Whisper Hallucination Steering
Whisper Hallucination Detection and Mitigation via Hidden Representation Steering and Sparse AutoEncoders
This paper detects and mitigates hallucinations in Whisper ASR outputs by steering internal audio encoder representations, especially via sparse autoencoder latents. It reduces hallucinations at inference time without fine-tuning, maintaining transcription quality.
Links
Paper & demos
Code & resources
Impact
Abstract
Whisper, a widely adopted ASR model, is known to suffer from hallucinations - coherent transcriptions generated for non-speech audio entirely disconnected from the input. We investigate whether hallucinations can be detected and mitigated through Whisper's internal representations. We extract audio encoder activations and evaluate two representation spaces: raw Whisper activations and Sparse AutoEncoder (SAE) latents. We show that both spaces encode linearly separable hallucination-related information, with discriminative power concentrated in a sparse feature subset and increasing toward deeper encoder layers. We propose two steering strategies: activation-space steering and SAE latent-space steering. SAE-based steering reduces hallucination rate from 72.63% to 14.11% for Whisper small and from 86.88% to 27.33% for Whisper large-v3 on the full non-speech test set, with small WER degradation on speech data, approaching the performance of fine-tuning-based methods.
Introduction
This paper studies hallucinations in Whisper, focusing on the failure mode where the ASR model emits fluent, coherent transcripts for non-speech audio that are unrelated to the input signal. The authors adopt the paper's operational definition of hallucination as coherent output disconnected from the input, and they concentrate on the common case of assigning transcripts to silence, noise, and other non-speech segments.
The core question is whether hallucinations are already detectable in Whisper's internal encoder representations, and whether those same representations can be modified at inference time to suppress hallucinations without fine-tuning the model. The paper answers both in the affirmative: hallucination-related information is linearly decodable from both raw encoder activations and Sparse AutoEncoder (SAE) latents, and both representation spaces can be steered to reduce hallucinations. The strongest results come from SAE-based steering, which substantially lowers hallucination rate while keeping speech recognition quality reasonably close to the unsteered model.
Two Whisper variants are evaluated: Whisper small and Whisper large-v3. The paper's main empirical claim is that hallucination-relevant information becomes more separable in deeper encoder layers, and that only a small subset of SAE features is needed to predict and steer hallucinations effectively.
Problem formulation and metrics
The authors use Whisper's own inference-time filter signals, no_speech_prob and avg_logprob, to define a sample-level detection rule. Let $p_i$ denote no_speech_prob and $l_i$ denote avg_logprob for sample $i$. A sample is counted as speech-containing if it passes the default Whisper thresholds $\tau_p = 0.6$ and $\tau_l = -1.0$; otherwise it is suppressed.
The paper defines Detection Rate as
$$ \mathrm{DR}(\mathcal{D}) = \frac{1}{|\mathcal{D}|} \sum_{i=1}^{|\mathcal{D}|} \mathbb{I}\{p_i < \tau_p \;\lor\; l_i > \tau_l\}. $$
For non-speech data, Hallucination Rate is simply $\mathrm{HR} = \mathrm{DR}$, i.e. the fraction of non-speech samples that are incorrectly treated as speech. For speech data, the paper uses $\mathrm{HR} = 1 - \mathrm{DR}$ to quantify over-suppression of genuine speech. Speech quality is measured with WER for English and CER for Chinese.
A key point is that the hallucination labels used for classifier training are not human annotations; they are derived from Whisper's own filtering rule on non-speech data. The work therefore analyzes and mitigates hallucination behavior relative to Whisper's internal decision boundary.
Background: raw activations, SAE latents, and steering
The paper compares two representation spaces extracted from Whisper's audio encoder:
- Raw Whisper activations: residual-stream hidden states from each encoder layer, averaged across time to obtain a fixed-size vector per segment.
- SAE representations: sparse latent vectors produced by AudioSAE checkpoints trained on Whisper encoder activations, then aggregated over time using non-zero average pooling.
The SAE architecture uses an expansion coefficient of $8$, producing latent dimensions of $6144$ for Whisper small ($8 \times 768$) and $10240$ for Whisper large-v3 ($8 \times 1280$). The checkpoints use a Batch-Top-$k$ design with $k=50$, so exactly 50 SAE latents are active per token during inference.
For both representation spaces, the authors train linear classifiers to test whether hallucination-related information is linearly separable. For SAE latents, the classifier's coefficients are also used as feature-importance scores to identify the most discriminative sparse dimensions, which then define the steering mask.
They investigate two families of inference-time interventions:
- Activation steering, which adds a contrastive direction to the hidden state.
- SAE latent steering, which modifies selected sparse features before reconstructing the activation and reinjecting it into the encoder stream.
Activation-space steering
The activation steering vector is constructed from contrastive means over hallucinating and non-hallucinating samples:
$$ \mathbf{v} = \frac{1}{|\mathcal{N}|} \sum_{i \in \mathcal{N}} \mathbf{h}^{(i)}_l - \frac{1}{|\mathcal{H}|} \sum_{i \in \mathcal{H}} \mathbf{h}^{(i)}_l, $$
where $\mathbf{h}^{(i)}_l$ is the residual-stream activation at layer $l$ for sample $i$, $\mathcal{N}$ is the non-hallucinating set, and $\mathcal{H}$ is the hallucinating set. At inference time, steering is applied as
$$ \tilde{\mathbf{h}}^{(t)}_l = \mathbf{h}^{(t)}_l + \alpha \mathbf{v}, $$
with scalar coefficient $\alpha$ controlling the intervention strength.
SAE latent-space steering
For SAE steering, the classifier's feature-importance scores $\boldsymbol{\beta}$ are used to select the top-$k$ sparse dimensions with the largest $|\beta_j|$. The sign is flipped to move away from hallucination-promoting features. The paper defines a sparse direction vector $\mathbf{s} \in \{-1,0,1\}^m$ and an average latent-magnitude vector $\bar{\mathbf{Z}}$ computed on the reference data. Two steering variants are considered:
Additive steering:
$$ \mathbf{z}' = \mathbf{z} + \alpha \; \mathbf{s} \odot \bar{\mathbf{Z}}. $$
Multiplicative steering:
$$ \mathbf{z}' = \mathbf{z} \odot \alpha^{\mathbf{s}}. $$
The steered latent is then decoded back to activation space and injected into the encoder. A central empirical finding is that additive steering is more reliable than multiplicative steering because multiplicative steering cannot change a latent dimension that is currently zero; if a feature is inactive, it remains untouched regardless of importance. Additive steering can still move those dimensions.
Experimental setup
Models and decoding
The experiments use Whisper small and Whisper large-v3. Inference uses greedy decoding with default Whisper options, with temperature set to zero and beam search disabled. SAE inference relies on the AudioSAE Batch-Top-$k$ checkpoints trained on Whisper activations.
Datasets
The paper separates data into non-speech sets for hallucination analysis / steering and speech sets for measuring transcription quality. Splits are carefully isolated: classifiers are trained, steering vectors are computed, and hyperparameters are tuned only on non-speech train data; the non-speech test split is reserved for final evaluation.
| Dataset | Subset | Type | Split | N samples |
|---|---|---|---|---|
| MUSAN Noise | noise | Non-speech | Train | 930 |
| WHAM! | tr | Non-speech | Train | 20000 |
| FSD50k | dev | Non-speech | Train | 40966 |
| FSD50k-filtered | dev | Non-speech | Train | 38607 |
| FULL | — | Non-speech | Train | 61896 |
| UrbanSound8K | — | Non-speech | Test | 8732 |
| WHAM! | cv / tt | Non-speech | Test | 8000 |
| FSD50k | eval | Non-speech | Test | 10231 |
| FSD50k-filtered | eval | Non-speech | Test | 9127 |
| FULL | — | Non-speech | Test | 26963 |
| LibriSpeech | test-clean | Speech (EN) | Test | 2620 |
| LibriSpeech | test-other | Speech (EN) | Test | 2939 |
| FLEURS | en | Speech (EN) | Test | 647 |
| FLEURS | zh | Speech (ZH) | Test | 945 |
| AISHELL-1 | — | Speech (ZH) | Test | 141600 |
The authors also define an FSD50k-filtered subset that removes labels containing the words speech, music, or human. This yields 3,463 retained samples in both train and test splits. The FULL train/test sets are unions of the respective non-speech splits and contain 61,896 and 26,963 samples.
Classification protocol
Hallucination detection is posed as a binary classification problem, independently for each encoder layer. The classifier is logistic regression from scikit-learn with the saga solver, preceded by MaxAbsScaler normalization. The evaluation uses stratified 5-fold cross-validation, with the scaler fit only on the training portion of each fold. The paper reports AUC as the threshold-independent separability metric.
For SAE latents, the same protocol is used, and the averaged classifier weights provide feature importance scores for steering. The paper later shows that hallucination-relevant signal is concentrated in a small number of SAE features, enabling sparse steering masks.
Steering protocol
All steering hyperparameters are tuned by grid search on non-speech train data using HR as the primary objective, while WER/CER are monitored to ensure speech quality does not collapse. The steering point is the final encoder layer, chosen because the layer-wise classifiers show the strongest separability there. The paper then evaluates single-layer and multi-layer variants under the tuned hyperparameters.
Baseline hallucination rates
The raw Whisper models hallucinate heavily on non-speech data, but the rate depends strongly on dataset and model size.
| Dataset | Whisper small train HR (%) | Whisper small test HR (%) | Whisper large-v3 train HR (%) | Whisper large-v3 test HR (%) |
|---|---|---|---|---|
| MUSAN Noise | 79.2 | — | 63.1 | — |
| WHAM! | 68.9 | 66.9 | 93.1 | 92.0 |
| FSD50k | 80.6 | 81.9 | 69.0 | 75.0 |
| FSD50k-filtered | 80.2 | 80.8 | 68.5 | 73.6 |
| UrbanSound8K | — | 67.0 | — | 95.2 |
| FULL | 76.8 | 72.6 | 76.7 | 86.8 |
The notably high baseline HR on UrbanSound8K and WHAM! for Whisper large-v3 shows that more capable ASR does not eliminate hallucination risk; in fact, the stronger model can still be highly prone to generating non-speech transcripts on certain acoustics.
Results: hallucination detection in representation space
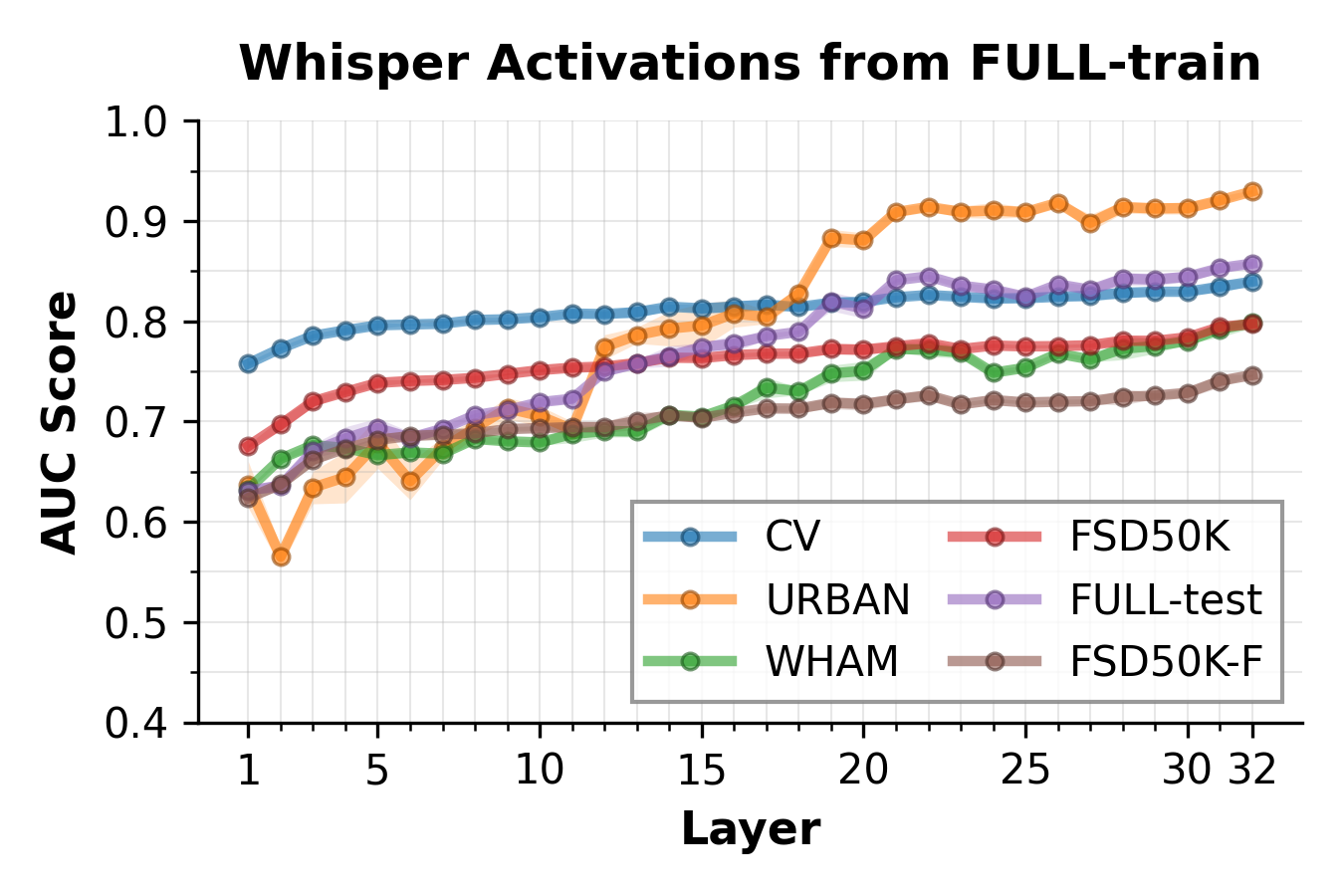
The first main result is that hallucination-related information is linearly separable in both raw encoder activations and SAE latents. The layer-wise AUC curves improve toward deeper encoder layers, indicating that the encoder progressively organizes the signal into a more discriminative space for this failure mode.
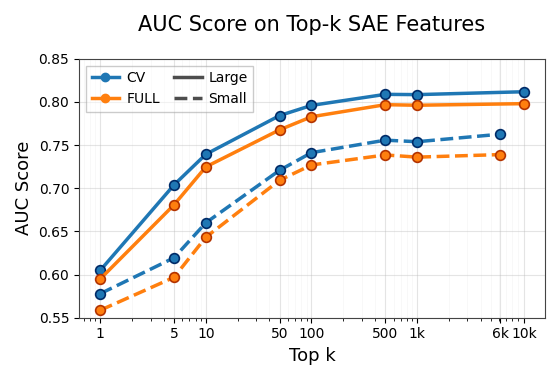
The top-$k$ ablation is especially important. Classification performance stabilizes once roughly 50 to 100 SAE features are retained, and gains beyond that are small. This is evidence that hallucination-relevant information is concentrated in a sparse subset of latent dimensions rather than distributed uniformly across the overcomplete SAE space.
In the layer-averaged comparison on the FULL-train setup, the reported AUC scores are as follows:
| Representation | Model | CV AUC | UrbanSound8K | WHAM! cv/tt | FSD50k eval | FSD50k-filtered eval | FULL test |
|---|---|---|---|---|---|---|---|
| Whisper | small | 0.77 | 0.71 | 0.75 | 0.77 | 0.77 | 0.76 |
| Whisper | large-v3 | 0.73 | 0.80 | 0.72 | 0.76 | 0.70 | 0.77 |
| SAE | small | 0.76 | 0.68 | 0.73 | 0.77 | 0.76 | 0.74 |
| SAE | large-v3 | 0.81 | 0.87 | 0.72 | 0.76 | 0.71 | 0.80 |
The paper emphasizes three takeaways from these numbers. First, both representations achieve above-chance AUC on all datasets. Second, the FULL-train set is the strongest or near-strongest training source for generalization to the FULL test set. Third, SAE latents are particularly strong for Whisper large-v3, where the FULL-test AUC reaches 0.80.
Layer-wise trends are consistent across datasets: later encoder layers are more discriminative than early layers. This motivates steering at the final encoder layer and supports the broader claim that hallucination-relevant information is more explicit deeper in the encoder.
Results: steering and hallucination mitigation
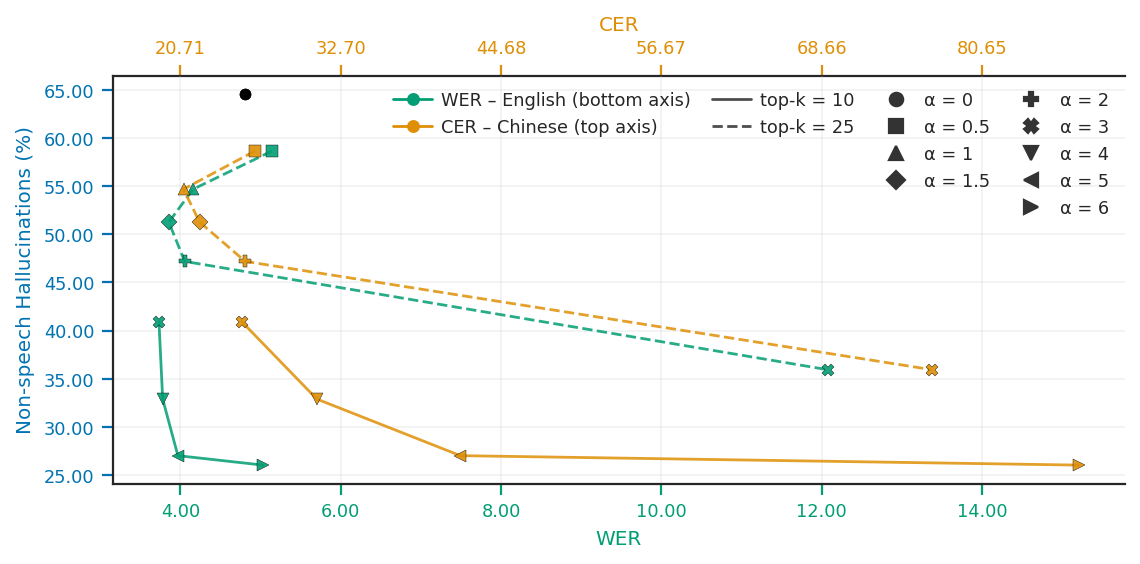
The paper evaluates steering with two objectives in tension: reduce hallucinations on non-speech audio and preserve speech recognition quality on English and Chinese speech. The experiments show that SAE-based steering is consistently more effective than raw activation steering for reducing hallucinations, especially when the steering mask is sparse.
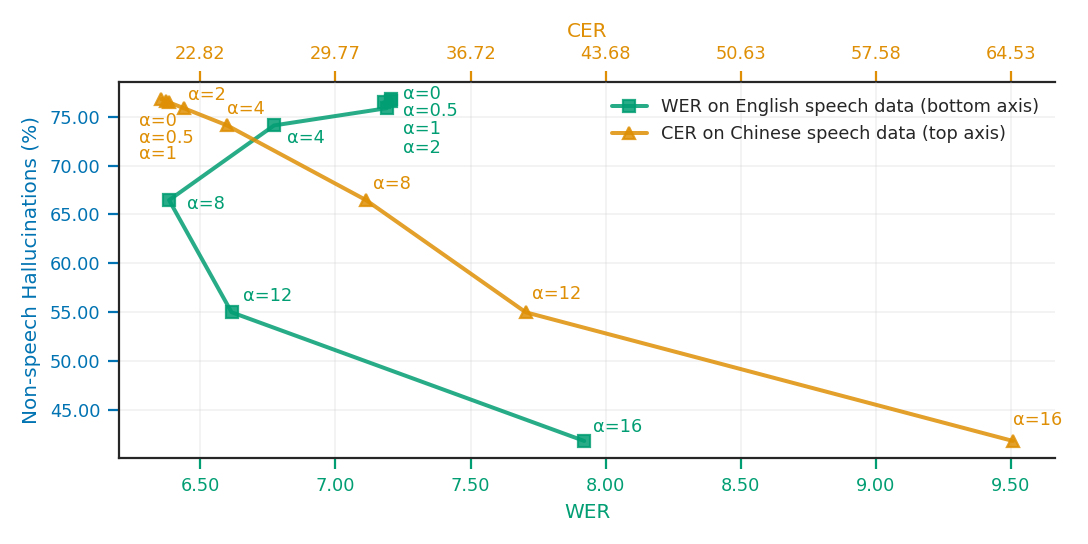
For activation steering, the tuned coefficients are relatively simple: the Pareto frontier suggests $\alpha=8$ for Whisper small and $\alpha=2$ for Whisper large-v3. However, the gains are limited. On the FULL non-speech test set, activation steering reduces HR from 72.63% to 40.60% for Whisper small when multiple late layers are steered together, and from 86.88% to 82.37% for Whisper large-v3 at its best reported setting. This is a meaningful but modest improvement compared with SAE-based steering.
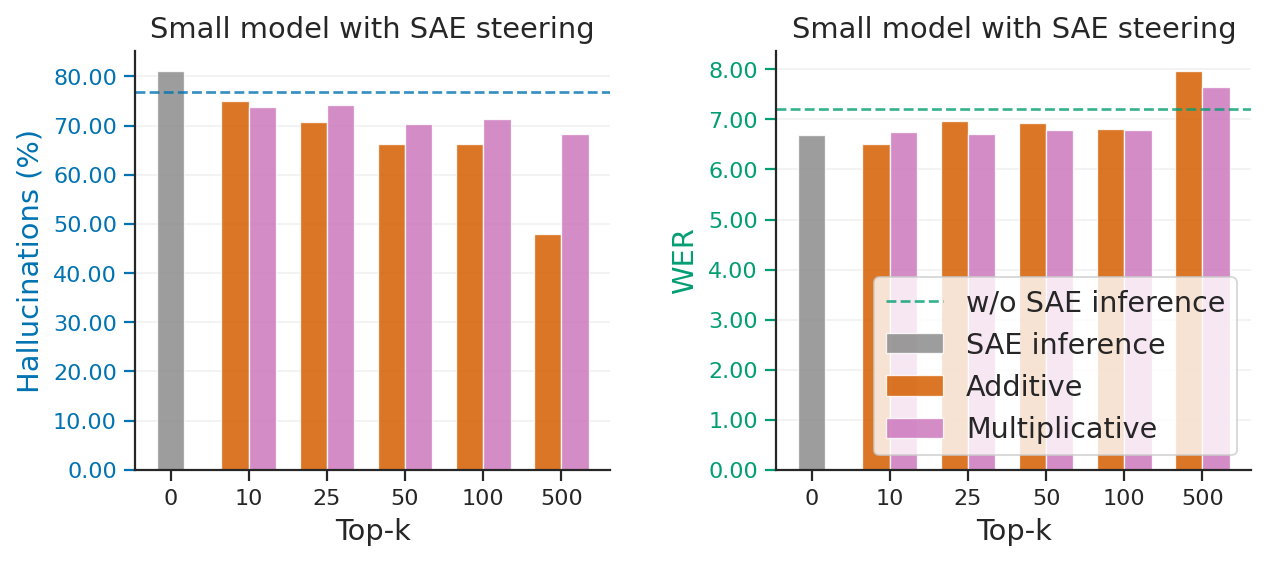
The SAE ablation comparing additive and multiplicative steering shows that the additive variant is preferable, particularly at small $k$. The reason is structural: multiplicative steering only rescales already active latents, so zero-valued features remain unchanged even if they are important for hallucination control. Additive steering can still perturb such latent dimensions. This makes the additive method more effective in the sparse SAE regime.
The authors therefore focus on additive steering in the final comparisons and keep $k$ small. For classification, performance saturates around 50 to 100 features, but for steering the best trade-off appears with much smaller masks, indicating that the steering signal itself can be localized even more tightly than the detection signal.
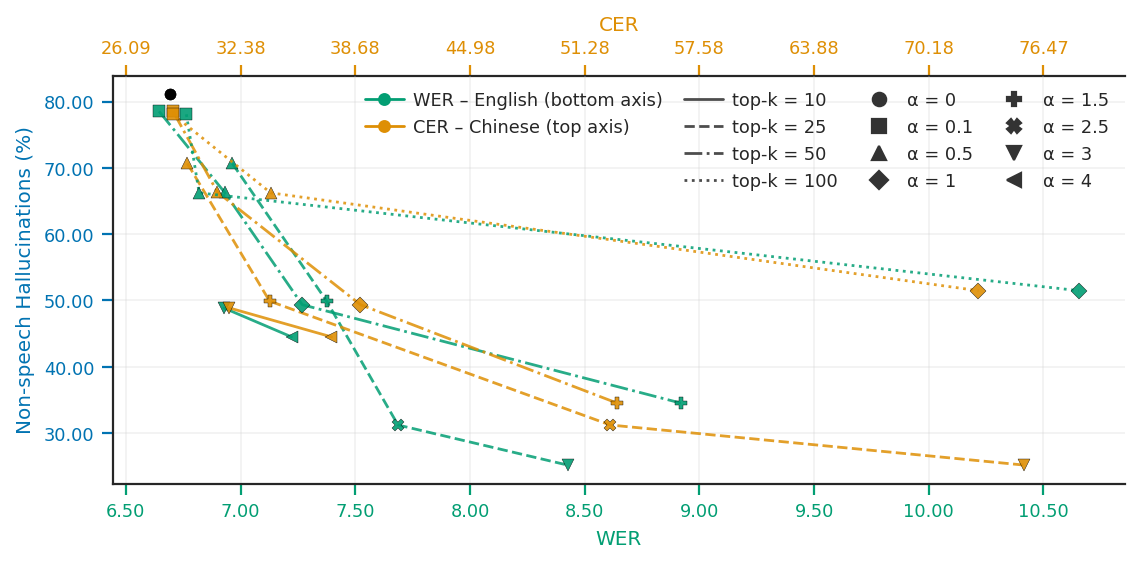
The strongest SAE results are obtained with late-layer or multi-layer interventions and small top-$k$ masks. The paper reports the following best configurations:
| Representation | Model | Layer | $\alpha$ | top-$k$ | Urban HR (%) | WHAM HR (%) | FSD50k HR (%) | FULL HR (%) | LibriSpeech clean WER | LibriSpeech other WER | FLEURS en WER | FLEURS zh CER | AISHELL-1 CER |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SAE | small | 12 | 3 | 25 | 8.68 | 4.68 | 26.12 | 14.11 | 4.45 | 11.34 | 12.38 | 79.01 | 92.98 |
| SAE | large-v3 | 26+32 | 3.5 | 10 | 19.88 | 27.05 | 33.92 | 27.33 | 3.70 | 7.58 | 8.73 | 59.92 | 66.24 |
These are the paper's headline mitigation results. For Whisper small, HR on the FULL non-speech test set falls from 72.63% to 14.11%. For Whisper large-v3, HR drops from 86.88% to 27.33%. These reductions are much larger than those obtained with activation steering.
The paper also notes that very aggressive steering can be destructive. In the SAE table, some settings nearly eliminate hallucinations but cause catastrophic speech degradation, especially for Chinese. This is visible in the very large CER values when steering is too strong or when the SAE pipeline is applied to out-of-domain speech. The authors explicitly attribute part of the Chinese degradation to the SAE not being trained on Chinese speech data.
Comparison with Calm-Whisper
To contextualize performance, the paper compares against Calm-Whisper, which intervenes on decoder self-attention heads and reports both masking-only and fine-tuned variants. On Whisper large-v3, the comparison is:
| Method | HR (%) on UrbanSound8K | clean WER | other WER |
|---|---|---|---|
| Baseline | 95.98 | 2.11 | 4.02 |
| Calm-Whisper (masking) | 24.10 | 3.57 | 5.98 |
| Calm-Whisper (fine-tuned) | 15.51 | 2.19 | 4.13 |
| Activation steering | 90.21 | 4.11 | 6.73 |
| SAE steering (32 layer) | 30.68 | 2.38 | 4.87 |
| SAE steering (26+32 layers) | 19.88 | 3.70 | 7.58 |
The main comparison points are:
- SAE steering is substantially better than activation steering for hallucination reduction.
- The best SAE result approaches the masking-only Calm-Whisper regime and comes within reach of the fine-tuned Calm-Whisper HR on UrbanSound8K.
- Unlike Calm-Whisper, this paper's method operates on the encoder side, implying that hallucination-relevant structure is already present in the encoder representation before decoding begins.
Interpretation and limitations
The results support the paper's central interpretation: Whisper hallucinations are not just a decoder-generation artifact; they are already encoded in the audio encoder's hidden states, and these states contain a sparse linear signal that can be exploited both for detection and for mitigation. The increasing AUC with depth suggests that later encoder layers sharpen the hallucination vs. non-hallucination boundary, which is why the final layer is the best intervention point in the paper's setup.
Several limitations are evident from the reported experiments:
- Heuristic labels: hallucination labels come from Whisper's own thresholding rule, not manual annotation.
- Language mismatch: Chinese speech quality, especially CER, can degrade sharply under SAE-based interventions because the SAE is not trained on Chinese data.
- Trade-off sensitivity: stronger steering can reduce hallucinations dramatically but may also harm speech recognition, especially on multilingual evaluation.
- Limited activation steering: raw activation addition helps, but it is consistently weaker than SAE steering in the reported setups.
- Single-family SAE training: the paper suggests that multilingual SAE training could improve robustness.
The authors explicitly point to multilingual SAE training and multi-layer steering as future directions. These are natural extensions because the current SAE intervention is strongest when the feature basis matches the speech domain well, and because the best hallucination suppression sometimes comes from combining late layers.
Conclusion
This paper demonstrates that Whisper hallucinations can be both detected and mitigated through internal representations alone. Raw encoder activations and SAE latents both linearly encode hallucination-related information, but the SAE space is especially useful because the signal is sparse and localized. In mitigation experiments, SAE-based steering consistently outperforms activation steering and achieves substantial hallucination reduction without fine-tuning the Whisper weights.
The strongest reported SAE configuration lowers FULL-test hallucination rate to 14.11% for Whisper small and 27.33% for Whisper large-v3, while preserving a usable level of speech recognition quality on English and partially matching the effect of fine-tuned decoder-head masking methods. The paper's practical takeaway is that encoder-side sparse representation steering is a viable, fine-tuning-free tool for controlling ASR hallucinations.
Code & Implementation
This repository provides core inference and interpretability utilities for Sparse AutoEncoders (SAEs) trained on encoder layers of Whisper and HuBERT models, as described in the paper. It allows loading pretrained SAEs, running them on Whisper or HuBERT activations, extracting sparse feature representations, and performing analyses to understand the features learned by the model.
The main implementation lives in the audio_sae package, which includes:
BatchTopKSAEmodel classes for sparse autoencoding.- Interpretability tools in
interp.pyfor reconstruction quality metrics, feature activation analysis, classification of feature types, and visualizations. - Model wrappers in
audio_sae/modelsthat expose Whisper or HuBERT encoder activations for SAE input.
The repo provides example notebooks demonstrating inference with Whisper and interpretability workflows.
Training and feature-steering code used in the paper is not included here; this repo focuses on pretrained SAE inference and analysis. SAE checkpoints are hosted externally on the HuggingFace Hub.