TargetSEC
TargetSEC: Plug-and-Play In-the-Wild Speech Emotion Conversion via Arousal-Conditioned Latent Style Diffusion
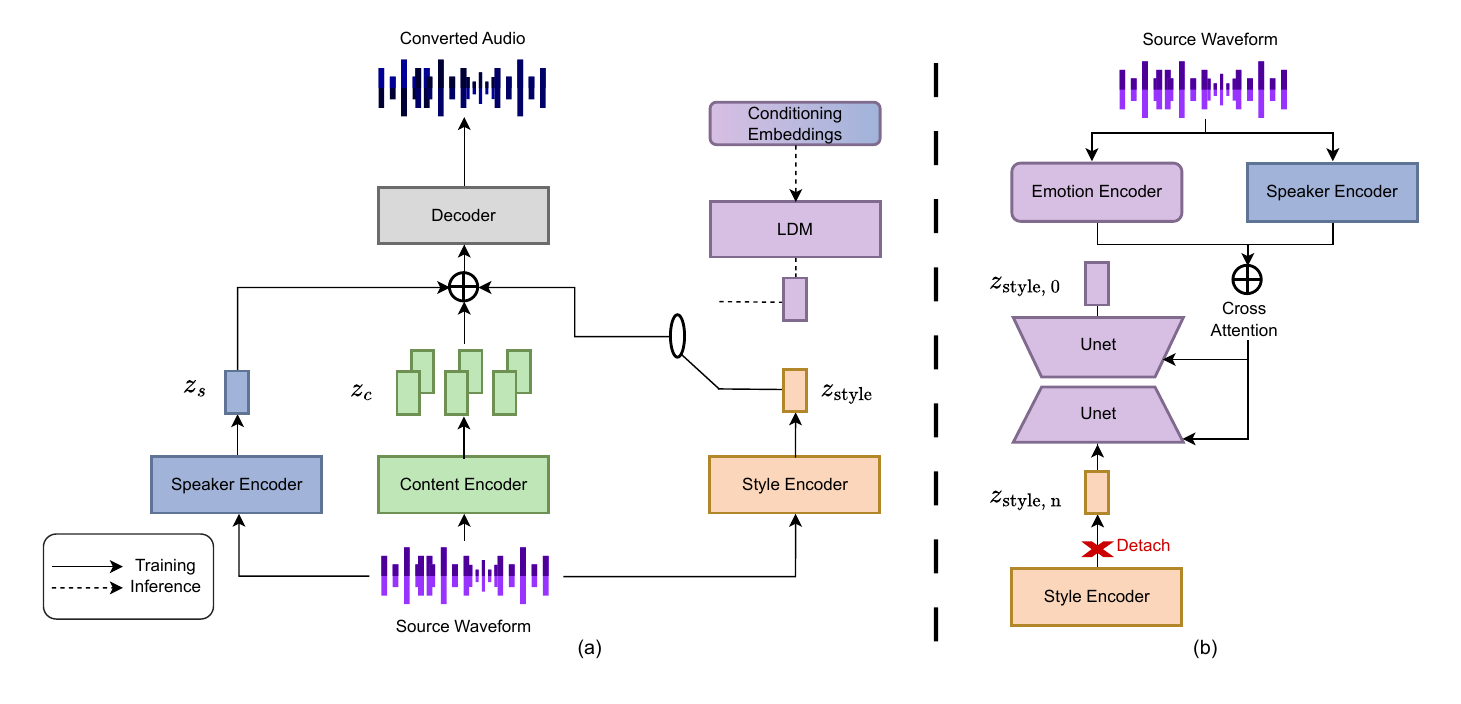
TargetSEC introduces a latent diffusion method to convert speech emotion by generating emotion-aligned style embeddings conditioned on speaker identity and arousal level. It uniquely enables high-quality emotion conversion without altering the core speech synthesis model, excelling on in-the-wild speech data.
Links
Paper & demos
Impact
Abstract
Speech Emotion Conversion (SEC) aims to transform the emotion of a source utterance into a target emotion while preserving content and speaker identity. SEC on in-the-wild data is challenging due to the non-parallel nature of training data and complex real-world acoustics. Existing fixed-duration approaches either struggle to shift the emotion effectively (high quality, low conversion) or degrade speech naturalness (low quality, high conversion). We propose TargetSEC, an embedding-driven latent diffusion framework that generates emotion-focused style embeddings conditioned on speaker identity and continuous emotion. Unlike methods that diffuse over spectrograms, TargetSEC operates in a compact latent space. Experiments on the MSP-Podcast dataset show that TargetSEC outperforms current non-duration baselines in conversion accuracy while maintaining high speech quality, and achieves performance comparable to duration-prediction systems without explicit temporal modeling.
Introduction and problem setting
TargetSEC addresses speech emotion conversion (SEC): given a source utterance, the goal is to change its emotional expression to a target emotion while preserving linguistic content and speaker identity. The paper focuses on the difficult in-the-wild setting, where training data are non-parallel and acoustically diverse, in contrast to controlled acted datasets. The authors argue that current fixed-duration SEC systems face a practical trade-off: some preserve speech quality but only weakly shift emotion, while others achieve stronger emotion transfer at the cost of naturalness.
The paper’s central idea is to move emotion generation from the waveform or spectrogram domain into a compact latent style space. Instead of diffusing over high-dimensional audio representations, TargetSEC learns a latent diffusion prior over style embeddings that are conditioned on speaker identity and a continuous arousal target. The method is designed as a plug-and-play module: the heavy speech synthesis backbone is trained once, and at inference the style encoder is replaced by a learned diffusion prior that predicts an emotion-aligned style embedding.
The paper emphasizes that arousal is the most reliable continuous emotion dimension for audio, and therefore restricts control to arousal rather than full valence-arousal-dominance modeling. This choice is aligned with prior SEC work and with the observation that speech acoustics reflect arousal more clearly than valence.
Contributions claimed by the paper
- A latent diffusion framework for SEC on in-the-wild data, with the diffusion model operating on compact style embeddings rather than spectrograms.
- A conditioning strategy based on speaker embeddings and continuous emotion embeddings, rather than text prompts.
- A plug-and-play architecture that enables emotion conversion without changing the synthesis model backbone, and that could in principle be extended to other continuous or discrete style attributes.
Overall architecture
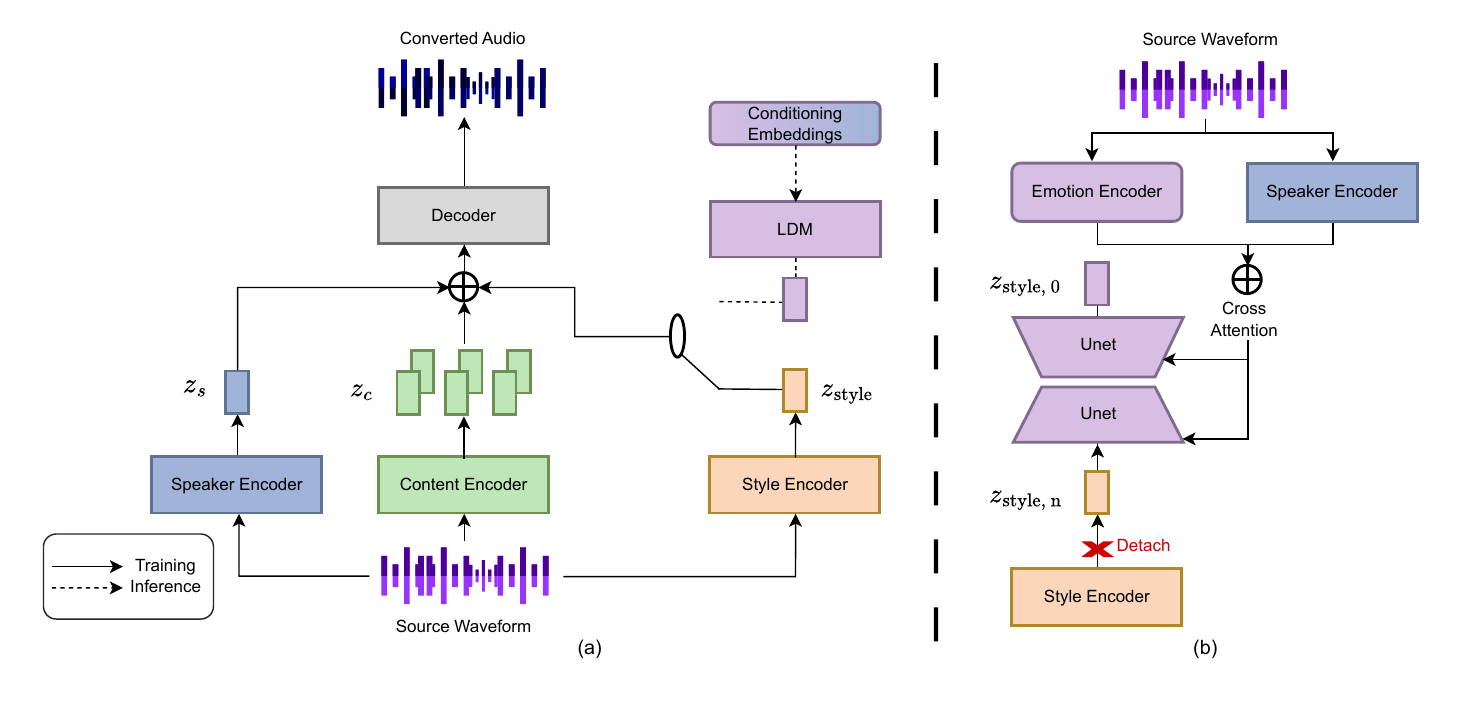
TargetSEC is an encoder-decoder resynthesis system with three representational branches: content, speaker, and style. A separate emotion encoder provides conditioning for the latent diffusion model. During backbone training, the model uses ground-truth style embeddings. During inference, that style encoder is removed and replaced by a diffusion model that generates the style embedding from speaker identity and target emotion.
The decoder is a HiFi-GAN V1 waveform generator. The design follows the broader encoder-decoder template used in recent latent-diffusion speech systems, but the conditioning interface is simplified: instead of textual descriptions, the model uses structured emotion and speaker inputs.
Representation disentangling
The paper uses pretrained encoders for all upstream features, and keeps them frozen during training. This makes the system closer to a modular SEC pipeline than an end-to-end generator.
Content encoder
A pretrained HuBERT encoder extracts a sequence of downsampled continuous content features $E_c(x) = (c_1, \ldots, c_L)$ from an input waveform $x$. These features are quantized with $k$-means into discrete tokens $u \in \{1, \ldots, K\}$, which are then mapped into a 128-dimensional continuous space. The model uses fixed-length windows; with HuBERT operating at 50 Hz, a segment of length $S$ seconds yields a content tensor $z_c \in \mathbb{R}^{L \times 128}$ with $L = 50S$.
Speaker encoder
Speaker identity is represented by a pretrained WavLM-based speaker verification model that outputs a 512-dimensional utterance-level d-vector $z_s$. This vector is broadcast across time and concatenated with the content representation, yielding a speaker-aware representation.
Style encoder
The training target for the diffusion model is a 128-dimensional global style vector $z_{\text{style}}$ produced by a pretrained style encoder from MetaStyleSpeech. The style encoder is only used during training of the diffusion prior; at inference it is replaced by the generated style vector. The paper chooses this encoder because of its reported ability to generalize zero-shot to unseen speakers and because it has been effective in related style conversion systems.
Emotion encoder
Emotional conditioning comes from a pretrained speech emotion recognition model fine-tuned on MSP-Podcast v1.7. It produces a 1024-dimensional emotion embedding $z_e$ together with continuous predictions for arousal, valence, and dominance. The paper uses this embedding both as conditioning for the diffusion model and as part of the evaluation pipeline for measuring conversion success.
Latent diffusion model
The diffusion module models a conditional prior over style embeddings, written as $p(z_{\text{style}} \mid z_s, z_e)$. In other words, the model learns to predict what style embedding should correspond to a given speaker and a given target emotion.
Rather than predicting noise directly, TargetSEC predicts the velocity parameterization, following recent diffusion work that reports improved stability. The training objective is:
$$ \mathcal{L}_v = \mathbb{E}_{n,\, z_{\text{style}},\, \epsilon}\left[\lVert v_n - v_\theta(z_{\text{style},n}, n, z_s, z_e) \rVert_2^2\right] $$
where the target velocity is defined as:
$$ v_n = \sqrt{\bar{\alpha}_n}\,\epsilon - \sqrt{1-\bar{\alpha}_n}\, z_{\text{style}}. $$
The forward diffusion process adds Gaussian noise to the style vector, and the network is trained to denoise in velocity space. The paper states that this parameterization is used to improve generation stability compared with standard noise prediction.
At inference time, TargetSEC uses classifier-free guidance (CFG) to steer generation toward the target emotion. The conditional and unconditional predictions are combined as
$$ v_{\text{cfg}} = v_{\text{unc}} + w\,(v_{\text{cond}} - v_{\text{unc}}), $$
where $w$ is the guidance scale. To reduce artifacts, the authors additionally apply guidance rescaling and obtain a final velocity $\tilde{v}$.
Loss function and training objective
The overall generator objective combines adversarial learning, feature matching, waveform reconstruction, and emotion alignment:
$$ L_G = \sum_k \bigl( L_{\text{adv}}(D_k) + \lambda_{\text{fm}} L_{\text{fm}}(D_k) \bigr) + \lambda_{\text{rec}} L_{\text{rec}} + \lambda_{\text{emo}} L_{\text{emo}}. $$
Here, $L_{\text{adv}}$ and $L_{\text{fm}}$ follow the HiFi-GAN adversarial and feature-matching setup. $L_{\text{rec}}$ is the $L_1$ distance between mel-spectrograms of the reference and synthesized audio. The emotion term $L_{\text{emo}}$ encourages the synthesized speech to match the target arousal by minimizing the Concordance Correlation Coefficient-based error:
$$ L_{\text{emo}} = 1 - \frac{2\rho\sigma_e\sigma_{\hat{y}}}{\sigma_e^2 + \sigma_{\hat{y}}^2 + (\mu_e - \mu_{\hat{y}})^2}, $$
where $\mu$ and $\sigma$ denote mean and variance, and $\rho$ is the Pearson correlation coefficient.
The paper fixes the loss weights to $\lambda_{\text{fm}} = 2$, $\lambda_{\text{rec}} = 45$, and $\lambda_{\text{emo}} = 1$.
Inference procedure
During inference, the learned style encoder is replaced by the latent diffusion prior. Following prior SEC evaluation practice, the target emotion embedding is built from the training set by averaging the top 20% of samples associated with the desired arousal level. This averaged embedding, together with the speaker embedding, conditions the diffusion model to generate an emotion-aligned style vector, which is then passed to the decoder.
The paper’s key systems-level claim is that this provides a form of emotion conversion without explicit temporal modeling. The model changes style while keeping the underlying resynthesis backbone unchanged.
Experimental setup
Dataset
Experiments are conducted on MSP-Podcast v1.10, an in-the-wild emotional speech corpus with more than 150,000 labeled clips, corresponding to approximately 230 hours of audio. The official train split is further partitioned into an 80/20 split, and the official Test1 partition is reserved for evaluation.
Training strategy
All feature extractors are pretrained and frozen: lexical/content, speaker, emotion, and style. Training proceeds in two phases. First, the encoder-decoder backbone is trained to reconstruct audio from ground-truth style embeddings using fixed-length 2.5 s segments. Second, the latent diffusion model is trained to predict the style embeddings conditioned on speaker and emotion representations.
Optimization uses AdamW with task-specific learning rates. The diffusion process uses $N = 1000$ steps with a linear noise schedule $\beta \in [10^{-4}, 0.02]$. At inference time, the authors use 100 diffusion steps, guidance scale $w = 4$, and rescaling factor $\phi = 0.7$.
Evaluation metrics
Because the training data are non-parallel, evaluation is objective and non-intrusive. The paper reports Wav2Vec-MOS (WVMOS) as a proxy for speech naturalness. For emotion conversion accuracy, it uses the emotion recognition model as a surrogate SER system and measures the arousal error between target and synthesized speech. The authors also extend prior evaluation by adding an objective speaker-verification-based identity measure.
Confidence intervals are computed across source utterances, averaged over all target emotions for each source sample.
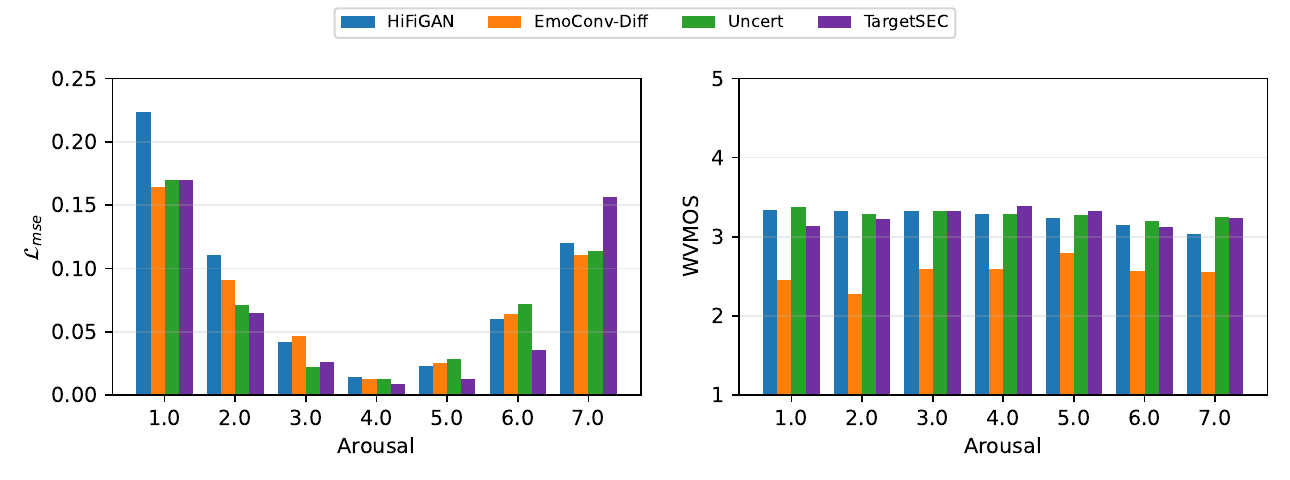
Baselines
The paper compares TargetSEC against three in-the-wild SEC systems:
- HiFiGAN: the backbone architecture used as a direct baseline, with direct emotion embedding injection.
- EmoConv-Diff: a diffusion baseline that operates on mel-spectrograms.
- Uncert: a duration-prediction extension of the HiFiGAN baseline.
TargetSEC is positioned as the non-duration latent-diffusion alternative that improves emotion conversion while keeping the synthesis backbone unchanged.
Main results
The main quantitative result is that TargetSEC achieves the best conversion error among the non-duration baselines, while maintaining naturalness close to the HiFiGAN backbone and far above spectrogram diffusion. The paper reports an MSE of $0.0677$ with 95% CI $[0.0674, 0.0679]$ and notes that this is comparable to the duration-prediction system Uncert.
| Model | Duration prediction | WVMOS | $L_{\text{mse}}$ | $L_{\text{abs}}$ |
|---|---|---|---|---|
| HiFiGAN | No | 3.26 | 0.084 | 24% |
| EmoConv-Diff | No | 2.56 | 0.072 | 21% |
| Uncert (HiFiGAN + DP) | Yes | 3.30 | 0.069 | 20% |
| TargetSEC | No | 3.25 | 0.068 | 21% |
In terms of naturalness, TargetSEC reaches WVMOS 3.25, essentially matching the HiFiGAN baseline at 3.26 and substantially outperforming EmoConv-Diff at 2.56. This is one of the paper’s key empirical claims: diffusion in latent style space avoids the quality degradation observed when diffusion is applied directly to spectrograms.
On conversion accuracy, TargetSEC attains the best result among non-duration methods and approaches the duration-prediction baseline. The authors interpret this as evidence that latent diffusion can deliver strong emotion shift without the need for explicit temporal modeling in typical mid-range arousal settings.
Arousal-wise behavior
The paper analyzes performance across target arousal values and observes a clear pattern. TargetSEC performs best, or is at least competitive, in the mid-to-high arousal range from 2 to 6, which the authors state covers most in-the-wild speech. In this range, it can even outperform the duration-based Uncert system at moderately expressive levels such as arousal 2 and 6.
Performance worsens at the extremes, arousal 1 and 7. The explanation given is that very low or very high arousal often corresponds to changes in speaking rate and temporal structure, such as slower speech in boredom or faster speech in anger. Because TargetSEC uses a fixed-duration mapping and does not explicitly model temporal expansion or compression, it cannot fully capture these edge cases.
A second important observation is that TargetSEC is emotionally more stable than the direct-injection baseline. The HiFiGAN baseline degrades in naturalness as arousal increases, while TargetSEC maintains a much flatter WVMOS profile across the arousal spectrum. The authors attribute this to the latent diffusion prior being more robust to high-variance prosody than direct emotion injection.
Speaker identity preservation
The paper also reports an objective speaker-preservation analysis using cosine similarity between source and converted speech embeddings from a pretrained ECAPA-TDNN speaker verification model. The random-pair baseline is $0.05 \pm 0.09$, while the intra-speaker similarity of ground-truth samples is $0.58 \pm 0.17$; the latter is relatively low and variable because MSP-Podcast is acoustically complex and in-the-wild.
TargetSEC reaches $0.29 \pm 0.11$, which is much higher than random and indicates that speaker identity is largely retained, though not perfectly. The paper presents this as a reasonable trade-off: stronger emotional modification naturally risks some loss of identity cues, but the output remains clearly tied to the source speaker rather than collapsing to an average voice.
Ablation study
The ablation study examines two design choices: whether the mapping is diffusion-based or deterministic, and whether speaker conditioning helps when combined with emotion conditioning. The authors compare four configurations.
| Model configuration | Diffusion | WVMOS | $L_{\text{mse}}$ | $L_{\text{abs}}$ |
|---|---|---|---|---|
| MLP (Emotion only) | No | 3.44 | 0.083 | 24% |
| MLP (Speaker + Emotion) | No | 3.45 | 0.080 | 24% |
| LDM (Emotion only) | Yes | 3.21 | 0.070 | 22% |
| TargetSEC (full) | Yes | 3.25 | 0.068 | 21% |
The ablation supports two conclusions. First, deterministic MLP baselines achieve high naturalness but poor emotion control because they tend to regress toward the dataset’s mean prosody. Second, adding diffusion substantially improves conversion accuracy, and adding speaker conditioning on top of diffusion yields the best overall performance. The final system therefore benefits from both probabilistic modeling and identity-aware conditioning.
Interpretation of the design choices
The paper’s broader methodological point is that SEC for in-the-wild speech is less about generating raw audio from scratch and more about controlling a latent expressive manifold. By learning a conditional prior over style embeddings, TargetSEC confines the most difficult part of emotion conversion to a low-dimensional space while leaving the high-fidelity decoder untouched.
This explains the observed quality/conversion trade-off: direct spectrogram diffusion can struggle with signal fidelity, while direct style injection is too weak to produce accurate emotion shifts. TargetSEC sits between these extremes by using diffusion to generate a richer style embedding, but still decoding through a stable HiFi-GAN synthesis model.
Limitations and future work stated by the paper
The paper explicitly identifies a structural limitation: because TargetSEC does not model duration, it cannot capture the speech-rate and timing changes associated with extreme arousal values. This is reflected in the degradation at arousal 1 and 7. The authors suggest that explicit duration prediction is necessary if the goal is to handle these extreme emotional states robustly.
A second limitation is that the work only controls arousal. The modular diffusion design could, in principle, be adapted to other style descriptors such as valence, dominance, or speaker attributes, but this is left for future work.
The paper also notes that further evaluation should include subjective speaker-similarity testing, since the current identity analysis is objective and the speaker similarity numbers remain well below the ground-truth upper bound.
Conclusion
TargetSEC is presented as a compact, modular SEC framework for in-the-wild speech. Its main result is that latent diffusion over style embeddings can improve emotion conversion accuracy while preserving speech quality, without requiring explicit duration modeling. On MSP-Podcast Test1, the system outperforms the non-duration baselines, matches the quality of the direct HiFi-GAN backbone, and remains competitive with a duration-prediction system in the arousal ranges that dominate real-world data.
The paper’s take-home message is that an emotion-conditioned latent prior is a practical way to introduce expressive control into speech synthesis, but explicit temporal modeling will likely be needed to handle the most extreme emotional states.