Resonant Minds
Resonant Minds: Closed-Loop Social Avatars with Theory of Mind
Resonant Minds is a closed-loop dual-agent avatar system combining perception, Theory of Mind reasoning, and emotion-driven video synthesis for strategic, lifelike conversations. It models social dialogue with information asymmetry, generating speaker and reactive listener behaviors in rich multimodal interaction.
Demos
These demos showcase Resonant Minds generating socially intelligent dual-agent interactions with Theory of Mind. Watch how avatars infer and respect hidden mental states while engaging in natural, goal-driven dialogue. The demos balance dialogue coherence with expressive, emotion-controlled visual and audio synthesis, surpassing baselines on social reasoning and multimodal expression.
Links
Paper & demos
Code & resources
Impact
Abstract
Creating lifelike digital humans with genuine social intelligence requires unifying cognitive reasoning and multimodal generation within a coherent framework. Current approaches treat these as separate tasks: Large Language Models excel at dialogue but lack embodied expression, while diffusion-based talking head models achieve visual fidelity but ignore social cognition. To bridge this gap, we propose a closed-loop dual-agent framework integrating perception, social reasoning, and expression into a continuous interaction cycle. The perception module analyzes partners' multimodal behaviors from video, while the social reasoning module infers hidden mental states through Theory of Mind and selects responses via an ensemble mechanism. The expression module then generates emotion-controllable videos that jointly synthesize speaker speech and facial expressions with listener reactive behaviors, capturing bidirectional dynamics absent in prior work. We further construct a hierarchical Persona-Scenario dataset with psychologically grounded personas and private social goals to support evaluation under information asymmetry. Experiments on this dataset demonstrate competitive or superior performance on both dialogue quality and video generation metrics. Notably, our method surpasses even the full-information Script mode on key dialogue quality dimensions, suggesting that explicit mental state inference under uncertainty can elicit more thoughtful dialogue than unrestricted information access. Project page: https://resonantminds.github.io/.
Overview
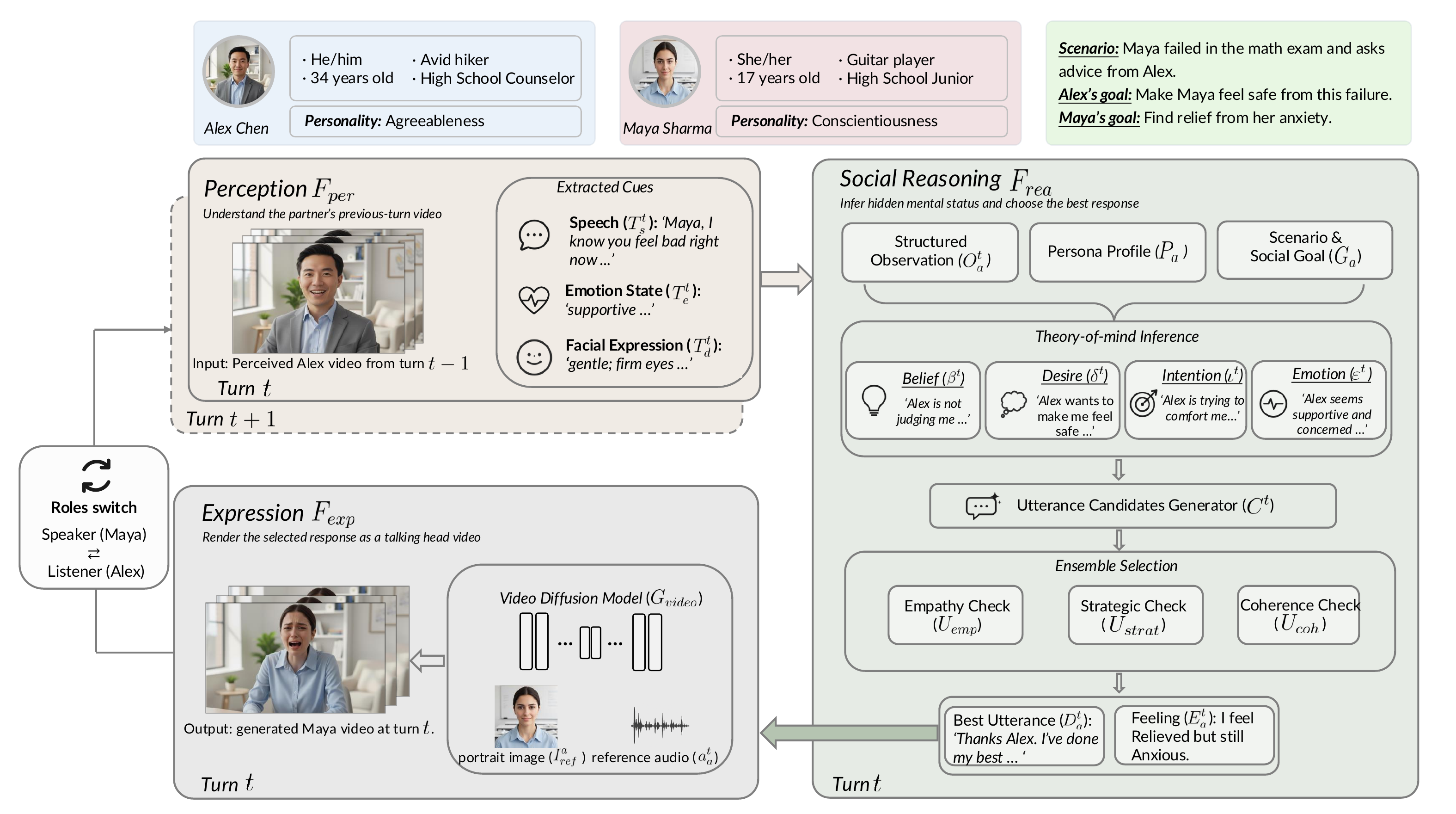
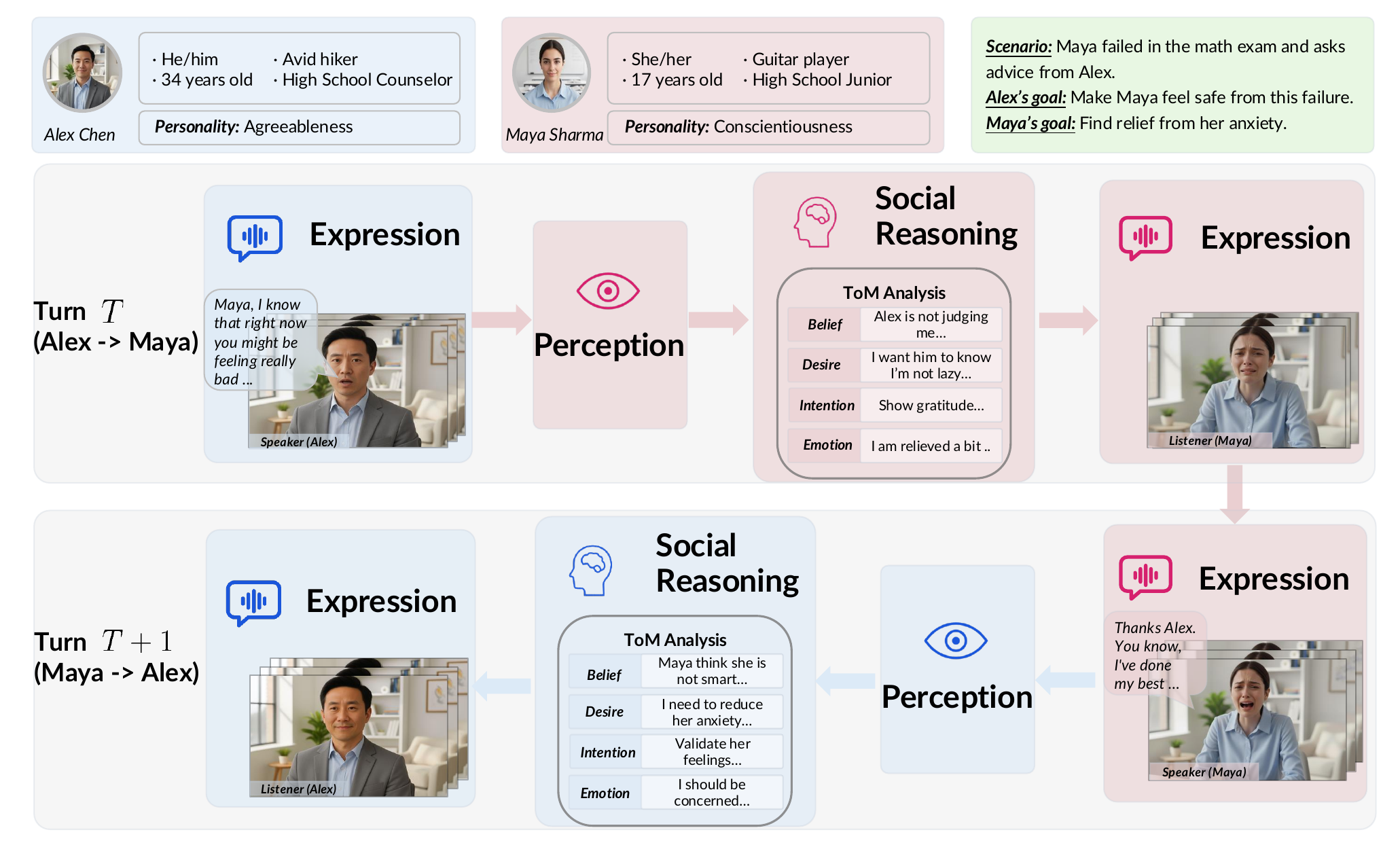
Resonant Minds proposes a closed-loop framework for dual-agent conversational avatars that couples social reasoning with multimodal generation. The paper argues that prior systems are split across two incompatible paradigms: language-only agents can reason about dialogue but lack embodiment, while talking-head generators can render expressive faces but have no explicit social cognition. The key idea is to unify these into a single interaction loop in which each agent (1) perceives the partner’s previous video, (2) infers hidden mental states via Theory of Mind (ToM), (3) selects a response through an ensemble over empathy, strategy, and coherence, and (4) renders both speech and facial behavior into a new video that becomes the other agent’s next observation.
The paper frames social interaction as a partially observable Markov game with two agents, each owning a persistent persona profile $P_i=(\mathcal{B}_i,\Psi_i,\mathcal{G}_i)$, where $\mathcal{B}_i$ is biographical background, $\Psi_i$ is a Big Five-grounded personality narrative, and $\mathcal{G}_i$ is a private social goal hidden from the partner. The contribution is not just a conversational policy, but a multimodal closed loop that attempts to preserve the realistic asymmetry of human interaction while still generating emotionally expressive conversational video.
Problem Formulation and Core Design
The method models a dyadic interaction as a partially observable Markov game $\langle \mathcal{S},\mathcal{A},\mathcal{O},\mathcal{T} \rangle$, with joint action space $\mathcal{A}=\mathcal{A}_a\times\mathcal{A}_b$ and observation space $\mathcal{O}=\mathcal{O}_a\times\mathcal{O}_b$. At each turn, agent $i$ receives an observation $o_i^t$ derived from the partner’s prior video, then selects an action $A_i^t=(D_i^t,E_i^t)$ consisting of a textual utterance and an emotion descriptor. This symbolic action is turned into speech and video. The generated video is then fed back as the partner’s next observation, creating the paper’s “closed-loop” behavior.
The authors emphasize three design principles:
- Perception: infer speech, affect, and facial expression from the partner’s video rather than relying only on dialogue text.
- ToM-based social reasoning: infer hidden belief, desire, intention, and emotion from observable cues.
- Expression: synthesize both the speaker and a reactive listener so the video reflects bidirectional conversational dynamics.
Method
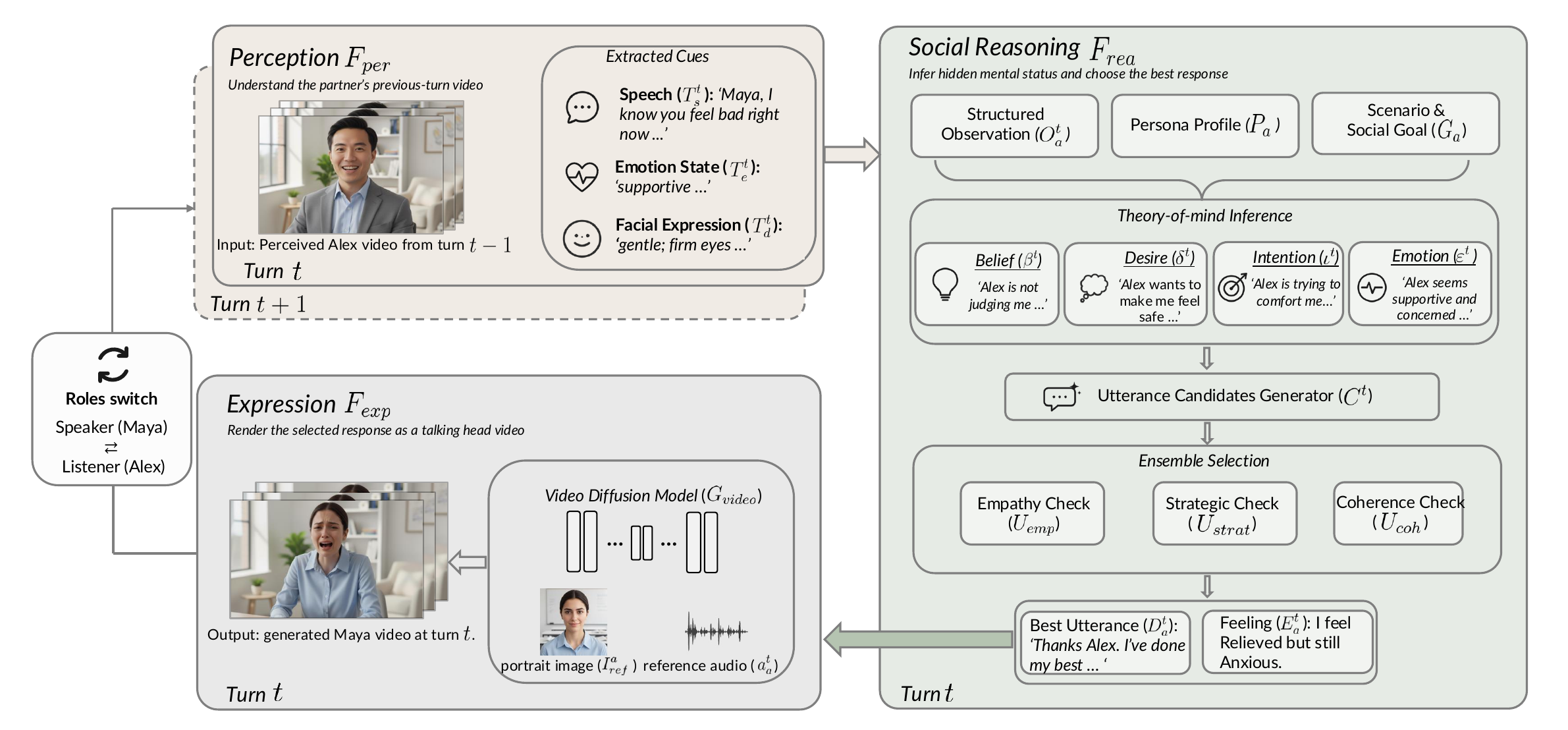
1. Multimodal Perception
The perception module uses HumanOmni-7B to analyze the partner’s previous turn video $V^{t-1}$, composed of frames and audio, and extract structured observations:
$$o_i^t = (T_s^t, T_e^t, T_d^t),$$
where $T_s^t$ is the transcribed speech, $T_e^t$ is the inferred emotion, and $T_d^t$ is the facial-expression description. The paper uses first-person prompting to preserve the information asymmetry of agent mode. In implementation, video is sampled at 1 FPS and the perception model is run deterministically with a 512-token generation budget.
2. Social Reasoning with Theory of Mind
The social reasoning module is the cognitive core. It takes the current observation, dialogue history, and the agent’s persona profile and returns an updated history plus the selected action:
$$\mathcal{H}_i^t, A_i^t = \mathcal{F}_{\text{rea}}(o_i^t, \mathcal{H}_i^{t-1}, P_i).$$
The paper implements this module with GPT-4o and structured prompting. It has three stages:
- ToM analysis: infer the partner’s hidden mental state using the BDIE schema.
- Candidate generation: generate multiple diverse response candidates.
- Ensemble selection: score candidates by empathy, strategy, and coherence, then choose the weighted best one.
The ToM component estimates
$$\hat{M}_j^t = (\beta^t,\delta^t,\iota^t,\epsilon^t),$$
where the four components correspond to belief, desire, intention, and emotion. These are represented in free-form text rather than as a fixed symbolic ontology.
Candidate generation produces $K=3$ options:
$$\mathcal{C}^t = \{A_{i,1}^t,\ldots,A_{i,K}^t\}.$$
Each candidate is scored by three GPT-4o judges:
- Empathy evaluator: does the response appropriately acknowledge the partner’s emotional state?
- Strategy evaluator: does the response advance the agent’s private goal?
- Coherence evaluator: does the response stay consistent with persona and dialogue history?
Scores are normalized and combined with equal weights by default:
$$A_i^t = \operatorname*{arg\,max}_{A_{i,k}^t \in \mathcal{C}^t} \sum_j \lambda_j U_j(A_{i,k}^t),$$
with $\lambda_{\text{emp}} = \lambda_{\text{strat}} = \lambda_{\text{coh}} = 1/3$.
3. Expression: Emotion-Controlled Dual-Agent Video Synthesis
The expression module converts the selected action into a multimodal output video:
$$V_i^t = \mathcal{F}_{\text{exp}}(A_i^t, P_i, I_{\text{ref}}^i).$$
This module is important because the paper does not merely generate a speaker turn; it also generates a reactive listener. The listener is conditioned on the perceived speaker action and the listener’s own personality, enabling bidirectional nonverbal feedback.
There are three subcomponents:
- Text-to-Emotion adapter: maps free-form emotion text to an 8-dimensional weight vector over basic emotion categories.
- Index-TTS v2: produces emotionally controlled speech from the utterance and emotion descriptor.
- DICE-Talk: renders the speaker and listener videos; the two streams are composed horizontally into a $1024\times512$ frame and temporally smoothed using RIFE interpolation from 12.5 FPS to 25 FPS.
The paper’s adapter uses a frozen CLIP text encoder followed by a trainable MLP that outputs a normalized 8-way distribution over contempt, sadness, happiness, surprise, anger, disgust, fear, and neutral. The adapter is trained on roughly 360 synthetic text-weight pairs with KL divergence, AdamW, 30 epochs, batch size 16, and cosine learning-rate decay from $10^{-3}$ to $10^{-6}$. Only the MLP is trained; CLIP remains frozen.
The video generator is DICE-Talk fine-tuned on SVD-xt with FP16 precision, 25 inference steps, a reference guidance scale of 3.0, and emotion guidance scale of 6.0. The authors stress that DICE-Talk natively accepts only discrete emotion priors, so the adapter is what enables free-form textual emotion control in their system.
Dataset: Persona-Scenario
To evaluate under information asymmetry, the authors construct a hierarchical Persona-Scenario dataset. It contains 50 personas, 90 scenarios, and 365 face-voice avatar pairs. Personas are built through a sparse-to-rich pipeline and stored as JSON with three layers: facts, personality, and private goals.
Facts layer. Each persona starts from a manually authored seed of 3–5 attributes such as age, gender, occupation, and location. GPT-4o expands this into richer biography details, and a T5-based NLI model checks consistency to remove contradictions.
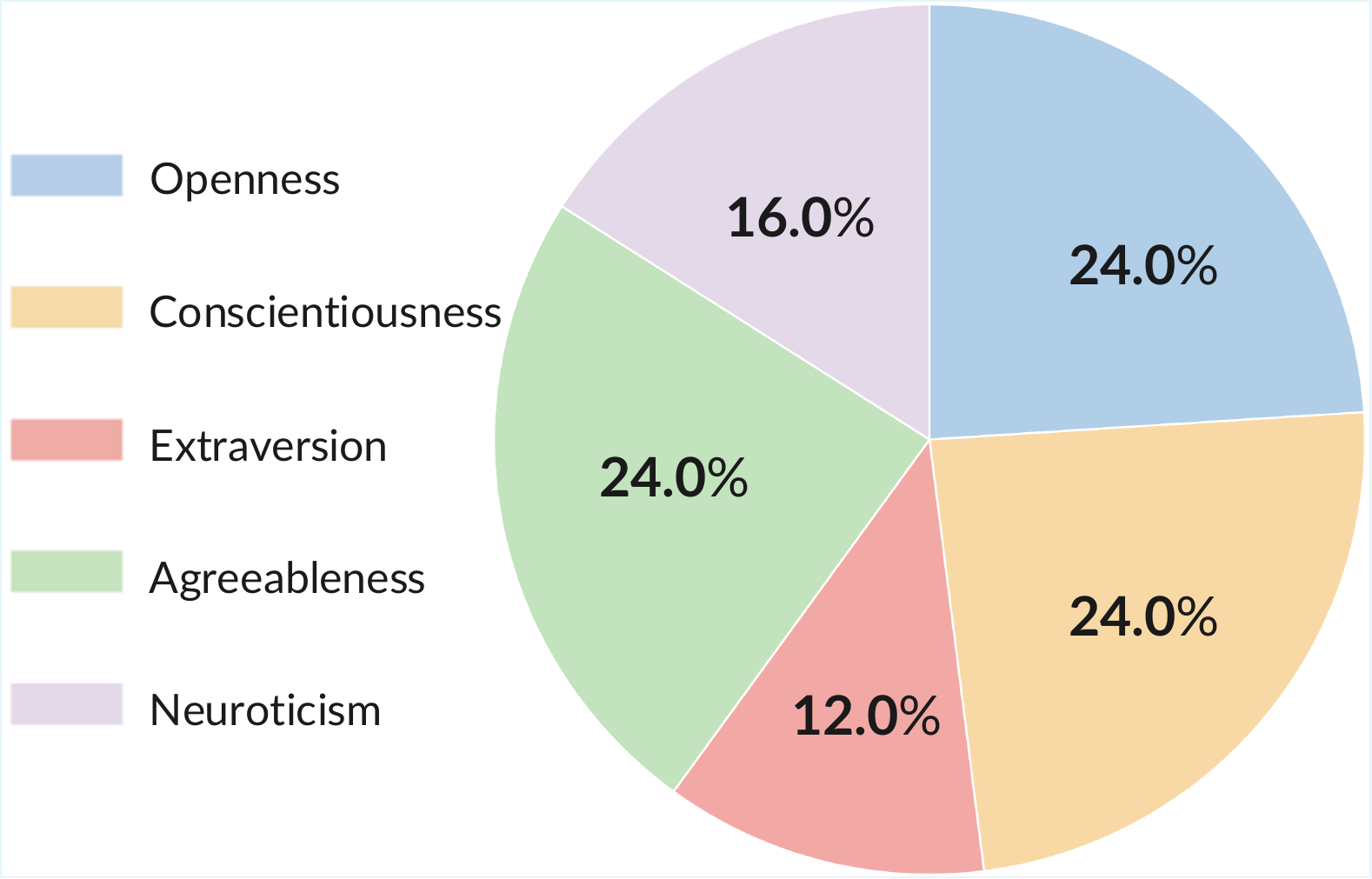
Psychological layer. Personality narratives are generated from the Big Five framework using a personality-prompting method. The authors report that they pre-assign target trait levels so the overall distribution is approximately uniform across the 50 personas, reducing trait bias.
Private goals. Goals are generated at test time from the persona and the selected scenario. Crucially, each agent’s goal is independent and hidden from the other agent, so the interaction preserves information asymmetry.
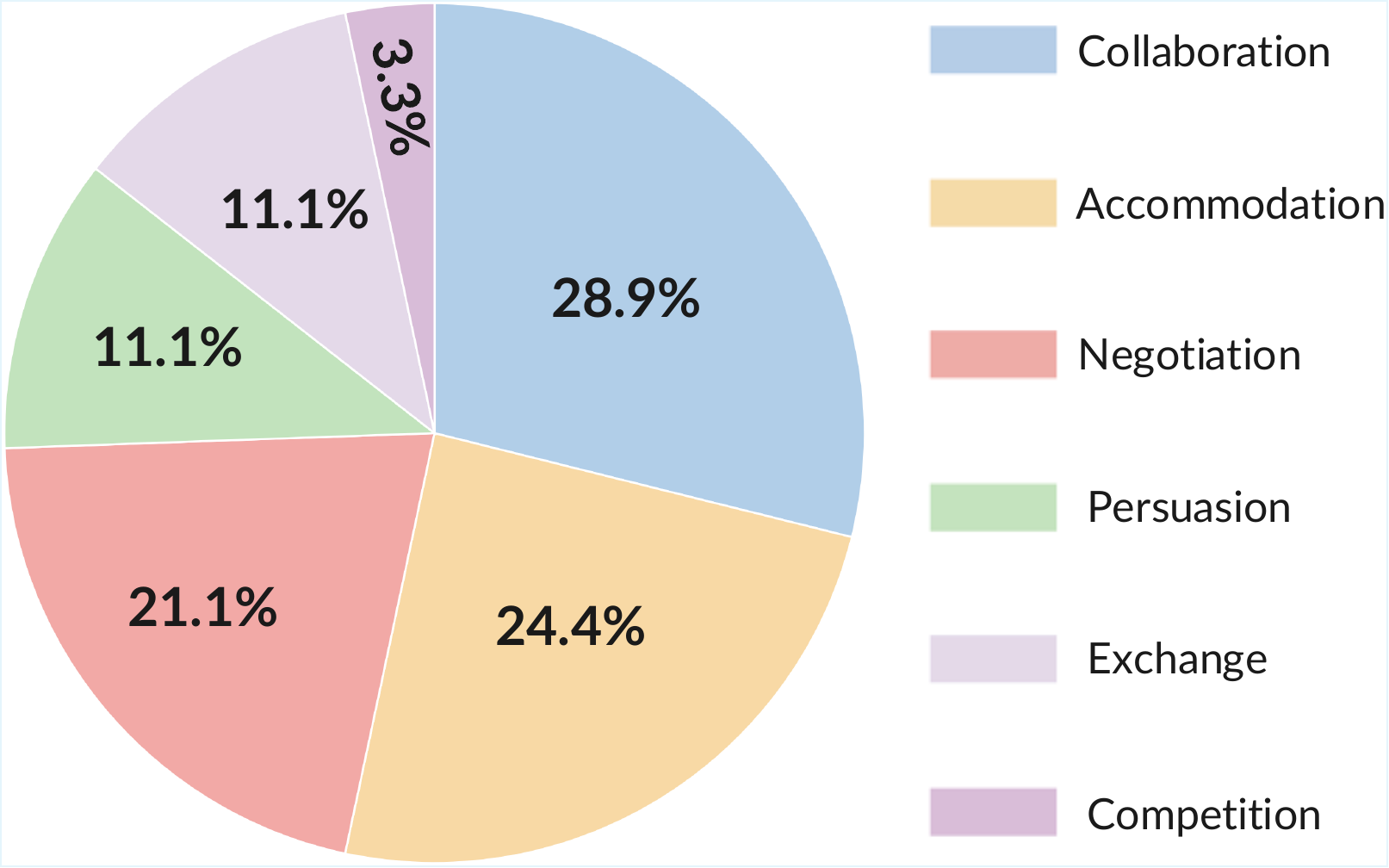
Scenarios. The authors adapt 90 two-party scenarios from Sotopia, selecting cases that cover six interaction types: negotiation, exchange, competition, collaboration, accommodation, and persuasion. Scenario-persona pairing is done by GPT-4o-based semantic matching so the persona background plausibly fits the scenario.
Avatar resources. The 365 face-voice pairs come from VICO and VICOX, with 230 male and 135 female pairs. Each includes a $512\times512$ portrait and a 3–5 second reference audio clip.
Test protocol. For reproducibility, the paper uses 10 fixed test cases with seed 2132. Each test case samples two personas, a scenario, gender-aligned face-voice pairs, and scenario-specific private goals.
Experimental Setup
The system stack used for experiments is:
- Dialogue generation: GPT-4o.
- Perception: HumanOmni-7B.
- Speech synthesis: Index-TTS v2 with emotion control, plus ElevenLabs for listener backchannel generation.
- Video synthesis: DICE-Talk with emotion control.
- Composition: side-by-side rendering and RIFE interpolation for temporal smoothing.
All experiments were run on servers with 8 NVIDIA V100 GPUs using PyTorch 2.6.0 and CUDA 12.2.
Baselines
The paper compares against different baselines for dialogue and video generation.
Dialogue baselines: Agent mode, which only sees its own persona and goals and has no ToM or perception; and Script mode, which receives both agents’ full profiles and private goals, serving as an unrealistic full-information reference.
Video baselines: SadTalker, Hallo3, EDTalk, Sonic, and DICE-Talk. For fair comparison, all methods use Index-TTS v2 for audio synthesis and are evaluated on the same test cases.
| Property | Agent | Script | Ours |
|---|---|---|---|
| LLM backbone | GPT-4o | GPT-4o | GPT-4o |
| Info access | Own only | Both agents | Own only |
| Multimodal perception | No | No | Yes |
| ToM analysis | No | No | Yes |
| Candidate generation | No | No | Yes ($K=3$) |
| Ensemble mechanism | No | No | Yes |
| Prompt layers | 2 | 2 | 3 |
Metrics
Dialogue quality is measured using four LLM-based evaluation frameworks: Sotopia-Eval, LLM-Eval, GPT-Score, and G-Eval. These collectively assess goal completion, linguistic quality, persona consistency, and naturalness. Audio quality is evaluated with Open-D and Emo-Acc from URO-Bench. Visual quality uses LipLMD, AVOffset, and AVConf from the ViCo protocol, and emotional expressiveness is measured with Emo Score from an external emotion recognizer.
Results: Dialogue Quality
The key result is that the proposed system outperforms the realistic Agent baseline on nearly all dialogue metrics, and in some cases even exceeds the full-information Script reference. The strongest pattern is improved social intelligence under uncertainty: the model is better at preserving secrets, staying coherent with persona, and producing responses judged as more appropriate and likeable.
| Dimension | Evaluator | Criterion | Script† Mean | Agent Mean | Ours Mean |
|---|---|---|---|---|---|
| Goal Completion | Sotopia-Eval | Believability | 8.95 | 8.17 | 9.19 |
| Goal | 8.87 | 6.54 | 7.92 | ||
| Secret | -2.33 | -1.77 | -1.01 | ||
| Social rules | -0.09 | -0.07 | -0.04 | ||
| Naturalness | LLM-Eval | Content | 89.49 | 82.98 | 88.23 |
| Grammar | 97.65 | 98.11 | 97.13 | ||
| Relevance | 94.72 | 89.11 | 94.25 | ||
| Appropriateness | 93.26 | 88.29 | 94.98 | ||
| Naturalness | GPT-Score | Fluency | 98.55 | 87.26 | 96.71 |
| Consistency | 96.91 | 85.23 | 97.51 | ||
| Coherence | 98.29 | 97.49 | 98.53 | ||
| Depth | 55.85 | 51.40 | 57.30 | ||
| Diversity | 93.88 | 73.20 | 96.33 | ||
| Likeability | 91.02 | 66.93 | 90.72 | ||
| Naturalness | G-Eval | Relevance | 3.98 | 3.52 | 3.95 |
| Fluency | 2.52 | 2.38 | 2.48 | ||
| Coherent | 4.89 | 4.79 | 4.85 |
† Script is a full-information reference and is not counted in the bold ranking in the paper.
The paper’s qualitative interpretation is important: Script mode can achieve high goal completion but tends to leak private information because omniscient access encourages over-disclosure. Agent mode respects information asymmetry but often generates repetitive, verbose, and non-convergent turns. The proposed method sits in between: it preserves secrecy better than Script mode and resolves conversations more effectively than Agent mode by using ToM to infer partner boundaries without seeing their private goals.
| Method | Bel. | Goal | Secret | Depth | Flu. | Pref. |
|---|---|---|---|---|---|---|
| Script | 3.70 | 3.82 | 3.49 | 3.54 | 3.95 | 40.5% |
| Agent | 3.33 | 3.76 | 3.41 | 3.75 | 3.54 | 23.5% |
| Ours | 3.50 | 3.88 | 3.84 | 3.67 | 3.88 | 36.0% |
Human dialogue evaluation used 22 raters across bargaining, movie selection, and dormitory-conflict scenarios. The proposed method outperformed the Agent baseline on four of the five numeric scales and on overall preference.
Results: Audio and Video Quality
On the audiovisual side, the method is designed to improve not only lip synchronization but also expressive social realism. The authors explicitly state that their approach trades some rigid geometric fidelity for richer emotion dynamics, especially because the dual-agent output includes both speaker and listener reactions.
| Method | Open-D | Emo-Acc | LipLMD | AVOffset | AVConf | Emo Score |
|---|---|---|---|---|---|---|
| SadTalker | 48.50 | 58.00 | 26.50 | -37.18 | 2.45 | 0.28 |
| Hallo3 | 55.00 | 65.00 | 32.00 | -31.44 | 2.76 | 0.30 |
| EDTalk | 57.83 | 75.11 | 21.91 | -31.54 | 2.49 | - |
| Sonic | 53.08 | 65.56 | 28.01 | -33.94 | 2.66 | - |
| DICE-Talk | 54.11 | 57.25 | 28.47 | -44.47 | 2.85 | 0.3057 |
| Ours (w/o listener) | 57.50 | 90.28 | 33.72 | -38.67 | 2.64 | 0.3333 |
| Ours | 61.00 | 91.92 | 22.39 | -33.96 | 2.50 | 0.3604 |
The main video-generation findings are:
- The full model obtains the best Open-D and Emo-Acc, suggesting that the dual-TTS and emotion-control pipeline produces both natural speech and emotionally faithful output.
- The model also achieves the best Emo Score over the full dual-agent video, indicating stronger emotional expressiveness than baselines.
- The ablation Ours (w/o listener) is worse than the full model on the key affective metrics, showing that listener modeling is not just cosmetic; it helps with emotional quality and perceived conversation realism.
- Geometry-based metrics such as LipLMD and AVConf favor some constrained baselines, but the paper argues that those methods achieve the result by limiting motion diversity and expression dynamics.



Ablation Study
The ablation table shows a fairly clean separation of responsibilities between the modules:
- Without the ensemble, Emo Score drops notably while Emo-Acc remains almost unchanged, implying that ensemble selection mainly improves how the video looks at the level of emotional expressiveness rather than basic emotion correctness.
- Without emotion control or without perception, Emo-Acc collapses sharply, confirming that emotion control and perception are critical for getting the right affective signal into the generated speech/video.
- Without ToM, all metrics degrade, which supports the paper’s claim that explicit mental-state inference is central to both dialogue quality and cross-modal coordination.
| Ablation | Emo Score | Emo-Acc | Open-D |
|---|---|---|---|
| w/o ensemble | 0.3005 | 91.36 ± 11.15 | 59.75 ± 3.16 |
| w/o emotion | 0.3506 | 66.39 ± 12.04 | 58.50 ± 3.06 |
| w/o perception | 0.3547 | 68.81 ± 13.11 | 58.08 ± 2.63 |
| w/o ToM | 0.3003 | 65.84 ± 13.71 | 58.25 ± 2.91 |
| Ours | 0.3604 | 91.92 ± 9.93 | 61.00 ± 3.01 |
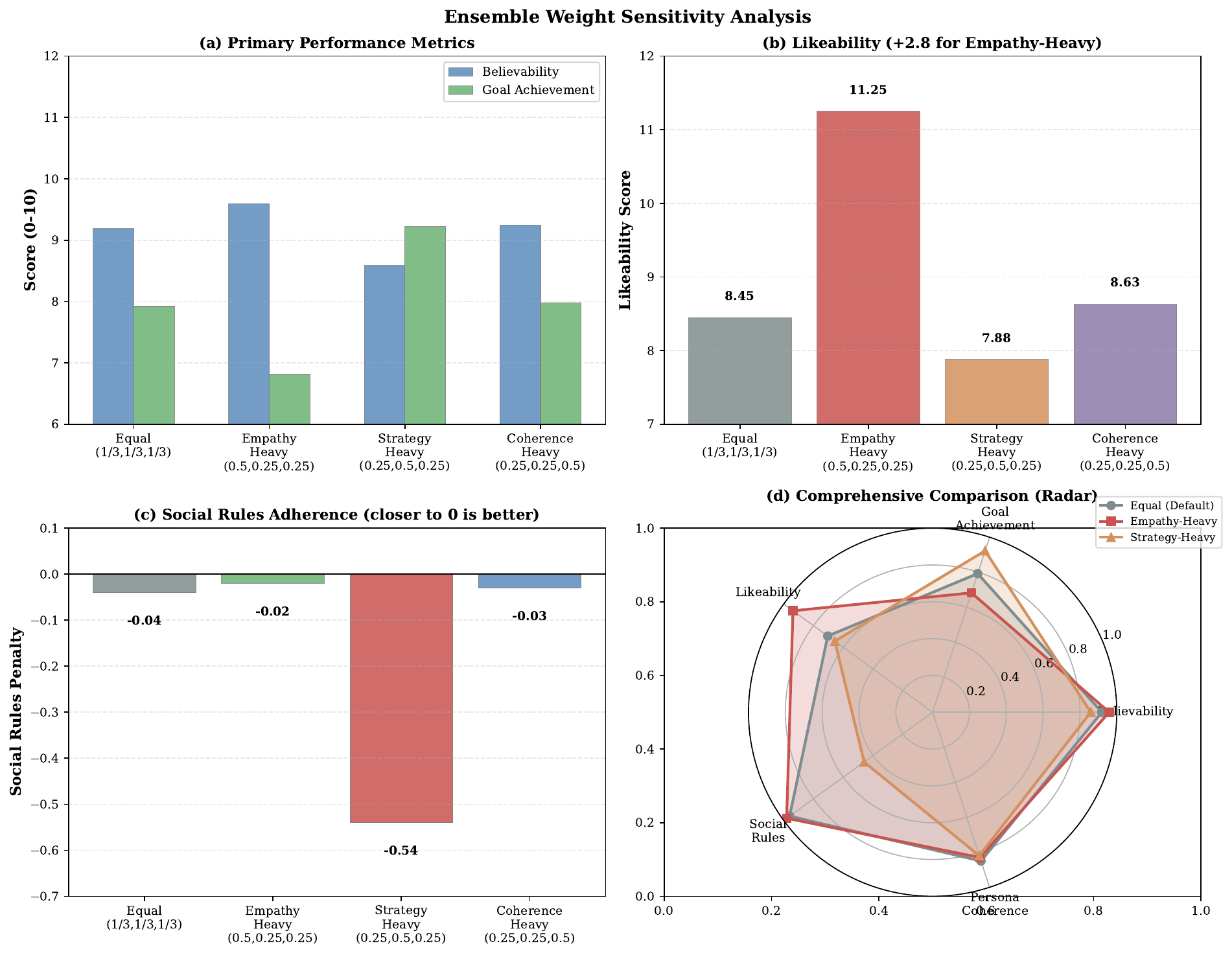
The supplementary sensitivity analysis reports that equal weights balance dialogue quality best. Empathy-heavy settings improve likeability and social-rule adherence but reduce goal achievement; strategy-heavy settings improve goal completion but hurt social naturalness; coherence-heavy settings preserve fluency but provide no advantage over equal weighting. This supports the paper’s choice of $1/3$ for each evaluator.
Generalization and User Studies
The paper checks out-of-distribution transfer on 30 cases sampled from DialToM and Sotopia-Hard. Performance drops only modestly: goal achievement decreases from 8.00 to 7.54, believability from 9.25 to 7.35, coherence from 4.73 to 3.51, and fluency from 2.45 to 2.28, while relevance increases from 3.92 to 4.12. The authors interpret this as evidence that the system’s behavior is driven by ToM reasoning rather than scenario memorization.
| Setting | Goal | Bel. | Secret | Soc. | Coh. | Flu. | Rel. |
|---|---|---|---|---|---|---|---|
| In-dist. | 8.00 | 9.25 | -1.00 | -0.05 | 4.73 | 2.45 | 3.92 |
| OOD | 7.54 | 7.35 | -1.42 | -0.13 | 3.51 | 2.28 | 4.12 |
| Δ | -0.46 | -1.90 | -0.42 | -0.08 | -1.22 | -0.17 | +0.20 |
The user study has two parts:
- Dialogue quality: 22 raters scored dialogues on believability, goal achievement, secret preservation, depth, fluency, and preference. The proposed method outperformed the Agent baseline on four of the five numeric scales and on overall preference.
- Video quality: 85 participants rated 12 videos covering 6 scenario types and 8 emotion categories. The proposed method achieved the highest emotional-expression score, the highest naturalness, and the highest overall quality.
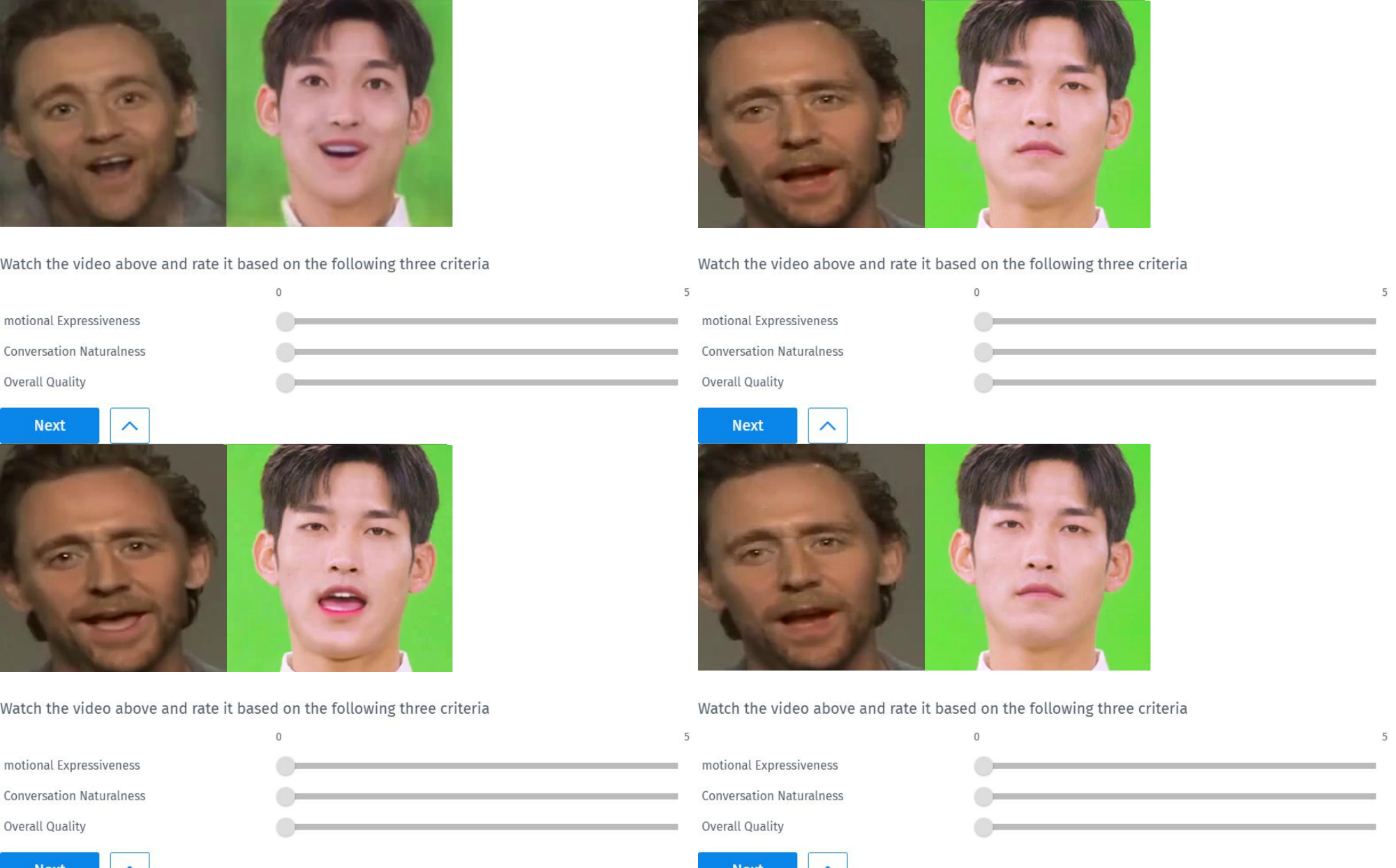
| Method | Emotion Expr. | Naturalness | Overall Quality |
|---|---|---|---|
| EDTalk | 3.38 | 2.13 | 2.08 |
| Sonic | 2.62 | 3.10 | 3.10 |
| DICE-Talk | 3.18 | 4.15 | 3.29 |
| Ours | 4.50 | 4.34 | 3.38 |
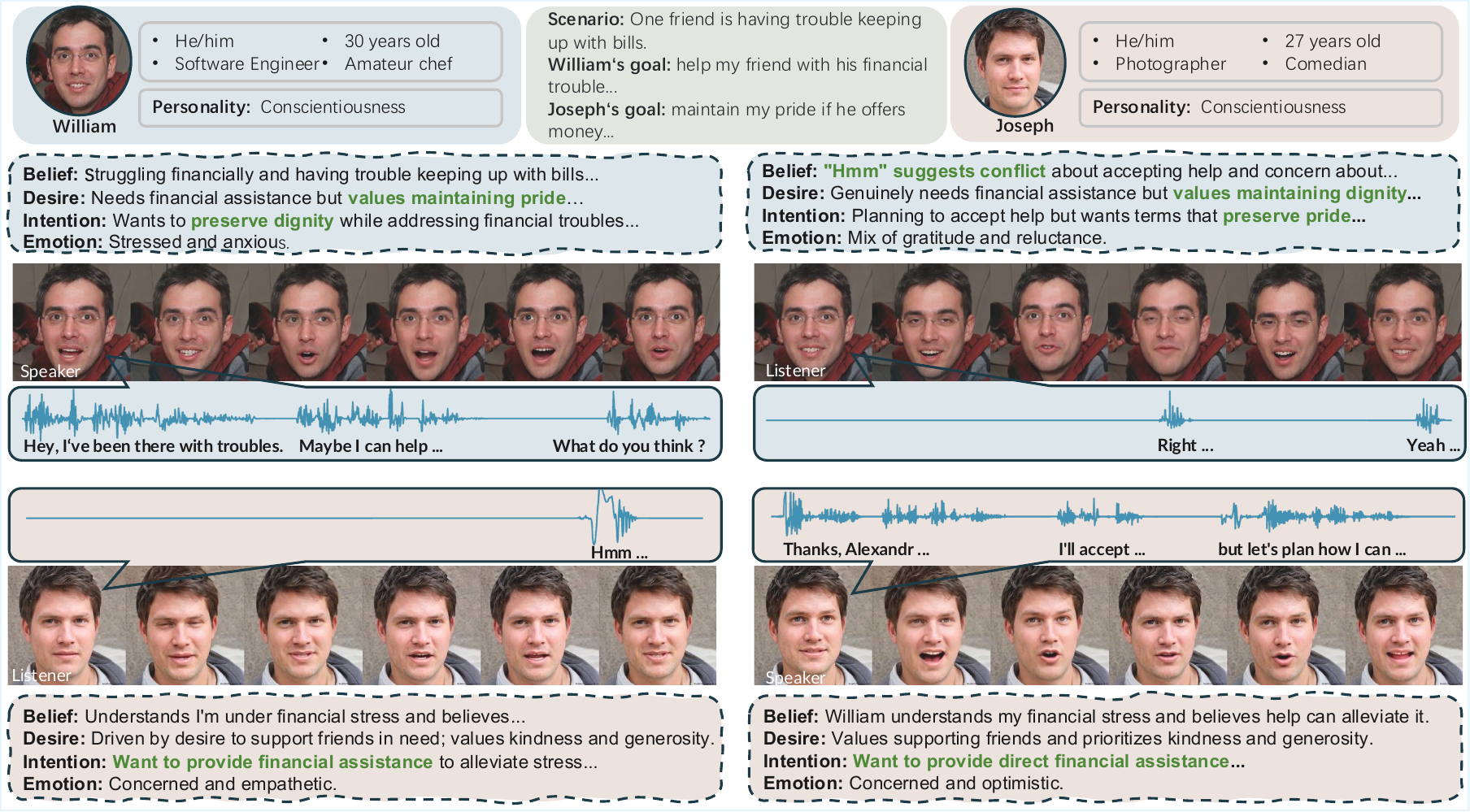
Qualitative Case Studies and Causal Analysis
The qualitative section highlights a central claim of the paper: explicit ToM can outperform both naive agent mode and full-information Script mode when the goal is socially plausible interaction. In the case study, Script mode violates information asymmetry by referencing a family detail that the other agent never disclosed. Agent mode becomes verbose and probing, causing the partner to over-disclose. The proposed method instead infers that the partner is uncomfortable being probed, rejects candidate responses that would push too aggressively, and selects a boundary-respecting response that still advances the speaker’s goal.
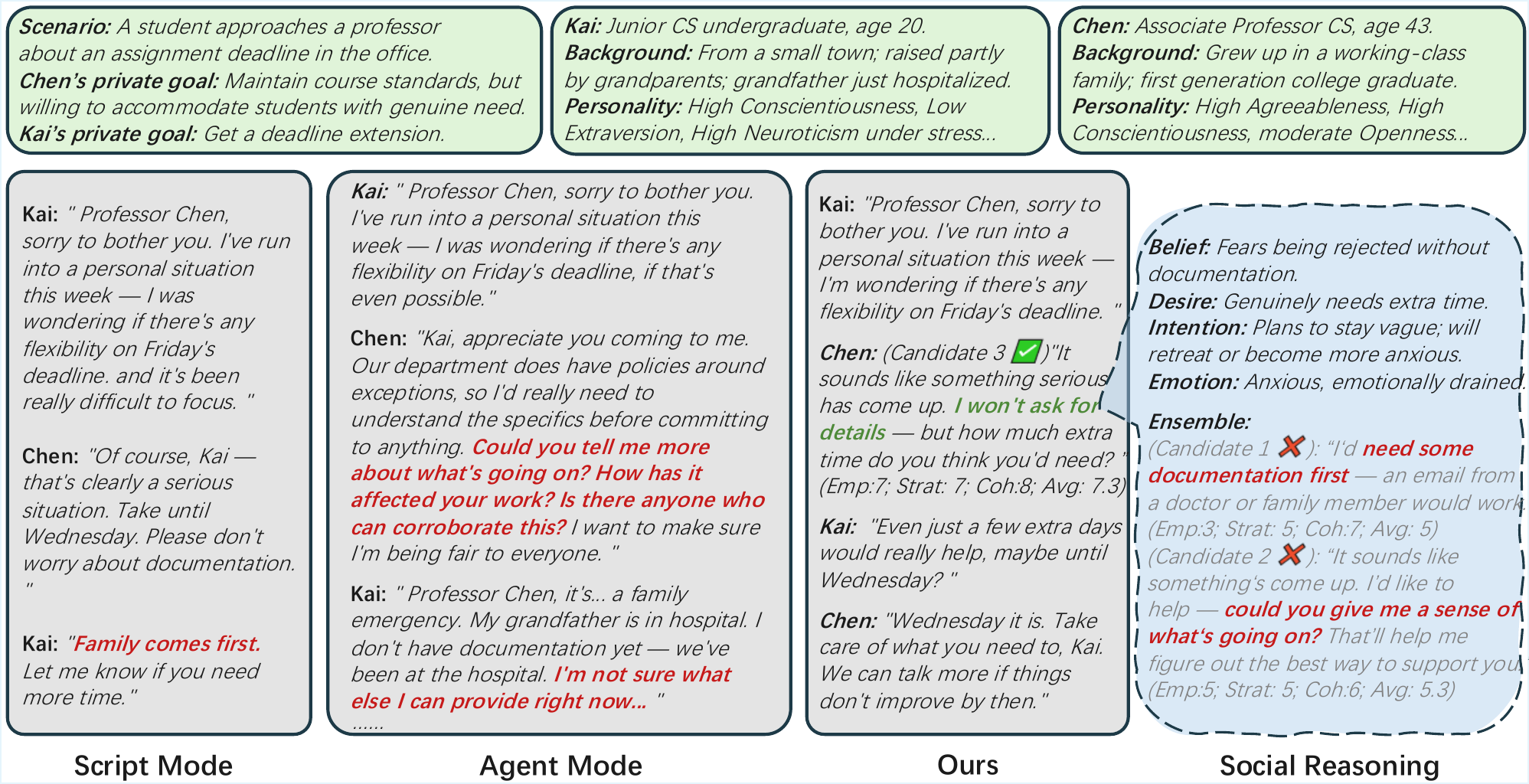
Additional qualitative visual examples show that the model can render synchronized emotional transitions across turns and generate compound emotional states via the 8-dimensional emotion vector. The paper argues that these results demonstrate not only expressiveness but also conversational grounding, because the listener’s backchannel is conditioned on the partner’s content and the agent’s inferred social stance.
Limitations
The paper is explicit about two main limitations. First, emotion control is still tied to the 8 discrete MEAD-style categories inherited by DICE-Talk, so nuanced states such as “bittersweet nostalgia” fall outside the training distribution. Second, the 50 personas span a limited demographic and cultural range, which constrains the breadth of social behavior the benchmark can test. The authors suggest extending to continuous emotion annotations, richer cross-cultural grounding, and personality that evolves across multi-session interactions.
Takeaways for a Talking-Head / Conversational-AI Team
- The main architectural novelty is the closed-loop coupling of perception, ToM reasoning, and dual-agent expression, rather than treating dialogue and avatar generation as separate problems.
- The key social-cognition insight is that explicit inference under uncertainty can be better than full-information access, because it encourages boundary-aware, socially plausible dialogue.
- The visual-generation novelty is not just lip-sync or emotion control, but reactive listener modeling integrated into the output video.
- The Persona-Scenario dataset is designed to make information asymmetry testable and repeatable, which is useful if your team wants to benchmark social intelligence rather than only surface fluency.
Conclusion
Overall, Resonant Minds presents a strong systems-level argument for unifying multimodal perception, Theory of Mind, and emotion-controllable generation in a single conversational avatar loop. The reported results support the claim that socially grounded reasoning improves both dialogue and animation quality, and that explicit mental-state inference can produce better behavior than unrestricted access to hidden information. The paper’s practical value lies in its end-to-end formulation: it is not merely an avatar generator or a dialogue agent, but a framework for socially aware embodied interaction.
Code & Implementation
This repository is currently a placeholder. According to the README, the authors plan to open-source the code, data, and benchmark in the future, but as of now, the implementation code and datasets are not yet released.
The repository contains a detailed README with the project overview, but there are no source files present for the multimodal perception, social reasoning, or emotion-controllable expression modules described in the paper.
Future releases are expected to include inference code for closed-loop dual-agent conversation generation, the Persona-Scenario dataset, and evaluation scripts.