IRAF
IRAF: Interference-Resilient Adaptive Fusion for Noise-Robust End-to-End Full-Duplex Spoken Dialogue Systems
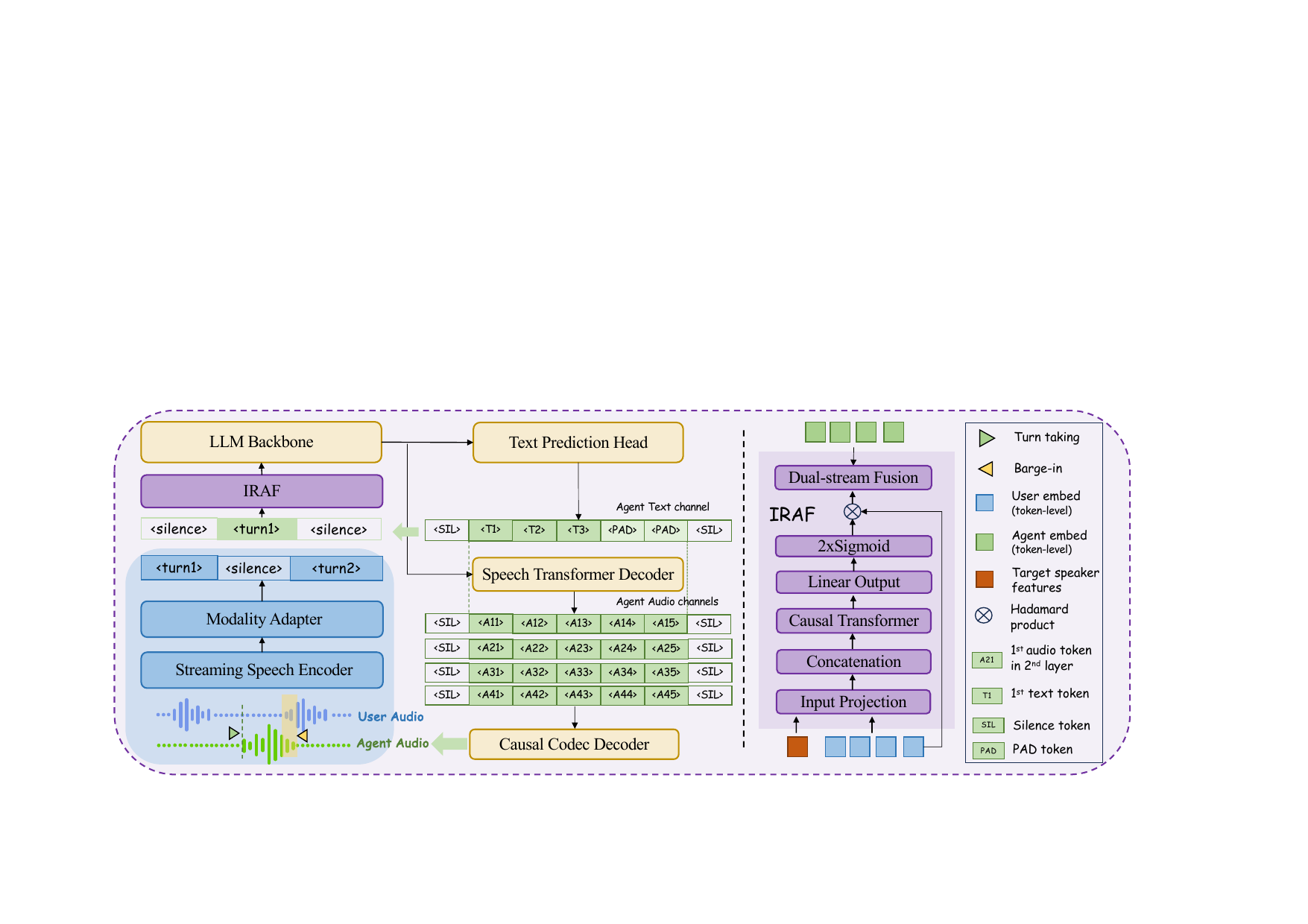
IRAF introduces an adaptive gating module to dynamically rescale user audio embeddings for noise-robust, real-time full-duplex spoken dialogue systems. This mitigates interference from overlapping speakers and noise, improving turn-taking and response quality without added latency.
Links
Paper & demos
Code & resources
Impact
Abstract
Full-duplex spoken dialogue models allow voice agents to listen and speak concurrently, enabling natural interaction with real-time overlap. However, end-to-end dual-channel models that jointly encode user and agent streams may degrade in realistic acoustic environments: interfering speakers leaking into the user microphone can be encoded as part of the user query, corrupting the LLM's conditioning and causing unstable turn-taking and reduced response quality. We propose Interference-Resilient Adaptive Fusion (IRAF), a lightweight, streaming-compatible module that modulates the contribution of user audio to the LLM frame by frame. IRAF predicts a scalar reliability gate from target-speaker and user audio embeddings and rescales user representations before fusion with agent embeddings. Experiments on MS-MARCO and InstructS2S-200K show consistent gains in response quality and full-duplex interaction under interfering-speaker conditions.
1. Problem Setting and Core Idea
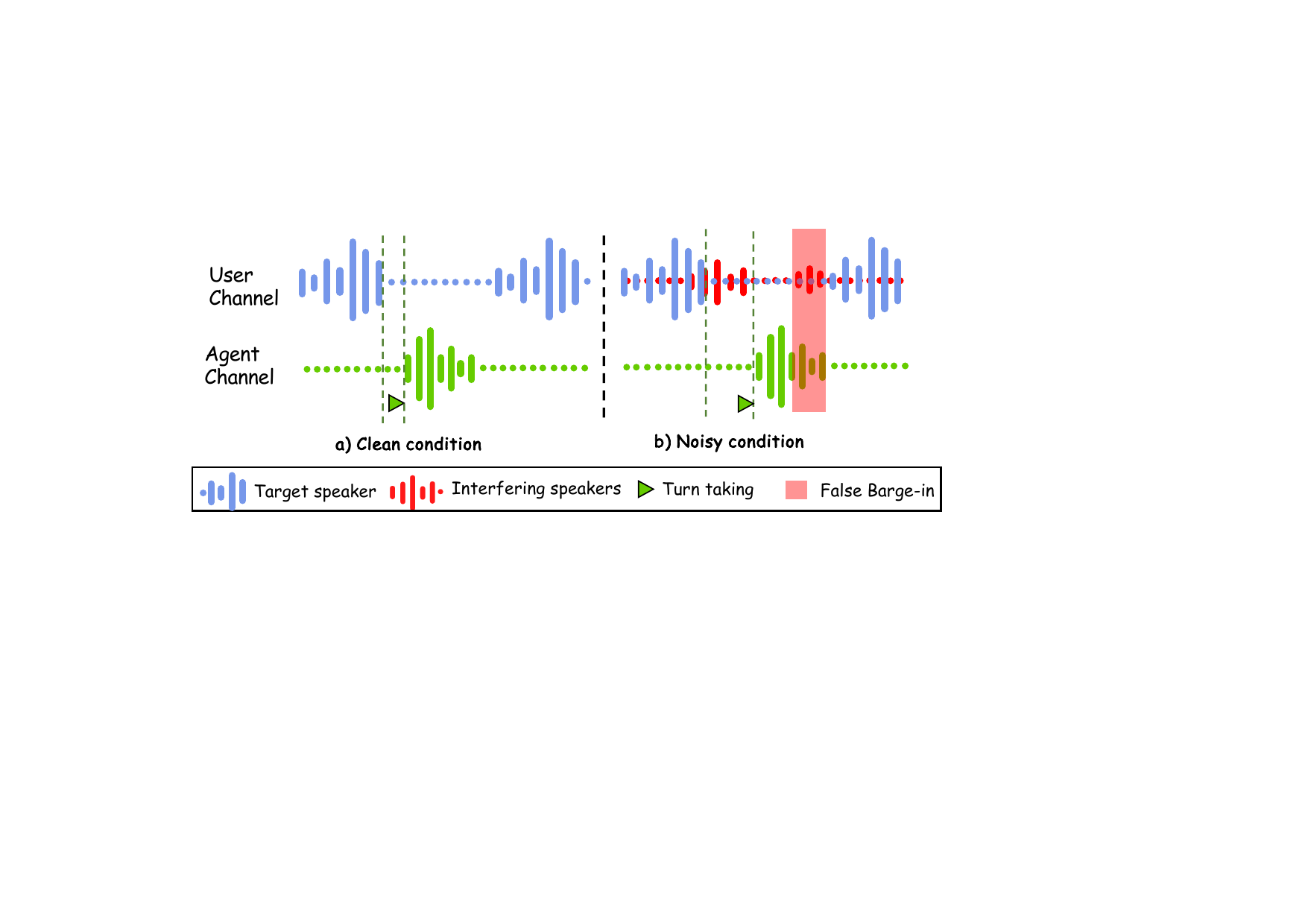
This paper addresses a specific failure mode in end-to-end full-duplex spoken dialogue systems: when the user microphone picks up interfering speech, an E2E dual-channel model may encode non-target speech as if it were part of the user query. In the authors' framing, this corrupts the conditioning context seen by the language model, which can destabilize turn-taking, produce false barge-in behavior, and reduce response quality. The problem is especially acute for full-duplex systems because they must operate causally and with low latency, while also handling overlap between user and agent speech in real time.
The proposed solution is Interference-Resilient Adaptive Fusion (IRAF), a lightweight, streaming-compatible module that predicts a frame-level reliability gate from target-speaker and user-audio embeddings. The gate rescales the user representation before it is fused with the agent-side text representation, so interference-dominated frames contribute less to the language model input while target-user frames are preserved.
2. Model Architecture
The overall system is a multi-stream E2E duplex model with a user speech stream and an agent text stream. The user audio is processed by a streaming speech encoder operating at 12.5 Hz, plus a modality adapter that converts the waveform into frame-level embeddings $X \in \mathbb{R}^{T \times D}$, where $T$ is the number of frames and $D$ is the embedding dimension. The agent-side input is represented as text embeddings $Y^{\mathrm{txt}} \in \mathbb{R}^{T \times D}$.
The paper follows a duplex design in which the fused representation is consumed by an LLM backbone, while a separate autoregressive speech transformer decoder predicts the agent's speech tokens $Y^a$ conditioned on the LLM hidden states $h$. The speech decoder is described as a 12-layer causal Transformer following the T5 architecture. The text tokenizer is SentencePiece with a 32k vocabulary. The authors also state that agent speech tokens are extracted with NanoCodec at 12.5 Hz using finite scalar quantization.
In the baseline duplex fusion, the user audio and agent text embeddings are directly combined. IRAF replaces this static treatment with a learned, time-varying reliability estimate. At each frame $t$, the model concatenates a target-speaker embedding $s \in \mathbb{R}^n$ with the current and past user audio embeddings $X_{\le t}$ and passes the result through a small transformer-based fusion module $f(\cdot \mid \psi)$. The module is described as having three parts: an input projection layer that maps speaker and audio features into a shared space, a causal Transformer layer that aggregates streaming context, and a linear output head that produces the reliability gate.
The gate is defined as
$$g_t = 2 \times \operatorname{Sigmoid}(f(s, X_{\le t} \mid \psi)) \in [0,2].$$
This gate rescales the user audio embedding before fusion with the agent text embedding, yielding the fused input $g_t X_t + Y_t^{\mathrm{txt}}$ for the LLM. The range $[0,2]$ allows the module to both suppress and amplify the user stream relative to the direct-sum baseline.
3. Training Objective and Supervision
The paper formulates training as a multi-channel next-token prediction objective. Let $Y^{\mathrm{txt}}$ denote the agent text tokens and $Y^a$ the agent speech tokens. The losses are weighted cross-entropies for the text decoder and the speech decoder:
$$
\mathcal{L}(Y^{\mathrm{txt}}, Y^a \mid X, \theta, \phi)
= - \sum_{t=1}^{T} \Big[ \lambda_1 \log p_{\theta}(Y_t^{\mathrm{txt}} \mid Y_{
The weights are set to $\lambda_1 = 1.0$ for text and $\lambda_2 = 5.0$ for speech. IRAF is trained jointly with the full duplex model, and it receives an auxiliary binary supervision signal derived from clean training utterances: frame labels are $1$ when the target speaker is active and $0$ otherwise. This auxiliary task is weighted by $0.1$.
The paper emphasizes that IRAF is lightweight and streaming-compatible, so it preserves the end-to-end formulation without adding extra response latency.
Two datasets are used to evaluate the method. The first is single-turn MS MARCO, a large-scale QA benchmark with anonymized Bing queries and human-written answers. For spoken QA, the authors synthesize speech for the question-answer pairs using CosyVoice2. The second is multi-turn InstructS2S-200K, a speech-to-speech dialogue dataset with approximately 200,000 conversation sessions covering common-sense and general world-knowledge interactions.
To convert the data into duplex training examples, each conversation is turned into two synchronized streams: user and agent. When one party speaks, the other channel is filled with silence, yielding non-overlapping duplex signals. A fixed inter-turn pause of 0.64 s is inserted between the user's utterance and the agent's response.
For user interruption modeling, the authors shorten the inter-turn gap so the next user utterance overlaps with the agent's ongoing speech. Once interruption starts, the remaining agent speech is truncated and replaced with silence after a fixed latency of 0.64 s. During training, barge-in events are injected stochastically with probability $0.5$ per turn.
To approximate real-world noisy full-duplex conditions, the paper also constructs interference-augmented data using MUSAN. MUSAN speech is used as interfering speakers, and MUSAN noise is used as background noise. The speech and noise corpora are partitioned into three non-overlapping splits for train, validation, and test. For MS MARCO, the interfering SNR is sampled uniformly from 0 to 10 dB; for InstructS2S-200K, the SNR range is 0 to 20 dB.
The paper evaluates two acoustic settings: (1) interfering speakers only, and (2) interfering speakers plus background noise.
The implementation uses the NeMo Toolkit. The speech encoder is a 100M-parameter streaming pretrained encoder with 80 ms right context. The LLM backbone is initialized from TinyLlama with 1.1B parameters. The speech representation uses NanoCodec at 0.6 kbps by default, producing four code channels with vocabulary size 4,037 each. The speech decoder is a 12-layer causal Transformer, and the user-target identity embedding is extracted with a pretrained ECAPA-TDNN. For simplicity, speakers from different conversations are treated as distinct identities.
The IRAF fusion module itself uses only a single Transformer layer. Training uses AdamW with cosine-annealing learning rate scheduling, peak learning rate $3 \times 10^{-4}$, 2,500 warm-up steps, and gradient clipping with maximum norm 1.0. The dataset split ratio is 0.945 / 0.005 / 0.05 for train / validation / test. MS MARCO uses per-GPU batch size 1 with gradient accumulation of 8. InstructS2S-200K uses duration-based bucketing with 60 s batch duration and gradient accumulation of 4 per GPU.
The paper evaluates two complementary aspects of duplex behavior: response quality and full-duplex interaction.
Table 1 reports results on MS MARCO under MUSAN speech interference. The main takeaway is that clean-only training is fragile, noise augmentation helps substantially, and IRAF adds another consistent gain across both interference conditions.
Under interfering speakers only, the clean baseline collapses to 0.66 BLEU, 0.11 sBERT, 1.46 s RL, and 6.2% RSR. Noise augmentation recovers most of the lost performance, reaching 12.74 BLEU, 0.506 sBERT, 0.97 s RL, and 93.1% RSR. IRAF improves further to 14.20 BLEU, 0.523 sBERT, 0.96 s RL, and 95.7% RSR.
The same pattern holds when both interfering speakers and background noise are present. The clean baseline is nearly unusable on this setting, while NoisyAug reaches 11.33 BLEU, 0.454 sBERT, 0.98 s RL, and 88.2% RSR. IRAF improves this to 12.01 BLEU, 0.476 sBERT, 0.94 s RL, and 92.5% RSR.
The authors summarize the effect of IRAF on MS MARCO as a consistent improvement over NoisyAug in both response quality and interaction reliability, with the strongest absolute gains appearing in the response success rate and the semantic/lexical metrics.
Table 2 evaluates the method on the multi-turn InstructS2S-200K benchmark, which is a harder setting because it stresses both long-horizon response quality and interaction control, including explicit barge-ins.
The reported deltas over NoisyAug show that IRAF is particularly beneficial in the multi-turn setting. Under interfering speakers only, it improves BLEU by +4.12, sBERT by +0.11, reduces RL by 0.15 s, raises RSR by 21.8 percentage points, and slightly lowers stop latency by 0.01 s while increasing SSR to 99.8%. Under both interference and background noise, it improves BLEU by +1.51, sBERT by +0.03, reduces RL by 0.07 s, and raises RSR by 13.2 percentage points, while maintaining near-ceiling barge-in performance.
Importantly, the barge-in metrics are already high for NoisyAug in the test setting, so the main value of IRAF in InstructS2S-200K is not merely improved stopping, but substantially better response quality and turn-taking reliability in the presence of interference.
The paper also reports an SNR study on InstructS2S-200K, showing that IRAF improves both BLEU and response success rate across all tested SNRs. The authors use this figure to argue that the method is not tuned to a narrow acoustic regime, but remains effective as interference severity changes.
The key conceptual contribution is that the model does not treat every frame of user audio as equally reliable. Instead, it uses target-speaker information to estimate whether the current acoustic evidence is likely to come from the intended user. This matters in the duplex setting because the user channel can be contaminated by other speakers, and naive fusion would pass those corrupted frames straight into the LLM.
In effect, IRAF is a learned, causal, per-frame confidence estimator for the user stream. Because the gate is produced with a small transformer module and applied before fusion, the approach is compatible with streaming and avoids the cost and latency of explicit source separation. The paper positions this as especially useful in realistic conversational environments where overlap is irregular, interference is non-stationary, and the system must decide quickly whether to continue listening, respond, or stop speaking.
The paper's empirical comparison is centered on three configurations: CleanBase, NoisyAug, and IRAF. In that sense, the reported ablation is at the system level rather than a component-by-component dissection of the gating module. The source text does not report finer-grained ablations such as removing the speaker embedding, changing the gate range, or replacing the causal Transformer inside IRAF with a simpler predictor.
The evaluation is also bounded by the paper's simulation setup. All noisy conditions are synthetic mixtures based on MS MARCO and InstructS2S-200K with MUSAN speech/noise, and the multi-turn interruption setup uses a fixed 0.64 s truncation/latency rule. Speakers from different conversations are treated as distinct identities. These choices make the experiments controlled and reproducible, but they also mean the paper does not yet demonstrate performance on fully unconstrained live microphone recordings.
A further scope limitation is that the paper does not present a detailed runtime or memory benchmark, even though it claims streaming compatibility and low latency. The evidence for efficiency is therefore architectural rather than measured in a dedicated speed table.
IRAF is a simple but well-targeted modification to duplex spoken dialogue models: it learns when the user stream should be trusted and when it should be suppressed before fusion with the agent-side context. Across both MS MARCO and InstructS2S-200K, and across both interference conditions tested, the method consistently improves response quality and turn-taking behavior over a strong noise-augmented baseline. The results suggest that frame-level reliability gating is an effective strategy for making end-to-end full-duplex spoken dialogue systems more robust in realistic multi-speaker acoustics.
4. Dataset Construction and Noise/Interference Simulation
5. Implementation Details
6. Evaluation Protocol and Metrics
7. Main Results on MS MARCO
Method
Noisy Source
BLEU
sBERT
RL (s)
RSR
Interfering speakers only CleanBase ALL 0.66 0.11 1.46 6.2% NoisyAug LIBRI 12.69 0.503 0.98 91.0% NoisyAug US-GOV 13.30 0.512 0.96 94.1% NoisyAug ALL 12.74 0.506 0.97 93.1% IRAF LIBRI 13.81 0.516 0.97 95.4% IRAF US-GOV 14.38 0.536 0.94 98.2% IRAF ALL 14.20 0.523 0.96 95.7% Both interfering speakers and background noise CleanBase ALL 0.00 0.03 1.49 2.8% NoisyAug LIBRI 11.12 0.445 0.98 87.1% NoisyAug US-GOV 11.53 0.465 0.96 91.3% NoisyAug ALL 11.33 0.454 0.98 88.2% IRAF LIBRI 11.64 0.472 0.94 91.2% IRAF US-GOV 12.34 0.486 0.93 92.8% IRAF ALL 12.01 0.476 0.94 92.5% 8. Main Results on InstructS2S-200K
Method
BLEU
sBERT
RL (s)
RSR
SL (s)
SSR
Interfering speakers only CleanBase 1.13 0.22 1.39 13.9% 1.29 42.7% NoisyAug 9.64 0.47 0.97 69.2% 0.74 99.0% IRAF 13.76 0.58 0.82 91.0% 0.73 99.8% Both interfering speakers and background noise CleanBase 0.91 0.21 1.41 9.8% 1.34 40.2% NoisyAug 8.32 0.44 1.05 56.0% 0.74 99.6% IRAF 9.83 0.47 0.98 69.2% 0.73 100.0% 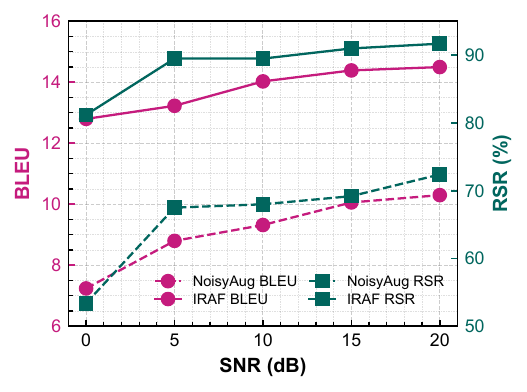
9. Interpretation of the Method
10. Stated Contributions and Novelty
11. Scope, Ablations, and Limitations Reflected by the Paper
12. Bottom Line