TRADE
TRADE: Transducer-Augmented Decoder for Speech LLM
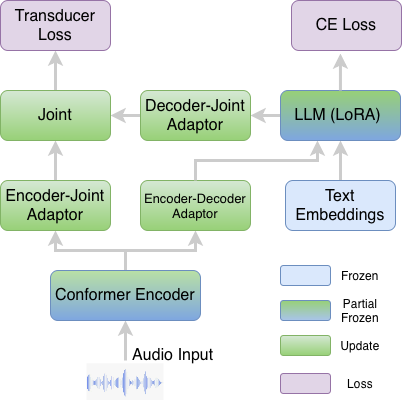
TRADE integrates a speech transducer with a large multimodal language model by tightly coupling frame-synchronous acoustic alignment and linguistic reasoning, enabling accurate, low-latency streaming and flexible long-form speech recognition in a single unified system.
Links
Paper & demos
Impact
Abstract
Speech Large Language Models (Speech LLMs) lack a principled mechanism for streaming inference: their label-synchronous generation has no acoustic-frame alignment, making real-time decoding and end-of-utterance detection difficult. We propose TRADE TRansducer-Augmented DEcoder, which augments a multimodal LLM with a transducer branch that shares the audio encoder and uses the LLM's hidden states directly as the prediction network -- coupling frame-synchronous acoustic alignment with the LLM's linguistic reasoning. Three design choices make the system accurate, streamable, and long-form capable: (1)Tightly coupled dual vocabularies -- a compact transducer vocabulary derived from the LLM vocabulary, enabling zero-cost score fusion; (2)Chunk-synchronized streaming training with gradient stopping, eliminating the train-inference mismatch at offline-equivalent memory cost; and (3)Localized Decoder Audio Attention (LDAA), a causal sliding window that caps KV-cache memory independently of utterance length. A single TRADE checkpoint supports offline and streaming decoding across a continuous range of latency operating points. TRADE achieves 6.71% average WER on the Open ASR Leaderboard, while the streaming recognition with 960ms chunk size reaches 8.40% from the same checkpoint. On long-form speech, it obtains 3.64% WER on TED-LIUM and 10.88% on Earnings-22 without external segmentation. TRADE provides sentence-end punctuation timestamps that, when combined with acoustic voice activity detection (VAD), improve end-of-utterance detection by +0.03 F_1 over acoustic VAD alone.
Problem Setup and Main Idea
The paper addresses a core weakness of speech large language models: their decoding is label-synchronous, so token generation is not explicitly aligned to acoustic frames. That makes streaming inference awkward, because the model does not naturally know when to emit a token, when to keep listening, or when an utterance has ended. Existing streaming speech-LLM designs either hard-code emission timing through fixed chunks or token interleaving, or attach auxiliary alignment signals without making acoustic timing the primary driver of decoding.
TRADE, short for TRansducer-Augmented DEcoder, proposes a tighter coupling: a shared audio encoder feeds both a transducer branch and an LLM branch, and the LLM hidden states themselves are used as the transducer prediction network. The transducer supplies frame-synchronous read/write control, while the LLM contributes linguistic reasoning and surface-form recovery through score fusion. The result is a single model that can operate offline, in streaming mode across multiple latency points, and on long-form audio without external segmentation.
The paper’s central claim is that this coupling gives the system three desirable properties at once: accurate recognition, principled streamability, and bounded-memory long-form decoding. The design is organized around three mechanisms: tightly coupled dual vocabularies, chunk-synchronized streaming training with gradient stopping, and localized decoder audio attention (LDAA).
Architecture Overview
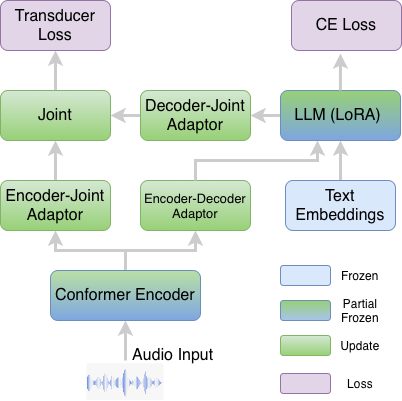
TRADE builds on a shared acoustic backbone and then splits into two training and decoding paths. The encoder is a FastConformer-XL initialized from Parakeet-TDT-0.6B-v2 with 24 layers, 1,024 hidden dimensions, and 8× subsampling; only the top six transformer layers are fine-tuned and the rest are frozen. SpecAugment is applied during training.
The LLM backbone is Llama-3.2-1B, fine-tuned with LoRA on all attention projections using rank $r=16$ and scaling $\alpha=32$. A single-layer causal transformer adaptor with 2× frame-stacking downsampling projects encoder outputs into the LLM embedding space so that the LLM can consume audio embeddings in a streaming-compatible way. On the transducer side, a linear encoder-to-joint projection maps acoustic states into the joint network, and a linear decoder-to-joint projection maps LLM hidden states into the transducer prediction space. These are combined by a one-hidden-layer ReLU MLP joint network with joint dimension 1,024.
The transducer vocabulary is compact: about 20K tokens derived from the LLM vocabulary. Importantly, original token IDs are preserved, so the LLM embedding table and output projection remain valid without remapping. The transducer vocabulary is built by tokenizing a corpus sample, lowercasing and normalizing token surface forms, pruning to the top-$K$ acoustically realizable forms, and retaining non-verbalized symbols separately. This keeps the RNNT lattice tractable while still allowing the LLM to recover casing, punctuation, and homophone-specific surface forms at inference time.
Dual Vocabulary Design and Decoding
TRADE’s vocabulary design is a major novelty. The model maintains a full LLM vocabulary $\mathcal{V}_\text{llm}$ and a compact transducer vocabulary $\mathcal{V}_\text{trans}$. The compact vocabulary is derived from the LLM vocabulary rather than learned independently. Token surface forms are normalized, pronunciation-equivalent variants are merged, and only acoustically realizable tokens are kept for the RNNT branch. Non-verbalized tokens such as punctuation, whitespace, and formatting symbols are excluded from the transducer lattice but retained by the LLM.
At inference time, the two vocabularies collaborate. For a verbalized token $c$, the LLM probability mass is marginalized over the homophone set $\mathcal{H}(c)$:
$$ \log \tilde{p}^{\text{LLM}}_c = \operatorname{logsumexp}_{v \in \mathcal{H}(c)} \log p^{\text{LLM}}_v. $$
The final compact-token decision is then selected by score fusion:
$$ \hat{c} = \arg\max_{c \in \mathcal{V}_\text{trans} \setminus \{\varnothing\}} \bigl[w\log p^{\text{trans}}_c + (1-w)\log \tilde{p}^{\text{LLM}}_c\bigr], $$
with default fusion weight $w=0.5$. After the compact token is selected, the LLM chooses the surface form within the associated homophone set. For blank emissions, the LLM can also recover leading non-verbalized tokens before the acoustic frame advances, which is how punctuation is inserted without a separate post-processing stage.
This design is meant to preserve the transducer’s frame-level control while recovering the surface-form richness of the LLM. The ablation later in the paper shows that joint fusion is better than either endpoint alone, and that the compact vocabulary of 20K tokens is the best trade-off across offline, decoder-only, and streaming modes.
Training Objective and Streaming Mechanics
The total loss combines the LLM cross-entropy loss and the transducer loss:
$$ \mathcal{L}_\text{total} = (1-\alpha)\,\mathcal{L}_\text{ce} + \alpha\,\mathcal{L}_\text{trans}, $$
with default $\alpha=0.5$. The transducer loss is computed with the k2 pruned RNNT algorithm, which keeps the large-vocabulary transducer tractable by restricting the lattice to high-probability arcs. The LLM is trained with teacher forcing over the full token sequence, and for each verbalized token the prediction feature is taken from the LLM hidden state immediately preceding that token. This can correspond to a non-verbalized token, which matters because punctuation tokens are emitted on blank steps rather than through the transducer vocabulary.
Streaming is handled with chunk-synchronized training. At each chunk boundary, the LLM is refreshed on the audio observed so far, using only a bounded audio window and the partial transcript. The paper extends the chunk-synchronized scheme from the TAED line of work and adds a crucial optimization: gradients are stopped from the transducer path back into the LLM during streaming training. That avoids retaining a separate LLM activation graph for every chunk and keeps memory usage on the same order as offline training.
Dynamic chunk-size training is used throughout. For utterances up to 25 seconds, the chunk size is sampled from $\{4,8,16,24,32,\text{full}\}$ post-subsampling frames with probabilities $\{0.1,0.1,0.1,0.1,0.1,0.5\}$. Longer utterances are trained with full context. This exposes the model to both low-latency and offline-like conditions, so one checkpoint can be deployed across a continuous range of latency settings.
Localized Decoder Audio Attention and CADA
The other key streaming challenge is memory growth on long inputs. If the LLM attends to the entire acoustic history, KV-cache size grows with utterance length. TRADE addresses this with Localized Decoder Audio Attention (LDAA), a causal sliding window over recent acoustic context.
At acoustic frame $t$, the LLM observes an interval $[\tau^-_{\delta(t)},\tau^+_{\delta(t)})$ bounded by a left-context window and one lookahead chunk. The window size is expressed as $(N_l+2)\cdot C$ frames, where $N_l$ is the number of left-context chunks and $C$ is the chunk size. The paper chooses a 5-second left-context window by calibrating against acoustic support-span analysis; this is enough to cover the 99th percentile of token support span.
The streaming encoder itself uses Copy-and-Append Data Augmentation (CADA). CADA appends copy frames corresponding to the next chunk, and a block-diagonal attention mask ensures that each encoder layer sees exactly one chunk of lookahead without cascading future information across layers. Relative positional encoding is adjusted to use true temporal positions, and the Conformer convolution module is applied per chunk with explicit left-context and lookahead padding. The output is split into an original encoding and a lookahead encoding, and the CADA-aware adaptor processes both jointly so the LLM gets an anticipatory prefix without future-frame leakage.
The paper emphasizes that LDAA and CADA solve different problems: CADA makes streaming encoder computation causal and chunk-aware, while LDAA bounds the LLM-side memory footprint independently of utterance length. Together they make long-form inference feasible with a single checkpoint.
Model Configuration and Optimization
The decoder-side adapter stack is intentionally small. The encoder-decoder adaptor is a single-layer causal transformer with 2× frame-stacking downsampling. The transducer joint network is a single-hidden-layer MLP with ReLU. The model uses AdamW with $\beta_1=0.9$, $\beta_2=0.98$, and weight decay $10^{-3}$. Training uses cosine annealing with 500 warmup steps, minimum learning rate $10^{-6}$, and 35,000 total steps, with gradients clipped to 1.0 and accumulated over eight steps.
The fine-tuned encoder top six layers and the LoRA parameters use an effective learning rate of $10^{-4}$, while the adaptor and joint-network parameters use $10^{-3}$. Training is carried out in bfloat16 on 16 H200 GPUs.
The paper’s implementation uses a compact 20K-token transducer vocabulary derived from Llama-3.2-1B-Instruct. The vocabulary construction appendix reports that this choice keeps average token inflation close to the LLM tokenizer baseline while making the joint network tractable.
Training and Evaluation Data
The large-scale model is trained on approximately 153,411 hours of audio from a multi-domain corpus. The dominant sources are Granary YODAS English (102,461 hours, 66.8%) and Multilingual LibriSpeech English (44,420 hours, 29.0%), with smaller contributions from SPGISpeech, LibriSpeech variants, VoxPopuli, Earnings-22, and AMI. This breadth is meant to support both general ASR and long-form domain-robust transcription.
Evaluation covers the Open ASR Leaderboard English benchmark, LibriSpeech dev-other for streaming-latency analysis, TED-LIUM 3 for long-form ASR and end-of-utterance detection, and Earnings-21 / Earnings-22 for long-form finance-domain speech. The paper reports that WER is computed after Whisper-normalizing both hypotheses and references.
Main Results on the Open ASR Leaderboard
On the Open ASR Leaderboard English benchmark, TRADE achieves a 6.71% average WER on the eight test sets. This is slightly better than the paper’s decoder-only speech-LLM baseline at 6.87%, while also supporting streaming inference. The same checkpoint can be used in offline mode, streaming mode, or LLM-only decoding without architectural changes.
| System | Avg | AMI | E22 | Giga | LS-c | LS-o | SPGI | TED | Vox |
|---|---|---|---|---|---|---|---|---|---|
| Whisper-large-v3 | 7.44 | 15.95 | 11.29 | 10.02 | 2.01 | 3.91 | 2.94 | 3.86 | 9.54 |
| Parakeet-TDT-0.6B-v3 | 6.32 | 11.39 | 11.19 | 9.57 | 1.92 | 3.59 | 3.98 | 2.80 | 6.09 |
| Canary-1B-v2 | 7.15 | 16.01 | 11.79 | 10.82 | 2.18 | 3.56 | 2.28 | 4.29 | 6.25 |
| Decoder-only LLM (ours) | 6.87 | 16.16 | 11.51 | 10.07 | 1.70 | 3.01 | 2.23 | 3.71 | 6.59 |
| TRADE (offline) | 6.71 | 14.85 | 11.02 | 10.24 | 1.60 | 3.13 | 2.36 | 3.84 | 6.60 |
| TRADE (stream-960 ms) | 8.40 | 17.16 | 15.62 | 11.07 | 2.00 | 4.07 | 4.42 | 4.61 | 8.22 |
| TRADE (stream-640 ms) | 9.35 | 18.04 | 16.23 | 11.25 | 2.29 | 5.00 | 4.60 | 4.98 | 9.35 |
The paper’s interpretation is that joint transducer-LLM decoding recovers much of the quality of the pure decoder baseline while adding a principled streaming mechanism. The streaming gap is real, but the model remains competitive at 960 ms and 640 ms chunks from the same checkpoint. The recommended streaming operating point is 640 ms because it sits near the knee of the WER-latency curve.
Streaming Latency Trade-off
On LibriSpeech dev-other, the paper reports detailed streaming latency measurements across chunk sizes from 320 ms to 5,120 ms. Besides WER and average lagging, it reports differentiable average lagging (DAL), average proportion (AP), and real-time factor (RTF) on a single H200 GPU.
| Chunk (ms) | WER | AL (ms) | DAL (ms) | AP | RTF |
|---|---|---|---|---|---|
| 320 | 6.26 | 813 | 1263 | 0.61 | 0.171 |
| 480 | 4.83 | 989 | 1451 | 0.64 | 0.139 |
| 640 | 4.04 | 1217 | 1694 | 0.68 | 0.111 |
| 960 | 3.60 | 1674 | 2206 | 0.74 | 0.091 |
| 1280 | 3.56 | 2166 | 2761 | 0.80 | 0.082 |
| 5120 | 2.95 | 5431 | 5804 | 0.97 | 0.048 |
Several trends stand out. First, the biggest WER gain occurs when moving from 320 ms to 480 ms, and 640 ms is identified as the recommended compromise between latency and accuracy. Second, the curve flattens beyond 640 ms: 960 ms and 1280 ms improve WER only modestly relative to the extra lag. Third, every operating point runs below real time, with the worst RTF still only 0.171. The 5,120 ms setting approaches offline behavior while remaining faster than real time.
The paper also reports that DAL tracks AL closely but is always higher because it enforces monotone emission. AP rises from 0.61 at 320 ms to 0.97 at 5,120 ms, confirming that the model emits substantially before seeing the entire utterance except near the offline regime.
Long-Form ASR Results
TRADE is evaluated on long-form speech using 5,120 ms chunks together with the bounded LDAA window and a 20-token sliding text context window. This setup is designed to prevent runaway KV-cache growth and to avoid repetition or hallucination on hour-long recordings.
| System | TED-LIUM 3 | Earnings-21 | Earnings-22 |
|---|---|---|---|
| FastConf. FT+LCA+GT | 4.98 | 13.84 | 19.49 |
| Canary-1B-v2 with parallel chunks | — | — | 13.93 |
| TRADE | 3.64 | 9.75 | 10.88 |
TRADE is reported to outperform the compared long-form baselines on all three benchmarks, without external VAD segmentation or chunked post-processing. The paper notes GPU memory usage of around 8 GB during inference. The long-form recipe also includes a runtime repetition filter that detects short n-gram loops, removes the detected suffix from the active buffer, crops the LLM KV cache, and forces the decoder to advance one acoustic frame.
End-of-Utterance Detection
Because TRADE emits tokens with acoustic timestamps, the authors use punctuation emissions as a semantic signal for end-of-utterance detection. They evaluate on TED-LIUM 3 as unsegmented long-form audio, matching predicted boundaries to reference boundaries with a 0.5 s tolerance. Three predictors are compared: VAD-only, punctuation-only, and symmetric fusion, where a terminal or weak punctuation token must co-occur with a VAD silence onset within a window.
| Method | Precision | Recall | F1 |
|---|---|---|---|
| VAD-only | 0.336 | 0.684 | 0.451 |
| Punctuation-only | 0.216 | 0.793 | 0.340 |
| Symmetric fusion | 0.362 | 0.724 | 0.482 |
Symmetric fusion is the best method in the paper, improving over acoustic VAD alone by about 0.03 F1 absolute. The appendix further reports that at 320 ms streaming, 95.4% of utterances emit within 200 ms of the aligned reference end, and the 95th-percentile end-of-utterance latency changes by only about 80 ms between 320 ms and 5,120 ms chunks.
Vocabulary Ablations and Fusion Sensitivity
The paper studies two ablations that motivate the final design choices. First, fusion weight sensitivity shows that performance is fairly flat across a wide range of weights. On LibriSpeech test-other, TED, and Vox, the mean WER changes little for $w$ in the range 0.1 to 0.7, with the best mean at $w=0.3$ and only about 0.1% absolute spread between the endpoints and the optimum. This supports the claim that both the compact transducer and the LLM contribute complementary information.
| Mode / $w$ | LS-o | TED | Vox | Mean |
|---|---|---|---|---|
| Decoder ($w=0$) | 3.22 | 3.98 | 6.55 | 4.58 |
| TRADE, $w=0.1$ | 3.21 | 3.88 | 6.52 | 4.54 |
| TRADE, $w=0.3$ | 3.15 | 3.80 | 6.52 | 4.49 |
| TRADE, $w=0.5$ | 3.13 | 3.84 | 6.60 | 4.52 |
| TRADE, $w=0.7$ | 3.15 | 3.86 | 6.64 | 4.55 |
| TRADE, $w=0.9$ | 3.17 | 3.89 | 6.67 | 4.58 |
| Transducer ($w\to 1$) | 3.19 | 3.92 | 6.67 | 4.59 |
Second, vocabulary size matters. Across offline TRADE, decoder-only mode, and streaming mode, the 20K compact vocabulary is best. The streaming setting is especially sensitive: 20K substantially improves over 10K and 15K because it reduces fragmentation of mid-frequency words under bounded chunk context.
| Vocab | TRADE | Decoder mode | Stream-640 ms |
|---|---|---|---|
| 10K | 6.94 | 7.09 | 10.78 |
| 15K | 6.92 | 6.85 | 11.56 |
| 20K | 6.71 | 6.43 | 8.97 |
The vocabulary-construction appendix explains why 20K is the sweet spot: it keeps average token inflation small relative to the base LLM tokenizer while preserving enough coverage to avoid excessive fragmentation. The pruning procedure preserves all original token IDs, so the LLM can continue using its original embeddings and output projection unchanged.
Training Dynamics and Blank-Rate Regularization
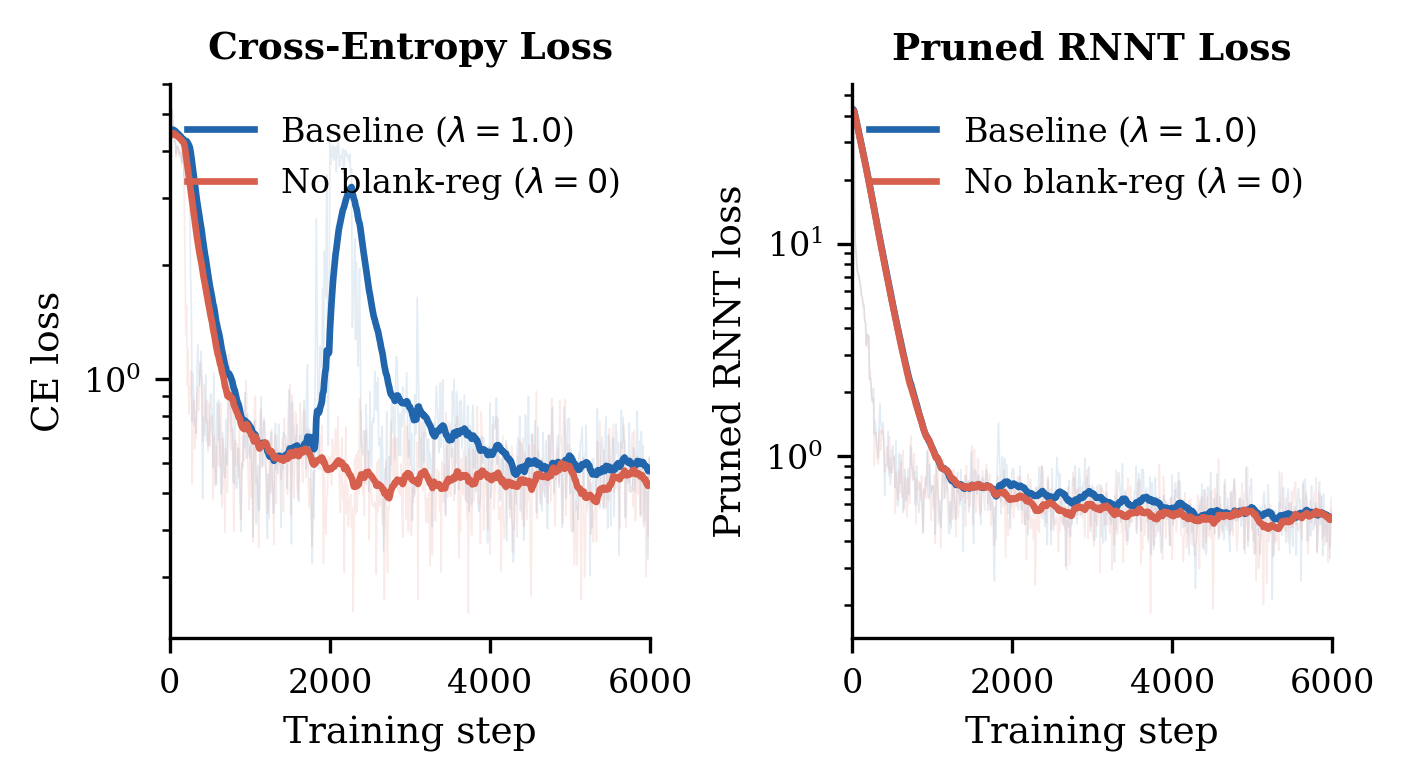
The appendix includes a blank-rate regularization ablation trained on LibriSpeech-960h for 6,000 steps. With no blank-rate regularization, cross-entropy falls faster early in training, which the authors interpret as the model collapsing toward the LLM path via over-blanking. The baseline with blank-rate regularization keeps the transducer more acoustically engaged, leading to slightly higher pruned RNNT loss but a healthier balance between the two objectives.
Acoustic Support Span and Timing Analysis
The paper analyzes the emission timing of the trained model to justify the LDAA window. On LibriSpeech test-other, across 320 ms, 640 ms, and 5,120 ms streaming modes, the acoustic support span distribution is invariant to chunk size. The mean span is 1.54 s, the 95th percentile is 2.56 s, the 99th percentile is 3.28 s, and the maximum is 14.80 s. A 3.5 s window covers the 99th percentile, while the default 5 s window leaves additional margin.
The same analysis shows that at 320 ms streaming, 95.4% of utterances emit within 200 ms of the reference end, with p5/p95 latency of [-320, +160] ms. The timing remains stable as chunk size changes, supporting the claim that the acoustic context requirement is largely independent of the chosen streaming operating point.
What the Paper Claims as Novel
- It turns the LLM hidden state into the transducer prediction network, making the transducer the frame-synchronous controller while preserving the LLM’s language modeling strengths.
- It derives a compact transducer vocabulary directly from the LLM vocabulary, preserving token IDs and enabling zero-cost score fusion with the LLM output distribution.
- It introduces chunk-synchronized streaming training with gradient stopping, so a single checkpoint can be used across offline and multiple streaming latencies without a large train-inference mismatch.
- It proposes localized decoder audio attention to bound decoder memory by a fixed sliding window, enabling long-form transcription without length-dependent KV-cache growth.
The authors position TRADE as a tighter alternative to prior streaming speech-LLM approaches that either hard-code timing or rely on auxiliary alignment signals. Their argument is that a transducer branch provides the principled acoustic frame alignment that label-synchronous LLM decoding lacks, while the LLM still handles linguistic reasoning and surface-form richness.
Limitations
The paper is explicit about several limitations. All experiments are English-only, so multilingual robustness is not evaluated. Streaming accuracy is still meaningfully worse than offline accuracy, as shown by the gap between 6.71% offline WER and 9.35% at 640 ms streaming on the leaderboard benchmark. End-of-utterance detection is evaluated only on TED-LIUM with boundaries derived from an automatic segmenter, not human annotation, and the resulting $F_1$ of 0.482 is moderate rather than strong.
Compute is another limitation: training requires 16 H200 GPUs, 35,000 optimizer steps, and about 153K hours of audio. The paper also notes that the model is built on a 1B-parameter LLM backbone and has not been scaled to larger LLMs, so the benefits of the transducer-LLM coupling at larger scale remain unverified.
Bottom Line
TRADE is a speech-LLM architecture that makes frame-synchronous decoding a first-class part of the model instead of an external heuristic. Its main contribution is not just higher recognition accuracy, but a practical operating envelope: one checkpoint can be used for offline ASR, several streaming latency points, long-form transcription, and punctuation-aware end-of-utterance detection. The empirical results suggest that the transducer branch improves streamability and timing control without sacrificing the LLM’s ability to recover fluent text, while the memory-bounding mechanisms make the design usable on long recordings.