MeanVC 2
MeanVC 2: Robust Low-Latency Streaming Zero-Shot Voice Conversion
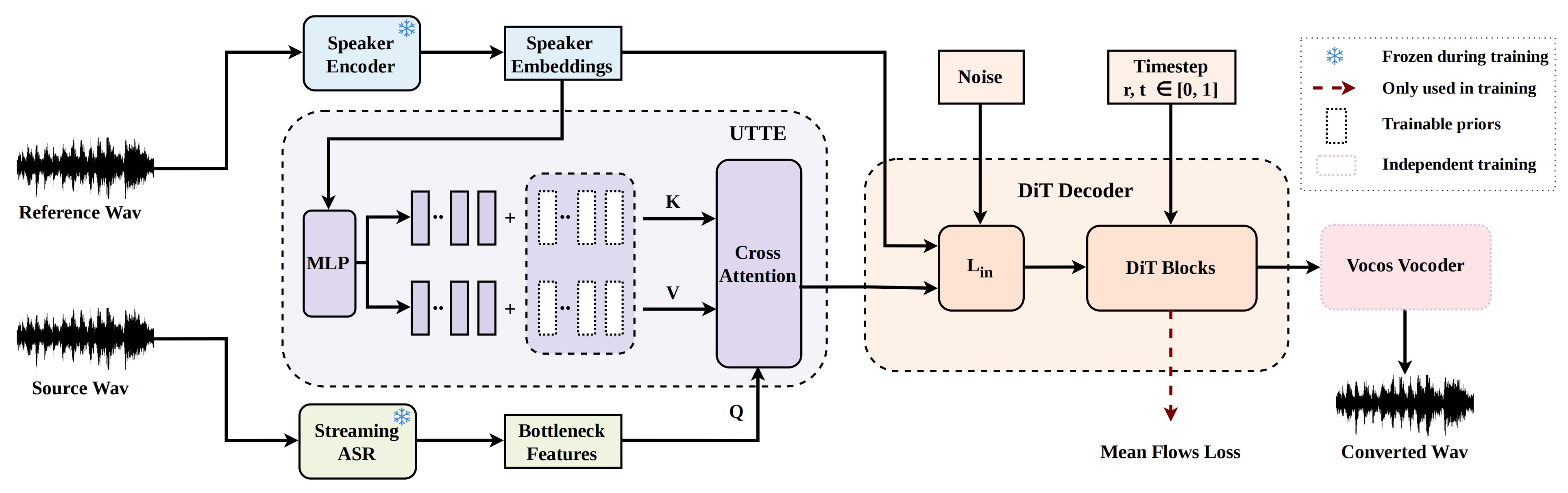
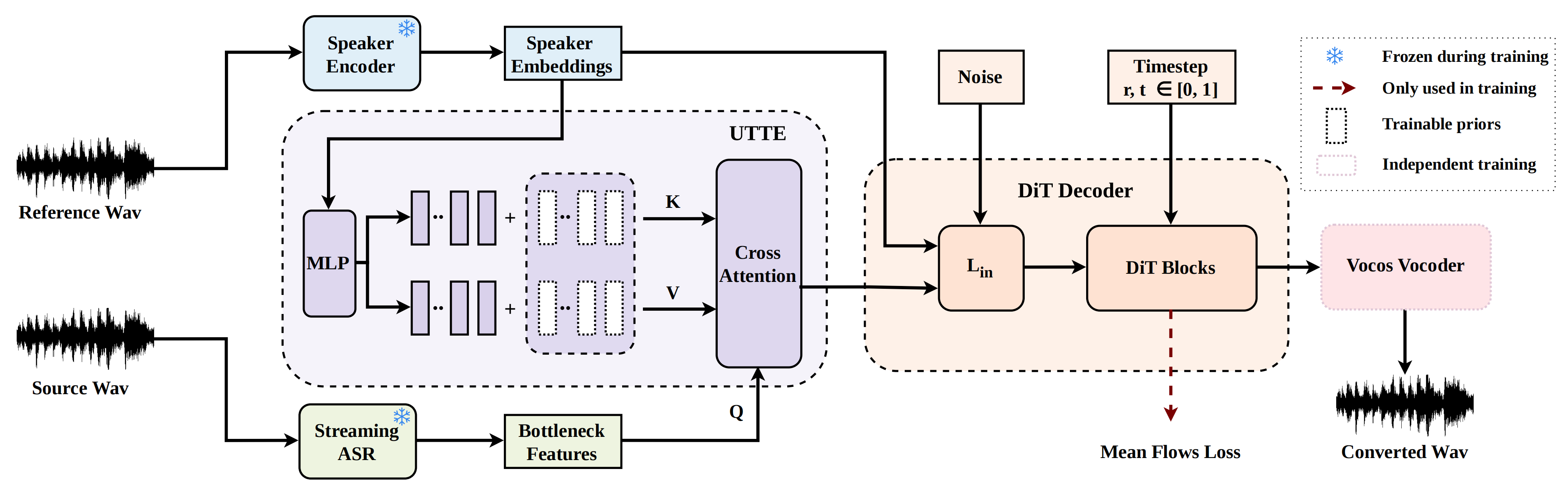
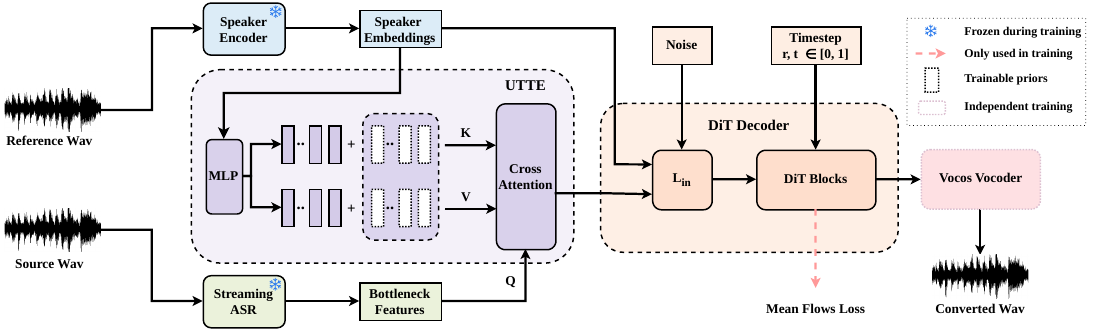
MeanVC 2 improves streaming zero-shot voice conversion by using future-receptive chunking for stable low-latency output and a universal timbre token encoder for robustness to low-quality references, enabling real-time speaker conversion with better naturalness and speaker similarity.
Demos
The demo showcases MeanVC 2's low-latency streaming zero-shot voice conversion with improved speaker similarity and robustness to low-quality references. It achieves stable conversion at 40 ms chunk size with high speech naturalness. The architecture figure illustrates key innovations like future-receptive chunking and a universal timbre token encoder that enhance performance and reduce latency.
Links
Paper & demos
Code & resources
Impact
Abstract
Streaming zero-shot voice conversion (VC) has become increasingly popular due to its potential for real-time applications. The recently proposed MeanVC achieves lightweight streaming zero-shot VC, but it has several limitations: its chunk-wise autoregressive denoising doubles the effective training sequence length, conversion quality degrades under small-chunk settings, and its timbre encoder directly relies on reference mel-spectrograms, making it sensitive to reference audio quality. To address these limitations we propose MeanVC 2. We introduce future-receptive chunking (FRC), which explicitly schedules past and future receptive fields across diffusion transformer decoder layers and removes clean-chunk teacher forcing. By incorporating bounded future context, FRC enables stable conversion with a 40 ms chunk size. We further introduce a universal timbre token encoder, which constructs a timbre representation from a global speaker embedding and retrieves fine-grained timbre cues via cross-attention, improving robustness to low-quality references and enhancing zero-shot speaker similarity. Experimental results show that MeanVC 2 significantly outperforms MeanVC, while reducing latency from 211 ms to 110 ms. Audio samples are publicly available. The source code will be publicly released.
Introduction
MeanVC 2 targets streaming zero-shot voice conversion (VC): converting a source utterance into the timbre of an unseen target speaker while preserving linguistic content, but doing so under real-time constraints. The paper positions this as a practical requirement for RTC-style settings such as live broadcasting, online meetings, and voice chat, where both latency and computational cost matter as much as quality and speaker similarity.
The paper’s starting point is the previous MeanVC system, which already combined chunk-wise autoregressive denoising with mean flows to achieve lightweight streaming VC. However, the authors identify three concrete weaknesses in that design: (1) chunk-wise autoregressive denoising doubles the effective training sequence length and is memory-hungry; (2) quality degrades when chunk sizes are small; and (3) the timbre encoder directly depends on reference mel-spectrograms, making the system sensitive to low-quality reference audio.
MeanVC 2 addresses these issues with two main ideas:
- Future-receptive chunking (FRC), a layer-wise receptive-field scheduling strategy for the diffusion transformer decoder that removes clean-chunk teacher forcing and introduces bounded future context.
- Universal timbre token encoder (UTTE), which reconstructs fine-grained timbre cues from a global speaker embedding through a key-value timbre token representation and cross-attention with bottleneck features.
The reported result is a streaming zero-shot VC system that is both more robust and lower latency than MeanVC, with end-to-end first-packet latency reduced from $211$ ms to $110$ ms while improving speaker similarity and speech quality metrics in the reported experiments.
Problem setting and motivation
The paper frames streaming zero-shot VC as a tradeoff among three competing goals: low latency, low computational cost, and high fidelity. Autoregressive methods tend to be faithful but incur sequential decoding latency; non-autoregressive methods reduce delay but can become fragile when the available streaming context is short. MeanVC attempted to strike a balance via chunk-wise autoregressive denoising and mean flows, but the authors argue that this still leaves practical inefficiencies and robustness gaps, especially for small chunks and poor reference recordings.
The motivation for MeanVC 2 is therefore twofold: improve the streaming decoder so that it remains stable at short chunk sizes, and replace the reference-sensitive timbre encoder with a speaker-conditioning mechanism that is more robust to degraded reference audio and less dependent on large-scale reference mel data.
Preliminaries: flow matching and mean flows
The paper briefly reviews conditional flow matching (CFM). Given a clean sample $x \sim p_{\text{data}}(x)$ and Gaussian noise $\epsilon \sim \mathcal{N}(0, I)$, an interpolation path is defined as
$$z_t = (1-t)x + t\epsilon,$$
with conditional velocity
$$v_t = \frac{d z_t}{d t} = \epsilon - x.$$
A neural network $f_{\theta}$ is trained by minimizing
$$\mathcal{L}_{\text{CFM}}(\theta) = \mathbb{E}_{t,x,\epsilon}\left[\lVert f_{\theta}(t, z_t) - v_t \rVert^2\right].$$
MeanVC 2 keeps the mean-flows formulation used in MeanVC to retain one-neural-function-evaluation sampling. The paper defines the average velocity over an interval $[r,t]$ as
$$u(z_t, r, t) = \frac{1}{t-r} \int_r^t v(z_{\tau}, \tau)\, d\tau,$$
and uses the mean-flows identity
$$u(z_t, r, t) = v(z_t, t) - (t-r)\frac{d}{d t}u(z_t, r, t).$$
Replacing the marginal velocity with the conditional velocity leads to the training target
$$u_{\text{tgt}} = v_t - (t-r)\left(v_t \partial_z u_{\theta} + \partial_t u_{\theta}\right),$$
and the learning objective becomes
$$\mathcal{L}_{\text{MF}}(\theta) = \mathbb{E}_{t,r,x,\epsilon}\left[\lVert f_{\theta}(z_t, r, t) - \operatorname{sg}(u_{\text{tgt}}) \rVert^2\right].$$
At $t=r$, this reduces to the standard CFM loss. For 1-NFE inference, the clean sample is recovered as $z_0 = z_1 - f_{\theta}(z_1, 0, 1)$ with $z_1 = \epsilon$.
Method overview
MeanVC 2 uses a recognition--synthesis architecture with five main parts: a streaming ASR module, a speaker encoder, UTTE, a DiT decoder, and a vocoder. The source waveform is converted into bottleneck features (BNFs) by a pretrained streaming ASR system, while the reference waveform is mapped into a global speaker embedding by a pretrained speaker encoder. UTTE then transforms that global embedding into a timbre-token memory and uses the BNFs as queries to retrieve fine-grained, content-aware timbre information. The result is a timbre-aware BNF representation that conditions the decoder.
The decoder is a diffusion-transformer (DiT) model trained with mean flows. It generates target mel-spectrograms in a streaming manner using FRC, and the vocoder then synthesizes the final waveform. The key design choice is that MeanVC 2 preserves the efficiency benefits of mean flows while reworking the temporal masking and speaker-conditioning pathways to be more streaming-friendly and more robust to poor references.
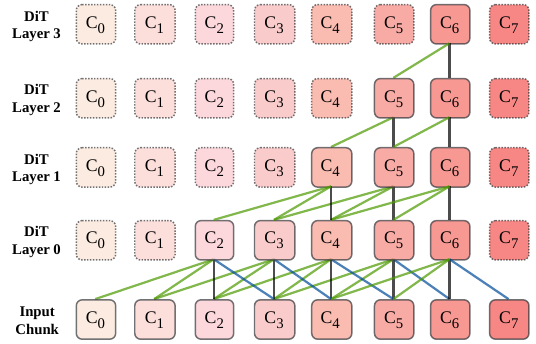
Future-receptive chunking
The paper’s first major contribution is future-receptive chunking (FRC). In MeanVC, chunk-wise autoregressive denoising uses clean mel chunks as prompts for noisy chunks. That preserves continuity but forces training to concatenate all clean chunks and noisy chunks into a $2N$-chunk sequence, which is expensive in memory and training time. The authors replace this with chunked training over the noisy sequence only, eliminating clean-chunk teacher forcing. Under the same training configuration, they report roughly a $60\%$ reduction in peak GPU memory footprint.
The downside of a purely short-history block mask is that temporal context becomes too fragmented for stable synthesis. FRC solves this by explicitly scheduling receptive fields across DiT layers. The temporal sequence is split into chunks $C_i$ of $B$ frames each. At each layer $\ell$, chunk $C_i$ can attend to at most $P_{\ell}$ previous chunks and $F_{\ell}$ future chunks, while always retaining full attention inside the chunk itself. In other words, attention from chunk $i$ to chunk $j$ is permitted only if
$$j \in [i-P_{\ell},\, i+F_{\ell}].$$
For the reported implementation with $L=4$ layers, the schedule is $P_{\ell} = \{2, 2, 1, 1\}$ and $F_{\ell} = \{1, 0, 0, 0\}$. This gives a total receptive field of $6$ past chunks, the current chunk, and $1$ future chunk, or $8$ chunks overall. The paper emphasizes that the bounded look-ahead is important: it supplies enough acoustic context to stabilize short-chunk conversion while keeping the system streaming and low-latency.
The most important conceptual distinction from the original MeanVC design is that FRC does not merely shrink the context window. It layer-wise expands the receptive field, allowing the model to aggregate context more progressively. That makes the temporal context less brittle than a fixed sliding-window mask and is the mechanism the paper credits for enabling stable $40$ ms chunking.
Universal timbre token encoder
The second major contribution is UTTE, introduced to make speaker conditioning less sensitive to low-quality reference audio. MeanVC relied on a multi-reference timbre encoder that extracted speaker characteristics directly from reference mel-spectrograms. The authors argue that this couples timbre extraction too tightly to reference audio quality and makes it harder to scale to large reference corpora with reliable labels.
UTTE starts from the global speaker embedding $s$ produced by the speaker encoder, then maps it to $K$ universal timbre token (UTT) key-value pairs $\{(k_i, v_i)\}_{i=1}^{K}$. The paper states that each pair is formed by adding a speaker-specific MLP output to a learnable prior term passed through $\tanh$:
$$k_i = \operatorname{MLP}_k(s)_i + \tanh(k_i^{\text{prior}}),$$
$$v_i = \operatorname{MLP}_v(s)_i + \tanh(v_i^{\text{prior}}).$$
The learnable priors are interpreted as universal timbre prototypes that can encode speaker-agnostic traits such as breathiness and nasality. The MLP outputs then adapt those prototypes to the target speaker. The paper explicitly notes that the $\tanh$ on the prior terms empirically improves token diversity.
Unlike methods that derive a separate time-varying timbre embedding, UTTE uses the BNFs themselves as queries in cross-attention over the UTT memory. This means the retrieved speaker cues are conditioned on the linguistic content of the current chunk, which the authors describe as pronunciation-aware timbre retrieval. The output is a timbre-aware BNF sequence passed downstream to the decoder.
In the authors’ framing, UTTE provides three benefits: better robustness to degraded references, better zero-shot speaker similarity, and improved data scalability because it reduces dependence on large-scale speaker-labeled reference mel-spectrograms.
Experimental setup
Training data. MeanVC 2 is trained on the open-source Emilia corpus. The authors filter out utterances shorter than $5$ s and randomly sample $10{,}000$ hours of Mandarin data. All audio is resampled to $16$ kHz for VC training.
Evaluation data. For zero-shot evaluation, the paper uses the Mandarin subset of the Seed-TTS test set, containing $2{,}018$ source-target test pairs. To assess robustness under low-quality references, the authors additionally select $30$ target speakers whose reference recordings have poor acoustic quality and sample $100$ utterances from the Seed-TTS test set as source recordings.
Streaming ASR and semantic features. Semantic features are extracted using Fast-U2++, a streaming ASR model implemented with WeNet and trained on WenetSpeech. The paper states that Fast-U2++ uses an $80$ ms chunk size during streaming inference and extracts semantic features from $16$ kHz waveforms with a $40$ ms frame length.
Model configuration. The full system contains $18$M parameters. The DiT decoder has $4$ blocks, hidden size $512$, and $2$ attention heads. UTTE contains two independent two-layer MLPs, $32$ UTT key-value pairs with hidden size $256$, and a cross-attention module with hidden size $256$ and $4$ heads. Speaker embeddings are extracted using ECAPA-TDNN, and Vocos is used as the vocoder.
Evaluation metrics. Subjective evaluation uses naturalness mean opinion score (NMOS) and speaker similarity mean opinion score (SMOS), both reported with $95\%$ confidence intervals. The listening tests sample $100$ test pairs and recruit $30$ listeners. Objective evaluation measures intelligibility via character error rate (CER), speaker similarity via SSIM from a WavLM-finetuned speaker verification model, and speech quality via DNSMOS. Streaming efficiency is reported using real-time factor (RTF) and end-to-end first-packet latency, measured on a single-core AMD EPYC 7542 CPU with single-threaded execution.
Baselines. The reported comparisons are against StreamVoice+, MeanVC with $80$ ms chunks, and MeanVC with $160$ ms chunks. MeanVC 2 uses $40$ ms chunks and a bounded future receptive field of one chunk, which the authors note corresponds to an effective first-packet buffering of $80$ ms at the BNF level.
Zero-shot VC results
Table 1 summarizes the main zero-shot VC results. The headline result is that MeanVC 2 achieves the best overall similarity and quality balance among the main systems, while also being the lowest-latency streaming model reported in the table. The paper emphasizes that MeanVC 2 is especially strong on DNSMOS, SMOS, and SSIM, and that its latency is comparable to the fastest MeanVC configuration while substantially outperforming it on similarity metrics.
| Method | NMOS $\uparrow$ | DNSMOS $\uparrow$ | CER (%) $\downarrow$ | SMOS $\uparrow$ | SSIM $\uparrow$ | Parameters (M) | RTF $\downarrow$ | Latency (ms) $\downarrow$ |
|---|---|---|---|---|---|---|---|---|
| GT | 4.07 ± 0.02 | 3.79 | 1.36 | - | - | - | - | - |
| StreamVoice+ | 3.70 ± 0.04 | 3.52 | 10.27 | 3.65 ± 0.02 | 0.552 | 153 | 14.732 | 1258.56 |
| MeanVC (80 ms) | 3.61 ± 0.02 | 3.37 | 11.66 | 3.61 ± 0.03 | 0.599 | 14 | 0.177 | 111.64 |
| MeanVC (160 ms) | 3.86 ± 0.04 | 3.81 | 5.11 | 3.87 ± 0.03 | 0.687 | 14 | 0.136 | 211.52 |
| MeanVC 2 | 3.81 ± 0.05 | 3.89 | 7.44 | 3.89 ± 0.04 | 0.710 | 18 | 0.371 | 109.88 |
| MeanVC 2 w/o forward mask | 3.54 ± 0.02 | 3.23 | 20.65 | 3.52 ± 0.02 | 0.573 | 18 | - | - |
| MeanVC 2 w/o UTTE | 3.77 ± 0.05 | 3.81 | 7.92 | 3.78 ± 0.02 | 0.682 | 13 | - | - |
| MeanVC 2 w/o tanh | 3.79 ± 0.03 | 3.83 | 7.79 | 3.82 ± 0.05 | 0.692 | 18 | - | - |
The paper draws several concrete conclusions from this table:
- Compared with MeanVC (80 ms), MeanVC 2 improves all five quality/similarity metrics: NMOS, DNSMOS, CER, SMOS, and SSIM.
- Compared with MeanVC (160 ms), MeanVC 2 is slightly weaker on NMOS and CER, which the authors attribute to the richer acoustic context available to the 160 ms setting, but MeanVC 2 is better on DNSMOS, SMOS, and SSIM while cutting latency roughly in half.
- Compared with StreamVoice+, MeanVC 2 is much smaller and dramatically faster, with $18$M parameters versus $153$M and latency of $109.88$ ms versus $1258.56$ ms.
The paper also notes a useful efficiency distinction: MeanVC 2 has VC-module RTF $0.371$, which is higher than the latency-matched MeanVC (80 ms) baseline at $0.177$, but the authors argue that this is not the fairest comparison because MeanVC (80 ms) is not matched on output granularity. Under the same $40$ ms output granularity, the paper reports MeanVC RTF as $0.316$ versus $0.371$ for MeanVC 2, implying only a moderate computational increase for the improved system. The full pipeline remains real-time, with the ASR encoder, VC module, and vocoder contributing $0.114 + 0.371 + 0.148 = 0.633 < 1.0$.
Another practical point emphasized by the authors is that all reported efficiency numbers are measured without additional engineering optimizations such as quantization or operator fusion. In other words, the paper presents these latency numbers as a baseline implementation result, not an aggressively optimized deployment figure.
Reference-robustness evaluation
To test speaker-conditioning robustness under degraded reference audio, the authors compare MeanVC 2 against the same system with UTTE replaced by MRTE. This experiment uses $30$ target speakers with poor-quality reference recordings and $100$ source utterances from Seed-TTS. The result is that replacing UTTE with MRTE consistently degrades performance on all reported metrics, supporting the claim that UTTE is more robust to low-quality references.
| Method | DNSMOS $\uparrow$ | CER (%) $\downarrow$ | SSIM $\uparrow$ |
|---|---|---|---|
| MeanVC 2 w/ MRTE | 1.39 | 7.64 | 0.621 |
| MeanVC 2 | 1.87 | 6.55 | 0.643 |
The authors interpret this as evidence that UTTE extracts more reliable speaker representations than MRTE when the reference audio is poor. The gain is visible in both quality and identity preservation, which is precisely the failure mode the method was designed to address.
Ablation study
The ablation study isolates the contributions of FRC, UTTE, and the $\tanh$ nonlinearity on the prior timbre tokens. The strongest single ablation is removing the forward mask from FRC, which produces the most severe degradation. This is the paper’s main evidence that limited look-ahead is not optional in the short-chunk regime; instead, bounded future context is essential for capturing enough acoustic context to prevent quality collapse.
Removing UTTE causes a noticeable drop in SSIM and also hurts quality, confirming that the encoder contributes timbre detail beyond what the global speaker embedding alone provides. Importantly, even this reduced $13$M-parameter variant still outperforms MeanVC (80 ms) across all metrics, which the authors use to argue that FRC is already a strong upgrade for short-chunk conversion. Removing the $\tanh$ activation leads to a smaller but consistent decline, suggesting that the activation regularizes the learned prior tokens and improves representation diversity.
A compact reading of the ablations is therefore:
- Forward mask removed: the most damaging ablation; bounded future context is crucial.
- UTTE removed: timbre similarity and reconstruction quality drop, showing that global speaker embedding alone is insufficient.
- $\tanh$ removed: moderate reduction, indicating that the prior-token shaping matters.
Discussion, stated tradeoffs, and limitations
The paper’s results support the claim that MeanVC 2 makes the streaming VC pipeline substantially more practical: it lowers latency, improves robustness to reference quality, and keeps the model small relative to larger streaming baselines. At the same time, the reported numbers also expose a few tradeoffs that function as the paper’s implicit limitations.
- MeanVC 2 is still slightly larger than the original MeanVC model, with $18$M parameters versus $14$M.
- Compared with the $160$ ms MeanVC setting, the new model sacrifices some NMOS and CER in exchange for much lower latency and stronger similarity metrics.
- The VC-module RTF is higher than the most latency-matched MeanVC baseline, so the gains are primarily architectural and robustness-oriented rather than a pure compute reduction inside the VC block itself.
- The paper explicitly notes that efficiency measurements are made without further deployment optimizations, so the reported latency is not necessarily the floor.
The paper does not present a broad failure analysis beyond the short-chunk and low-quality-reference scenarios, so the reported limitations are mainly the quality-latency-robustness tradeoffs visible in the tables rather than a separate qualitative error taxonomy.
Conclusion
MeanVC 2 is a streaming zero-shot VC system built to address the practical weaknesses of MeanVC. Its main technical contributions are FRC, which removes clean-chunk teacher forcing and introduces a layer-wise bounded future receptive field, and UTTE, which replaces direct reference-mel dependence with a timbre-token memory derived from a global speaker embedding. The result is a low-latency system that remains stable at $40$ ms chunks, is more robust to poor reference audio, and achieves stronger reported similarity and quality scores than prior streaming baselines while reducing end-to-end first-packet latency from $211$ ms to $110$ ms.