SAGE
Self-Learning Expression Deformations for Data-Efficient Gaussian Avatars
SAGE creates animatable 3D Gaussian avatars from minimal data by self-learning expression deformations using geometric and appearance consistency, eliminating the need for long expression data. It supports multiview, monocular, and one-shot inputs without pretraining, enabling efficient and accessible avatar creation.
Links
Paper & demos
Impact
Abstract
Modeling dynamic facial expressions using 3D Gaussian representations remains challenging due to their unstructured nature. Conventional Gaussian avatar pipelines require extensive multiview and sequential expression data, limiting scalability and accessibility. In this work, we introduce Self-Adaptive Gaussian Expression (SAGE), a framework for self-learning expression-induced Gaussian deformations that enables high-fidelity, animatable avatars from minimal input data. Our method jointly optimizes 2D Gaussian surfels and a Signed Distance Field (SDF) to enforce compact, surface-aligned Gaussian distributions, while a self-supervised expression learning phase replaces long training sequences with geometric and appearance consistency constraints. This design allows flexible deployment across multiple reconstruction regimes: in the multiview setting, only a single frame (timestep) is required instead of thousands; in the monocular setting, only head rotations are needed without expression sequences; and in the one-shot setting, no pretraining or priors are necessary. Experiments demonstrate that our approach achieves reconstruction and animation quality comparable to state-of-the-art methods, while reducing data requirements by several orders of magnitude. Our results highlight the potential of self-supervised Gaussian deformation learning as a step toward accessible, data-efficient avatar creation.
Introduction
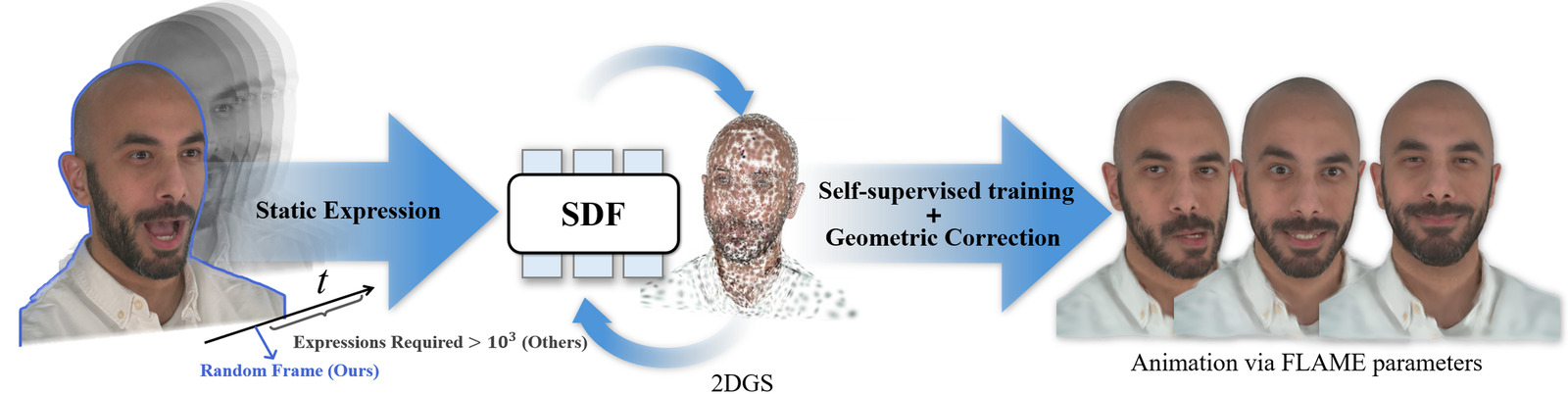
This paper addresses a central bottleneck in Gaussian-avatar head reconstruction: dynamic facial expression modeling with 3D Gaussian representations is difficult because the representation is unstructured, and existing avatar pipelines usually rely on long, densely captured multiview and/or expression sequences. The authors argue that this dependence limits scalability and makes high-quality animatable avatars inaccessible in practical settings.
Their solution is SAGE (Self-Adaptive Gaussian Expression), a framework that learns expression-induced Gaussian deformation from minimal data. The key idea is to replace long expression-supervised training with a combination of geometric constraints and self-supervised appearance consistency, while still producing avatars that can be animated by FLAME parameters. The paper positions SAGE as a data-efficient alternative across three reconstruction regimes: multiview reconstruction from a single timestep, monocular reconstruction from head-rotation data only, and one-shot reconstruction from a single image without pretraining or priors.
The method combines two ingredients that are tightly coupled throughout the pipeline: (i) joint optimization of 2D Gaussian surfels and a signed distance field (SDF) so that the Gaussians become compact and surface-aligned, and (ii) a second, self-supervised training phase that enforces geometric and appearance robustness under deformation. The paper’s claimed contribution is not merely a new renderer, but a training strategy that makes Gaussian avatars substantially less dependent on long expression datasets.
Problem Setting and Core Idea
The paper starts from the observation that 3D Gaussian splatting is highly effective for rendering, but its primitives are not inherently structured like meshes or implicit surfaces. When these primitives are animated, small geometric inconsistencies can become visible as texture drift, surface noise, or unstable view-dependent artifacts. In facial reenactment, this is especially problematic because expressions introduce non-rigid, high-frequency deformation around the mouth, eyes, cheeks, and brow.
Existing Gaussian-avatar methods, including mesh-bound and expression-conditioned variants, can achieve strong quality, but the paper argues they tend to require extensive sequential data to learn deformation reliably. SAGE instead tries to obtain deformation robustness by explicitly enforcing surface geometry and by self-supervising deformation consistency, so that the model learns how Gaussians should behave under expression changes even when expression supervision is sparse.
The pipeline is designed around FLAME-based rigging. In the terminology of the paper, each Gaussian is bound to a FLAME mesh triangle and transformed through the mesh’s local coordinate system. This makes the avatar controllable by FLAME shape, pose, and expression parameters, while the geometric constraints reduce the tendency of Gaussians to drift away from the facial surface during training and animation.
Preliminaries
The paper reviews three ingredients that SAGE builds on: 3D Gaussian splatting, 2D Gaussian splatting, and GaussianAvatars-style FLAME binding.
In standard 3D Gaussian splatting, a Gaussian primitive is parameterized as $\mathcal{G} = \{\mathbf{x}, \mathbf{R}, \mathbf{s}, \alpha, \mathbf{c}, \mathbf{sh}\}$ and rendered by tile-based rasterization given camera intrinsics and extrinsics. The key parameters are center position, rotation, scale, opacity, color, and spherical harmonics coefficients.
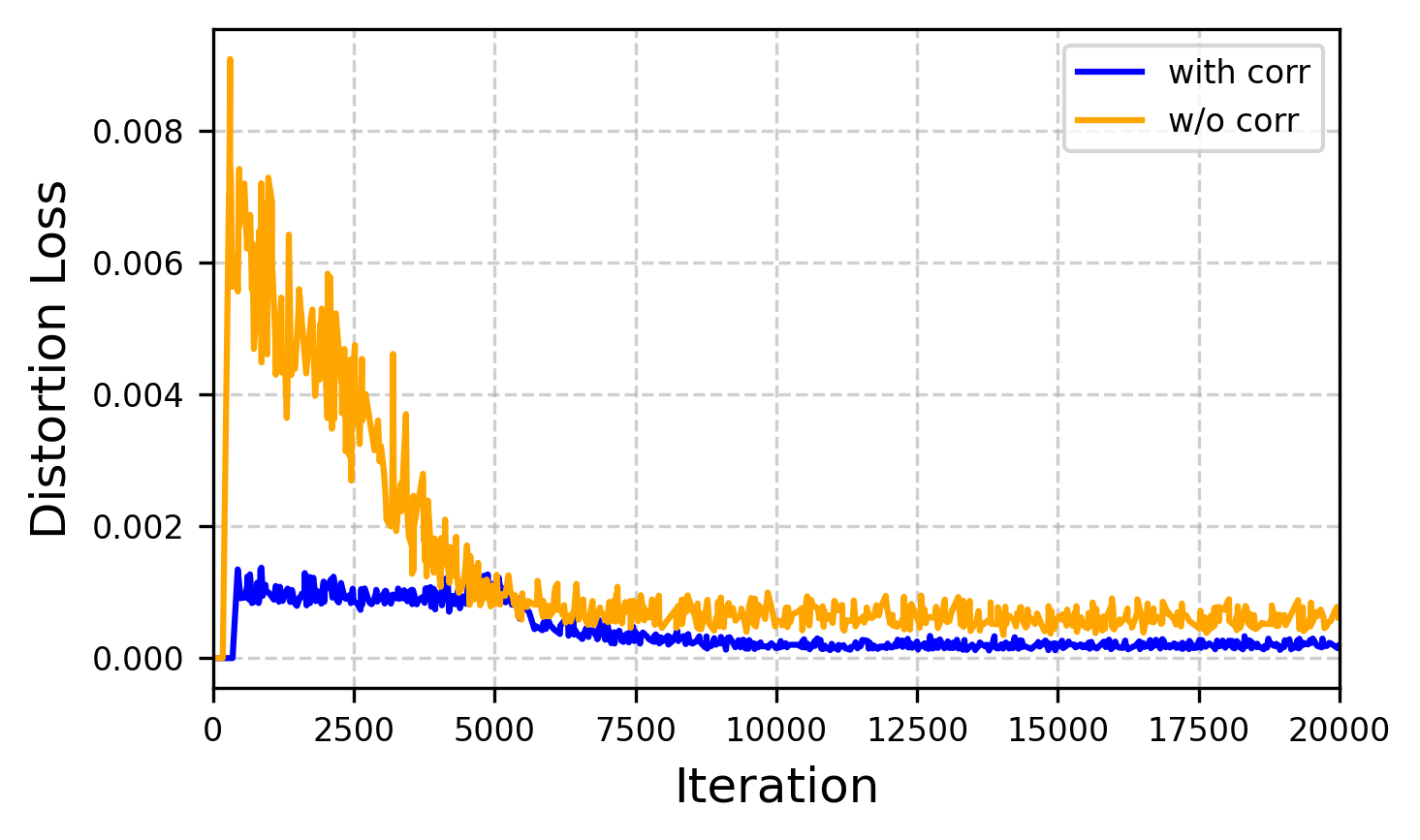
2D Gaussian splatting replaces ellipsoids with planar surfels to better align with thin surfaces. In this formulation, each primitive uses two tangent vectors $\mathbf{t}_1, \mathbf{t}_2$ and two in-plane scales $s_1, s_2$, with the normal defined by $\mathbf{t}_3 = \mathbf{t}_1 \times \mathbf{t}_2$. The paper highlights two regularizers from 2DGS that are important later: a distortion loss,
$$ \mathcal{L}_d = \sum_{i,j} \omega_i \omega_j |z_i - z_j|_1, $$
which reduces depth variation among overlapping splats, and a normal-consistency loss,
$$ \mathcal{L}_n = \sum_i \alpha_i \bigl(1 - |\mathbf{n}_i^\top \mathbf{N}|_1\bigr), $$
which aligns per-splat normals with estimated surface normals.
The GaussianAvatars baseline is important because it binds Gaussians to a tracked FLAME mesh. A local coordinate frame is defined per mesh triangle, and the Gaussian’s local attributes are mapped into global space using triangle origin, orientation, and scale. At runtime, the mesh is deformed via linear blend skinning and FLAME parameters $\{\boldsymbol{\beta}, \boldsymbol{\theta}, \boldsymbol{\psi}\}$.
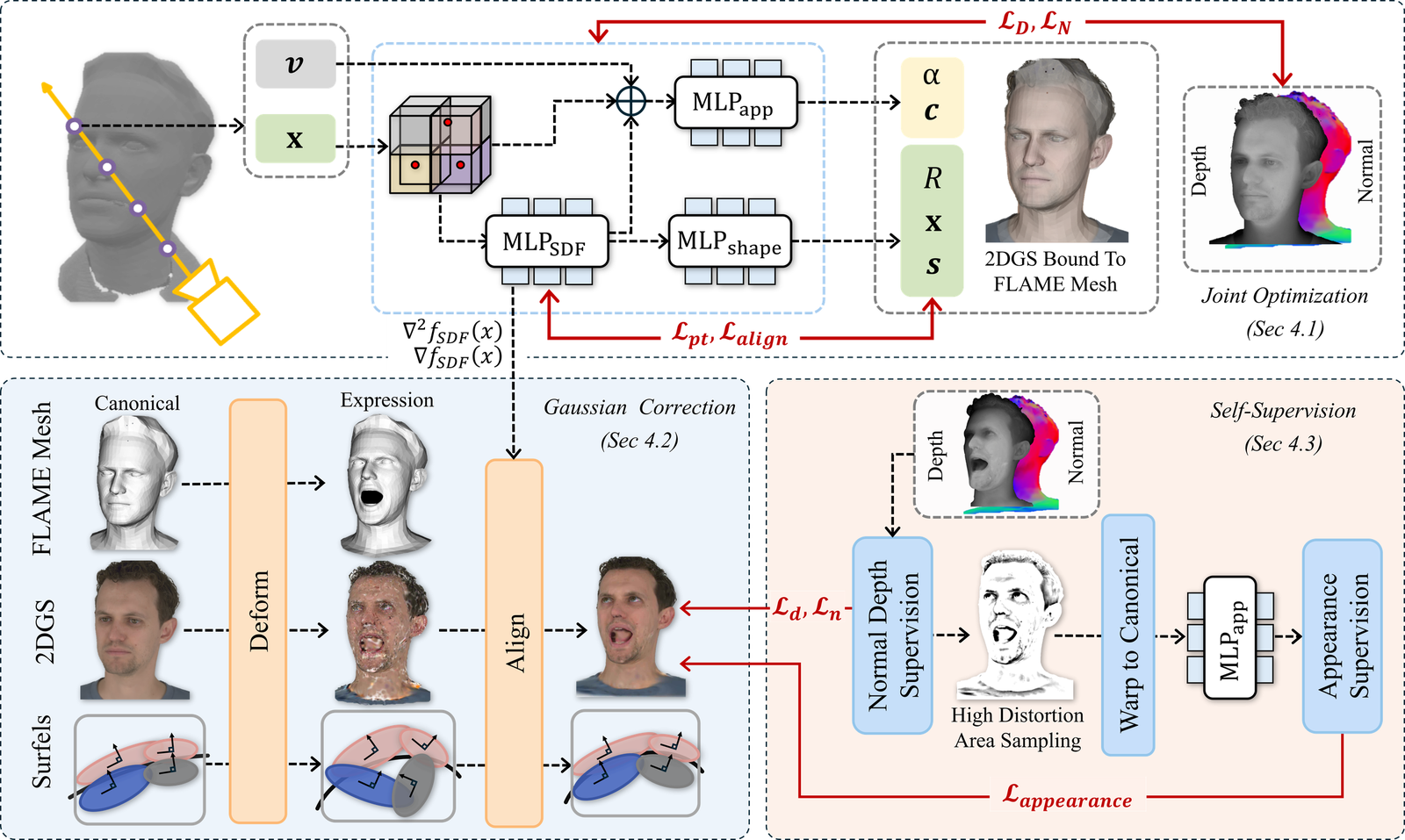
Method: SAGE
SAGE extends this FLAME-bound Gaussian setup with three tightly connected components: a first-stage joint optimization of SDF and 2DGS, a Gaussian attribute and shape parametrization network, and a deformation-aware correction mechanism that adapts surfel shapes during animation. The overall training is then completed by a second self-supervised phase focused on deformation robustness.
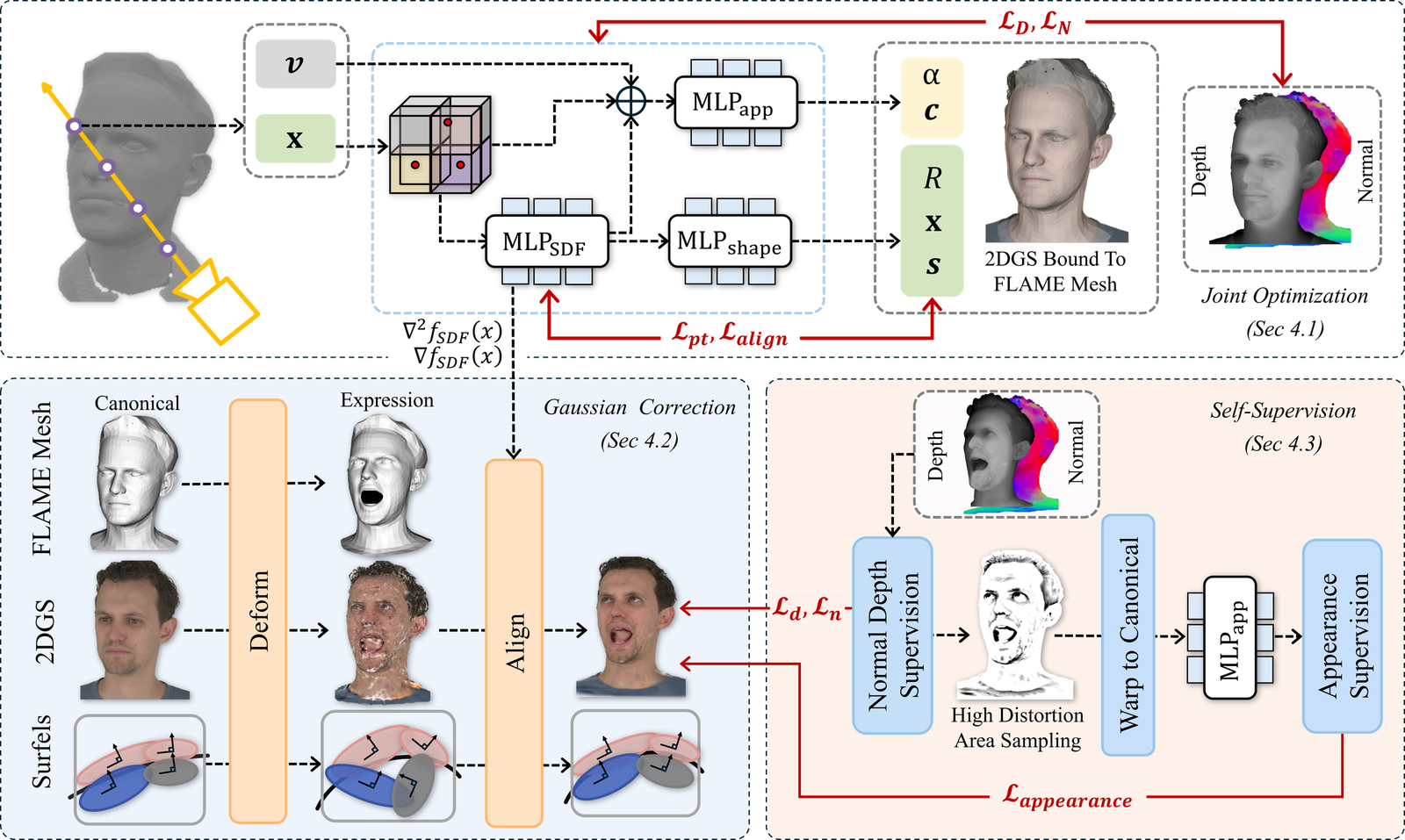
1) Neural surface reconstruction with SDF supervision
In the first phase, SAGE jointly optimizes an SDF $f_{\mathrm{SDF}}$ and Gaussian surfels. The paper explicitly uses the SDF to pull Gaussian centers toward the surface by minimizing the absolute SDF value at each Gaussian center:
$$ \mathcal{L}_{\mathrm{pt}} = |f_{\mathrm{SDF}}(\mathbf{x}^G)|_1. $$
To further encourage surfels to lie tangentially to the facial surface, the paper aligns the Gaussian normal with the SDF gradient-derived normal:
$$ \mathcal{L}_{\mathrm{align}} = \left|1 - \left| (\mathbf{t}_3^G)^\top \nabla f_{\mathrm{SDF}}(\mathbf{x}^G) \right| \right|_1. $$
Following MonoSDF-style supervision, the SDF is also trained with depth and normal maps rendered from 2DGS. The paper adds a smoothing constraint to reduce noisy behavior caused by Gaussian over-cluttering. Together, these terms are used to make the Gaussian distribution compact, close to the surface, and more stable for later deformation.
2) Parametrized Gaussian attributes
The paper emphasizes that discrete Gaussian primitives do not naturally share gradients with neighboring primitives, so attributes can become effectively uncorrelated and inconsistent across deformation. To combat this, SAGE parameterizes Gaussian attributes with separate MLPs instead of letting each Gaussian remain an isolated free variable.
The appearance network $f_{\mathrm{app}}$ is conditioned on the SDF and takes the query point, view direction, SDF gradient normal, and a latent feature vector from the SDF hash grid as input. It predicts color and opacity:
$$ \hat{\mathbf{c}},\hat{\alpha} = f_{\mathrm{app}}(\mathbf{x}^G, \mathbf{v}, \hat{\mathbf{n}}, \hat{\mathbf{z}}). $$
The appearance and surface regularization losses are combined as
$$ \mathcal{L}_{\mathrm{sdf}} = \mathcal{L}_{\mathrm{rgb}} + \lambda_{\mathrm{pt}}\mathcal{L}_{\mathrm{pt}} + \lambda_{\mathrm{align}}\mathcal{L}_{\mathrm{align}} + \lambda_{\mathrm{D}}\mathcal{L}_{\mathrm{D}} + \lambda_{\mathrm{N}}\mathcal{L}_{\mathrm{N}}. $$
The shape network uses multi-resolution hash-grid features and predicts Gaussian rotation and scale from the query point plus interpolated features:
$$ \{\mathbf{R}^G, \mathbf{s}^G\} = f_{\mathrm{shape}}\left(\mathbf{x}^G, \{\operatorname{interp}(\mathbf{x}^G, \Phi^l)\}_l\right). $$
The supplementary material clarifies that this shape network predicts the lower-triangular part of a matrix and a scalar, reconstructs a symmetric Hessian, and then uses eigen-decomposition to interpret the smallest eigenvector as the surfel normal. The remaining two eigenvectors define the tangent plane, and the two non-zero eigenvalues are rescaled to produce the surfel scales. This gives the network a geometry-aware way to infer local orientation and local anisotropy from the SDF.
3) Gaussian surfel correction from stretch and curvature
A distinctive component of SAGE is the surfel correction mechanism applied during deformation. For a given surfel, the method identifies nearby Gaussians using a small-radius ball query around the triangle that bounds the surfel. It then estimates local deformation from the relative transformation of neighbors, using $M_j = T_q^{-1} T_j$ with respect to the query surfel.
The linear part of each local transformation is projected onto the tangent plane to estimate principal stretches. The paper defines the stretch matrix using a tangent projection matrix $\mathbf{P} = \mathbf{I} - \nabla f_{\mathrm{SDF}}\nabla f_{\mathrm{SDF}}^T$ and a weighted sum over neighbors. In parallel, principal curvatures are estimated from a projected Hessian using the SDF second derivatives. These two geometric signals are then used to change surfel scale and rotation.
Scale is adjusted by both stretch and curvature:
$$ s_1^{\mathrm{adj}} = s_1 \cdot \sigma_1 \frac{1}{1 + w_s |\kappa_1|_1}, \quad s_2^{\mathrm{adj}} = s_2 \cdot \sigma_2 \frac{1}{1 + w_s |\kappa_2|_1}. $$
Rotation is corrected by aligning surfel basis vectors with principal curvature directions while preserving the original normal. The paper constructs small correction quaternions and multiplies them with the current Gaussian rotation quaternion. The stated purpose is to prevent excessive elongation in highly curved regions and to keep the local surfels aligned with the evolving surface geometry.
The paper also states that surfels without valid neighbors or surfels bound to the hair mesh are excluded from deformation updates. This is consistent with the broader design goal of focusing correction on reliable facial skin regions rather than on ambiguous or weakly observed areas.

4) Self-supervised training phase
The second phase is the paper’s main data-efficiency mechanism. Instead of requiring long image sequences with explicit expression supervision, SAGE deforms the avatar with FLAME parameters and then enforces consistency through regularization and appearance matching. The paper explicitly states that no ground-truth images are needed in this phase.
The phase uses the same 2DGS-style normal consistency and distortion regularizers, but now as self-supervised constraints under deformation. These encourage the Gaussians to remain tangential to the deformed surface and prevent the avatar from developing unstable local overlap or distortion artifacts.
Appearance consistency is enforced by comparing rasterized Gaussian pixels with canonical volumetric rendering after warping rays back to canonical space through the transformation of the mesh triangle where the ray intersects. Importantly, the paper does not sample uniformly; it focuses the appearance loss on regions with high normal-consistency or distortion error, which are typically the most artifact-prone. Hair regions are intentionally avoided.
The appearance loss is
$$ \mathcal{L}_{\mathrm{appearance}} = \sum_{h,w} \left|\hat{C}(\gamma(\mathbf{r}_{h,w})) - I_{h,w}\right|^2, $$
and the total loss in phase two is
$$ \mathcal{L}_{\mathrm{total}} = \lambda_n \mathcal{L}_{\mathrm{n}} + \lambda_d \mathcal{L}_{\mathrm{d}} + \lambda_a \mathcal{L}_{\mathrm{appearance}}. $$
The paper freezes the SDF and the hash feature grid during this phase, so the second phase fine-tunes deformation robustness without destabilizing the learned canonical geometry.

5) Adaptability across reconstruction regimes
A major claim of the paper is that the same framework can be deployed under multiple data regimes with only modest adaptation. The paper distinguishes three main settings.
- Multiview reconstruction: the method follows standard Gaussian splatting and static SDF reconstruction, but only a single timestep is needed rather than a long expression sequence.
- Monocular reconstruction: the paper states that only moderate head rotations are required. To support canonical reconstruction, it uses MonoNPHM’s deformation module to backward-warp rays into canonical space, and it adopts a pretrained deformation prior from MonoNPHM. The authors also add a super-resolution stage to mitigate motion blur and recover detail.
- One-shot reconstruction: the paper demonstrates that animatable avatars can be built from a single image. For this case, it integrates the GenHead module from Portrait-4D to synthesize pseudo-multiview images using a triplane head representation conditioned on FLAME parameters, then lightly fine-tunes on NeRSemble. A super-resolution stage is again used to restore higher-frequency appearance details.
The authors emphasize that these are pragmatic adaptations of the same core method, not separate models. The central reason the method transfers across regimes is the geometry-first design: the SDF anchors the canonical head shape, while Gaussian correction and self-supervision stabilize deformation without relying on dense expression sequences.
Training and Implementation Details
The experiments use 14 identities from the NeRSemble dataset, which contains 11 expression sequences captured by 16 cameras spanning frontal and side views. The paper uses the preprocessed version from GaussianAvatars, which selected 10 expression sequences. Images are downsampled to a resolution of 550 by 802, and FLAME tracking is performed with VHAP. One sequence is held out for testing self-reenactment.
The paper reports several implementation choices intended to stabilize optimization. It pretrains the SDF on a coarse FLAME mesh and initializes Gaussian optimization with that pretrained SDF. Rather than using 3DGS densification, the method initializes 150,000 points and distributes them across mesh triangles according to scale, giving more points to face regions and regions closer to the camera. During optimization, Gaussians are allowed to rebind to different triangles based on distance.
Because the mouth interior is unobserved, the authors add a new mesh inside the mouth, rig it to the lower jaw, and pretrain a mouth-interior Gaussian prior that is composited during rendering. They also darken Gaussians in high-distortion regions to mimic wrinkle-like shading effects. The supplementary material explains that these high-error regions correlate with facial creases and expression-dependent wrinkles.
Optimization uses Adam for all learnable parameters. The SDF, shape network, appearance MLP, and feature grid are implemented with adapted tiny-cuda-nn from NeuS2, using a learning rate of $10^{-4}$. The Gaussian model is trained for 30,000 iterations, after which the SDF branch is frozen for the second phase. The paper states that the full process takes about 2 hours on an NVIDIA A100 GPU.

Experimental Evaluation
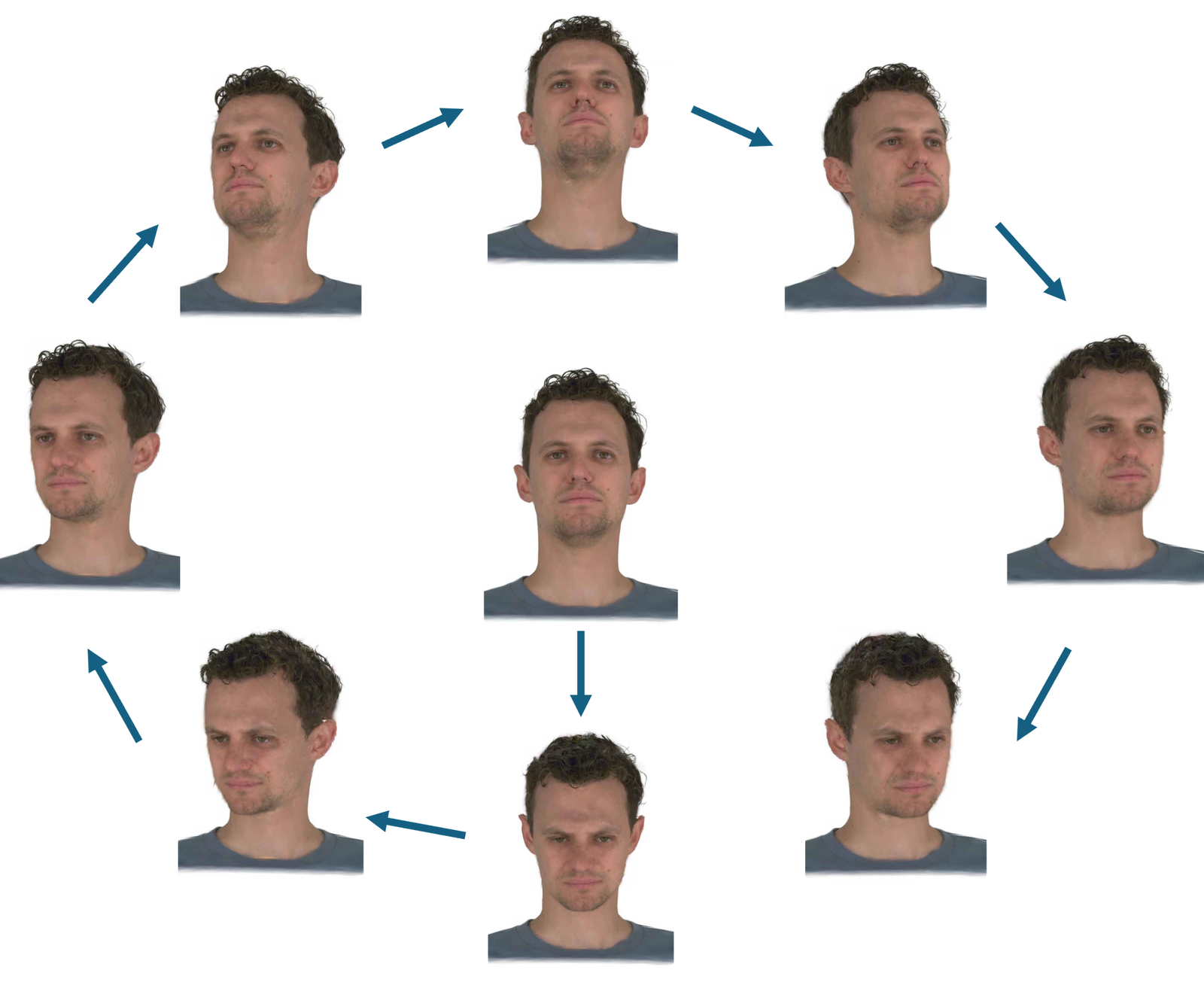
The paper evaluates SAGE on self-reenactment, novel-view synthesis, and reconstruction quality under multiple input regimes. The main metrics are PSNR, SSIM, and LPIPS. For qualitative comparisons, the paper uses several composite figures showing results under multiview, monocular, one-shot, and less-calibrated settings.
Main comparison setup
The experiments are grouped into five input-type settings. For multiview reconstruction, the paper compares against GaussianAvatars and Gaussian-Head-Avatar in both full-sequence and single-frame settings. For one-shot reconstruction, the paper compares against GPAvatar and LAM. For monocular reconstruction, it compares against FlashAvatar and RGBAvatar, again in both full-sequence and head-rotation-only variants.
The paper notes that GaussianAvatars and Gaussian-Head-Avatar require much longer training on full multiview data: approximately 5 hours for GA and 14 hours for GHA, which is substantially longer than the reported SAGE pipeline. In the monocular setting, the authors also use MICA tracking’s FLAME expression parameters for fair animation driving, while keeping the original translation and rotation parameters for pose accuracy.


Self-reenactment results
Self-reenactment is the paper’s primary evaluation task because it directly measures whether a reconstructed avatar can reproduce unseen expressions for the target identity. The paper reports that SAGE is competitive with or superior to state of the art across all reconstruction settings, even though it does not use explicit expression supervision.
The strongest qualitative claim is that SAGE preserves more stable facial geometry and fewer artifacts under sparse multiview input. In the one-shot setting, the paper reports better geometric fidelity and stronger multiview consistency than GPAvatar and LAM. In the monocular setting, it reports improved cross-view coherence and more reliable expression transfer than FlashAvatar and RGBAvatar.
| Method | Input Type | Novel Expression (frontal) | Novel Expression (all view) | ||||
|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | ||
| GA | MV-MF | 25.94 | 0.922 | 0.079 | 25.32 | 0.903 | 0.084 |
| GHA | MV-MF | 26.21 | 0.915 | 0.076 | 24.98 | 0.894 | 0.087 |
| GA | MV-SF | 17.75 | 0.825 | 0.200 | 17.23 | 0.823 | 0.215 |
| GHA | MV-SF | 16.21 | 0.757 | 0.214 | 15.29 | 0.762 | 0.243 |
| Ours | MV-SF | 25.41 | 0.896 | 0.085 | 24.27 | 0.879 | 0.094 |
| GPAvatar | One-shot | 17.89 | 0.816 | 0.180 | 15.47 | 0.755 | 0.286 |
| LAM | One-shot | 20.73 | 0.815 | 0.154 | 15.23 | 0.732 | 0.290 |
| Ours | One-shot | 21.04 | 0.821 | 0.125 | 18.57 | 0.785 | 0.169 |
| FlashAvatar | SV-MF | 21.24 | 0.866 | 0.143 | 16.95 | 0.810 | 0.239 |
| RGBAvatar | SV-MF | 21.32 | 0.845 | 0.135 | 15.95 | 0.809 | 0.252 |
| FlashAvatar | SV-HR | 18.36 | 0.830 | 0.159 | 15.89 | 0.783 | 0.271 |
| RGBAvatar | SV-HR | 19.79 | 0.827 | 0.147 | 16.95 | 0.820 | 0.260 |
| Ours | SV-HR | 23.90 | 0.90 | 0.089 | 22.76 | 0.881 | 0.102 |
Here, MV-MF means multiview / multi-frame, MV-SF means multiview / single-frame, SV-MF means single-view / multi-frame, and SV-HR means single-view / head-rotation-only. The main takeaway from the table is that SAGE closes or reverses the gap with methods trained on much denser supervision, especially in the sparse regimes where standard Gaussian avatar methods degrade sharply.
Quantitative comparison on INSTA
The paper also evaluates on INSTA, described as a less calibrated and more challenging capture setting. In this benchmark, the authors report both multiview multi-frame and one-shot reconstruction performance.

| Method | Input Type | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| GA | SV-MF | 28.11 | 0.944 | 0.065 |
| RGBAvatar | SV-MF | 29.02 | 0.933 | 0.087 |
| Ours | SV-MF | 29.03 | 0.925 | 0.082 |
| LAM | One-shot | 22.54 | 0.839 | 0.101 |
| Ours | One-shot | 24.80 | 0.887 | 0.088 |
On INSTA, the reported multiview results show that SAGE is competitive with the best baselines. In the one-shot case, SAGE improves over LAM by a large margin in all three metrics, which the paper interprets as evidence that the geometry-first design remains useful even under less calibrated capture conditions.
Qualitative novel-view and cross-reenactment results
The supplementary material states that direct numerical novel-view synthesis metrics are not reported because the experiment groups use different expressions and view sets, making direct cross-group comparison difficult. Instead, the paper provides qualitative comparisons showing that SAGE produces stronger cross-view consistency than RGBAvatar and LAM under sparse-view conditions.




The paper also provides cross-reenactment figures showing that the source avatar can be adapted to different target views. The text claims that SAGE’s stronger geometric anchoring improves multiview coherence and reduces the view-dependent artifacts commonly seen in sparse-input baselines.
Ablation Study
The ablation study focuses on four design choices: Gaussian attribute parametrization with MLPs, the second self-supervised phase, and Gaussian surfel correction. The paper reports ablations on both novel-view and self-reenactment quality. One important observation is that some design choices improve reenactment more than novel-view synthesis, highlighting a trade-off between static reconstruction fidelity and deformation robustness.
| Variant | Novel-View | Self-Reenactment | ||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| SAGE | 33.79 | 0.963 | 0.071 | 26.64 | 0.907 | 0.093 |
| w/o MLPs | 33.95 | 0.961 | 0.071 | 24.72 | 0.857 | 0.142 |
| w/o 2nd phase | 34.14 | 0.962 | 0.067 | 22.18 | 0.800 | 0.132 |
| w/o correction | Same as full | Same as full | Same as full | 25.42 | 0.905 | 0.101 |
The paper’s interpretation of these results is nuanced. Removing the MLPs hurts fine-grained identity details and makes colors more random, especially in regions such as facial hair and eyes. Without the second phase, reenactment quality drops substantially, which supports the claim that self-supervised deformation consistency is a key ingredient. Interestingly, the second phase can slightly reduce novel-view quality while improving reenactment, indicating a trade-off between static reconstruction and deformation generalization. Disabling surfel correction only mildly degrades performance, but it still weakens geometry and appearance, especially around the brow and mouth.
Expression Data Dependency
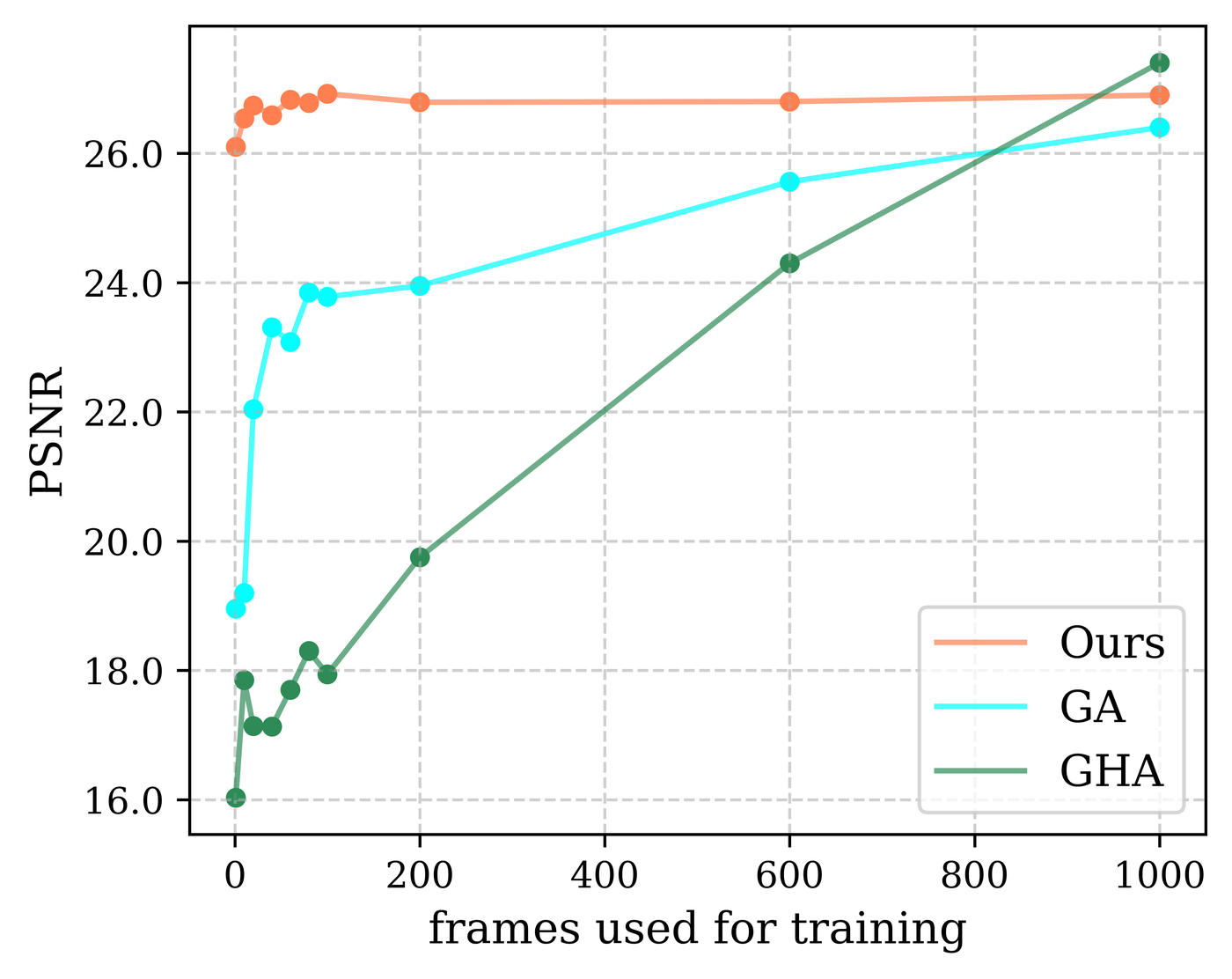
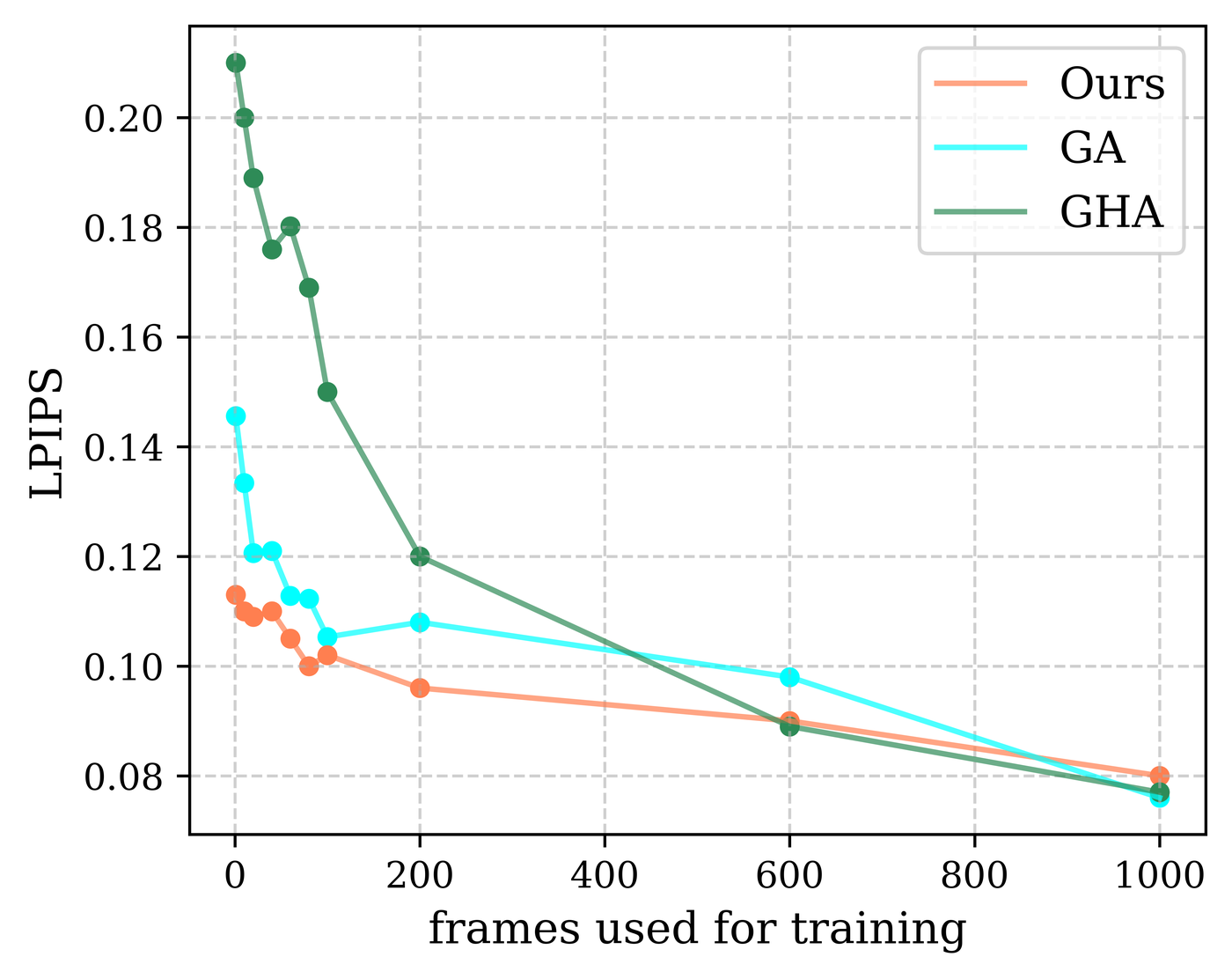
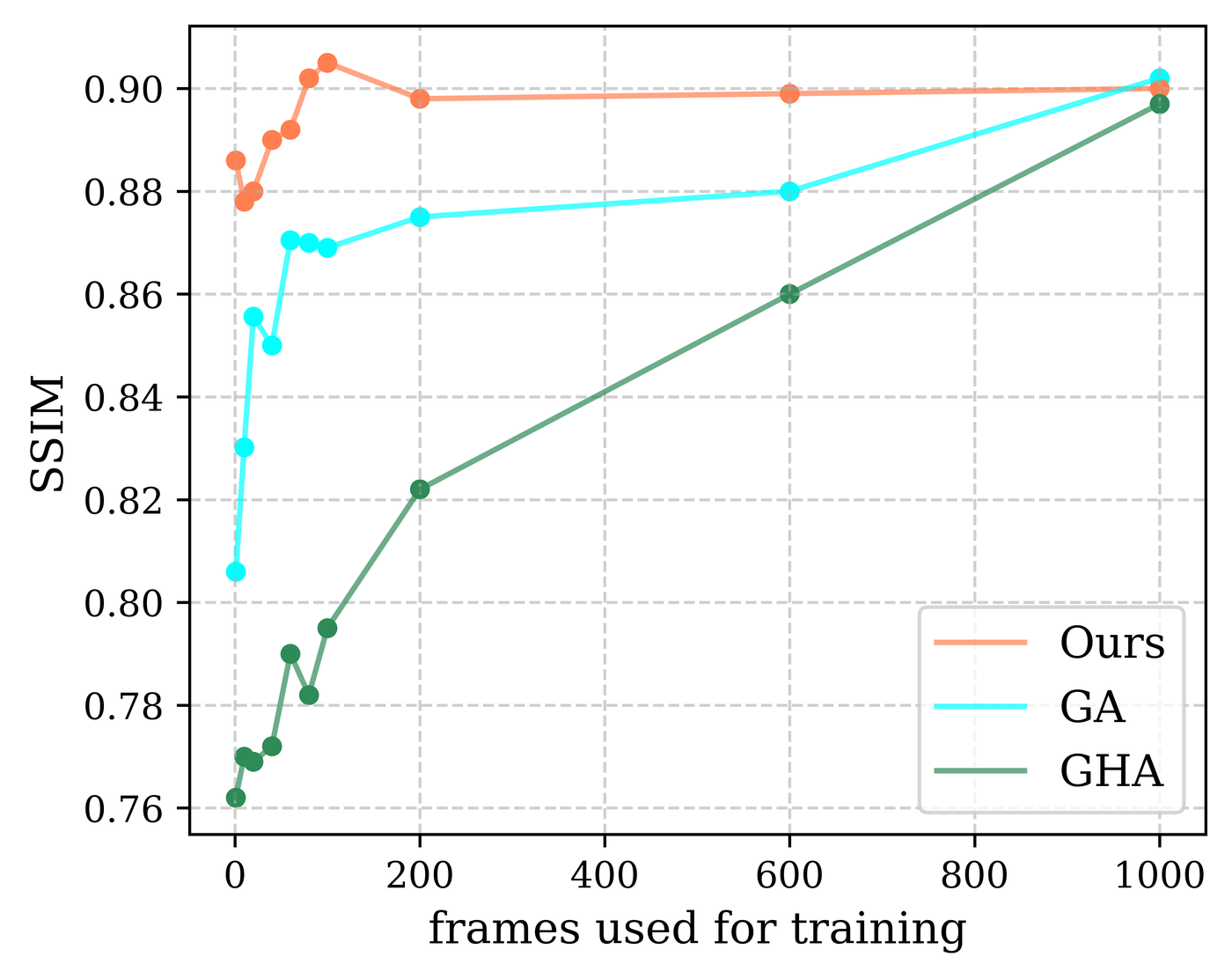
The supplementary experiments examine how sensitive the method is to the amount and type of expression supervision used during training. The first study varies the number of training expressions for participant 074 under the multiview setting. The paper reports that baseline models improve steeply as more frames are added, while SAGE remains robust even with sparse data and does not depend strongly on dense temporal supervision.
The second study changes the canonical expression used to reconstruct the SDF for participant 306, using six different expressions spanning from eyes-closed to mouth-open. The paper reports only small variations across these choices, suggesting that SAGE is relatively insensitive to which expression is selected as the canonical reference. A neutral, mouth-open reference tends to perform slightly better, while more extreme expressions can hurt performance because of missing eyeball visibility and more challenging fine facial creases.
| Expression | PSNR | SSIM | LPIPS |
|---|---|---|---|
| 1 | 25.62 | 0.873 | 0.118 |
| 2 | 26.94 | 0.885 | 0.109 |
| 3 | 26.53 | 0.868 | 0.123 |
| 4 | 27.31 | 0.892 | 0.102 |
| 5 | 27.12 | 0.906 | 0.110 |
| 6 | 27.32 | 0.890 | 0.099 |

Limitations, Ethical Considerations, and Scope
The paper is explicit about several limitations. First, SAGE depends on the quality and expressiveness of FLAME parameters; expressions that FLAME cannot represent accurately can still induce visible errors in the rendered result. Second, unobserved regions such as teeth and tongue depend on pre-fitting, so the method is not fully self-sufficient for every facial component. Third, the monocular and one-shot adaptations rely on auxiliary priors or synthetic data generation for practical reconstruction, even though the core method is geometry-driven.
The authors also note a broader future direction: the framework could be adapted to other Gaussian-based non-rigid objects, including human bodies, as long as per-Gaussian transformations can be inferred. They suggest possible improvements such as normal-map-conditioned diffusion for pseudo multiview synthesis, replacing FLAME with a more expressive model such as NPHM, and adding synthetic priors with identity encoding for better few-shot reconstruction.
The conclusion also includes ethical considerations. The authors emphasize privacy, consent, and misuse risks in animatable photorealistic avatar generation. They recommend explicit user consent, biometric-data security, watermarking, diverse datasets, and transparent deployment practices to mitigate risks such as identity theft, deepfakes, and bias.
Conclusion
SAGE presents a practical route toward data-efficient animatable Gaussian avatars by combining SDF-guided geometric supervision, parameterized Gaussian attributes, deformation-aware surfel correction, and a self-supervised second training phase. The central contribution is not a new rendering primitive alone, but a training and regularization strategy that allows Gaussian avatars to be trained from drastically less data while still maintaining strong reenactment quality.
Across multiview, monocular, and one-shot settings, the paper reports competitive or better performance than baselines that typically require much denser supervision. The results support the paper’s main thesis: self-supervised Gaussian deformation learning can make avatar creation substantially more accessible without sacrificing too much reconstruction or animation quality.