Mel-LLM
LLM can Read Spectrogram: Encoder-free Speech-Language Modeling
Mel-LLM is an encoder-free speech-language model that directly feeds Mel spectrograms into an LLM, enabling it to learn speech-text alignment without a separate speech encoder. It delivers competitive ASR results and promising TTS capabilities with a simpler, unified architecture.
Demos
The demos highlight Mel-LLM's encoder-free speech-language modeling by directly reading spectrograms for tasks including speech recognition, translation, summarization, and question answering. Evaluate the accuracy, clarity, and multilingual capabilities in transcription, translation quality, and integrated speech-language processing.
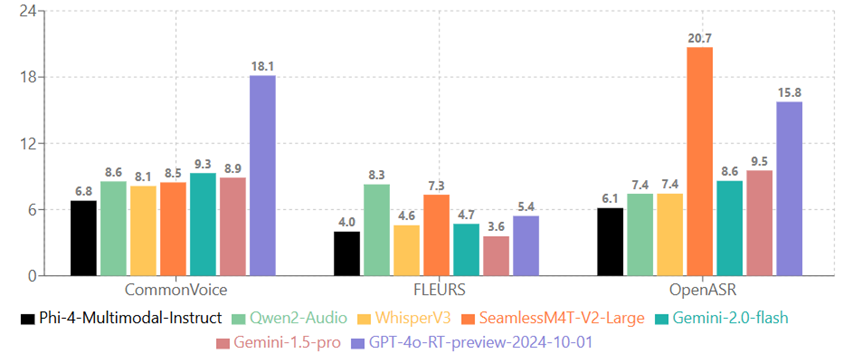
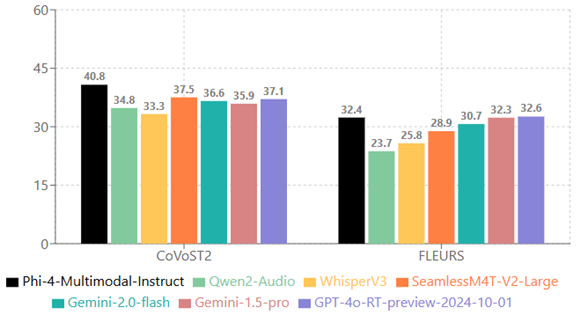
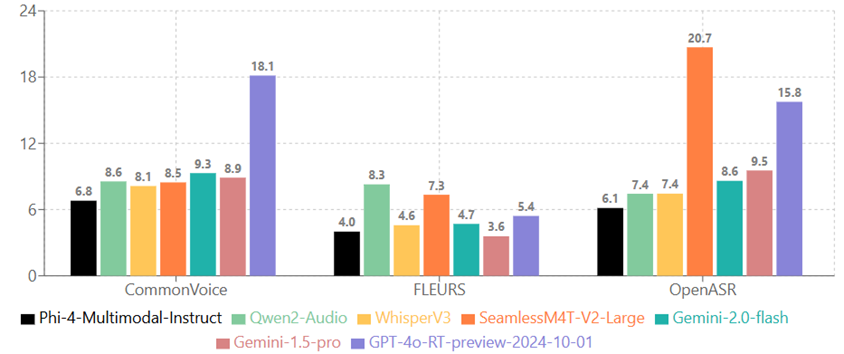
Links
Paper & demos
Code & resources
Impact
Abstract
Recent speech-aware large language models (Speech-LLMs) rely on a pre-trained speech encoder to convert audio into semantic-rich representations consumable by LLM. In this work, instead, we explore: can an LLM learn to read Mel spectrogram directly without a dedicated speech encoder? We propose Mel-LLM, an encoder-free Speech-LLM that feeds lightly pre-processed Mel spectrogram patches directly into the LLM through a linear projection, allowing the LLM to learn speech-text alignment purely through its own parameters. We conduct extensive experiments on both automatic speech recognition (ASR) and text-to-speech (TTS) tasks. For ASR, we evaluate on the OpenASR leaderboard public sets and production-level scaling experiments, demonstrating that the encoder-free solution achieves competitive performance with only limited degradation compared to encoder-initialized counterparts. We find that when data is limited, initialization from a multimodal checkpoint (Phi-4-MM) is crucial for maintaining performance. We also present ablation studies revealing which LLM layers are less relevant to speech encoding. For TTS, we show preliminary results with a next-token VAE approach. While TTS performance is not yet optimal, these results establish the feasibility of a fully unified encoder-free architecture for autoregressive speech-text modeling.
Introduction
This paper asks a direct architectural question for speech-language modeling: can a large language model learn to read Mel spectrograms without a dedicated speech encoder? The proposed answer is Mel-LLM, an encoder-free Speech-LLM that removes the conventional pre-trained speech encoder and instead feeds lightly processed Mel spectrogram patches directly into the LLM through a linear projection. The central claim is not that speech encoders are unnecessary in all regimes, but that a sufficiently capable LLM can internalize the missing speech-encoding function in its own parameters when trained end to end on enough paired speech-text data.
The motivation is practical and conceptual. Prior Speech-LLM systems typically rely on a large speech encoder such as Whisper- or Conformer-style front ends to convert audio into semantic representations before passing them to the LLM. That design adds parameters and latency, and it also constrains the information available to the LLM to whatever the encoder chooses to preserve. Mel-LLM removes the Transformer/Conformer encoder stack, keeps convolution only as an optional downsampling mechanism, and tests whether direct spectral modeling can be learned by the LLM backbone itself.
The paper evaluates this idea on two directions: automatic speech recognition (ASR) and text-to-speech (TTS). For ASR, the method is tested on OpenASR leaderboard public sets as well as in-house scaling experiments. For TTS, the authors provide preliminary results for a unified autoregressive mel-generation pipeline based on a next-token VAE-style Mel head. The main takeaway is that encoder-free speech-language modeling is feasible, competitive at scale, and especially effective when initialized from a multimodal checkpoint such as Phi-4-MM.
Core idea and high-level design
Mel-LLM is built on Phi-4-MM and uses the same LLM backbone for both speech understanding and speech generation. In the ASR setting, speech is converted to 80-dimensional log-Mel features, normalized, optionally downsampled by lightweight convolutions, projected into the LLM hidden space, and then decoded autoregressively as text. In the TTS setting, text is fed into the same LLM, which autoregressively generates continuous Mel frames through a VAE-like decoder and a stop predictor. The architecture therefore replaces the speech encoder with a single learnable projection path plus the LLM’s own layers.
A useful way to view the method is that the lower LLM layers are forced to become an implicit speech encoder during training, while the upper layers preserve the language modeling and semantic capabilities already present in Phi-4-MM. The paper’s layer-wise ablations support exactly this interpretation: lower layers adapt most strongly to acoustic processing, while several upper layers can be kept close to their initialization with only small degradation.
ASR method: encoder-free speech input path
For ASR, the input is an 80-dimensional log-Mel spectrogram sequence. The paper applies mean-variance normalization using training-set statistics, then optionally passes the sequence through lightweight convolution layers for time reduction. The convolution block is not a semantic speech encoder; it is retained only to downsample the time axis when desired. In the reported ASR experiments, the authors vary the time-reduction factor $r$ and use $r=8$ as the main setting for ASR. The output of this front end is linearly projected into the LLM embedding dimension.
The projection is described by
$$E^{s} = W_{\text{proj}} e + b_{\text{proj}}$$
where $e$ denotes the preprocessed speech features and $E^{s}$ is the speech embedding sequence consumed by the LLM. In the encoder-free setting, this projection is randomly initialized rather than being paired with a separate pretrained speech encoder. The LLM then receives the speech embeddings together with a text prompt embedding sequence and autoregressively generates the transcript.
The transcription objective is standard causal language modeling over the text tokens. If $E^{p}$ denotes prompt embeddings, the input to the LLM is the concatenation of speech and prompt embeddings, and the model predicts the transcript autoregressively:
$$\hat{T} = \operatorname{LLM}(\operatorname{Concat}(E^{s}, E^{p}))$$
The LLM itself is adapted with LoRA, while the base Phi-4-MM weights are frozen. The paper uses LoRA rank $r=320$ and scaling factor $\alpha=640$ on linear layers in the attention and MLP blocks. This is important: the claim is not that the entire multimodal model is retrained from scratch, but that the LLM’s low-rank adaptation plus the new input projection are sufficient to learn speech-text alignment directly from Mel patches.
TTS method: encoder-free speech output path
For TTS, the model turns text into speech by generating Mel frames autoregressively. The text tokens are fed directly into the LLM, followed by a start-of-audio token encoded in the paper’s figure as <s>. The LLM produces hidden states at speech positions, and those hidden states are decoded into Mel spectrogram frames by a Mel head that follows a VAE-style parameterization.
At each speech position, the Mel head splits a linear projection of the LLM hidden state into mean and log-variance parameters:
$$\mu, \log \sigma^{2} = \operatorname{split}(W_{\text{latent}} h)$$
Then the latent variable is sampled with reparameterization:
$$z = \mu + \sigma \odot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)$$
The decoded Mel frame is obtained through a residual MLP:
$$\hat{m} = z + \operatorname{MLP}_{\text{res}}(z)$$
The paper specifies three residual linear layers with tanh activation and dropout, followed by a five-layer Conv1D residual postnet:
$$\hat{m}_{\text{final}} = \hat{m} + \operatorname{Postnet}(\hat{m})$$
A separate stop predictor estimates when audio should end. The overall TTS objective combines reconstruction, KL, stop, and flux terms:
$$\mathcal{L}_{\mathrm{TTS}} = \mathcal{L}_{\mathrm{reg}} + \lambda_{\mathrm{KL}} \mathcal{L}_{\mathrm{KL}} + \lambda_{\mathrm{stop}} \mathcal{L}_{\mathrm{stop}} + \lambda_{\mathrm{flux}} \mathcal{L}_{\mathrm{flux}}$$
Here, $\mathcal{L}_{\mathrm{reg}}$ is an $L_{1}$ plus MSE reconstruction loss, $\mathcal{L}_{\mathrm{KL}}$ is the KL divergence, $\mathcal{L}_{\mathrm{stop}}$ is the binary cross-entropy loss for end-of-audio prediction, and $\mathcal{L}_{\mathrm{flux}}$ encourages temporal smoothness. The TTS design is explicitly positioned as a next-token VAE approach in the style of MELLE, but with the LLM itself as the backbone.
Model configuration and training setup
| Component | Reported setting |
|---|---|
| Backbone | Phi-4-MM |
| LLM hidden size | 3072 |
| LLM depth | 32 layers |
| Attention heads | 24 attention heads, 8 KV heads |
| LoRA | Rank 320, $\alpha=640$, applied to attention and MLP linear layers |
| ASR speech features | 80-dimensional log-Mel spectrograms with MVN normalization |
| ASR downsampling | Lightweight convolution; main settings include $r=8$ for ASR and $r=2$ for TTS |
| TTS Mel head | 3-layer residual MLP, dimension 256, plus 5-layer Conv1D postnet |
| ASR optimization | DeepSpeed ZeRO Stage-1 on 16 NVIDIA H100 GPUs; AdamW; peak learning rate $10^{-4}$; 9000 warmup steps; gradient clipping at 1.0; effective batch size 512 |
| ASR training schedule | Public data iterated three times; no gain beyond that according to the paper |
| TTS optimization | Dropout 0.5 on input/output linear projections; KL weight 0.05; stop weight 1.0; flux weight 0.5; trained for 5 epochs |
For ASR, the base LLM is frozen and only LoRA parameters are trained. For TTS, the same Phi-4-MM backbone is used with LoRA adaptation. The paper emphasizes that the encoder-free design is intentionally simple: the speech-specific inductive bias comes from the input feature format and optimization, not from a dedicated speech encoder network.
Data and evaluation protocol
ASR training uses only public English corpora, totaling about 31 million utterances, or roughly 64k hours. The listed sources are LibriSpeech, GigaSpeech, MLS English, SPGISpeech, Common Voice 15 English, VoxPopuli English, TED-LIUM, AMI, Earnings-22, and FLEURS English. The authors explicitly state that no proprietary or internal data is used for the OpenASR experiments.
Evaluation for ASR is carried out on OpenASR leaderboard public test sets: AMI, Earnings22, Gigaspeech, LibriSpeech clean, LibriSpeech other, SPGISpeech, TED-LIUM, and VoxPopuli. The metric is word error rate (WER). The paper also reports production-level scaling experiments on anonymized in-house test sets covering call center, conversation, and dictation; these are also measured with WER.
For TTS, the model is trained on Libriheavy 50k hours of English data. Zero-shot synthesis is evaluated on LibriSpeech test-clean, with intelligibility measured by WER from Whisper-large-v3 and perceptual quality measured by UTMOS. The generated Mel frames are converted to waveforms using a HiFi-GAN vocoder.
ASR main results on OpenASR
The main ASR comparison addresses three conditions: an encoder-initialized baseline, an encoder-initialized model with fine-tuning, and the encoder-free Mel-LLM under either Phi-4-MM initialization or random initialization. The key result is that the encoder-free model remains competitive, with only modest degradation relative to the encoder-based alternative.
| System | AMI | Earnings22 | Gigaspeech | LS-clean | LS-other | SPGISpeech | TED-LIUM | VoxPopuli | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Whisper-Large-V3 | 15.95 | 11.29 | 10.02 | 2.01 | 3.91 | 2.94 | 3.86 | 9.54 | 7.44 |
| Phi-4-MM | 11.69 | 10.16 | 9.78 | 1.68 | 3.83 | 3.13 | 2.90 | 5.91 | 6.14 |
| Phi-4-MM + FT | 11.16 | 9.57 | 9.45 | 1.32 | 2.95 | 1.70 | 2.70 | 6.03 | 5.61 |
| Random Enc FT | 12.19 | 14.31 | 10.38 | 1.62 | 4.27 | 2.04 | 3.29 | 7.65 | 6.97 |
| Mel-LLM (Phi-4-MM init) | 12.91 | 12.99 | 10.95 | 1.70 | 4.83 | 2.28 | 3.55 | 7.76 | 7.12 |
| Mel-LLM (Random init) | 13.65 | 11.98 | 11.38 | 1.83 | 5.50 | 2.47 | 4.42 | 8.25 | 7.44 |
Two comparisons stand out. First, the encoder-free Mel-LLM with Phi-4-MM initialization reaches an average WER of 7.12%, only 0.15 absolute points behind the encoder-initialized random-encoder fine-tuned baseline at 6.97%. Second, random initialization of the LLM is worse at 7.44%, showing that multimodal pretraining in Phi-4-MM provides an important starting point when data is limited.
Scaling behavior: limited public data versus 10x in-house data
The scaling experiments are central to the paper’s argument. On limited data, encoder-free speech modeling suffers a noticeable gap relative to an encoder-initialized system. When the authors scale to about 10 times more anonymized in-house training data, that gap shrinks substantially, supporting the claim that data scale is a key enabler for encoder-free architectures.
| Test set | Encoder-initialized | Encoder-free, limited data | Relative gap | Encoder-free, 10x scaled data | Relative gap |
|---|---|---|---|---|---|
| Call Center | 15.92 | 18.28 | +14.8% | 16.74 | +5.2% |
| Conversation | 15.83 | 17.10 | +8.0% | 16.25 | +2.7% |
| Dictation | 5.80 | 6.40 | +10.3% | 5.99 | +3.3% |
| Average | 12.52 | 13.93 | +11.3% | 12.99 | +3.8% |
The paper’s interpretation is straightforward: with insufficient data, the encoder-free model is still learning the mapping from acoustics to linguistic units; with enough data, the LLM can internalize this function and approach encoder-based performance. This is one of the strongest empirical supports for the paper’s thesis.
Ablation: token rate and downsampling
The token-rate ablation examines the trade-off between sequence length, training speed, and recognition quality. Lower token rates mean shorter sequences and higher training efficiency, but they can hurt WER if pushed too far. The paper reports that the 12.5 Hz setting gives the best balance for Mel-LLM, with a 1.57x training speedup over the encoder-based baseline.
| System | Token rate | AMI | Earnings22 | Gigaspeech | LS-clean | LS-other | SPGISpeech | TED-LIUM | VoxPopuli | Avg | Speedup |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Phi-4-MM-FT-Base | 12.5 Hz | 12.19 | 14.31 | 10.38 | 1.62 | 4.27 | 2.04 | 3.29 | 7.65 | 6.97 | 1.0x |
| Mel-LLM | 100 Hz | 12.34 | 10.56 | 10.41 | 1.63 | 4.50 | 2.20 | 3.29 | 7.74 | 6.58 | 0.33x |
| Mel-LLM | 50 Hz | 12.65 | 10.89 | 10.67 | 1.64 | 4.59 | 2.14 | 3.24 | 7.84 | 6.71 | 0.65x |
| Mel-LLM | 25 Hz | 13.18 | 13.69 | 10.80 | 1.73 | 4.77 | 2.15 | 3.38 | 7.96 | 7.21 | 1.09x |
| Mel-LLM | 12.5 Hz | 12.91 | 12.99 | 10.95 | 1.70 | 4.83 | 2.28 | 3.55 | 7.76 | 7.12 | 1.57x |
| Mel-LLM | 6.25 Hz | 14.80 | 15.13 | 11.82 | 1.86 | 5.70 | 2.49 | 3.91 | 8.43 | 8.02 | 1.88x |
The paper highlights two points. First, 25 Hz and 12.5 Hz perform similarly, but 12.5 Hz is preferred because it inherits the frame rate used in Phi-4-MM pretraining and yields the best quality-speed compromise. Second, very low token rates such as 6.25 Hz reduce quality too much, while very high rates such as 100 Hz and 50 Hz lengthen the sequence and slow training.
Ablation: which LLM layers matter for speech encoding?
The layer-wise ablation freezes upper LoRA layers at their Phi-4-MM initialization and observes how much recognition degrades. This is used to probe whether speech-specific adaptation is concentrated in lower or higher Transformer layers.
| System | AMI | Earnings22 | Gigaspeech | LS-c | LS-o | SPGISpeech | TED-LIUM | VoxPopuli | Avg |
|---|---|---|---|---|---|---|---|---|---|
| Phi-4-MM-FT-Base | 12.19 | 14.31 | 10.38 | 1.62 | 4.27 | 2.04 | 3.29 | 7.65 | 6.97 |
| Mel-LLM (Random init) | 13.65 | 11.98 | 11.38 | 1.83 | 5.50 | 2.47 | 4.42 | 8.25 | 7.44 |
| Mel-LLM (all LoRA) | 12.91 | 12.99 | 10.95 | 1.70 | 4.83 | 2.28 | 3.55 | 7.76 | 7.12 |
| + init. and freeze L16--31 | 14.08 | 13.43 | 11.78 | 2.25 | 6.67 | 2.86 | 3.96 | 8.48 | 7.94 |
| + init. and freeze L20--31 | 13.72 | 14.34 | 11.38 | 1.96 | 6.13 | 2.64 | 3.89 | 8.08 | 7.77 |
| + init. and freeze L24--31 | 13.76 | 12.72 | 11.26 | 1.95 | 5.54 | 2.46 | 3.70 | 8.05 | 7.43 |
| + init. and freeze L28--31 | 13.66 | 12.76 | 11.19 | 1.85 | 5.56 | 2.43 | 3.70 | 8.07 | 7.40 |
The interpretation in the paper is that upper layers already capture higher-level language semantics in Phi-4-MM and therefore need less task-specific adaptation. The larger degradation when freezing farther down the stack suggests that lower layers are doing most of the acoustic-to-linguistic conversion required for encoder-free ASR. In other words, the LLM is not merely memorizing transcripts; it is redistributing speech encoding into its early layers while preserving the language modeling function in the top layers.
TTS results: preliminary feasibility, not yet optimal quality
The TTS experiments are explicitly framed as preliminary. The key success criterion is feasibility: can the same encoder-free LLM backbone also generate speech-like Mel frames autoregressively? The answer is yes, but the training recipe is fragile and the quality is not yet competitive with mature TTS systems.
| System | WER | UTMOS |
|---|---|---|
| Mel-LLM (Random init) | Converges but produces no audible output | |
| Mel-LLM (Phi-4-MM, no norm) | 11.03 | 3.10 |
| Mel-LLM (Phi-4-MM, MVN) | 14.75 | 3.25 |
| + dropout 0.1 | 85.51 | 1.38 |
| + fix-KL (0-mean) | 12.65 | 3.22 |
| + sigma-VAE (0-mean) | 18.07 | 3.29 |
Several conclusions are drawn. First, random initialization is not sufficient for TTS: the model may converge numerically but generate no audible speech. Second, Phi-4-MM initialization is crucial for aligning text and mel spaces. Third, autoregressive generation is highly sensitive to training regularization; dropping input and output dropout from the default to 0.1 catastrophically harms both intelligibility and perceptual quality, which the authors interpret as a strong exposure-bias issue. Fourth, normalization and KL design choices trade off intelligibility and naturalness: MVN slightly worsens WER relative to no normalization but improves UTMOS, while fixed-KL and sigma-VAE variants do not consistently outperform the baseline.
What the experiments establish
Across ASR and TTS, the paper establishes three technical points. First, a large language model can directly consume Mel spectrograms without a separate speech encoder and still achieve competitive ASR performance. Second, data scale matters: encoder-free models are noticeably weaker in low-data settings, but the gap closes sharply as training data increases. Third, multimodal pretraining matters: Phi-4-MM initialization is especially important when the encoder is removed, because the model begins with some cross-modal alignment rather than having to discover it from scratch.
Equally important, the paper shows that the LLM backbone is not a passive decoder. Its lower layers are repurposed as an internal speech encoder, while upper layers retain language-semantic structure. This is the core architectural insight behind the ablations and the performance trends.
Limitations and future work
The authors are explicit that the TTS side is not yet optimal. The results are preliminary, and the generated speech quality remains below what would be expected from a production-grade system. The paper also treats ASR and TTS separately rather than training a single joint system that learns both understanding and generation in one loop.
Another practical limitation is the dependence on either multimodal initialization or large-scale data. In low-resource settings, encoder-free training degrades more clearly, and random initialization is inferior to Phi-4-MM initialization. The method therefore simplifies the architecture, but it does not eliminate the need for substantial training signal.
The paper’s stated future directions are to train ASR and TTS jointly and to explore speech-only pretraining for unified representation learning, with the goal of improving both speech understanding and speech generation in a single encoder-free architecture.
Concise takeaways for a conversational-AI team
- Mel-LLM removes the dedicated speech encoder and lets the LLM learn speech encoding directly from Mel spectrogram patches.
- ASR performance is competitive on OpenASR: the encoder-free Phi-4-MM-initialized model reaches 7.12% average WER, close to the encoder-based 6.97% baseline.
- Data scale is the main enabler for encoder-free speech modeling; the in-house gap drops from +11.3% relative WER to +3.8% when training data is scaled by 10x.
- Lower LLM layers absorb most of the acoustic adaptation, while upper layers remain more semantic and less task-specific.
- TTS is feasible with a next-token VAE Mel head, but quality is still preliminary and the recipe is sensitive to initialization and dropout.