Wispy to Voluminous
Wispy to Voluminous: Prior-free Multi-view Capture of Strand-level Facial Hair

This work presents a prior-free multi-view pipeline that reconstructs explicit 3D strand-level facial hair from optimized 3D Gaussian fields. It uniquely produces editable, sparse hair strands for beards, mustaches, eyebrows, and lashes, supporting animation and simulation unlike volumetric or learned-prior approaches.
Links
Paper & demos
Abstract
Facial hair is a defining trait of personal identity, yet remains a critical bottleneck for digital avatars. Recent volumetric methods achieve photorealism but bake hair into the underlying face geometry, preventing editability and failing to resolve sparse, strand-like structures. Meanwhile, scalp-hair reconstruction methods target dense hair volumes and do not transfer to the sparse, spatially-varying nature of facial hair. We present a pipeline that automatically reconstructs facial hair -- beard, mustache, lashes, and brows -- from multi-view images, converting an unstructured 3D Gaussian representation into an explicit curve-based strand representation. We resolve geometric ambiguities in four stages: (i) optimizing 3D Gaussians constrained by tracked head geometry to enforce early ray termination and suppress sub-surface noise; (ii) tracing continuous strands robust to frequent crossings and extreme curvature; (iii) grounding strands to the surface and resolving root-tip ambiguity via a physically-motivated prior; and (iv) refining the reconstruction through opacity-driven density control under photometric optimization. To our knowledge, this is the first method to reconstruct high-fidelity facial hair strands from a 3D Gaussian representation. The recovered strands faithfully preserve the orientation and sparsity patterns characteristic of facial hair, and yield assets immediately suitable for downstream production tasks, including facial animation and physical simulation, geometric grooming and transfer, appearance editing, and physics-based rendering.
Introduction
This paper addresses a long-standing gap in digital human modeling: reconstructing facial hair as explicit, editable strands rather than as baked appearance or volumetric density. The motivation is practical as much as geometric. Eyebrows shape expression, eyelashes affect gaze realism, and beards and mustaches are central to identity and style. Yet facial hair is especially difficult to capture because it is sparse, locally structured, tightly coupled to the facial surface, and often contains frequent crossings and occlusions. These properties make strand-level accuracy important, because errors cannot be hidden inside a dense volume the way they sometimes can in scalp hair reconstruction.
The paper argues that existing facial modeling systems fail for complementary reasons. Mesh-based pipelines usually omit facial hair or treat it as texture, leaving grooming to be done manually. Volumetric methods can look realistic, but they entangle geometry, appearance, and illumination in a representation that is poorly aligned with DCC tools and difficult to edit, simulate, or transfer. Meanwhile, scalp-hair reconstruction methods assume a dense, roughly uniform hair volume and typically rely on learned priors that do not generalize to the sparse, spatially varying patterns of facial hair. The core contribution is a prior-free pipeline that takes multi-view images and converts a 3D Gaussian representation into an explicit strand groom, supporting beard, mustache, eyebrow, and eyelash reconstruction.
The method is organized around four stages: depth-gated 3D Gaussian optimization, crossing-aware strand tracing, physically motivated grounding, and sparsity-aware refinement. The authors emphasize that this is, to their knowledge, the first method to reconstruct high-fidelity facial hair strands from a 3D Gaussian representation.

Problem Setup and High-level Goal
The input is a set of calibrated multi-view images under uniform illumination, together with a tracked facial mesh. The output is a set of explicit 3D curves, one per recovered hair strand, grounded to the face mesh. The paper’s goal is not merely to synthesize views, but to produce an asset that can be edited, transferred across subjects through shared UV topology, rendered with physically based hair shaders, and driven by downstream animation or simulation.
A key design choice is to use 3D Gaussian splatting as an intermediate representation. The authors exploit its ability to encode high-frequency directional structure while adding strong geometric constraints that force the optimization to stay on the hair side of the face-skin boundary. The representation is then transformed into curves through a sequence of geometric cleanup and tracing steps.
Method Overview
The full pipeline has four stages. Stage I optimizes a 3D Gaussian field from 2D orientation cues while preventing sub-surface leakage. Stage II filters the Gaussians, traces them into continuous strands, and stitches fragments. Stage III grounds the strands to the face mesh and resolves root-tip ambiguity separately for beards, eyebrows, and eyelashes. Stage IV performs a final photometric refinement with segment-level opacity control, pruning unsupported parts of strands while keeping the geometry compact and edit-friendly.
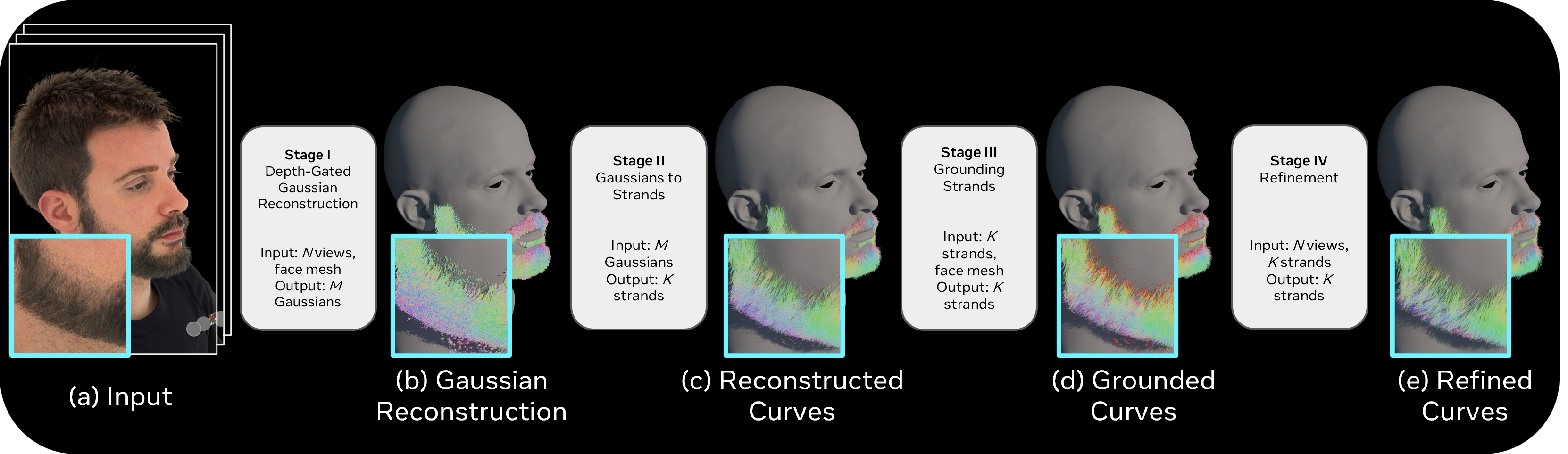
Stage I: Depth-Gated 3D Gaussian Optimization
The first stage lifts 2D orientation fields, computed from calibrated images with Gabor filters, into a 3D Gaussian orientation field. Each Gaussian’s orientation is defined by the principal axis of its covariance matrix. The authors use standard 3DGS alpha compositing,
$$
Q(p)=\sum_i T_i(p)\,\alpha_i(p)\,q_i(p), \qquad T_i(p)=\prod_{j
but modify the opacity term with a depth gate derived from the tracked face mesh. The mesh is rasterized to obtain a depth map $D_{\mathrm{mesh}}(p)$, and each Gaussian contribution is masked out when it lies behind the mesh surface:
$$
\tilde{\alpha}_i(p)=\mathbf{1}[d_i(p)\le D_{\mathrm{mesh}}(p)+\varepsilon]\,\alpha_i(p),
$$
with $
\\varepsilon=3\,\mathrm{mm}$ chosen to tolerate mesh registration error and the fact that hair roots can lie close to the skin. This simple gate is important because standard photometric optimization otherwise tends to place semi-transparent Gaussians along and behind the visible facial shell, creating noisy sub-surface artifacts that are hard to trace into strands later.
The Stage I objective combines photometric loss, orientation alignment, and hair-mask supervision:
$$
L_I = L_{\mathrm{rgb}} + \lambda_{\mathrm{dir}}L_{\mathrm{dir}} + \lambda_{\mathrm{mask}}L_{\mathrm{mask}},
$$
where $L_{\mathrm{rgb}}=(1-\lambda)L_1+\lambda L_{\mathrm{D\text{-}SSIM}}$ with $\lambda=0.2$, $\lambda_{\mathrm{dir}}=0.1$, and $\lambda_{\mathrm{mask}}=1.0$. The mask term compares the gated foreground opacity against the hair mask.
The paper’s ablations show that depth gating yields a visibly cleaner Gaussian field: without it, the optimizer spreads low-opacity primitives across the skin and hair support, while the gated version keeps primitives organized along strand trajectories. This improvement is not only cosmetic; it directly makes the downstream tracing stage more stable because sub-surface primitives are no longer available as false seeds or misleading neighbors.
Stage II converts the cleaned Gaussian field into polylines. It has three substeps: filtering, tracing, and stitching. The underlying idea is that facial hair strands can be recovered from a sparse directional point set if one uses opacity as a confidence signal and preserves connectivity carefully through crossings and fragments.
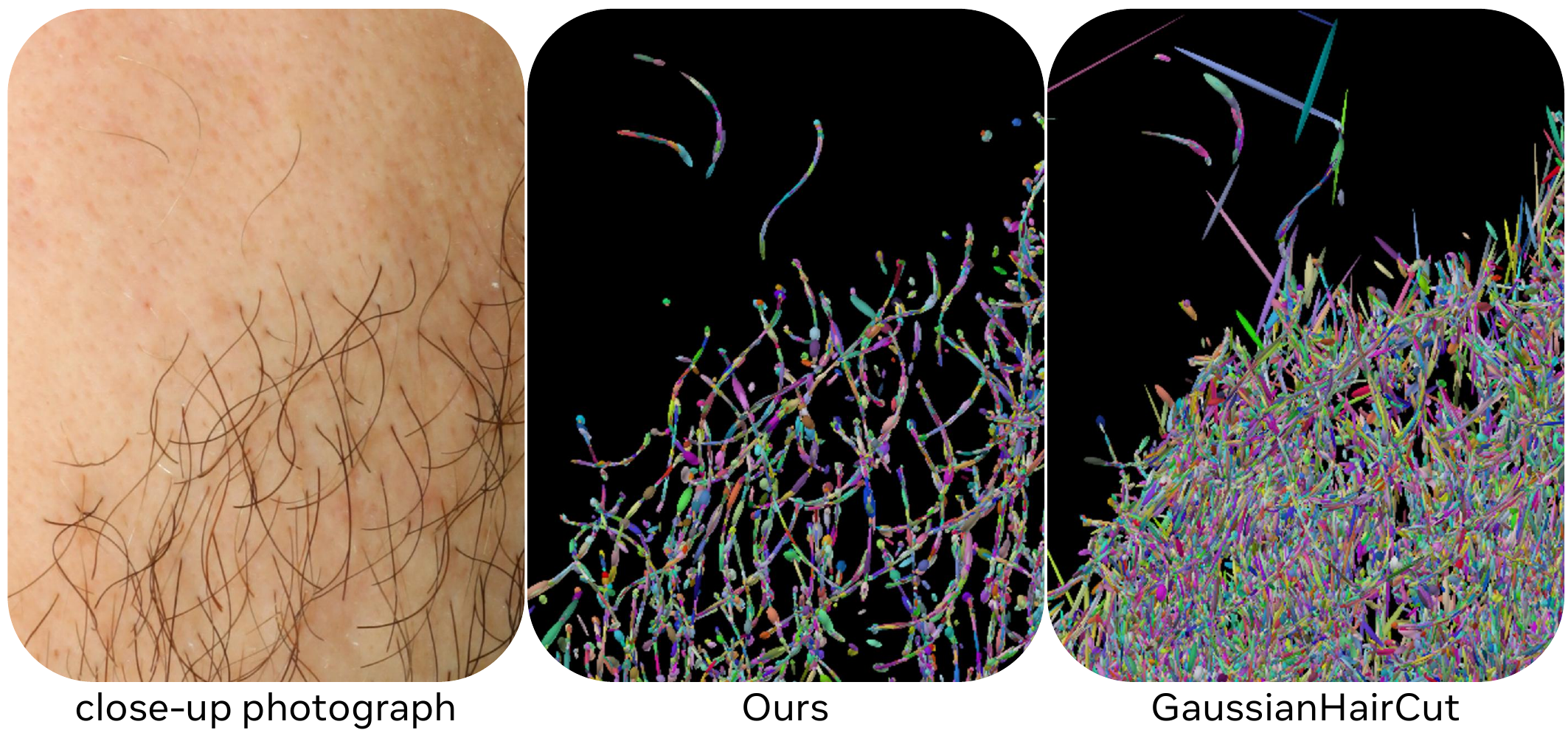
Even after depth-gated optimization, the Gaussian field still contains noise from specularities and view-averaging artifacts. The paper therefore filters Gaussians using three criteria: opacity thresholding, near-needle anisotropy measured by effective rank, and removal of centers that fall inside the tracked mesh. The authors then resample each Gaussian needle along its principal axis at roughly $0.1\,\mathrm{mm}$ spacing so that later tracing sees a more uniform directional point set.
A more detailed appendix description shows that the authors use opacity-weighted mean-shift updates. For a current state $(p^t,d^t)$, neighboring primitives contribute with weights
$$
\tilde{w}_i=\alpha_i^\lambda\exp\!\left(-\frac{\|p^t-x_i\|_2^2}{2\sigma_p^2}-\frac{\theta_i^2}{2\sigma_d^2}\right),
$$
where the opacity exponent down-weights unreliable low-opacity candidates. This helps consolidate the local directional mode before Euler tracing begins.
Once the field is cleaned, strands are traced by bidirectional Euler integration from high-opacity seeds. The step size is $0.3\,\mathrm{mm}$ for beard and eyebrow regions and $0.1\,\mathrm{mm}$ for eyelashes. At each step, the algorithm searches for neighboring Gaussians within a radius and with similar orientation, then updates the next position and tangent by opacity-weighted averaging:
$$
p_{n+1}=\frac{\sum_{k\in\mathcal{N}_{n+1}}\alpha_k\,\tilde\mu_k}{\sum_{k\in\mathcal{N}_{n+1}}\alpha_k}, \qquad
v_{n+1}=\operatorname{normalize}\!\left(\sum_{k\in\mathcal{N}_{n+1}}\alpha_k\,\tilde v_k\right).
$$
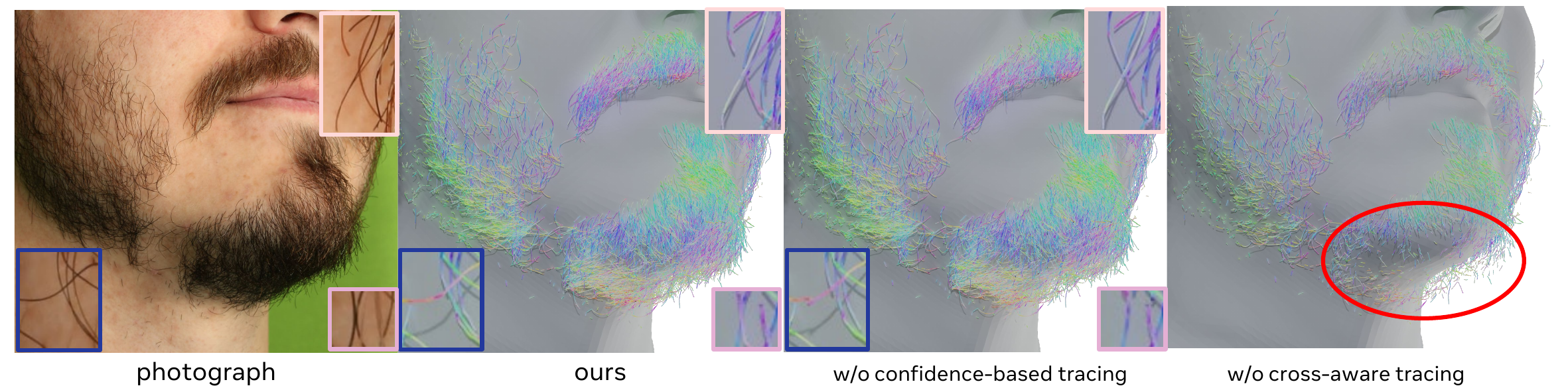
The tracing terminates when no valid neighbors remain. Crucially, the method does not simply delete all nearby primitives after one trace. Because facial hair frequently crosses itself, the paper introduces a crossing-aware suppression rule: near-parallel candidates inside a local cylinder are removed as redundant support, but candidates with sufficiently different orientation are preserved if a short look-ahead pseudo-trace suggests they are valid continuations. This is a key difference from older pipelines that can accidentally delete true crossing strands.
The final output of Stage II is a set of 3D strand polylines. The authors also add a stitching phase to repair fragmentation caused by weak observations and early termination. The stitcher applies three operations repeatedly: enclosed pruning, tip linking, and overlap merging. The paper notes that this is run regressively for 30 iterations until convergence.
In the ablation, removing opacity-based consolidation or crossing-aware suppression causes several failure modes: strands become misconnected, disconnected, or sparsely sampled, and dense beard regions in particular show frequent crossing artifacts. The full tracing pipeline recovers much more coherent strand geometry in these difficult cases.
The stitching stage is intended to merge fragments that really belong to the same physical strand. EnclosedPrune removes strands that are almost entirely contained within another strand when geometric proximity, tangent consistency, and projection monotonicity agree. TipLink connects compatible endpoints using one-to-one matching and cleans up crossing-like junctions to avoid kinks. OverlapMerge fuses partially overlapping strands that trace the same structure and discards fully redundant duplicates.
This stage matters because facial hair reconstructions are often fragmented by weak or view-dependent evidence; the result of Stage II alone is geometrically plausible but still incomplete, especially in denser regions where multiple local modes are visible.
Stage III anchors the traced curves to the mesh surface and resolves the root-tip ambiguity. The paper treats this as essential for animation readiness and for edit operations such as trimming, grooming, UV-based replanting, and cross-subject transfer. The grounding problem is especially hard for facial hair because roots are not organized like scalp hair and because different regions obey different geometric priors.
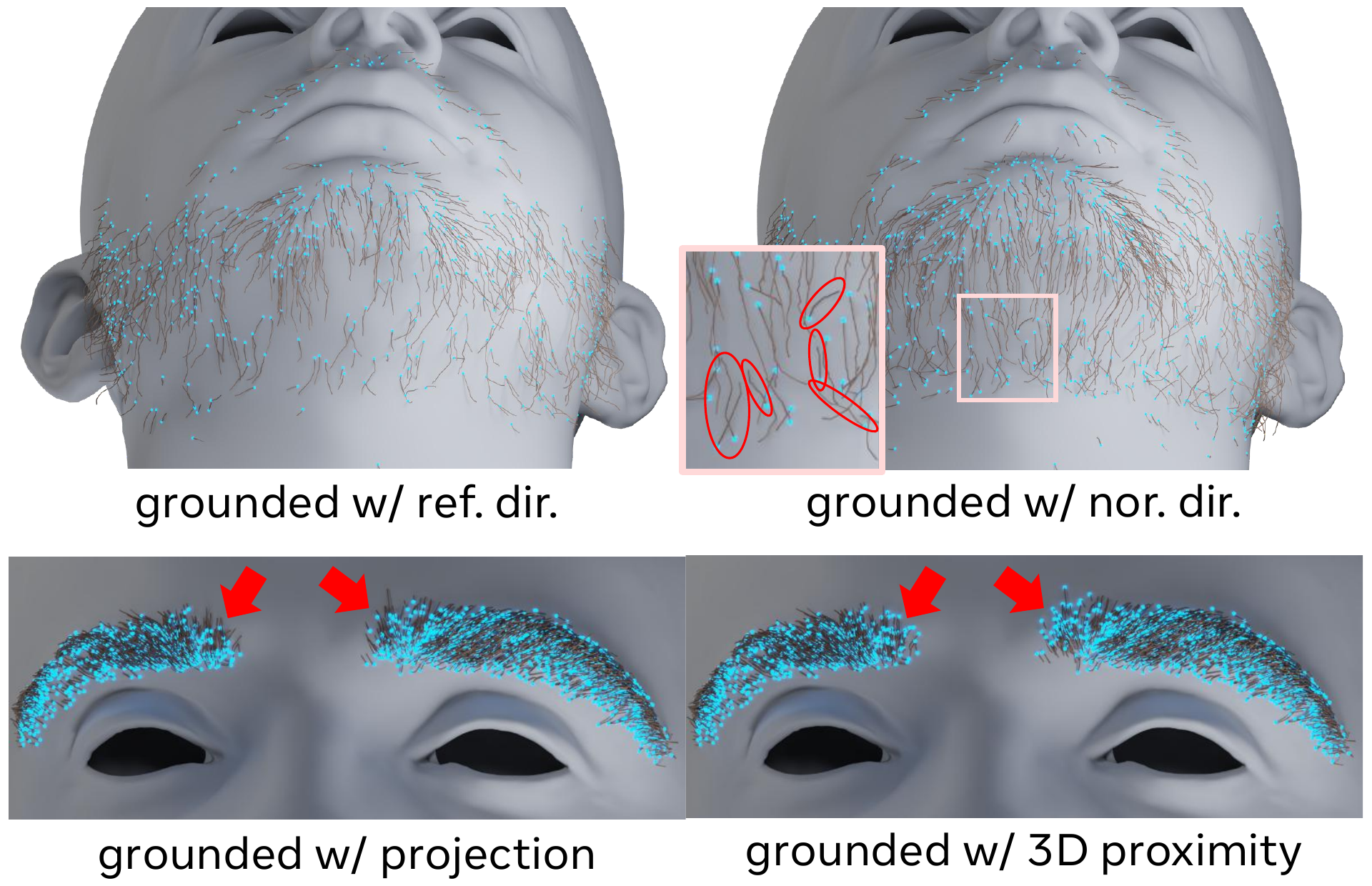
For beard and mustache strands, a surface-normal assumption is not reliable: facial hair often grows downward and outward, not orthogonally to the skin. The method therefore mixes the tracked surface normal $
\mathbf{n}$ and gravity direction $\mathbf{g}$ to form a reference direction
$$
r = \operatorname{normalize}((1-\lambda_r)\mathbf{n}+\lambda_r\mathbf{g}),
$$
with $\lambda_r=0.7$ so that gravity dominates. Endpoint candidates are then evaluated against this reference direction and a distance threshold. If one endpoint is both near the mesh and aligned with $r$, it is snapped to the surface as the root. If both endpoints pass, the more aligned one wins. Ambiguous strands are later resolved with voting among trusted grounded neighbors, and any strands that still float are completed by parallel translation toward the surface, up to a maximum growth distance.
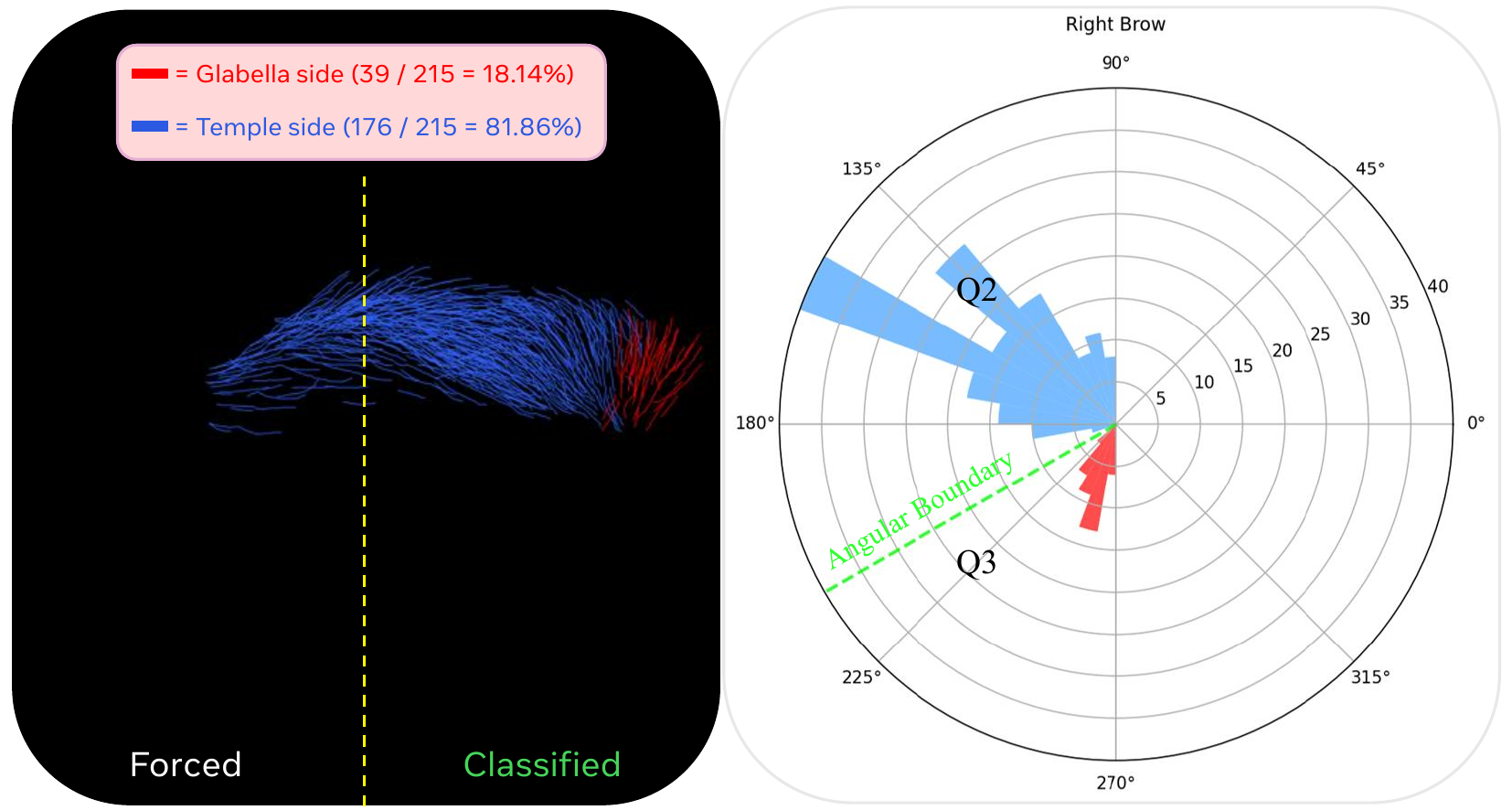
Eyebrows require a different rule because their growth direction is better interpreted in screen space relative to the glabella and temple. The authors mirror the frontal view, split the eyebrow into strips, and classify ambiguous strands based on the 2D direction of the tip relative to the inner endpoint. A $30^\circ$ angular threshold is used to decide when to flip the root assignment. The paper shows that the eyebrow growth directions are bimodal with a gap near this threshold, validating the heuristic.
Eyelashes are simpler: they are grounded primarily by proximity to the eyelid surface, since their strands remain close to the mesh and are more normal-aligned. Remaining floating lashes use the same voting and completion logic as the other regions.
The grounding ablation is one of the strongest validations in the paper. For beard strands, relying on the surface normal alone produces twisted and misaligned growth. For eyebrows, naive 3D proximity grounding makes strands near the glabella grow downward, which is physically implausible. The region-adaptive strategy fixes both issues and is a major reason the final assets behave well under editing and animation.
Stage IV addresses a recurring failure mode: over-reconstruction. Even with good tracing, the recovered strand set can be too dense because nearby Gaussian support often produces several nearly parallel strands, and photometric optimization does not automatically distinguish correctly sparse regions from over-dense ones. The paper emphasizes that facial hair sparsity is itself part of the signal, so density control must be explicit.
The refinement representation converts each strand into a chain of cylindrical Gaussian segments, enabling segment-level updates. Rather than directly optimizing vertices, the method uses a subject-specific VAE trained on grounded strands as a compact shape prior. This is important because the paper does not assume a large facial-hair dataset exists for a generic prior; instead, it builds a per-subject latent manifold that stabilizes refinement and denoises small tracing artifacts.
The strand surgery mechanism parameterizes each strand with $K$ opacity control points. Opacity is linearly interpolated along the polyline and any segment whose interpolated opacity falls below $\tau_\alpha=0.1$ is pruned. This can split a strand into multiple surviving sub-strands. Floating pieces are then re-grounded if possible; otherwise they are stitched back into root-connected geometry before being re-encoded by the VAE.
The refinement stage uses the same photometric loss as Stage I, plus a latent regularizer
$$
L_z = \lVert z-\hat z\rVert_1,
$$
where $\hat z$ is refreshed every 2,000 iterations, except at the final iteration to avoid over-pruning. The full refinement run lasts 10k iterations. This stage is what lets the pipeline adapt to sparse-to-dense transitions and align reconstructed density with the observed images more closely than tracing alone.
The refinement ablation shows that the final surgery stage meaningfully improves density matching. Without it, tracing produces unnaturally uniform coverage in sparse areas such as the mustache and lower chin. With refinement, redundant segments are pruned while supported ones are preserved, and the subject-specific VAE suppresses jitter introduced by surgery.
The paper evaluates on two datasets. The first is a synthetic high-quality human head dataset authored by technical artists. It contains 5 subjects, including one female and four male identities, rendered in Blender using 20 synchronized cameras at 8K resolution and then downsampled by $\times 2$. Because the data are synthetic, the camera intrinsics and extrinsics are exact, and the ground-truth head geometry is available for every identity. The subjects cover a variety of hair configurations: one male has four hairstyle variations, another has a beard only, and the remaining two have eyebrows and eyelashes only.
The second dataset is the captured facial-hair dataset of Beeler et al. The paper preprocesses it as a single subject with 13 forward-facing calibrated cameras and a scanned head mesh. For grounding, the authors optimize an in-house 3DMFM supervised by facial keypoints and the scanned mesh. Hair masks are extracted by reimplementing Beeler’s method with Gabor filtering and non-maximum suppression.
The paper also reports per-region runtime statistics on a single NVIDIA H200 (144 GB). Stage I takes about 15–20 minutes for eyelashes, 20–30 minutes for eyebrows, 30–50 minutes for sparse beard, 80–100 minutes for dense beard, and 100–120 minutes for a long/full beard. Stage II and III are relatively fast, usually under 2–10 minutes. Stage IV is skipped for eyebrows and eyelashes, but adds roughly 2–3 hours for beard cases. Final strand counts range from a few hundred to a few thousand for lashes and brows, and from around 10k to 60k for beards.
The paper reports that the method reconstructs the full spectrum of facial hair: fine eyelashes, sparse brows, short stubble, medium-length beards, and long dense beards. One of the recurring themes in the qualitative results is that the method preserves not just shape, but also the orientation and sparsity patterns characteristic of each subject’s hair. That matters because facial hair identity is often encoded as much in density and direction as in gross silhouette.
The authors highlight that the method can recover visible outer structure as well as some occluded inner beard structure, though the latter is also one of the paper’s limitations. They also note robust behavior on dyed and dark facial hair, which is important because albedo changes can weaken photometric gradients and orientation cues.
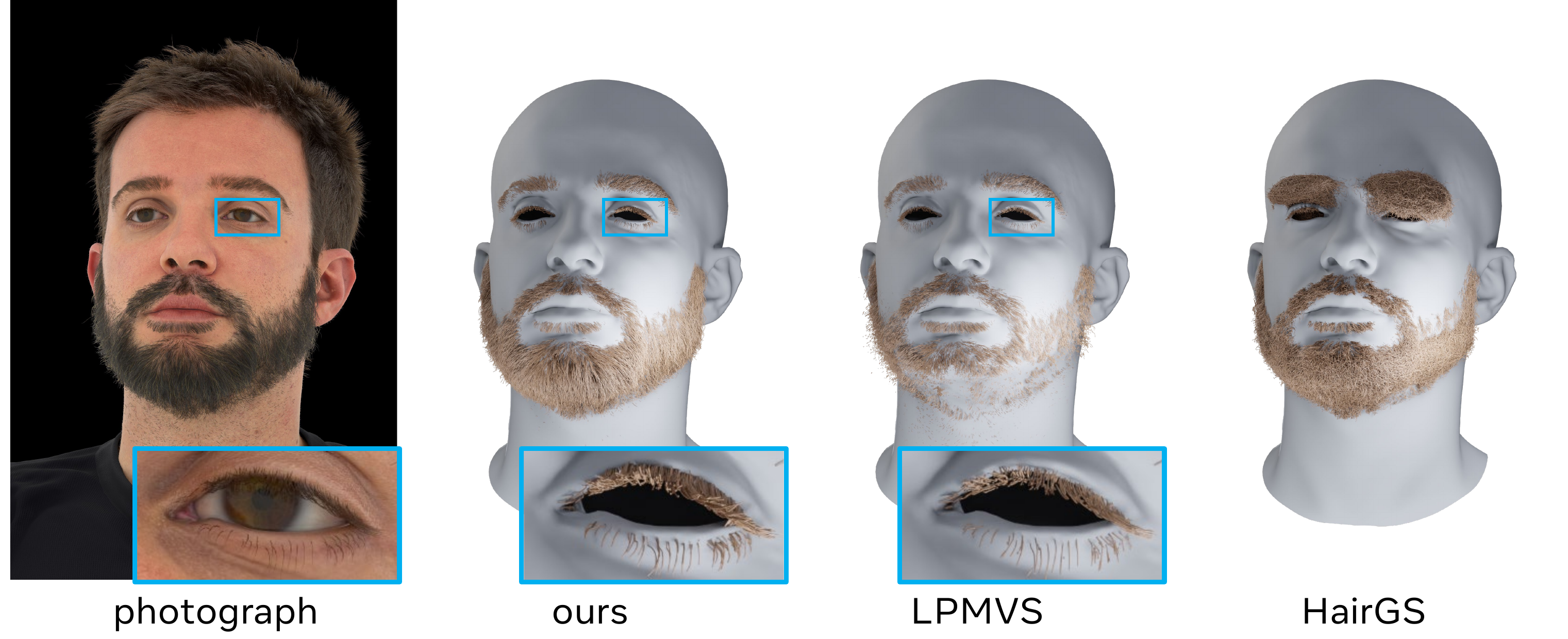
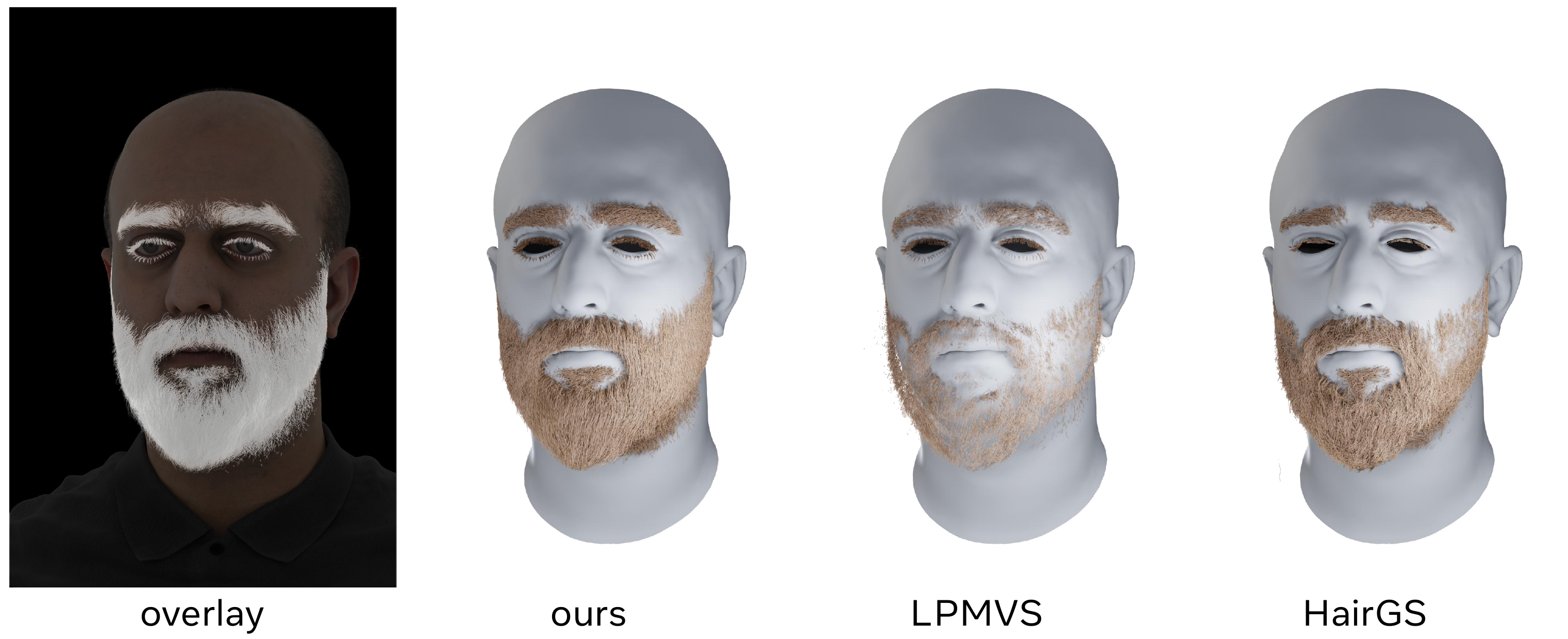
The main geometric comparison is against LPMVS and HairGS on the synthetic facial-hair dataset, and against Beeler et al. on the captured dataset. The paper’s overall message is that LPMVS can be competitive on short, relatively straight structures such as eyebrows, but tends to fragment strands and struggles more on curved or heavily occluded regions such as eyelashes and beards. HairGS, while prior-free, is much weaker on thin, localized facial structures, especially eyebrows. Beeler et al. remain strong in certain sparse regions but are less uniform in dense regions and do not provide the same end-to-end grounding/editing pipeline.
The paper also provides a quantitative facial-hair reconstruction benchmark using F1 and Strand Consistency (SC). SC measures how much of each ground-truth strand is explained by a single predicted strand, so it penalizes fragmented reconstructions even when point-level overlap is high. This is particularly relevant for facial hair, where strand continuity matters as much as recall.
The pattern is consistent: the proposed method is competitive with LPMVS on the easiest eyebrow setting, but becomes clearly better on continuity-aware metrics, and it dominates on dense beard reconstruction where occlusion and crossings matter most. HairGS is substantially weaker on thin, localized facial structures.
A major claim of the paper is that converting a reconstructed volume into grounded, explicit strands makes downstream editing much easier. The authors demonstrate several production-style operations that are awkward or impossible with a baked volumetric representation.
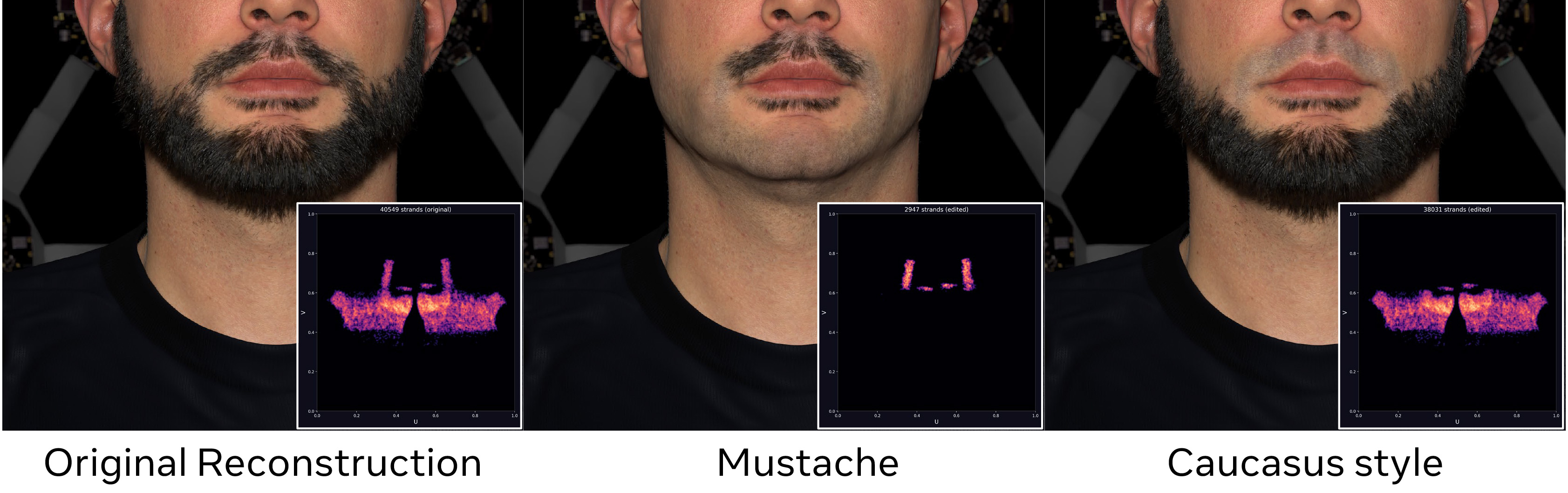
Because every strand root is attached to a UV coordinate on the face mesh, the root distribution can be visualized as a 2D density map in texel space. This “UV terrain” makes it straightforward to select and delete or fill spatially coherent groups of strands using rectangle or lasso interactions. The paper shows examples including mustache-only and beard-only style variants.
Since the roots are expressed in shared UV space, a beard reconstructed on one subject can be transferred to another without re-fitting or retraining. The asset is re-grounded on the target face by reusing the same UV root coordinates. This demonstrates that the output is not just a reconstruction result, but a transferable groom asset.
The paper also demonstrates a controlled editing example for eyelashes. Each lash is approximated as a planar circular arc; scaling the curvature while preserving arc length yields a mechanically plausible curl that keeps the root attached to the lid.
Because the strands have a well-defined root-to-tip orientation, the paper supports simple length-based cutting by trimming each strand at a fixed fraction of arc length from the root. The result is a style-consistent beard reduction without manual retopology or retraining.
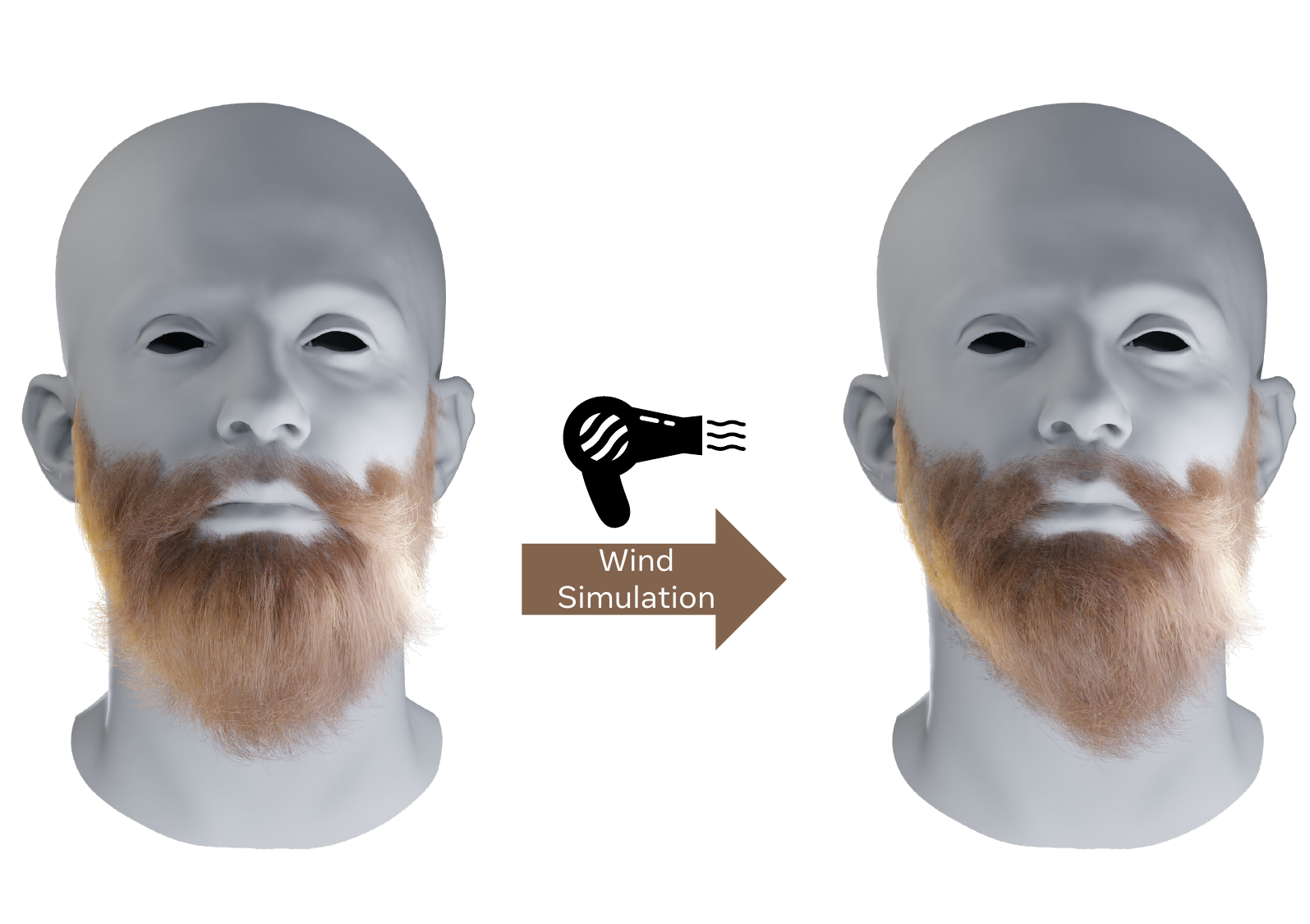
The explicit strand output can be rendered in Blender Cycles using the Principled Hair BSDF, and the authors report that the geometry responds properly to different lighting conditions and material edits. They also show a wind simulation based on a damped Verlet integrator with Follow-The-Leader inextensibility constraints. The stated point is not that facial hair is dramatically floppy, but that the output is compatible with standard physical solvers and path tracers in a way that implicit volumes are not.
The ablations isolate the contribution of each stage. The dominant pattern is that every stage addresses a distinct ambiguity: Stage I suppresses sub-surface noise, Stage II recovers connectivity, Stage III fixes growth direction and root placement, and Stage IV matches the observed density distribution. No single step can replace the others.
Without depth gating, the Gaussian optimizer spreads primitives across visible skin and subsurface regions, which contaminates the orientation field and disrupts later tracing. With depth gating, primitives stay organized along the facial-hair support, and the traced strands become more coherent.
Removing opacity-based filtering or crossing-aware suppression makes strands misconnect or vanish in dense beard and mustache regions. The full version recovers coherent strand direction and much better continuity.
The grounding ablation shows why a region-specific prior is necessary. Beard strands should not be aligned purely with the surface normal, and eyebrows near the glabella should not be grounded by generic proximity rules. The gravity-blended beard prior and the eyebrow-specific front-view logic correct these mistakes.
The refinement stage removes over-dense, nearly parallel traces and better matches sparse regions such as the mustache and lower chin. The subject-specific VAE also reduces jitter, suggesting that a compact learned latent prior is useful even in a prior-free geometric reconstruction pipeline.
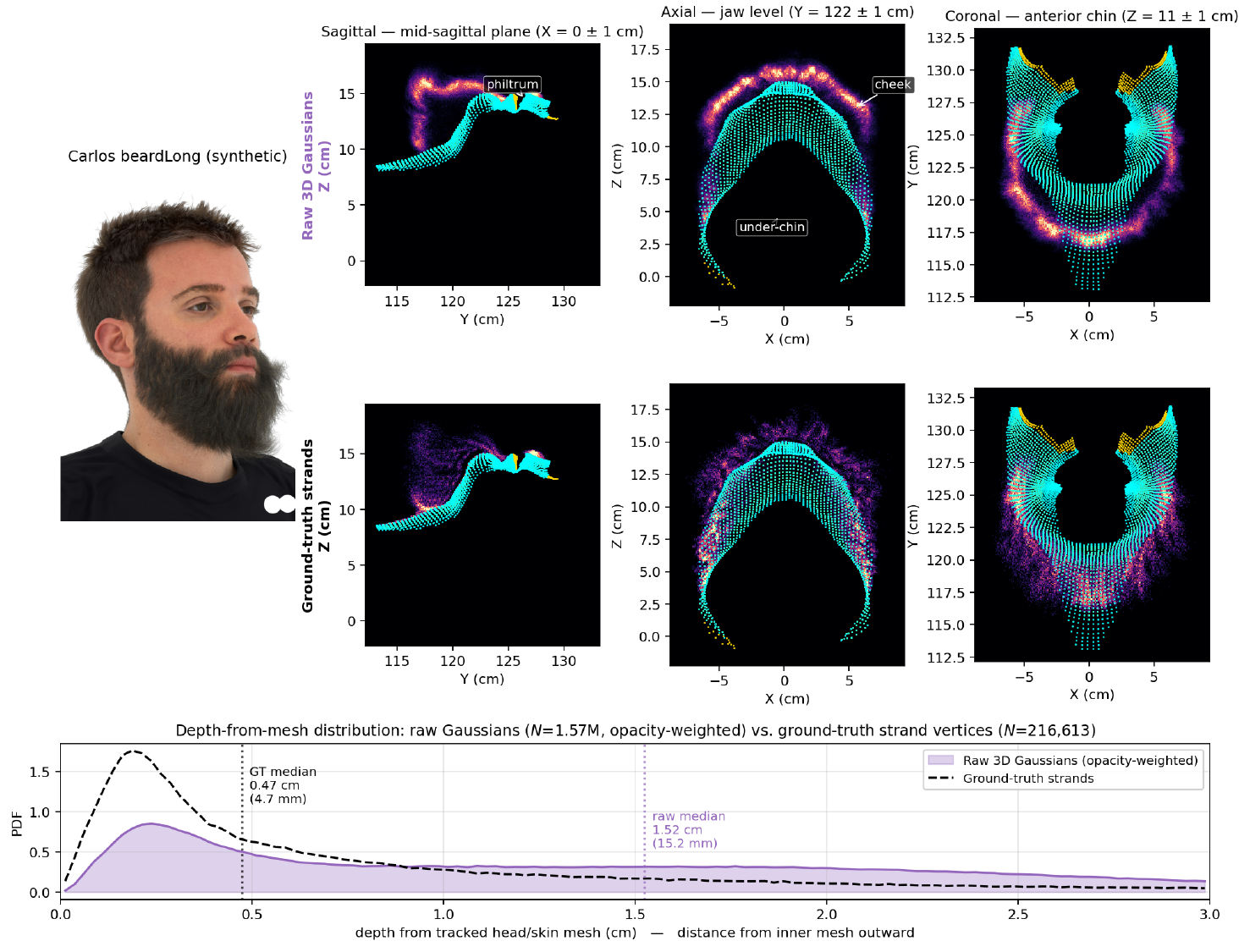
This tomographic analysis motivates one of the paper’s main limitations: the Gaussian optimization itself is biased toward the outer visible shell, which leaves inner beard structure weakly supported. That is especially problematic in occluded regions such as the philtrum, cheeks, and underside of the chin.
The paper identifies two primary limitations. First is surface bias: volumetric optimization tends to concentrate density on the outer visible shell, so interior beard structures can remain unsupported and cause tracing failures. Second is density ambiguity: photometric supervision alone cannot reliably tell whether a region is correctly sparse or mistakenly over-dense, because transmittance makes density and appearance hard to disentangle.
The authors suggest two future directions. One is to use physically based differentiable rendering under OLAT lighting so that abnormal appearance cues could drive geometry-level pruning. Another is to revisit the orientation field itself, possibly using continuous neural fields or anisotropic diffusion of orientation from well-supported outer shells into interior regions. They also note that a facial-hair-aware backward-growing strategy would be valuable, but is nontrivial because facial hair roots are distributed across semantically different regions rather than organized around a single scalp surface.
The supplementary material further shows sensitivity to input matting quality. Coarser masks preserve the broad hair distribution but lose fine wispy details, while better masks preserve finer boundaries. The method also appears robust to different albedos, including dark, gray, and dyed hair, which is encouraging for real-world use.
The key technical contribution of the paper is not just a better hair reconstructor, but a conversion from a volumetric intermediate representation into a grounded, explicit strand asset. The four-stage design is what makes this possible: depth gating suppresses the wrong geometry, tracing converts local orientation into curves, grounding makes the curves semantically usable on a face mesh, and refinement adjusts density to match the observed sparsity pattern. The resulting output is directly suited to editing, UV-based grooming, cross-subject transfer, physical rendering, and simulation.
Stage II: From Gaussians to Strands
Filtering and Consolidation
Crossing-aware Euler Tracing

Stitching Details
Stage III: Grounding Strands to the Face Mesh
Beard and Mustache Grounding
Eyebrows and Eyelashes
Stage IV: Sparsity-aware Refinement

Datasets and Experimental Setup
Region
# Gaussians
# Strands
Stage I
Stage II & III
Stage IV
Total
Eyelash ~10–100K 0.3–2.1K ~15–20 min <2 min — ~20 min Eyebrow ~0.15–0.27M 1.0–4.9K ~20–30 min <3 min — ~30 min Sparse beard (stubble) ~0.8M 4–6K ~30–50 min <5 min ~2 h ~3 h Dense beard (regular) ~1–3M 10–45K ~80–100 min ~10 min ~3 h ~4–5 h Long/full beard up to 4.2M 23–60K ~100–120 min ~10 min ~3 h ~5 h Qualitative Results

Comparisons with Prior Work


Region / Threshold
Method
F1
SC
Eyebrow, $0.1$ mm / $10^\circ$ LPMVS 0.583 0.480 HairGS 0.010 0.064 Ours 0.622 0.541 Eyebrow, $0.2$ mm / $20^\circ$ LPMVS 0.807 0.803 HairGS 0.055 0.408 Ours 0.806 0.854 Eyebrow, $0.5$ mm / $30^\circ$ LPMVS 0.956 0.968 HairGS 0.242 0.833 Ours 0.953 0.985 Eyelash, $0.1$ mm / $10^\circ$ LPMVS 0.748 0.514 HairGS 0.089 0.072 Ours 0.729 0.641 Eyelash, $0.2$ mm / $20^\circ$ LPMVS 0.966 0.849 HairGS 0.297 0.349 Ours 0.972 0.966 Eyelash, $0.5$ mm / $30^\circ$ LPMVS 0.996 0.977 HairGS 0.493 0.677 Ours 0.996 0.996 Beard, $0.5$ mm / $20^\circ$ LPMVS 0.599 0.374 HairGS 0.518 0.431 Ours 0.922 0.630 Beard, $1.0$ mm / $30^\circ$ LPMVS 0.871 0.648 HairGS 0.806 0.779 Ours 0.992 0.867 Beard, $1.0$ mm / $90^\circ$ LPMVS 0.952 0.887 HairGS 0.866 0.966 Ours 0.996 0.991 Applications Enabled by Explicit Grounded Strands
UV terrain-based trimming and style editing
Beard implantation across subjects

Eyelash curling

Beard cutting
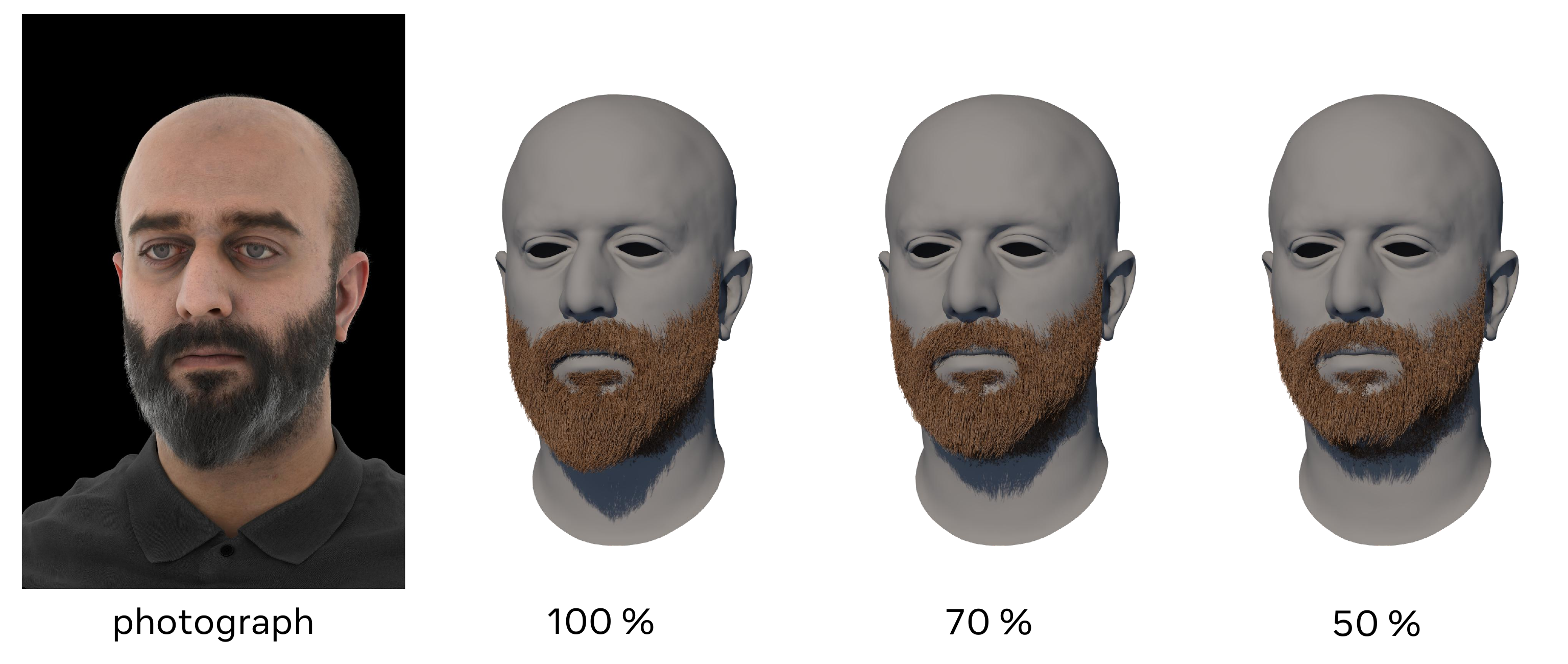
Physics-based relighting and simulation

Ablations and Failure Analysis
Depth-gated rasterization
Tracing and crossing handling
Grounding
Refinement
Limitations and Future Work


Takeaway