SSL-GMMVC
SSL-GMMVC: Interpretable Voice Conversion via Locally Linear GMM Transforms in Self-Supervised Representation Space
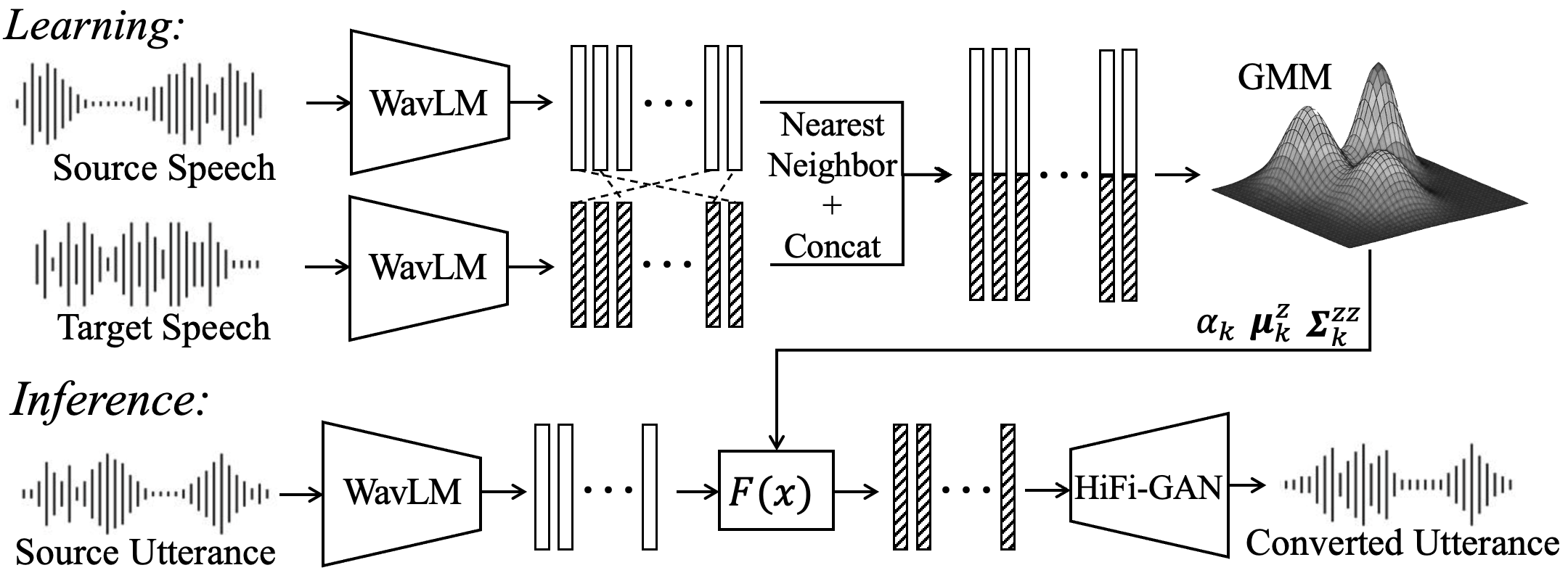
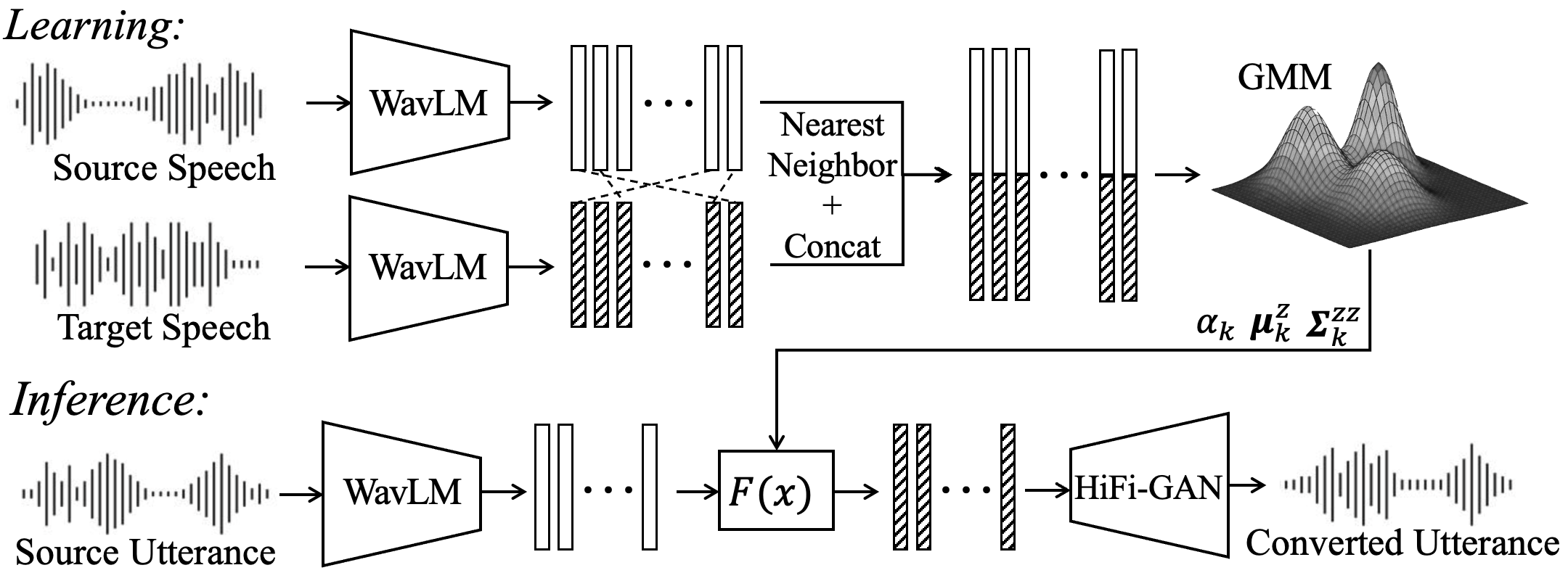
SSL-GMMVC is an interpretable voice conversion method using Gaussian mixture affine transforms in self-supervised speech space. It adapts to local structures to improve speaker similarity and reveals meaningful phonetic patterns, balancing simplicity and interpretability against complex neural models.
Demos
The SSL-GMMVC demo showcases interpretable voice conversion using locally linear GMM transforms in self-supervised speech representation space. Evaluate how well voice characteristics convert while keeping naturalness and intelligibility, and note the method's lightweight, interpretable approach compared to deep models.
Links
Paper & demos
Code & resources
Abstract
We introduce SSL-GMMVC, an interpretable voice conversion method in self-supervised speech space. The method models paired source-target features with a Gaussian mixture model and performs conversion as a posterior-weighted sum of affine transforms. This yields locally linear transformations that adapt to heterogeneous feature-space structure while remaining analytically tractable. Through objective and subjective evaluations, we show that SSL-GMMVC improves speaker similarity with comparable intelligibility and naturalness, and that even a constrained covariance variant surpasses a deep learning baseline as the number of mixture components increases. Further analyses link component selection to phonetic structure and reveal interpretable scaling and rotation in the learned transforms. These findings highlight SSL-GMMVC as an effective, analyzable framework for voice conversion.
Introduction
SSL-GMMVC addresses voice conversion (VC) as a transformation problem in self-supervised learning (SSL) feature space. The paper’s core motivation is that modern SSL embeddings such as WavLM provide rich acoustic representations, but many VC systems still rely on complex neural transformation modules. At the same time, very simple methods such as nearest-neighbor replacement or a single affine map in SSL space can already produce intelligible and speaker-like speech. SSL-GMMVC asks whether one can keep that simplicity and interpretability while gaining the flexibility needed to model local structure in the SSL space.
The proposed answer is a Gaussian mixture model (GMM) over paired source-target SSL features, combined with a posterior-weighted sum of component-wise affine transforms. In other words, the method replaces one global linear mapping with multiple locally linear maps, letting the conversion adapt to heterogeneous regions of the feature space while remaining analytically tractable. The paper argues that this is useful both practically, because it improves similarity under several conditions, and scientifically, because it exposes interpretable structure in SSL representations.
The paper’s main claims are: (1) a multi-component GMM transform can outperform a linear baseline in speaker similarity when enough paired data are available; (2) a constrained covariance variant can still exceed a deep learning baseline as the number of mixture components increases; and (3) the learned mixture assignments and transform spectra exhibit interpretable relationships to phonetic structure and speaker-pair distance.
Positioning relative to prior VC methods
The introduction situates SSL-GMMVC between two VC trends. On one side are SSL-based neural systems such as S3PRL-VC, FreeVC, and AdaptVC, which use SSL features but depend on more elaborate learned transformation networks. On the other side are simpler SSL-space methods such as kNN-VC and LinearVC. LinearVC is especially relevant because it shows that a single affine transform on SSL features can already be effective. SSL-GMMVC extends that idea by modeling local structure with a mixture model rather than forcing one global transform to fit all frames uniformly.
Formally, the method is presented as a structured generalization of LinearVC. When the number of mixture components is $K=1$, SSL-GMMVC reduces to a single affine map and is mathematically equivalent to LinearVC. For $K>1$, the method becomes globally nonlinear while preserving a closed-form, interpretable local linearization in each component.
Method
Pipeline overview
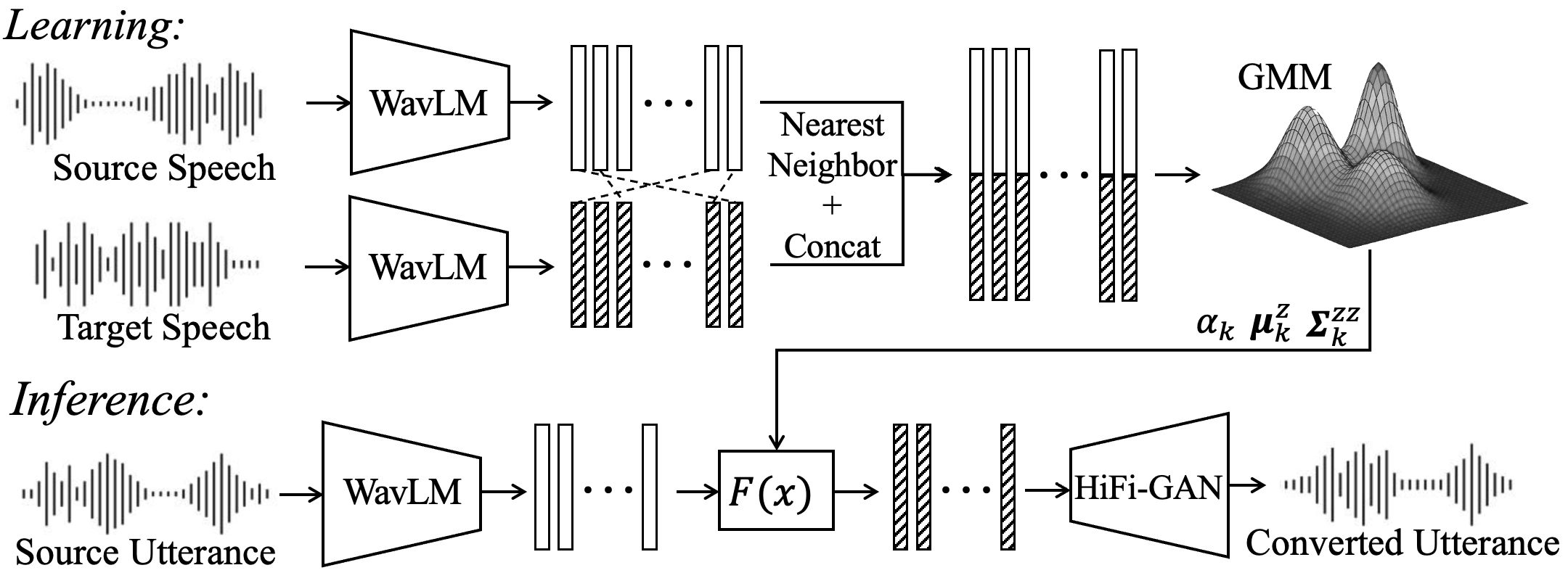
The pipeline has three stages. First, source and target utterances are converted to frame-level SSL features. Second, paired source-target vectors are created by nearest-neighbor alignment in SSL space. Third, a GMM is fit to the joint distribution of these paired vectors. At inference time, the source-side posterior over mixture components determines a weighted sum of affine transforms that maps source features into the target feature space. A vocoder then synthesizes waveform audio from the converted features.
Feature representation and alignment
The experiments use $1024$-dimensional SSL features from the 6th layer of WavLM-Large, extracted with $20$ ms frames from $16$ kHz speech. The paper follows prior work in aligning source and target features using bidirectional cosine-similarity nearest-neighbor matching. This alignment step is important because the GMM is fit not to raw waveforms, but to paired source-target feature vectors that approximate correspondence across utterances.
GMM voice conversion model
Let $b{x}, \mathbf{y} \in \mathbb{R}^D$ denote source and target SSL feature vectors at a frame. After alignment, the model forms the joint vector $\mathbf{z} = [\mathbf{x}^\top, \mathbf{y}^\top]^\top \in \mathbb{R}^{2D}$ and fits a $K$-component GMM:
$$p(\mathbf{z}) = \sum_{k=1}^{K} \alpha_k \, \mathcal{N}(\mathbf{z}; \boldsymbol{\mu}_k^{z}, \boldsymbol{\Sigma}_k^{zz}).$$
The joint mean and covariance are partitioned into source and target blocks:
$$\boldsymbol{\mu}_k^{z} = \begin{bmatrix} \boldsymbol{\mu}_k^{x} \\ \boldsymbol{\mu}_k^{y} \end{bmatrix}, \qquad \boldsymbol{\Sigma}_k^{zz} = \begin{bmatrix} \boldsymbol{\Sigma}_k^{xx} & \boldsymbol{\Sigma}_k^{xy} \\ \boldsymbol{\Sigma}_k^{yx} & \boldsymbol{\Sigma}_k^{yy} \end{bmatrix}.$$
Parameters $\{\alpha_k, \boldsymbol{\mu}_k^{z}, \boldsymbol{\Sigma}_k^{zz}\}_{k=1}^{K}$ are estimated with the EM algorithm. In the E-step, the responsibility of component $k$ for sample $\mathbf{z}_n$ is
$$p(k \mid \mathbf{z}_n) = \frac{\alpha_k \mathcal{N}(\mathbf{z}_n; \boldsymbol{\mu}_k^{z}, \boldsymbol{\Sigma}_k^{zz})}{\sum_{m=1}^{K} \alpha_m \mathcal{N}(\mathbf{z}_n; \boldsymbol{\mu}_m^{z}, \boldsymbol{\Sigma}_m^{zz})}.$$
At inference, the posterior is computed from the source marginal only:
$$p(k \mid \mathbf{x}) = \frac{\alpha_k \mathcal{N}(\mathbf{x}; \boldsymbol{\mu}_k^{x}, \boldsymbol{\Sigma}_k^{xx})}{\sum_{m=1}^{K} \alpha_m \mathcal{N}(\mathbf{x}; \boldsymbol{\mu}_m^{x}, \boldsymbol{\Sigma}_m^{xx})}.$$
The converted feature is the posterior-weighted sum of component-wise affine transforms:
$$\hat{\mathbf{y}} = F(\mathbf{x}) = \sum_{k=1}^{K} p(k \mid \mathbf{x})\,\Bigl\{\boldsymbol{\mu}_k^y + \boldsymbol{\Sigma}_k^{yx}(\boldsymbol{\Sigma}_k^{xx})^{-1}(\mathbf{x} - \boldsymbol{\mu}_k^x)\Bigr\}.$$
This is the paper’s central modeling idea: each component contributes a locally linear map, and the final output is a mixture-weighted interpolation among those local maps. The result is globally nonlinear conversion that still admits closed-form interpretation component by component.
Relationship to LinearVC
The paper explicitly shows that SSL-GMMVC subsumes LinearVC. If $K=1$, the posterior is identically $1$, so the conversion reduces to a single affine transform:
$$F(\mathbf{x}) = \boldsymbol{\mu}^y + \boldsymbol{\Sigma}^{yx}(\boldsymbol{\Sigma}^{xx})^{-1}(\mathbf{x} - \boldsymbol{\mu}^x).$$
By defining $\mathbf{W} = (\boldsymbol{\Sigma}^{xx})^{-1}\boldsymbol{\Sigma}^{xy}$ and $\mathbf{b} = \boldsymbol{\mu}^y - \mathbf{W}^\top \boldsymbol{\mu}^x$, this becomes $F(\mathbf{x}) = \mathbf{W}^\top \mathbf{x} + \mathbf{b}$, which is mathematically equivalent to LinearVC. Thus, SSL-GMMVC is not an unrelated method but a strict generalization of the linear baseline.
Covariance variants
The experiments evaluate two covariance parameterizations. Full ($\textit{F}$) allows unconstrained covariance matrices, while Cross Diag ($\textit{CD}$) constrains all four blocks in the joint covariance to be diagonal. The paper treats $\textit{CD}$ as a lower-complexity variant inspired by traditional GMM-VC practice, specifically to reduce overfitting risk and study how model capacity affects performance in high-dimensional SSL space.
Experimental setup
| Aspect | What the paper used |
|---|---|
| Speech data | CMU ARCTIC American English speech, using 6 speakers: male $\{\text{bdl}, \text{rms}, \text{aew}\}$ and female $\{\text{slt}, \text{clb}, \text{lnh}\}$; utterances are about 2--3 seconds long. |
| SSL representation | WavLM-Large 6th-layer features, $1024$ dimensions, $20$ ms frames, extracted from $16$ kHz audio. |
| Alignment | Bidirectional cosine-similarity nearest-neighbor matching between source and target features. |
| Training | EM estimation of the GMM, with mixture counts $K \in \{1,2,4\}$ and training-set sizes $N \in \{10,20,50,100,200,300\}$ utterances. |
| Vocoder | HiFi-GAN trained to accept WavLM-Large 6th-layer features. |
| Baselines | LinearVC with $\textit{NC}$ (No Constraint) and $\textit{BO}$ (Bias Only), plus FreeVC as a deep VITS-based zero-shot baseline. |
| Metrics | Speaker similarity via ECAPA-TDNN-based EER, intelligibility via Whisper-base WER, and naturalness via UTMOS. |
The paper evaluates all $30$ ordered speaker pairs from the 6 speakers. For objective evaluation, the same model family is trained separately for each pair. Intelligibility and naturalness are measured on $40$ utterances not used for training. For speaker similarity, the paper compares $100$ converted--real pairs against $100$ real--real pairs using cosine similarity between ECAPA-TDNN embeddings; higher EER means the converted speech is harder to distinguish from the target speaker and therefore more similar.
The subjective study is narrower but still covers all gender directions. It uses four speaker pairs: $\text{bdl}\to\text{rms}$, $\text{clb}\to\text{slt}$, $\text{bdl}\to\text{slt}$, and $\text{clb}\to\text{rms}$. For each pair and each model, five utterances are converted and each sample receives five ratings from crowdworkers on Lancers. Similarity is rated on a 4-point scale using a real target reference, while naturalness is rated on a 5-point scale in isolation. Each rater completes 21 trials and an attention-check real--real same-speaker trial; raters who fail that check are excluded.
In preliminary work, the authors found that increasing the number of reference utterances beyond 10 did not improve similarity, so they fixed the reference set size at 10 throughout the experiments.
Results
Objective evaluation
The most important trend is that SSL-GMMVC benefits from both more data and more mixture components, especially in the unconstrained $\textit{F}$ setting. For speaker similarity, the EER of SSL-GMMVC $\textit{F}$ rises steadily as $N$ increases, and $K=2$ or $K=4$ overtakes LinearVC $\textit{NC}$ once enough data are available. The paper reports that $\textit{F}$ surpasses LinearVC $\textit{NC}$ at $N \geq 100$ for $K=2$ and at $N \geq 200$ for $K=4$.
The most competitive objective speaker-similarity numbers are in the high-data unconstrained regime. For example, at $N=200$, SSL-GMMVC $\textit{F}$ with $K=2$ reaches an EER of $27.27\%$ and with $K=4$ reaches $27.30\%$, both above LinearVC $\textit{NC}$ at $25.88\%$. At $N=300$, the $K=4$ model reaches $27.35\%$ EER. By contrast, the constrained $\textit{CD}$ models produce much lower EERs overall, but still consistently beat LinearVC $\textit{BO}$ across all settings; the authors interpret this as the effect of allowing both scaling and shifting, whereas $\textit{BO}$ only permits mean shift.
For intelligibility, the unconstrained models initially suffer at $N=10$ but become comparable to or better than FreeVC once $N \geq 20$. The paper notes that SSL-GMMVC $\textit{F}$ does not beat LinearVC $\textit{NC}$ in WER, but remains close. In the reported table, for instance, $\textit{F}$ with $K=2$ has WER $2.81\%$ at $N=200$ and $2.85\%$ at $N=300$, while LinearVC $\textit{NC}$ is $2.61\%$ and $2.70\%$ at those same sizes. The constrained models remain intelligible even with only $N=10$ utterances, and SSL-GMMVC $\textit{CD}$ outperforms LinearVC $\textit{BO}$ in all WER settings.
Naturalness follows a similar pattern. In the unconstrained setting, SSL-GMMVC $\textit{F}$ with $K>1$ matches LinearVC $\textit{NC}$ and at larger data sizes can exceed FreeVC. At $N=200$, SSL-GMMVC $\textit{F}$ with $K=2$ reaches UTMOS $4.33$, matching the strongest value in the table and slightly exceeding FreeVC’s $4.25$; LinearVC $\textit{NC}$ is also at $4.33$ for the same size. The constrained models are more conservative but highly stable, and the paper emphasizes that $\textit{CD}$ with $K>1$ surpasses LinearVC $\textit{BO}$ in naturalness once $N \geq 100$.
One useful way to read the objective results is as an empirical trade-off curve. Larger $K$ and more data improve similarity, but the improvement is only useful if intelligibility and naturalness remain acceptable. SSL-GMMVC’s main advantage is that it makes this trade-off adjustable: the unconstrained $\textit{F}$ model pushes similarity higher when data are available, while the constrained $\textit{CD}$ model stays more robust in low-data conditions.
Subjective evaluation
The listening-test results broadly match the objective metrics, while also showing where objective and subjective rankings diverge slightly. With $N \geq 20$, all unconstrained models surpass FreeVC in perceived speaker similarity, and similarity MOS generally rises with more training data. The paper reports that SSL-GMMVC $\textit{F}$ exceeds LinearVC $\textit{NC}$ at $N \geq 200$ in the subjective test, which is consistent with the objective EER trend.
At $N=200$, the subjective similarity MOS for SSL-GMMVC $\textit{F}$ with $K=2$ is $2.88$ with a $95\%$ confidence interval of $\pm 0.18$, compared with LinearVC $\textit{NC}$ at $2.75(20)$ and FreeVC at $2.04(20)$. The $K=4$ model also performs well, reaching $2.65(19)$ at $N=200$ and $2.85(18)$ at $N=300$. For the constrained family, SSL-GMMVC $\textit{CD}$ consistently surpasses LinearVC $\textit{BO}$ and improves as $K$ increases, but it remains below the unconstrained family in target-speaker resemblance.
Naturalness in the subjective test behaves similarly to the objective UTMOS estimates. The unconstrained models are poor at $N=10$ because of conversion artifacts, but they recover quickly for larger $N$ and approach FreeVC-level naturalness as the training set grows. The constrained models remain stable across all $N$, matching the paper’s claim that the smaller parameterization makes content-preserving mappings easier to learn from limited data, even if the resulting speech sounds less like the target speaker.
Representative reported numbers
| Setting | EER $\uparrow$ | WER $\downarrow$ | UTMOS $\uparrow$ | Subjective similarity MOS | Subjective naturalness MOS |
|---|---|---|---|---|---|
| SSL-GMMVC $\textit{F}$, $K=2$, $N=200$ | $27.27\%$ | $2.81\%$ | $4.33$ | $2.88(18)$ | $3.97(18)$ |
| LinearVC $\textit{NC}$, $N=200$ | $25.88\%$ | $2.61\%$ | $4.33$ | $2.75(20)$ | $4.05(19)$ |
| FreeVC | $2.85\%$ | $3.85\%$ | $4.25$ | $2.04(20)$ | $4.11(18)$ |
| SSL-GMMVC $\textit{CD}$, $K=4$, $N=200$ | $4.20\%$ | $3.00\%$ | $4.13$ | $2.35(21)$ | $3.46(20)$ |
| LinearVC $\textit{BO}$, $N=200$ | $0.67\%$ | $3.22\%$ | $4.08$ | $1.58(18)$ | $3.54(24)$ |
This table is intentionally selective rather than exhaustive. The full paper evaluates all combinations of $N \in \{10,20,50,100,200,300\}$ and $K \in \{1,2,4\}$ for both covariance variants, with stability constraints that require $N \geq 50$ for $K=2$ and $N \geq 100$ for $K=4$.
Further analysis
Component selection and phonetic structure
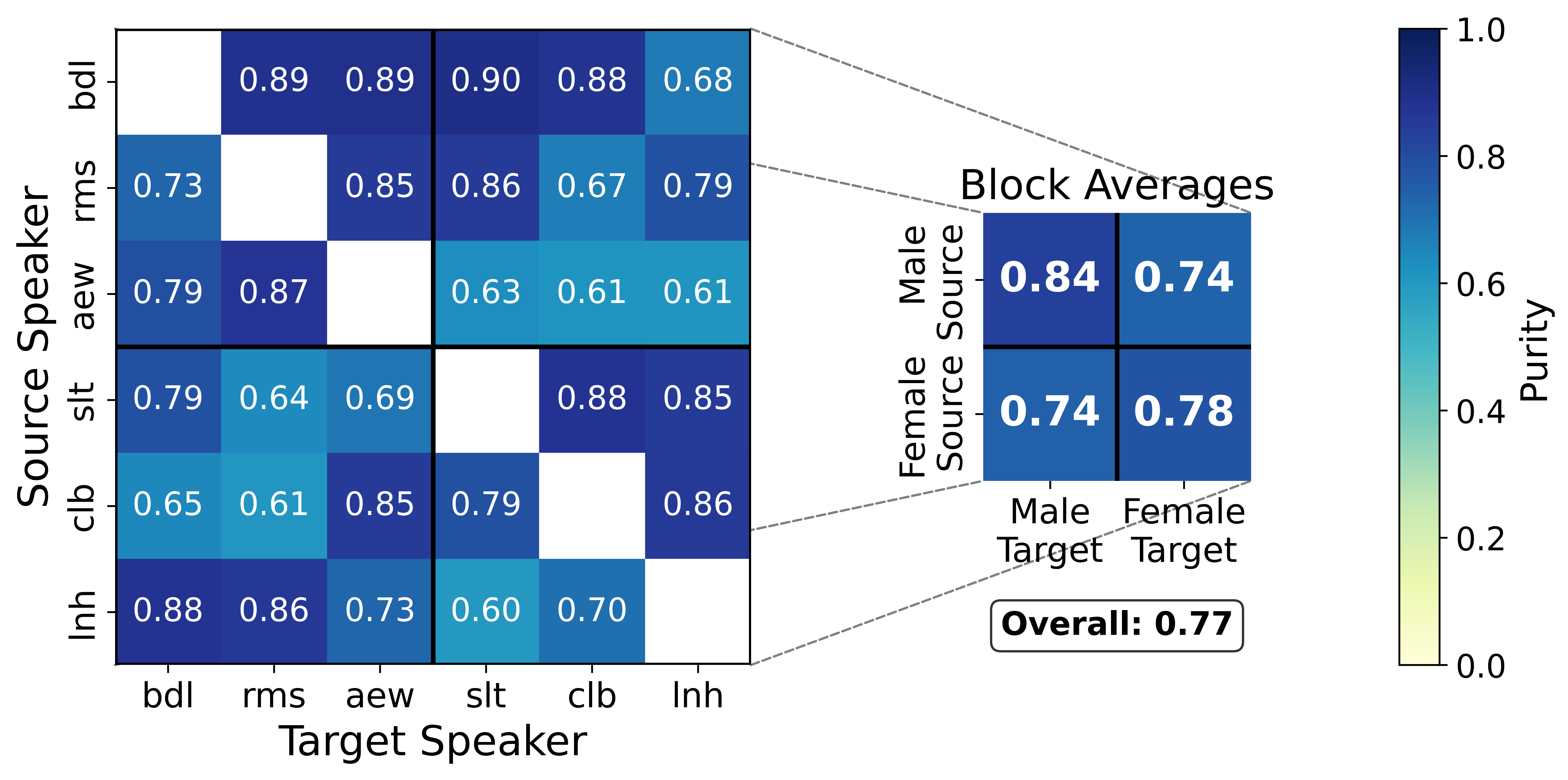
The authors investigate whether mixture selection aligns with phonetic categories. They analyze SSL-GMMVC $\textit{F}$ with $K=2$ and $N=200$ using $50$ held-out utterances per speaker pair. Frames are labeled as sonorants or obstruents via Montreal Forced Aligner, and purity is computed from the posterior responsibilities as a soft clustering score.
The result is that mixture selection shows relatively high overall purity with respect to sonority, indicating a meaningful relationship between component assignment and phonetic structure. The paper notes variation across speaker pairs, but the general trend is clear enough to support the interpretation that the GMM is discovering acoustically and phonologically relevant regions of SSL space. Same-gender conversions tend to achieve higher purity than cross-gender conversions.
Transformation geometry
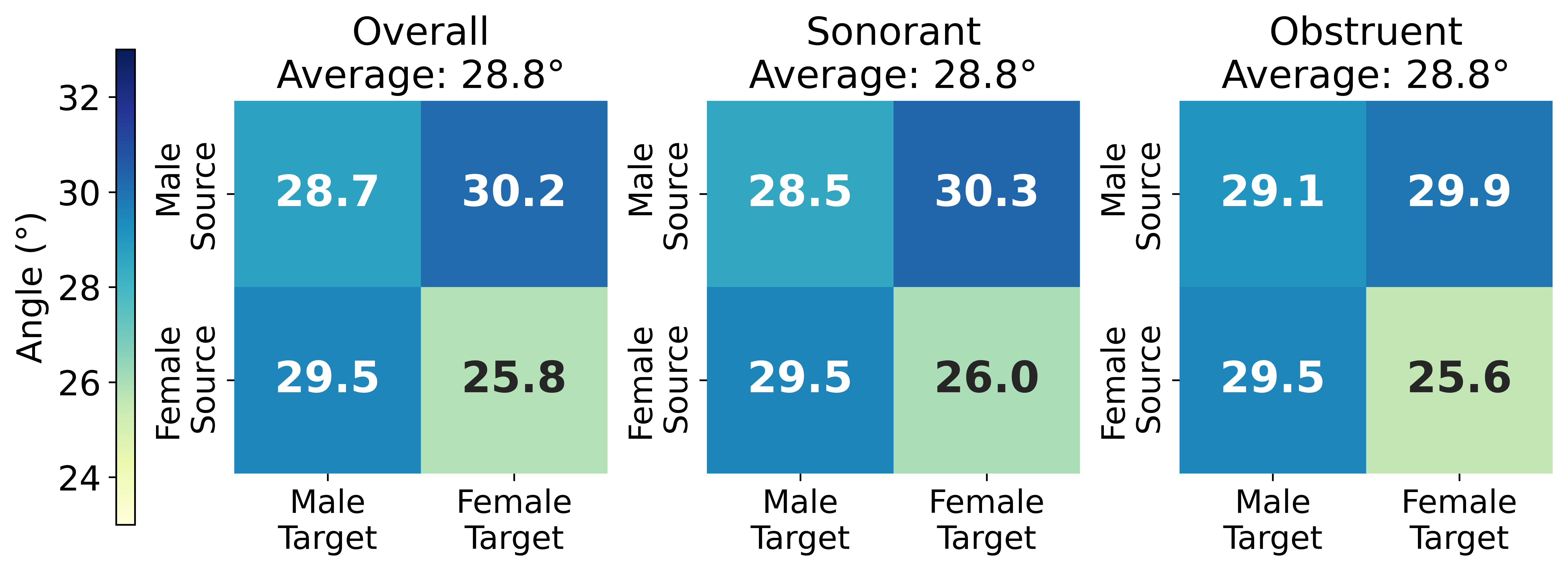
To understand the learned maps themselves, the paper examines SSL-GMMVC $\textit{F}$ with $K=1$ and $N=200$. It first measures per-frame cosine angles between source and converted SSL features, both overall and separately on sonorant and obstruent regions. These angles are typically in the $25$--$30^\circ$ range. Female-to-female pairs have the smallest angles, followed by male-to-male pairs, with cross-gender pairs having the largest angles. The paper reports no clear difference between sonorants and obstruents in this measure.
Because a cosine angle alone does not fully characterize a transform in $1024$ dimensions, the authors also analyze the eigenvalues of the conversion matrix $\mathbf{W}$ from the single-component model. Writing an eigenvalue as $\lambda = r e^{i\theta}$, they interpret $r$ as scaling and $\theta$ as the rotation angle of the associated plane. This is the paper’s main mechanistic interpretability result: the learned conversion is best described as a contractive rotation.
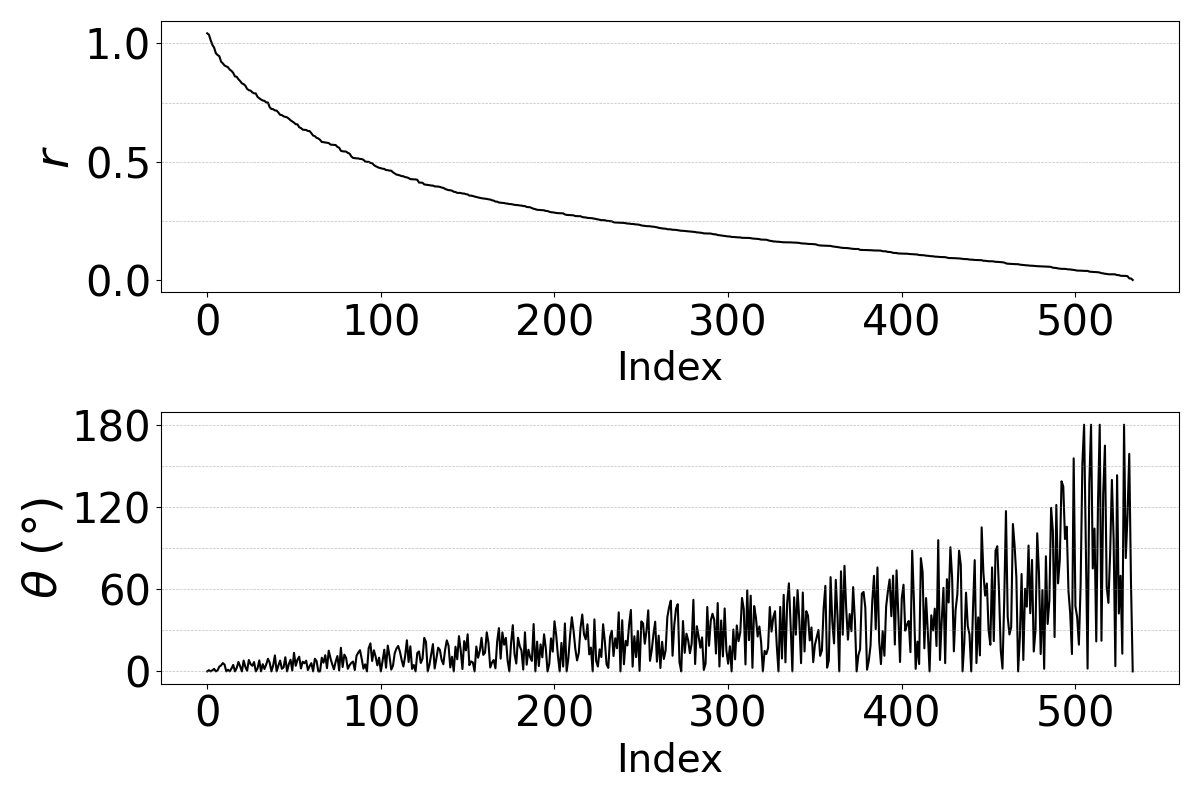
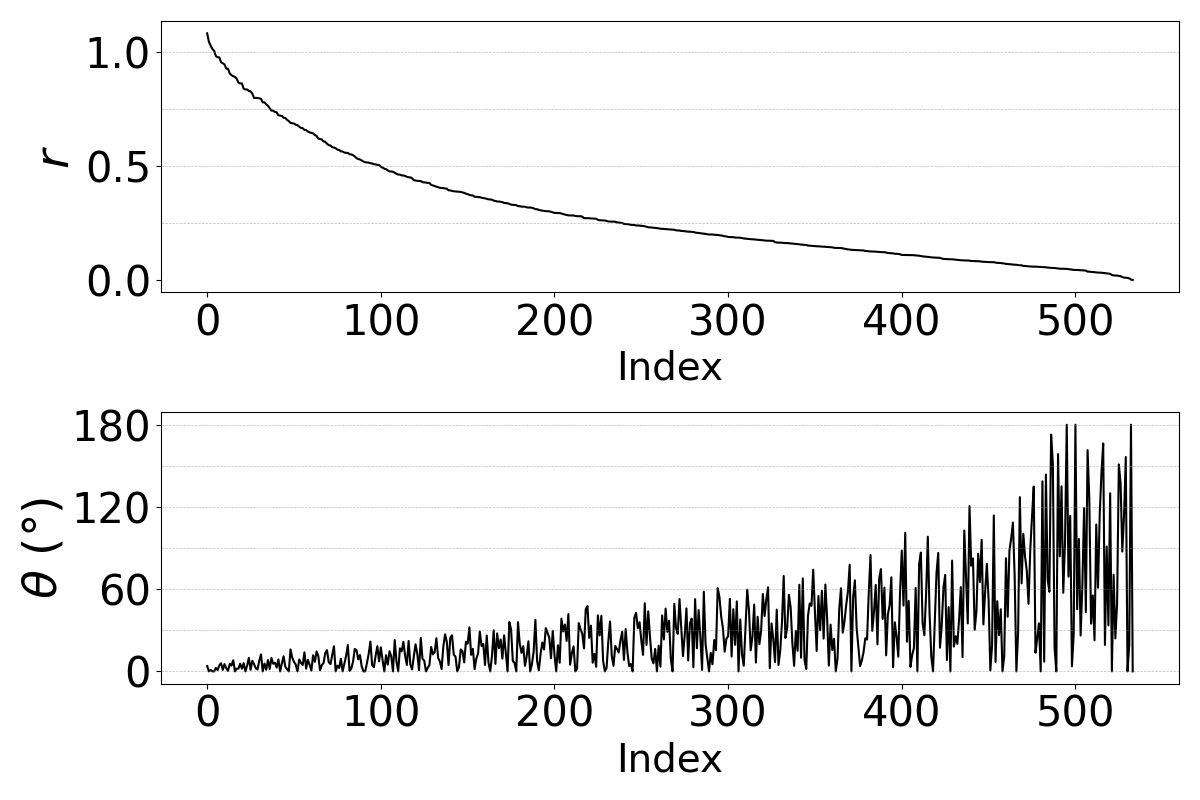
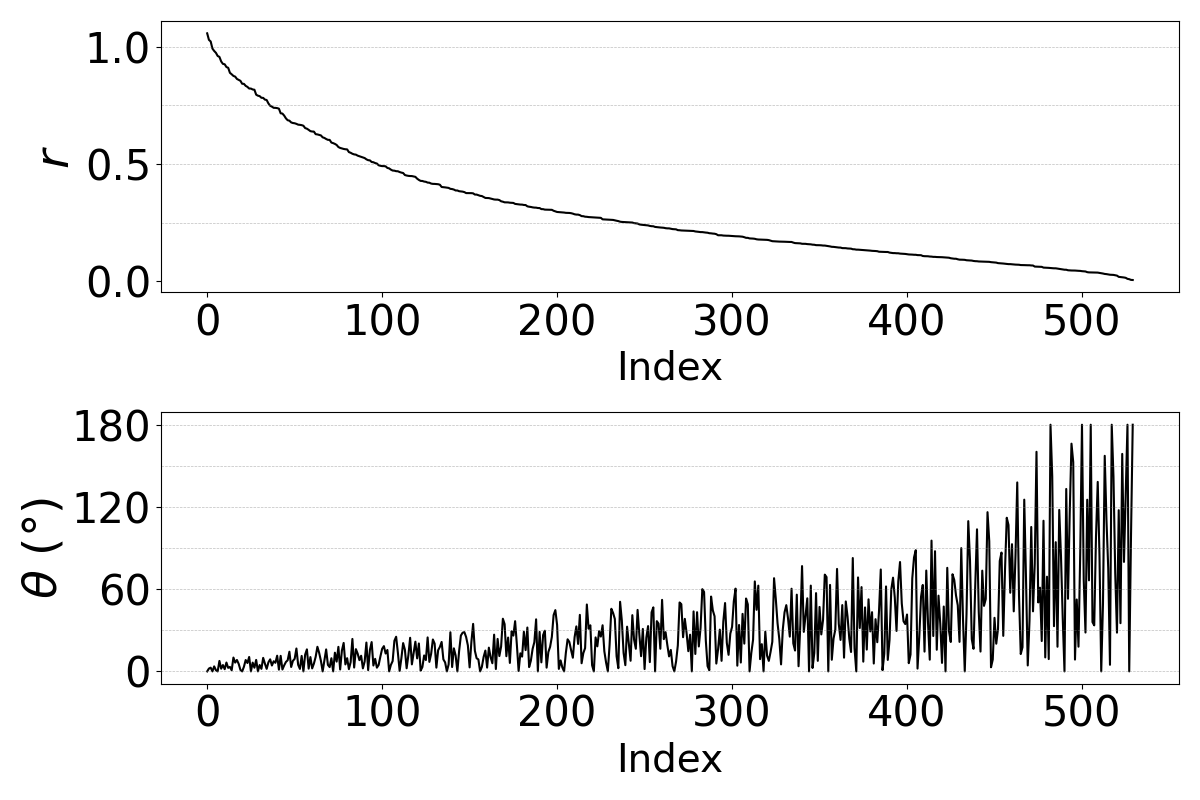
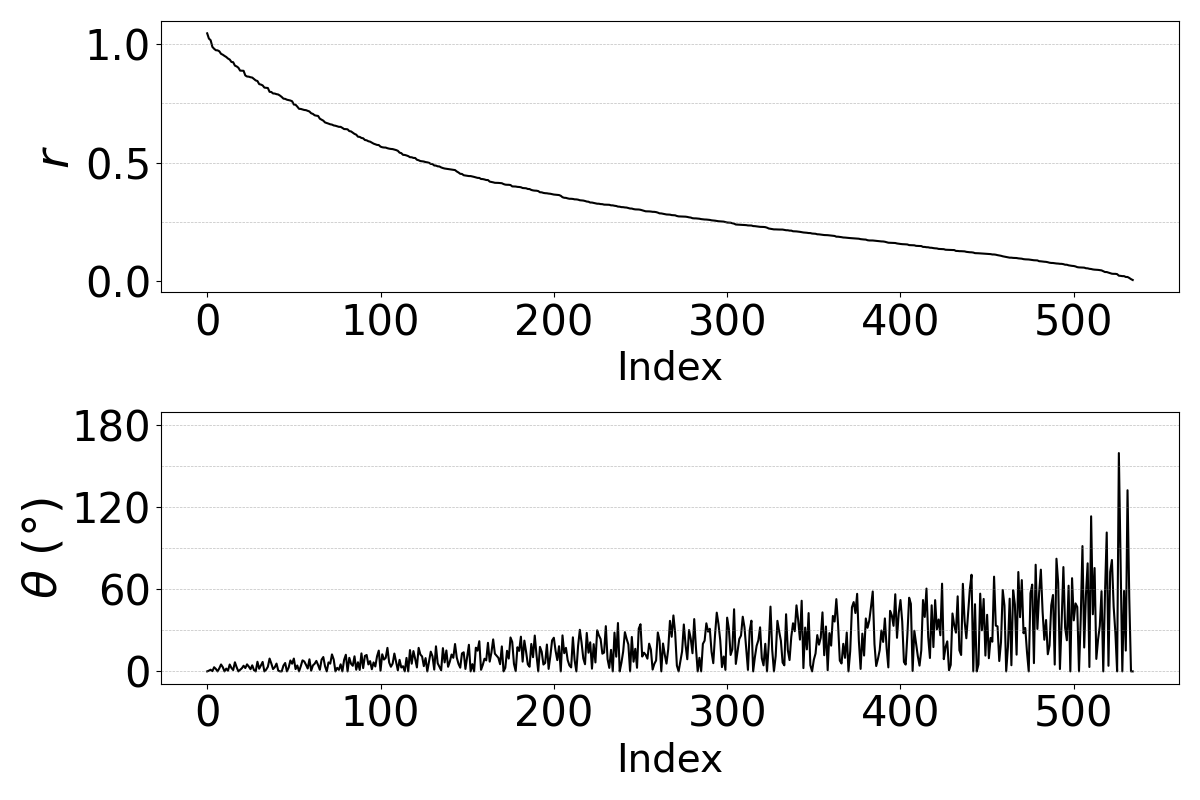
The spectra show that eigenmodes with high scaling factor $r$ usually have small rotation angles, while low-$r$ modes can have more variable angles but contribute less because they are strongly shrunk. This implies that the transform concentrates information in a relatively small number of components rather than distributing it uniformly across all dimensions. The paper also notes that the $\text{clb} \to \text{slt}$ pair has smaller rotation angles, consistent with the broader observation that female-to-female conversions tend to require smaller geometric changes than cross-gender conversions.
The authors cautiously suggest that the angle $\theta$ may reflect inter-speaker acoustic distance, but they stop short of claiming a definitive metric relationship. They also explicitly note a limitation: for $K>1$, they do not yet have a principled method for matching rotational planes across components, so the spectral analysis is restricted to the single-component model.
Interpretation, limitations, and takeaways
SSL-GMMVC’s main contribution is conceptual as much as empirical. It demonstrates that a mixture of locally linear transforms in SSL space can improve VC performance while preserving a transparent mathematical structure. In contrast to end-to-end neural VC systems, the method exposes the role of each GMM component, and the paper’s further analysis suggests that those components are not arbitrary: they correlate with phonetic categories and encode speaker-pair geometry in an interpretable way.
At the same time, the paper is clear about its limitations. The most important practical challenge is scaling the number of mixture components while keeping parameter estimation stable in a high-dimensional SSL space. That is why the authors cap $K$ at $4$ and require more data for larger mixtures. A second limitation is analytical: although the single-component model can be interpreted through eigenvalue spectra, there is not yet a principled way to align rotational planes across different components or speaker pairs, which limits the interpretability of the multi-component case.
Overall, the paper’s empirical message is that mixture-based local linearity is a meaningful middle ground between simple global transforms and more complex neural VC systems. With enough paired data, SSL-GMMVC $\textit{F}$ can improve speaker similarity while remaining competitive on intelligibility and naturalness; with restricted covariance, $\textit{CD}$ offers a more stable, lower-capacity option that still beats a linear constrained baseline and can surpass FreeVC in similarity as $K$ increases. The authors therefore frame SSL-GMMVC as both an effective VC system and a tool for studying the structure of SSL speech representations.
Conclusion
The paper concludes that SSL-GMMVC extends a single global affine map to locally linear GMM-based mappings in SSL feature space. Objective and subjective evaluations show improved speaker similarity over LinearVC in the settings where enough data are available, with comparable intelligibility and naturalness overall. The constrained covariance variant is especially notable because it remains stable and, with more mixture components, can surpass FreeVC in speaker similarity. The interpretability analyses add an important scientific dimension: mixture selection relates to phonetic structure, and the learned transforms behave like contractive rotations whose angles may encode speaker-pair distance. The authors close by identifying stable high-dimensional estimation and cross-component spectral alignment as open problems for future work.
Code & Implementation
This repository implements SSL-GMMVC, the interpretable voice conversion method proposed in the paper, which combines Gaussian Mixture Models (GMMs) with self-supervised speech representations for voice conversion.
The core implementation is organized around a modular GMM framework, factored along two independent axes: the mathematical covariance structure and the computational backend (CPU/GPU via PyTorch or Numpy). This modular design is managed by a central EM driver that fits the joint GMM, enabling flexible covariance constraints and backend-specific optimizations without changing the core algorithm.
The main source code modules are:
gmm/estimator.py: Implements the EM algorithm for fitting the joint GMM.gmm/covariance.py: Defines different covariance model classes that control the GMM's covariance structure.gmm/backends.py: Provides backend abstractions to switch between CPU/GPU and Numpy/PyTorch computations.gmm/presets.py: Offers preset configurations combining covariance structures and backends for ease of use.
This design allows seamless extension, such as adding new covariance constraints or computational backends, by creating subclasses in the corresponding modules.
The repository is designed to be used with Python 3.10 and requires a CUDA-capable GPU for running the PyTorch backend. It uses the UV tool for dependency management and environment setup.