VoxCPM2
VoxCPM2 Technical Report

VoxCPM2 is a 2B-parameter multilingual text-to-speech foundation model unifying voice design, zero-shot cloning, and high-fidelity super-resolution. It uses continuous-latent modeling for controllable and scalable speech generation without external discrete tokenizers.
Demos
VoxCPM2 demos show natural, expressive 48kHz TTS in 30 languages without language tags. Evaluate cross-lingual voice transfer, voice design from text, and style-controlled voice cloning with timbre preservation. These demos reflect the model's diffusion-based approach and large multilingual data training for studio-quality speech synthesis.

Links
Paper & demos
Code & resources
Abstract
We present VoxCPM2, a https://info.arxiv.org/help/prep#abstractsfully open-source multilingual and controllable speech generation foundation model that extends the hierarchical diffusion-autoregressive modeling paradigm of VoxCPM. VoxCPM2 advances the framework in three key dimensions: (i) capability, by unifying 30 languages, 9 Chinese dialects, natural-language voice design, style-controllable voice cloning, and high-fidelity continuation cloning within a single backbone; (ii) quality, through an asymmetric AudioVAE that encodes at 16 kHz and reconstructs at 48 kHz, enabling implicit super-resolution with high encoding efficiency; and (iii) scale, by jointly scaling the model to 2B parameters and the training data to over 2 million hours of multilingual speech. To support these diverse capabilities within one model, we introduce a unified sequence organization that expresses all generation modes through different arrangements of the same input building blocks, allowing joint training under a single set of parameters and objective. VoxCPM2 achieves state-of-the-art or competitive performance on public zero-shot and instruction-following TTS benchmarks. On our internal 30-language evaluation set, it attains an average WER of 1.68%. These results demonstrate that hierarchical continuous-latent modeling, without relying on any external discrete speech tokenizer, offers a viable and powerful foundation for large-scale multilingual and controllable speech generation. The model weights, fine-tuning code, and inference tools are publicly released under the Apache 2.0 license to foster community research and development.
Introduction
VoxCPM2 is a 2B-parameter multilingual and controllable text-to-speech foundation model that extends the hierarchical diffusion-autoregressive design of VoxCPM into a larger, more capable, and more practical system. The paper’s central claim is that a fully end-to-end continuous-latent approach can scale to broad multilingual coverage and rich controllability without relying on an external discrete speech tokenizer. VoxCPM2 is positioned as a single backbone that supports basic TTS, natural-language voice design, reference-based voice cloning, controllable cloning, and continuation cloning.
The motivation is straightforward: token-based TTS pipelines have benefited from large-language-model scaling, but quantization discards acoustic detail and often pushes high-quality systems toward multi-stage architectures that separate semantic planning from acoustic reconstruction. By contrast, continuous-latent methods preserve richer signal detail, but are harder to optimize because semantic structure and local acoustic texture must be modeled jointly. VoxCPM2 retains the hierarchical decomposition of VoxCPM while scaling it to 30 languages, 9 Chinese dialects, and more than 2 million hours of training speech.
The report emphasizes three main advances:
- Capability: one backbone covers multilingual synthesis, zero-shot cloning, style-controllable voice cloning, and natural-language voice design.
- Quality: a new asymmetric AudioVAE encodes 16 kHz audio and reconstructs at 48 kHz, so the model can generate higher-fidelity waveforms without increasing the autoregressive sequence length.
- Scale: the system grows to 2B parameters and is trained on over 2 million hours of multilingual speech.
Overall Architecture
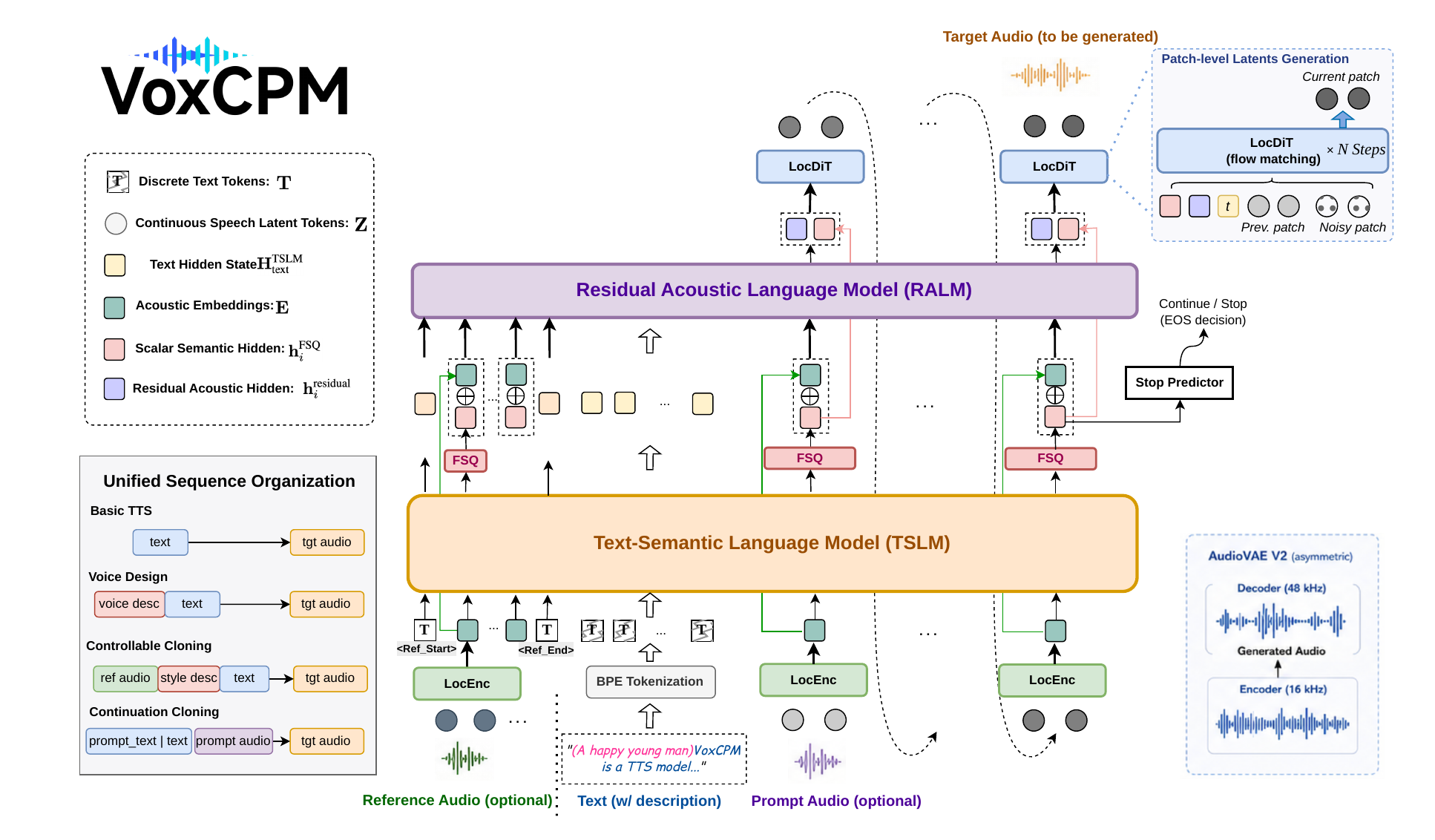
The model operates entirely on continuous audio latents produced by AudioVAE V2. The encoder maps 16 kHz waveforms to 64-dimensional latent frames at 25 Hz. The backbone groups every $P=4$ frames into one patch, yielding an autoregressive rate of 6.25 Hz, where each step corresponds to 160 ms of audio. This compact sequence length is important for long-form stability and efficient inference.
The autoregressive backbone has four main parts:
- Local Encoder (LocEnc) to summarize previous latent patches into acoustic history.
- Text-Semantic Language Model (TSLM) to model text, prompts, and high-level semantic or style instructions.
- Residual Acoustic Language Model (RALM) to refine fine-grained acoustic details from the semantic skeleton and audio history.
- Local Diffusion Transformer (LocDiT) to denoise and predict each next latent patch.
The generation process for patch $i$ is written as:
$$z_i \sim \operatorname{LocDiT}(h_i^{\mathrm{FSQ}}, h_i^{\mathrm{residual}}, z_{i-1}; t),$$
where
$$h_i^{\mathrm{FSQ}} = \operatorname{FSQ}(\operatorname{TSLM}(\mathbf{T}, \mathbf{E}_{ Here, $\mathbf{T}$ denotes text tokens, $\mathbf{E}_{ AudioVAE V2 is the latent codec used by the whole system. Its key design choice is asymmetry: it encodes input audio at 16 kHz but decodes to 48 kHz. This makes two things possible at once: the language-model-side latent sequence stays compact, and the final waveform can be rendered at a higher sample rate than the input. The paper frames this as an implicit super-resolution mechanism that improves output fidelity without lengthening the AR loop. Architecturally, AudioVAE V2 keeps the streaming-friendly causal-convolutional structure of the original AudioVAE and changes the rate-related modules. The 16 kHz encoder uses a strided causal CNN stack with downsampling ratios $[2, 5, 8, 8]$, producing a $640\times$ temporal reduction and 25 Hz latent frames. The 48 kHz decoder mirrors the structure with a deeper causal CNN stack and wider channels, using upsampling ratios $[8, 6, 5, 2, 2, 2]$. The decoder also accepts an optional target-sample-rate condition, so the same latent can be rendered at different output rates. Compared with VoxCPM, VoxCPM2 introduces several architectural refinements intended to improve conditioning bandwidth, better preserve information, and support large-scale multilingual controllability. The report also notes that the backbone is scaled along depth, width, and context length. The maximum sequence length grows to 8192. The patch size remains $P=4$, which keeps the LM-side token rate at 6.25 Hz. This was already introduced in VoxCPM1.5, and VoxCPM2 retains it because it lowers inference cost and helps long-form generation stability. A notable addition is an isolated reference-audio pathway. A single reference clip from the target speaker can be inserted as a delimited prefix, using VoxCPM2 does not use separate heads or specialized modules for different user-facing tasks. Instead, it expresses multiple generation modes through different input layouts over the same set of building blocks. The model processes a text token stream and an audio-latent stream in parallel, with a binary modality indicator selecting the embedding type. The paper describes five configurations, which collapse into four main capabilities: For voice design and controllable cloning, the free-form description is simply prepended to the synthesis text. For continuation cloning, the prompt audio and its transcript act as observed context, and the model continues autoregressively. During training, only the target-audio segment contributes to the loss; conditioning prefixes are excluded. The training objective keeps the two-term VoxCPM formulation: a patch-level conditional flow-matching loss over target latent patches, and a binary stop-prediction loss on the TSLM-FSQ hidden states. Both are masked to the target segment. To enable classifier-free guidance at inference, the model randomly drops LM-side conditioning of the LocDiT with probability 10% during training. Optimization uses AdamW with cosine learning-rate decay and linear warmup. VoxCPM2 uses a three-stage progressive curriculum: The training corpus contains over 2 million hours of multilingual speech, with Chinese and English as the largest portions. The remaining 28 languages each contribute roughly 1k to 50k hours depending on availability and annotation quality. The base TTS pipeline includes source separation, voice activity detection, ASR-based transcript alignment, and quality filtering. For controllable generation, the paper combines tens of thousands of hours of open-source expressive speech with several thousand hours of internally curated and annotated data. Expressive utterances are prefiltered with lightweight emotion classifiers so that only sufficiently expressive samples are annotated. Natural-language annotations cover voice-design attributes such as age, gender, accent, vocal texture, and scenario, as well as style attributes such as emotion, speaking rate, pitch, energy, and emphasis. The descriptions are generated using general-purpose audio understanding models such as Step-Audio R1 and Gemini 2.5 Pro, then verified with expert classifiers for gender, age, and emotion. Reference clips for cloning are mined from the same recording session by retaining clips with speaker-embedding cosine similarity above 0.7 and excluding clips that directly precede the target utterance. To reduce leakage between style and content, the authors also generate content-decoupled examples by cloning a described utterance onto a semantically unrelated transcript while keeping the original description as the control prompt. These synthetic examples are mixed into training, mainly in stage 2, while stage 3 focuses on native high-quality speech. The model generates one latent patch at a time. The paper uses three inference techniques to trade off quality and speed: The evaluation suite covers zero-shot voice cloning, multilingual synthesis, natural-language controllability, codec reconstruction quality, inference efficiency, and subjective listening tests. The paper compares VoxCPM2 against a broad mix of open-source and closed-source systems, including the CosyVoice family, MaskGCT, Spark-TTS, FireRedTTS, F5-TTS, Qwen3-TTS, IndexTTS2, VibeVoice, HiggsAudio-v2, MOSS-TTS, Fish Audio S2, LongCat-Audio-DiT, ElevenLabs, Hume, MiniMax-Speech, Seed-TTS, DiTAR, and MegaTTS3. VoxCPM and VoxCPM1.5 are also included as internal references. For intelligibility the paper uses WER for English and most European languages and CER for Chinese and other character-based languages. Speaker similarity is measured by cosine similarity from a pretrained speaker verification model. For controllable generation the paper uses the official instruction-following scores of InstructTTSEval, broken into APS, DSD, and RP. Public benchmarks include Seed-TTS-Eval, CV3-Eval, MiniMax-MLS-Test, and InstructTTSEval. For broader coverage the authors also construct an internal 30-language benchmark with 500 utterances per language. Reference audio for cloning evaluation is drawn from CommonVoice and FLEURS. On the internal benchmark, Gemini 3.1 Flash Lite is used for ASR because Whisper-large-v3 has limited accuracy on some low-resource languages. On Seed-TTS-Eval, VoxCPM2 reaches competitive zero-shot cloning results at 2B parameters. The paper reports: The authors emphasize that these results are competitive among both open-source and closed-source systems, with particularly strong speaker similarity given the model’s fully end-to-end continuous-latent design. VoxCPM2 improves over VoxCPM and VoxCPM1.5 on similarity, while maintaining good intelligibility. The paper also evaluates three inference recipes for cloning: The combined reference-plus-continuation recipe is the best overall choice. The paper’s interpretation is that the continuation prefix contributes temporal and prosodic alignment, while the isolated reference segment supplies robust speaker identity. The reference-only mode can be better on the hardest Chinese subset for intelligibility, but usually at the cost of similarity. The multilingual results are reported on CV3-Eval, MiniMax-MLS-Test, and the internal 30-language benchmark. On CV3-Eval, VoxCPM2 is competitive across the nine benchmark languages and is especially stable on the hard subsets, with 8.55 on hard-zh and 8.48 on hard-en. The paper notes that Fish Audio S2 remains stronger on many CV3-Eval languages, but VoxCPM2 is notably smaller and maintains an end-to-end continuous-latent design without discrete tokenizers. On MiniMax-MLS-Test, VoxCPM2 achieves the best speaker similarity on 22 out of 24 languages, which the authors interpret as evidence that the hierarchical continuous-latent model preserves speaker identity well across language families. Intelligibility is also strong for many languages, including Chinese, Dutch, Finnish, German, and Turkish. The weaker cases are Arabic and Hindi, which the paper attributes to limited training data and possible ASR evaluation noise on those languages. For unseen languages such as Czech and Romanian, the system still yields partially intelligible speech, suggesting some zero-shot transfer. On the internal benchmark, VoxCPM2 performs especially well on several Southeast Asian and low-resource languages such as Khmer, Lao, Burmese, and Thai. The paper reports that this evaluation confirms the model’s balanced multilingual capability within a single unified backbone. VoxCPM2 supports voice design, where a voice is synthesized from a natural-language description with no reference audio, and controllable cloning, where a reference clip is combined with style instructions. Both are implemented through the unified sequence organization, with no dedicated control heads or separate style encoders. On InstructTTSEval, VoxCPM2 performs strongly. The most important numbers reported are: The English result is the strongest overall among compared systems. On Chinese, VoxCPM2 ties for the best APS score but is somewhat behind on the more abstract instruction-following tasks. The authors attribute this to limited annotation diversity for higher-level persona and style descriptions. They also mention that the model supports 30 languages and 9 Chinese dialects for voice design and style control, and that preliminary singing voice generation appears possible because song-style data was included, although singing quality remains a work in progress. The reconstruction experiments compare the codec used by VoxCPM, VoxCPM1.5, and VoxCPM2. The key takeaway is that AudioVAE V2 offers competitive full-band and speech-quality metrics under a more challenging super-resolution setup. These results show complementary strengths: VoxCPM remains very strong on low-band speech metrics, VoxCPM1.5 does best on full-band Mel distance because it works directly at high sample rate, and VoxCPM2 is competitive across both low-band and full-band metrics despite encoding 16 kHz audio and reconstructing at 48 kHz. The paper uses this to support the asymmetric codec design. Despite being the largest model in the family, VoxCPM2 remains efficient enough for consumer hardware. On a single NVIDIA RTX 4090, the PyTorch implementation achieves an RTF of 0.30 with about 8 GB VRAM, while the Nano-vLLM serving path reduces RTF to 0.13. The paper highlights that this is over 7× real-time on the same GPU. VoxCPM1.5 and VoxCPM are faster in raw PyTorch RTF at their smaller sizes, but VoxCPM2 keeps the compact 6.25 Hz token rate, which is the main reason deployment remains practical. Because the architecture is causal and patch-local, the system also supports streaming and batched serving, including compatibility with vLLM-Omni for production use. The paper includes 50-listener double-blind MOS studies over roughly 100 samples spanning zero-shot cloning, multilingual synthesis, and controllable generation. VoxCPM2’s subjective performance is consistent with the objective metrics and is often near the top among compared systems. In zero-shot cloning, VoxCPM2 achieves the highest speaker similarity among the listed systems. In multilingual synthesis, it attains the highest naturalness MOS. In controllable generation, it achieves the highest instruction MOS. The paper also notes an important methodological point: speaker-embedding cosine similarity does not always fully capture perceived cloning quality, because human listeners are sensitive to fine-grained personal and prosodic cues that objective similarity metrics may miss. The authors are explicit about several limitations. First, cross-lingual synthesis quality is still affected by data imbalance, so low-resource languages remain weaker than major languages. Second, highly abstract or complex instructions are harder to follow consistently across languages, especially where annotation diversity is limited. Third, computational and deployment overhead remains important as model scale grows, even though the system is still efficient enough for real-time use on a single RTX 4090 under optimized serving. The paper also flags singing voice generation as preliminary: it is a promising extension of controllable synthesis, but still needs substantial improvement. More generally, the authors say that future work will focus on expanding high-quality long-tail corpora, refining continuous-latent representations, and improving instruction-following robustness across styles and languages. On the responsible-use side, the paper highlights that high-fidelity speech generation raises safety concerns and suggests stronger safeguards in future versions, including content provenance tracking, digital watermarking, and voice cloning detection. The model, fine-tuning code, and inference tools are released under Apache 2.0 to support research and development, but the report clearly frames responsible deployment as necessary. The main technical takeaway is that VoxCPM2 demonstrates a scalable alternative to discrete-token TTS: a hierarchical continuous-latent model can be trained end-to-end, without an external speech tokenizer, and still achieve strong multilingual intelligibility, high speaker similarity, robust instruction following, and practical streaming inference. The paper’s strongest evidence comes from the combination of a unified sequence organization, an asymmetric 16 kHz-to-48 kHz codec, a larger backbone with higher conditioning bandwidth, and a multi-stage training curriculum that preserves base TTS quality while gradually adding controllable behaviors. This repository contains the full implementation of VoxCPM2, a tokenizer-free Text-to-Speech system designed for multilingual speech generation, creative voice design, and true-to-life cloning. The core TTS pipeline is encapsulated in the Model architectures corresponding to the original VoxCPM and the VoxCPM2 extensions are implemented under the The repository integrates additional utilities, such as a denoiser for acoustic noise suppression, which is optional during initialization. Users can instantiate the system either from pre-downloaded checkpoints or directly load from Hugging Face Hub snapshots using Overall, this codebase directly maps to the paper's described methodology, providing efficient state-of-the-art multilingual TTS with support for 30 languages, natural voice design, and fine-grained style control, all in a single unified pipeline.Methodology
AudioVAE V2: asymmetric codec for 48 kHz reconstruction
Backbone refinements and scaling
Component
VoxCPM
VoxCPM1.5
VoxCPM2
Backbone parameters ~0.6B ~0.8B ~2B LocEnc 4L, H=1024 8L, H=1024 12L, H=1024 TSLM MiniCPM-4-0.5B (24L, H=1024) MiniCPM-4-0.5B (24L, H=1024) MiniCPM-4-1B (28L, H=2048) FSQ latent dim 256 256 512 RALM 6L, H=1024 8L, H=1024 8L, H=2048 LocDiT 4L, H=1024 8L, H=1024 12L, H=1024 Patch size 2 4 4 LM-side token rate 12.5 Hz 6.25 Hz 6.25 Hz Max sequence length 4096 4096 8192 Input sample rate 16 kHz 44.1 kHz 16 kHz Output sample rate 16 kHz 44.1 kHz 48 kHz Reference-audio pathway
REF_START and REF_END, even when no transcript is available. This pathway provides speaker identity information to the causal TSLM and RALM without requiring the reference clip to serve as a temporal prefix of the target utterance. The paper highlights that this is distinct from continuation-based cloning and enables a decoupled voice-cloning mode that is useful for controllable cloning.Unified sequence organization
Mode Sequence layout Basic TTS $\langle\text{text}\rangle \rightarrow \langle\text{target audio}\rangle$ Voice design $\langle\text{voice description} + \text{text}\rangle \rightarrow \langle\text{target audio}\rangle$ Reference cloning $\langle\text{reference audio}\rangle \mid \langle\text{text}\rangle \rightarrow \langle\text{target audio}\rangle$ Controllable cloning $\langle\text{reference audio}\rangle \mid \langle\text{style description} + \text{text}\rangle \rightarrow \langle\text{target audio}\rangle$ Continuation cloning $\langle\text{prompt text} + \text{target text}\rangle \mid \langle\text{prompt audio}\rangle \rightarrow \langle\text{target audio}\rangle$ Training objective and curriculum
Inference
Experimental Setup
Results
Zero-shot voice cloning on Seed-TTS-Eval
Recipe test-EN WER / SIM test-ZH CER / SIM test-ZH-Hard CER / SIM Continuation only 1.01 / 77.7 1.97 / 72.6 8.16 / 72.4 Reference only 1.10 / 75.3 1.81 / 67.0 6.85 / 70.0 Reference + continuation 0.99 / 79.5 1.94 / 75.2 7.44 / 74.9 Multilingual capability
Metric Result Average across 30 languages 1.68% Languages below 3% 28 Languages below 1% 6 Voice design and controllable generation
Subset APS DSD RP InstructTTSEval-ZH 85.2 71.5 60.8 InstructTTSEval-EN 84.2 83.2 71.4 AudioVAE V2 reconstruction quality
Model Input Output VCTK MelD-48k VCTK MelD-16k VCTK STOI-16k VCTK PESQ-16k Song Describer MelD-48k Song Describer MelD-16k
VoxCPM 16 kHz 16 kHz 1.787 0.801 0.911 3.940 2.371 1.246
VoxCPM1.5 44 kHz 44 kHz 1.139 0.926 0.836 3.148 1.267 1.311
VoxCPM2 16 kHz 48 kHz 1.335 0.813 0.907 3.906 1.334 1.133
Inference efficiency and deployment
Inference path Params RTF VRAM VoxCPM2 (PyTorch) 2B 0.30 ~8 GB VoxCPM2 (Nano-vLLM) 2B 0.13 ~8 GB VoxCPM1.5 (PyTorch) 0.8B 0.15 ~6 GB VoxCPM (PyTorch) 0.6B 0.17 ~5 GB Subjective listening tests
Task Metric VoxCPM2 Zero-shot cloning N-MOS 4.78 ± 0.02 Zero-shot cloning S-MOS 4.74 ± 0.03 Multilingual synthesis N-MOS 4.78 ± 0.02 Multilingual synthesis S-MOS 4.66 ± 0.03 Controllable generation N-MOS 4.48 ± 0.04 Controllable generation I-MOS 4.50 ± 0.03 Limitations and Future Work
Takeaway
Code & Implementation
VoxCPM class located in src/voxcpm/core.py, which provides user-friendly methods for text-to-speech generation, voice design from natural language, and controllable voice cloning leveraging a hierarchical diffusion-autoregressive model architecture.src/voxcpm/model/ directory, with dynamic selection at runtime based on configuration files.VoxCPM.from_pretrained(), supporting flexible hardware configurations and optional fine-tuning with LoRA weight adaptation.