BareWave
BareWave: Waveform-Native Flow-Matching Text-to-Speech
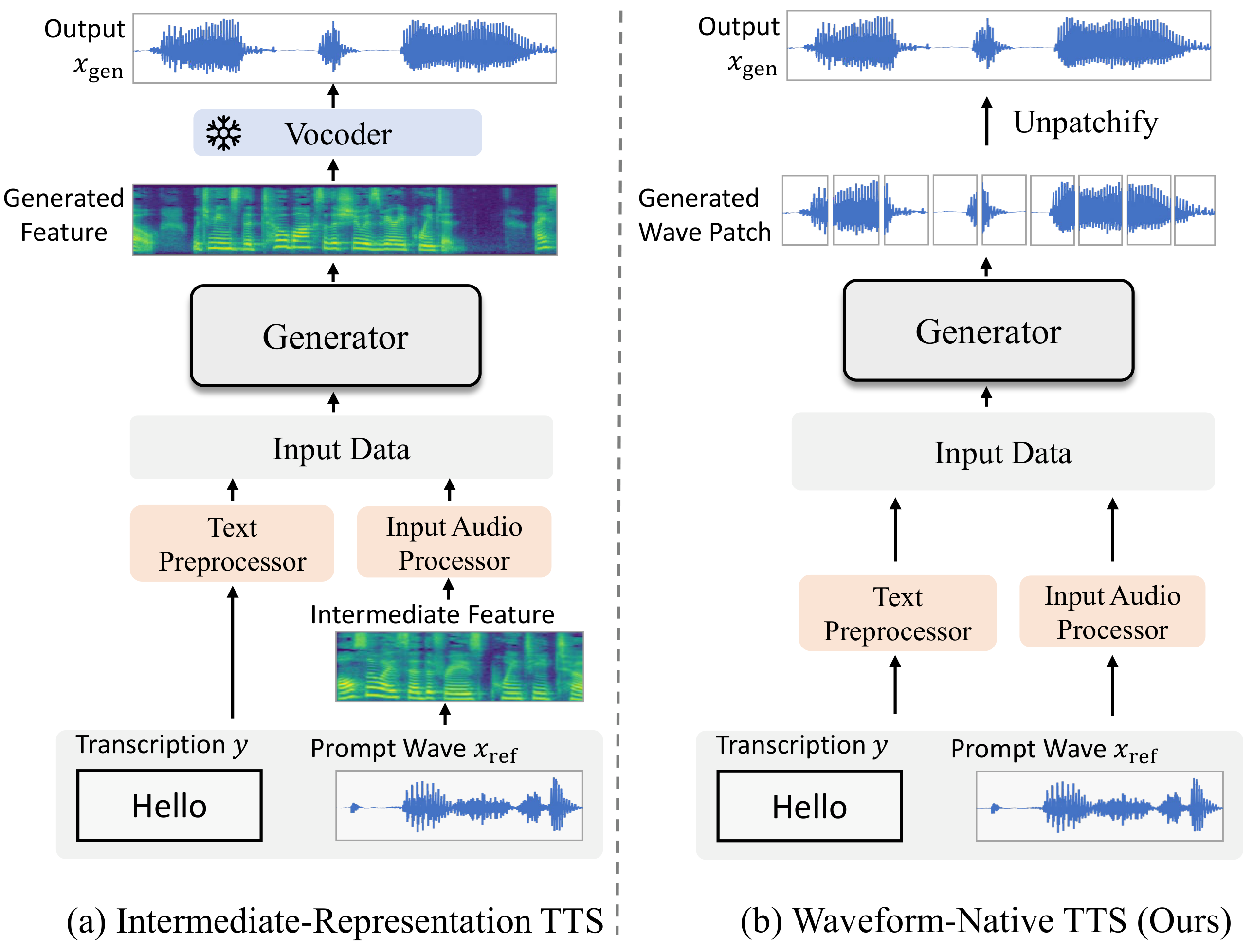
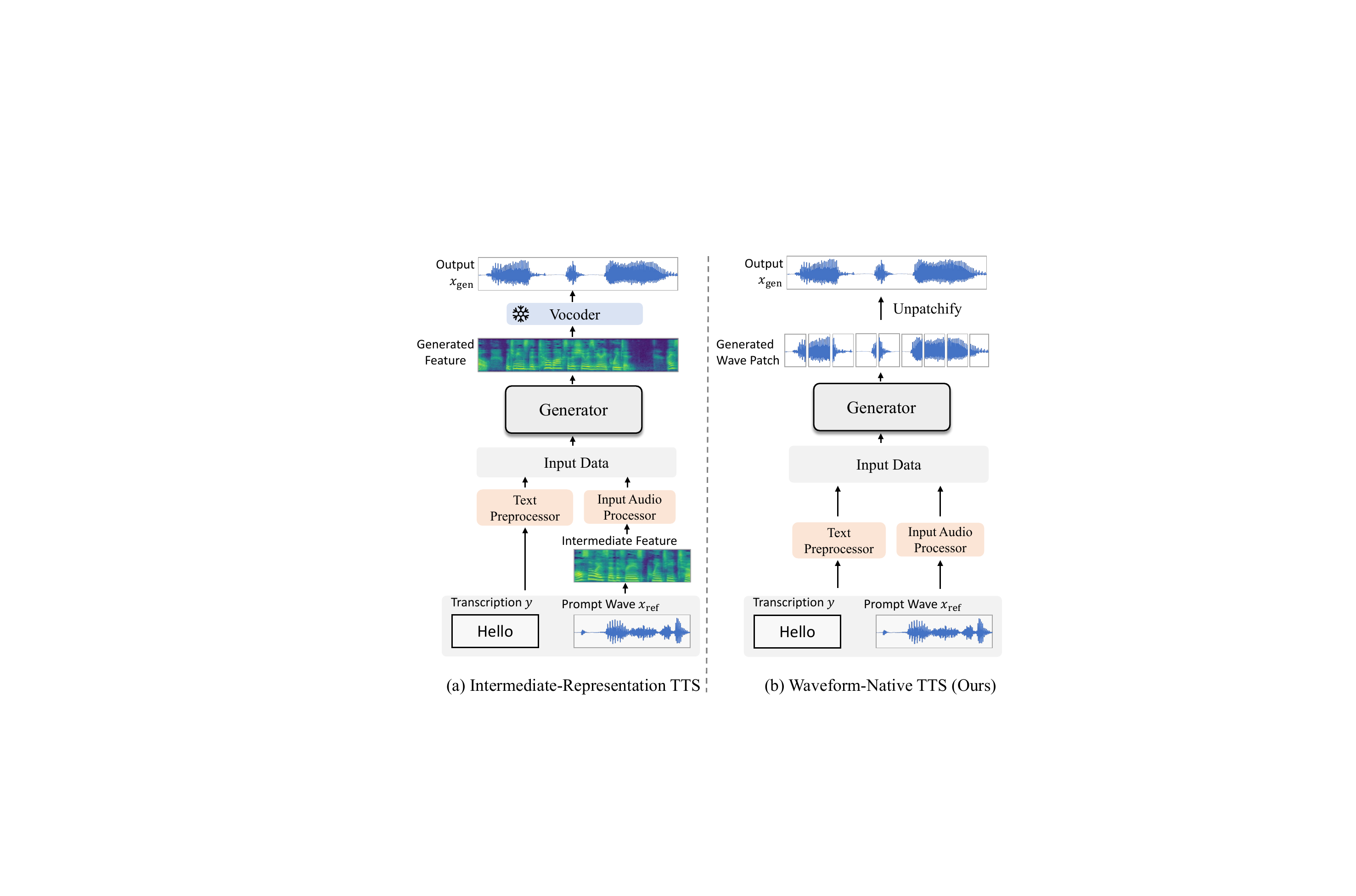
BareWave is a waveform-native text-to-speech model that directly synthesizes waveforms from text and prompt audio without intermediate steps. It introduces new training methods to address waveform modeling challenges, enabling high-quality zero-shot voice cloning with a streamlined inference process.
Demos
The BareWave demos showcase a waveform-native text-to-speech system that directly generates speech waveforms without intermediate representations. Focus on the naturalness, intelligibility, and speaker similarity under zero-shot voice cloning compared to strong baselines. The training innovations—representation alignment, staged noise scheduling, and velocity-aware perceptual alignment—drive improved quality and efficiency.
Links
Paper & demos
Impact
Abstract
Removing intermediate representations and separately trained decoding stages has become an important direction in generative modeling. In text-to-speech, however, high-quality systems are still commonly built through an intermediate acoustic representation before waveform synthesis. In this work, we present BareWave, a fully waveform-native framework for direct text-to-wave generation in flow-matching TTS. We consider this setting to raise three training challenges: raw-waveform modeling lacks a strong pretrained representational scaffold, different stages of training benefit from different noise schedules, and data-space perceptual objectives do not automatically share the temporal structure of the velocity-space flow objective. As a result, direct waveform training is hard to optimize efficiently, hard to push toward a strong final operating point with a fixed recipe, and hard to integrate effective perceptual refinement. Guided by this view, we develop a direct text-to-wave training framework that combines training-time representation alignment, staged noise scheduling, and velocity-aware perceptual alignment (VAPA), while preserving a single waveform-native inference path without pretrained components at test time. Experiments on zero-shot voice cloning show that strong intelligibility, speaker similarity, and naturalness can be achieved under a fully waveform-native inference path, supporting waveform-native flow-matching TTS as a practical direction. Project page with audio demos is available at https://barewave.github.io/.
Introduction
BareWave studies zero-shot text-to-speech under a strict waveform-native constraint: the model should synthesize waveform samples directly from text and a short prompt waveform, without an intermediate acoustic representation and without a separately trained vocoder at inference. The paper positions this as a stronger form of simplification than recent high-quality zero-shot pipelines, which often still rely on codec tokens, mel-spectrograms, speaker encoders, pretrained text encoders, or a separate waveform decoder.
The core claim is that a direct waveform model can be made practical if the training recipe compensates for three difficulties that arise once inference-time crutches are removed:
- Lack of pretrained representational scaffolding: the model must organize linguistic, speaker, and acoustic structure directly in waveform space.
- Noise-schedule sensitivity across training: early optimization and late refinement benefit from different timestep distributions.
- Mismatch between flow loss and perceptual refinement: the main flow objective is evaluated in velocity space, while perceptual losses live in data space and do not automatically receive the same time-dependent weighting.
To address these issues, BareWave combines training-time representation alignment, staged noise scheduling, and velocity-aware perceptual alignment (VAPA), while keeping inference as a single text-and-prompt-to-waveform generator.
Problem Formulation and High-Level Design
The task is framed as conditional speech infilling for zero-shot voice cloning. Given text $c$ and a prompt waveform $a$, the model predicts a target waveform $hat{x}$ directly. During training, a random target span is masked, and the remaining waveform plus the full text condition provide context. This infilling setup lets the authors train on long waveform sequences while still learning prompt-conditioned synthesis.
The paper emphasizes that the final inference graph is intentionally minimal. All auxiliary components used during training are removed at test time, so the model does not depend on a pretrained speech encoder, a separate vocoder, or an intermediate latent representation at inference.
Method
Flow Matching on Waveform Samples
Training uses conditional flow matching. A clean waveform $x$ and noise sample $\epsilon$ are interpolated by
$$z_t = t x + (1-t)\epsilon, \qquad t \in [0,1],$$
with velocity
$$v = \frac{\partial z_t}{\partial t} = x - \epsilon.$$
The model learns a velocity field $v_\theta(z_t,t,c,a)$ by minimizing mean-squared error to the target velocity:
$$\mathcal{L}_{\mathrm{CFM}} = \mathbb{E}_{x,\epsilon,t}\left[\lVert v_\theta(z_t,t,c,a)-v\rVert_2^2\right].$$
The generator is parameterized to directly predict the clean waveform target, $\hat{x}_\theta = f_\theta(z_t,t,c,a)$, rather than noise or velocity. The paper notes that converting this $x$-prediction into velocity space induces a reweighting:
$$\hat{v}_\theta = \frac{\hat{x}_\theta - z_t}{1-t}, \qquad v = \frac{x - z_t}{1-t},$$
and, on the masked region, the corresponding flow loss becomes
$$\mathcal{L}_{\mathrm{fm}} = \mathbb{E}_{i: M_i=1}\,\frac{1}{(1-t)^2}(\hat{x}_{\theta,i}-x_i)^2.$$
This conversion is central to the paper’s argument: losses expressed in data space are implicitly amplified near the clean endpoint when viewed through the velocity-space flow objective.
Sampling and Classifier-Free Guidance
At inference, waveform generation is obtained by integrating the ODE
$$\frac{\mathrm{d} z_t}{\mathrm{d} t} = \tilde{v}_\theta(z_t,t,c,a).$$
The paper uses a fixed-step Heun solver. Classifier-free guidance is enabled by randomly dropping the prompt-audio condition, and sometimes both prompt audio and text, during training. In inference, the conditional and unconditional predictions are combined as
$$\tilde{v}_t = \hat{v}_t^{\mathrm{uncond}} + s(t)\bigl(\hat{v}_t^{\mathrm{cond}}-\hat{v}_t^{\mathrm{uncond}}\bigr),$$
where the guidance strength is applied within a prescribed interval and reduced to $1$ outside that interval.
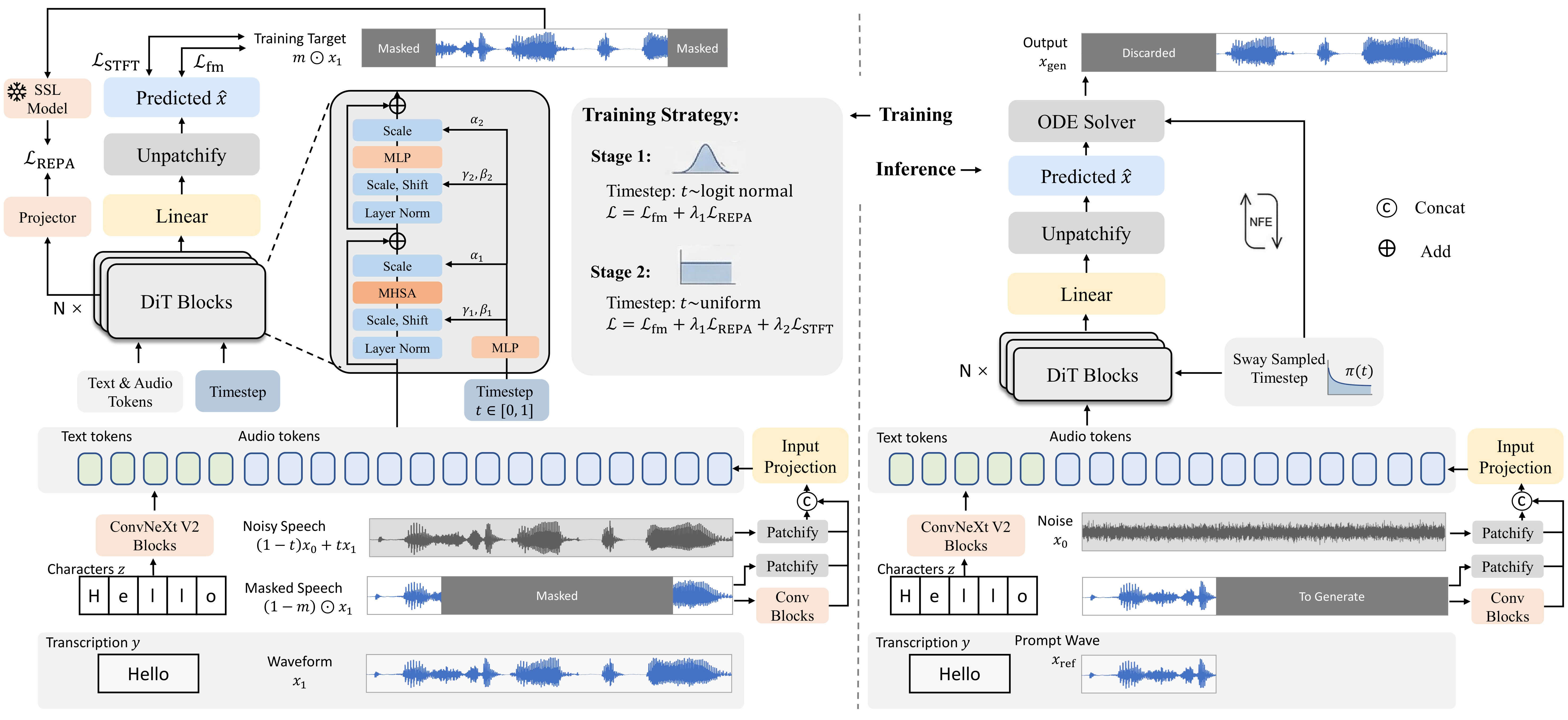
Waveform-Patch DiT Backbone
The generator is a waveform-patch DiT rather than a spectrogram or codec-token model. The noisy waveform is patchified by a 1-D convolutional embedder with kernel size and stride equal to the patch size. In the experiments, the patch size is 768 samples, which corresponds to about 32 ms at 24 kHz.
Prompt audio is represented using a hierarchical prompt stream: one branch uses a dedicated convolutional frontend to extract coarse downsampled features aligned to the patch rate, and another branch passes raw prompt waveform patches directly. Text is represented at the character level, refined by four ConvNeXt-style blocks, and inserted as in-context tokens before the audio stream. The unified token sequence is processed by 32 DiT blocks with timestep modulation and rotary positional encoding. A final layer predicts patch-wise clean waveform values, and a non-overlapping unpatchify step reconstructs the waveform.
The reported architecture hyperparameters are:
- 32 DiT blocks
- 16 attention heads
- Hidden size 1280
- MLP ratio 4.0
- Total parameters: 983.6M
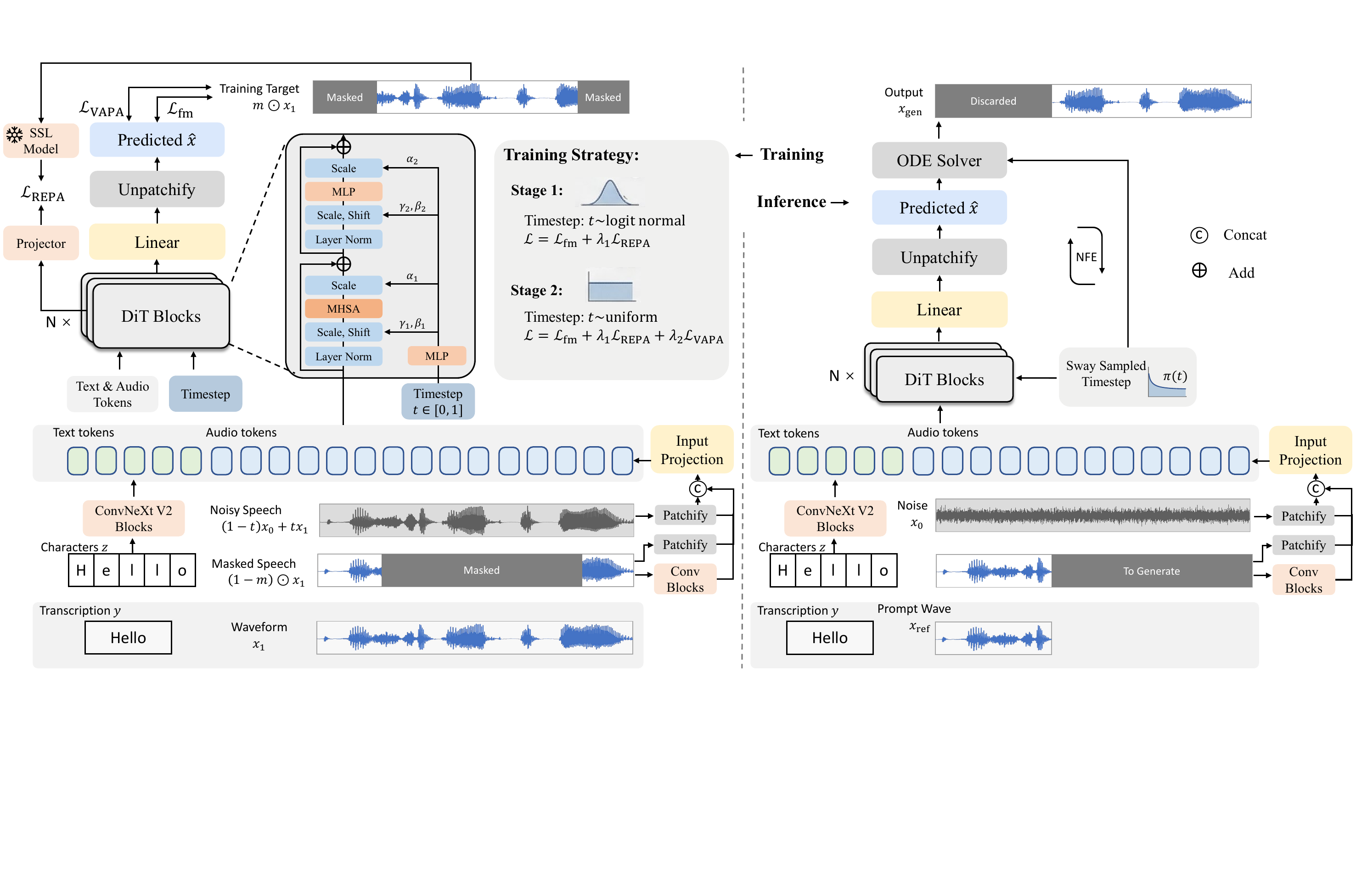
Training Strategy
Training-Time Representation Alignment
To supply a missing speech prior, the model aligns an internal hidden state to frozen self-supervised speech features from WavLM-base+, computed on the ground-truth target waveform. A selected transformer-layer representation $h_\ell$ is linearly interpolated to the teacher length, passed through a lightweight projection head, and matched with a cosine-distance loss:
$$\mathcal{L}_{\mathrm{REPA}} = \mathbb{E}_{i \in \Omega}\left[1 - \cos\bigl(\phi(h_\ell)_i, h^{\mathrm{teacher}}_i\bigr)\right].$$
The projection head is small by design: two Conv1d--GroupNorm--Mish blocks followed by a $1\times1$ Conv1d output layer. This branch is strictly training-only and is removed at inference.
Staged Noise Scheduling
The authors argue that a single timestep distribution is not ideal throughout optimization. Instead, they use a two-stage schedule over normalized training progress $u \in [0,1]$:
$$p(t \mid u) = \begin{cases} p_{\mathrm{logit\text{-}normal}}(t;\mu,\sigma), & u < \rho,\\ p_{\mathrm{uniform}}(t), & u \ge \rho, \end{cases}$$
where the first stage uses a convergence-friendly logit-normal distribution and the later stage switches to uniform sampling to emphasize cleaner regions. In the main experiments, the first stage uses $\mu=-0.4$, $\sigma=0.8$, and noise scale 0.1. For REPA runs, the switch to uniform occurs at 240k equivalent updates.
Velocity-Aware Perceptual Alignment (VAPA)
The perceptual term uses a multi-resolution STFT distance combining phase, log-magnitude, local spectral-gradient, and Laplacian components. The paper’s key observation is that a fixed-weight perceptual loss becomes relatively underweighted near the clean endpoint, because the flow objective effectively introduces a stronger time-dependent weighting there.
To compensate, VAPA scales the perceptual loss by a velocity-aware factor:
$$\mathcal{L}_{\mathrm{VAPA}} = \mathbb{E}_{x,\epsilon,t}\left[(1-t)^{-\gamma}\,\mathcal{D}_{\mathrm{STFT}}\bigl(\hat{x}_\theta(z_t,t,c,a),x\bigr)\right].$$
The paper uses $\gamma=1$, matching the norm order of the base STFT and mel-style distances, and clips $1-t$ by $\epsilon_t=0.01$ for numerical stability. VAPA is enabled only in the late refinement stage.
Overall Objective
The total training objective is
$$\mathcal{L}_{\mathrm{total}} = \mathcal{L}_{\mathrm{fm}} + \lambda_1 \mathcal{L}_{\mathrm{REPA}} + \mathbb{I}[u \ge \rho]\,\lambda_2 \mathcal{L}_{\mathrm{VAPA}}.$$
The reported weights are $\lambda_1 = 0.0025$ and $\lambda_2 = 4 \times 10^{-4}$.
Datasets, Training Setup, and Evaluation
All same-data experiments are trained on the English subset of Emilia. After filtering out utterances with transcription failures or language mismatches, the corpus contains 19.4k hours of 24 kHz speech. Training examples are limited to utterances between 0.3 s and 30 s, converted to mono if needed, and DC offset is removed before batching.
The evaluation task is zero-shot voice cloning, reported on two test sets:
- Seed-TTS test-en
- LibriSpeech-PC test-clean, using a cross-sentence protocol with 1127 evaluation samples
For each evaluation pair, the synthesis text is formed by concatenating the prompt transcript and the target transcript. Unless otherwise specified, the target duration is estimated from the prompt duration and the prompt/target text-length ratio, avoiding oracle duration at test time.
Metrics are:
- WER for intelligibility and content fidelity, computed with Whisper-large-v3 via Faster-Whisper
- SIM-o for speaker similarity, computed with a WavLM-large-based ECAPA-TDNN speaker verification model
- UTMOS for perceptual naturalness, computed with the open-source SpeechMOS evaluator
Training details reported in the paper include 4 NVIDIA A800 GPUs, Muon for the DiT backbone, AdamW for the remaining parameters, learning rates of $10^{-3}$ and $5\times10^{-5}$, zero weight decay, 20k warmup updates, and gradient clipping of 1.0. Runs without REPA use a batch size of 19200 waveform frames, while REPA runs use 9600 due to memory limits. All update counts are reported as equivalent updates normalized to seen data volume.
The first-stage logit-normal schedule uses $\mathrm{logit}(t) \sim \mathcal{N}(\mu,\sigma^2)$ with $\mu=-0.4$ and $\sigma=0.8$. The main training recipe uses 640k equivalent updates. Prompt-audio dropout for classifier-free guidance is 0.3, and joint text-plus-prompt dropping is 0.2. Inference uses 50 NFE steps, Heun integration, sway coefficient $-1.0$, guidance scale 3.5, and EMA 0.9999.
Main Results
Table 1 summarizes the paper’s main zero-shot voice-cloning results. The strongest message is that a fully waveform-native system can be competitive with strong intermediate-representation baselines, while preserving a simpler inference path.
| Method | Training data | Params | Seed-TTS WER | Seed-TTS SIM-o | Seed-TTS UTMOS | LibriSpeech WER | LibriSpeech SIM-o | LibriSpeech UTMOS |
|---|---|---|---|---|---|---|---|---|
| Ground Truth | -- | -- | 1.86 | 0.734 | 3.53 | 2.48 | 0.695 | 4.10 |
| CosyVoice 2 | 167K Multi. | 618M | 2.51 | 0.659 | 4.15 | 2.05 | 0.659 | 4.38 |
| FireRedTTS | 248K Multi. | ~580M | 3.82 | 0.46 | -- | 2.69 | 0.47 | -- |
| F5-TTS Base (+ Vocos) | 19.4k EN | 335.8M + 13.5M | 2.09 | 0.573 | 3.83 | 3.17 | 0.597 | 4.10 |
| E2-TTS Base (+ Vocos) | 19.4k EN | 333M + 13.5M | 3.50 | 0.582 | 3.41 | 4.32 | 0.632 | 3.84 |
| Simple direct-wave baseline | 19.4k EN | 983.6M | 2.42 | 0.424 | 3.35 | 3.45 | 0.416 | 3.60 |
| BareWave (basic training) | 19.4k EN | 983.6M | 2.34 | 0.478 | 3.43 | 3.32 | 0.471 | 3.69 |
| BareWave (proposed training scheme) | 19.4k EN | 983.6M | 1.75 | 0.602 | 3.72 | 2.88 | 0.614 | 4.01 |
On Seed-TTS test-en, BareWave with the proposed training scheme obtains the best same-data WER and SIM-o, at 1.75% WER and 0.602 SIM-o, while reaching 3.72 UTMOS. On LibriSpeech-PC, it reaches 2.88% WER and 0.614 SIM-o, improving over F5-TTS Base on both metrics and trailing E2-TTS Base on SIM-o. The authors note that BareWave is slightly below F5-TTS Base on UTMOS in some comparisons, which they attribute to the difficulty of single-stage waveform rendering without a dedicated vocoder.
Among the waveform-native baselines, the simplest direct-wave system already achieves 3.45% WER, 0.416 SIM-o, and 3.60 UTMOS, showing that direct waveform modeling is viable but not yet strong. Adding a stronger prompt-side representation hierarchy improves this to 3.32% WER, 0.471 SIM-o, and 3.69 UTMOS, indicating that prompt-side structure matters. The full BareWave recipe then substantially improves the operating point.
Ablations and Analysis
REPA Ablation and Data Efficiency
The paper first isolates representation alignment by comparing matched-budget models with and without REPA. The reported curves show that REPA consistently improves training efficiency, with the most stable gains in SIM-o and additional gains in WER and UTMOS. The interpretation is that the frozen WavLM teacher gives the raw waveform model a more informative speech prior during optimization.
Noise Schedule, Perceptual Loss, and VAPA
Table 2 reports the ablation of the staged schedule and perceptual refinement on LibriSpeech-PC near a 600k equivalent training budget.
| Recipe | WER | SIM-o | UTMOS |
|---|---|---|---|
| Base (w/o REPA) | 3.32 | 0.471 | 3.69 |
| + REPA | 2.86 | 0.522 | 3.70 |
| + late uniform | 2.93 | 0.543 | 3.82 |
| + late uniform + refined STFT | 3.38 | 0.585 | 3.88 |
| + late uniform + refined STFT + VAPA | 3.52 | 0.610 | 3.97 |
The ablation shows a clear progression:
- REPA improves the base waveform model by adding representational scaffolding.
- Late uniform continuation increases SIM-o and UTMOS relative to the REPA-only model, suggesting that later training benefits from denser clean-region sampling.
- Refined STFT further improves perceptual metrics, especially naturalness.
- VAPA gives the best SIM-o and UTMOS in the ablation, confirming that velocity-aware scaling makes the perceptual loss more effective in the refinement stage.
The paper also analyzes the logit-normal first-stage noise distribution. Compared with a uniform timestep distribution, the logit-normal schedule focuses on middle noise levels and converges much faster early in training. The resulting curves show substantially better WER and SIM-o at the same early budget, while UTMOS is less sensitive. This supports the authors’ claim that the first stage should be optimized for convergence rather than final clean-state coverage.
The effect of the logit-normal mean is also examined. Lower means improve WER in the sweep, while higher means improve SIM-o and UTMOS, indicating that the early noise distribution shifts the operating point rather than providing a single universally best value.
Prompt-Side Representation Hierarchy
The paper isolates the prompt path and shows that a representation hierarchy on the prompt side improves waveform-native synthesis. Using the same training data and no REPA, the simple direct-wave baseline reaches 3.45% WER and 0.416 SIM-o, whereas adding the representation hierarchy improves to 3.32% WER and 0.471 SIM-o. The authors interpret this as evidence that prompt conditioning benefits from a stronger internal organization of the prompt signal.
| Variant | WER | SIM-o |
|---|---|---|
| Simple direct-wave baseline | 3.45 | 0.416 |
| + Representation Hierarchy | 3.32 | 0.471 |
Teacher-Layer Sensitivity for REPA
The REPA target layer affects the trade-off between metrics. Deeper teacher layers reduce WER, while an intermediate layer, reported as layer 10, gives stronger SIM-o than a shallow layer-6 target. In the supplemental setup, the selected source layer is the 18th DiT block. The main conclusion is that alignment depth changes the balance among intelligibility, similarity, and naturalness rather than improving all three equally.
Inference-Time CFG Sweep
The paper scans classifier-free guidance from 2.5 to 10.0 under the Heun-50 setting. Stronger guidance generally improves WER, but SIM-o peaks at CFG 3.5 and then declines as guidance becomes too strong. The selected operating point is therefore 3.5, because it gives the best balance of SIM-o and UTMOS while retaining competitive WER.
What Is Novel Here?
- Fully waveform-native zero-shot TTS: the model removes the intermediate acoustic representation, pretrained inference-time components, and separate vocoder from the test-time path.
- Training-only scaffolding: REPA, staged noise schedules, and VAPA are used strictly to make direct waveform optimization work better, not to complicate inference.
- Velocity-aware perceptual design: the paper explicitly links the time dependence of the flow objective to the scaling of perceptual losses and corrects for the mismatch.
- Practical zero-shot results: the system achieves competitive intelligibility and similarity under a single direct text-to-waveform path.
Limitations
The main limitation stated in the paper is scale: the waveform-native generator uses 983.6M parameters, which is larger than the compared mel-based baselines and therefore increases training and inference cost. The authors suggest compression and distillation as promising future directions.
Conclusion
BareWave demonstrates that direct waveform generation for zero-shot TTS is not only feasible but competitive when the training recipe is carefully designed. The combination of training-time representation alignment, staged timestep sampling, and velocity-aware perceptual alignment gives the model the missing prior, better optimization dynamics, and a perceptual refinement mechanism that is consistent with the flow-matching objective. The result is a single waveform-native inference path with no intermediate acoustic representation or separate vocoder, supporting waveform-native flow-matching TTS as a practical direction.