FlashTTS
FlashTTS: Fast Streaming TTS with MTP Acceleration and X-pred Mean Flow Distillation
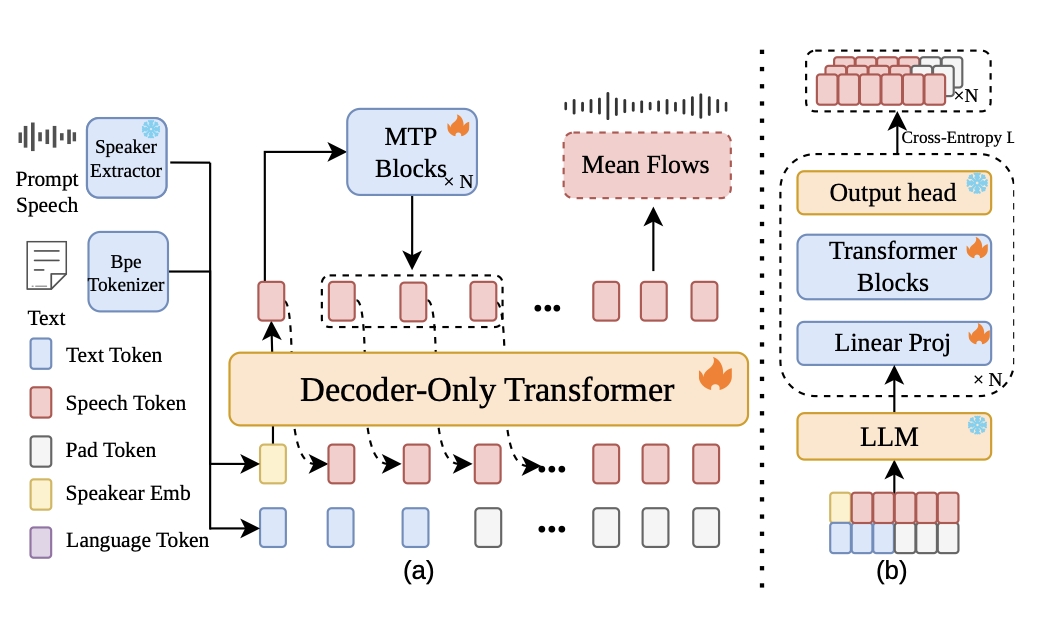
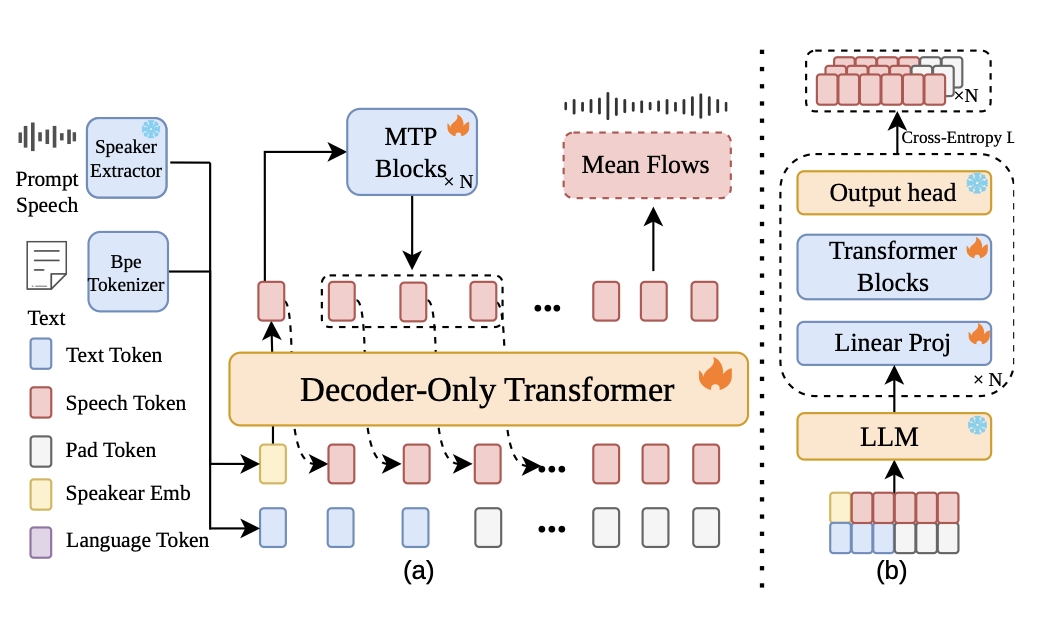
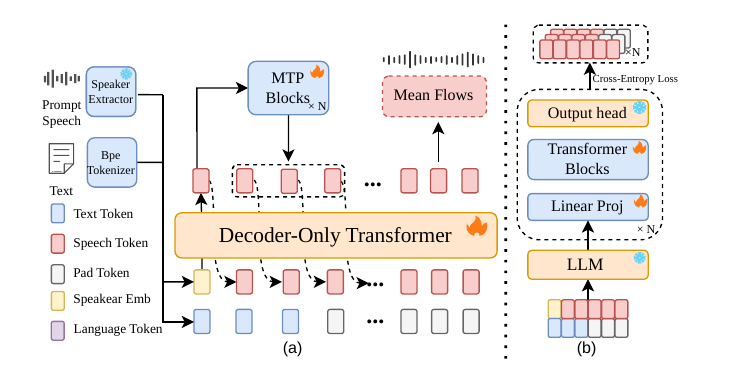
FlashTTS introduces a streaming TTS framework that processes text and speech incrementally, using parallel multi-token prediction and a fast mean flow decoder to enable low-latency real-time speech synthesis. It uniquely optimizes both input streaming and decoding speed for conversational applications.
Demos
These demos highlight FlashTTS's fast, low-latency streaming TTS across multiple languages and zero-shot voice cloning. When evaluating, note its responsiveness, naturalness, and ability to handle streaming input with minimal delay. The architecture image clarifies the efficient two-stage training process enabling these features.
Links
Paper & demos
Code & resources
Impact
Abstract
Recent progress in speech dialogue systems requires Text-to-Speech (TTS) models to be faster and more responsive. Modern speech dialogue systems impose two primary requirements on TTS models: low latency and support for streaming inputs and outputs. However, most existing single-codebook LLM-based TTS methods rely on multi-stage pipelines that lack native streaming capabilities. These systems typically suffer from high end-to-end latency due to slow autoregressive prediction and multi-step flow matching. To address these limitations, we propose FlashTTS, an open-source and low-latency streaming TTS framework. FlashTTS introduces a lagged multi-track architecture that natively processes streaming text and speech inputs, thereby eliminating the need for sentence-level buffering. To accelerate acoustic generation, we integrate parallel Multi-Token Prediction (MTP) with an X-pred mean flow matching decoder. This configuration achieves high-fidelity token-to-mel generation in exactly two function evaluations (2-NFE). By jointly optimizing input processing and decoding efficiency, FlashTTS offers a practical foundation for real-time speech dialogue systems. Experiments show that FlashTTS substantially reduces First-Packet Latency to 325ms compared to robust streaming baselines, all while preserving strong zero-shot voice cloning and cross-lingual intelligibility. Speech samples are available. The model code and checkpoints will be released as open source.
Introduction
FlashTTS addresses a specific bottleneck in modern speech-dialogue systems: text-to-speech must be both low latency and natively streaming on input and output. The paper argues that many strong LLM-based TTS systems still rely on cascaded or multi-stage pipelines that are not designed for incremental text ingestion and that pay a large end-to-end latency cost because of slow autoregressive token generation and multi-step flow matching. In the authors' framing, this makes them a poor fit for real-time conversational systems, where the TTS component should begin speaking quickly after the first text tokens arrive and continue synthesizing smoothly as more input streams in.
The paper's core claim is that FlashTTS attacks both sources of delay simultaneously. First, it introduces a lagged multi-track streaming input scheme so the model can consume text and speech context incrementally rather than buffering a full sentence. Second, it accelerates decoding with a combination of parallel Multi-Token Prediction (MTP) and an X-pred mean flow matching decoder, producing token-to-mel generation in exactly $2$ neural function evaluations in the reported operating point. The result is a streaming TTS system that the authors position as a practical foundation for real-time speech dialogue pipelines.
The implementation is built on a Qwen2.5-0.5B backbone and is evaluated on multilingual zero-shot voice cloning and streaming latency benchmarks. The reported headline result is a first-packet latency of $325$ ms on the Minimax subset, substantially below the robust streaming baseline used in the paper, while preserving competitive speech quality and cross-lingual intelligibility.
Problem Setting and Main Contributions
The paper is motivated by a specific deployment regime: conversational systems where the upstream text stream may itself be generated incrementally by another model, and the downstream TTS must therefore start speaking before the full utterance is finalized. In this setting, conventional sentence-level buffering is costly, and even if output is chunked, token prediction can remain the dominant latency source.
The paper's contributions can be summarized as follows:
- Native streaming input: a lagged multi-track representation that models speech, text, and language as parallel streams, avoiding the need to wait for a complete sentence before synthesis begins.
- Faster token prediction: parallel MTP modules that predict multiple future tokens from the frozen backbone hidden states, with a verification step based on the backbone's more stable distributions.
- Fast acoustic decoding: an X-pred mean flow decoder that predicts clean mel-spectrograms directly and is distilled to operate in a minimal number of function evaluations, with block-level chunked attention to support streaming output.
- End-to-end latency reduction: a system-level design that jointly reduces first-token latency, tokenizer decode latency, and first-packet latency in a real conversational pipeline.
The paper also emphasizes that single-stream token modeling can better align semantic and acoustic representations for zero-shot TTS than some more complex alternatives, but that the main target here is not raw offline quality. Rather, FlashTTS is tuned for the latency-quality trade-off required by interactive applications.
Method: FlashTTS Architecture
1. Lagged Multi-Track Streaming Input
FlashTTS replaces the conventional interleaved or concatenated text-speech serialization used in many TTS systems with a stacked track structure. The paper describes three parallel streams:
- Speech track: initialized with a speaker embedding and then extended with generated speech tokens.
- Text track: receives input text tokens and uses padding once the text ends, so the tensor shape remains aligned as generation continues.
- Language track: provides continuous language conditioning throughout the generation process.
The practical benefit of this design is that the model can process text incrementally instead of requiring full-sentence buffering. In the paper's argument, this is a structural requirement for real-time conversational systems rather than a minor implementation convenience.
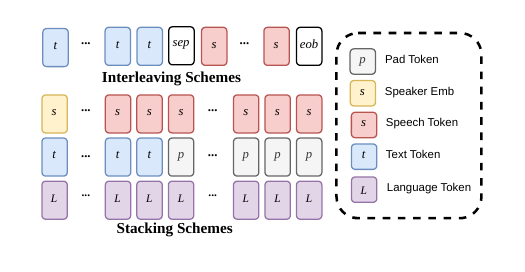
The comparison figure contrasts this stacked design with more conventional input organizations. The key point is that the lagged multi-track formulation is intended to align the model's representation with streaming operation, where text may arrive token-by-token and speech output should begin before the entire prompt is complete.
2. Parallel Multi-Token Prediction
To speed up autoregressive speech token generation, the paper adopts Multi-Token Prediction in a parallel form inspired by DeepSeek-V3. Let $\mathbf{h}^{0}_{0:t}$ denote the final hidden states from the backbone language model over the current time span. Each parallel MTP module consumes the same backbone state and produces a future-token representation:
$$\mathbf{h}^{k}_{0:t} = \operatorname{MTP}_{k}(\mathbf{h}^{0}_{0:t}), \quad k \in \{1,2,\dots,N-1\}.$$
These outputs are passed through a shared language-model head to form distributions over future speech tokens. The training objective is a cross-entropy loss over shifted targets:
$$\mathcal{L}_{\mathrm{MTP}} = \sum_{k=1}^{N-1} \mathcal{L}_{\mathrm{CE}}\big(\mathbf{S}^{k}_{0:T-k-1},\mathbf{G}_{k+1:T}\big),$$
where $T$ is the sequence length, $\mathbf{G}$ is the ground-truth token sequence, and each branch learns to predict one step further into the future. The paper freezes the backbone parameters during this stage, training only the extra MTP layers. Because the MTP branches are lightweight, their speculative predictions can be unstable; the authors therefore add a verification mechanism that uses the frozen backbone's more robust distribution to validate the speculative tokens.
The paper notes that the empirical text-token frame rate is typically only $3$ to $5$ Hz, which is one reason a parallel future-token predictor can be effective without breaking the time structure of speech generation.
3. X-pred Mean Flow Distillation
The acoustic decoder is based on mean flow matching, combined with an explicit data-prediction parameterization inspired by recent mean-flow and JIT-style work. The key design choice is to predict the clean mel-spectrogram $\hat{x}_{\theta}$ directly, rather than having the network optimize velocity fields in a high-dimensional space. The paper argues that direct velocity prediction is harder to optimize, while explicit data prediction is more stable for distillation.
The mean velocity over an ordinary differential equation interval $[r,t]$ is written as:
$$u(z_t,r,t) = \frac{1}{t-r} \int_{r}^{t} v(z_{\tau},\tau)\,d\tau.$$
The model predicts clean data $\hat{x}_{\theta}(z_t,r,t)$, and the corresponding estimated mean velocity is derived analytically as:
$$\hat{u}_{\theta}(z_t,r,t) = \frac{1}{t}\big(z_t - \hat{x}_{\theta}(z_t,r,t)\big).$$
The training objective minimizes the squared distance between this estimated mean velocity and a stop-gradient target $u_{\mathrm{tgt}}$:
$$\mathcal{L}_{\mathrm{MF}}(\theta) = \mathbb{E}\Big[\lVert \hat{u}_{\theta}(z_t,r,t) - \operatorname{sg}(u_{\mathrm{tgt}}) \rVert^2\Big].$$
The authors explicitly state that when $t=r$, the objective reduces to standard conditional flow matching. At inference time, the decoder recovers the clean sample from an initial latent sample using one-step mean-flow sampling; the full FlashTTS system combines this with MTP so that token prediction and acoustic decoding together reach the reported $2$-NFE configuration.
To make the decoder compatible with streaming output, the paper adds block-level chunked attention, which allows the acoustic model to operate on chunks rather than requiring the entire utterance at once. This is important because the system is designed for interactive speech generation rather than offline synthesis.
Training Procedure and Model Configuration
Two-Stage Training
FlashTTS is trained in two stages. Stage 1 learns the main generation pathway with streaming input tracks, while Stage 2 adds the MTP modules. The mean-flow decoder is distilled separately from a pretrained conditional flow-matching teacher.
- Stage 1: the full backbone is optimized with dynamic frame-based batching of $40{,}000$ on $8$ A100 GPUs using AdamW, a peak learning rate of $1\times 10^{-4}$, $20$k warmup steps, and cosine decay over $1$M steps.
- Stage 2: the backbone is frozen and only the MTP modules are trained on $4$ A100 GPUs with a peak learning rate of $5\times 10^{-5}$.
- X-pred MeanFlow distillation: the decoder is distilled on $8$ RTX 4090 GPUs with batch size $2{,}000$, gradient accumulation $2$, and a peak learning rate of $7\times 10^{-5}$.
The model is built on the Qwen2.5-0.5B backbone with hidden size $896$, $24$ layers, $14$ attention heads, and a feed-forward dimension of $4864$. Each MTP module adds a Qwen2.5-style decoder layer with the same architecture. The X-pred MeanFlow decoder uses a $16$-layer diffusion transformer with hidden size $768$, approximately $159.25$M parameters, followed by a $50$M-parameter HiFi-GAN $24$ kHz vocoder.
Training Data and Evaluation Data
The training set comprises approximately $300{,}000$ hours of open-source speech data drawn from Emilia, Emilia-Yodas, LibriHeavy, and WenetSpeech4TTS. For zero-shot evaluation, the paper uses the Seed-TTS test sets and the MiniMax multilingual test set.
For tokenization, the paper uses S3Tokenizer v2. The baseline emphasized for token-level comparison is CosyVoice2, because it is close in parameter scale and also uses an ASR-token-centric design. The paper additionally compares against other mainstream TTS systems and two commercial systems in the multilingual table.
Evaluation Protocol
The paper reports both objective and subjective measures. Quality and intelligibility are measured using WER, CER, SIM, and CMOS, while efficiency is measured using speed-up ratio, Real-Time Factor $\mathrm{RTF}$, Tokens Per Second $\mathrm{TPS}$, and First-Packet Latency $\mathrm{FPL}$. The authors also report First-Token Latency and tokenizer First-Packet Decode Latency in the detailed latency study.
Subjective CMOS tests use $100$ randomly sampled test pairs and $30$ listeners, with results reported at $95\%$ confidence intervals in the paper. WER/CER are computed with Paraformer-zh for Chinese and Whisper-large-v3 for the other languages. Speaker similarity is measured as cosine similarity between generated and reference embeddings extracted from a fine-tuned WavLM-large model.
Experimental Results
Latency and Streaming Quality on the Minimax Subset
The paper's most relevant real-time result is the latency/quality table on the Minimax subset, evaluated on a single NVIDIA RTX 4090 while the upstream text stream is generated by a Qwen2-7B model to simulate a realistic conversational pipeline. The authors explicitly state that these efficiency numbers are measured without engineering optimizations, so they reflect the raw architectural speed rather than an aggressively tuned deployment system.
A central comparison is between CosyVoice2 and several FlashTTS operating points. CosyVoice2 requires buffering $5$ text tokens before synthesis, while FlashTTS begins generation with a single token, which is one reason its first-token latency is much lower.
| Model configuration | TPS | FTL (ms) | LLM Lat. (ms) | TPP (ms) | FPL (ms) | RTF | WER | SIM | CMOS |
|---|---|---|---|---|---|---|---|---|---|
| CosyVoice2 (10-NFE) | 51 | 257 | 425 | 339 | 843 | 0.913 | 26.2 | 0.721 | 0.00 |
| FlashTTS Stage 1 (2-NFE) | 50 | 60 | 246 | 123 | 377 | 0.793 | 18.0 | 0.702 | 0.08 |
| FlashTTS Stage 1 (3-NFE) | 50 | 60 | 246 | 198 | 413 | 0.824 | 17.2 | 0.711 | 0.15 |
| FlashTTS MTP-3 (2-NFE) | 73 | 62 | 195 | 123 | 325 | 0.632 | 18.8 | 0.695 | 0.05 |
| FlashTTS MTP-3 (3-NFE) | 72 | 62 | 215 | 165 | 366 | 0.702 | 17.5 | 0.714 | 0.12 |
| FlashTTS MTP-5 (2-NFE) | 75 | 62 | 206 | 123 | 328 | 0.621 | 20.8 | 0.668 | -0.08 |
The best latency operating point reported by the paper is MTP-3 (2-NFE), which achieves $73$ TPS, $62$ ms first-token latency, $123$ ms tokenizer first-packet decode latency, and $325$ ms first-packet latency. This is the main number behind the paper's claim of a substantially lower-latency streaming TTS system. Relative to CosyVoice2, the same setting improves WER from $26.2$ to $18.8$ and improves RTF from $0.913$ to $0.632$, while keeping CMOS slightly positive.
The table also reveals an important trade-off. Increasing the number of MTP branches from $3$ to $5$ raises TPS slightly, but acoustic fidelity deteriorates, as reflected by the negative CMOS for MTP-5 (2-NFE). Similarly, moving from $2$-NFE to $3$-NFE generally improves quality metrics such as WER and CMOS, but increases TPP, FPL, and RTF. The authors therefore identify MTP-3 (2-NFE) as the most balanced configuration for real-time dialogue.
Zero-Shot Multilingual Speech Synthesis
The paper evaluates zero-shot cloning and multilingual generalization on the MiniMax multilingual set, covering Chinese, English, Japanese, Korean, French, and German. FlashTTS is compared against two commercial systems and CosyVoice2. The table shows that FlashTTS expands language coverage beyond the baseline, including French and German, which are not supported by CosyVoice2 in the reported table.
| Model | Chinese WER | Chinese SIM | English WER | English SIM | Japanese WER | Japanese SIM | Korean WER | Korean SIM | French WER | French SIM | German WER | German SIM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MiniMax* | 2.25 | 0.780 | 2.16 | 0.756 | 3.52 | 0.776 | 1.75 | 0.776 | 4.10 | 0.628 | 1.91 | 0.733 |
| ElevenLabs* | 16.03 | 0.677 | 2.34 | 0.613 | 10.65 | 0.738 | 1.87 | 0.700 | 5.22 | 0.535 | 0.57 | 0.614 |
| CosyVoice2 | 1.22 | 0.773 | 3.44 | 0.765 | 7.94 | 0.803 | 16.68 | 0.778 | -- | -- | -- | -- |
| FlashTTS | 1.08 | 0.743 | 3.02 | 0.662 | 10.59 | 0.751 | 3.49 | 0.734 | 8.62 | 0.564 | 9.96 | 0.672 |
The multilingual results show a mixed but informative picture. FlashTTS achieves the best Chinese WER among the open-source systems in the table and performs better than CosyVoice2 in English WER and Korean WER. It also uniquely supports French and German among the open-source systems shown. However, its SIM values are not uniformly best: CosyVoice2 remains stronger on SIM for Chinese, English, Japanese, and Korean, which indicates that FlashTTS trades some similarity fidelity for broader streaming capability and lower latency.
Seed-TTS Test Sets
The Seed-TTS evaluation further clarifies the quality trade-off. The paper reports both a Stage 1 and Stage 2 FlashTTS setting, and in this benchmark Stage 1 is slightly better than Stage 2 on both languages. The broader message is that the stage optimized for MTP acceleration is not necessarily the best one for raw synthesis quality.
| Model | test-zh CER | test-zh SIM | test-en WER | test-en SIM |
|---|---|---|---|---|
| Seed-TTS | 1.12 | 0.796 | 2.25 | 0.762 |
| MaskGCT | 2.27 | 0.774 | 2.62 | 0.714 |
| F5-TTS | 1.56 | 0.741 | 1.83 | 0.647 |
| Llasa-8B-250k | 1.59 | 0.684 | 2.97 | 0.574 |
| Spark-TTS | 1.20 | 0.672 | 1.98 | 0.584 |
| CosyVoice2 | 1.45 | 0.748 | 2.57 | 0.652 |
| FlashTTS Stage 1 | 1.38 | 0.718 | 2.21 | 0.572 |
| FlashTTS Stage 2 | 1.51 | 0.699 | 2.55 | 0.523 |
On Seed-zh, FlashTTS Stage 1 reaches CER $1.38$ and SIM $0.718$, while Stage 2 reaches CER $1.51$ and SIM $0.699$. On Seed-en, Stage 1 gives WER $2.21$ and SIM $0.572$, while Stage 2 gives WER $2.55$ and SIM $0.523$. Compared with the best specialized systems in the table, FlashTTS is not the strongest on absolute quality, but the authors present it as a latency-first streaming model rather than an offline quality-only model.
Ablation Study
The ablation table isolates the contribution of each main architectural element. The reported speed-up ratio is the strongest indicator of how much each component contributes to real-time use.
| Model | WER (%) | SIM | Speed-up ratio (%) |
|---|---|---|---|
| CosyVoice2 | 2.21 | 0.743 | 0 |
| FlashTTS | 2.17 | 0.713 | 49.23 |
| w/o X-pred | 2.28 | 0.691 | 12.53 |
| w/o MTP | 1.91 | 0.719 | 12.52 |
| w/o Language ID | 3.42 | 0.702 | 49.28 |
The ablation results show that both MTP and X-pred are essential for the reported acceleration. Removing either one collapses the speed-up ratio from roughly $49\%$ to about $12.5\%$. The language ID signal is also important: without it, WER rises sharply to $3.42\%$ even though the speed-up ratio remains high. This supports the paper's interpretation that the system needs explicit semantic/language conditioning to keep speculative decoding stable during aggressive parallel generation.
Interestingly, removing MTP yields a lower WER ($1.91\%$) than the full model on the ablation subset, but at a major cost to throughput. The paper's broader conclusion is that the complete architecture intentionally prioritizes the latency-quality balance needed for streaming speech dialogue rather than maximizing offline-quality metrics alone.
What the Results Say About the Design
Across the tables, the paper's main message is consistent: FlashTTS is not simply a faster decoder; it is an end-to-end streaming system in which input handling, token prediction, and acoustic decoding are all shaped around real-time constraints. The lagged multi-track input scheme addresses waiting time before synthesis can start, MTP reduces the cost of producing future speech tokens, and X-pred mean flow keeps the mel decoder to a minimal number of function evaluations. The latency table makes clear that the most useful configuration is not the one with the most MTP branches, nor the one with the highest NFE, but the one that best balances speculative throughput and reconstruction stability.
The multilingual results also suggest a design trade-off common to streaming systems: FlashTTS broadens language coverage and reduces latency, but it does not always match the best SIM values of slower or more offline-oriented baselines. This is especially visible in English, Japanese, and Korean SIM on the MiniMax table, where CosyVoice2 is often stronger on similarity. The authors explicitly frame this as an acceptable trade-off for real-time deployment.
Limitations and Trade-offs Reported in the Paper
The paper does not include a separate standalone limitations section, but several limitations and trade-offs are directly visible in the reported experiments:
- Quality-speed tension in MTP depth: moving from $3$ to $5$ MTP branches slightly increases TPS but degrades CMOS and worsens WER in the latency table.
- NFE trade-off: $3$-NFE generally improves quality over $2$-NFE, but at the cost of higher TPP, FPL, and RTF.
- Similarity gap on some languages: FlashTTS often trails CosyVoice2 on SIM in the multilingual table, even when WER is better or comparable.
- Stage 2 is not a quality upgrade benchmark: on Seed-TTS, the MTP-trained Stage 2 configuration is slightly worse than Stage 1 on both Chinese and English metrics.
- Language conditioning matters: removing language ID hurts cross-lingual robustness substantially, indicating that the fast speculative setup is sensitive to explicit language control.
Taken together, these findings suggest that FlashTTS is best understood as a carefully optimized real-time system rather than a universally superior TTS model on every quality metric.
Conclusion
FlashTTS proposes a coherent architecture for low-latency streaming TTS in conversational systems. Its main technical idea is to treat streaming as a first-class constraint at both the input and output sides: the lagged multi-track representation removes sentence-level buffering, parallel MTP reduces token-generation delay, and X-pred mean flow reduces acoustic decoding to a small number of function evaluations. On the reported benchmarks, the system reaches $325$ ms first-packet latency in its best streaming setting and substantially lowers first-token latency relative to the CosyVoice2 baseline, while preserving usable zero-shot cloning and multilingual intelligibility.
For a talking-head or conversational-AI stack, the practical implication is that FlashTTS is designed to sit in the latency-critical path of a dialogue pipeline, where the main objective is not only natural speech but also responsiveness under incremental input. The paper's results support the claim that this can be done with a single-codebook, LLM-based TTS stack when streaming input organization and speculative decoding are jointly optimized.
Code & Implementation
The FlashTTS repository provides an open-source implementation closely following the paper's proposed fast streaming TTS architecture. The repo is organized into several main components:
cosyvoice/: Contains the core FlashTTS implementation, including the LLM decoder, text tokenizer, speaker embedding extraction (via CAMPPlus), and frontend audio/text processing. It also includes the streaming input stacking architecture and multi-token prediction model components.jit_meanflow_xpred/: Implements the efficient acoustic generation using the X-pred mean flow matching method. This module achieves the fast 2-NFE mel-spectrogram generation described in the paper and integrates with a HiFi-GAN vocoder for waveform synthesis.examples/inference.py: Demonstrates how to perform inference with FlashTTS, supporting text-to-speech with zero-shot voice cloning, and an alternative MeanFlow-only mode for acoustic generation from tokens. Streaming inference modes and batch processing are supported here as well.
The repository leverages a YAML-based configuration system for model and inference setup and supports GPU acceleration with torch.cuda. The modular design cleanly separates the acoustic model (MeanFlow X-pred) from the LLM decoder and frontend processing, reflecting the staged architecture in the paper.
The README and example scripts provide clear usage instructions for running FlashTTS with streaming input/output, zero-shot speaker adaptation, and batch inference, enabling researchers and developers to reproduce the paper's reported low-latency and high-fidelity TTS performance.