dots.tts
dots.tts Technical Report
dots.tts is a 2B-parameter continuous autoregressive text-to-speech model that generates speech in a semantically structured continuous latent space. Innovations include full-history conditioning and self-corrective post-training for robust, expressive, and low-latency multilingual speech.
Demos
The demos highlight dots.tts's state-of-the-art text-to-speech ability with very low word error rates and high speaker similarity across multiple languages. Watch the architecture overview for its unique fully continuous pipeline and the evaluation charts demonstrating top benchmark performance and voice cloning quality. These visuals illustrate dots.tts's synthesis accuracy, stability, and expressiveness.
Links
Paper & demos
Code & resources
Impact
Abstract
We present dots.tts, a 2B-parameter continuous autoregressive text-to-speech (TTS) foundation model that models speech in a continuous latent space. Compared with existing continuous autoregressive models, our key innovations are threefold. First, we train an AudioVAE with multiple objectives to build a semantically structured and prediction-friendly continuous speech space. Second, we use full-history conditioning in the flow-matching head to preserve long-range consistency and reduce drift during generation. Third, we apply reward-free self-corrective post-training to the flow-matching head to further improve robustness and acoustic quality. After being trained on a large-scale multilingual corpus, dots.tts achieves the best average performance on Seed-TTS-Eval, with WERs of 0.94%/1.30%/6.60% and SIM scores of 81.0/77.1/79.5 on the zh/en/zh-hard test sets, respectively. Across other benchmarks, dots.tts also consistently demonstrates open-source state-of-the-art performance, exhibiting strong generation stability, voice cloning ability, and emotional expressiveness. For efficient inference, we further apply CFG-aware MeanFlow distillation, enabling low-latency speech generation with first-packet latencies of 85/54 ms in output streaming and dual-streaming modes, respectively. To facilitate reproducible research and practical deployment, we release the training and inference code, together with the pretrained, post-trained, and MeanFlow-distilled checkpoints, under the Apache 2.0 license.
Overview
dots.tts is a 2B-parameter continuous autoregressive text-to-speech foundation model. The paper frames its goal as closing two bottlenecks in continuous-AR TTS: long-range error accumulation during autoregressive rollouts, and an immature post-training stack compared with discrete-token cascade systems. The main design choice is to model speech in a continuous latent space instead of discrete acoustic tokens, while keeping the system fully end-to-end and streamable.
The reported design combines three ideas:
- a high-fidelity AudioVAE trained with reconstruction, WavLM alignment, and multitask supervision so the continuous latent space is both expressive and easy for the downstream generator to predict;
- a fully history-conditioned AR flow-matching head that preserves long-range consistency by conditioning on the full generated history rather than a truncated context;
- reward-free self-corrective post-training plus CFG-aware MeanFlow distillation to improve robustness and reduce inference cost.
The paper reports strong performance on Seed-TTS-Eval, MiniMax-Speech multilingual evaluation, CV3-Eval, and EmergentTTS-Eval, together with low-latency streaming behavior on a single H800 GPU.
Problem setting and motivation
The introduction argues that modern TTS expectations go beyond intelligibility: users want expressive output, controllability, real-time synthesis, and coverage of neutral reading, emotional dialogue, paralinguistic events, singing, and general audio. The paper contrasts three TTS routes:
- NAR flow-matching / diffusion systems, which are good for offline synthesis but less natural for interactive dialogue;
- discrete-token autoregressive systems, which reuse LLM infrastructure and dominate deployment, but are limited by tokenizer bottlenecks;
- continuous-latent autoregressive systems, which remove quantization bottlenecks and can better cover speech plus richer audio phenomena, but suffer from error accumulation.
The paper’s thesis is that continuous AR becomes practical once the latent space is structured for prediction, the rollout is made long-range stable, and post-training is adapted to the continuous setting.
Model architecture
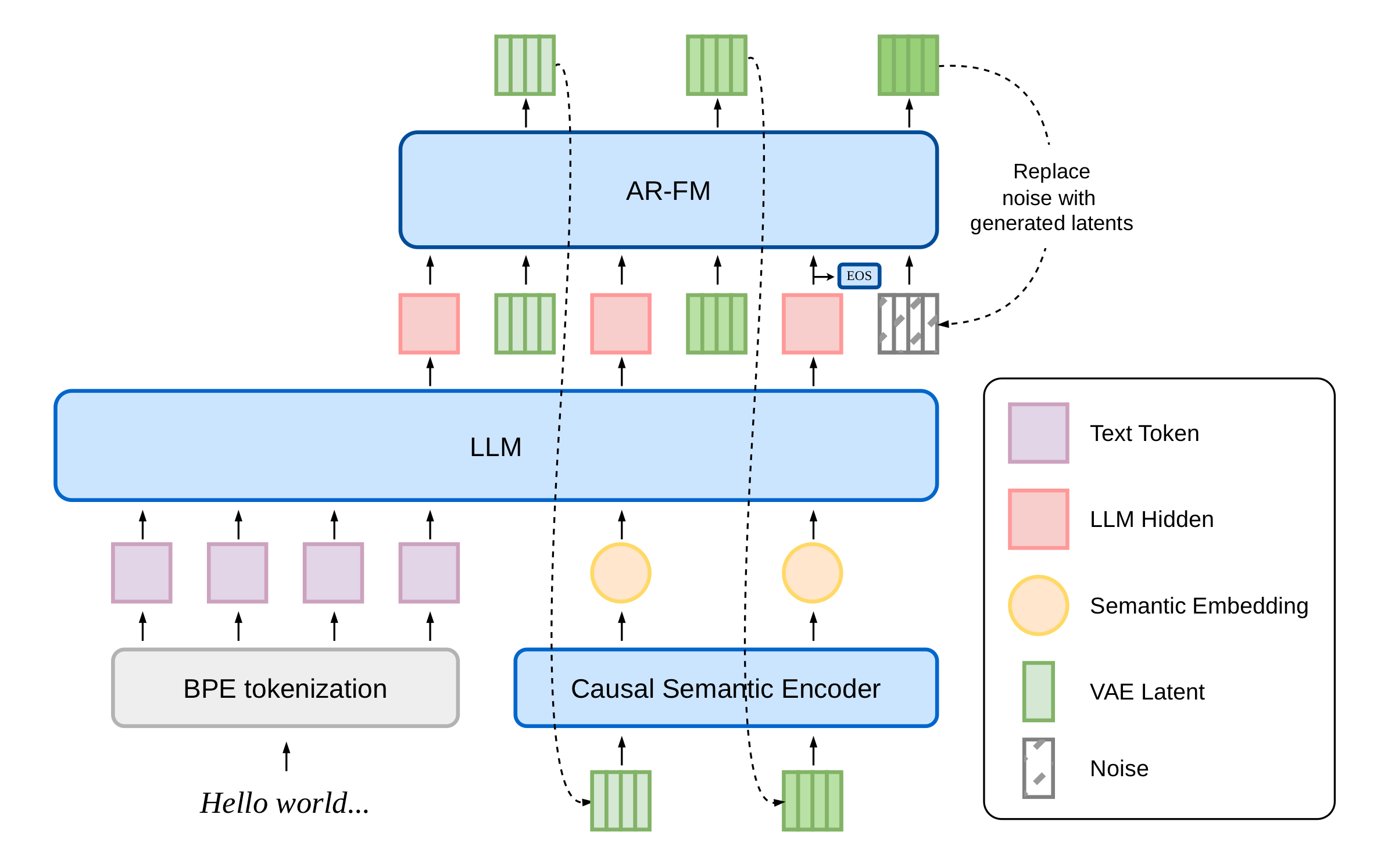
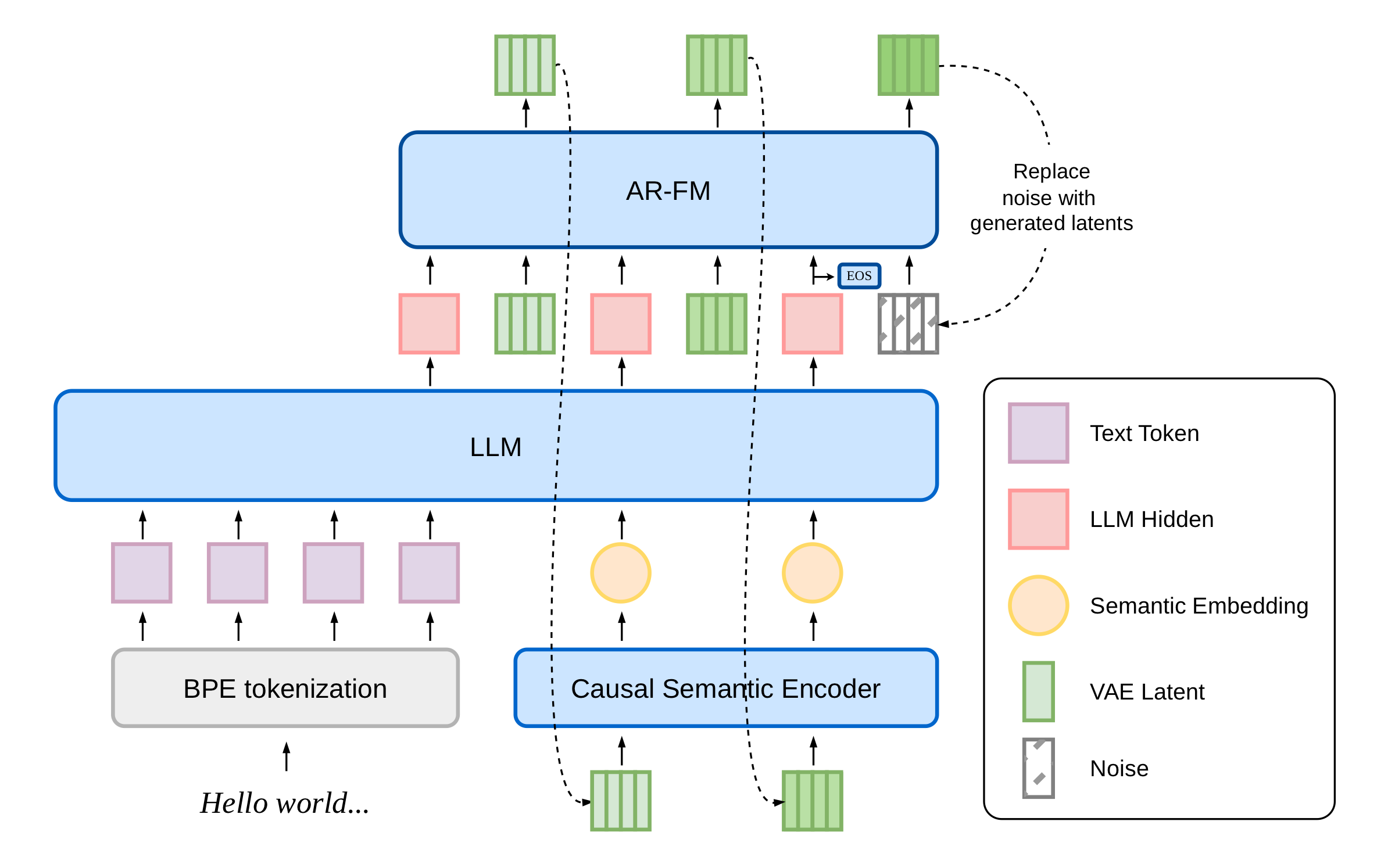
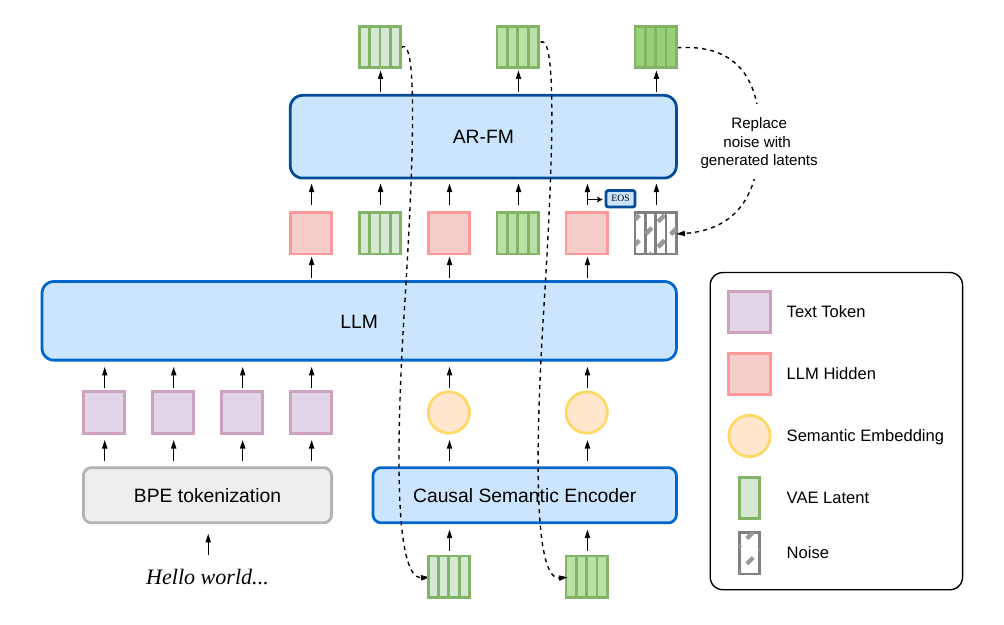
dots.tts is decomposed into two decoupled parts: a frozen AudioVAE that defines the continuous representation, and an autoregressive backbone that predicts that representation patch by patch. The AudioVAE encodes 48 kHz mono speech into a 128-dimensional latent stream at 25 Hz, corresponding to about 1920x temporal downsampling, and decodes with a causal BigVGAN-style decoder.
The autoregressive backbone has three modules:
- a semantic encoder that compresses each newly generated audio patch into a compact semantic summary;
- a flow-matching head that generates each next 4-frame latent patch.
The audio-side interface to the LLM is intentionally reduced to a 6.25 Hz semantic summary of the generated history, not the raw VAE latent. The paper emphasizes that this decoupling is important for long-rollout stability because the LLM reasons over compact semantic history while the acoustic detail is handled by the flow-matching head.
The core streaming cycle is:
- LLM consumes text and the latest 6.25 Hz audio-semantic token.
- The AR flow-matching head predicts the next 4-frame latent patch at 25 Hz.
- The semantic encoder converts that patch back into one 6.25 Hz embedding.
- The embedding is fed back into the LLM for the next step.
![Attention masks and RoPE position IDs of the AR flow-matching head ($H$ blocks of size $1$, $P$/$Z$ blocks of size $L=4$). (a) Block-causal training mask over [$C|Z$]. (b) Per-step inference mask at step $n$, with the KV-cached history on the left and the newly appended $(H_n, Z_n)$ on the right. (c) Position IDs: the train row is the $C$ and $Z$ segments concatenated, with the red marker at the boundary where $Z$'s positions reset; the inference row places $Z_n$ at the same positions $Z_n$ occupied in training.](https://akapulu-public-assets.s3.us-west-1.amazonaws.com/blogs/research-digest/p/2606.07080/arxiv/fig/_preview/figures__figure2_attn_mask.png)
AudioVAE
The AudioVAE follows a HoliTok-style recipe with a causal BigVGAN-v2 decoder and fully causal convolutions on both encoder and decoder sides. The encoder uses strided residual blocks with downsample strides $[2, 2, 2, 4, 6, 10]$, ending in a posterior projection that outputs per-frame mean and log-variance. In addition to the standard KL prior, the model adds flow regularization to shape a smooth latent space.
The paper trains the AudioVAE in two stages:
- Stage 1 optimizes reconstruction: multi-period plus sub-band CQT adversarial losses, multi-scale mel-spectral reconstruction, feature matching, and KL plus flow regularization.
- Stage 2 adds learnability supervision: a frame-level alignment loss against frozen WavLM features and a multitask downstream block with ASR, emotion, and speaker classification objectives. The retained encoder becomes the semantic frontend used by the backbone.
The reported motivation is that a reconstruction-only continuous latent can still be too difficult for an LLM to predict reliably, so the second stage makes it semantically structured without sacrificing fidelity.
Semantic encoder
The semantic encoder is reused from the AudioVAE training pipeline. It first halves the frame rate with a strided causal-convolution projector, then applies a 24-layer causal Transformer with hidden size $1024$ and FFN size $4096$, and finally groups outputs in pairs to yield an end-to-end $4\times$ downsampling from 25 Hz latent frames to 6.25 Hz LLM tokens. Its outputs are pretrained to align with semantic structure rather than low-level acoustics.
Autoregressive flow-matching head
The acoustic generator is a Diffusion Transformer with 18 layers, hidden size $1024$, FFN size $4096$, RoPE in every layer, RMSNorm with QK-norm, and adaLN-zero modulation conditioned on diffusion time and a speaker embedding. It predicts the rectified-flow vector field and is solved with a small number of Euler steps at inference.
Each step synthesizes a 4-frame latent patch at 25 Hz. The head conditions on three streams in a shared hidden space: the current LLM hidden state, the clean patches from all earlier audio positions, and the noisy patch under denoising. A frozen CAM++ x-vector is added as a global speaker condition. Classifier-free guidance is enabled by independently dropping the LLM hidden stream and the speaker stream with probability $0.5$ during training.
The paper stresses that the head is trained with a block-causal attention mask so that parallel training exactly matches per-step inference. In the concatenated training sequence, a cause half $C$ contains the clean history and a generation half $Z$ contains noisy patches. The mask ensures that $Z_n$ can attend only to $H_{\le n}$ and $P_{ The paper gives explicit objectives for the AudioVAE, backbone pretraining, self-corrective alignment, and MeanFlow distillation. A compact summary is below. The AudioVAE loss is: $$
\mathcal{L}_{\mathrm{vae}} =
\mathcal{L}_{\mathrm{mel}} + \mathcal{L}_{\mathrm{adv}} + \mathcal{L}_{\mathrm{fm}} + \beta_{\mathrm{kl}}\mathcal{L}_{\mathrm{kl}}
+ \lambda_{\mathrm{wavlm}}\mathcal{L}_{\mathrm{wavlm}} + \lambda_{\mathrm{sup}}\mathcal{L}_{\mathrm{sup}}.
$$ Here the first group is reconstruction-oriented, while the second group adds WavLM alignment and multitask supervision for downstream learnability. Backbone pretraining uses two losses: The key point is that the flow-matching loss is the only loss that backpropagates through the LLM and semantic encoder, so the LLM is optimized end-to-end through the acoustic objective rather than via a separate text-only loss. In simplified form, the flow objective is: $$
\mathcal{L}_{\mathrm{fm}} = \mathbb{E}\left[\left\|v_\theta(x_t, t, H_{\le n}, P_{ The total backbone pretraining loss is the sum of flow matching and EOS loss. After pretraining, the paper updates only the DiT acoustic generator inside the AR-FM head. The LLM, semantic encoder, AudioVAE, and speaker encoder are frozen. This stage is explicitly reward-free: it does not use a reward model, human preference model, or external acoustic teacher. Instead, the model rolls itself off the data manifold by one step, samples auxiliary off-trajectory states, and learns to steer those states back toward the clean endpoint. The training setup reported in the paper is: The authors describe this stage as directly addressing the mismatch between pretraining and inference, where small velocity errors accumulate over multiple autoregressive patches. The final stage freezes the self-corrected DiT as a teacher and trains a student DiT with the same backbone plus a duration embedder. The teacher trajectory is generated with a 16-step Euler solver, and classifier-free guidance is fused into the teacher target so that the student directly learns the CFG-guided mean velocity over a time interval $[t_a, t_b]$. The student is trained for 50K steps with the same 8-hour global audio batch used in pretraining, 5K-step warmup, cosine decay to $2 \times 10^{-6}$, peak learning rate $1 \times 10^{-4}$, and interval sampling from a log-normal distribution with mean $-0.4$ and standard deviation $1.0$. Anchor samples are mixed with probability $0.5$ for stability. At inference, the MeanFlow student predicts interval updates in a single conditional pass per step, avoiding separate conditional and unconditional evaluations because CFG has already been distilled into the target. The backbone is trained on 1.5M hours of speech, captioned speech, and a small fraction of general audio from three sources. The paper also notes that the AudioVAE is trained on 48 kHz audio and includes a small general-audio share so the latent can cover non-speech sounds, even though the released backbone is still speech-heavy. Content fidelity is evaluated using ASR-based error rate: WER for English and other non-Chinese languages, and CER reported as WER for Chinese for table compatibility. Speaker similarity is measured as cosine similarity between WavLM-SV embeddings of generated speech and the reference prompt. The paper uses the benchmark default ASR settings for multilingual evaluation: Whisper-Large-v3 for English and multilingual benchmarks, Paraformer for Mandarin Chinese, and the benchmark default ASR for the remaining MiniMax languages. For baseline comparison, the paper cites original-paper numbers or official default inference configurations and does not retune baselines. The compared systems include CosyVoice 2/3, Qwen3-TTS, IndexTTS 2, FireRedTTS-2, Seed-TTS, MiniMax-Speech, Fish-Audio S2, F5-TTS, MegaTTS3, DiTAR, VibeVoice, and VoxCPM 2. The first quantitative check is the VAE reconstruction task on LibriSpeech test-other. The main takeaway is that the learned 48 kHz continuous latent is faithful enough that reconstruction is not the downstream bottleneck. The paper reports that the latent itself adds almost nothing to end-to-end error, and that stage 2 supervision makes the latent learnable as an LLM target. Compared with representative discrete tokenizers and continuous representations, the dots.tts VAE sits in the top band on most metrics, while using a much higher input bandwidth than prior continuous baselines. The paper highlights the 0.969 SIM and 4.14 WER as evidence that the latent preserves fidelity while remaining usable for downstream generation. Seed-TTS-Eval is the main zero-shot voice-cloning benchmark. The paper evaluates test-en, test-zh, and test-zh-hard under the standard reference-prompt protocol and reports the pretrained model, the self-corrected model, and MeanFlow variants with $\mathrm{NFE} \in \{2,3,4\}$. The strongest reported summary is that dots.tts achieves the best average WER and SIM across the benchmark, with the self-corrected model peaking on similarity and the pretrained model already leading on average WER. Interpretation in the paper: The MiniMax benchmark covers 24 languages and uses two reference speakers per language. The paper’s main findings are that dots.tts (SOAR) achieves the highest average SIM at 83.9, and that a dots.tts variant takes the per-language SIM lead on 19 of 24 languages and ties on 2 more. The average WER is competitive but not uniformly best, with low-resource languages contributing most of the gap. The authors attribute the low-resource WER gap to insufficient BPE coverage and note that the similarity scores remain strong even when WER rises. CV3-Eval adds a hard Chinese/English split and, importantly, a cross-lingual voice-cloning subset. The paper treats cross-lingual cloning as a difficult test of timbre disentanglement. Key observations from the paper: EmergentTTS-Eval uses a Gemini-based audio judge to compare systems against a fixed gpt-4o-mini-tts reference over six expressiveness-oriented scenarios: Emotions, Foreign Words, Paralinguistics, Complex Pronunciation, Questions, and Syntactic Complexity. The paper reports both WER and head-to-head win rate. The paper interprets these results as a tradeoff: SOAR tightens text faithfulness and yields the best Syntactic Complexity score in the table, but it reduces expressiveness on the emotion-related columns compared with the pretrained model. Pretrain is the strongest open-source system on overall win rate, while SOAR gives the lowest open-source WER and best syntax score. Efficiency is reported on Seed-TTS-Eval using vllm-omni on a single NVIDIA H800 GPU. The LLM runs on vLLM with continuous batching and paged-KV attention, while the AR-FM head and semantic encoder are JIT-compiled with The reported results are: The paper’s interpretation is that interleaving lets a conversational upstream LLM drive synthesis token by token, so audio can start as soon as the first text token is emitted rather than waiting for a full response prefix. This is positioned as the mode to use for duplex voice agents and other real-time dialogue settings. The limitations section is unusually explicit about what remains unresolved: The technical novelty of dots.tts is not just that it uses a continuous latent space, but that it makes continuous AR practical by combining: a learnable semantic latent, a history-aware backbone interface, block-causal training that matches inference exactly, reward-free self-correction, and CFG-aware MeanFlow distillation. The reported results show that this recipe is strong on zero-shot cloning, multilingual similarity, and expressiveness-related syntax, while remaining honest about lexical coverage weaknesses in low-resource and out-of-distribution text conditions. The The model architecture and training components are defined under The repository README provides detailed usage instructions, including CLI examples, Python API calls, and descriptions of pretrained checkpoint variants for base, self-corrective-aligned, and MeanFlow-distilled models optimized for different speed-quality trade-offs. Overall, the code release aligns closely with the paper's description, offering end-to-end support from training to inference, voice cloning, and efficient streaming synthesis. The design emphasizes seamless interaction with large pretrained models and continuous latent speech representations for high-quality TTS.Objectives and training recipe
AudioVAE objective
Backbone pretraining
Self-corrective alignment
CFG-aware MeanFlow distillation
Reported training schedule
Data
Evaluation protocol
Experimental results
AudioVAE reconstruction quality
Model
Sample rate
FPS
PESQ NB
PESQ WB
STOI
UTMOS
SIM
WER (%)
Ground truth -- -- 4.55 4.64 1.000 3.50 1.000 4.59 XY-Tokenizer 16 kHz 100 2.80 2.23 0.89 3.46 0.82 6.19 WavTokenizer 16 kHz 75 2.40 1.96 0.87 3.22 0.68 13.35 X-codec2 16 kHz 50 2.83 2.26 0.90 3.64 0.81 6.85 SAC 16 kHz 62.5 2.92 2.39 0.90 3.84 0.85 5.77 SemanticVAE 16 kHz 40 3.99 3.80 0.969 3.76 0.963 4.15 MingTok-Audio 16 kHz 50 4.23 4.12 0.981 3.75 0.950 4.27 VibeVoice 24 kHz 7.5 2.85 -- 0.823 3.72 -- -- dots.tts VAE 48 kHz 25 4.09 3.95 0.973 3.75 0.969 4.14 Seed-TTS-Eval
Model
test-en WER
test-en SIM
test-zh WER
test-zh SIM
test-zh-hard WER
test-zh-hard SIM
Avg. WER
Avg. SIM
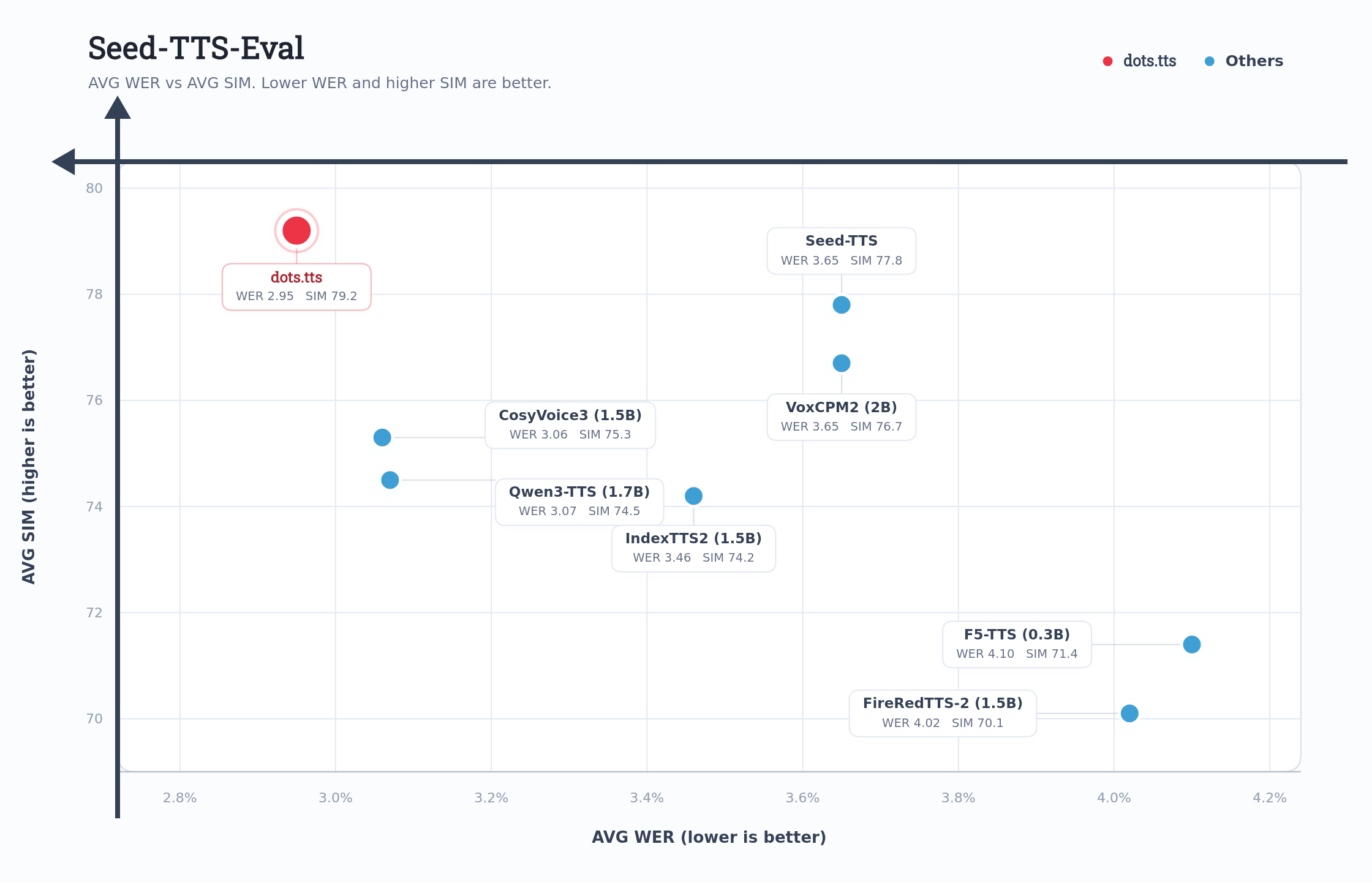
CosyVoice 3 2.22 72.0 1.12 78.1 5.83 75.8 3.06 75.3 Qwen3-TTS 1.23 71.7 1.22 77.0 6.76 74.8 3.07 74.5 Seed-TTS 2.25 76.2 1.12 79.6 7.59 77.6 3.65 77.8 VoxCPM 2 1.84 75.3 0.97 79.5 8.13 75.3 3.65 76.7 dots.tts (Pretrain) 1.34 76.8 0.96 80.5 6.46 79.2 2.92 78.8 dots.tts (SOAR) 1.30 77.1 0.94 81.0 6.60 79.5 2.95 79.2 dots.tts (MF, NFE=4) 1.29 76.2 0.94 80.0 6.60 78.5 2.94 78.2 dots.tts (MF, NFE=3) 1.41 75.9 1.02 79.9 7.19 78.6 3.21 78.1 dots.tts (MF, NFE=2) 1.51 75.2 1.04 79.1 7.74 76.7 3.43 77.0
MiniMax-Speech multilingual test set
Model
Average WER
Average SIM
MiniMax 2.8 76.6 ElevenLabs 7.5 65.5 Fish-Audio S2 3.7 78.0 VoxCPM 2 5.7 82.3 dots.tts (Pretrain) 6.6 83.5 dots.tts (SOAR) 6.8 83.9 dots.tts (MF$_4$) 6.8 83.5 CV3-Eval
Model
zh
en
hard-zh
hard-en
en→zh WER
en→zh SIM
zh→en WER
zh→en SIM
CosyVoice 2 4.08 6.32 12.58 11.96 13.50 63.3 6.47 64.3 CosyVoice 3 3.91 4.99 9.77 10.55 8.01 66.9 4.32 66.4 Fish-Audio S2 2.65 2.43 9.10 4.40 -- -- -- -- VoxCPM 2 3.65 5.00 8.55 8.48 -- -- -- -- dots.tts (Pretrain) 3.51 5.24 9.69 5.99 10.88 74.6 4.97 71.9 dots.tts (SOAR) 3.71 4.50 9.22 4.49 10.75 75.0 5.66 72.8 dots.tts (MF, NFE=4) 3.95 4.05 9.10 4.37 10.73 73.8 5.24 70.9
EmergentTTS-Eval
Model
WER (%)
Overall
Emotions
Paraling.
Foreign
Complex Pron.
Questions
Syntax
Gemini-2.5-Flash-TTS 10.39 70.7% 95.9% 91.3% 58.5% 55.7% 63.0% 57.9% Gemini-2.5-Pro-TTS 11.79 69.3% 86.9% 82.3% 58.2% 64.8% 61.3% 61.8% gpt-4o-audio-preview 11.87 65.2% 88.8% 82.1% 60.2% 40.4% 57.0% 59.5% gpt-4o-mini-tts 10.76 56.3% 59.2% 58.8% 57.3% 52.4% 52.7% 57.1% dots.tts (Pretrain) 10.86 49.2% 72.7% 54.7% 39.5% 18.0% 48.4% 58.4% dots.tts (MF4) 11.75 47.9% 59.8% 55.2% 36.3% 16.7% 50.5% 64.8% dots.tts (SOAR) 10.45 47.6% 63.9% 52.7% 39.4% 16.4% 47.0% 65.7% Efficiency and streaming
torch.compile. The MeanFlow-distilled student uses $\mathrm{NFE}=4$ per patch.
What the paper claims as its main contributions
Limitations and open issues
Bottom line
Code & Implementation
dots.tts repository contains the full training and inference code for the 2-billion-parameter continuous autoregressive text-to-speech model described in the paper. It implements the core model, which combines a semantic encoder, a large language model (LLM), and an autoregressive flow-matching head over a high-fidelity AudioVAE operating at 48 kHz.src/dots_tts/models/dots_tts/, with model.py serving as the main model assembly around the core network. The inference runtime is implemented in src/dots_tts/runtime.py, which provides a high-level API for loading pretrained checkpoints, running generation with optional voice cloning, and streaming synthesis output efficiently.