E2E Discrete Token LLM TTS
End-to-End Training for Discrete Token LLM based TTS System
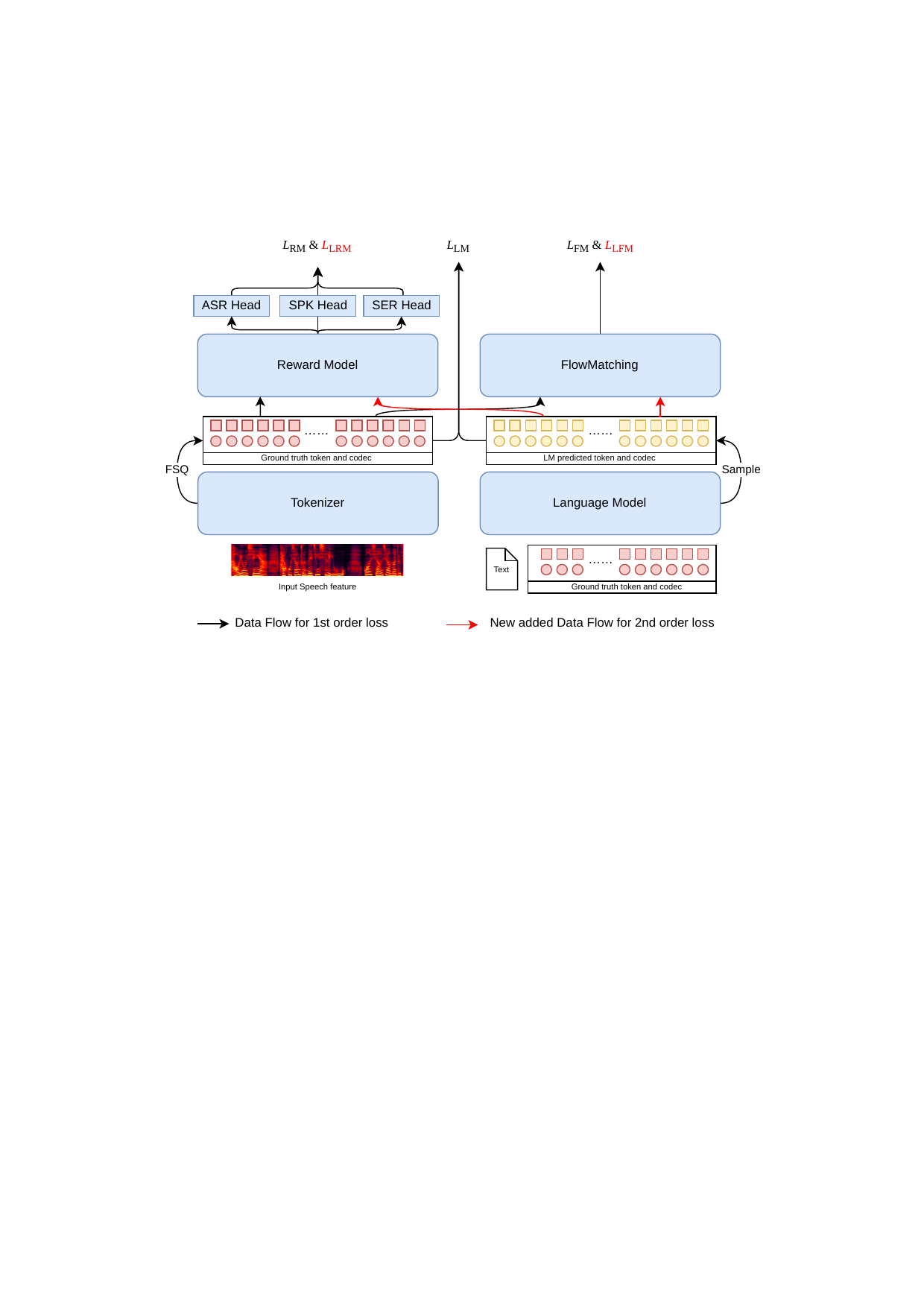
This paper introduces a unified end-to-end training for discrete token-based TTS, jointly optimizing the tokenizer, LLM, flow-matching decoder, and reward model. This approach improves token quality and synthesis by reducing mismatch and tailoring tokens specifically for speech generation.
Links
Paper & demos
Code & resources
Abstract
Recent state-of-the-art (SOTA) text-to-speech (TTS) systems typically adopt a cascaded pipeline consisting of a speech tokenizer, an autoregressive large language model (LLM), and a diffusion based flow-matching (FM) model, with these components trained independently. In this paper, we propose a fully end-to-end (E2E) optimization framework that unifies the training of the speech tokenizer, LLM, FM model, and an additional reward model (RM). Specifically, we first jointly optimize the tokenizer using multi-task objectives derived from reconstruction for FM, next-token prediction for LLM, and multi recognition task for RM. This joint training encourages the discrete speech token space to capture acoustically and semantically salient information that is better tailored to TTS. We then further optimize the LLM using downstream reconstruction and recognition by FM and RM, which reduces inference-time mismatch and steers the LLM toward more preferred generations. Experimental results show that our E2E framework consistently outperforms cascaded baselines. On the Seed-TTS-Eval benchmark, our system achieves a word error rate (WER) of 0.78% and 1.56%, a new SOTA result with a 0.6B-parameter LLM and 0.5B-parameter FM model. These results validate that holistic E2E optimization is critical for improving discrete-token-based TTS systems with a much simpler training pipeline.
1. Problem Setting and Core Idea
The paper targets a common design pattern in recent large-scale text-to-speech (TTS) systems: a cascaded pipeline with (i) a speech tokenizer that maps audio to discrete tokens, (ii) an autoregressive large language model (LLM) that predicts tokens from text, and (iii) a flow-matching (FM) decoder that reconstructs speech from the tokens. The authors argue that most systems train these modules independently, which creates three related problems: the tokenizer is optimized by proxy objectives that may not align with TTS, the LLM is trained only to predict tokens rather than to produce tokens that are easy to reconstruct and recognize, and the FM decoder is trained on ground-truth tokens rather than the LLM’s predicted tokens, creating train-test mismatch.
Their proposal is a fully end-to-end (E2E) optimization framework that jointly trains the tokenizer, LLM, FM model, and an auxiliary reward model (RM). The key claim is that a speech token space becomes more useful for TTS when it is directly shaped by downstream synthesis and recognition requirements, rather than by unrelated pretraining proxies such as ASR-only or SSL-only objectives. The method is designed to improve both token quality and system-level generation quality while keeping the overall pipeline simpler than a collection of separately trained modules.
2. Architecture Overview
The system consists of four trainable components:
- Speech tokenizer: converts an utterance $x_{1:T}$ into discrete token indices $c_{1:T}$ and quantized vectors $q_{1:T}$.
- Reward model (RM): a multi-task recognition model that operates on the quantized representation and performs ASR, speaker emotion recognition (SER), and speaker identification (SPK).
- LLM: autoregressively predicts the token sequence conditioned on text and token history.
- FM decoder: reconstructs speech from the token representation using a flow-matching objective.
The tokenizer uses Finite Scalar Quantization (FSQ) with a single codebook. The paper states that the low-rank dimensionality is 8 and each dimension has 3 codes, giving a total codebook size of $6561$. The quantized vector is retrieved by a codebook lookup:
$$q_i = \operatorname{CodeBook}(c_i), \qquad c_{1:T}, q_{1:T} = \operatorname{Tokenizer}(x_{1:T}).$$
The authors note that the LM, FM, and RM can consume either token embeddings or acoustic-token-derived inputs, and that the FSQ codebook is shared across modules so gradients can flow through the shared discrete representation in a straight-through style.
The LM is built from Qwen3-0.6B and its vocabulary is extended with the $6561$ speech tokens plus $4$ special control tokens. The speech token embeddings are tied to the FSQ codebook through a lightweight linear adaptation layer. The FM uses a Diffusion Transformer (DiT) backbone and is reported as a $0.5$B-parameter model. The RM is built from a CTC-based ASR system with a Conformer encoder and additional attention pooling heads for SER and SPK; the tokenizer and RM are reported as $0.6$B and $0.7$B parameters, respectively.
3. Losses and End-to-End Objectives
3.1 First-order loss: joint supervision of the tokenizer
The first training objective, called the first-order loss $L_1$, directly backpropagates from all downstream modules into the tokenizer. The RM contributes three recognition losses: ASR, SER, and SPK. Specifically, the paper defines
$$L_{\text{RM}} = L_{\text{ASR}} + L_{\text{SER}} + L_{\text{SPK}},$$
where $L_{\text{ASR}}$ is CTC loss, $L_{\text{SER}}$ is cross-entropy over emotion labels, and $L_{\text{SPK}}$ is a cosine-similarity loss between the RM output and a pretrained x-vector speaker embedding. The FM is trained to predict a velocity field for reconstruction; the paper writes the noisy mixture as
$$\mathbf{x} = \mu \mathbf{x} + (1-\mu)\mathbf{n}, \qquad \mathbf{n} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}), \; \mu \sim U(0,1),$$
and uses a reconstruction objective of the form
$$L_{\text{FM}} = \lVert \operatorname{FM}(q_{1:T}, \mu) - (\mathbf{x} - \mathbf{n}) \rVert.$$
The LM is trained with next-token prediction, but once the tokenizer is trainable the logits are computed through similarity to codebook entries rather than a fixed classifier head. The paper emphasizes that this stabilizes training when token labels change during joint optimization. The LM loss is the usual cross-entropy over the token sequence,
$$L_{\text{LM}} = \sum_{t=1}^{T} \operatorname{CrossEntropy}\bigl(c_t, p(c_t \mid c_{1:t-1})\bigr).$$
The complete first-order objective is
$$L_1 = \alpha L_{\text{LM}} + \beta L_{\text{RM}} + \gamma L_{\text{FM}}.$$
This stage is the paper’s main mechanism for teaching the tokenizer to encode only the information that is actually useful for downstream TTS: semantic structure for the LLM, acoustic detail for the FM, and recognition-relevant information for the RM.
3.2 Second-order loss: optimization under predicted tokens
The second objective, called the second-order loss $L_2$, feeds LLM-predicted tokens into the FM and RM instead of ground-truth tokens. This reduces the mismatch between training and inference, because the FM learns to handle the LLM’s actual output distribution. The authors also allow gradients to flow through the discrete sampling step by using Gumbel-Softmax or by directly using hidden states.
$$q'_t = \operatorname{CodeBook}\bigl(\operatorname{GumbelSoftmax}(p(c_t \mid c_{1:t-1}))\bigr) \quad \text{or} \quad h^{\text{LM}}_t.$$
The corresponding losses are denoted $L_{\text{LRM}}$ and $L_{\text{LFM}}$, and their sum defines the second-order loss:
$$L_2 = L_{\text{LRM}} + L_{\text{LFM}}.$$
The paper’s interpretation is that $L_2$ acts like a reinforcement-style alignment signal: the LM is pushed toward token sequences that are easier to reconstruct, better recognized, and more robust under the downstream FM.
4. Three-stage Training Pipeline
The authors split training into three stages to keep optimization stable.
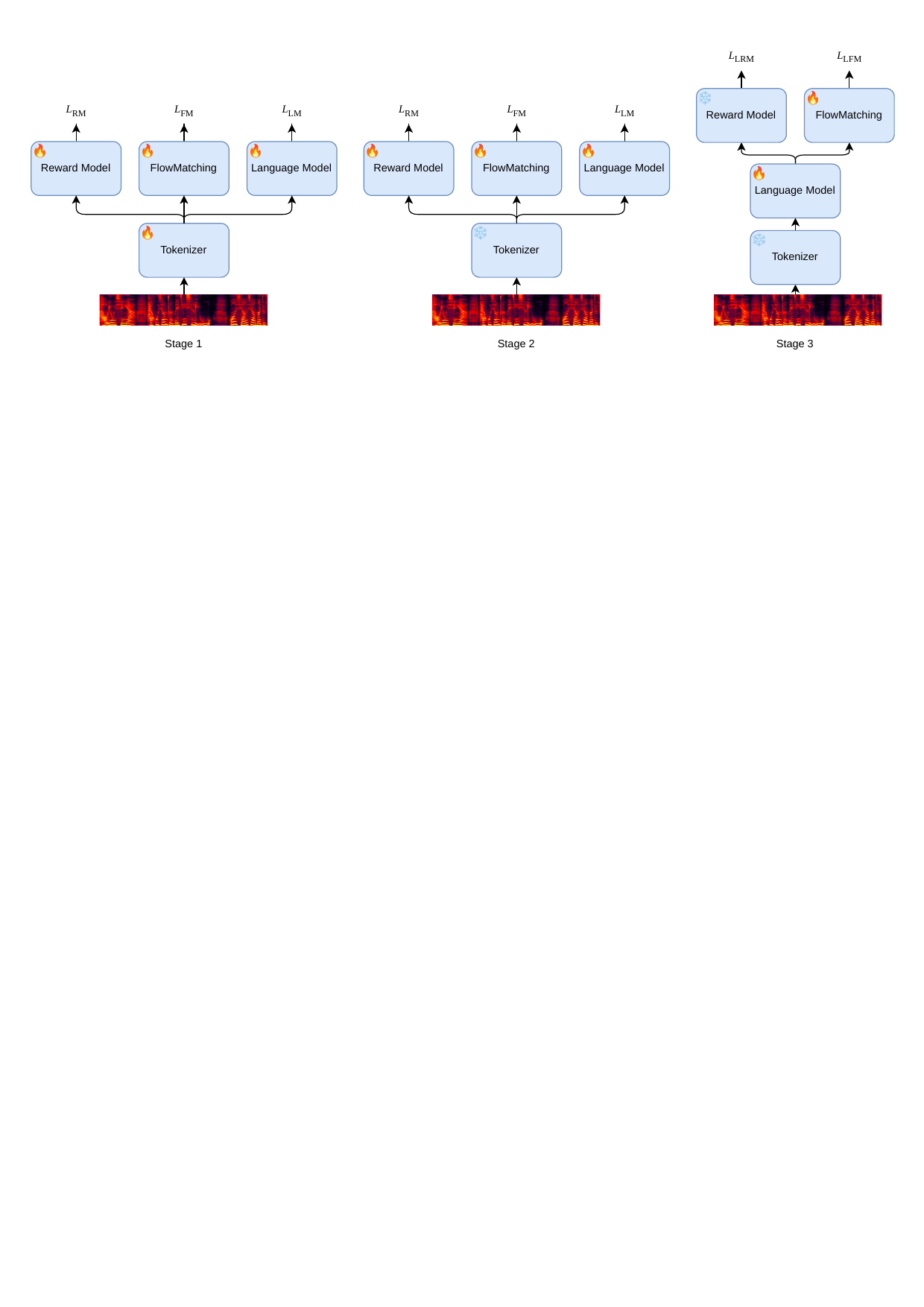
- Stage 1: all parameters are trainable and only $L_1$ is used. This stage jointly shapes the tokenizer using the downstream objectives from the LM, FM, and RM.
- Stage 2: the tokenizer is frozen and the RM, FM, and LM are trained independently. The paper notes that different datasets can be used for different modules at this stage; for example, noisier or lower-quality data can be added for RM training while cleaner speech is used for FM.
- Stage 3: the RM is frozen and the LM and FM are optimized using $L_2$, which trains them on predicted-token inputs and further reduces inference-time mismatch.
The reported optimization setup uses AdamW, linear warmup, and cosine annealing. Stage 1 uses a $25$k-step warmup and a peak learning rate of $10^{-4}$ with weights $0.1$ for $L_{\text{LM}}$ and $1.0$ for both $L_{\text{FM}}$ and $L_{\text{RM}}$. Stage 2 lowers the learning rate to $10^{-5}$ while keeping a $25$k-step warmup. Stage 3 uses $L_2$; within $L_{\text{LRM}}$, the ASR loss weight is $1.0$ and the SPK loss weight is $0.1$, while SER is used only when emotion conditioning is needed.
Training is performed on 64 NVIDIA H20 GPUs.
5. Information-theoretic View of the Tokenizer
A notable part of the paper is the analysis of the tokenizer from a source-coding perspective. The token entropy is defined as
$$H(X_n) = -\sum_{k=1}^{C} p(X_n = k) \log_2 p(X_n = k).$$
The paper relates the speech entropy to the discrete token representation through
$$H(Y_n) = H(X_n) + H(Y_n \mid X_n) - H(X_n \mid Y_n).$$
Because the tokenizer is deterministic, $H(X_n \mid Y_n)=0$. Therefore, increasing token entropy is equivalent to reducing the reconstruction uncertainty $H(Y_n \mid X_n)$. The authors argue that the FM objective is a natural way to minimize this uncertainty. They also model token predictability with a first-order Markov approximation:
$$\tilde{H}(X) = H(X_{n+1} \mid X_n) = H(X_n) - I(X_{n+1}; X_n).$$
Under this view, a good speech tokenizer should simultaneously have high token entropy $H(X_n)$ and strong temporal dependency $I(X_{n+1}; X_n)$, so that the codebook is well utilized and the next-token prediction problem remains structured rather than degenerate.
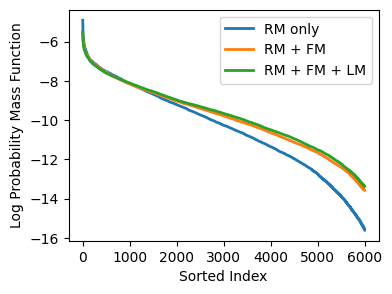
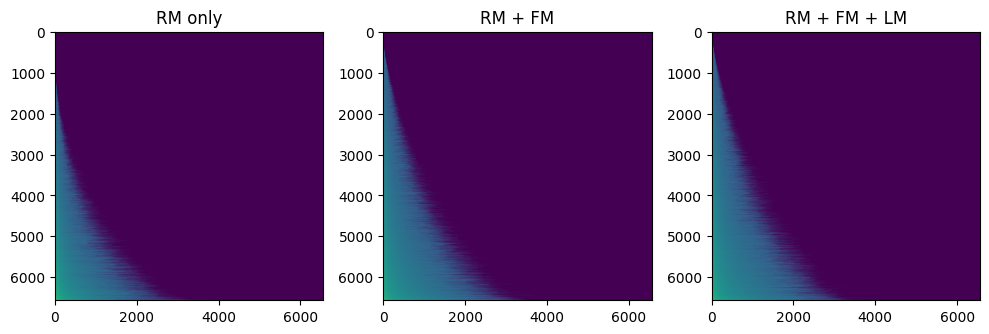
In the frequency plots, the authors report that FSQ gives nearly $100\%$ codebook utilization, but the tokenizer trained without $L_{\text{LM}}$ and $L_{\text{FM}}$ exhibits a long-tailed, concentrated token distribution. Adding $L_{\text{FM}}$ flattens the unigram distribution, and adding $L_{\text{LM}}$ further smooths the bigram distribution.
Their measured token statistics on LibriTTS are:
| Tokenizer | $H(X_n)$ | $I(X_{n+1};X_n)$ |
|---|---|---|
| RM only | 10.905 | 2.50 |
| RM + FM | 11.254 | 2.53 |
| RM + FM + LM | 11.363 | 2.55 |
The conclusion the paper draws is that E2E training makes the token space more informative and more predictive at the same time, which is exactly what a TTS pipeline wants.
6. Experimental Setup
Experiments use an in-house TTS dataset of about 100,000 hours of speech in Chinese and English, with a language ratio of $4{:}1$. The data are collected from publicly accessible websites and transcribed with Whisper-Large-V3 and FireRedASR. The authors also use DNSMOS to estimate perceptual quality. To reduce noisy and mislabeled examples, they filter out utterances with DNSMOS below $3.3$ or transcription difference rate above $5\%$.
Evaluation is done on several benchmarks and subsets reported in the paper: Seed-TTS-Eval / SEED test sets for zero-shot TTS, CV3-Subject for reconstruction analysis, LibriSpeech test-clean and CommonVoice for recognition evaluation, MELD and IEMOCAP for emotion recognition, and LibriTTS for token statistics.
The paper reports the following parameter scales: tokenizer $0.6$B, RM $0.7$B, LM $0.6$B, and FM $0.5$B. The overall system is intentionally simpler than many multi-stage training recipes because the tokenizer, generator, and reward/recognition objectives are unified under one E2E framework.
7. Main Results: Zero-shot TTS
The central result is that the three-stage E2E training improves content consistency and speaker similarity relative to a non-E2E baseline and is competitive with or better than recent TTS systems on the Seed-TTS-Eval benchmark. The paper reports the following values:
| Model | test-zh CER $ $ | test-zh SS | test-en WER $ $ | test-en SS | test-hard CER $ $ | test-hard SS |
|---|---|---|---|---|---|---|
| Human | 1.26 | 0.755 | 2.14 | 0.734 | - | - |
| MaskGCT | 2.27 | 0.774 | 2.62 | 0.714 | 10.27 | 0.748 |
| F5-TTS | 1.56 | 0.741 | 1.83 | 0.647 | 8.67 | 0.713 |
| F5R-TTS | 1.37 | 0.754 | - | - | 8.79 | 0.718 |
| ZipVoice | 1.40 | 0.751 | 1.70 | 0.697 | - | - |
| OmniVoice | 0.84 | 0.777 | 1.60 | 0.741 | - | - |
| Seed-TTS | 1.12 | 0.796 | 2.25 | 0.762 | 7.59 | 0.776 |
| Spark TTS | 1.20 | 0.672 | 1.98 | 0.584 | - | - |
| CosyVoice3-1.5B | 1.12 | 0.781 | 2.21 | 0.720 | 5.83 | 0.758 |
| Qwen3-TTS-0.6B | 1.18 | - | 1.64 | - | - | - |
| JoyVoice | 0.97 | 0.786 | 1.69 | 0.736 | 5.55 | 0.746 |
| E2E-TTS-Stage1 | 1.16 | 0.775 | 2.09 | 0.690 | 7.68 | 0.752 |
| E2E-TTS-Stage2 | 0.86 | 0.775 | 1.72 | 0.696 | 7.21 | 0.752 |
| E2E-TTS-Stage3 | 0.78 | 0.781 | 1.56 | 0.705 | 6.61 | 0.759 |
| w/o E2E-training | 0.87 | 0.760 | 1.89 | 0.682 | 7.35 | 0.745 |
The numbers show a clear progression across the training stages. Stage 1 already improves the tokenizer and produces a usable system, Stage 2 narrows the mismatch between modules, and Stage 3 gives the best overall content consistency. The strongest reported zero-shot result is 0.78% CER on Chinese and 1.56% WER on English, with speaker similarity of $0.781$ on test-zh and $0.705$ on test-en.
The comparison against the non-E2E baseline is especially important: even with the same training corpus, the conventional pipeline is weaker on both content consistency and speaker similarity. The authors interpret this as evidence that the joint objectives are not merely regularization, but directly address module mismatch and token design.
8. Reconstruction Ability of the FM
The paper separately evaluates the FM decoder, because one goal of the joint tokenizer training is to make the discrete codes more useful for reconstruction. On SEED test sets and CV3-Subject, Stage 2 and Stage 3 consistently improve reconstruction metrics relative to Stage 1. The results reported are:
| Model | test-zh CER | test-zh SS | test-en WER | test-en SS | CV3-Subject WER | CV3-Subject SS |
|---|---|---|---|---|---|---|
| $S^3$-Tokenizer-FSQ | 3.31 | 0.787 | 4.09 | 0.709 | 11.50 | 0.761 |
| E2E-TTS-Stage1 | 3.36 | 0.814 | 3.42 | 0.688 | 11.71 | 0.762 |
| E2E-TTS-Stage2 | 3.05 | 0.825 | 3.26 | 0.704 | 11.67 | 0.781 |
| E2E-TTS-Stage3 | 2.93 | 0.826 | 3.08 | 0.702 | 11.56 | 0.780 |
| w/o $L_{\text{LM}}$ | 3.12 | 0.812 | 3.45 | 0.691 | 11.56 | 0.774 |
| w/o $L_{\text{LM}}$ and $L_{\text{FM}}$ | 3.68 | 0.799 | 4.11 | 0.662 | 12.30 | 0.768 |
Two observations are emphasized in the paper. First, Stage 2 gives a substantial jump, consistent with the idea that the tokenizer benefits when it is jointly shaped by downstream reconstruction. Second, Stage 3 further improves WER but not always speaker similarity, which the authors attribute to adaptation toward the LM’s predicted-token distribution rather than pure fidelity to the reference speaker.
The ablation on $L_{\text{LM}}$ and $L_{\text{FM}}$ shows that both are important. Removing both losses degrades reconstruction clearly, and removing only $L_{\text{LM}}$ still hurts performance relative to the full objective. The paper’s interpretation is that $L_{\text{FM}}$ is especially important for acoustic reconstruction, while $L_{\text{LM}}$ contributes semantic structure and token regularity.
9. Recognition Ability of the RM
The RM is evaluated as a recognition model in its own right, using ASR and SER tasks. This is important because the RM is not just a training-side regularizer; it is one of the sources of supervision that shapes the tokenizer’s latent space.
| Model | CMV-zh WER | CMV-en WER | LS-clean WER | IEMOCAP WA | MELD WA |
|---|---|---|---|---|---|
| Whisper-large-V3 | 12.40 | 9.66 | 2.56 | - | - |
| Emo2Vec-large | - | - | - | 67.3 | 57.4 |
| SenseVoice-small | 10.78 | 14.71 | 3.15 | 65.7 | 57.8 |
| $S^3$-Tokenizer-FSQ | 7.27 | 10.67 | - | - | - |
| Qwen-TTS-Tokenizer | 14.99 | 10.40 | - | - | - |
| E2E-TTS-Stage1 | 6.85 | 14.62 | 2.27 | - | - |
| E2E-TTS-Stage2 | 6.50 | 14.53 | 2.22 | 60.8 | 55.6 |
| w/o $L_{\text{LM}}$ | 7.16 | 14.77 | 2.23 | 60.2 | 54.1 |
| w/o $L_{\text{LM}}$ and $L_{\text{FM}}$ | 7.69 | 16.53 | 2.96 | 59.5 | 55.7 |
The RM remains competitive despite operating on quantized inputs. The paper highlights that it outperforms the $S^3$ tokenizer and Qwen-TTS tokenizer on the Chinese ASR setting and that adding Stage 2 improves the RM, showing that the tokenizer’s E2E training still benefits from a later standalone refinement phase. The effect of $L_{\text{FM}}$ and $L_{\text{LM}}$ is again positive, in line with self-supervised representation-learning intuitions.
10. What the Ablations Say
The paper’s ablation story is coherent across metrics:
- Stage-wise training matters: Stage 1 initializes the shared token space, Stage 2 improves module specialization, and Stage 3 makes the LM/FM pair robust to predicted-token inputs.
- Joint training helps token design: the tokenizer trained with RM + FM + LM yields higher entropy and more balanced token usage than RM alone.
- $L_{\text{FM}}$ is critical for reconstruction: removing it weakens the FM’s ability to preserve speech content and similarity.
- $L_{\text{LM}}$ improves predictability and structure: it helps the tokenizer and improves downstream speech reconstruction and token statistics.
- E2E beats conventional cascades: training the tokenizer first and then training LM/FM separately is worse than the proposed holistic optimization, even on the same dataset.
11. Stated Contributions and Novelty
Based on the paper body, the main contributions are:
- A fully end-to-end optimization framework for discrete-token LLM-based TTS that jointly trains the tokenizer, LLM, FM decoder, and RM.
- A two-level objective design: a first-order loss that shapes the tokenizer with downstream tasks, and a second-order loss that trains the LLM/FM on predicted-token distributions.
- An information-theoretic analysis connecting token entropy and token predictability to TTS quality.
- Empirical evidence that holistic optimization produces better zero-shot synthesis, better reconstruction, and better recognition features than a non-E2E baseline.
- A simpler training pipeline than many prior cascaded systems, while still reaching new best-reported WERs on the Seed-TTS-Eval benchmark in the reported configuration.
12. Limitations and Practical Takeaways
The paper does not present a dedicated limitations section, but several constraints are evident from the experiments and discussion. The reported evaluation is centered on Chinese and English with in-house data, plus a limited set of public recognition and analysis benchmarks. The paper also does not report runtime, streaming latency, or subjective MOS results in the provided body, so the impact of the E2E training on deployment cost is not quantified here. In addition, the authors note that future work will examine the effects of E2E training on individual components such as the FM, RM, and tokenizer more carefully.
The main practical takeaway for a conversational-AI / talking-head team is that the token space should not be treated as a frozen intermediate representation: if the discrete tokens are the interface between text planning and acoustic rendering, then training that interface against all downstream objectives can materially improve the overall system. In this paper, the improvement comes from making the tokenizer optimizable by synthesis and recognition, and then making the generator optimizable under its own predicted-token distribution.
Code & Implementation
The repository GPT-SoVITS provides a full codebase supporting a text-to-speech system based on discrete token large language models, aligning well with the paper's end-to-end training framework for TTS.
Main components include:
- Training scripts: For example,
s2_train_v3.pyands2_train_v3_lora.pyimplement the training loops for the TTS synthesis model, supporting multi-GPU distributed training and configuration-driven hyperparameters as described in the paper's joint optimization approach. - Model definitions: Located primarily under
module/models.pyand related modules, these define the neural architectures (SynthesizerTrn and variants) central to the speech tokenizer, autoregressive LLM, and flow-matching components. - Inference utilities: Scripts such as
inference_webui.pyprovide a web-based interface for zero-shot and few-shot voice conversion and TTS inference, facilitating practical demonstration of the end-to-end system. - Configuration and pretrained models: The
configs/directory includes YAML and JSON configuration files specifying training and model parameters, while pretrained weights are organized inpretrained_models/.
The README and source code suggest the repo offers comprehensive pipelines for training and inference, including multi-task objectives and hardware-optimized implementations following the paper's methodology.
In summary, the repository fully realizes the holistic end-to-end discrete token TTS system proposed in the paper, integrating tokenizer training, LLM optimization, and flow-matching models within a unified framework.