C-Gate
Is Text All You Need? Text as a Universal Information Bottleneck for Speech LLMs
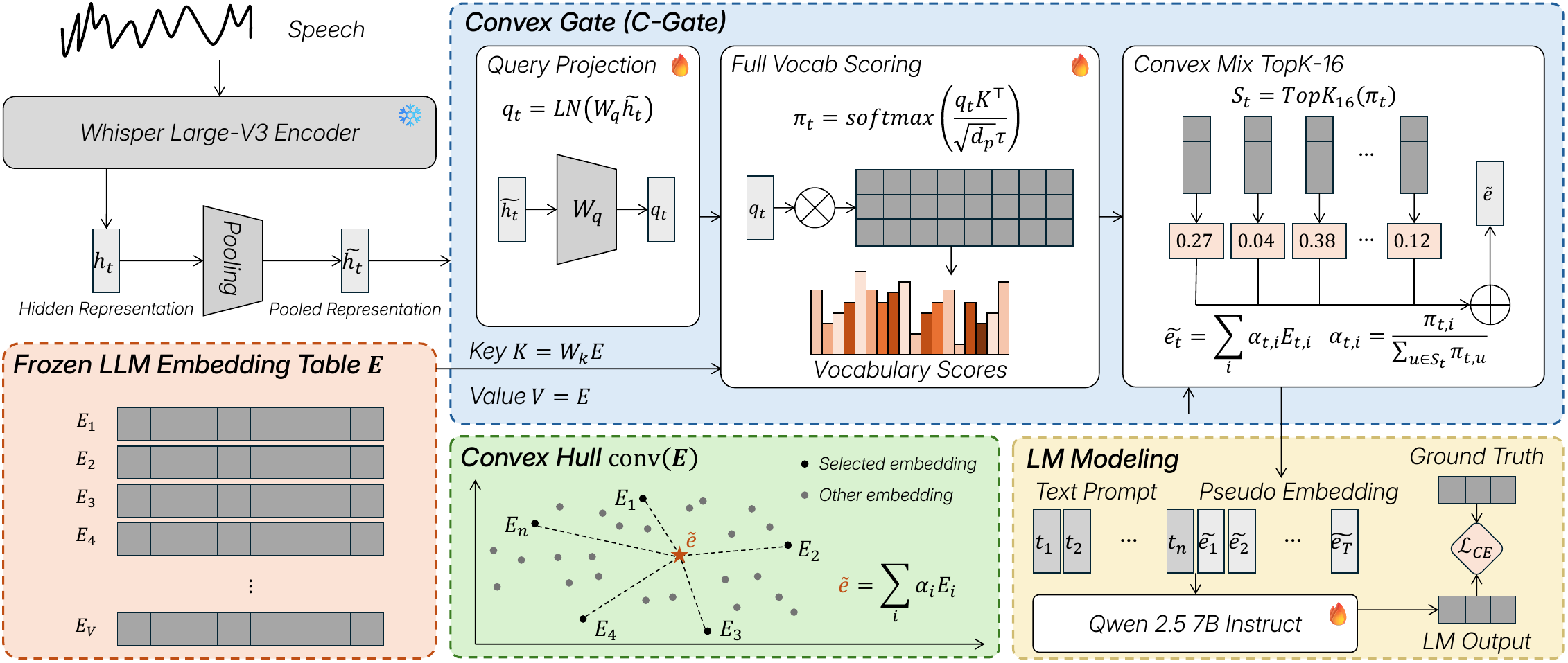
C-Gate is a speech-to-LLM interface that constrains speech representations within the LLM's input embedding manifold using a convex-hull constraint. This enables continuous speech integration into frozen LLMs, preserving paralinguistic information and improving joint ASR, emotion recognition, and spoken reasoning.
Links
Paper & demos
Impact
Abstract
Large language models (LLMs) provide a powerful reasoning backbone for speech understanding, but integrating continuous acoustic signals into a frozen LLM remains challenging. Existing speech-to-LLM interfaces typically operate at two extremes: either enforcing near-discrete token alignment, which benefits transcription but loses paralinguistic information, or learning unconstrained continuous representations, which can drift away from the LLM's input space and degrade autoregressive decoding. In this work, we propose Convex Gate (C-Gate), a speech-to-LLM bridge that constrains all speech representations to lie within the LLM's input embedding manifold with an architectural convex-hull constraint. Concretely, each frame is represented as a convex combination of token embeddings, ensuring compatibility with the pretrained LLM while preserving continuous expressivity. Across automatic speech recognition (ASR) and emotion recognition, C-Gate achieves strong joint performance, improving LibriSpeech WER by up to 48.7% relative while matching or exceeding single-task emotion accuracy. Beyond performance, our analysis reveals a key insight: information is not carried by discrete token identities, but by time-resolved trajectories in the embedding space. Causal interventions confirm that both the trajectory structure and alignment to the pretrained embedding manifold are critical for performance. These results suggest that geometry, rather than token discreteness, is the fundamental design factor in speech-to-LLM interfaces, and provide a controlled regime for studying multimodal integration in frozen LLMs. We release the checkpoint, per-sample outputs, mechanism dumps, and intervention suite for replication.
Introduction
This paper studies how to connect a frozen speech encoder to a frozen large language model (LLM) for speech understanding without collapsing speech into a brittle text-only channel or drifting into an input space the LLM was never trained to read. The motivation is practical: instruction-tuned LLMs such as Qwen2.5-7B carry reasoning, response formatting, and tool-use priors that are expensive to relearn from speech data alone, so the main problem is not whether to use an LLM, but what form of speech representation should be injected into its context.
The authors argue that existing speech-to-LLM bridges sit at two extremes. Some methods encourage near-discrete alignment to vocabulary tokens, which is useful for automatic speech recognition (ASR) but tends to suppress paralinguistic information such as emotion or prosody. Other methods use unconstrained continuous bridge states, which are flexible but can drift away from the pretrained LLM input manifold and destabilize autoregressive decoding. C-Gate is proposed as a middle ground: speech is mapped into the convex hull of the LLM’s own token embeddings, so every injected frame is a continuous mixture of real token vectors rather than a free latent vector or a one-hot token choice.
The central claim is geometric rather than lexical: the important thing is not whether the bridge chooses discrete token identities, but whether the speech signal stays inside the LLM’s trained input geometry while remaining time-resolved. The paper’s analysis repeatedly returns to this point, showing that the information-bearing object is a trajectory through the embedding manifold, not a bag of token labels.
Key reported contributions are: a convex-hull speech-to-LLM interface, improved joint ASR and emotion recognition under matched training budgets, mechanistic evidence that time-ordered support trajectories are the working channel, and a more controlled evaluation protocol for spoken reasoning benchmarks.
Method: Convex Gate (C-Gate)
C-Gate takes hidden states from a frozen Whisper-large-v3 encoder and converts them into a speech prefix that lies inside the frozen LLM’s input embedding manifold. If the encoder outputs $h_{1:T}$, the bridge first applies stride-$4$ mean pooling to produce pooled states $\tilde{h}_{1:T'}$, where $T' = \lceil T/4 \rceil$. Each pooled state is then scored against the full vocabulary embedding table of the LLM.
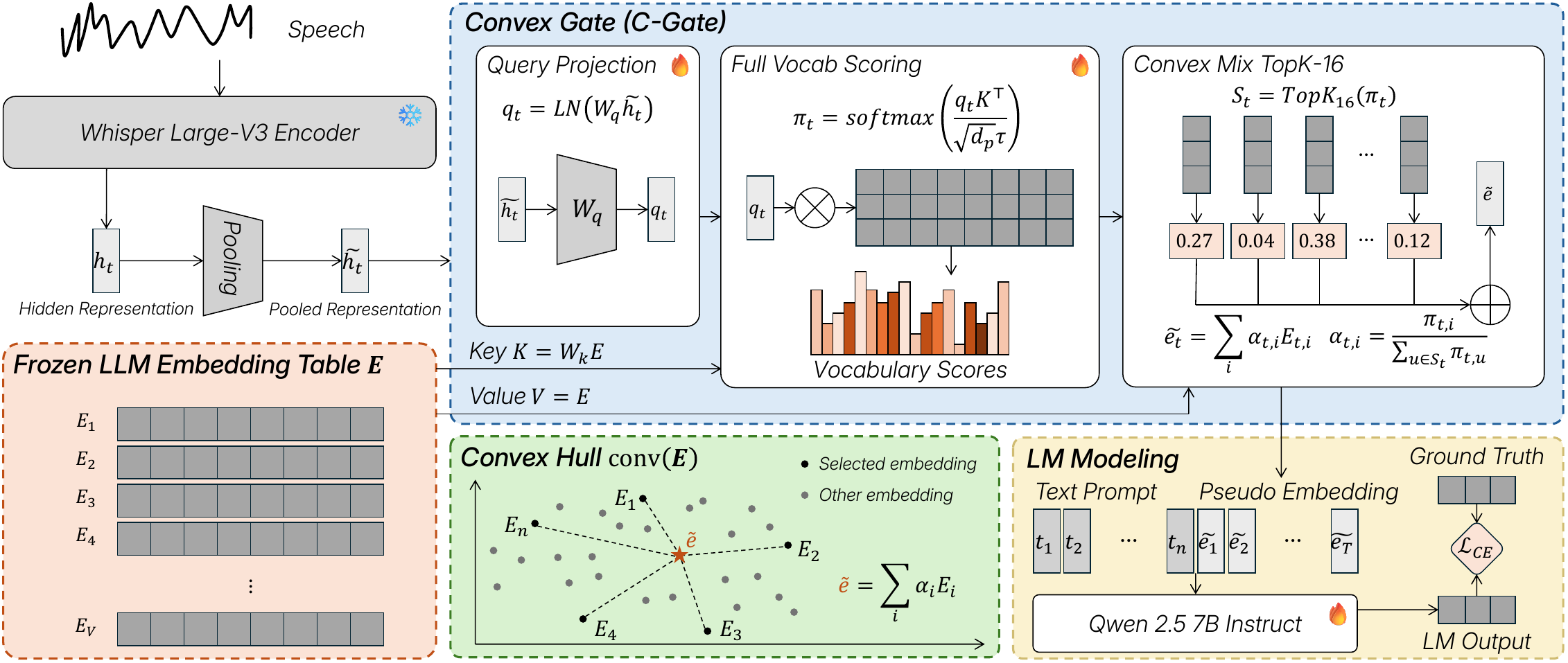
Formally, each bridge vector is constrained to the convex hull of the embedding table $E$:
$$ \operatorname{conv}(E)=\left\{\sum_{v=1}^{V} \alpha_v E_v : \alpha_v \ge 0,\ \sum_{v=1}^{V} \alpha_v = 1\right\}. $$
The bridge computes a query from the pooled speech state using layer normalization and a learned projection, while the embedding table is projected only for key scoring. For frame $t$,
$$ q_t = \operatorname{LN}(W_q \tilde{h}_t), \qquad K = W_k E, $$
followed by a full-vocabulary softmax over query-key scores,
$$ \pi_t = \operatorname{softmax}\!\left(\frac{q_t K^\top}{\sqrt{d_p}\,\tau}\right), $$ where $\tau$ is a learned temperature.
Instead of using the entire posterior, C-Gate keeps the top-$16$ support and renormalizes it. The speech prefix inserted into the LLM is therefore
$$ \alpha_{t,v} = \begin{cases} \pi_{t,v}/\sum_{u \in S_t} \pi_{t,u}, & v \in S_t,\\ 0, & v \notin S_t, \end{cases} \qquad \tilde{e}_t = \sum_{v\in S_t} \alpha_{t,v} E_v, $$
where $S_t = \operatorname{TopK}_{16}(\pi_t)$. Because the values are raw embedding rows and not learned latent vectors, each $\tilde{e}_t$ is guaranteed to lie in $\operatorname{conv}(E)$. The paper emphasizes that this is a deterministic support-selection step after full-vocabulary scoring, not a separate sparse routing objective.
Once the speech prefix is built, it is concatenated with the task prompt embeddings and fed into the frozen LLM for standard autoregressive decoding. The paper does not use CTC, prefix forcing, an external classifier head, or a task-specific decoder. Target tokens are trained with next-token cross-entropy only.
A particularly important implementation detail is that the bridge does not learn values in an unconstrained latent space: it reuses the LLM’s own embedding rows as the value basis. This is the architectural reason the authors call it a convex-hull constraint rather than merely an embedding-table lookup.
Training setup
The trainable part of the system is deliberately limited. The paper trains only the bridge similarity scorer $(W_q, \operatorname{LN}, W_k, \tau)$ and the LLM self-attention projections $\{W_Q, W_K, W_V, W_O\}$ in Qwen layers $0$ through $23$. Everything else remains frozen: the Whisper encoder, the LLM embedding table, the LM head, all MLPs, and all layer norms. The total trainable budget is $707.25$M parameters, broken down as $2.49$M bridge parameters and $704.75$M self-attention parameters.
Training uses a single multi-task cross-entropy objective with dynamic loss reweighting. The paper defines
$$ \mathcal{L}^{(t)} = \sum_{i \in \mathcal{T}} w_i^{(t)} \mathcal{L}_i^{(t)}, \qquad w_i^{(t)} \propto \left(\frac{\mathcal{L}_i^{\mathrm{EMA},t}}{\mathcal{L}_i^{\mathrm{init}}}\right)^\alpha, \qquad \alpha = 1, $$
with exponential moving average smoothing at decay $0.9$ and clipped task weights in $[0.2, 5.0]$. This dynamic reweighting is used for the multitask configurations and is meant to balance interference between tasks of different difficulty and gradient scale.
The model variants are:
- C-Gate-ASR: trained on ASR only.
- C-Gate-Emotion: trained on emotion recognition only.
- C-Gate-Reasoning: trained on reasoning speech tasks only.
- C-Gate-2T: ASR + emotion.
- C-Gate-3T: ASR + emotion + reasoning, with dynamic reweighting.
Benchmarks and evaluation protocol
The main evaluation suite covers three types of tasks: transcription, emotion recognition, and spoken reasoning. For ASR, the paper reports LibriSpeech test-clean autoregressive (AR) WER and teacher-forced (TF) WER. For emotion recognition, the main benchmark is RAVDESS, treated as a closed-set emotion completion task. For reasoning, the paper evaluates VoiceBench-BBH (VB-BBH), Big-Bench Hard heldout (BBH-HO), SpeechMMLU, Massive Multi-task Audio Understanding and Reasoning (MMAU), and Massive Multi-task Spoken Language Understanding (MMSU).
The authors stress that the evaluation is designed as a controlled comparison of interface designs under identical training budgets rather than a broad leaderboard contest. Reasoning scores are explicitly treated as boundary measurements, because multiple-choice audio benchmarks can be sensitive to weak audio grounding or text-only shortcuts.
Main results
| Method | AR-WER ↓ | TF-WER ↓ | Emotion ↑ | VB-BBH ↑ | BBH-HO ↑ | SpMMLU ↑ | MMAU ↑ | MMSU ↑ |
|---|---|---|---|---|---|---|---|---|
| C-Gate-ASR | 7.76 | — | — | — | — | — | — | — |
| C-Gate-Emotion | — | — | 96.2 | — | — | — | — | — |
| C-Gate-Reasoning | — | — | — | 45.3 | 23.6 | 53.2 | 44.0 | 55.5 |
| C-Gate-2T | 4.78 | 3.60 | 97.1 | — | — | — | — | — |
| C-Gate-3T | 3.98 | 3.89 | 90.5 | 55.4 | 40.0 | 61.4 | 48.3 | 60.6 |
The central empirical pattern is that joint training helps ASR rather than merely preserving it. Under identical ASR data and trainable-parameter budget, C-Gate-2T reduces LibriSpeech AR-WER from $7.76\%$ to $4.78\%$, a $38.4\%$ relative reduction. C-Gate-3T reduces it further to $3.98\%$, which is a $48.7\%$ relative reduction over C-Gate-ASR and a $16.7\%$ reduction over C-Gate-2T.
Emotion recognition is preserved or improved in the 2-task regime: C-Gate-Emotion reaches $96.2\%$, while C-Gate-2T reaches $97.1\%$. The paper notes that the improvement is class-symmetric rather than a frequency collapse, with the strongest gains on calm and neutral and only modest regressions on some other categories.
In the 3-task setting, the model still improves ASR while maintaining useful emotion recognition at $90.5\%$. This is framed as a stress test: reasoning supervision begins to compete with the paralinguistic channel, but the bridge still yields better ASR than the ASR-only baseline.
On the reasoning side, C-Gate-3T improves over C-Gate-Reasoning on every reported benchmark: VB-BBH goes from $45.3$ to $55.4$, BBH-HO from $23.6$ to $40.0$, SpMMLU from $53.2$ to $61.4$, MMAU from $44.0$ to $48.3$, and MMSU from $55.5$ to $60.6$. The paper treats these numbers as boundary measurements of what the frozen-LLM bridge can support under joint supervision, not as a claim of fully grounded speech reasoning.
Public-reference scale calibration
The paper also compares C-Gate-3T to public, academic, and large-scale audio LLMs, explicitly cautioning that the comparison is for scale calibration rather than a strict leaderboard because the systems differ substantially in training data, model capacity, and benchmark coverage.
| System | LibriSpeech WER ↓ | MMSU ↑ | MMAU ↑ |
|---|---|---|---|
| Qwen-Audio-Chat | 2.0 | 46.9 | 41.9 |
| Qwen2-Audio-Instruct | 1.6 | 53.3 | 52.5 |
| Qwen2.5-Omni-7B | 1.8 | 61.3 | 65.6 |
| Kimi-Audio-7B-Instruct | 1.28 | 62.2 | 65.2 |
| Audio Flamingo 3 | 1.57 | 61.4 | 72.4 |
| LTU-AS | 4.9 | N.R. | N.R. |
| BLSP+RP | 6.4 | N.R. | N.R. |
| WavLLM | 2.0 | N.R. | N.R. |
| SALMONN | 2.1 | 30.0 | 32.8 |
| AlignFormer | 3.52 | N.R. | N.R. |
| C-Gate-3T | 3.98 | 60.6 | 48.3 |
The authors highlight two calibration points from this table. First, on MMSU, C-Gate-3T reaches $60.6\%$, which is within $1.6$ percentage points of the strongest reported entry in the table, Kimi-Audio-7B-Instruct at $62.2\%$. Second, its LibriSpeech AR-WER of $3.98\%$ is competitive with several public-data bridges, though not with the largest-scale foundation models.
Mechanism: what information actually flows through the bridge?
A major part of the paper is devoted to showing that the bridge does not behave like a symbolic transcript retriever. Instead, the useful signal is distributed across a time-ordered trajectory of support choices inside the LLM embedding manifold. The authors combine routing statistics, probing, attention analysis, and causal perturbations to support this claim.
Diffuse routing is not lexical token retrieval
Although C-Gate selects a top-$16$ support per frame, the renormalized posterior over those supports remains close to uniform. The normalized entropy of the top-$16$ posterior is reported in the range $0.962$ to $0.987$ of the maximum entropy $\log 16$, which means the per-frame mixture weights are diffuse rather than sharply one-hot. The paper also reports utterance-level KL quantities against the uniform distribution, but emphasizes that these are within-input concentration measures, not mutual information.
A key diagnostic is that the per-frame top-1 token identities are stable within a model yet do not correspond in any interpretable way to transcript words, emotion labels, or other symbolic categories. This supports the authors’ claim that the bridge channel is not lexical retrieval. Since the posterior is close to uniform over a huge vocabulary, the gradient through the softmax is also tiny near initialization or near-diffuse regimes, scaling roughly like $1/V$; the paper uses $V = 151{,}936$ and notes that this explains why adaptation accumulates in self-attention rather than in a single symbolic route.
In parallel, the paper uses a bag-of-support probe: treating the selected token ids across an utterance as an order-invariant multiset gives $77.7\%$ accuracy on RAVDESS, compared with $67.8\%$ for a matched probe on the upstream Whisper representation. By contrast, pooling the per-frame bridge outputs into a single utterance vector gives only $16.8\%$ under the same probe setup. The conclusion is that information resides in the time-resolved sequence of selected supports, not in the static mixture vector itself.
The paper uses a Fano-style argument to show that this is consistent with the observed emotion probe results. With an error rate around $p_e \approx 0.223$ on an $8$-class task, the selected-support bag retains at least about $1.6$ bits per utterance of mutual information lower bound.
Task-conditional self-attention readout
The authors extract text-to-audio attention matrices and summarize them with an entropy-based effective rank. Under emotion prompts, attention collapses to a pooled low-rank readout, with effective rank around $1.2$ to $1.7$ in middle layers. Under ASR prompts, the same model reads the same bridge trajectory in a more position-sensitive manner, reaching higher effective rank; in the ASR-only model, layer-14 rank is reported as $9.78$. C-Gate-2T switches cleanly between these behaviors depending on the prompt, which the paper interprets as evidence that the bridge can support both utterance-level and position-sensitive tasks through a shared representation.
In C-Gate-3T, the paper observes that both emotion and ASR prompts remain low-rank across the 28 Qwen2.5-7B layers, with a small but consistent ASR-over-emotion gap in early and middle layers. This suggests that task prompting changes the readout even when the underlying bridge is shared.
Causal interventions on the trained model
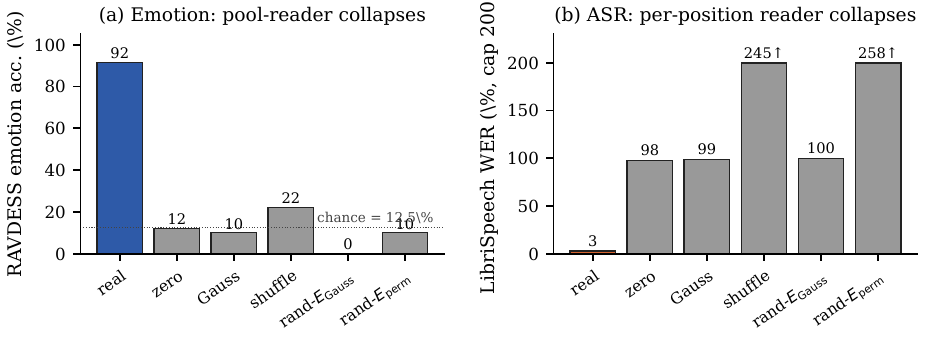
The strongest evidence in the paper comes from interventions applied to a released C-Gate-3T checkpoint while holding the encoder, bridge weights, LLM weights, prompt template, and decoder fixed. The tests use $200$ RAVDESS samples and $200$ LibriSpeech samples.
| Perturbation | Emotion accuracy | LibriSpeech WER |
|---|---|---|
| Real audio | 91.5% | 2.8% |
| Zero waveform | 12.0% | 97.5% |
| RMS-matched Gaussian noise | 10.0% | 98.5% |
| Frame-trajectory shuffle | 22.0% | 244.5% |
| Gaussian embedding table | 0.0% | 100.0% |
| Row-permuted embedding table | 10.0% | 257.9% |
These perturbations isolate three necessary factors. First, real acoustic input matters: replacing the waveform with zeros or RMS-matched Gaussian noise collapses both tasks. Second, temporal order matters: shuffling the bridge trajectory in time severely damages both emotion and ASR, showing that the model uses a trajectory, not a support multiset. Third, the trained embedding manifold matters: replacing the LLM embedding table with either same-shape Gaussian noise or a row-permuted table removes the gains, even though vocabulary cardinality and dimensionality are preserved. The paper takes this as evidence that manifold alignment with the pretrained embedding table is the load-bearing factor.
Interpretation and takeaways
The paper’s broader message is that geometry is the critical design variable in speech-to-LLM interfaces. C-Gate preserves compatibility with the frozen LLM by constraining speech representations to the convex hull of its token embeddings, but it does not force them to become literal tokens. This lets the model keep enough continuous expressivity to carry paralinguistic information while avoiding the drift problems of unconstrained latent bridges.
One practical implication is that adding trainable capacity near the LLM is not enough; the capacity has to be organized as a bridge that lives in the correct input geometry. The authors therefore argue that the useful signal is a time-ordered support trajectory through $\operatorname{conv}(E)$, and that self-attention adaptation alone is insufficient if the representation leaves the pretrained manifold.
Another implication is methodological: reasoning benchmarks should not be treated as evidence of grounded audio understanding without additional checks. The paper explicitly frames its spoken-reasoning scores as stress tests and performs audio-replacement and support-shuffle interventions to verify that the bridge actually carries audio information.
Limitations
The paper is clear about its limitations. The strongest alternative explanation is that C-Gate succeeds because it adds trainable capacity close to the LLM, rather than because the capacity is specifically organized as a convex codebook query. A matched Q-Former-style learned-token bridge under the same frozen encoder, prompts, and parameter budget would be the most informative comparison.
The evaluation is also narrow in several respects: the paper uses one encoder-LLM pair, one training seed, and an acted closed-set emotion benchmark (RAVDESS). The reasoning tasks are not claimed to be fully grounded spoken reasoning; they are boundary measurements that still require stronger audio-contribution audits.
The authors also caution against deployment for high-stakes speaker inference, and note that raw third-party audio is not redistributed.
Conclusion
C-Gate is a controlled speech-to-LLM bridge that writes each speech frame as a convex combination of LLM token embeddings. In the reported experiments, this geometric constraint improves ASR substantially under joint training, preserves or improves emotion recognition in the two-task setting, and supports useful though carefully bounded spoken-reasoning performance in the three-task setting. Mechanistically, the paper shows that the effective information channel is a time-ordered trajectory through the pretrained embedding manifold, not discrete token identity itself.
The main contribution is therefore not just a new adapter, but a stronger experimental regime for studying how frozen LLMs consume speech: keep the backbone fixed, constrain the bridge to the embedding manifold, and test whether the information lies in geometry, not in lexical discreteness.