Palindromic-VC
From A to B to A: Palindromic Zero-Shot Voice Conversion with Non-Parallel Data

Palindromic-VC is a zero-shot voice conversion method using synthetic pairs from KNN retrieval over self-supervised features for non-parallel training and strong speaker identity preservation, generalizing across languages without parallel data.
Demos
The demos showcase Palindromic-VC's ability to perform zero-shot voice conversion from a source to a target speaker and back to the source, using only non-parallel data. Listen for how well voice identity is preserved after the round-trip conversion and the naturalness and clarity of the synthesized speech, demonstrating the model's feature alignment and vocoder quality.

Links
Paper & demos
Abstract
We present a voice conversion (VC) framework that utilizes K-Nearest Neighbors (KNN) retrieval over WavLM representations to align non-parallel source and target speech, constructing synthetic training pairs for supervised learning. The retrieved segments serve as synthetic inputs, while real target audio provides ground-truth outputs, forming a synthetic-to-real training paradigm that naturally supports multilingual data without requiring parallel corpora or explicit alignment. To ensure consistent target-speaker identity, we incorporate a speaker loss derived from a pretrained speaker verification model. Experiments across multiple languages demonstrate that the proposed approach achieves high naturalness and strong speaker similarity, outperforming competitive VC baselines, despite being trained exclusively on English data. Samples can be accessed at: https://palindromic-vc.github.io.
Introduction and problem setting
This paper studies zero-shot, any-to-any voice conversion in a non-parallel setting: at inference time, the system sees an unseen source speaker, an unseen target speaker, and only a short target-side reference utterance, but no aligned source-target utterance pairs. The task is to modify the source speech so that it sounds like the target speaker while preserving linguistic content and remaining natural.
The paper positions itself against two common families of voice conversion methods. First, parallel-data methods are powerful but expensive because they require aligned utterances. Second, many non-parallel methods rely on disentangling content and speaker factors using ASR, TTS, or self-supervised features, which can be brittle, language dependent, or leaky with respect to speaker identity. As an alternative, the authors build supervision from synthetic pairs generated by KNN retrieval in a self-supervised feature space.
The key idea is what the authors call a palindromic training scheme: instead of converting real source speech directly to target speech during training, they first synthesize a source-like input from target audio, then train a model to map that synthetic input back to the real target. This yields supervised training signals without requiring parallel corpora.
- They use KNN retrieval over WavLM representations to construct synthetic training inputs from non-parallel speech.
- They add a waveform-level speaker verification loss using a pretrained speaker verification model to strengthen target-speaker identity preservation.
- They train and evaluate on English and test cross-lingual generalization on several languages from Multilingual LibriSpeech without non-English fine-tuning.
- They report improvements in speaker similarity and robustness relative to recent VC baselines, while remaining competitive on intelligibility and perceptual quality metrics.
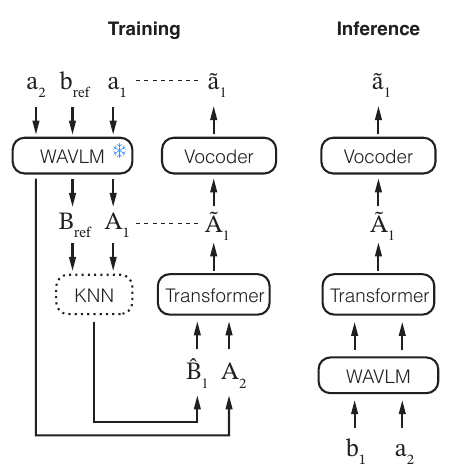
Method overview
The overall training pipeline uses a synthetic intermediate representation. Given a target utterance $a_1$ and a gallery of reference utterances from another speaker $b_{\mathrm{ref}}$, the system extracts WavLM features, retrieves acoustically similar segments via KNN, and produces a synthetic source feature sequence $\hat{B}_1$. During training, the model consumes this synthetic input together with a target-speaker reference and learns to reconstruct target-like features and waveforms.
The training triplet is described in the paper as $A_2$, $\hat{B}_1$, and $a_1$: $\hat{B}_1$ acts as the synthetic source, $a_1$ is the real target supervision, and $A_2$ provides an additional reference from the same target speaker. At inference time, the model is applied directly to real source speech with a target reference, so the method is not restricted to synthetic inputs once training is complete.
The reason for the term palindromic is that the model is trained on a procedure that conceptually goes from target speech to synthetic source-like speech and then back to target speech again, i.e., from $A$ to $B$ to $A$. This allows the framework to exploit non-parallel speech as though it were supervised data.
In the paper’s terminology, the KNN-based conversion backbone comes from KNN-VC-style retrieval over SSL features. The authors emphasize that the synthetic inputs can be generated offline, which makes the overall supervision scalable and decouples the expensive retrieval step from model optimization.
Architecture and training objectives
Stage 1: vocoder pre-training
The first stage trains a vocoder that maps WavLM features back to waveforms in an autoencoding setup. Following the KNN-VC baseline, the model uses the 6th layer of WavLM as the feature source. The vocoder has about 16 million parameters and is trained for 100K steps.
The vocoder objective combines waveform reconstruction and adversarial learning:
- Multi-resolution STFT loss for spectral reconstruction.
- Multi-period discriminator and multi-scale discriminator adversarial losses, in the HiFi-GAN style.
The purpose of this stage is to make waveform reconstruction stable enough that the next stage can use waveform-level supervision through a speaker verifier.
Stage 2: transformer training
The conversion model is a six-layer Transformer with 16 attention heads, hidden dimension 1024, and about 77 million parameters. It is trained for 800K steps with Adam and learning rate $3 \times 10^{-4}$.
The stage-2 objective is the sum of two terms:
$$ \mathcal{L} = \mathcal{L}_{\text{L1}} + \mathcal{L}_{\text{spk}}. $$
The first term, $\mathcal{L}_{\text{L1}}$, is an $L_1$ distance between the predicted target-side features and the ground-truth target features. The second term, $\mathcal{L}_{\text{spk}}$, is a speaker loss computed at the waveform level using a pretrained speaker verification model from ECAPA-style speaker recognition.
Concretely, the paper states that the model extracts speaker embeddings and hidden representations from both the reference waveform $a_2$ and the converted waveform $\widetilde{a}_1$, and then compares them using cosine similarity and $L_1$ distance. This pushes the converted output toward the target speaker’s identity directly in waveform space rather than relying only on feature reconstruction.
A notable implementation detail is that the authors found it important to use the same reference segment both as input to the transformer and in the speaker loss. They report that this choice makes training more stable and consistent.
Stage 3: vocoder post-training
In the final stage, the authors train a new vocoder instance on features produced by the transformer, again for 100K steps and using the same reconstruction and adversarial losses as in stage 1. The goal is to adapt the vocoder to the feature distribution emitted by the conversion transformer rather than only to clean WavLM features.
This stage is explicitly motivated as a way to reduce artifacts and improve naturalness in the final waveform output. The ablation section shows that post-training can raise DNS-MOS while largely preserving speaker similarity and intelligibility.
Datasets and evaluation protocol
Training and in-language testing use LibriSpeech (the paper states 960 hours). For multilingual evaluation, the authors use test sets from Multilingual LibriSpeech.
Training pairs are created by randomly pairing audio segments from different source and target speakers. The paper states that it generates three different target speakers for each segment across the 960 hours of LibriSpeech.
Multilingual evaluation is performed on the following languages and speaker counts:
| Language | # Source | # Target | Total duration (min.) |
|---|---|---|---|
| Dutch | 6 | 6 | 148 |
| English | 27 | 27 | 85 |
| French | 17 | 17 | 150 |
| German | 25 | 25 | 151 |
| Italian | 10 | 10 | 153 |
| Polish | 4 | 4 | 147 |
| Portuguese | 10 | 10 | 156 |
| Spanish | 18 | 18 | 152 |
Evaluation is carried out at four prompt durations: 3, 10, 30, and 60 seconds. For each language, the authors evaluate three random seeds of 50 randomly selected source-target pairs.
Objective metrics are speaker similarity, Equal Error Rate $\mathrm{EER}$, Word Error Rate $\mathrm{WER}$, Character Error Rate $\mathrm{CER}$, and DNS-MOS for multilingual quality. The paper uses Redimnet Speaker Verifier for speaker similarity and $\mathrm{EER}$, and Whisper-Large-V3 for transcript-based $\mathrm{WER}$ and $\mathrm{CER}$. For fairness, the speaker verification model used for evaluation is different from the one used in the speaker loss.
Subjective evaluation uses MOS and SMOS on a 1--5 scale. Three samples are selected from each duration category, giving twelve samples total, and each category is rated by at least ten participants.
English results
The paper compares the method against Seed-VC, KNN-VC, Vevo, and O\_O-VC. On English data, the authors report that their method is strongest on speaker identity preservation, while remaining broadly competitive on intelligibility and human-rated quality.
A careful reading of the table shows that the paper marks its method as best for speaker similarity and EER across all durations, while several baselines remain stronger on some naturalness and transcription metrics. In particular, Vevo and O\_O-VC obtain very strong WER/CER values in some duration settings, and Seed-VC is competitive on some subjective scores. The main reported advantage of the proposed method is therefore not that it dominates every metric, but that it provides the most consistent identity preservation without a clear quality or intelligibility penalty.
| Model | Prompt (s) | Spk Sim | EER | WER | CER | MOS | SMOS |
|---|---|---|---|---|---|---|---|
| Seed-VC | 3 | 0.455 | 0.007 | 0.041 | 0.019 | 3.545 | 3.200 |
| Seed-VC | 10 | 0.578 | 0.060 | 0.042 | 0.021 | 3.000 | 3.500 |
| Seed-VC | 30 | 0.622 | 0.083 | 0.026 | 0.011 | 3.666 | 3.583 |
| Seed-VC | 60 | 0.630 | 0.090 | 0.033 | 0.014 | 3.400 | 3.600 |
| KNN-VC | 3 | 0.380 | 0.033 | 0.430 | 0.277 | 1.182 | 1.500 |
| KNN-VC | 10 | 0.552 | 0.053 | 0.115 | 0.062 | 2.588 | 2.642 |
| KNN-VC | 30 | 0.617 | 0.070 | 0.042 | 0.018 | 3.500 | 3.500 |
| KNN-VC | 60 | 0.631 | 0.073 | 0.046 | 0.020 | 3.000 | 2.800 |
| Vevo | 3 | 0.510 | 0.047 | 0.038 | 0.013 | 3.909 | 4.100 |
| Vevo | 10 | 0.639 | 0.133 | 0.033 | 0.011 | 3.765 | 4.071 |
| Vevo | 30 | 0.651 | 0.093 | 0.022 | 0.007 | 3.750 | 3.750 |
| Vevo | 60 | 0.332 | 0.010 | 0.197 | 0.129 | 1.300 | 1.200 |
| O\_O-VC | 3 | 0.368 | 0.010 | 0.050 | 0.018 | 3.636 | 3.500 |
| O\_O-VC | 10 | 0.419 | 0.020 | 0.036 | 0.019 | 3.588 | 4.071 |
| O\_O-VC | 30 | 0.431 | 0.007 | 0.038 | 0.013 | 3.583 | 3.666 |
| O\_O-VC | 60 | 0.453 | 0.010 | 0.031 | 0.012 | 3.800 | 3.100 |
| Ours | 3 | 0.612 | 0.097 | 0.056 | 0.023 | 3.455 | 3.300 |
| Ours | 10 | 0.713 | 0.180 | 0.049 | 0.022 | 3.647 | 4.000 |
| Ours | 30 | 0.717 | 0.170 | 0.047 | 0.019 | 3.666 | 3.583 |
| Ours | 60 | 0.712 | 0.150 | 0.050 | 0.021 | 3.800 | 3.300 |
The most important pattern is that the proposed system is strongest on identity-related metrics, especially at short prompt durations where reference information is limited. The paper explicitly notes that KNN-VC degrades substantially in the low-resource 3-second setting, while the palindromic training strategy remains robust.
For subjective evaluation, the authors report that under short prompts of 3 and 10 seconds, their method achieves significantly higher MOS and SMOS than KNN-VC. As the prompt length increases to 30 and 60 seconds, the performance gap narrows, but the method still remains stable.
Cross-lingual generalization
The multilingual experiments are important because the model is trained exclusively on English, yet evaluated on Dutch, French, German, Italian, Polish, Portuguese, and Spanish in addition to English. The paper emphasizes that no fine-tuning on non-English data is used.
The figure in the paper shows that the method achieves consistent WER improvements across all prompt durations in the multilingual setting, while speaker similarity and DNS-MOS remain broadly comparable to competitive methods. This is the paper’s main evidence that the synthetic supervision scheme generalizes beyond the training language.
The authors also highlight that the method does not require explicit prosody modeling. In contrast to O\_O-VC, which uses a dedicated $F_0$ conditioning adapter to address prosodic mismatch, the proposed system keeps the design simpler while still maintaining prosodic consistency reasonably well according to the reported examples and comparisons.
Ablation: vocoder post-training
The main ablation isolates the effect of stage-3 vocoder post-training. The authors report that, before post-training, the converted audio contains audible artifacts even though speaker similarity and WER are already strong. Post-training is meant to adapt the vocoder to transformed feature distributions and remove these artifacts.
| Model | Prompt (s) | Spk Sim | WER | DNS-MOS |
|---|---|---|---|---|
| Without vocoder post-training | 3 | 0.580 | 0.057 | 3.396 |
| Without vocoder post-training | 10 | 0.696 | 0.046 | 3.621 |
| Without vocoder post-training | 30 | 0.718 | 0.037 | 3.753 |
| Without vocoder post-training | 60 | 0.725 | 0.033 | 3.801 |
| With vocoder post-training | 3 | 0.582 | 0.050 | 3.366 |
| With vocoder post-training | 10 | 0.689 | 0.042 | 3.770 |
| With vocoder post-training | 30 | 0.695 | 0.033 | 3.819 |
| With vocoder post-training | 60 | 0.697 | 0.045 | 3.834 |
The ablation supports the authors’ claim that post-training improves perceptual quality: DNS-MOS is higher for three of the four prompt durations, while speaker similarity and WER remain broadly in the same range. The effect is modest at short durations and more visible at 10, 30, and 60 seconds.
What the paper claims as its main contributions
- A non-parallel, zero-shot, any-to-any VC framework that learns from controlled synthetic supervision rather than aligned data.
- A palindromic training strategy that turns target speech into synthetic source-like input and then learns to invert that mapping back to the target.
- A waveform-level speaker verification loss that directly encourages identity preservation and improves speaker similarity relative to the baseline backbone.
- Multilingual generalization from English-only training without non-English fine-tuning.
Limitations and future work
The paper does not provide a separate failure-analysis section, but its results and closing discussion make several constraints clear. First, the training recipe is still centered on a pretrained SSL encoder, a vocoder, and a speaker verifier, so the system depends on strong pretrained components rather than learning everything end to end from raw audio. Second, the multilingual evaluation is only at test time; the model is not adapted to the non-English languages during training. Third, the authors note that vocoder post-training is useful because otherwise artifacts remain audible, which means waveform quality is still sensitive to the decoder stage.
In the conclusion, the authors explicitly list future work directions: scaling the method to larger datasets, handling highly expressive speech, and extending the framework toward real-time and streaming voice conversion. Those are the only future directions stated in the paper, so they should be treated as the paper’s own identified open problems rather than additional speculation.