HoliDubber
HoliDubber: Holistic Video Dubbing for Complex Acoustic Scenes via Text-Guided Audio Synthesis
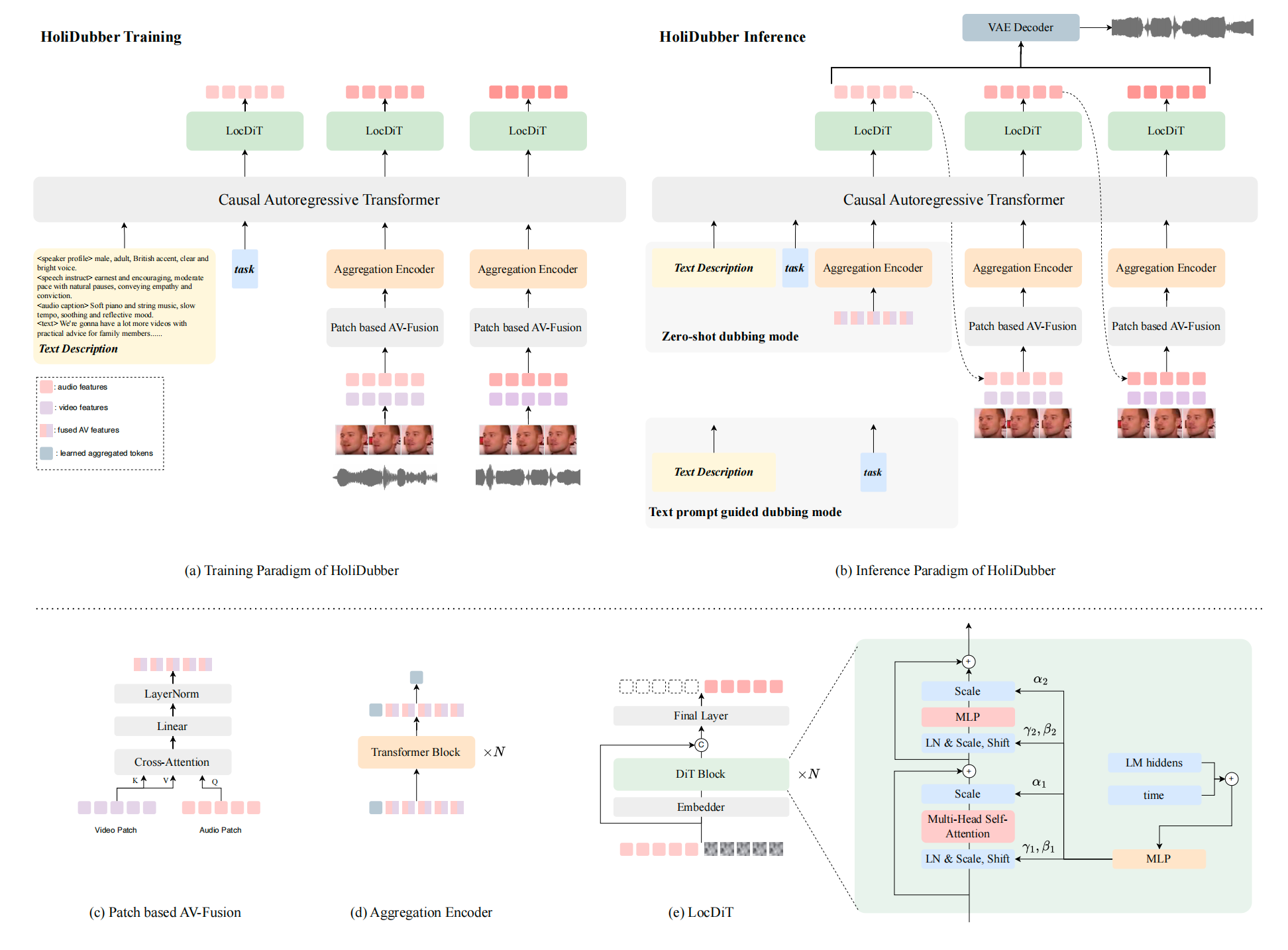
HoliDubber unifies speech and sound effect generation from text prompts for video dubbing, aligning audio with visual lip movements for natural, holistic acoustic scenes. It breaks from prior speech-only models by producing synchronized, multimodal audio outputs from a single unified model.
Demos
These demos showcase HoliDubber's holistic video dubbing capabilities, jointly generating speech and ambient sounds from text prompts or reference audio without fine-tuning. Evaluate lip-sync accuracy, vocal timbre preservation, and how well sound effects integrate in complex acoustic scenes. HoliDubber outperforms baselines in speech quality and synchronization.
Links
Paper & demos
Abstract
Video dubbing is a cornerstone of multimedia content creation, aiming to synthesize synchronized acoustic sequences for visual streams. While Text-to-Speech (TTS) and Text-to-Audio (TTA) generation have each achieved remarkable progress, existing dubbing systems remain confined to isolated speech synthesis without incorporating sound effects and ambient audio, forcing practitioners to rely on fragmented workflows and laborious manual post-mixing. To address this limitation, we present HoliDubber, a holistic video dubbing framework that moves beyond speech-only generation by enabling the joint synthesis of speech and sound effects from a single text prompt. Specifically, HoliDubber adopts a patch-based autoregressive diffusion transformer architecture, where a causal language model autoregressively models aggregated patch embeddings to capture global temporal structure, and a Diffusion Transformer decoder generates high-fidelity continuous tokens within each patch, following a divide-and-conquer strategy. To achieve cross-modal alignment, visual features are encoded into patch-level representations and fused with audio patches via cross-attention, enabling the model to ground speech generation in the speaker's visual articulation dynamics. In addition, we introduce HoliDub-Bench, a benchmark curated from established datasets with synchronized video-text-audio triplets designed for holistic dubbing evaluation. Extensive experiments demonstrate that HoliDubber significantly outperforms existing methods across multiple benchmarks in speech quality, synchronization, and speaker similarity. Furthermore, results on HoliDub-Bench validate the effectiveness of joint speech-and-sound generation, establishing a new paradigm for holistic video dubbing in complex acoustic scenes. \footnote{The demo page of the project is https://holidubber.github.io}
Introduction
HoliDubber addresses a gap in video dubbing systems: existing methods mostly synthesize speech only, whereas real multimedia scenes often require a coherent mixture of speech, background ambience, and sound effects. The paper argues that current dubbing workflows are fragmented because speech synthesis, sound-effect generation, and final mixing are handled by separate tools, which makes end-to-end control difficult and increases manual post-production effort. HoliDubber is proposed as a holistic video dubbing framework that generates both speech and non-speech audio from a single text prompt, while also conditioning on silent video and optionally on a reference speech clip.
The paper positions this work at the intersection of text-to-speech, text-to-audio, and automated video dubbing. Its core novelty is not simply better speech synthesis, but a unified acoustic scene generator that can produce speech and sound effects jointly and align them with visual articulation. The authors emphasize that this is especially relevant for complex acoustic scenes, where audio quality, lip synchronization, speaker identity, and background sound realism all matter simultaneously.
The overall task can be written as $Y = \text{HoliDubber}([R], T, V)$, where $V$ is silent video, $T$ is a text prompt, and $[R]$ denotes optional reference speech. The model supports two inference modes: zero-shot dubbing with a reference speaker and text-prompt-guided dubbing without a reference speaker. In both cases, the model aims to synthesize an acoustic sequence that is synchronized to the video and faithful to the textual content.
Method Overview
HoliDubber is built as a patch-based autoregressive diffusion system operating in a continuous audio latent space. The design follows a divide-and-conquer strategy: a causal autoregressive transformer models inter-patch structure and global temporal dependencies, while a local diffusion transformer generates the intra-patch continuous audio tokens with high fidelity. This lets the model use a coarse global planner followed by a fine local generator, instead of relying on a single monolithic decoder.
The end-to-end system has five main components: an Audio-VAE that encodes waveform audio into continuous latents, a patch-based audio-visual fusion module, an aggregation encoder, a causal autoregressive transformer, and a local diffusion transformer (LocDiT). Audio is reconstructed from the latent space using the VAE decoder.
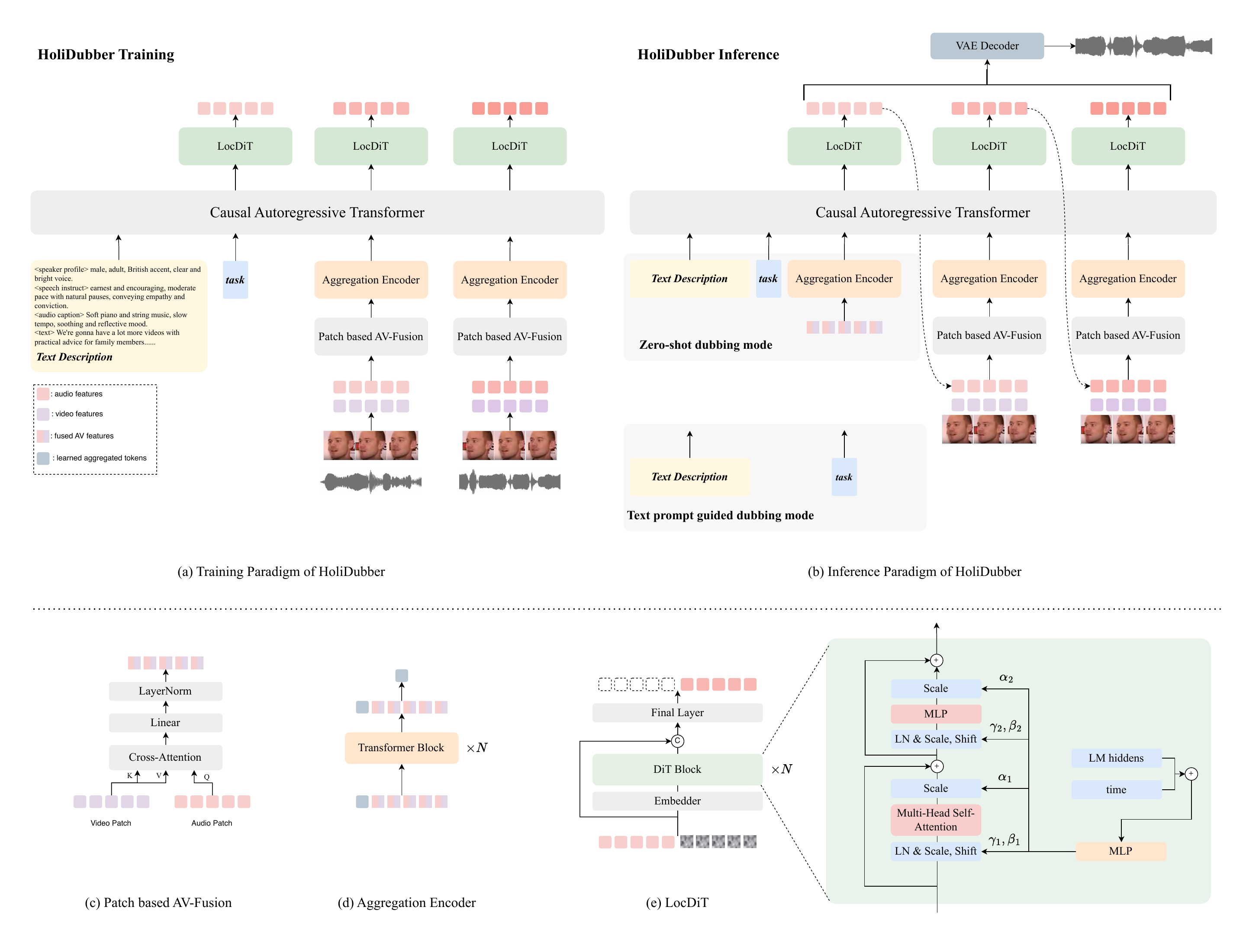
Patch-based audio-visual fusion
The key synchronization mechanism is patch-level fusion via cross-attention. Audio patch tokens are used as queries, and video patch features are used as keys and values. Crucially, each audio patch attends to the forthcoming visual segment rather than the current one, which allows the model to anticipate upcoming lip motion and better align generated speech with articulation in an autoregressive setting.
The authors argue that cross-attention is preferable to simple concatenation because it injects visual context as a side channel without perturbing the learned audio feature distribution of the pretrained text-to-audio backbone. It also permits selective focus on the most informative visual cues, which matters because lip motion is temporally sparse and only a subset of frames carry strong articulatory evidence.
Aggregation encoder
After patch fusion, each patch contains multiple fused audio-visual tokens. The aggregation encoder prepends a learnable token and applies a bidirectional Transformer encoder. The output at the special token position becomes a compact embedding summarizing the local audio-visual context for that patch. This is the bridge between fine-grained local fusion and the global autoregressive model.
Local diffusion transformer
The causal autoregressive model only predicts a coarse patch-level embedding, so HoliDubber uses LocDiT to reconstruct the full continuous latent patch. LocDiT is a bidirectional Transformer trained with a flow-matching objective. It conditions on the autoregressive output $h_i$ and the previously generated patch $x_{i-1}$, enabling local continuity at patch boundaries and reducing the accumulation of errors that often appears in explicit coarse-to-fine cascades.
In the paper’s notation, noise $epsilon$ is sampled from a standard normal distribution and linearly interpolated with the ground-truth target patch $x_0$:
$$x_t = (1-t)\epsilon + t x_0, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I}), \quad t \sim \mathcal{U}(0,1).$$
The velocity predictor $v_\theta(x_t, t, c)$ is trained with the conditional flow-matching loss
$$\mathcal{L} = \mathbb{E}_{t,\epsilon,x_0}\left[\|v_\theta(x_t, t, c) - (x_0 - \epsilon)\|^2\right],$$
where $c = (h_i, x_{i-1})$ is the joint condition. At inference time, each patch is generated autoregressively, and LocDiT solves the learned ODE with a numerical solver to transform sampled noise into the target continuous latent patch.
Training Strategy and Input Representations
HoliDubber is trained in a multi-stage fashion. First, an Audio-VAE is trained on heterogeneous audio to establish a continuous latent space covering speech, environmental sounds, music, and mixtures. Then a text-guided audio generation backbone is pretrained without video. Finally, the video-conditioned dubbing model is trained on top of that backbone, with random prompt-field dropout so the same model can operate both as a zero-shot dubber and as a text-prompt-guided generator.
Audio-VAE
The Audio-VAE replaces the discrete residual-vector-quantization bottleneck used by DAC-style codecs with a continuous VAE bottleneck parameterized by mean and log-variance. The backbone largely follows DAC, including ResidualUnits, Snake activations, weight-normalized convolutions, and multi-scale dilations. The motivation is to remove quantization artifacts and obtain a latent space better suited to continuous generative modeling with flow matching.
Audio is resampled to 32 kHz and encoded at 25 Hz. The Audio-VAE is trained on roughly 30,000 hours of audio, evenly split in a 1:1:1 ratio across speech, general audio, and naturally mixed speech-plus-background recordings. The paper reports a latent dimension of 64, a 0.1 weight on the KL term, and an adversarial multi-scale discriminator loss.
Text-guided audio backbone
The causal autoregressive transformer is initialized from Qwen2.5-1.5B. This backbone is pretrained on about 130,000 hours of audio-text data: 80,000 hours of Emilia speech with plain transcripts, 20,000 hours of mixed speech-audio, 20,000 hours of speech annotated with structured fields, and 10,000 hours of non-speech audio and music. This pretraining gives the model a broad generative prior before any video conditioning is introduced.
Video conditioning and prompt dropout
For video conditioning, the authors use AV-HuBERT as the video encoder and align the visual feature rate to the 25 Hz audio-latent frame rate. The patch size is 5. The aggregation encoder uses 4 Transformer blocks with 8 attention heads, and LocDiT uses 12 Transformer blocks with 16 attention heads. During HoliDubber training, auxiliary textual fields are randomly dropped with probability 0.5, leaving only the transcription field. This is what allows one unified model to support both zero-shot dubbing and prompt-guided holistic generation at inference time.
Structured audio caption pipeline
A major part of the paper is the construction of structured prompts for audio data. The captioning pipeline uses Qwen3-Omni-30B-A3B-Instruct as the caption generator and Whisper-large-v3 as the ASR model. Each clip is annotated with three fields: <speaker profile>, <speech instruct>, and <audio caption>, plus a <text> transcript derived by source separation followed by ASR. The <speaker profile> field covers gender, age range, accent, and timbre; <speech instruct> captures speaking rate, emotion, and vocal quality; and <audio caption> describes background music, ambient sounds, and spatial or dynamic relations.
The prompt is explicitly designed around a grounded-only principle: describe only what is actually heard and avoid hallucinated sound events. The authors also report a human verification step in which sampled captions are checked for hallucinations, speaker misidentification, and mismatch with the audio.

Datasets and Benchmark Construction
HoliDubber is trained on VoxCeleb2 and CelebV-Dub. VoxCeleb2 contributes more than 1 million utterances from 6,112 speakers and approximately 2,442 hours of speech. The authors emphasize that VoxCeleb2 is useful because it contains challenging in-the-wild conditions: interviews, outdoor scenes, studios, public speeches, and handheld recordings with wide variation in lighting, pose, motion blur, and background acoustics. For evaluation, 991 VoxCeleb2 clips are held out in total: 641 for HoliDub-Bench and 350 for a standard test set.
CelebV-Dub is a curated real-world dubbing dataset with about 86 hours of expressive speech. It includes emotionally varied, unconstrained videos and is used to evaluate expressiveness and style handling. The paper holds out 477 clips in total: 359 for HoliDub-Bench and 118 for the standard test set.
HoliDub-Bench is the paper’s custom benchmark for holistic dubbing evaluation. It contains 1,000 clips, about 2.4 hours of data, sampled from VoxCeleb2 and CelebV-Dub. The selection deliberately emphasizes complex acoustic scenes: rich background sounds from VoxCeleb2 and pronounced emotional variation from CelebV-Dub. Because HoliDub-Bench includes structured audio captions, evaluation is performed only in the text-prompt-guided mode.
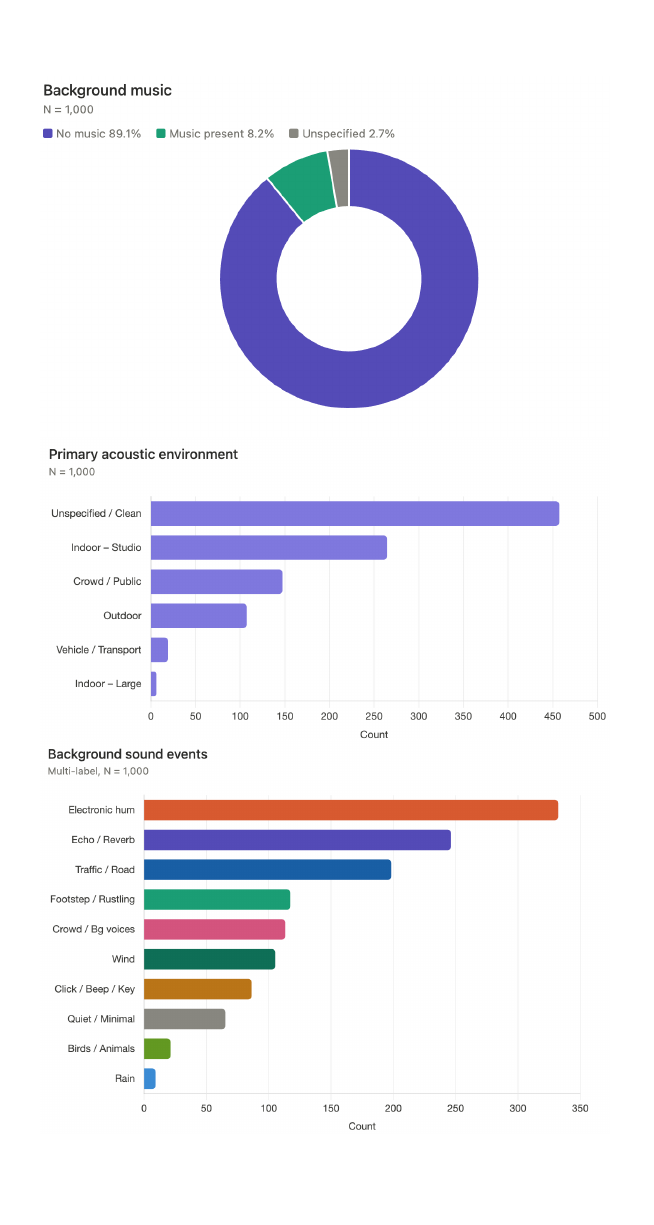
The benchmark statistics show that 89.1% of clips contain no background music, 8.2% contain music, and 2.7% are unspecified. For acoustic environments, 45.7% are unspecified/clean, 26.4% are indoor studio or room, 14.7% are crowd/public space, 10.7% are outdoor, 1.9% are vehicle/transport, and 0.6% are indoor large or reverberant spaces. Common background event labels include electronic hum/equipment, echo/reverberation, traffic/road noise, footstep/rustling, crowd/background voices, and wind, with long-tail categories such as birds/animal sounds and rain.
Evaluation Protocol and Baselines
The paper evaluates two inference modes. In zero-shot dubbing mode, the main question is how well the model preserves the reference speaker’s identity while achieving synchronization and naturalness. Metrics include LSE-C, LSE-D, SPK-SIM, EMO-SIM, WER, UTMOS, and MOS. In text-prompt-guided mode, there is no reference speech, so SPK-SIM is omitted and non-speech audio quality is additionally measured with FD, FAD, KLD, and IS.
The main baselines are AlignDiT, VoiceCraft-Dub, and FunCineForge. AlignDiT is a DiT-based dubbing approach trained on LRS3. VoiceCraft-Dub is an NCLM-based video dubbing model trained on LRS3 and CelebV-Dub. FunCineForge is an MLLM-based dubbing system trained primarily on CineDub-CN and CineDub-EN, and it is the only baseline here that supports a prompt-guided mode, although it still requires reference speech as an input.
Quantitative Results
Zero-shot dubbing on VoxCeleb2 and CelebV-Dub
In zero-shot mode, HoliDubber is competitive across all metrics and tends to provide the most balanced overall behavior. The paper highlights that it achieves the strongest speaker similarity among the compared methods on both test sets, near-top lip synchronization, strong emotion similarity, and a better realism-synchronization trade-off than methods that over-optimize for studio-clean speech.
| Model | VoxCeleb2 test set | CelebV-Dub test set | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LSE-C | LSE-D | SPK-SIM | EMO-SIM | WER | UTMOS | MOS | LSE-C | LSE-D | SPK-SIM | EMO-SIM | WER | UTMOS | MOS | |
| GT | - | - | 0.71 | 0.980 | 19.91 | 2.51 | 3.82 | - | - | 0.55 | 0.950 | 9.19 | 2.87 | 3.92 |
| AlignDiT | 6.92 | 7.90 | 0.55 | 0.980 | 20.92 | 2.77 | 3.72 | 6.63 | 7.66 | 0.41 | 0.951 | 12.31 | 3.16 | 3.79 |
| VoiceCraft-Dub | 4.50 | 9.95 | 0.31 | 0.973 | 49.12 | 2.64 | 3.62 | 6.31 | 8.33 | 0.27 | 0.955 | 29.03 | 3.27 | 3.71 |
| FunCineForge | 1.56 | 13.29 | 0.46 | 0.978 | 21.22 | 3.70 | 3.91 | 2.63 | 11.89 | 0.34 | 0.954 | 21.47 | 3.65 | 4.06 |
| HoliDubber | 6.83 | 7.87 | 0.68 | 0.981 | 24.12 | 2.79 | 3.83 | 6.65 | 7.92 | 0.46 | 0.951 | 17.95 | 3.24 | 3.96 |
The authors’ interpretation is that HoliDubber achieves the best balance between lip sync, speaker identity, and perceptual realism. AlignDiT slightly leads on content accuracy in the VoxCeleb2 setting, but HoliDubber is better on speaker similarity and close to the top on synchronization. In the paper’s discussion, higher UTMOS is not automatically better than the ground truth, because real in-the-wild recordings are not as clean as studio speech. HoliDubber is presented as closer to the acoustic realism of the source videos while still remaining intelligible and well synchronized.
Text-prompt-guided dubbing on VoxCeleb2 and CelebV-Dub
In prompt-guided mode, only FunCineForge is compared directly because the other baselines do not support this operating mode. HoliDubber achieves much better lip synchronization and much better non-speech audio fidelity, while FunCineForge still tends to produce smoother speech according to UTMOS. The paper reports that HoliDubber is preferred by human listeners on MOS and better matches the target acoustic scenes.
| Dataset | Model | LSE-C | LSE-D | EMO-SIM | WER | UTMOS | MOS | FD | FAD | KLD | IS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| VoxCeleb2 | GT | - | - | - | 19.91 | 2.51 | 3.82 | - | - | - | - |
| FunCineForge | 1.54 | 13.17 | 0.990 | 21.10 | 3.55 | 3.86 | 16.34 | 5.18 | 1.60 | 1.16 | |
| HoliDubber | 6.52 | 8.18 | 0.994 | 20.03 | 3.04 | 3.92 | 10.21 | 3.82 | 1.43 | 1.26 | |
| CelebV-Dub | GT | - | - | - | 9.19 | 2.87 | 3.92 | - | - | - | - |
| FunCineForge | 2.69 | 11.84 | 0.977 | 22.17 | 3.65 | 3.96 | 15.24 | 4.11 | 0.79 | 1.15 | |
| HoliDubber | 6.55 | 8.06 | 0.978 | 19.42 | 3.12 | 3.99 | 6.85 | 3.16 | 0.69 | 1.32 |
The strongest gains in prompt-guided mode are on audio-generation metrics. On both datasets, HoliDubber substantially lowers FD, FAD, and KLD relative to FunCineForge and improves IS modestly or competitively, showing that the model can synthesize non-speech audio that better matches the target distribution. The paper interprets this as evidence that the unified text-guided generator preserves coherence between speech and background acoustics.
HoliDub-Bench results
HoliDub-Bench is where the paper most directly tests the holistic generation claim. HoliDubber is compared against its own text-guided audio backbone without video conditioning, denoted TTA. HoliDubber improves lip synchronization dramatically, lowers WER, increases UTMOS and MOS, and substantially improves FAD, showing that adding visual conditioning helps both speech alignment and the realism of the generated soundscape.
| Model | LSE-C | LSE-D | EMO-SIM | WER | UTMOS | MOS | FD | FAD | KLD | IS |
|---|---|---|---|---|---|---|---|---|---|---|
| GT | - | - | - | 14.51 | 2.80 | 3.89 | - | - | - | - |
| TTA | 1.21 | 15.26 | 0.993 | 15.28 | 2.97 | 3.81 | 9.52 | 10.51 | 1.89 | 1.54 |
| HoliDubber | 6.44 | 8.08 | 0.992 | 12.81 | 3.02 | 3.96 | 10.95 | 3.08 | 1.86 | 1.51 |
Interestingly, TTA slightly outperforms HoliDubber on FD and IS, but HoliDubber decisively wins on FAD, lip sync, WER, and perceptual quality. The paper treats this as evidence that simply generating diverse audio is not enough: the audio must also remain synchronized and coherent with the visual scene. HoliDubber therefore trades a bit of isolated audio diversity for stronger multimodal consistency.
Ablations and Additional Analysis
The ablation study is run on the VoxCeleb2 test set in zero-shot mode. It focuses on three design choices: reference video conditioning, patch-based AV fusion, and random prompt-field dropout during training.
| # | Method | LSE-C | LSE-D | SPK-SIM | EMO-SIM | WER | UTMOS |
|---|---|---|---|---|---|---|---|
| 1 | HoliDubber | 6.83 | 7.87 | 0.68 | 0.981 | 24.12 | 2.79 |
| 2 | w/o ref-video | 4.29 | 10.21 | 0.65 | 0.980 | 21.43 | 2.91 |
| 3 | w/o patch-av-fusion | 4.15 | 10.15 | 0.15 | 0.972 | 62.19 | 1.76 |
| 4 | w/o prompt random drop | 4.61 | 9.96 | 0.56 | 0.980 | 25.62 | 2.86 |
The main takeaways are clear. Removing the reference video degrades synchronization, confirming that visual grounding matters. Replacing cross-attention fusion with simple concatenation causes catastrophic collapse in speaker similarity and WER, which the paper interprets as evidence that preserving the pretrained audio feature distribution is critical. Finally, removing random field dropout creates a train-test mismatch because the model never sees partial prompts during training, which reduces zero-shot robustness.
The paper also includes an appendix comparison of a decoupled pipeline, where speech is generated first and background audio is generated separately by AudioLDM before the two tracks are mixed. HoliDubber outperforms this pipeline on almost every metric, especially UTMOS, FAD, and WER. The only metric where the decoupled pipeline does slightly better is IS, which the authors attribute to greater diversity in isolated background audio generation, albeit at the expense of coherence and mixing quality.
| Model | LSE-C | LSE-D | EMO-SIM | WER | UTMOS | MOS | FD | FAD | KLD | IS |
|---|---|---|---|---|---|---|---|---|---|---|
| GT | - | - | - | 14.51 | 2.80 | 3.89 | - | - | - | - |
| HoliDubber (prompt) + AudioLDM | 5.21 | 8.82 | 0.980 | 16.67 | 2.03 | 3.81 | 17.65 | 5.53 | 2.01 | 1.65 |
| HoliDubber | 6.44 | 8.08 | 0.992 | 12.81 | 3.02 | 3.96 | 10.95 | 3.08 | 1.86 | 1.51 |
The appendix also breaks down HoliDub-Bench’s acoustic diversity. Background music is rare but present, the environment distribution spans clean, indoor, crowd, outdoor, vehicle, and reverberant settings, and background sound-event labels show a long-tailed but realistic mixture of electronic hum, reverberation, traffic, footsteps, crowd voices, wind, birds, and rain. This is used to justify HoliDub-Bench as a stress test for realistic dubbing conditions rather than a clean benchmark.
Implementation Details
The paper gives fairly concrete training settings. The Audio-VAE is trained for 1,120,000 steps with batch size 128 on 8 NVIDIA H20 GPUs, using AdamW with an initial learning rate of $10^{-4}$ and an exponential decay schedule. Training uses 32 kHz audio, 0.4 second crops, latent dimension 64, reconstruction loss, KL divergence with weight $\beta = 0.1$, and a multi-scale discriminator loss. The authors report about 1,200 GPU hours for this stage.
The text-guided audio pretraining stage runs for 10 epochs with a batch size of 8,000 VAE latent frames on 32 NVIDIA H20 GPUs. It uses AdamW, a peak learning rate of $10^{-4}$, a 20,000-step linear warmup, and a constant schedule. The HoliDubber stage itself is trained for 50 epochs with batch size 8,000 VAE latent frames on 8 NVIDIA H20 GPUs, using a constant learning rate of $8 \times 10^{-5}$ and a prompt dropout probability of 0.5.
Inference uses a LocDiT step count of 10. All video is processed at 25 FPS, and the audio latents are aligned to the same 25 Hz temporal resolution. The patch size is 5, which means the model performs both local and global reasoning over compact temporal chunks rather than over the entire sequence uniformly.
Interpretation, Contributions, and Limitations
The paper’s main contribution is conceptual as much as it is architectural: it reframes dubbing from speech-only generation to holistic acoustic scene generation. It also contributes a reusable structured-caption pipeline for audio supervision, a benchmark tailored to complex acoustic scenes, and a patch-based audio-visual fusion strategy that preserves a pretrained text-to-audio backbone while adding video grounding.
The experimental narrative is consistent throughout the paper. HoliDubber is strongest when all of its design choices are present: cross-attention fusion, visual conditioning, prompt dropout, and the pretrained continuous audio backbone. The ablations show that each piece matters, especially patch-based fusion. The paper also makes a strong case that end-to-end holistic generation is preferable to a decoupled speech-plus-background mixing pipeline because it avoids the artifacts of post-mixing and better coordinates speech with ambient sound.
The paper does not provide a dedicated limitations section, but it does state future work directions. The authors plan to extend HoliDubber to multilingual dubbing, multi-speaker dialogue scenes, and more diverse acoustic scenarios. Based on the reported experiments, the current system is still centered on single-speaker dubbing-style inputs and on the two datasets used for training and evaluation.