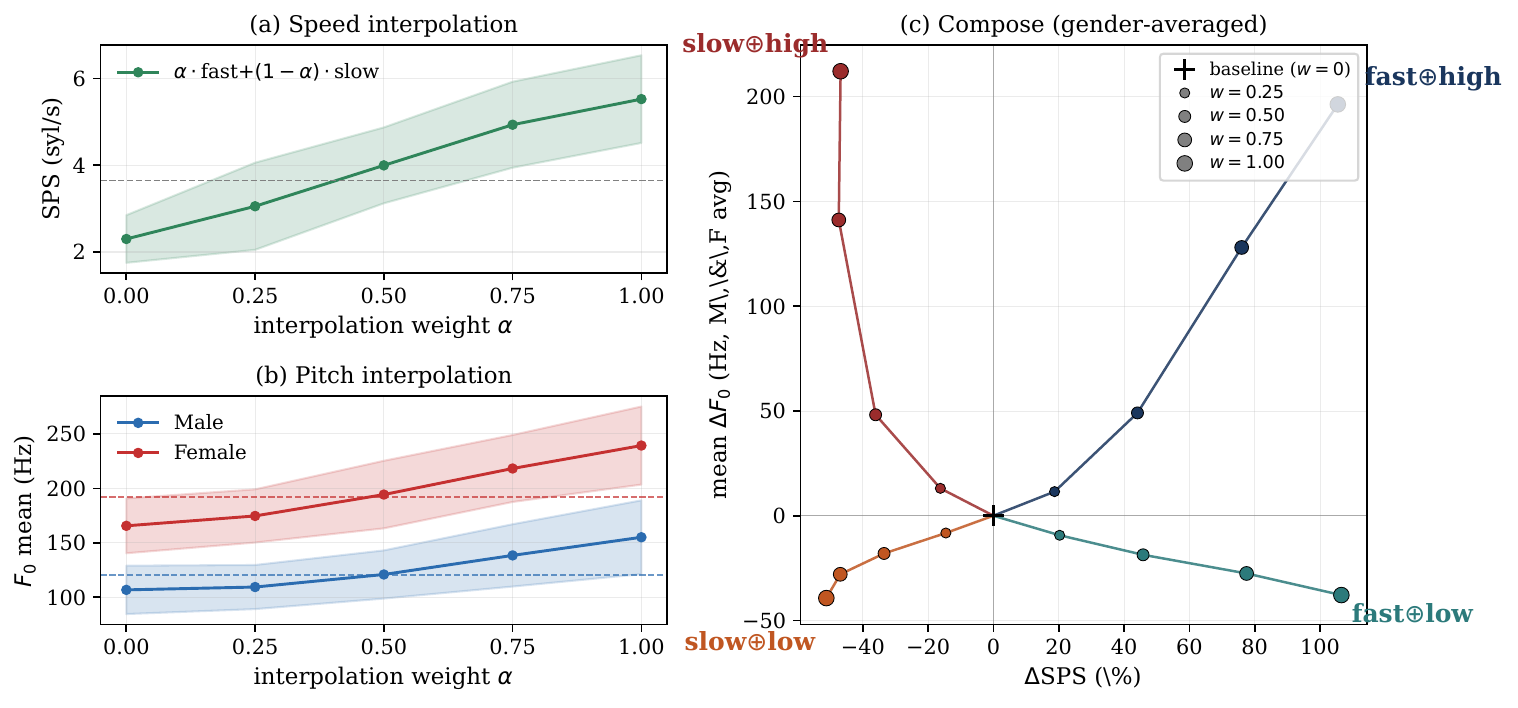
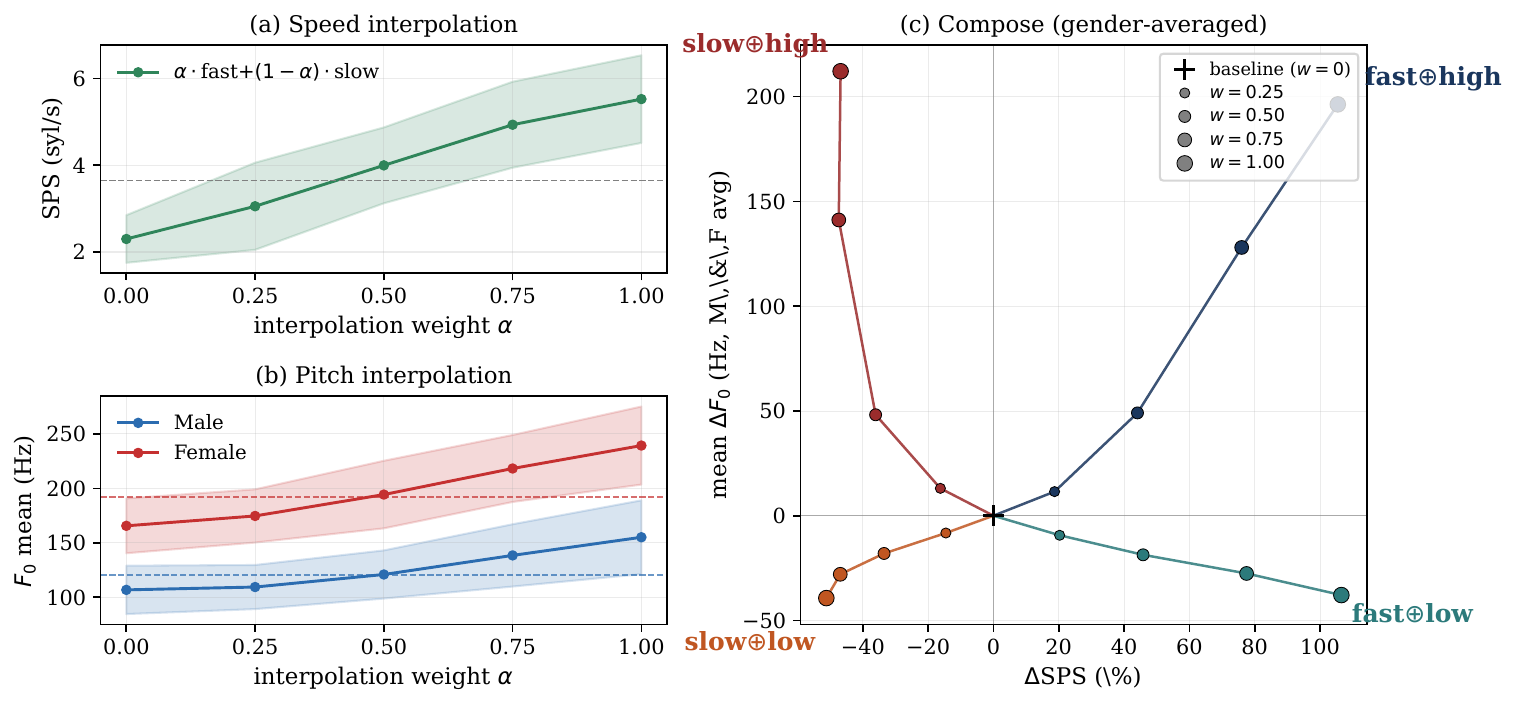
Continuous interpolation between opposite adapters
The paper then tests whether opposite adapters form a smooth control continuum rather than two unrelated endpoints. It linearly blends fast with slow and high-pitch with low-pitch on a gender-balanced 200-utterance subset, using $\alpha \in \{0, 0.25, 0.5, 0.75, 1.0\}$. The target style metric changes smoothly with $\alpha$, while off-axis metrics remain close to baseline. Importantly, WER follows a U-shaped curve and is lowest at the center blend $\alpha=0.5$ for both axes, which the authors interpret as a stable interpolation regime rather than a degenerate average.
| Speed axis: $\alpha \cdot$ fast $+ (1-\alpha) \cdot$ slow | Pitch axis: $\alpha \cdot$ high $+ (1-\alpha) \cdot$ low | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| $\alpha$ | SPS | WER% $\downarrow$ | SpkSim $\uparrow$ | UTMOS $\uparrow$ | $F_0$ (M/F) | $\alpha$ | SPS | WER% $\downarrow$ | SpkSim $\uparrow$ | UTMOS $\uparrow$ | $F_0$ (M/F) |
| 0.00 | 2.30 | 4.50 | 0.647 | 3.00 | 123/196 | 0.00 | 3.72 | 3.36 | 0.629 | 3.16 | 107/166 |
| 0.25 | 3.05 | 4.25 | 0.649 | 3.18 | 121/193 | 0.25 | 3.71 | 2.60 | 0.644 | 3.19 | 109/175 |
| 0.50 | 4.00 | 2.16 | 0.645 | 3.29 | 121/194 | 0.50 | 3.64 | 2.14 | 0.644 | 3.28 | 121/194 |
| 0.75 | 4.93 | 2.91 | 0.624 | 3.32 | 121/193 | 0.75 | 3.64 | 3.02 | 0.634 | 3.34 | 138/218 |
| 1.00 | 5.52 | 3.51 | 0.614 | 3.31 | 119/192 | 1.00 | 3.62 | 2.96 | 0.614 | 3.35 | 155/239 |
The interpolation curves are supported by the authors’ monotonicity analysis over individual utterances: the average Spearman correlation between $\alpha$ and the target statistic is $0.954 \pm 0.088$ for speed, $0.874 \pm 0.154$ for male pitch, and $0.923 \pm 0.099$ for female pitch. This is important because it shows the smooth trend is not merely an artifact of averaging.
Multi-axis composition and overshoot behavior
GLASS also composes one speed adapter with one pitch adapter across four combinations: fast$\oplus$high, fast$\oplus$low, slow$\oplus$high, and slow$\oplus$low. At the default composition weight $w_A=w_B=0.5$, all four combinations move toward the intended speed-pitch quadrant, and each axis retains roughly $80\%$ to $121\%$ of its single-axis effect. The paper interprets this as evidence that the learned style directions are largely separable in token-policy space.
| Combination | ret$_{\text{SPS}}$ | ret$_{F_0,\text{M}}$ | ret$_{F_0,\text{F}}$ |
|---|---|---|---|
| fast$\oplus$high | 83% | 121% | 114% |
| fast$\oplus$low | 86% | 90% | 91% |
| slow$\oplus$high | 98% | 109% | 117% |
| slow$\oplus$low | 91% | 80% | 82% |
The authors also evaluate the more aggressive setting $w_A=w_B=1.0$ and show why $w=0.5$ is the safer default. Full-strength composition can overshoot the pitch axis into unrealistic registers or suppress voicing. For example, fast$\oplus$high reaches male $F_0$ of 318.9 Hz and female $F_0$ of 385.5 Hz, while combinations involving low-pitch adapters can reduce voicing ratio to 0.32--0.37, indicating creaky or aperiodic phonation.
| Combination | SPS | $F_0$(M) | $F_0$(F) | voicing |
|---|---|---|---|---|
| fast$\oplus$high | 7.50 | 318.9 | 385.5 | 0.64 |
| fast$\oplus$low | 7.54 | 106.2 | 147.0 | 0.37 |
| slow$\oplus$high | 1.94 | 326.3 | 392.0 | 0.58 |
| slow$\oplus$low | 1.78 | 106.8 | 136.1 | 0.32 |
| Baseline | 3.65 | 120.4 | 192.2 | 0.65 |
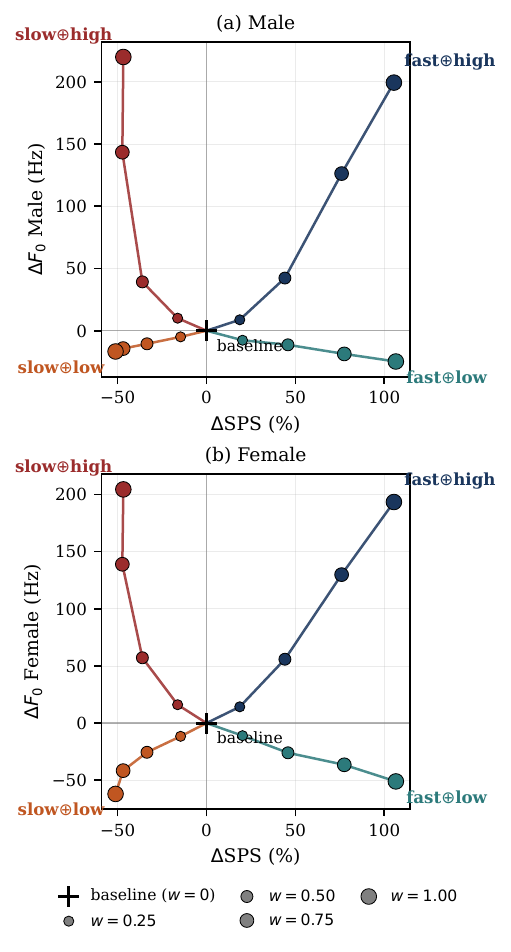
The gender-specific figure reinforces the averaged trend: both male and female subsets move toward the intended quadrants as $w$ increases. Taken together, the interpolation and composition experiments support the paper’s claim that reward-trained LoRA adapters define reusable style directions, not just one-off fine-tuned outputs.
Contributions and takeaways
- GLASS reframes acoustic style control in zero-shot TTS as reward-guided policy optimization over speech tokens.
- It learns style directions without style labels, using post-generation rewards for speaking rate, pitch, and intelligibility.
- It stores each direction as a frozen-backbone LoRA update, enabling modular reuse.
- It demonstrates three inference-time operations: swapping, smooth interpolation, and multi-axis composition.
- It shows that these operations preserve quality substantially better than DSP-based signal transformations.
Limitations
The paper is explicit that the method is limited to two measurable acoustic axes: speaking rate and pitch. These are interpretable and useful, but they do not capture richer prosodic or paralinguistic properties such as emotion, speaking effort, accent, or conversational style. Extending GLASS to those settings would require reliable automatic rewards or human preference feedback.
The evaluation also relies on proxy measures: speech-token length for speaking rate, voiced-frame mean $F_0$ for pitch, Whisper-based WER for intelligibility, and automatic speaker-similarity and naturalness metrics. These proxies make training and evaluation scalable and reproducible, but they do not fully replace human perceptual judgment. The authors therefore frame the current work as a foundation for a larger library of reward-trained style adapters rather than a complete solution to open-ended style control.