OmniFaceRig
OmniFaceRig: Fully Automatic Inner-Mouth-Aware Face Rigging Across Diverse 3D Character Topologies

OmniFaceRig fully automates 3D face rigging by converting static meshes into rigs with inner-mouth geometry and FACS blendshapes, supporting humans and diverse animals. It uniquely generates teeth, gums, and tongue with collision-aware blendshape transfer, enabling animation-ready avatars without manual input.
Demos
These demos show OmniFaceRig’s automatic pipeline that transforms static 3D character meshes into facial rigs with detailed inner-mouth geometry. Look for accurate facial expressions, seamless teeth and tongue integration, and versatility across humans and diverse animals with no manual setup. The results highlight quick, ready-to-animate rigs across varied character types.

Links
Paper & demos
Code & resources
Abstract
Facial rigging - creating FACS-based blendshapes together with inner-mouth geometry (teeth, gums, and tongue) - remains a major bottleneck in 3D character production. Existing pipelines still require substantial designer effort, especially for manual landmark annotation, per-character template adjustment, and inner-mouth placement. We present OmniFaceRig, a fully automatic end-to-end pipeline that converts a static surface-only 3D character mesh, with no pre-modeled oral cavity, into an inner-mouth-aware FACS rig with up to 155 blendshapes, procedurally fitted teeth, gums, and tongue, and re-packed UV/texture. OmniFaceRig supports diverse topologies - humans, humanoids, long-muzzled animals (e.g., dogs, wolves, foxes), and short-muzzled animals (e.g., cats, bears, rabbits, tigers) - with no manual landmarks, no user-provided templates, and no per-asset setup. The pipeline combines hybrid VLM+CV riggability checking, multi-model face parsing, dense keypoint-driven template registration, procedural inner-mouth construction, and collision-aware blendshape transfer. For non-human characters, OmniFaceRig selects topology-specific face and inner-mouth templates and uses collision-aware inner-mouth fitting to reduce teeth-face intersections without exposing users to category-specific tuning. We also publicly release Omni-Bench, a freely available benchmark dataset of 1,000 biped 3D characters with FACS facial blendshapes and inner-mouth geometry, spanning humans, humanoids, cats, dogs, and other animals. Experiments show high final rigging success on screened Omni-Bench inputs, nearly complete face detection recall from the segmentation ensemble and reliable inner-mouth placement with low penetration. Together, OmniFaceRig provides an automatic path from static generated characters to animation-ready facial rigs across both human and non-human topologies.
Introduction
OmniFaceRig addresses a production bottleneck that sits between character generation and animation: converting a static surface-only 3D character mesh into a fully usable facial rig with FACS blendshapes and explicit inner-mouth geometry. The paper argues that existing 3D generation systems increasingly produce visually plausible character meshes, but those meshes typically lack the deformation-ready face topology, blendshape controls, and oral-cavity structures needed for animation. In production, the missing pieces are expensive because they normally require manual landmarking, template adjustment, and hand placement of teeth, gums, and tongue. OmniFaceRig’s goal is to remove that manual work entirely while supporting both human and non-human topologies.
The core claim is a fully automatic end-to-end pipeline that starts from a static mesh with no pre-modeled oral cavity and outputs a production-ready facial rig with up to 155 blendshapes, procedurally fitted inner-mouth geometry, and re-packed UV/texture. Unlike prior systems that focus only on the outer face surface, OmniFaceRig explicitly synthesizes teeth, gums, and tongue and keeps them collision-aware during expression transfer. The method is designed to generalize across humans, humanoids, long-muzzled animals, and short-muzzled animals with no manual landmarks, no user-provided template, and no per-asset tuning.

What is new relative to prior face rigging?
- Cross-topology face rigging: the same pipeline is intended to work across humans, humanoids, and multiple animal face families.
- Automatic oral-cavity creation: teeth, gums, and tongue are synthesized procedurally rather than copied from a hand-authored template.
- Blendshape output: the final rig is a FACS-style blendshape set, not just a neutral mesh or a latent deformation representation.
- Unattended operation: the system removes manual correspondence annotation and per-character template setup, which are the usual bottlenecks in rigging pipelines.
- Benchmark contribution: the paper also releases Omni-Bench, a large rigged dataset meant to support evaluation of automatic facial rigging on both human and animal assets.
Omni-Bench Dataset
Omni-Bench is presented as a public benchmark of 1,000 rigged biped 3D characters. The assets originate from a text/image-to-3D generation pipeline based on AssetGen2, and the paper states that all released assets are selected from inputs that pass the initial riggability screen and are then processed by OmniFaceRig. Every asset is provided in biped T-pose and ships with the generation provenance: text prompt, 2D reference image, final mesh, FACS blendshapes, and inner-mouth geometry.

Dataset composition
| Subset | Count | Description |
|---|---|---|
| Humans + humanoids | 500 | Realistic humans across 13 occupations, plus stylized fantasy, sci-fi, and cyberpunk humanoids. |
| Animals | 500 | 150 cats, 150 dogs, and 200 other rigging-amenable animals such as bears, tigers, lions, foxes, wolves, rabbits, and deer. |
| Total | 1,000 | Biped assets in T-pose, all rigged by OmniFaceRig. |
The paper emphasizes that Omni-Bench is useful for more than a single rigging benchmark. Because each asset includes text prompt, intermediate 2D image, and final 3D mesh, it can also support broader text-to-3D and multimodal research. The authors also position Omni-Bench as a dataset that fills a gap in existing face datasets by combining FACS blendshapes, inner-mouth geometry, full-character assets, and animal coverage in one release.
Method Overview
OmniFaceRig is a two-stage pipeline. Stage 1 performs face template fitting: it renders the input mesh to a frontal view, detects and crops the face, parses facial regions with a multi-model segmentation ensemble, runs a hybrid VLM+CV riggability check, extracts 2D and 3D keypoints, and fits a topology-specific canonical face template to the input. Stage 2 constructs the final blendshape rig: it fuses the fitted face into the original mesh, generates and places inner-mouth geometry, rebuilds UVs and texture, and transfers FACS blendshapes from a canonical rigged template.
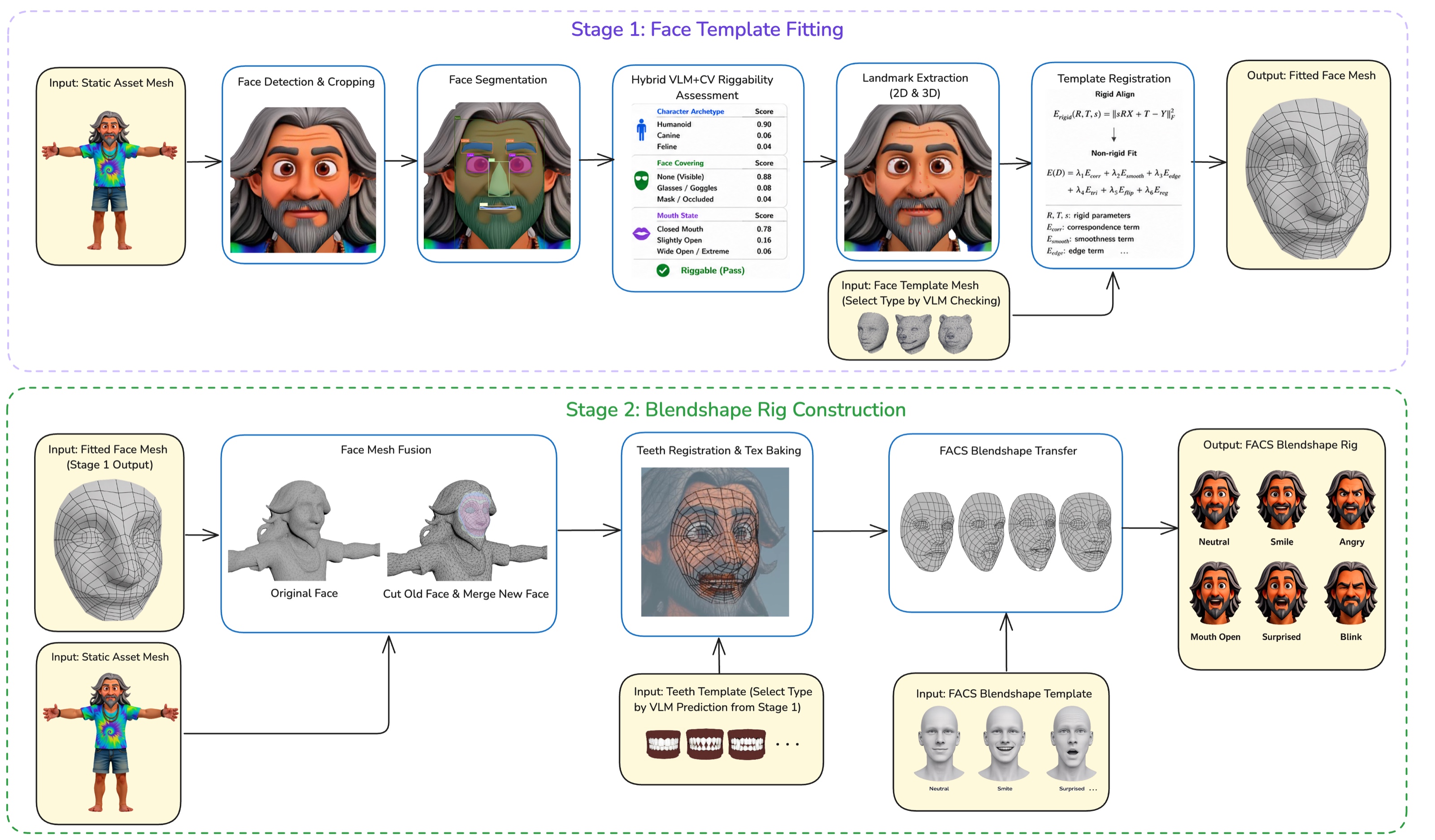
Why the pipeline is structured this way
- Stage 1 is perception-heavy: its purpose is to robustly localize facial structure on a wide variety of generated meshes.
- Stage 2 is geometry-heavy: once a fitted template exists, the system can fuse it into the original mesh, synthesize missing oral structures, and transfer expressions.
- Canonical templates reduce complexity: rather than training a fully general regressor, the method uses a small library of topology-specific templates and deformation fitting.
- Inner-mouth handling is explicit: teeth, gums, and tongue are not approximated implicitly; they are built as separate geometry and then made collision-aware.
Riggability assessment
Before full processing, OmniFaceRig applies a riggability checker to filter out assets that are unlikely to succeed downstream. The checker is a hybrid of a Vision-Language Model and computer vision signals. It is not merely a binary classifier; it also chooses downstream configuration, including the face template variant and the inner-mouth archetype.
The paper describes three sources of evidence. First, the VLM handles semantic judgments such as character archetype, face covering status, mouth state, and teeth visibility. Second, segmentation masks provide geometric tests such as whether face/eye/mouth regions exist, whether they lie inside the face boundary, whether eye occlusion is excessive, and whether the eye-to-head ratio or lip-seal curvature looks plausible. Third, for human-like faces only, mouth landmarks are used but gated by a lip-evenness statistic $\mathrm{CV}_{\mathrm{lip}}$ so that unreliable landmarks do not poison the decision. The mouth decision is the only component that uses explicit fusion; for human-like characters it is a majority vote across VLM, segmentation, and landmarks when the landmark gate passes, while for non-human characters the landmark signal is ignored.
Per-question signal assignment
| Question | Checked aspect | Signal source |
|---|---|---|
| Q1 | Face type (human / animal / other) | VLM |
| Q2 | Number of visible faces | VLM |
| Q3 | Number of visible eye orbits | VLM |
| Q4 | Mouth present and localizable | Majority vote |
| Q5 | Eye-region occlusion or obstruction | Segmentation mask |
| Q6 | Eyewear covering eyes | VLM |
| Q7 | Mouth state | VLM |
| Q8 | Teeth visibility | VLM |
| Q9 | Eye-to-head size ratio | Segmentation mask |
| Q10 | Lip-seal curvature | Segmentation mask |
The checker is conservative by design. The paper explicitly treats riggability as an input eligibility filter rather than a guarantee of final success: it rejects obvious invalid assets such as missing faces, severe eye or mouth occlusions, non-standard viewpoints, and unsupported facial topologies. Even a screened asset can still fail later because of segmentation errors, unstable template fitting, or implausible mouth localization. The validation metrics are therefore reported separately from final rigging success.
Rigability checker performance
| Method | Accuracy | Recall | F1 |
|---|---|---|---|
| VLM only | 94.69% | 94.76% | 94.71% |
| CV segmentation filtering only | 76.72% | 94.87% | 80.87% |
| VLM + CV (Ours) | >95% | >95% | >95% |
The paper’s takeaway is that the VLM is strong at semantic understanding, while the CV side is better at rejecting geometric edge cases. Combining them gives the best overall checker.
Segmentation ensemble
For face parsing, OmniFaceRig uses a four-model ensemble that is explicitly designed to cover human and non-human topology variation. The ensemble runs face landmark detection, a base Sapiens parser, SAM 3, and fine-tuned Sapiens parsers in parallel, then selects the best output per facial region. The design is important because no single model is reliable across humans, stylized humanoids, and animals. Human face landmarks are precise on conventional faces, while the Sapiens-based models and SAM 3 cover stylized or non-human cases.
The authors also describe a Sapiens-based training recipe. Starting from Sapiens-1B, they first pretrain at $512 \times 512$ resolution and then briefly switch to $1024 \times 1024$ to sharpen facial boundary cues. They also perform mid-stage unsupervised adaptation on 20 million curated stylized character images. For fine-tuning, they freeze the ViT encoder, attach a lightweight three-stage deconvolutional decoder, and train two parser heads: a 41-class stylized parser for human-like characters and a 38-class humanoid parser for cartoon animals and strongly non-human characters.
Segmentation training details
- Backbone: Sapiens-1B ViT encoder.
- Training data: about 10,000 annotated frontal T-pose images covering humans, humanoids, felines, canines, ursines, and other stylized creatures.
- Optimization: AdamW with learning rate $10^{-4}$, cosine decay, 500 warmup steps, batch size 16, and class-balanced cross-entropy.
- Schedule: 50 epochs on 8× NVIDIA A100 GPUs, about 24 hours.
- Augmentation: horizontal flip, color jitter, random rotation of $\pm 15^\circ$, and random scale of $0.8$ to $1.2$.
Template registration
The fitting stage aligns a small library of quad-mesh templates to the input asset using keypoints extracted from the ensemble masks. OmniFaceRig maintains three topology-specific face templates: human, long-muzzle, and short-muzzle. The VLM chooses among them automatically based on the character’s topology. The paper’s design choices are intentionally tuned for robustness on stylized and animal faces rather than just conventional human heads.
A central design decision is the nose-landmark-free template. The authors argue that nose contours are too unreliable across animals and stylized characters: noses are often tiny, irregular, merged with the muzzle, or incorrectly segmented. Instead of forcing nose anchors, the optimization uses surrounding facial structure to infer the nose region indirectly. This avoids unstable correspondences and makes the method more robust to diverse anatomy.

The template design also separates the mesh used for fitting from the mesh used for animation quality. The paper notes that the fitting template and the animated topology are decoupled and linked by UV correspondence, so the fitting mesh can be optimized for landmark matching without sacrificing edge flow around eyes and mouth. In addition, the template is a minimum region fit: it hugs the convex hull of facial features instead of extending deep into neck or chin regions, which reduces merge artifacts.
Keypoint extraction is robustified by several fallbacks. If a border keypoint projects badly, the system snaps it to the nearest valid face-mask boundary and, if necessary, searches the nearest pixel on the actual mesh surface. If 2D-to-3D projection still fails, later keypoints can fall back to the resolved 3D locations of earlier anchors. Eye masks are also selected adaptively: landmark-derived eye masks are preferred on humans, segmentation-derived eye masks are preferred on non-humans, and the system falls back automatically when needed.
Registration objective
After a rigid alignment step, the template undergoes non-rigid optimization with a composite energy. The rigid stage minimizes
$$E_{\text{rigid}} = \sum_{i \in \mathcal{K}} \| s \mathbf{R}\mathbf{v}_i + \mathbf{t} - \mathbf{p}_i \|^2,$$
where $\mathcal{K}$ is the keypoint set, $\mathbf{R}$ is rotation, $s$ is scale, $\mathbf{t}$ is translation, $\mathbf{v}_i$ are template keypoints, and $\mathbf{p}_i$ are target asset keypoints.
The non-rigid stage optimizes per-vertex offsets $\mathbf{d}_i$ under a weighted sum
$$E(\mathbf{D}) = \lambda_1 E_{\text{corr}} + \lambda_2 E_{\text{smooth}} + \lambda_3 E_{\text{edge}} + \lambda_4 E_{\text{tri}} + \lambda_5 E_{\text{flip}} + \lambda_6 E_{\text{reg}}.$$
The terms are:
- Correspondence loss: pulls deformed template keypoints toward the target keypoints, using a robust penalty such as Huber loss.
- Smoothness: encourages neighboring vertices to move coherently.
- Edge-length preservation: keeps local geometry close to the template.
- Triangle-shape preservation: reduces shearing and skinny triangles.
- Flip penalty: discourages orientation reversal and foldovers.
- Offset regularization: keeps the deformation from becoming unnecessarily large.
The paper reports near-zero alignment error below $10^{-5}$ on normalized meshes, and emphasizes that the nose-free design plus the flip penalty eliminate crashes on animal assets in Omni-Bench.
Inner-mouth synthesis and blendshape construction
Once the face template is fitted, Stage 2 builds the final rig. The original input mesh does not include an oral cavity, so teeth, gums, and tongue must be synthesized rather than transferred. OmniFaceRig selects one of four inner-mouth archetypes from a small library: human, canine, monster, or flat. The VLM chooses the archetype in Stage 1 based on the rendered appearance of the character.
The selected teeth template is warped into the fitted mouth using radial basis function deformation and non-uniform scaling. Placement is refined with As-Rigid-As-Possible deformation and then further corrected with a signed distance field pass that pushes intersecting face regions outward along the SDF gradient. The gums and tongue are fit at the same time. This ARAP + SDF strategy is the paper’s main mechanism for reducing teeth-face intersections both at rest and under expression deformation.
After the geometry is in place, the UV layout is rebuilt and texture is re-sampled onto the new mesh. The face region is given roughly 10× more texel density than non-face regions, and the inner-mouth surfaces are placed on a separate texture channel. The final facial expressions are transferred from a canonical FACS template using sparse deformation transfer, followed by Point Deform and Delta Mush smoothing. The authors note that this preserves character identity while letting the same expression basis work across humans, humanoids, and animals.
| Shape category | Refinement |
|---|---|
| Closed-eye shapes | Upper-eyelid vertices are snapped to the lower lid and locally relaxed for contact-aware closure. |
| Eye-gaze shapes | Eye-region vertices rotate around virtual eyeball centers estimated by Procrustes fit. |
| Jaw-related shapes | The lower-teeth subset moves coherently with jaw motion. |
| Collision-aware refinement | SDF-based teeth-face penetration checks are re-applied for each expression shape. |
The method supports three output tiers: Core with 13 shapes, Additional with 46 shapes, and Full with 155 shapes. The paper frames these as configurable deployment tiers rather than separate models.
Experiments and Results
All rigging and evaluation experiments are run on a single NVIDIA A100 GPU, with segmentation model training performed offline on 8× A100s. The paper reports end-to-end latency of 20 to 30 seconds per asset including data I/O. Stage 1 takes about 8 to 10 seconds, and Stage 2 takes about 10 to 15 seconds. The authors highlight this as a 2 to 3 order-of-magnitude reduction compared with manual sculpting workflows that can take hours or days.
Evaluation metrics
- MAE: mean absolute per-vertex error between predicted and ground-truth expression meshes.
- Q95: the 95th-percentile vertex error, used as a worst-case measure.
- Penetration rate: percentage of penetrating vertices between inner-mouth components and the outer face.
- Success rate: percentage of screened assets for which the full pipeline completes and passes final geometric quality checks.
- Processing latency: end-to-end runtime in seconds.

Comparison with prior methods on human/humanoid heads
| Method | MAE ↓ (mm) | Q95 ↓ (mm) | Penetration ↓ (%) |
|---|---|---|---|
| DT | 2.93 | 8.41 | -- |
| NFR | 2.77 | 7.21 | -- |
| RigAnyFace | 1.01 | 2.94 | 0.17 |
| OmniFaceRig (Ours) | 0.85 | 2.50 | 0.05 |
On this 200-head evaluation, OmniFaceRig achieves the best accuracy and the lowest penetration rate. Relative to RigAnyFace, the paper reports about a 16% improvement in MAE and a 15% improvement in Q95, while penetration drops to 0.05%, a 3.4× improvement over RigAnyFace.
Omni-Bench comparison
| Method | MAE ↓ (mm) | Q95 ↓ (mm) | Penetration ↓ (%) | Success rate ↑ (%) |
|---|---|---|---|---|
| DT | 3.12 | 9.05 | -- | 82.4 |
| NFR | 2.95 | 8.11 | -- | 85.1 |
| OmniFaceRig (Ours) | 0.92 | 2.71 | 0.08 | 99.0 |
The Omni-Bench evaluation is restricted to humans and humanoids because DT and NFR are human-topology methods. On this subset, OmniFaceRig retains sub-millimeter error, very low penetration, and a near-perfect final success rate. The paper explicitly notes that RigAnyFace is not re-evaluated here because its code is not publicly available. For the broader Omni-Bench set including animals, the authors report that OmniFaceRig achieves zero crashes on all animal assets.
Segmentation ablation
| Model config | Human | Cat | Dog | Overall |
|---|---|---|---|---|
| Face landmark only | 92% | 12% | 18% | 41% |
| Sapiens only | 88% | 35% | 42% | 55% |
| SAM 3 only | 78% | 71% | 68% | 72% |
| Fine-tuned Sapiens only | 90% | 89% | 85% | 88% |
| 4-model ensemble (Ours) | 100% | 100% | 97% | ~99% |
This ablation makes the logic of the ensemble clear. Face landmarks are very good on standard human faces, but collapse on animals. The base Sapiens parser is better than landmarks on non-human faces but still degrades due to its human-centric pretraining. SAM 3 provides the broadest single-model coverage, but at coarser boundaries. Fine-tuned Sapiens improves animal parsing substantially. The combined four-model ensemble is best because it mixes precision on humans with broad coverage on stylized and animal faces.
Nose-anchor ablation
The paper strongly motivates the nose-free template design with both qualitative and quantitative evidence. When nose anchors are included, the pipeline produces severely distorted nose-mouth regions on 78% of animal assets and crashes on 10%, driven by inaccurate or unstable nose segmentation and by the fact that uniform boundary sampling on tiny or irregular nose contours does not produce consistent correspondences. Removing nose anchors eliminates those artifacts and reduces the crash rate to 0% across all animal assets in Omni-Bench.
Latency
The full system runs in roughly 20 to 30 seconds per asset on a single A100, including I/O. This is fast enough for offline or batch generation, but the paper does not claim real-time interactivity. The authors emphasize that the system is still far faster than manual rigging, but it is not intended as a real-time editing tool.
Limitations

The limitation section is explicit: OmniFaceRig is robust within its supported topology families, but it is not a universal facial parameterization. The current system targets visible-faced characters whose facial topology falls within the human, long-muzzle, and short-muzzle template families. Birds with sharp beaks, fish-like faces, insects with oversized compound eyes, and seahorse-like animals with unusual snouts are outside the system’s design envelope and may be rejected by the riggability checker or fail later even if segmentation succeeds.
The paper also notes that expanding coverage will require more templates, more segmentation labels, and new riggability criteria. Even for supported families, the pipeline is best suited to offline or batch processing rather than real-time editing.
Takeaway
The main technical contribution of OmniFaceRig is not a single learned model but a carefully engineered automatic rigging system that combines semantic filtering, multi-model parsing, topology-aware template fitting, explicit oral-cavity synthesis, and collision-aware blendshape transfer. The paper’s result is a practical path from generated surface-only characters to animation-ready facial rigs across both human and non-human topologies, backed by a new benchmark and a set of ablations that isolate why each design choice matters.