RigPAPR
RigPAPR: Rig-Based Animation of Static Neural Point Clouds from a Fixed-Viewpoint Video

RigPAPR animates static neural point clouds to follow a fixed-viewpoint monocular video, recovering a rigged 3D asset. It avoids joint-boundary artifacts by using a shape-free proximity-attention renderer that naturally reforms surfaces under articulation, unlike prior Gaussian splat or mesh-based approaches.
Links
Paper & demos
Abstract
Static neural point reconstructions capture a subject at high fidelity from posed images. Given such a reconstruction, we aim to animate it to follow a monocular fixed-viewpoint driving video of the subject, whether captured or produced by image-to-video (I2V) generation, and to recover a rigged, re-posable 3D asset. Existing methods deform Gaussian splats through direct linear blend skinning (LBS) or mesh proxies, both of which are prone to joint-boundary artifacts under articulation, even with per-primitive corrections. We trace the artifact to the representation: each splat carries an individual shape calibrated in the canonical pose to tile with its neighbours. Under rigid LBS, each splat moves with its bone but cannot bend, so the canonical tiling breaks at joint boundaries into gaps and spikes. Proximity attention point rendering (PAPR) instead carries no per-primitive shape; each pixel is recomposed at render time from the deformed primitives' positions, so the surface re-forms naturally with the articulation. We present RigPAPR, which auto-rigs a static PAPR cloud and drives it under direct LBS from a single fixed-viewpoint video, without mesh proxy, pose-dependent correction, or category template. On synthetic subjects, RigPAPR matches the strongest baseline at the supervised view and exceeds mesh-based and Gaussian-splatting baselines at novel views by 3+dB PSNR, with cleaner joint-boundary renderings of both synthetic and real subjects.
Problem Setting and Core Idea
RigPAPR addresses a specific animation-and-reconstruction problem: given a static neural point cloud reconstructed from posed images, recover a skeleton-rigged, re-posable 3D asset that can follow a single fixed-viewpoint monocular driving video of the subject. The driving video may be a real capture or a video synthesized by image-to-video (I2V) generation. The output should still render from novel viewpoints and remain editable as a skeletal asset.
The paper argues that existing neural-point rigging pipelines fail for a representation-level reason. Gaussian splats encode local shape inside each primitive via a per-primitive covariance, so when direct linear blend skinning (LBS) moves each primitive rigidly with a bone, the canonical tiling between adjacent splats breaks at joint boundaries, producing gaps and spikes. Mesh-proxy methods reduce some symptoms but still inherit the same mismatch because the local primitive shape was calibrated in the canonical pose. RigPAPR instead uses proximity attention point rendering (PAPR), where primitives have no fixed per-primitive shape; rendered pixels are recomposed from the current neighborhood of deformed points, so the surface can re-form under articulation.
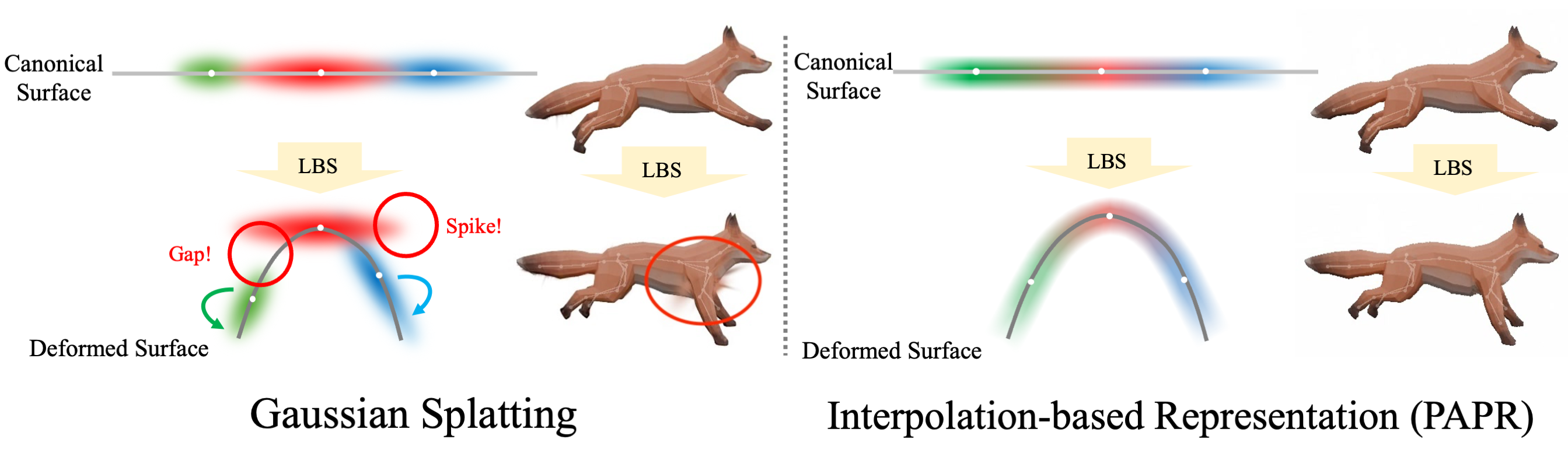
Representation Background: Why PAPR Is a Better Fit for Rigging
PAPR represents a scene as a set of points with positions and view-independent features. Rendering does not rely on a mesh or explicit connectivity. For each camera ray, PAPR selects the top-$K$ nearest points and aggregates them with a proximity-attention mechanism, so the pixel color is formed from the local spatial configuration at render time. This means that when LBS changes point positions, the renderer automatically recomputes the local support and can continue to produce a coherent surface-like image.
The paper emphasizes two consequences. First, because the renderer uses the same indexed point set before and after deformation, there is no connectivity graph for LBS to tear apart. Second, the attention weights renormalize over the current top-$K$ neighborhood, so gradients can still flow even when points move far from their canonical arrangement. That property becomes important when the method fine-tunes the point cloud and the rig under a single-view driving sequence.
Method Overview
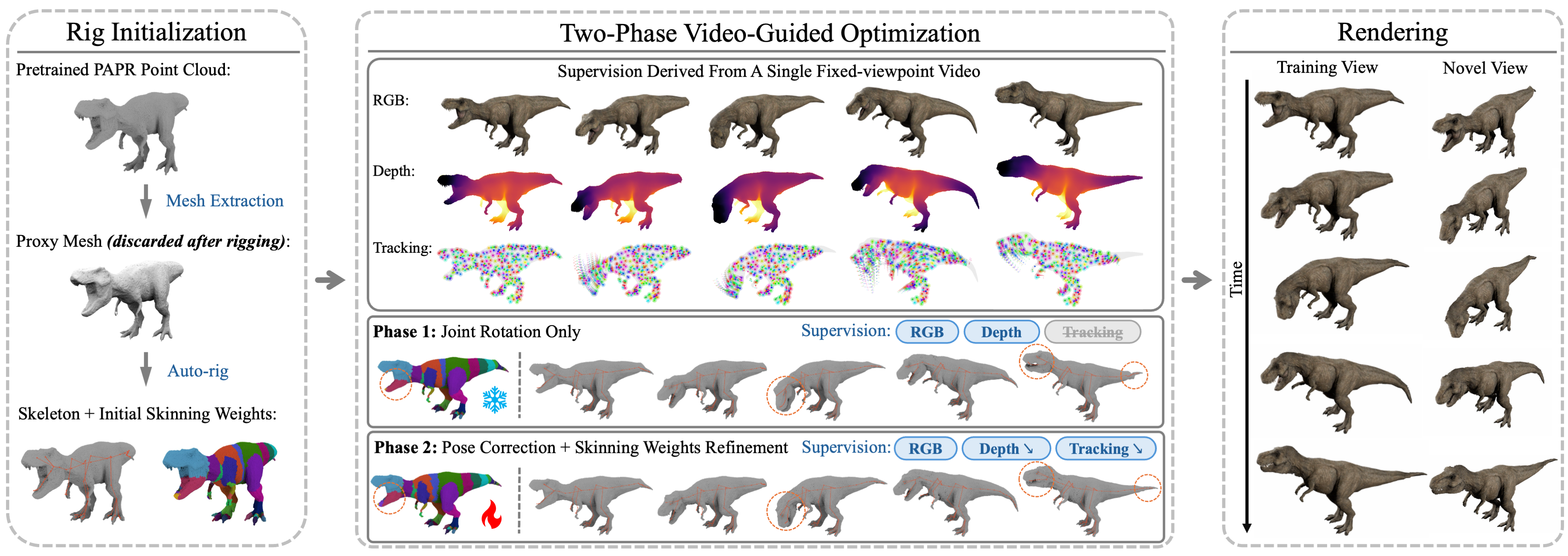
RigPAPR starts from a pre-trained PAPR cloud and a monocular fixed-viewpoint driving video. It first auto-rigs the point cloud using a transient mesh proxy, then deforms the points directly with LBS, and finally refines the motion and skinning using a two-phase optimization guided by video-based priors. The mesh proxy is used only for initialization and is discarded once the skeleton and weights are obtained.
Scene, skeleton, and pose variables
The paper writes the canonical PAPR scene as $N$ points $\{(\mathbf{p}_i, \mathbf{u}_i, \tau_i)\}_{i=1}^N$, where $\mathbf{p}_i \in \mathbb{R}^3$ is position, $\mathbf{u}_i \in \mathbb{R}^d$ is a view-independent feature, and $\tau_i$ is an influence score. The skeleton has $B$ bones, and each point carries skinning weights $\mathbf{w}_i \in \mathbb{R}^B$. A pose at time $t$ consists of one axis-angle rotation per bone and a global root translation $\mathbf{t}^t$.
Under direct LBS, the deformed point position is
$$\mathbf{p}_i^t = \mathbf{t}^t + \sum_{b=1}^B w_{i,b}\, \mathbf{T}_b(\mathbf{R}^t)\, \mathbf{p}_i^0,$$
where $\mathbf{p}_i^0$ is the canonical point position and $\mathbf{T}_b(\mathbf{R}^t)$ is the bone-to-world transform at frame $t$ composed with the bind-pose inverse so that the canonical configuration is fixed. Only positions are deformed; the features and influence scores travel rigidly with each point, and the frozen PAPR renderer recomposes the image from the deformed neighborhood at render time.
Auto-rigging initialization
The initial rig is obtained in two steps. First, the trained PAPR cloud is meshed with OffsetOPT to produce a triangle proxy. Second, Puppeteer auto-rigs that proxy and returns a skeleton with $B$ bones plus per-vertex skinning weights. Those vertex weights are transferred back to PAPR points by $k$-nearest-neighbour inverse-distance weighting with $k=6$. The proxy exists only for initialization and is removed afterward.
The implementation uses a U-Net-free PAPR variant, with a fully point-based proximity-attention renderer and no image-space decoder. The renderer is frozen for all downstream optimization in the paper.
Two-Phase Video-Guided Optimization
The driving sequence is single-view and therefore under-constrained: depth and articulation can explain the same 2D residual. RigPAPR resolves this ambiguity by using monocular depth and 2D tracking as temporary scaffolding, then fading those priors out so the final fit is not locked to their biases.
Phase 1: depth-supervised joint-motion initialization
Phase 1 freezes the skinning weights and optimizes the per-frame joint rotations and root translations. The frames are fit sequentially from the binding frame, warm-starting each frame from the previous one. The loss combines image reconstruction, a relative-depth term, and a descendant-weighted rotation regularizer.
The image reconstruction loss is
$$\mathcal{L}_{\text{rgb}} = 0.8\,\mathrm{L1} + 0.2\,(1-\mathrm{SSIM}),$$
with an additional LPIPS term weighted by $0.01$.
The depth supervision uses Depth Anything 3 in metric-depth mode. Because the raw depth scale is not in PAPR units, the method computes a closed-form per-frame scale on a random subsample of $4096$ canonical points, keeps that scale fixed during backpropagation, and penalizes the calibrated relative-depth residual. Only points in front of the camera, inside both frames, and inside the foreground mask are used.
The paper also uses a descendant-weighted regularizer to keep higher-level bones quieter than leaf bones. If $n_{\text{desc}}(b)$ is the number of descendants of bone $b$, then
$$\alpha_b = \frac{1+n_{\text{desc}}(b)}{\overline{1+n_{\text{desc}}(\cdot)}}.$$
Phase 1 then penalizes joint rotation magnitude with
$$\mathcal{L}_{\text{rot}}^{(1)} = \frac{1}{B}\sum_{b=1}^B \alpha_b\,\|\boldsymbol{\omega}_b^t\|_2^2.$$
Phase 2: correction MLP, weight refinement, and video tracking
Phase 2 freezes the Phase 1 joint trajectories and introduces two additional learnable components: a small temporal MLP that predicts per-joint axis-angle corrections, and the skinning-weight logits that define the active weights through a softmax. In contrast to Gaussian-splat methods that use per-primitive correction heads, the corrections here operate at the joint level.
The correction network takes a positional encoding of the normalized frame index $t/T$ with sine and cosine bands from frequency exponents $0$ through $10$, producing a $23$-dimensional input. It has two hidden layers of width $128$, ReLU activations, and a linear output head that emits $3B$ values. The output layer is zero-initialized so the correction starts at zero.
Skinning weights are stored as unconstrained per-point logits $\mathbf{l}_i$ and mapped to active weights by
$$\mathbf{w}_i = \operatorname{softmax}(\mathbf{l}_i).$$
Phase 2 adds a CoTracker 3 loss, an as-rigid-as-possible distance-preservation term over each point's canonical $k$-nearest neighbors, and regularizers on the corrections and weights. Both the depth loss and the tracking loss decay to zero during Phase 2, so the final refinement is still governed by rendering quality.
The Phase 2 skinning refinement uses two extra regularizers: a smoothness term on the canonical $k$-NN graph, and an entropy-style sparsity term that encourages each point to depend on fewer bones. The paper also regularizes the composed bone rotations with a Frobenius-norm penalty on the deviation from identity.
The skin-weight smoothness term is
$$\mathcal{L}_{\text{smooth}} = \frac{1}{Nk}\sum_{i=1}^{N}\sum_{j\in\mathcal{N}(i)} \|\mathbf{w}_i-\mathbf{w}_j\|_1.$$
The Phase 2 rotation regularizer is applied to the composition of the Phase 1 rotation and the correction rotation:
$$\mathcal{L}_{\text{rot}}^{(2)} = \frac{1}{TB}\sum_{t=1}^{T}\sum_{b=1}^{B} \alpha_b\,\|\mathbf{R}_b^t\mathbf{R}_b^{(c,t)}-\mathbf{I}\|_F^2.$$
Practical schedules and optimization details
- Phase 1 uses Adam with cosine annealing from $5\times 10^{-3}$ to $1\times 10^{-4}$.
- Phase 2 uses Adam with separate learning rates: $3\times 10^{-4}$ for the correction MLP and $1\times 10^{-2}$ for the skinning logits, annealed to $1\times 10^{-5}$ over $30{,}000$ iterations.
- Phase 1 fits each frame for $2{,}000$ iterations and proceeds sequentially from the binding frame.
- All optimization runs on a single NVIDIA RTX 3090 GPU; for a $16$-frame sequence, Phase 1 takes about one hour and Phase 2 about one hour.
Attention-guided track seeding
Instead of naively projecting every canonical point and using that pixel for tracking, RigPAPR seeds CoTracker from the renderer's own attention. The canonical image is run through PAPR, and for each foreground pixel the top-$K$ attention weights are examined. The method keeps the dominant point for each pixel only when its top-1 attention is at least $0.05$, discards low-confidence points, deduplicates the result, and uses the corresponding pixel locations as the 2D tracking queries. This reduces label noise because the tracked point is one that the renderer actually relies on at the canonical view.
Experimental Setup
The paper compares RigPAPR against one baseline from each of the two representational families it contrasts with: Puppeteer as the mesh-based animation baseline, and a modified Mani-GS as the Gaussian-splatting baseline. The Mani-GS baseline is strengthened with three changes: per-triangle adaptive scaling is disabled, binding rotations and offsets are further fine-tuned in Phase 2, and a foreground-mask loss is added.
The synthetic evaluation uses five Objaverse subjects spanning three morphologies: T-Rex and Simpsons as bipeds, fox and wolf as quadrupeds, and spider as an octopod. Each synthetic scene is rendered as a fixed-viewpoint $512\times 512$ video. For Mani-GS and RigPAPR, the static scene is first pretrained using multi-view reconstruction from a ring of cameras around the subject. Puppeteer receives the ground-truth mesh and texture directly.
The real-world evaluation uses two captured subjects, robot and statue, at $960\times 540$. For those scenes, only Mani-GS and RigPAPR are run. The driving video for each real scene is generated from the canonical frame using Kling 3.0, so the reported training-view metrics are against the generated reference. Sequence lengths range from 16 to 40 frames.
Quantitative Results
The key quantitative result is that RigPAPR matches or slightly exceeds the strongest baseline at the supervised view, but substantially improves held-out novel views. The paper reports PSNR, SSIM, and LPIPS on training-view and, for synthetic scenes, novel-view cameras.
| Method | Synthetic Training View | Synthetic Novel View | Real-World Training View | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| Puppeteer | 22.48 | 0.941 | 0.044 | 19.27 | 0.923 | 0.075 | --- | --- | --- |
| Mani-GS | 28.53 | 0.974 | 0.026 | 20.51 | 0.927 | 0.072 | 25.68 | 0.955 | 0.049 |
| Ours | 29.07 | 0.972 | 0.027 | 23.63 | 0.945 | 0.044 | 25.82 | 0.944 | 0.063 |
On the synthetic training view, RigPAPR achieves the best PSNR and is close to Mani-GS on SSIM and LPIPS. On synthetic novel views, RigPAPR is clearly strongest across all three metrics, with a roughly $3$ dB PSNR margin over Mani-GS. On the real-world training view, RigPAPR slightly exceeds Mani-GS in PSNR but trails it in SSIM and LPIPS. The important qualitative point is that the novel-view gain persists even when the supervised-view performance is similar.
Qualitative comparison on synthetic and real subjects
Across the synthetic objects, Mani-GS shows the joint-boundary spikes that the paper attributes to per-splat covariance tiling breaking under articulation. Puppeteer often places joints or body parts incorrectly and does not always reproduce the observed motion faithfully. RigPAPR produces cleaner boundaries and better preserves the articulation sequence. The paper notes that regions that remain occluded in the fixed training view may still be less accurate, because the single-view priors do not observe them directly.

On the real-world robot and statue captures, Mani-GS again tends to show spiky limb or lower-body artifacts in the novel view, while RigPAPR remains cleaner. The paper also reports a novel-pose driving experiment on the robot subject, where both methods are driven by two pose sequences not seen during fitting. RigPAPR generalizes better off-trajectory, while Mani-GS exhibits visible limb artifacts.

Ablations and Diagnostic Experiments
The ablations focus on three questions: how much the two-phase optimization matters, whether depth supervision is useful in Phase 1, and whether the representation itself is responsible for the boundary artifacts even when geometry and skinning are oracle-perfect.
Two-phase optimization ablation
The main ablation compares Phase 1 alone against the full method on the synthetic scenes. The overall trend is that Phase 2 improves the training view for both RigPAPR and Mani-GS, but the novel-view gain is much more important for RigPAPR. RigPAPR Phase 1 already outperforms Mani-GS on novel view, and the full method remains the best overall on training view while staying strong on novel view.
| Configuration | Training View | Novel View | ||||
|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| Mani-GS (Phase 1) | 26.71 | 0.962 | 0.037 | 20.14 | 0.925 | 0.073 |
| Mani-GS (Full) | 28.53 | 0.974 | 0.026 | 20.51 | 0.927 | 0.072 |
| Ours (Phase 1) | 28.13 | 0.965 | 0.029 | 23.84 | 0.947 | 0.043 |
| Ours (Full) | 29.07 | 0.972 | 0.027 | 23.63 | 0.945 | 0.044 |
For RigPAPR, Phase 2 improves the training-view metrics by about $0.9$ dB PSNR, but slightly lowers novel-view PSNR by about $0.2$ dB, which the authors interpret as mild overfitting to the supervised view. The resulting asset still renders cleanly from novel viewpoints. For Mani-GS, Phase 2 improves the training view more strongly, but the novel-view gap relative to RigPAPR remains.

| Configuration | Training PSNR | Training SSIM | Training LPIPS | Novel PSNR | Novel SSIM | Novel LPIPS | Chamfer ($\times 10^{-3}$) |
|---|---|---|---|---|---|---|---|
| Phase 1 without relative depth | 29.21 | 0.953 | 0.034 | 21.38 | 0.934 | 0.045 | 15.64 |
| Phase 1 | 27.72 | 0.945 | 0.035 | 24.05 | 0.942 | 0.039 | 5.68 |
| Full | 31.08 | 0.972 | 0.025 | 23.95 | 0.945 | 0.034 | 4.60 |
On T-Rex, removing relative depth from Phase 1 improves the training view but causes the rotation trajectory to drift off the physically plausible solution, especially at the head. Relative-depth supervision restores 3D plausibility and sharply improves chamfer distance to the ground-truth mesh. Phase 2 then refines the skinning weights and joint corrections, giving the best training-view PSNR and the best geometry match overall.
Mani-GS adaptive-scaling ablation
The paper also shows that Mani-GS's per-triangle adaptive scaling is itself a major artifact source. When enabled, thin or near-degenerate triangles cause splat covariances to blow up under articulation. Phase 2 rotation refinement reduces but does not eliminate the resulting spikes. This is why the main paper reports Mani-GS with adaptive scaling disabled: that setting is materially stronger.

Oracle mesh-deformation ablation
To isolate the rendering representation from geometry and skinning quality, the paper drives all methods from the same ground-truth mesh sequence. In this setting, the geometry and poses are no longer the source of error: the baselines and RigPAPR all receive identical oracle articulation. The result is decisive: both mesh-bound splat baselines still show joint-boundary tiling artifacts at the deformed frame, while RigPAPR does not. This supports the paper's central claim that the artifact is representation-inherent rather than a consequence of imperfect rigs or geometry.

Interpretation of the Main Findings
The strongest evidence in the paper is not just that RigPAPR improves a benchmark number or two, but that it fixes a specific failure mode that remains even under oracle deformation. The ablations show that depth priors matter early, tracking helps in Phase 2, and the auto-rig is valuable, but the key robustness gain comes from pairing LBS with a covariance-free interpolation-based representation. In other words, the method does not rely on patching per-splat artifacts after the fact; it changes the underlying primitive so that the rendering process is inherently compatible with articulated motion.
The paper also makes a practical point relevant to talking-head or conversational-AI pipelines: a fixed-viewpoint driving video is exactly the kind of motion source that I2I/I2V systems produce most directly, so the method is aligned with content that may be available without multi-camera capture. At the same time, the output is a re-posable rigged asset, which is useful for animation and re-targeting, not just video replay.
Limitations
The limitations are straightforward and important. First, the method inherits the failure modes of its 2D scaffolding: Phase 1 depends on monocular depth, and Phase 2 depends on 2D tracking. If those priors are wrong, the error propagates into the recovered articulation, and the single fixed view does not provide enough constraints to correct it. Second, the auto-rigging stage is load-bearing; if the inferred skeleton or initial skinning is poor, later optimization can only partially recover, especially on shapes outside the auto-rigger's comfort zone. Third, regions occluded in the binding frame receive no appearance supervision during canonical pretraining, so when articulation later reveals them they may appear as holes or stray colors rather than coherent surface detail.
The broader-impact discussion also notes a social risk: the same pipeline that can turn a capture into a rigged asset could be misused to re-animate real people without consent. The authors recommend consent-aware capture practices, provenance tags, and downstream detection if such systems are deployed on human subjects.
Conclusion
RigPAPR's main contribution is to connect articulated animation with a representation whose primitives do not carry fixed per-primitive shape. By auto-rigging a static PAPR cloud and animating it directly from a fixed-viewpoint driving video, the method recovers a re-posable 3D asset that renders cleanly under articulation and generalizes better to novel viewpoints than the Gaussian-splat and mesh-based baselines reported in the paper.